SAE Probing: What is it good for?
post by Subhash Kantamneni (subhashk), Josh Engels (JoshEngels), Senthooran Rajamanoharan (SenR), Neel Nanda (neel-nanda-1) · 2024-11-01T19:23:55.418Z · LW · GW · 0 commentsContents
Update February 2025: TLDR Motivation and Problem Setting Data Efficiency Label Corruption Out of Distribution (OOD) Data and Class Imbalance Interpretability Understanding SAE features better Understanding datasets better ChatGPT-3.5 vs Human text (Identifying spurious correlations) GLUE CoLA (Correcting an established dataset!) Conclusions None No comments
Subhash and Josh are co-first authors. Work done as part of the two week research sprint in Neel Nanda’s MATS stream
Update February 2025:
We have recently expanded this post into a full paper: https://arxiv.org/abs/2502.16681
Our results are now substantially more negative. We find that SAE probes do not consistently beat baselines on test AUC and are not a useful addition to a practitioner's toolkit. We also found that baseline logistic regression probes worked as well even on the interpretability case studies that we were initially most excited about. We also tried multi-token probing and found that although SAE probes improved with max or mean aggregation, an attention-based logistic regression probe removed most of the advantage.
*The old title of this post was: SAE Probing: What is it good for? Absolutely something!
TLDR
- We show that dense probes trained on SAE encodings are competitive with traditional activation probing over 60 diverse binary classification datasets
- Specifically, we find that SAE probes have advantages with:
- Low data regimes (~ < 100 training examples)
- Corrupted data (i.e. our training set has some incorrect labels, while our test set is clean)
- Settings where we worry about the generalization of our probes due to spurious correlations in our dataset or possible mislabels (dataset interpretability) or if we want to understand SAE features better (SAE interpretability).
- We find null results when comparing SAE probes to activation probes with OOD data in other settings or with imbalanced classes.
- We find that higher width and L0 are determining factors for which SAEs are best for SAE probing.
Motivation and Problem Setting
Sparse autoencoders (SAEs) have quickly become the hot topic in mechanistic interpretability research, but do they have any actual use cases? We argue probing might be one! The intuition is that if SAEs are doing what we want them to and finding meaningful model variables, we should be able to use them as a strong inductive bias for training good linear probes. Anthropic recently released an update exploring a similar idea, but only explored variations on one dataset in a single setting. We collected over 60 binary classification datasets (described here). These datasets include sentiment classification, linguistic acceptability, differentiating ChatGPT and human written text, identifying attributes like gender, nationality, and occupation of historical figures, spam classification, hate speech identification, and truthfulness.
Naively, as SAEs just learn a linear decomposition of model activations, a standard linear probe should always be at least as good for learning the training data distribution. But in the real world we rarely evaluate probes exactly in distribution, so to evaluate the viability of SAE probing we investigate a range of more realistic settings where we thought the inductive bias of being sparse and interpretable might help: data scarcity, label corruption, OOD generalization, class imbalance, and dataset interpretability. We run all experiments on layer 20 of Gemma 2 9B base.
Data Efficiency
There are many settings where data can be difficult to collect (user data, medical records, etc.). We expect SAE probes to have some advantages here, because there are an order of magnitude fewer active latents for a given token than dimensions in the residual stream, so it should be easier to find the “correct” combination of latents with limited data.
Summary plot (see below for full details): We do find SAE probes have some advantages in data scarce settings: across datasets and training sizes, SAE probes outperform baselines 27% of the time, and in data scarce settings (<34 datapoints), our advantage increases to 35%! This provides preliminary evidence that SAE probes can be competitive with baselines, although the majority of the time SAE probes get beat by baselines (red), often tie (white), and sometimes win (blue). We attribute this to activation probes being a very competitive baseline; SAE probes should be seen as an additional tool in the kit rather than a replacement.
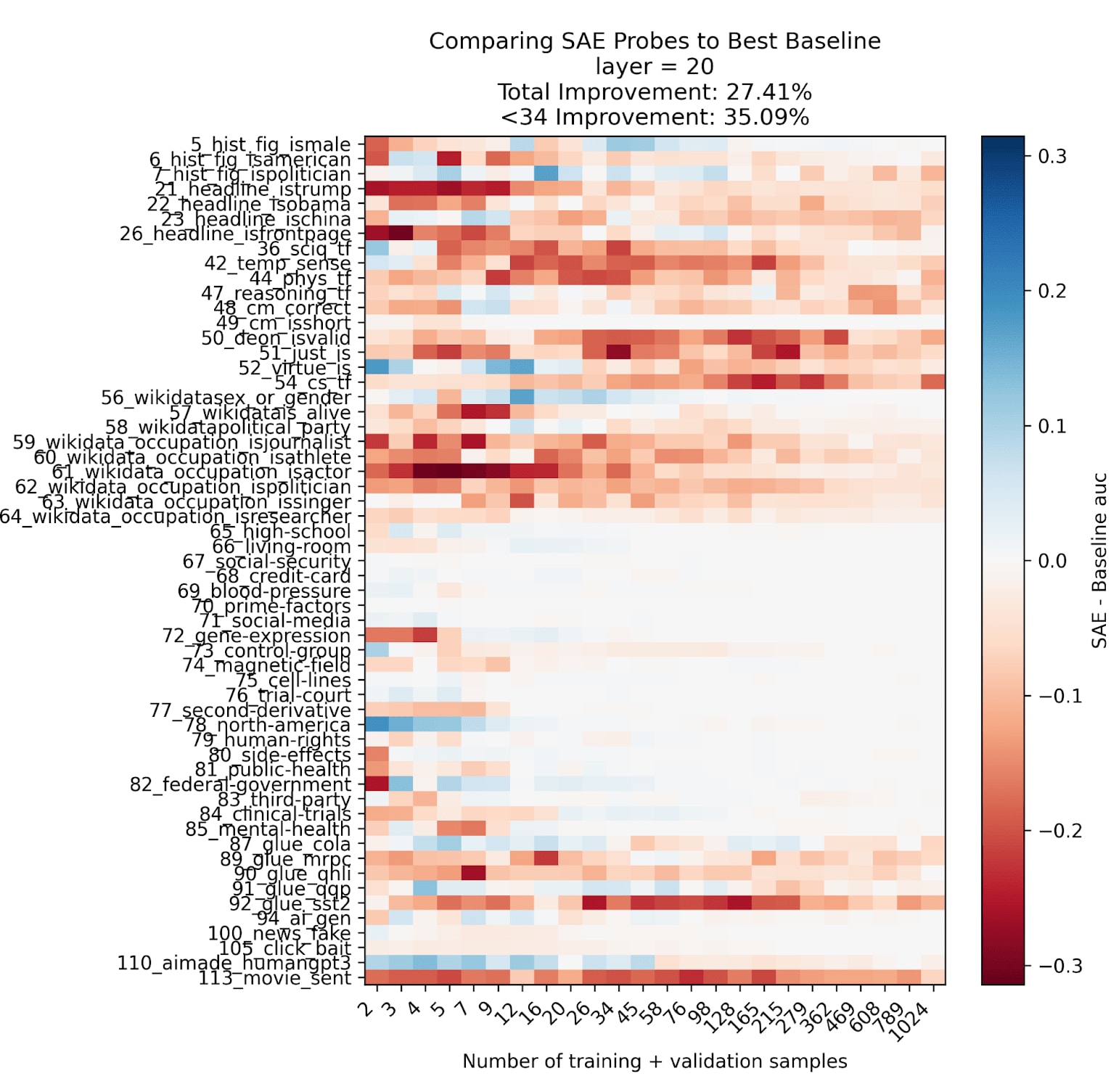
Method details: we train baseline and SAE probes on a logspaced number of examples from 2 to 1024 with balanced classes. To mimic actual data scarce settings, we do hyperparameter selection using only the data at hand (using cross validation[1] and choosing hyperparameters with the highest validation AUC), and test on an independent set of 300 examples. Our metric of choice throughout this study is ROC AUC[2].
The baseline methods and hyperparameters we consider are
- Logistic Regression - Grid search over L2 regularization strength, [1e-5, 1e5]
- PCA Logistic Regression - Grid search over n_components ranging from [1,100]
- KNN - Grid search over k from [1,100]
XGBoost - Random search over a variety of parameters[3]
- MLP - Random search over width, depth, and weight decay. Uses ReLU and Adam.
We choose the best of these five methods using AUC on the hidden test set (so we “cheat” to make our baselines stronger), but the majority of the time simple logistic regression wins out[4].
We also investigate SAEs of a range of widths and L0s and find that in general, the widest SAE wins out: width = 1M, L0 = 193. We attribute this to that SAE combining the highest quality latents with lower reconstruction error, although it’s a little surprising because for relatively simple concepts, we expect feature splitting to make wide SAEs less performative than narrower ones. Here, we plot the percentage of datasets and training sizes where each SAE width/L0 outperforms baselines on test AUC, and we clearly see that 1M L0 193 dominates.
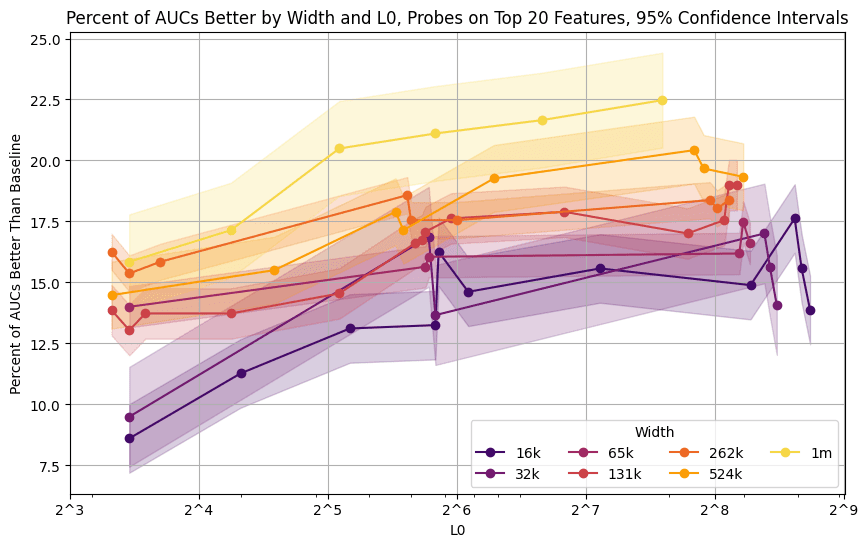
We take the 1M L0 = 193 as our SAE for all probing experiments. We isolate the top 100 latents by mean difference between classes on the training data, and use L2 regularization on the resulting basis with the same validation strategy as logistic regression on activations. Below, in blue we see the 1M L0 = 193 SAE, and in black the best baseline plotted across a few datasets. The light colors show all other SAE probes.
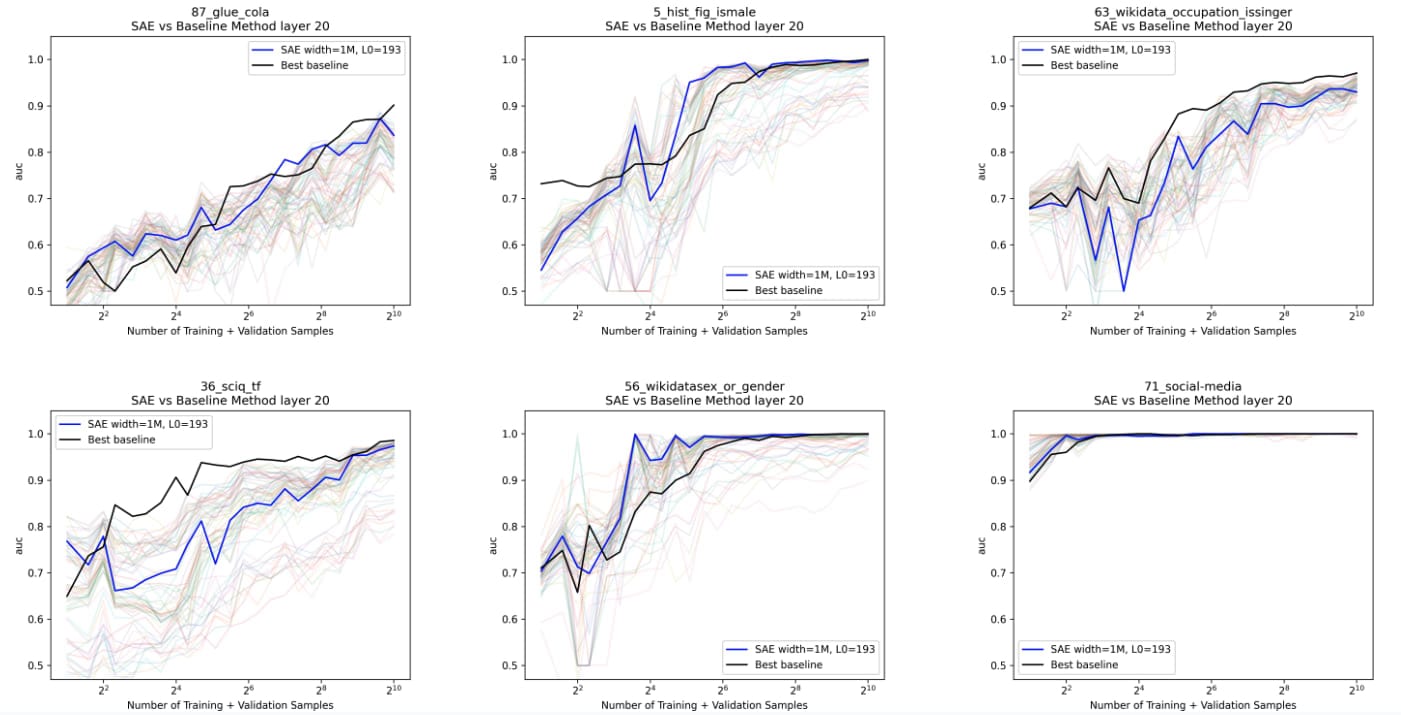
In general, we find that our advantage is greatest at small training sizes. Both the percentage of datasets SAE probes win on, and the average amount they win by on those datasets, are largest at small training fractions. We informally use the word “win” to mean the SAE outperforms the baseline.
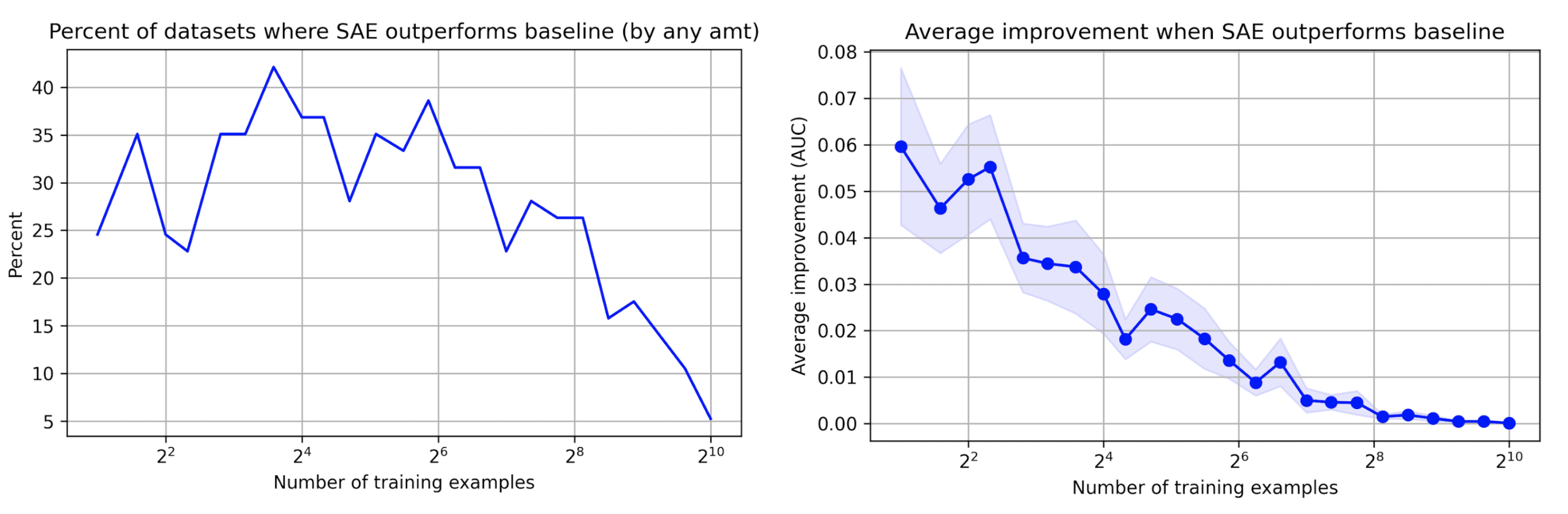
An important caveat is that the average difference between SAE probes and baselines is also greatest at small training examples. So, when we “win,” we win by the most, but when we “lose,” we also lose by the most at small training sizes. Succinctly: SAE probes have the greatest advantage at small training sizes, but also the most variance.
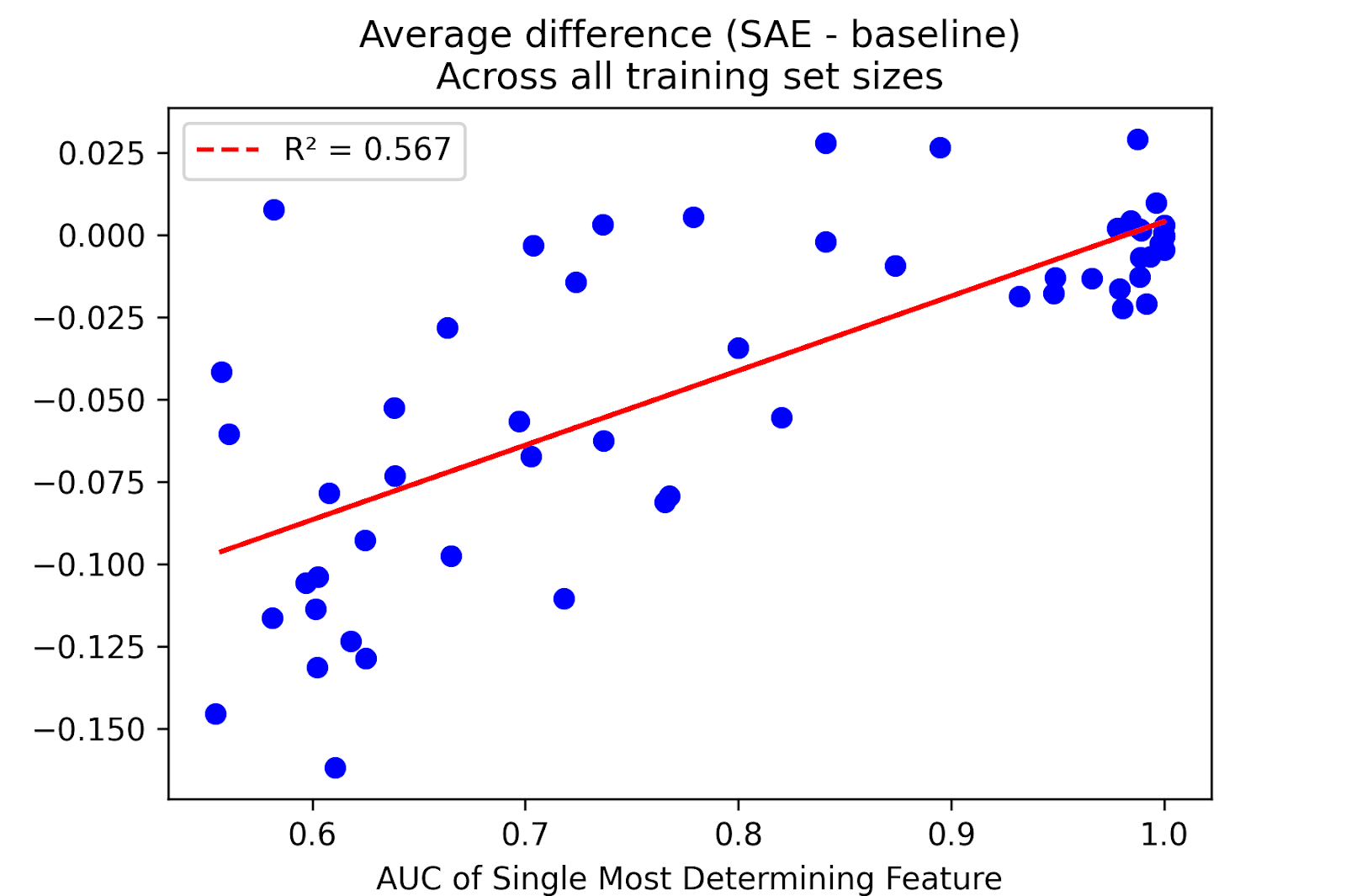
Why don’t SAE probes outperform baselines more consistently? At the end of the day, SAEs throw out information from the residual stream when finding a ~100 dimensional way to represent a ~3500 dimensional space. The additional inductive bias from SAE latents being meaningful can be outweighed by the loss of information, especially if there is not an SAE latent dedicated to the task at hand. For example, we find that a soft predictor of the difference between SAEs and baseline performances across training sizes is if there is a single latent that can do the task. Each blue dot here is a different dataset.
Label Corruption
We now fix the number of training examples to 1024 and see what happens when some percentage of the labels are corrupted (e.g. X% corruption means X% of the 1024 training labels are flipped). Are SAE probes more robust when training on corrupted data and testing on clean data? Yes!
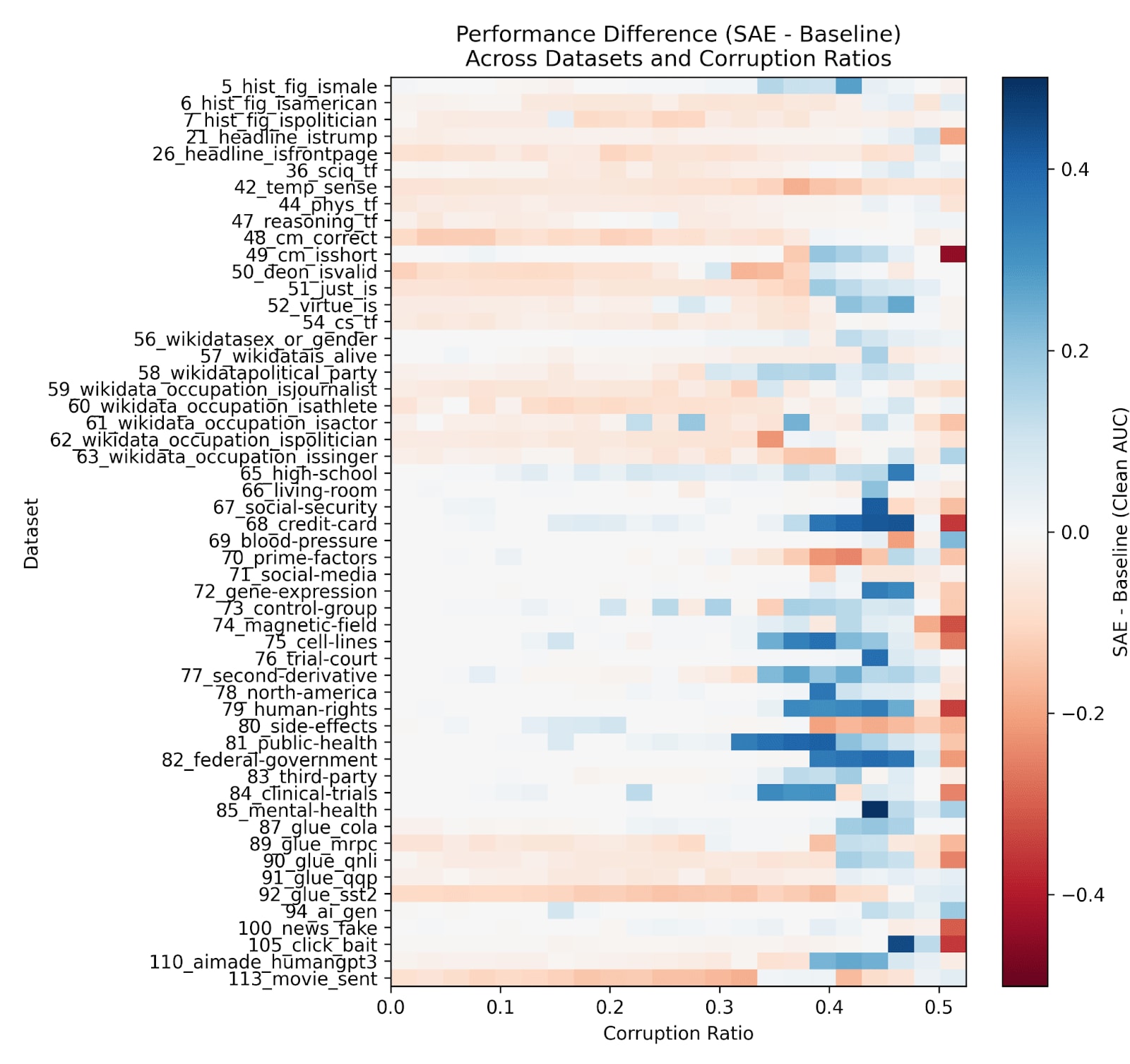
We have the greatest advantage over baselines with high corruption ratios. Because of the consistent dominance of logistic regression in data efficiency, we use that as our baseline in these experiments. Notably, the bluest parts of the graph occur on the same type of task: [65, 85] are tasks which identify if a certain phrase is in the text. Still, our advantage is significant on other datasets as well, and greater than in the data efficient setting.
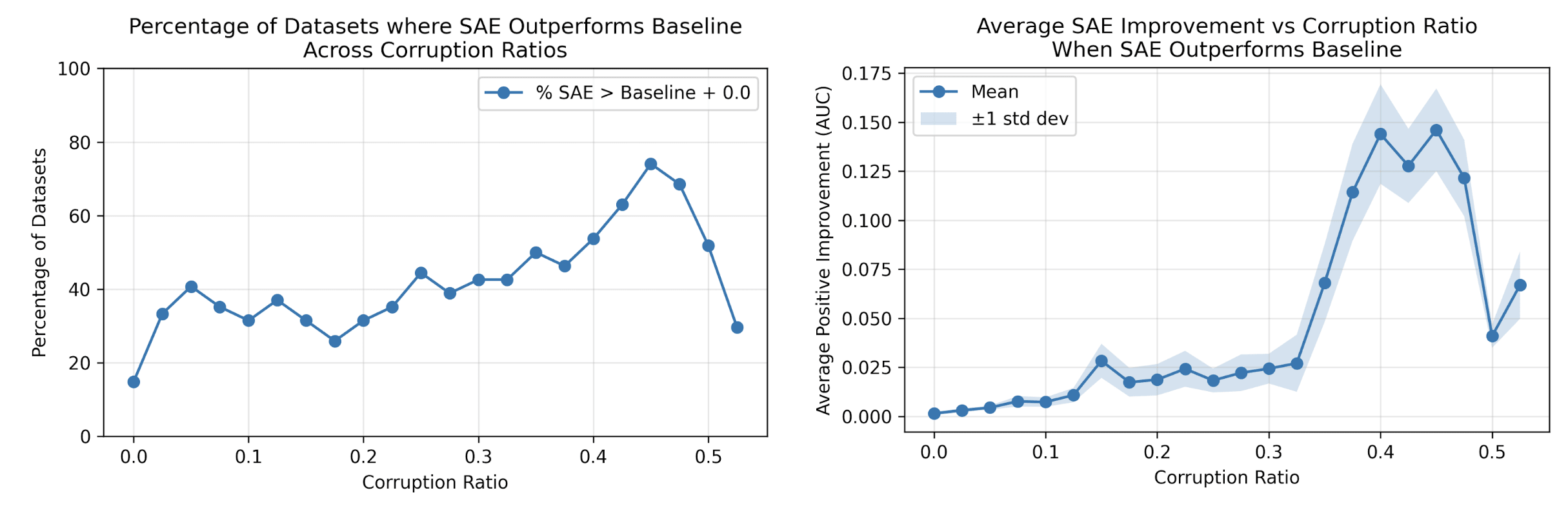
We can “win” on upwards of 40% of datasets at a corruption ratio of 0.3, and that number reaches >60% at higher corruption ratios, where we also begin to win by much larger margins. Importantly, we think this can represent realistic real world scenarios: when faced with a question like “which response do you like better” from ChatGPT, or “was this ad relevant” on YouTube, many people might choose randomly, introducing a high fraction of label noise.
Here are comparisons between SAEs and baselines for a few datasets:
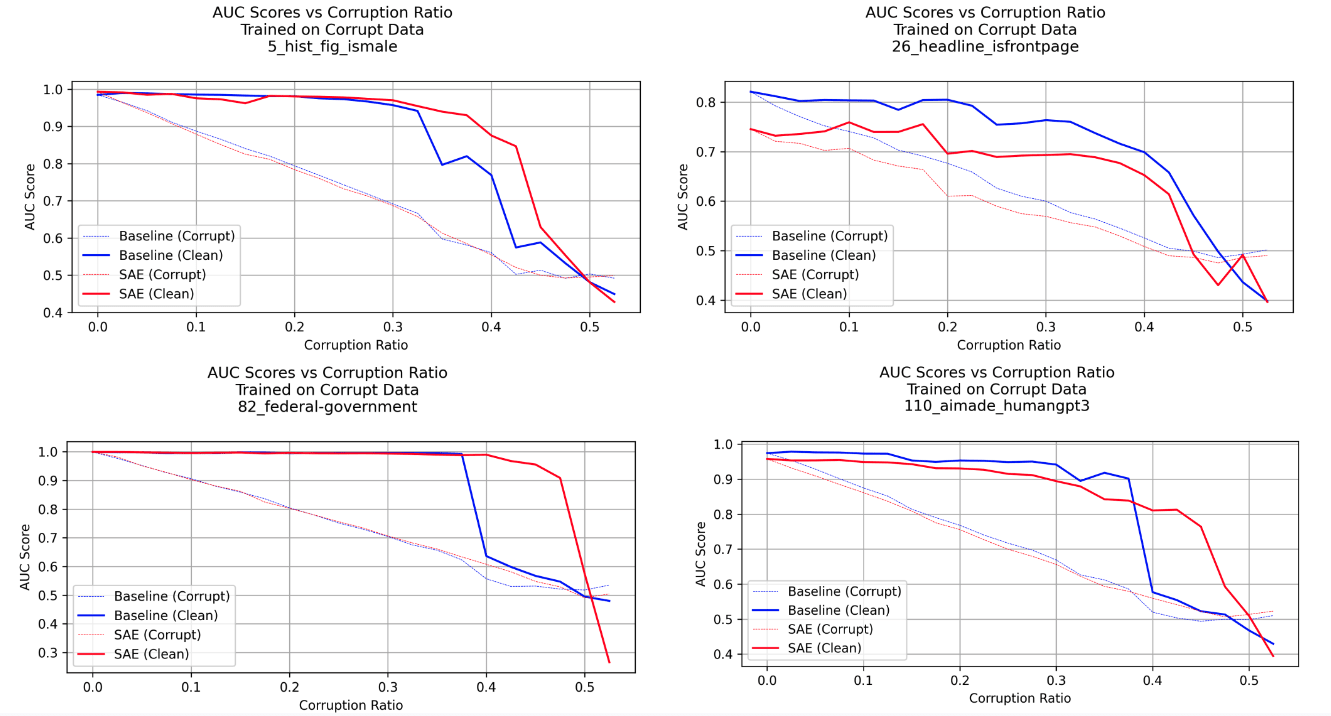
Each of these SAE (red) and baseline (blue) probes were trained on data with X% of the labels corrupted, and evaluated on a test set with X% corruption ratio (thin) and a clean test set (thick). Even as the corruption ratio increases, we see that both baselines and SAEs show robustness to learning the “true”, clean distribution (thick) over the corrupt distribution (thin), but baselines generally cliff off earlier than SAEs do.[5]
Why are SAEs more robust to label noise? We think that having a small, meaningful basis makes it harder for SAE probes to overfit with corrupt data. For example, if our task was identifying if a sentence is linguistically acceptable, and there is a feature for is_grammatical that contributes most to that task, even if some of the labels are corrupted it might be hard for the SAE to find other features to fit to the corrupted labels; it only knows the “true” grammatical feature.[6][7]
Out of Distribution (OOD) Data and Class Imbalance
Our preliminary findings are that SAEs do not have advantages in situations where the training data is of a different distribution than the testing data, or when we deal with class imbalance.
We sampled 8 datasets and devised a test set that was OOD for each. For example, for a task identifying the gender of a historical figure, our test set was the gender of fictional characters, and for the task identifying if a phrase is in the text, we converted the text to a different language to see if the same probe could generalize OOD. We trained the SAE probes and baselines on 1024 examples of in distribution data, and tested on 300 examples of the OOD test set.
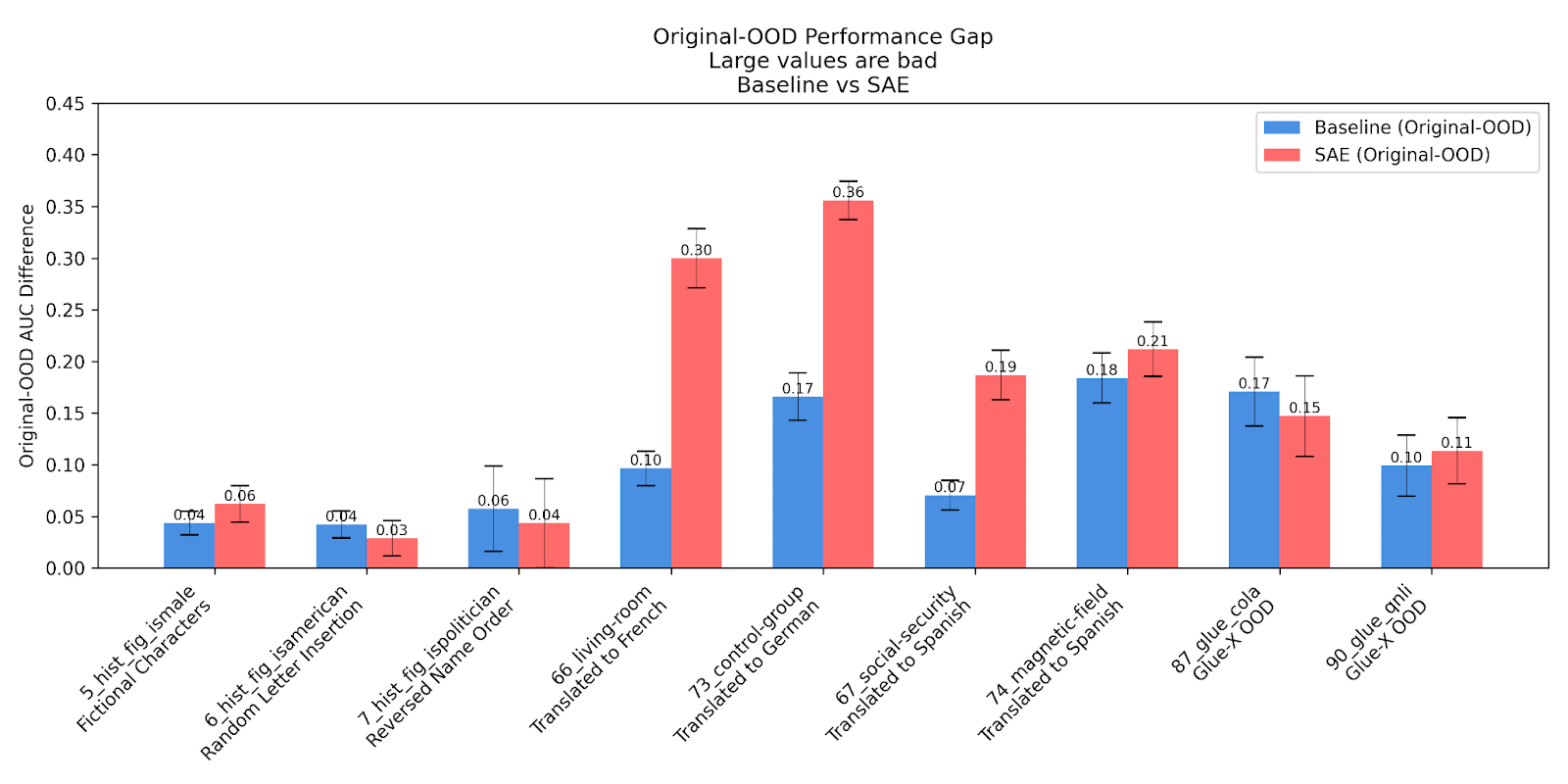
We find that for most tasks, the difference between the SAE probes and baselines was within the margin of error. The notable exception is language translation tasks, where we find that SAE probes get dominated by baselines. Upon further investigation, we find that this is because the Gemma SAEs were primarily trained on English data. For example, although there is a single feature that can determine if the phrase “control group” is in text with AUC = 1 (task ID 73), we find it doesn’t fire on the Spanish, German, or French (the languages we tested) translations of "control group".
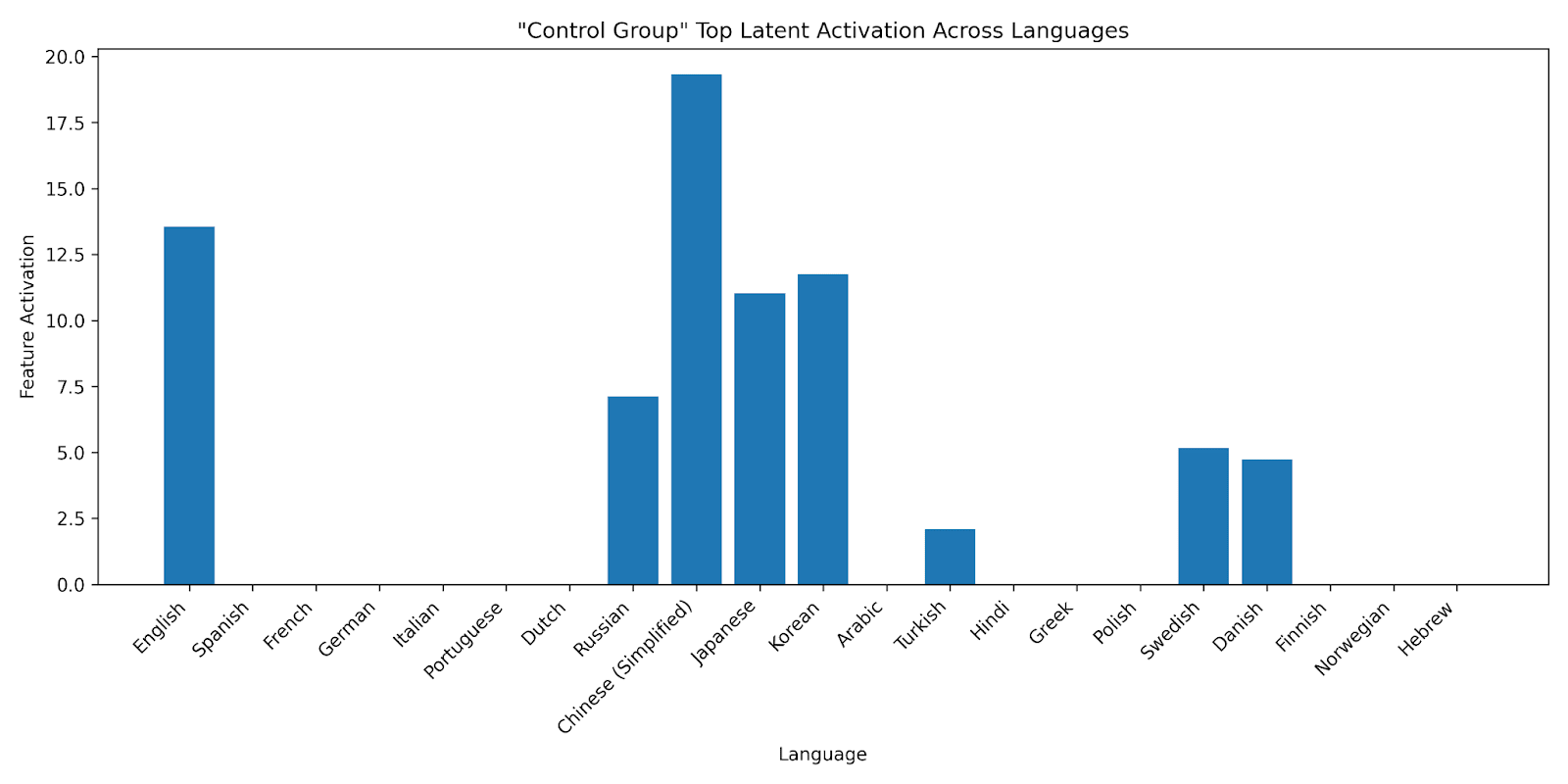
Thus, our preliminary findings with just a few datasets are that SAEs are competitive with baselines on some OOD tasks, but struggle significantly with multilingual tasks.
We shift focus to class imbalance, where we similarly find that SAEs don’t hold advantages over baselines, but remain competitive. We fix the number of training examples to 34 and alter the imbalance ratio from 0.05 to 0.95 in increments of 0.05. We use a small number of training examples because we expected SAEs to be able to learn the positive/negative classes with fewer examples of each.
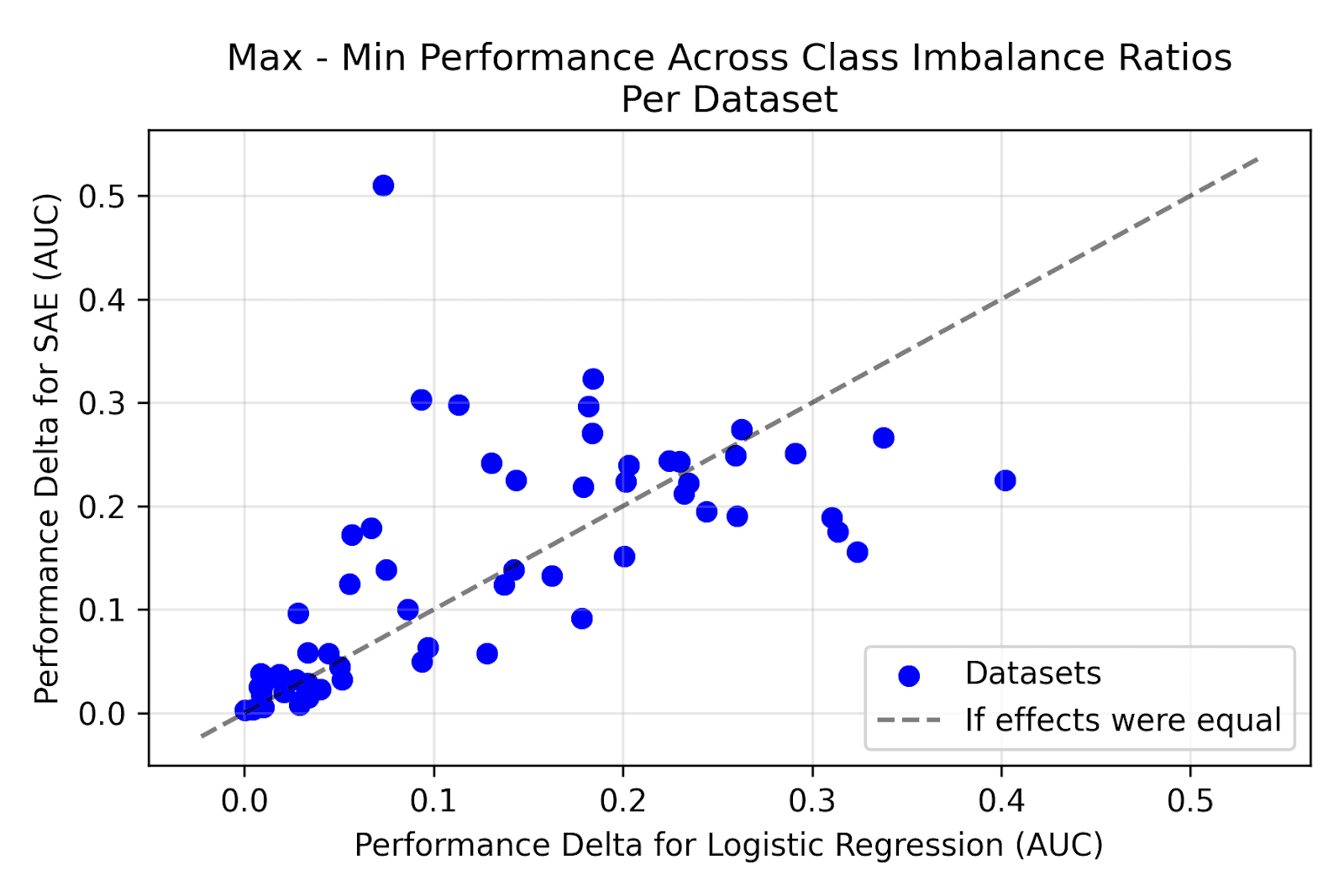
We see that the difference between the best performance and the worst performance at different class imbalance ratios per dataset (our measure of imbalance robustness) seems to be roughly the same for baselines and SAE probes. If anything, it seems like baselines might be slightly more robust to class imbalance.
Why didn’t OOD and imbalanced class SAE probes work out better? The former we attribute to baseline probes learning a more faithful, “true” representation of the feature (if the dataset is uncorrupted). Baseline probes have a specific feature they’re interested in learning in a supervised way, while SAE latents are unsupervised, and when SAE probing we find the set of latents that is most closely aligned with the feature of interest. In that sense, baseline probes have more capacity for learning the specific feature of interest. However, we find more of a null than a definitive answer to if SAE probes are better/worse OOD[8]. We don’t have a strong hypothesis for why imbalanced class probes don’t work better - one experiment we should try is shifting to 1024 training examples instead of confounding data efficiency with class imbalance. We can also test the setting where we have imbalanced classes in the training data but balanced classes in the test set.
Interpretability
Of course, SAEs were created for interpretability research, and we find that some of the most interesting applications of SAE probes are in providing interpretability insight. We see two interpretability uses of SAE probes: 1) understanding SAE features better 2) understanding datasets better (e.g. identifying possible data corruption and spurious correlations).
Understanding SAE features better
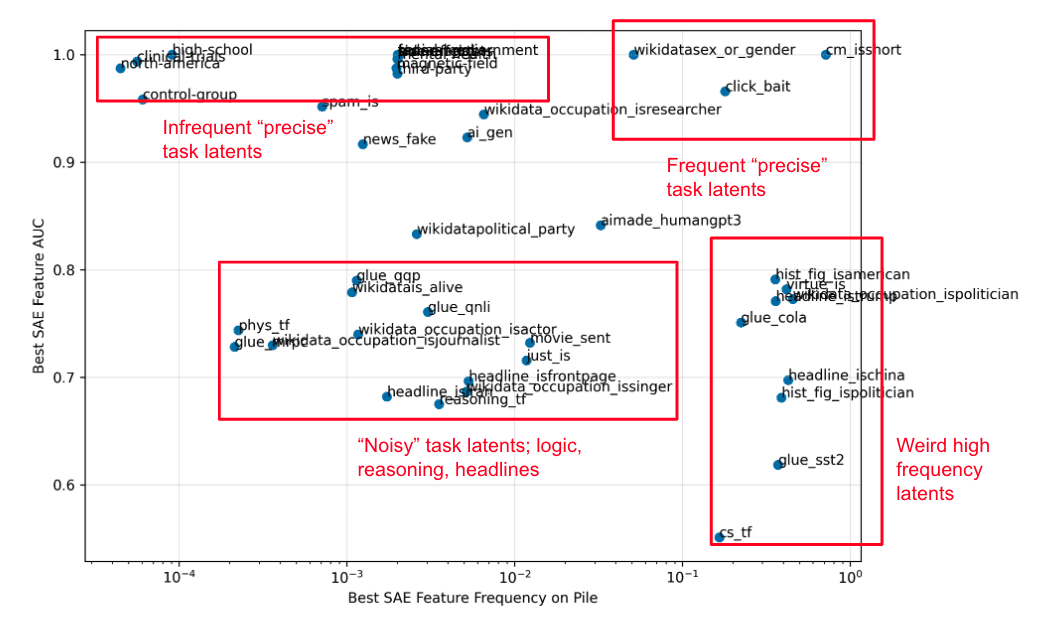
We identify the top SAE latent for each dataset, and run all of them on 5M tokens from the Pile. We find some interesting patterns: there are some high frequency latents which fire on >10% of the Pile (right of plot) that can sometimes be extremely differentiating (top right). On the other hand, we find extremely rare latents that are incredibly precise (the top left of the plot is entirely dedicated to identifying specific phrases). We can zoom in on one dataset from each of these quadrants and look at what their SAE features fire on.

Understanding datasets better
We find the most interesting interpretability application of SAE probes to be understanding datasets better. Because the SAE basis is interpretable, we can look at what latents are used to peer into how the dataset is being classified.
ChatGPT-3.5 vs Human text (Identifying spurious correlations)
We first study a dataset that consists of text written by ChatGPT-3.5 and humans, with the goal of differentiating the two. SAE probes have a significant advantage at small training sizes, and there exists a single latent with AUC ~0.80, so what is it the probe latching onto?
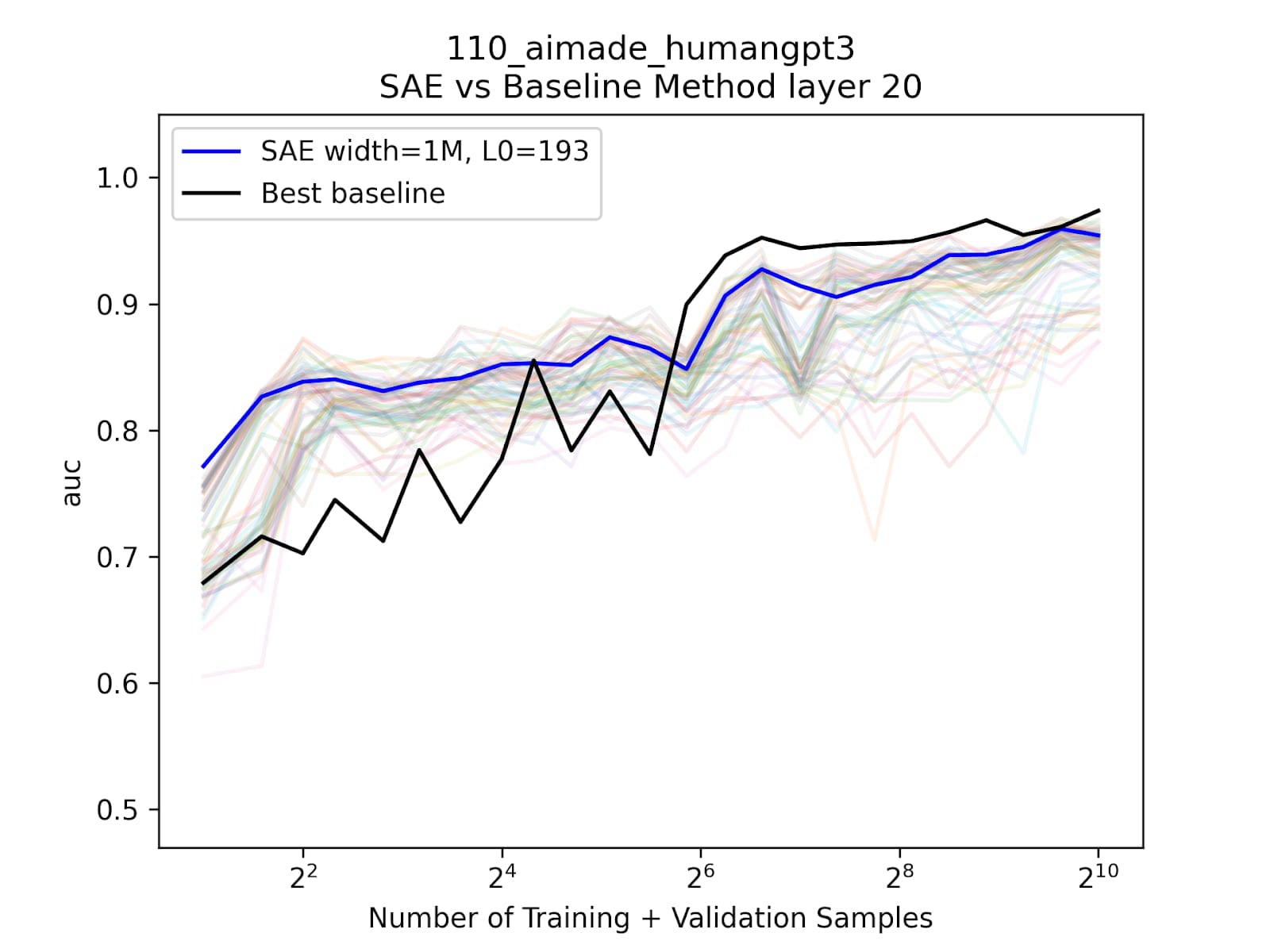
We find that this most determining feature actually identifies whether there is a period or not on the last token. And when we plot the distribution of last tokens of the dataset, we find that significantly more of the AI text ends with a period than the human text.
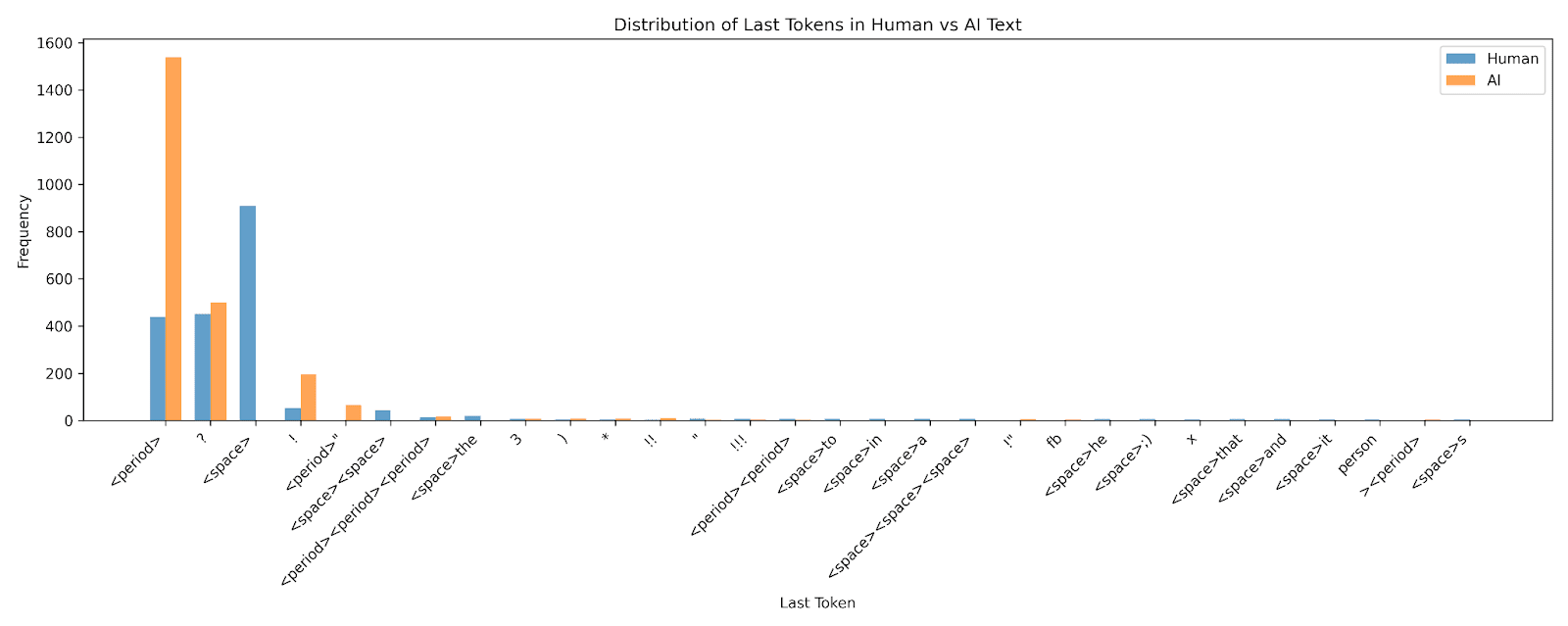
Thus, we find that even though our SAE probe is effective, it is only because the data has a spurious correlation with an easy feature. So SAE probes allowed us to discover something defective about our dataset! Notably, Anthropic also showed the potential for SAE probes to identify spurious correlations.
GLUE CoLA (Correcting an established dataset!)
SAE probes can discover spurious correlations in our dataset, but what else can they tell us? We move to studying GLUE CoLA, a dataset that has been cited >1000 times, where SAE probes show an advantage at small training set sizes and are consistently competitive. CoLA consists of sentences, and a label of 1 if the sentence is a fully grammatical English sentence, and 0 otherwise.
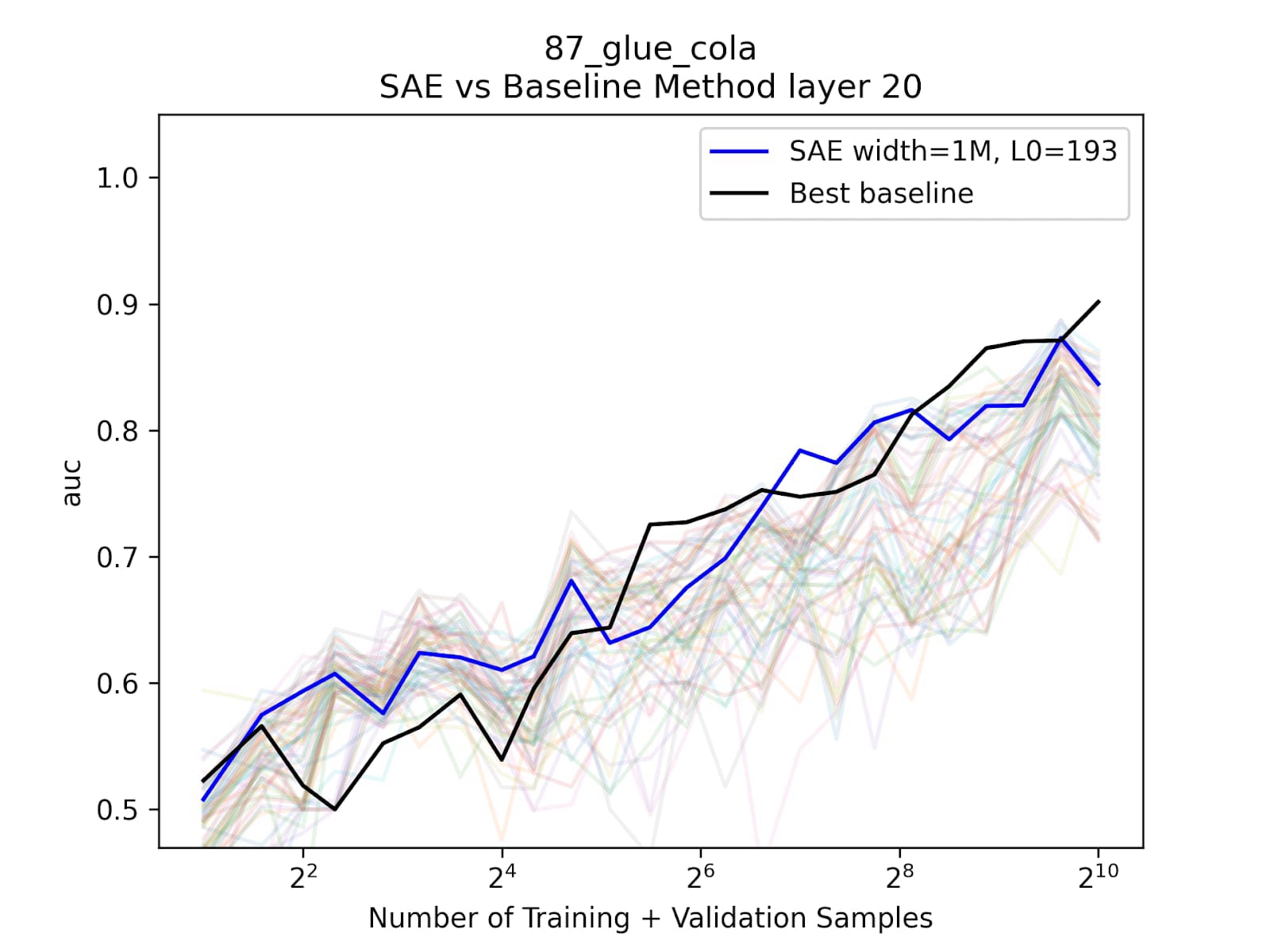
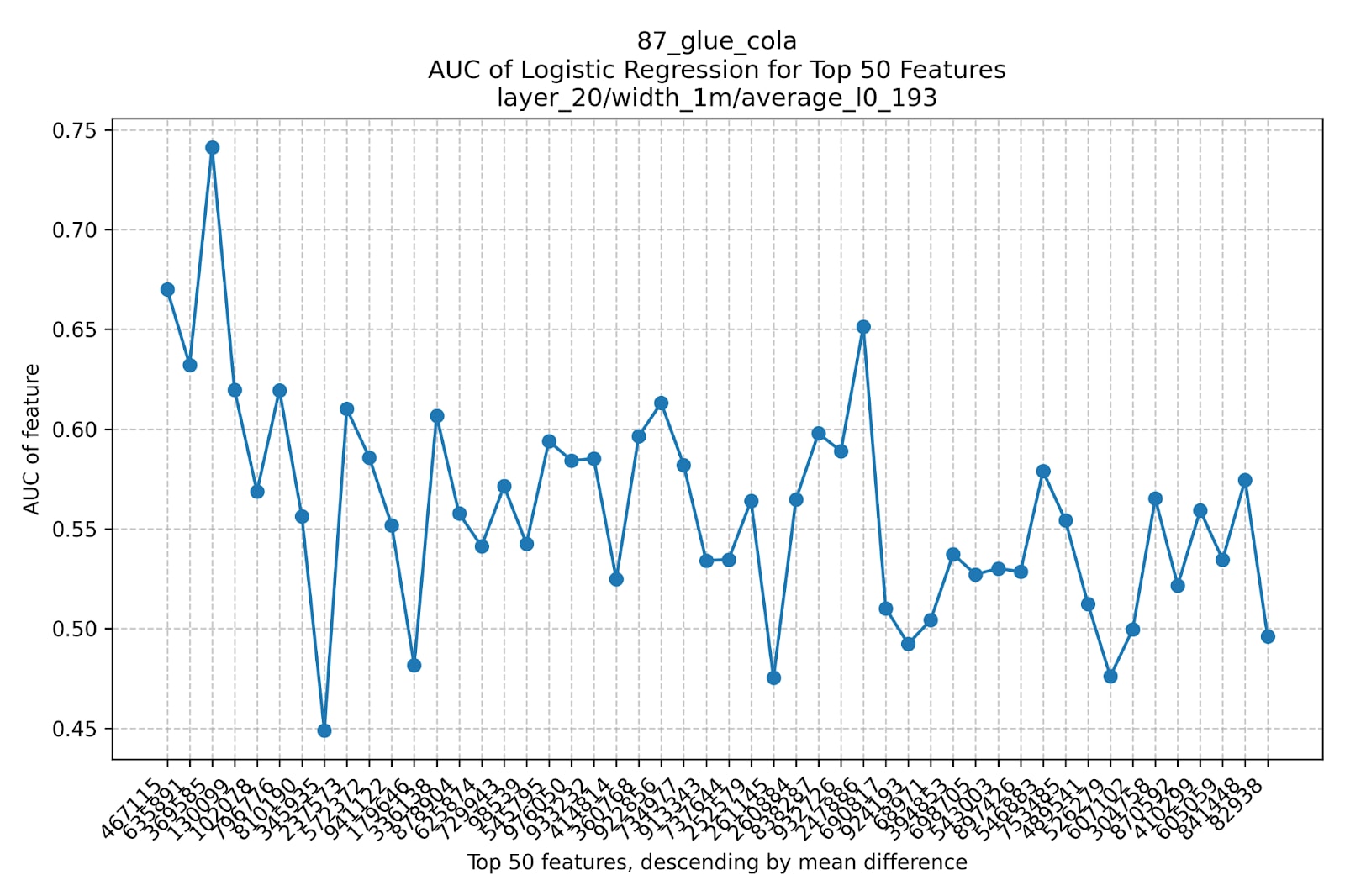
We find an SAE feature with AUC of ~0.75 that we zoom into. This feature seems to fire on ungrammatical text. When looking at its errors, we find that our feature often seems to be more correct than the actual dataset!
Here are examples where the dataset says the sentence is grammatical, but the feature says are ungrammatical (these are simply the five top activating labeled grammatical examples the feature fires on). To us, many of these seem truly ungrammatical!
Palmer is a guy who for for him to stay in school would be stupid. 23.78
how many have you given of these books to these people. 23.26
I don't remember what all I said? 22.20
This hat I believe that he was wearing. 18.98
Our love their. 18.60
Lucy recounted a story to remember because Holly had recounted as story not to. 17.96
On the other hand, here is a random set of examples which the dataset says are ungrammatical, but the feature says are grammatical. Again, some of these seem actually grammatical!
Any lion is generally majestic.
The politician perjured his aide.
The bear sniff
They persuaded it to rain.
Brown equipped a camera at Jones.
It tried to rain.
We dived into the CoLA paper, and found that there have been disagreements in the field of linguistics over the quality of judgements of sentence acceptability. In fact, when asking 5 linguistics PhD students to rate the acceptability of CoLA statements, the CoLA authors find that ensembling their predictions results in a 13% disagreement rate with the CoLA labels, so there is a chance that some of the CoLA labels are wrong, and our feature of interest is right![11]
To test this, we take 1000 sentences from CoLA, and ask 3 frontier LLMs to rate if they’re linguistically acceptable sentences[12]. We ensemble their predictions by taking a majority vote, and consider this to be the “ground truth” label[13]. We then test how our baseline, SAE probe, and single feature classifier do on the original (dirty) labels, the ground truth labels, and the specific labels where the ground truth and original label disagree (the “corrupted” labels).
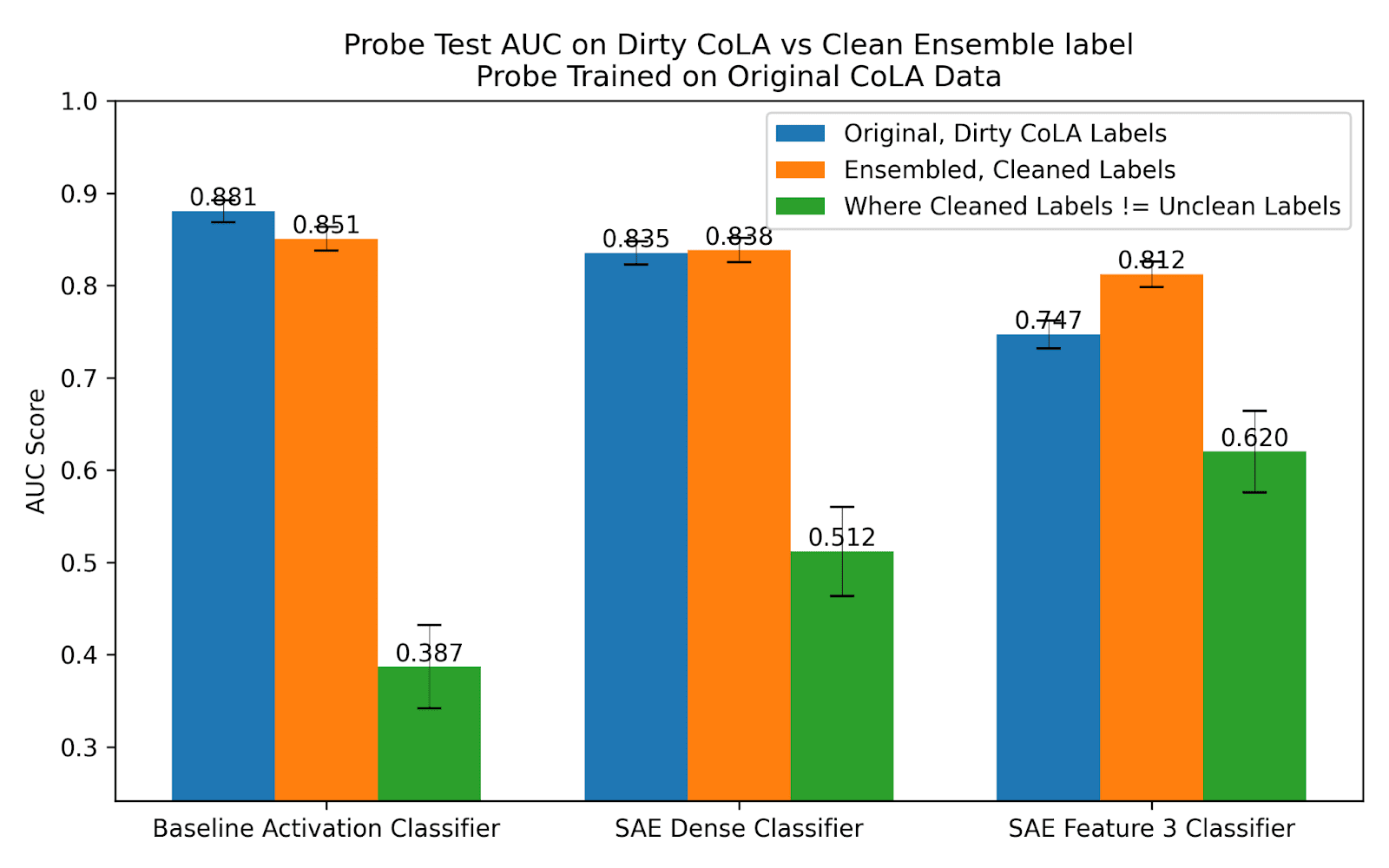
Remarkably, we find that the single feature classifier outperforms other methods significantly on the labels that were corrupted (green column). We believe this is because the single feature cannot overfit to the corrupted labels, it can only represent what it thinks is grammatical/ungrammatical.
This is a real world example of SAE probes excelling on label noise, and this telling us something useful about what we thought was ground truth!
Conclusions
We find that SAE probes are a useful addition to a practitioner's toolkit. They excel in cases where data is scarce, possibly corrupted, or when we want to interpret our probe or dataset more. In the future, we are especially excited about applying SAE probes to cases with label noise, as we believe that we might be able to design real world case studies (e.g. probing for truthfulness) where SAE probes could have significant performance improvements (and ensuing safety benefits). We also believe that as larger SAEs become publicly available, SAE probing will become a more powerful technique.
Author contribution statement: Subhash and Josh are equal contributors to this project. Sen provided helpful mentorship throughout as a TA, and Neel proposed the project and gave useful feedback.
- ^
With fewer than 13 samples, we use leave-two-out cross validation, with fewer than 128 samples we use k-fold cross validation with k = 6, and larger than that we set aside 20% of the data for validation and the rest for training.
- ^
We use ROC AUC because it evaluates classifier performance across all thresholds, offering a more balanced view of true and false positive rates and measures the overall discrimination ability of a probe (its “strength).
- ^
N_estimators, max_depth, learning_rate, subsample, colsample_bytree, reg_alpha, reg_lambda, min_child_weight
- ^
We find it interesting that logistic regression seems to be so dominant across datasets even when compared with nonlinear methods with considerably more capacity.
- ^
Notably, we did not do extensive optimization in the label noise setting. For example, we could have set class encodings to 0.2 and 0.8 instead of 0 and 1 to “soften” the logistic regression. We don’t expect this to have a major impact on our results because both SAEs and baselines use logistic regression and both would see a performance boost.
- ^
This example will come up again during our GLUE CoLA case study in the interpretability section!
- ^
Importantly, the strength of SAE probes to be robust to label noise could be a weakness in other settings. For example, if there is nuance in class labels SAEs probes might not be able to fit to them because they lack the capacity of traditional activation probes.
- ^
This is in contrast to Anthropic’s work, which finds that SAE probes can outperform activation probes on OOD data, although margins of error are not reported and only a single dataset is used.
- ^
Ex: “After Jim lost the card game he pouted for hours. [SEP] childish” True
- ^
It’s also possible that the code feature fires because words in code need to be a logical continuation of what came before, but this seems like too big of a stretch.
- ^
This is a sensitive claim, and depends on exactly what “wrong” and “right” means in terms of linguistic acceptability. Neither of the authors of this post are linguists, but we use an ensemble of native speakers as an acceptable signal of right and wrong. This seems to be the standard in linguistics as well. Citing CoLA: “Chomsky (1957) defines an empirically adequate grammar of a language L as one which generates all and only those strings of L which native speakers of L judge to be acceptable. Evaluating grammatical theories against native speaker judgments has been the dominant paradigm for research in generative syntax over the last sixty years (Schütze, 1996).”
- ^
We use GPT-4o, Sonnet 3.5, and LLama 3.1 405B. Our results are sensitive to the prompt. For example when just asking to rate acceptability, all of the LLMs made basic mistakes like saying sentences without periods were acceptable. These results use the prompt: “Assess the following sentence for grammatical correctness and proper punctuation. A grammatically correct sentence should have no errors in syntax, usage, or structure and must include appropriate punctuation, such as a period at the end for declarative sentences. Do not modify the sentence. Answer with 'yes' only if the sentence is completely free of grammatical errors and is punctuated correctly, otherwise answer 'no':”
- ^
This is not the same as ensembling true human predictions, but due to constrained resources we were unable to rate 1000 sentences for acceptability ourselves.
0 comments
Comments sorted by top scores.