The slingshot helps with learning
post by Wilson Wu (wilson-wu) · 2024-10-31T23:18:16.762Z · LW · GW · 0 commentsContents
1 Introduction 1.1 The k-sparse parity task 1.2 The slingshot effect 2 Why do slingshots happen in the k-sparse parity setting? 2.1 Hinge loss 2.2 Cross-entropy loss 2.3 Resetting AdamW mitigates slingshots 3 Slingshots and generalization 3.1 Slingshots tend to decrease test loss 3.2 Slingshots vs random jumps 3.3 Slingshots and LLC 4 Discussion None No comments
The slingshot effect is a late-stage training anomaly found in various adaptive gradient optimization methods. In particular, slingshots are present with AdamW, the optimizer most widely used for modern transformer training. The original slingshot paper observes that slingshots tend to occur alongside grokking, a phenomenon in which neural networks trained on algorithmic tasks generalize to the test set long after perfectly fitting the training set. In this post we take a closer look at slingshots and their effect on generalization in the setting of 1-hidden-layer MLPs trained on -sparse parity, a specific algorithmic task. The main results are 1) an explanation of why slingshots occur in models trained with hinge loss that partially transfers to models trained with cross entropy loss and 2) empirical evidence that slingshots are biased towards decreasing test loss.
1 Introduction
1.1 The -sparse parity task
A -sparse parity function is a function that takes in a bitstring of length and returns the parity (XOR) of a specific size subset of the input bits. Thus, for fixed , there are different -sparse parity functions. We start by sampling one of these functions at random; the model's task is then to learn this function from a training set of input/output sample pairs. Intuitively, the heart of this problem is distinguishing from the training samples alone which of the input bits is relevant. Learning -sparse parities is a well-studied task with known computational[1] lower bounds. See Barak et al. 2023 for more details.
In our experiments, we train a 1-hidden-layer ReLU MLP on this task. Input bitstrings of length are encoded as vectors in for input to the model. We set and and MLP dimensionality . All experiments (unless noted otherwise) use the AdamW optimizer with learning rate set to and all other hyperparameters left as default.
1.2 The slingshot effect
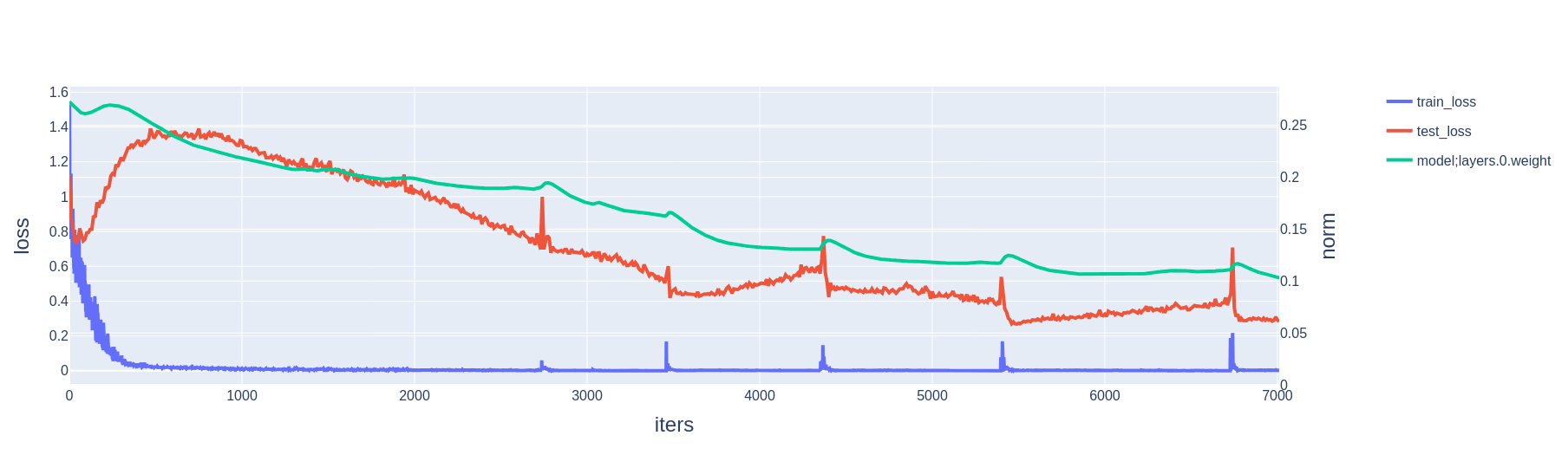
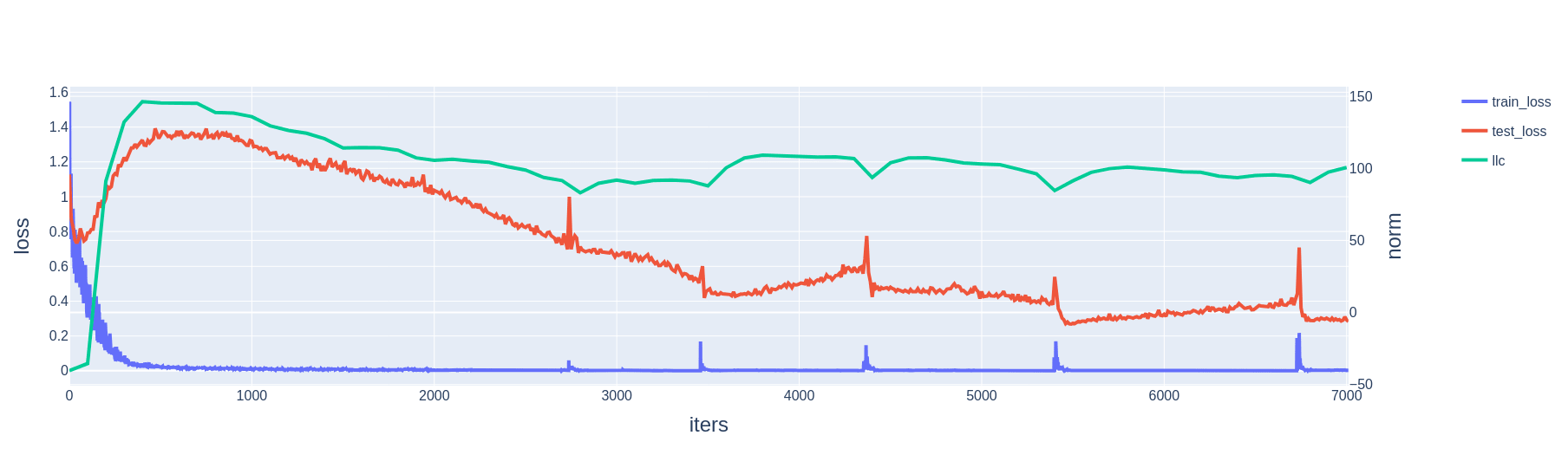
A slingshot is a spike in training loss co-occurring with a sudden increase in weight norm. In our experiments, we observe that it is often also associated with a sudden drop in test loss.
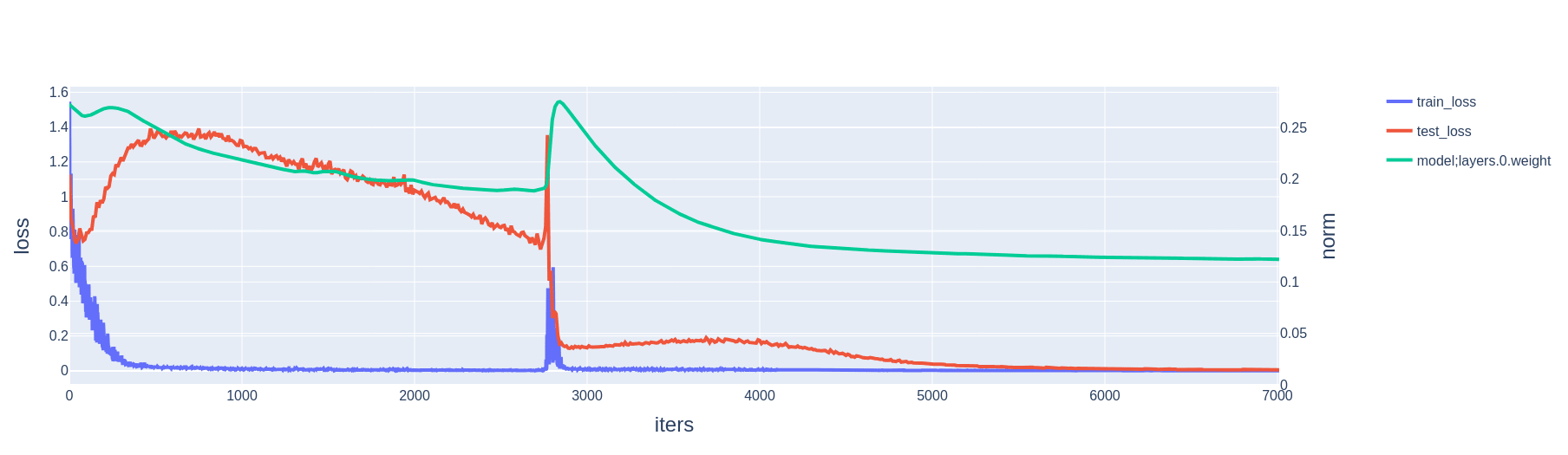
2 Why do slingshots happen in the -sparse parity setting?
We first consider models trained with hinge loss, for which we have an explanation of the slingshot phenomenon. Then we consider models trained with cross-entropy loss; there the picture is somewhat messier, but some aspects of the same explanation still transfer over.
When discussing AdamW's internal state we will use the same notation as in the pseudocode here.
2.1 Hinge loss
For hinge loss, we remap the expected model output from 0/1 to . The loss given model output and ground truth label is then . As opposed to the case with cross-entropy loss, with hinge loss there are wide (topologically open) regions of output space, and thus parameter space, for which the loss (and hence the gradient) is precisely zero.
The story goes:
- Training proceeds until the model perfectly fits the training data and model parameters enter a zero training loss basin.
- Within this basin, because there is no gradient, momentum quickly decays to zero. Movement in parameter space is then driven entirely by weight decay. Meanwhile, the variance estimate more slowly decays to zero. (The default AdamW decay factors, and the ones we use in our experiments, are for momentum and for variance.)
- Eventually, weight decay causes the model parameters to hit a wall of the basin; i.e., they have shrunk to the point where they no longer maintain perfect accuracy on the training set. The gradient is no longer zero; momentum is updated as approximately , variance is updated as approximately ,[2] and parameters are updated as
- This large parameter update (a factor of larger than is typical[3]) slingshots the model parameters out of the zero loss basin. Geometrically, the slingshot must be in the direction of increasing weight norm, because the parameters hit the basin's wall while moving in the direction of decreasing weight norm.
- If the gradient wherever the model parameters land happen to be aligned with , then the effect is compounded.[4] E.g., if it so happens that , then in the next step the numerator of the parameter update is roughly doubled, while the denominator is multiplied by a factor of . Immediately after the slingshot, the numerator scales linearly with the number of following steps aligned with the initial gradient, while the denominator scales with the square root.
Note that, with AdamW, the weight decay is decoupled from the momentum and variance estimates. Thus, if the gradient at each step is near zero, both these estimates decay towards zero. Simultaneously, the model still moves in parameter space under the effect of weight decay.
If we were using Adam instead, the corresponding condition would be for the loss gradient and weight decay terms to cancel each other out. In this case, the model parameters would necessarily be near-stationary and unable to "drift into a wall" as in Step 3 above. Indeed, we do not find any slingshots when using the Adam optimizer. Note that this seems to contradict the results of Thilak et al.; see Sec. 4 for further discussion of this and other discrepancies.

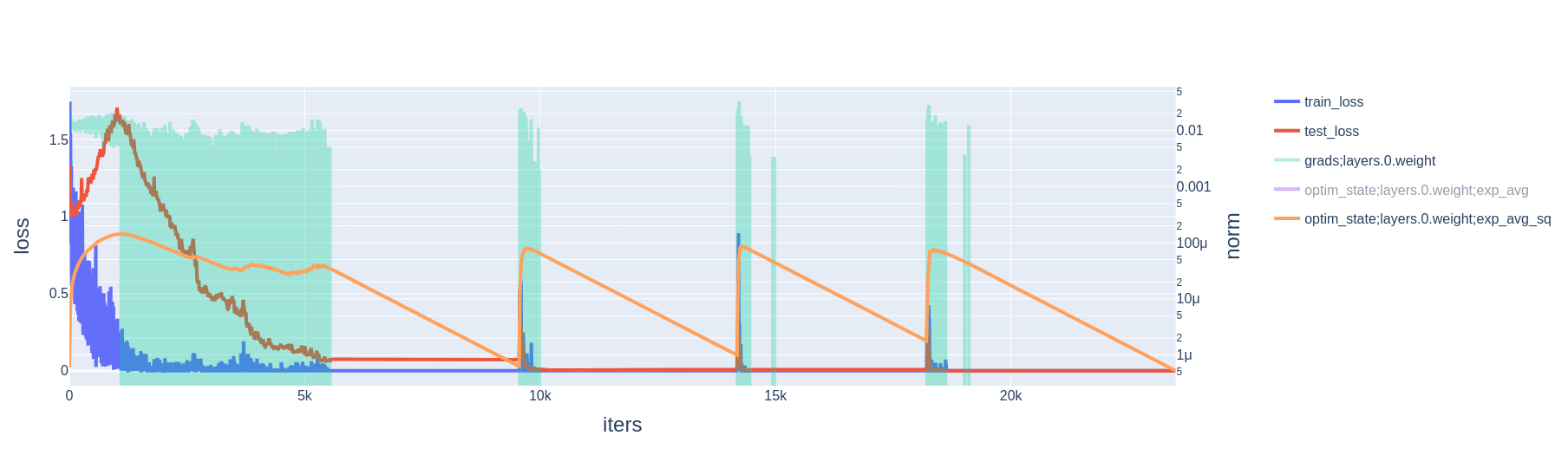
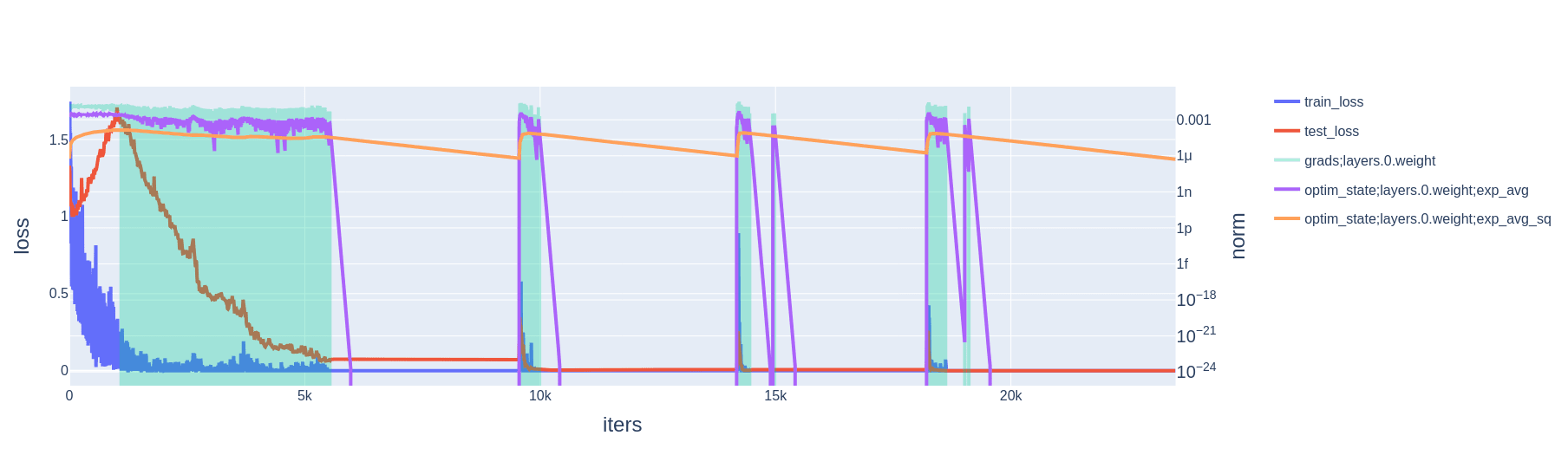
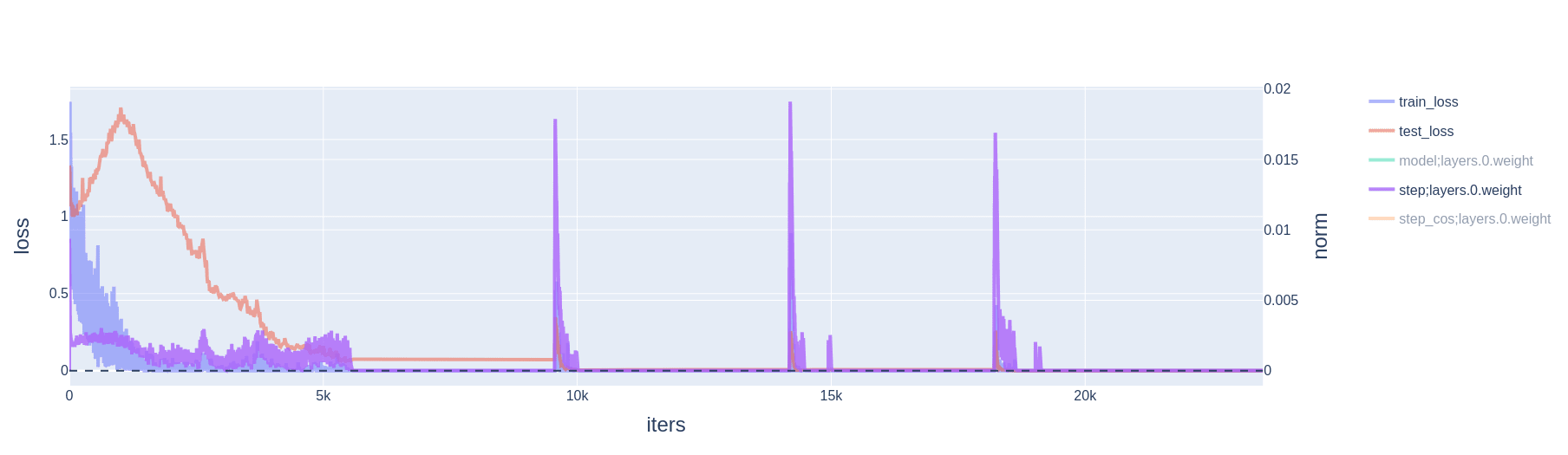
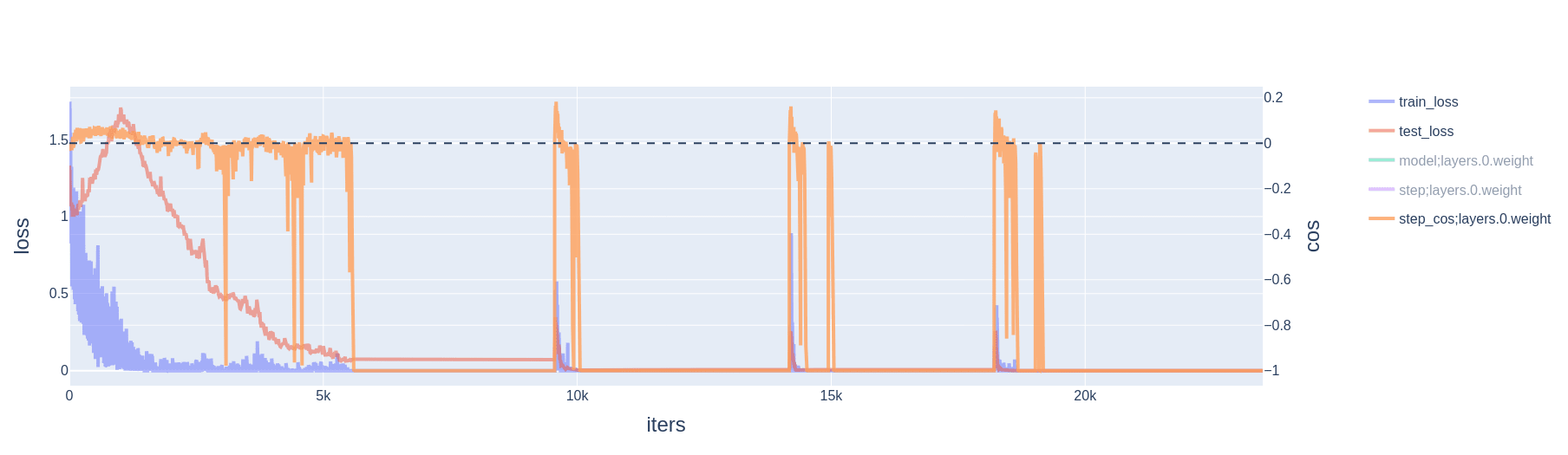
2.2 Cross-entropy loss
When using cross-entropy loss, the training loss and its gradient are never zero. Rather, once the model has attained perfect train accuracy, the loss gradient and weight decay are competing forces: the model can always decrease cross-entropy loss by scaling up weights. Yet, slingshots still do occur, and still appear alongside 1) spikes in gradient, momentum, and variance; and 2) large optimizer steps taken in the direction of increasing weight norm.
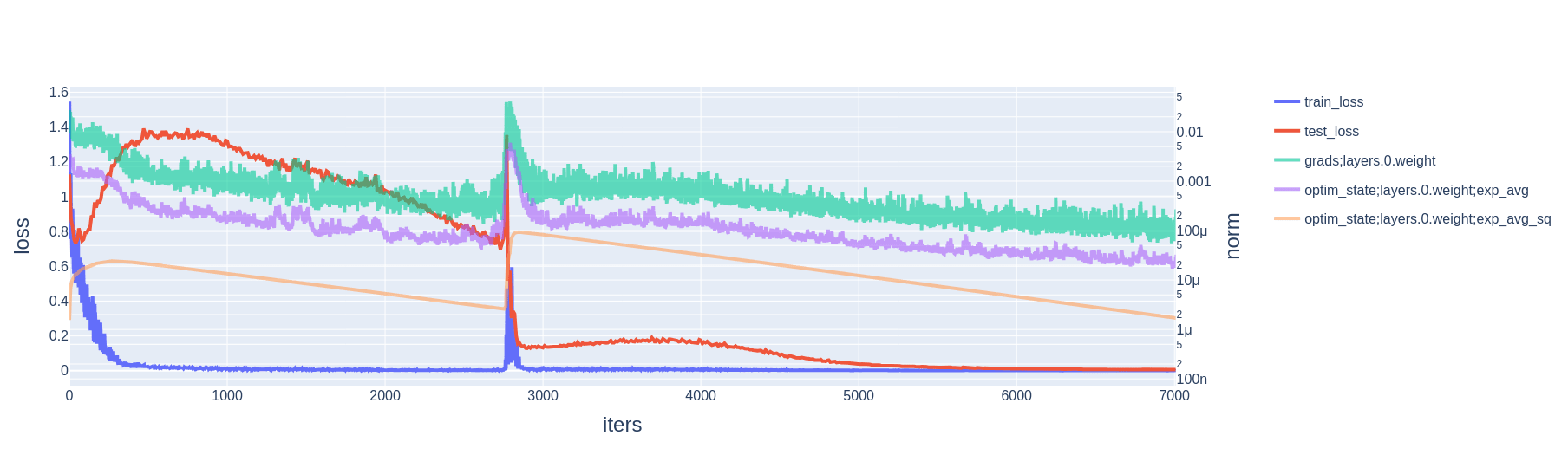
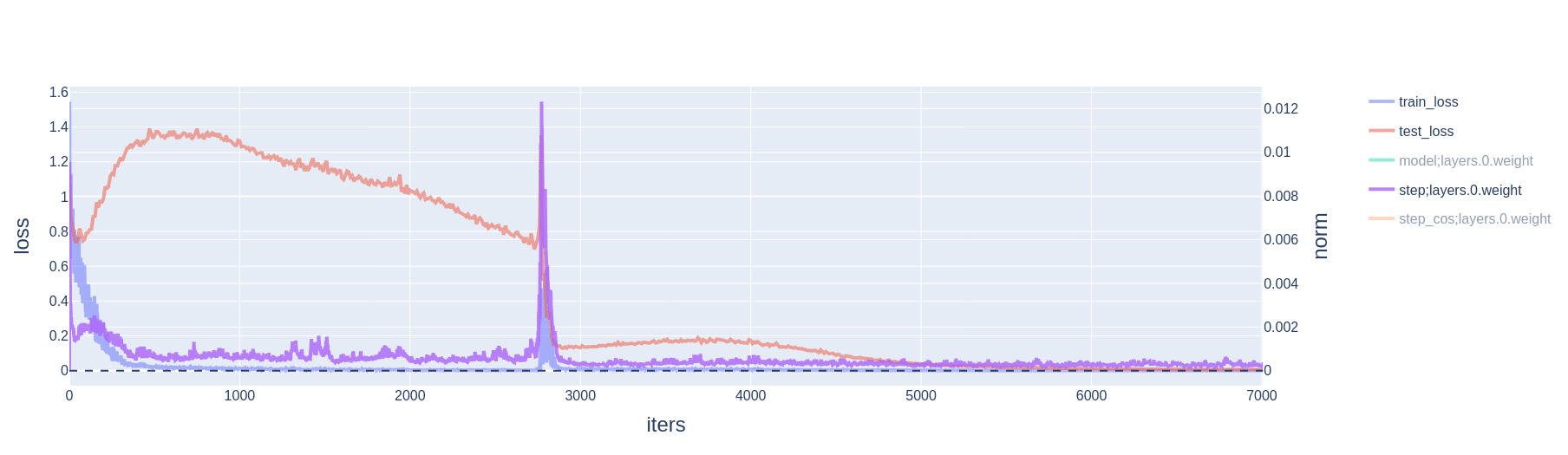
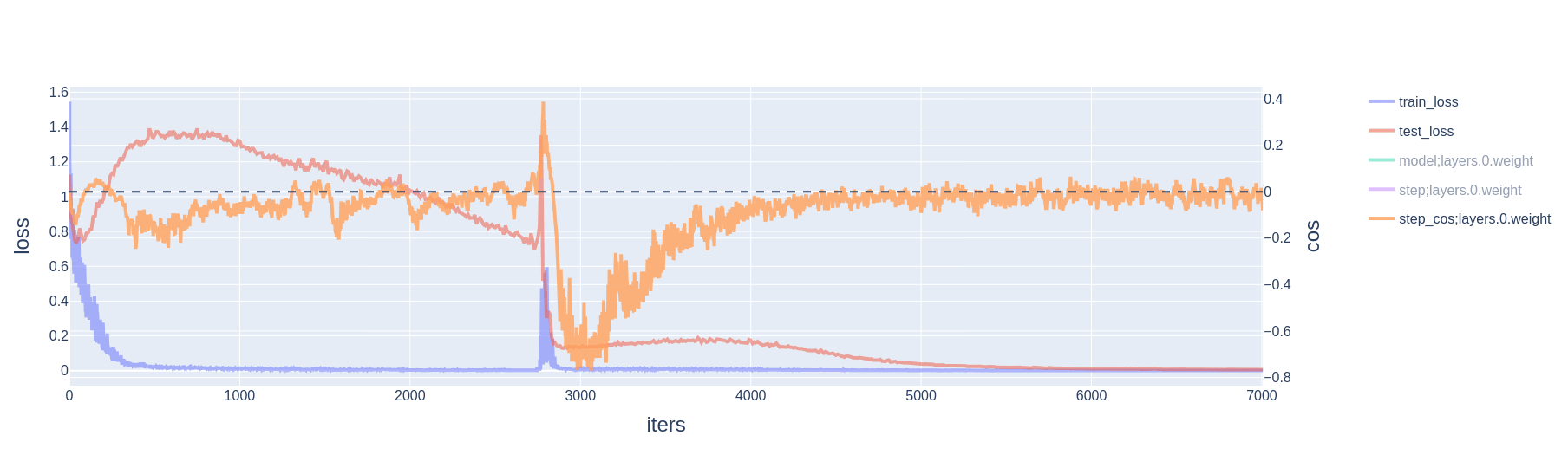
2.3 Resetting AdamW mitigates slingshots
The explanation given in Steps 4 and 5 of Sec. 2.1 rely on the number of iterations being large and thus the normalizations of the momentum and variance by and being negligible. Thus, if we were to reset AdamW's state right before a slingshot, we should expect to find the instability substantially mitigated. This is indeed what we find, although the spikes in train and test loss do not entirely disappear (Fig 10). A reset in AdamW's internal state is itself a discontinuity in the training process, which may explain why the loss curves are not entirely smoothed out. Note also that this iteration count resetting trick only temporarily prevents the slingshot, so it needs to applied several times over the course of a training run.
3 Slingshots and generalization
3.1 Slingshots tend to decrease test loss
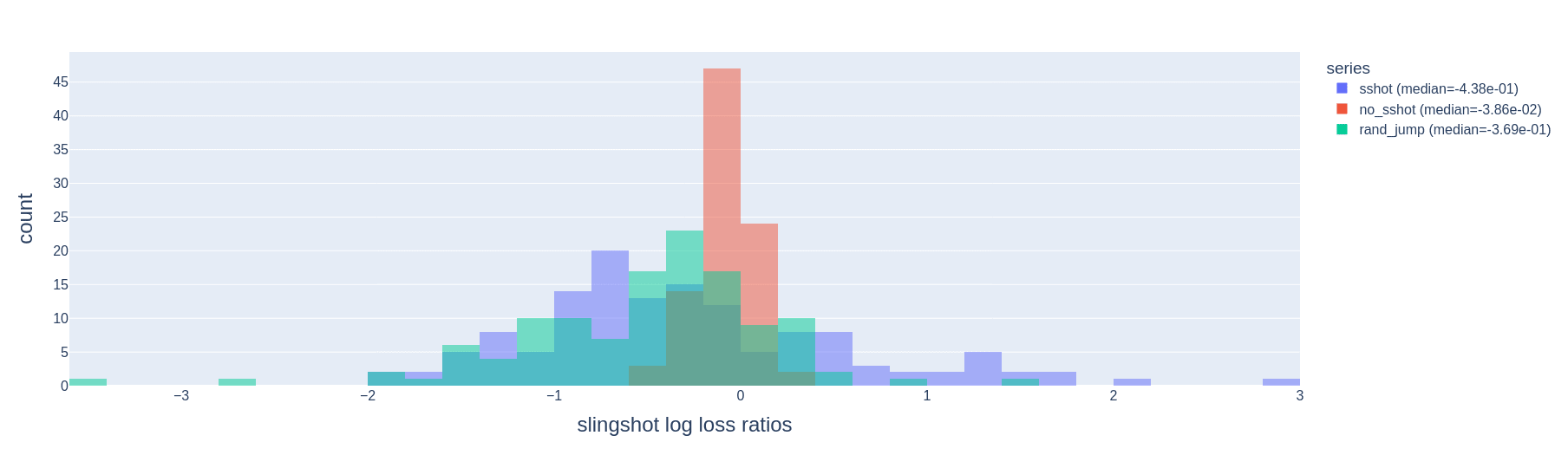
We run 100 training runs of models trained on the -sparse parity task with cross-entropy loss, and automatically detect slingshots. We look at the difference in test loss before and after each slingshot, and compare these to the difference in test loss before and after intervals of the same length without slingshots. We find that slingshots tend to reduce test loss more than training for the same amount of time without slingshots (Fig. 11).
3.2 Slingshots vs random jumps
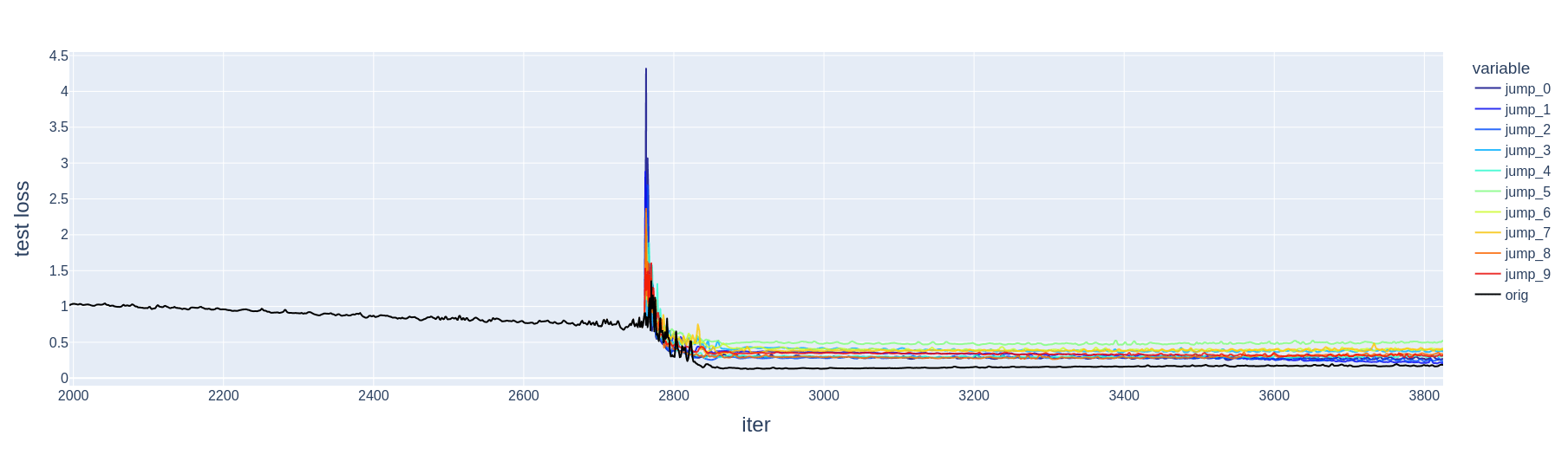
Why do slingshots help with generalization? One possible story is that they are simply a mechanism for jumping out of poorly-generalizing local minima in the training loss landscape. One might then further suppose that a jump in any arbitrary direction results in the same benefits. We test this directly by starting at points in training right before a slingshot and sampling jumps in random directions with the same magnitude as the slingshot. We find preliminary[5] evidence that, contrary to this supposition, the original slingshot tends to reduce test loss more than a random jump does (Fig. 11, 12).
Currently, we do not have a good explanation for why slingshots induce better generalization than random jumps. One possibility is that an artificially introduced random jump does not update AdamW's internal state in the same way as a slingshot does, thus attenuating the affect described in Sec. 2.1.5. It should also be noted that our method for detecting slingshots, and thus the size and starting point of the random jump, is somewhat unprincipled[6]; possibly, a more "correct" jump size and starting point would weaken or eliminate the difference between slingshots and random jumps we observe here.
3.3 Slingshots and LLC
The local learning coefficient (LLC) of a point in a model's parameter space is a measure of model complexity in a neighborhood around that point. That the LLC varies with the model parameters is a crucial difference from the classical statistical picture, in which the effective dimensionality is constant across all parameters. (For example, consider linear regression—the dimensionality of the model is equal to the number of weight parameters, regardless of the setting of the weights.) At least in the Bayesian setting, the LLC is closely related to generalization properties of the model. See the Distilling SLT [? · GW] sequence for more details.
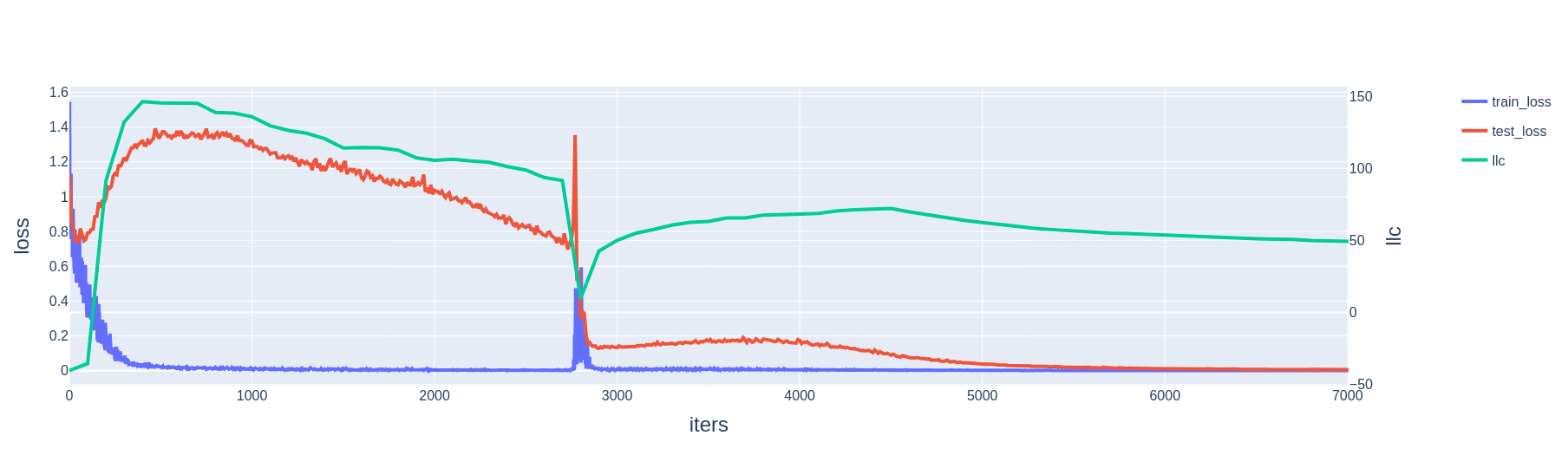
We estimate the LLC for models trained on cross-entropy loss[7] and find that it tends to decrease after a slingshot (Fig. 13). Intuitively, we can interpret this observation as the slingshot moving the model from a more complex memorizing solution to a simpler generalizing solution.
4 Discussion
The scope of this post is fairly limited: we only discuss a very simple model (one-hidden-layer MLP) trained on a synthetic algorithmic task. The explanation of the slingshot effect given in Sec. 2.1 holds in its entirety only for models trained with hinge loss (or, possibly, for other setups with open regions in parameter space with vanishing gradient). It is unclear how well this explanation carries over to the wide range of settings investigated by Thilak et al. 2024. In particular, there are several slingshot regimes in their paper that 1) do not fit our explanation and 2) we are unable to empirically replicate:
- When using Adam instead of AdamW, and/or when weight decay is set to zero. In this case, for the momentum and variance estimates to decay to zero, it seems necessary for model parameters to be near-stationary. It is then intuitively unlikely that parameters could then re-enter a high-gradient region, triggering a slingshot.
- Extremely rapid decay factors up to and including (Fig. 21 in Thilak et al.). In this case, there is effectively no momentum, and the parameter update is approximately equal to the sign of the gradient.
Perhaps there are multiple possible sources of instability in late stages of training with adaptive optimizers, all of which manifest in the training loss curve as a "slingshot-like" effect. If so, the topic of this post is then only a single member in this family of instabilities.
Despite these caveats, we do find evidence in this toy setting that, during slingshots, the model tends to jump to better-generalizing solutions. The current lack of understanding of this phenomenon indicates that there is still much work to do connecting generalization and the inductive biases of adaptive optimizer methods.
Code for running the experiments in this post can be found in this notebook.
Acknowledgements: This work was completed during MATS 6.0. Many thanks to @Jesse Hoogland [LW · GW] for mentorship and @DanielFilan [LW · GW] for research management, as well as to @LawrenceC [LW · GW] and @jacob_drori [LW · GW] for feedback on drafts of this post. I am supported by a grant from the Long-Term Future Fund.
- ^
Even though samples are information-theoretically sufficient to distinguish the -sparse parity function, constant-noise queries are necessary to learn the function in the statistical query model, which encapsulates gradient-based methods.
- ^
We can ignore the rescaling by and , respectively, because late in training both and are approximately zero. We also ignore the influence of the term in the denominator of the parameter update.
- ^
If and were set to more comparable values, this factor would disappear. However, the explanation in Step 5 still goes through. We still observe slingshots when setting , in which case . Anecdotally, slingshots in this regime appear to be smaller but more frequent (as variance decays to zero more rapidly).
- ^
This effect depends on adjacent gradients being correlated—if they were independent, then both the numerator and the denominator of the parameter updates would scale as the square root of the number of steps immediately following a slingshot. (The standard deviation of the sum of independent Gaussians scales as ). Empirically, we find that cosine similarities between gradients of adjacent steps are on average positive throughout training, not just during slingshots. In the case of cross-entropy loss, correlated gradients can be explained by the negative loss gradient pointing outwards once the training data has been fit perfectly. (Scaling up the model decreases loss.)
- ^
The difference in log test loss ratio between slingshot intervals and non-slingshot intervals is statistically significant (p<0.05, Mood's median test), but the difference between slingshots and random jumps is not (p>0.05).
- ^
We made the arbitrary choice of defining a slingshot interval as 1) starting when the training loss, after previously decreasing below , exceeds and 2) ending when the training loss returns to below . We did not check whether our results are robust to other methods of detecting spikes in training loss.
- ^
It would not make sense to estimate the LLC for models trained on hinge loss, because the model parameters quickly reach flat basins of zero training loss. If the training loss landscape is flat in a neighborhood of a point then the LLC at that point is zero.
0 comments
Comments sorted by top scores.