Inverse scaling can become U-shaped
post by Edouard Harris · 2022-11-08T19:04:54.536Z · LW · GW · 15 commentsThis is a link post for https://arxiv.org/abs/2211.02011
Contents
The abstract in full: None 16 comments
Edit: Here's a great comment by Ethan Perez [? · GW] that caveats this result, that I'd recommend reading for context.
This is a paper by folks at Quoc Le's team at Google that examines the winning tasks from Round 1 of Anthropic's Inverse Scaling Prize [AF · GW]. They find that 3/4 of the winning tasks — which exhibited negative returns-to-scale when tested on LMs up to the scale of Gopher (280B) — go back to exhibiting positive returns-to-scale at even greater model sizes such as PaLM (540B).
The abstract in full:
Although scaling language models improves performance on a range of tasks, there are apparently some scenarios where scaling hurts performance. For instance, the Inverse Scaling Prize Round 1 identified four ''inverse scaling'' tasks, for which performance gets worse for larger models. These tasks were evaluated on models of up to 280B parameters, trained up to 500 zettaFLOPs of compute.
This paper takes a closer look at these four tasks. We evaluate models of up to 540B parameters, trained on five times more compute than those evaluated in the Inverse Scaling Prize. With this increased range of model sizes and training compute, three out of the four tasks exhibit what we call ''U-shaped scaling'' -- performance decreases up to a certain model size, and then increases again up to the largest model evaluated. One hypothesis is that U-shaped scaling occurs when a task comprises a ''true task'' and a ''distractor task''. Medium-size models can do the distractor task, which hurts performance, while only large-enough models can ignore the distractor task and do the true task. The existence of U-shaped scaling implies that inverse scaling may not hold for larger models.
Second, we evaluate the inverse scaling tasks using chain-of-thought (CoT) prompting, in addition to basic prompting without CoT. With CoT prompting, all four tasks show either U-shaped scaling or positive scaling, achieving perfect solve rates on two tasks and several sub-tasks. This suggests that the term "inverse scaling task" is under-specified -- a given task may be inverse scaling for one prompt but positive or U-shaped scaling for a different prompt.
Key figure from the paper is below, showing results for LMs up to PaLM 540B. Note that positive scaling resumes for 3/4 of the inverse scaling tasks at the 2.5e24 FLOPs datapoint, which indeed corresponds exactly to vanilla PaLM 540B.[1]
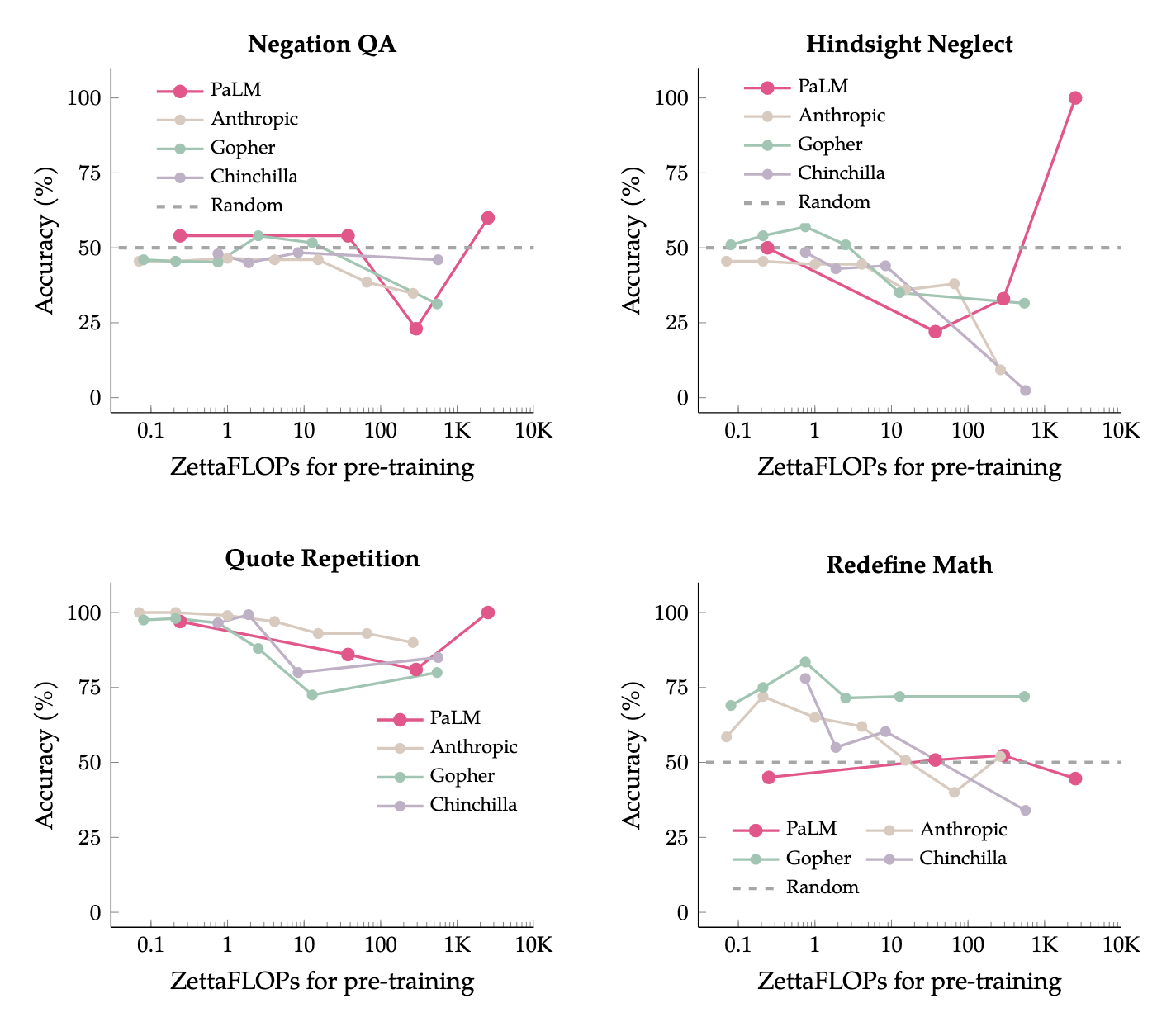
- ^
From Table 22 in the PaLM paper.
15 comments
Comments sorted by top scores.
comment by Ethan Perez (ethan-perez) · 2022-11-09T00:35:49.800Z · LW(p) · GW(p)
Edit: The authors have updated the paper based on my feedback; see my thoughts on the updated version in this comment [LW(p) · GW(p)]
The authors modified some of the tasks enough that they aren't actually the tasks we found inverse scaling on. For example, they evaluate on the 1-shot instead of 0-shot versions of some tasks, and giving an example of how to do the task is probably a huge hint. In another case, they reduce the number of few-shot examples used, when spurious correlations in the few-shot examples are the reason for the inverse scaling. So some of the comparisons to existing models aren't valid, and I don't think the current results are strong evidence that scaling further reverses the inverse scaling trends that we found.
Relevant discussion of the task changes they made here:
- https://twitter.com/EthanJPerez/status/1588352204540235776
- https://twitter.com/_jasonwei/status/1588605921814777856
↑ comment by Edouard Harris · 2022-11-09T16:34:17.585Z · LW(p) · GW(p)
Excellent context here, thank you. I hadn't been aware of this caveat.
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2022-11-11T16:38:24.333Z · LW(p) · GW(p)
I'd recommend editing a link to Ethan's comment to the top of the post - I think people could easily lead with a misleading impression otherwise
Replies from: Edouard Harris↑ comment by Edouard Harris · 2022-11-18T14:59:51.654Z · LW(p) · GW(p)
Done, a few days ago. Sorry thought I'd responded to this comment.
↑ comment by LawrenceC (LawChan) · 2022-11-09T01:49:06.847Z · LW(p) · GW(p)
Do you expect all of the inverse scaling trends (for the round 1 winners) to go on forever?
This seems incredibly implausible to me, given all of four examples are capabilities failures and not alignment failure, and all four examples are capabilities that most humans can demonstrate.
↑ comment by Ethan Perez (ethan-perez) · 2022-11-15T22:05:18.401Z · LW(p) · GW(p)
I'm not too sure what to expect, and I'd be pretty interested to e.g. set up a Metaculus/forecasting question to know what others think. I'm definitely sympathetic to your view to some extent.
Here's one case I see against- I think it's plausible that models will have the representations/ability/knowledge required to do some of these tasks, but that we're not reliably able to elicit that knowledge (at least without a large validation set, but we won't have access to that if we're having models do tasks people can't do, or in general for a new/zero-shot task). E.g., for NegationQA, surely even current models have some fairly good understanding of negation - why is that understanding not showing in the results here? My best guess is that NegationQA isn't capabilities bottlenecked but has to do with something else. I think the updated paper's results that chain-of-thought prompting alone reverses some of the inverse scaling trends is interesting; it also suggests that maybe naively using an LM isn't the right way to elicit a model's knowledge (but chain-of-thought prompting might be).
In general, I don't think it's always accurate to use a heuristic like "humans behave this way, so LMs-in-the-limit will behave this way." It seems plausible to me that LM representations will encode the knowledge for many/most/almost-all human capabilities, but I'm not sure it means models will have the same input-output behavior as humans (e.g., for reasons discussed in the simulators [AF · GW] post and since human/LM learning objectives are different)
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2022-11-16T03:55:51.225Z · LW(p) · GW(p)
I will happily bet that NeQA resolves with scale in the next 2 years, at something like 1:1 odds, and that in the worst case resolves with scale + normal finetuning (instruction finetuning or RLHF) within the next two years at something like 4:1 odds (without CoT)! (It seems like all of them are U-shaped or positive scaling with CoT already?)
I made a manifold market for the general question: if I'm not incorrect, the updated paper says that 2/4 of them already demonstrate u-shaped scaling, using the same eval as you did?
I'll make one for NeQA and Redefine Math later today.
I think it's plausible that models will have the representations/ability/knowledge required to do some of these tasks, but that we're not reliably able to elicit that knowledge (at least without a large validation set, but we won't have access to that if we're having models do tasks people can't do, or in general for a new/zero-shot task).
I agree that these tasks exist. If intent alignment fails and we end up with a misaligned AGI, then we in some sense can't get the AI to do any of the nice powerful things we'd like it to do. We'd like to see examples of this sort of failure before we make a powerful unaligned AGI, ideally in the scaling laws paradigm.
Broadly speaking, there are three types of inverse scaling curves: 1) those that resolve with scale, ie capabilities tasks, 2) those that are in some sense "tricking" the model with a misleading prompt where human labelers use additional context clues to not be tricked (for example, that they're labelling an ML dataset, and so they should probably answer as literally as possible, or 3) alignment failures (very hard to elicit). 1) resolves with scale, 2) can be easily fixed with tweaks to the prompt or small amounts of instruction finetuning/RLHF, and I think we agree that 3) is the interesting kind.
My claim is that all four of these tasks are clearly not alignment failures, and I also suspect that they're all of type 1).
In general, I don't think it's always accurate to use a heuristic like "humans behave this way, so LMs-in-the-limit will behave this way." It seems plausible to me that LM representations will encode the knowledge for many/most/almost-all human capabilities, but I'm not sure it means models will have the same input-output behavior as humans (e.g., for reasons discussed in the simulators [AF · GW] post and since human/LM learning objectives are different)
That's super fair. I think I'm using a more precise heuristic than this in practice, something like, "if you're not 'tricking' the model in some sense, things that untrained humans can do in the first go can be done by models", though this still might fail in the limit for galaxy-brain reasons.
(EDIT: made a manifold market for round 2 inverse scaling tasks as well)
comment by Ethan Perez (ethan-perez) · 2022-11-15T21:39:59.900Z · LW(p) · GW(p)
The authors have updated their arXiv paper based on my feedback, and I'm happy with the evaluation setup now: https://arxiv.org/abs/2211.02011v2. They're showing that scaling PALM gives u-shaped scaling on 2/4 tasks (rather than 3/4 in the earlier version) and inverse scaling on 2/4 tasks. I personally found this result at least somewhat surprising, given the fairly consistent inverse scaling we found across various model series' we tried. They're also finding that inverse scaling on these tasks goes away with chain-of-thought prompting, which I think is a neat finding (and nice to see some success from visible-thoughts-style methods here). After this paper, I'm pretty interested to know:
- what PALM scaling laws look like for Round 2 inverse scaling tasks
- if inverse scaling continues on the other 2 tasks Round 1 tasks
- if there are tasks where even chain-of-thought leads to inverse scaling
↑ comment by gwern · 2022-11-15T23:34:59.754Z · LW(p) · GW(p)
They're also finding that inverse scaling on these tasks goes away with chain-of-thought prompting
So, like some of the Big-Bench PaLM results, these are more cases of 'hidden scaling' where quite simple inner-monologue approaches can show smooth scaling while the naive pre-existing benchmark claims that there are no gains with scale?
Replies from: ethan-perez↑ comment by Ethan Perez (ethan-perez) · 2022-11-16T03:55:03.316Z · LW(p) · GW(p)
Yup
comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2022-11-09T02:59:15.787Z · LW(p) · GW(p)
Please note that the inverse scaling prize is not from Anthropic:
The Inverse Scaling Prize is organized by a group of researchers on behalf of the Fund for Alignment Research (FAR), including Ian McKenzie, Alexander Lyzhov, Alicia Parrish, Ameya Prabhu, Aaron Mueller, Najoung Kim, Sam Bowman, and Ethan Perez. Additionally, Sam Bowman and Ethan Perez are affiliated with Anthropic; Alexander Lyzhov, Alicia Parrish, Ameya Prabhu, Aaron Mueller, Najoung Kim, Sam Bowman are affiliated with New York University. The prize pool is provided by the Future Fund.
Anthropic has provided some models as a validation set, but it's not even the most common affiliation!
comment by Neel Nanda (neel-nanda-1) · 2022-11-08T19:38:16.913Z · LW(p) · GW(p)
Really interesting, thanks for sharing!
I find it super surprising that the tasks worked up until Gopher, but stopped working at PaLM. That's such a narrow gap! That alone suggests some kind of interesting meta-level point re inverse scaling being rare, and that in fact the prize mostly picked up on the adverse selection of "the tasks that were inverse-y enough to not have issues on the models used.
One prediction this hypothesis makes is that people were overfitting to "what can GPT-3 not do" and thus that there's a bunch of submitted tasks that were U-Shaped by Gopher, and the winning ones were just the ones that were U Shaped a bit beyond Gopher?
I'm also v curious how well these work on Chinchilla.
Replies from: ethan-perez↑ comment by Ethan Perez (ethan-perez) · 2022-11-09T00:39:29.931Z · LW(p) · GW(p)
See this disclaimer [AF · GW] on how they've modified our tasks (they're finding u-shaped trends on a couple tasks that are different from the ones we found inverse scaling on, and they made some modifications that make the tasks easier)
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2022-11-09T13:35:21.416Z · LW(p) · GW(p)
Oh that's sketchy af lol. Thanks!
Replies from: ytay017