AI Impacts Survey: December 2023 Edition
post by Zvi · 2024-01-05T14:40:06.156Z · LW · GW · 6 commentsContents
A Very Large Survey Full of Contradictions They’ve Destabilized the Timeline What, Me Worry? The Biggest Question Not So Fast with the Not So Fast Safety Research Is Good Actually Questions for Next Season None 6 comments
Katja Grace and AI impacts survey thousands of researchers on a variety of questions, following up on a similar 2022 survey as well as one in 2016.
I encourage opening the original to get better readability of graphs and for context and additional information. I’ll cover some of it, but there’s a lot.
A Very Large Survey Full of Contradictions
Here is the abstract, summarizing many key points:
In the largest survey of its kind, we surveyed 2,778 researchers who had published in top-tier artificial intelligence (AI) venues, asking for their predictions on the pace of AI progress and the nature and impacts of advanced AI systems.
The aggregate forecasts give at least a 50% chance of AI systems achieving several milestones by 2028, including autonomously constructing a payment processing site from scratch, creating a song indistinguishable from a new song by a popular musician, and autonomously downloading and fine-tuning a large language model.
If science continues undisrupted, the chance of unaided machines outperforming humans in every possible task was estimated at 10% by 2027, and 50% by 2047. The latter estimate is 13 years earlier than that reached in a similar survey we conducted only one year earlier [Grace et al., 2022]. However, the chance of all human occupations becoming fully automatable was forecast to reach 10% by 2037, and 50% as late as 2116 (compared to 2164 in the 2022 survey).
As I will expand upon later, this contrast makes no sense. We are not going to have machines outperforming humans on every task in 2047 and then only fully automating human occupations in 2116. Not in any meaningful sense.
I think the 2047 timeline is high but in the reasonable range. Researchers are likely thinking far more clearly about this side of the question. We should mostly use that answer as what they think. We should mostly treat the 2116 answer as not meaningful, except in terms of comparing it to past and future estimates that use similar wordings.
Expected speed of AI progress has accelerated quite a bit in a year, in any case.
Most respondents expressed substantial uncertainty about the long-term value of AI progress: While 68.3% thought good outcomes from superhuman AI are more likely than bad, of these net optimists 48% gave at least a 5% chance of extremely bad outcomes such as human extinction, and 59% of net pessimists gave 5% or more to extremely good outcomes.
A distribution with high uncertainly is wise. This is in sharp contrast to expecting a middling or neutral outcome, which makes little sense.
Between 37.8% and 51.4% of respondents gave at least a 10% chance to advanced AI leading to outcomes as bad as human extinction. More than half suggested that “substantial” or “extreme” concern is warranted about six different AI-related scenarios, including spread of false information, authoritarian population control, and worsened inequality.
Once again, we see what seems contradictory. If I thought there was a 10% chance of human extinction from AI, I would have “extreme” concern about that. Which I do.
There was disagreement about whether faster or slower AI progress would be better for the future of humanity. However, there was broad agreement that research aimed at minimizing potential risks from AI systems ought to be prioritized more.
We defined High-Level Machine Intelligence (HLMI) thus:
High-level machine intelligence (HLMI) is achieved when unaided machines can accomplish every task better and more cheaply than human workers. Ignore aspects of tasks for which being a human is intrinsically advantageous, e.g. being accepted as a jury member. Think feasibility, not adoption.
This is a very high bar. ‘Every task’ is very different from many or most tasks, especially combined with both better and cheaper. Also note that this is not all ‘intellectual’ tasks. It is all tasks, period.
We asked for predictions, assuming “human scientific activity continues without major negative disruption.” We aggregated the results (n=1,714) by fitting gamma distributions, as with individual task predictions in 3.1.
In both 2022 and 2023, respondents gave a wide range of predictions for how soon HLMI will be feasible (Figure 3).
The aggregate 2023 forecast predicted a 50% chance of HLMI by 2047, down thirteen years from 2060 in the 2022 survey. For comparison, in the six years between the 2016 and 2022 surveys, the expected date moved only one year earlier, from 2061 to 2060.
They’ve Destabilized the Timeline
This is the potential future world in which, as of 2047, an AI can ‘do every human task better and cheaper than a human.’
What happens after that? What do they think 2048 is going to look like? 2057?
That is the weirdest part of the whole exercise.
From this survey, it seems they are choosing not to think about this too hard? Operating off some sense of ‘things will be normal and develop at normal pace’?
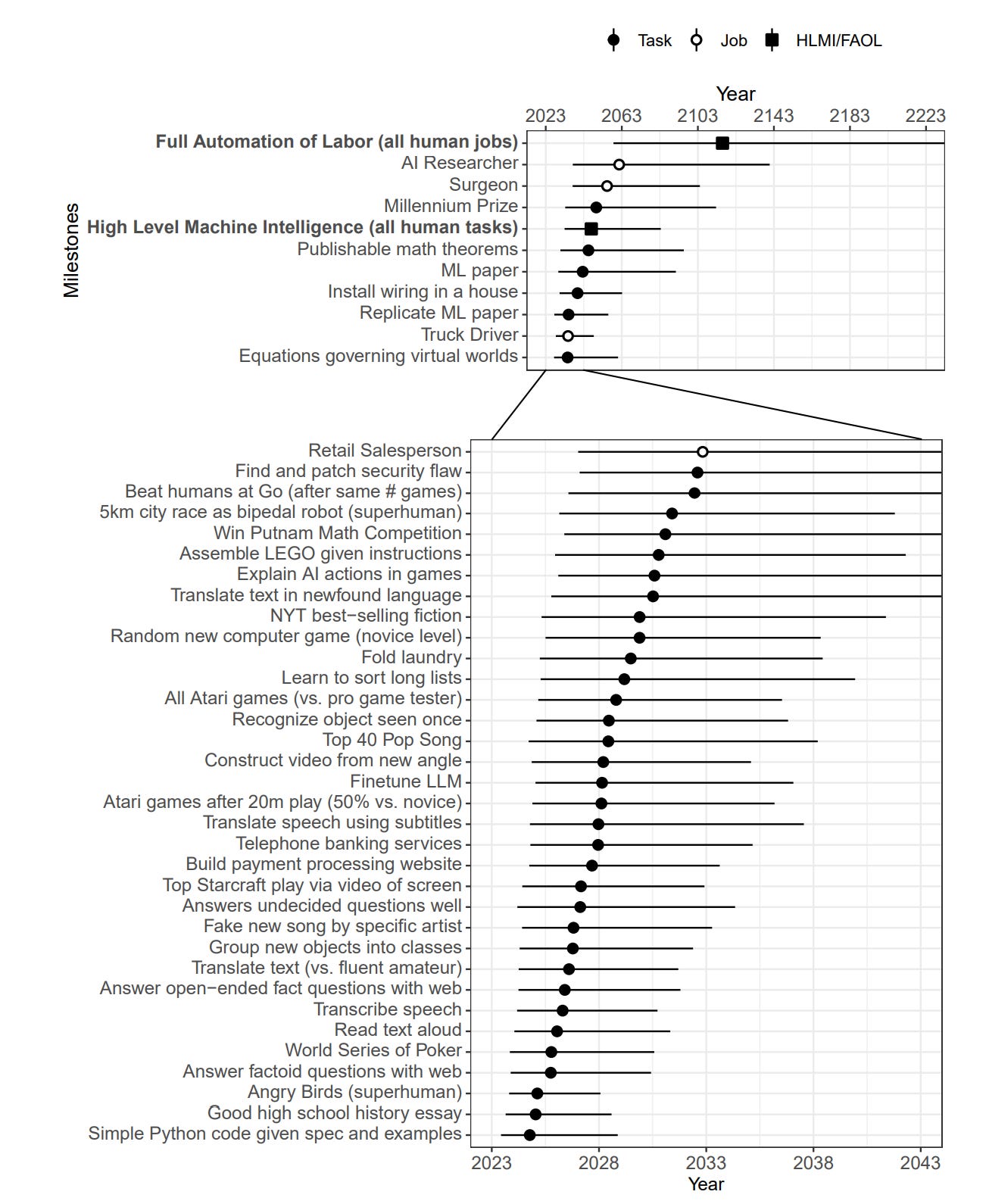
[Note that I misread the second chart initially as having the same scale as the first one. The second chart is an expansion of the lefthand side of the first chart.]
Do they actually expect us to have AI capable of doing everything better than we are, and then effectively sit on that for several generations?
Including two human generations during which the AIs are doing the AI research, better and cheaper than humans? The world is going to stay that kind of normal and under control while that happens?
FOAL below is Full Automation of Human Labor, HLMI is High Level Machine Intelligence.
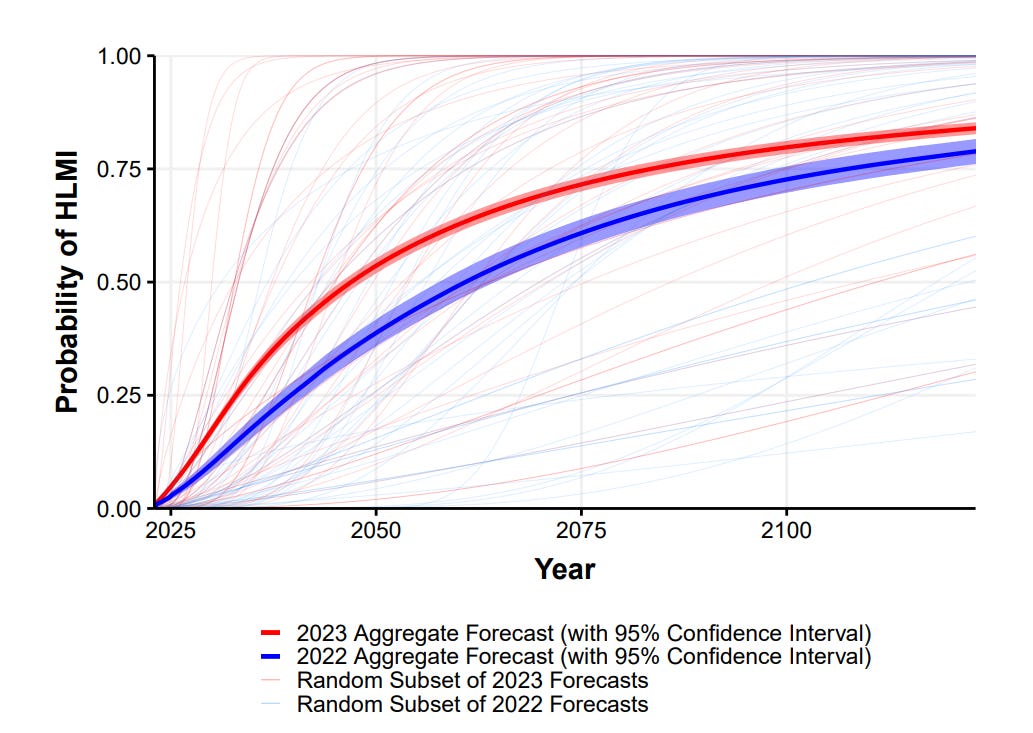
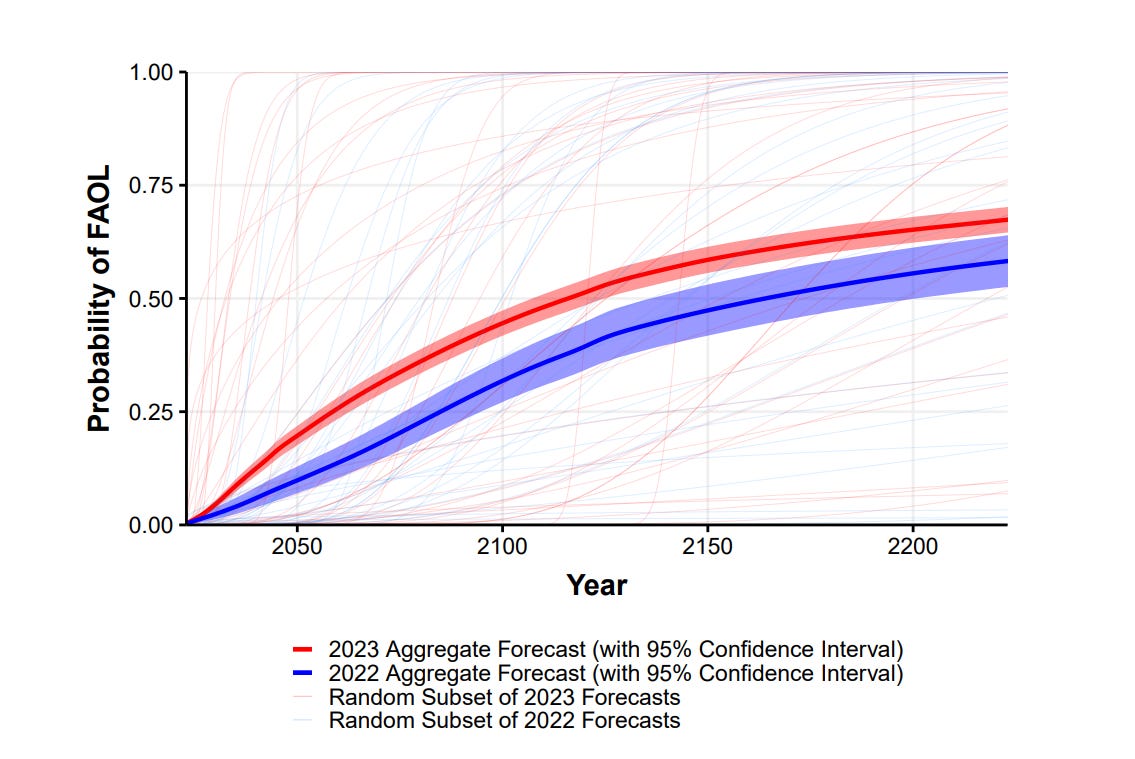
The paper authors notice that they too are confused.
Since occupations might naturally be understood either as complex tasks, composed of tasks, or closely connected with one of these, achieving HLMI seems to either imply having already achieved FAOL, or suggest being close. We do not know what accounts for this gap in forecasts. Insofar as HLMI and FAOL refer to the same event, the difference in predictions about the time of their arrival would seem to be a framing effect.
If the reason for the difference is purely ‘we expect humans to bar AIs from fully taking over at least one job employing at least one person, or at least we expect some human to somewhere continue to be able to perform some labor’ then that could explain the difference. I’d love to have some clarifying questions.
This also seems to be a basic common sense test about consequences of AI: If AI is in full ‘anything you can do I can do better’ mode, will that be an order of magnitude acceleration of technological progress?
I mean, yes, obviously? I assume this graph’s descriptions on the left are accidentally reversed, but even so this seems like a lot of people not thinking clearly? You can doubt that HLMI will arrive, but if we do have it, the consequences seem clear. Unless people think we would have the wisdom and ability to mostly not use it at all?
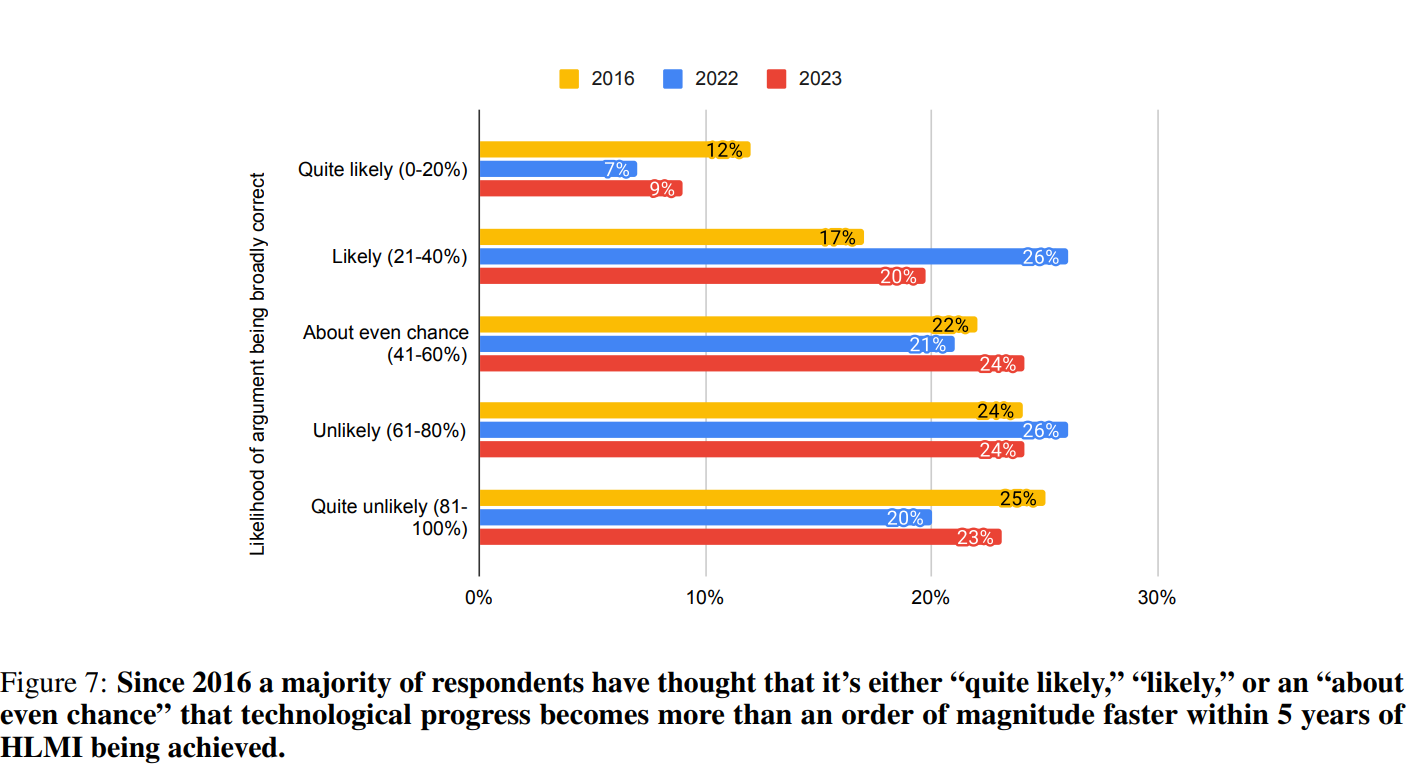
Or:
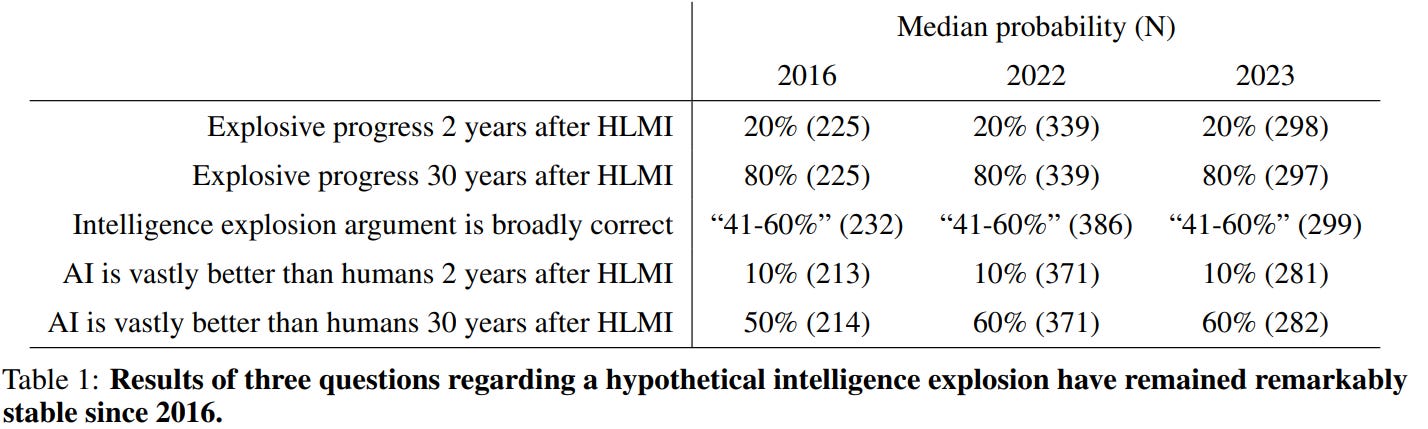
To state the obvious, AI is vastly better than humans zero (0) years after HLMI. If you can do actual everything better than me using a vastly different architecture than mine, you are not only a little bit better. Certainly two years later a 10% chance simply makes zero sense here.
Here is more absurdity, these are probabilities by 2043. This is not even close to a consistent set of probability distributions. Consider which of these, or which combinations, imply which others.

Certainly I think that some of these listed possible events are not so uncertain, such as ‘sometimes deceive humans to achieve a goal without this being intended by humans.’ I mean, how could that possibly not happen by 2043?
What, Me Worry?
And here is what people are concerned about, an extremely concerning chart.

Worries are in all the wrong places. The most important worry is… deepfakes? These are not especially central examples of the things we should be worried about.
Of all the concerns here, the biggest should likely be ‘other’ simply because of how much is left not full under the other umbrellas. One could I suppose say that ‘AIs with wrong goals become powerful’ and ‘AI has its goals set wrong’ cover a lot of ground, even if I would describe the core events a different way.
One could also take this not as a measure of what is likely, but rather a measure of what is ‘concerning.’ Meaning that people express concern for social reasons, rather than because the biggest worries from AI that is expected to be able to literally do all jobs better and cheaper than humans are… deepfakes and manipulation of public opinion. I mean, seriously?
Another option is that people were thinking in contradictory frames. In one frame, they realize that HLMI-level AI is coming. In another frame, they ask ‘what is concerning?’ and are thinking only about mundane AI.
The Biggest Question
On the net consequences of AI, including potential existential risk, sensemaking is not getting better.

Of all the potential consequences of HLMI, an AI capable of doing everything better than humans, ‘neutral’ does not enter into it. That makes absolutely no sense. It is the science fiction story we tell ourselves so that we can continue telling the same relatable human stories. It might go great, it might be the end of everything worthwhile, what it absolutely will not be is meh.
If you tell me it ‘went neutral’ then I can come up with a story, where someone or some group creates HLMI/ASI and then decides to use it to ensure no one else builds one and otherwise leave things entirely alone because they think doing anything else would be worse. I mean, it’s definitely an above-average plan for what to do given what other plans I have seen, but no.
So what do we make of these p(doom) numbers? Let’s zoom in, these are probabilities that someone responded with 10% or higher based on question wording:
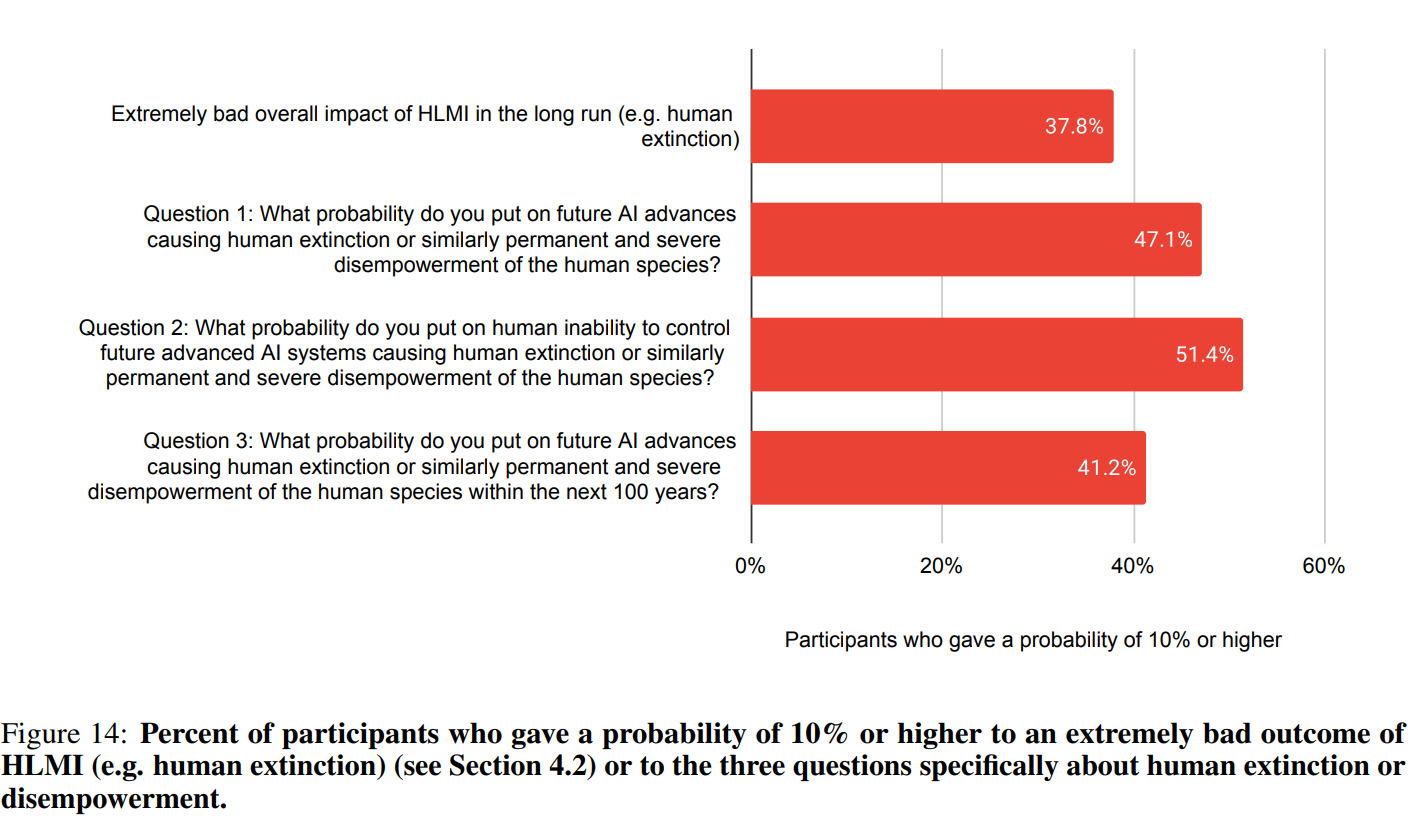
The p(doom) numbers here are a direct contradiction. We’re going to get some weird talking points.
In Figure 12, we have a mean of 9% and median of 5% for the full range of ‘extremely bad’ outcomes.
In Figure 13’s question 3, we have 14.4% mean chance of either human extinction or severe disempowerment, or 16.2% chance in the longer term, and still 5% median.
Then, in question 2, they ask ‘what probability do you put on human inability to control future advanced AI systems causing human extinction or similarly permanent and severe disempowerment’ and they have a mean of 19.4% and a median of 10%.
She’s more likely to be a librarian and a feminist than only a librarian, you say.
Is this mostly a classic conjunction fallacy? The framing effect of pointing out we could lose control, either biasing people or alternatively snapping them out of not thinking about what might happen at all? Something else?
This is not as big an impact as it looks when you see 5% vs. 10%. What is happening is largely that almost no one is saying, for example, 7%. So when 47% of responses are 10% or higher, the median is 5%, then at 51% it jumps to barely hitting 10%. Both 5% and 10% are misleading, the ‘real’ median here is more like 8%.
I did a survey on Twitter asking how best to characterize the findings of the survey.
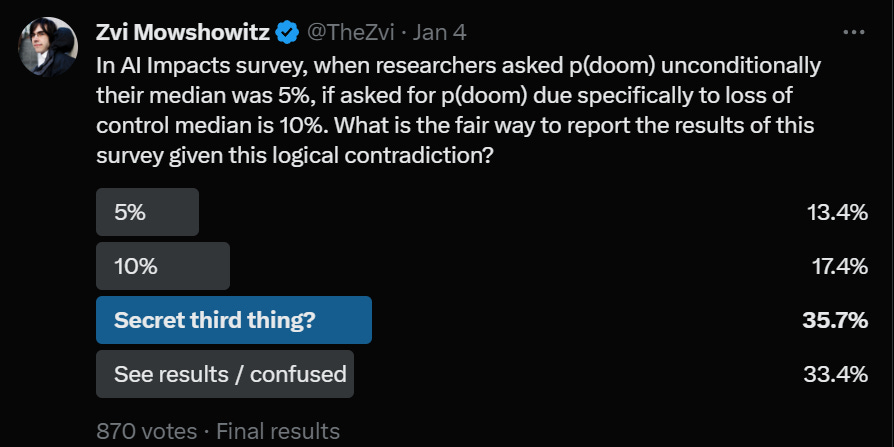
I think this poll is right. 10% is closer to accurate than 5%, but ‘median of 5%-10% depending on framing, mean of 9%-19%’ is the correct way to report this result. If someone wanted to say ‘researchers say a one in ten chance of doom’ then that is a little fast and loose, I’d avoid saying that, but I’d consider it within Bounded Distrust.
The important thing is that:
- Researchers broadly acknowledge that existential risk from AI is a real concern.
- Researchers put that risk high enough that we should be willing to make big investments and sacrifices to mitigate that risk.
- Researchers do not, however, think that such risks are the default outcome.
- Researchers disagree strongly about the magnitude of this risk.
Most importantly, existential risk is a highly mainstream concern within the field. They also are highly mainstream among the public when surveys ask.
Any media report or other rhetoric attempting to frame such beliefs as fringe positions either hasn’t done the homework, or is lying to you.
Nate Silver: This is super interesting on AI risk. Think it would be good if other fields made more attempts to conduct scientific surveys of expert opinion. (Disclosure: I did a very small bit of unpaid consulting on this survey.)
The fact that there is broad-based practitioner concern about AI safety risk (although with a lot of variation from person to person) and a quickening of AI timelines is significant. You’ll still get the occasional media report framing these as fringe positions. But they’re not.
Not So Fast with the Not So Fast
Despite these predictions of potential doom, support for slowing down now was if anything a tiny bit negative, even purely in terms of humanity’s future.

This actually makes perfect sense if (and only if) you buy that AGI is far. If HLMI is only scheduled for 2047, then slowing down from 2024-2029 does not sound like an awesome strategy. If I was told that current pace meant AGI 2047, I too would not be looking to slow down short term development of AI.
I’d want to ‘look at the crosstabs’ here, as it were, but I think a very reasonable reaction is something vaguely like:
- If you think AGI plausibly arrives within 10 years or so, you want to slow down.
- If you think AGI is highly unlikely to arrive within 10 years, but might within 25 years, you want to roughly maintain current pace while looking to lay groundwork to slow down in the future.
- If you think AGI is almost certainly more than 25 years away, and you (highly reasonably) conclude mundane pre-AGI fears are mostly overblown, accelerate for now, and perhaps worry about the rest later.
I believe the groundwork part of this is extremely important, and worry a lot about path dependence, but confidence that the timeline was 25 years or more would absolutely be a crux that would change my mind on many things.
I would love to see more people, including those with ‘e/acc’ in their bio, say explicitly that the timeline question is a crux, and their recommendations rely on AGI being far.
Safety Research Is Good Actually
One bright spot was strong support for prioritization of AI safety research, although not strong enough and with only small improvement from 2022.
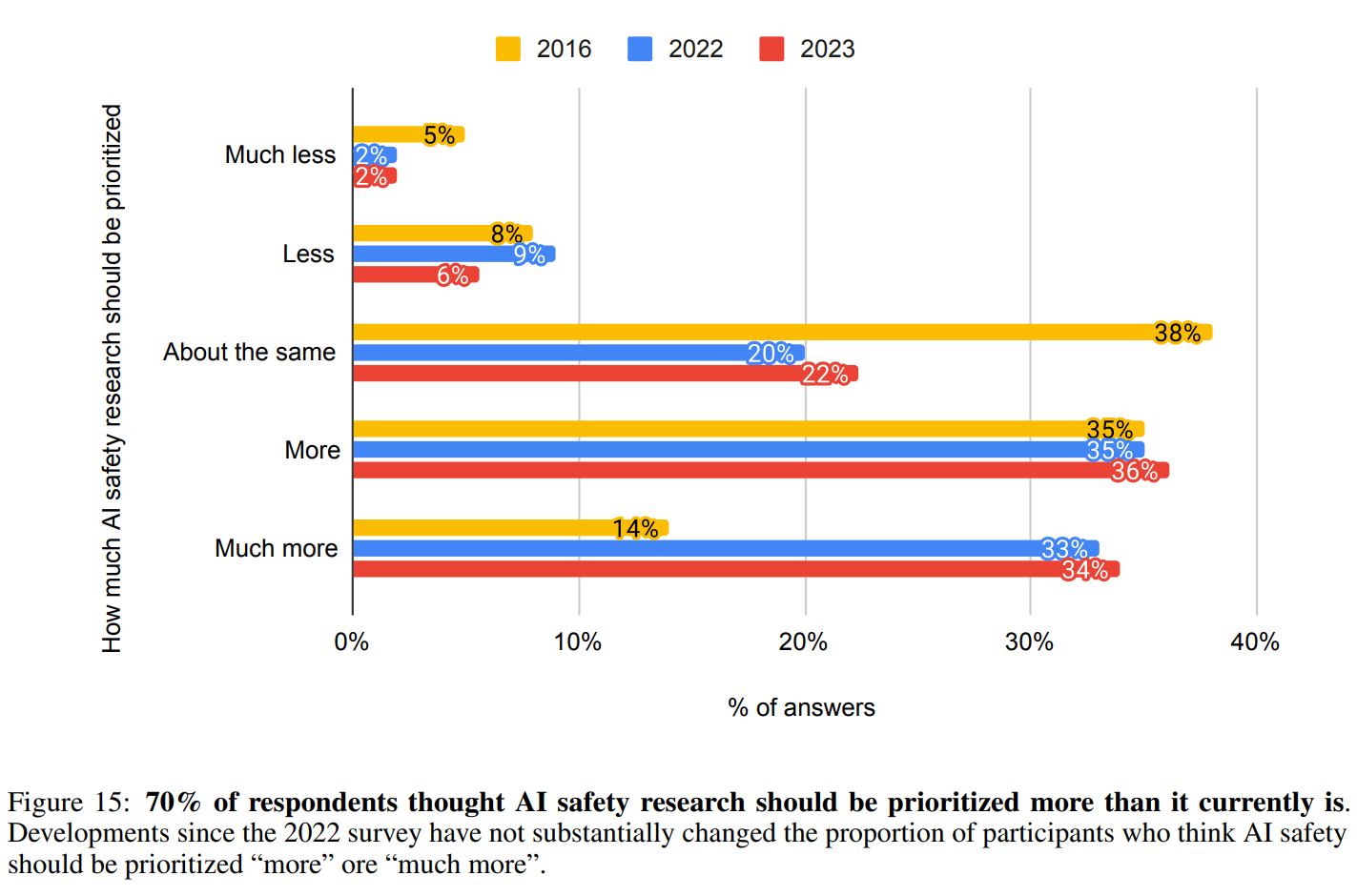
I continue to not understand the attitude of not wanting much more safety work. I can understand wanting to move forward as fast as possible. I can understand saying that your company in particular should focus on capabilities. I can’t see why one wouldn’t think that more safety work would be good for the world.
I think the 13% here for ‘alignment is among the most important problems in the field’ is silently one of the most absurd results of all:
A second set of AI safety questions was based on Stuart Russell’s formulation of the alignment problem [Russell, 2014]. This set of questions began with a summary of Russell’s argument—which claims that with advanced AI, “you get exactly what you ask for, not what you want”—then asked:
1. Do you think this argument points at an important problem?
2. How valuable is it to work on this problem today, compared to other problems in AI?
3. How hard do you think this problem is, compared to other problems in AI?
The majority of respondents said that the alignment problem is either a “very important problem” (41%) or “among the most important problems in the field” (13%), and the majority said the it is “harder” (36%) or “much harder” (21%) than other problems in AI. However, respondents did not generally think that it is more valuable to work on the alignment problem today than other problems. (Figure 16)
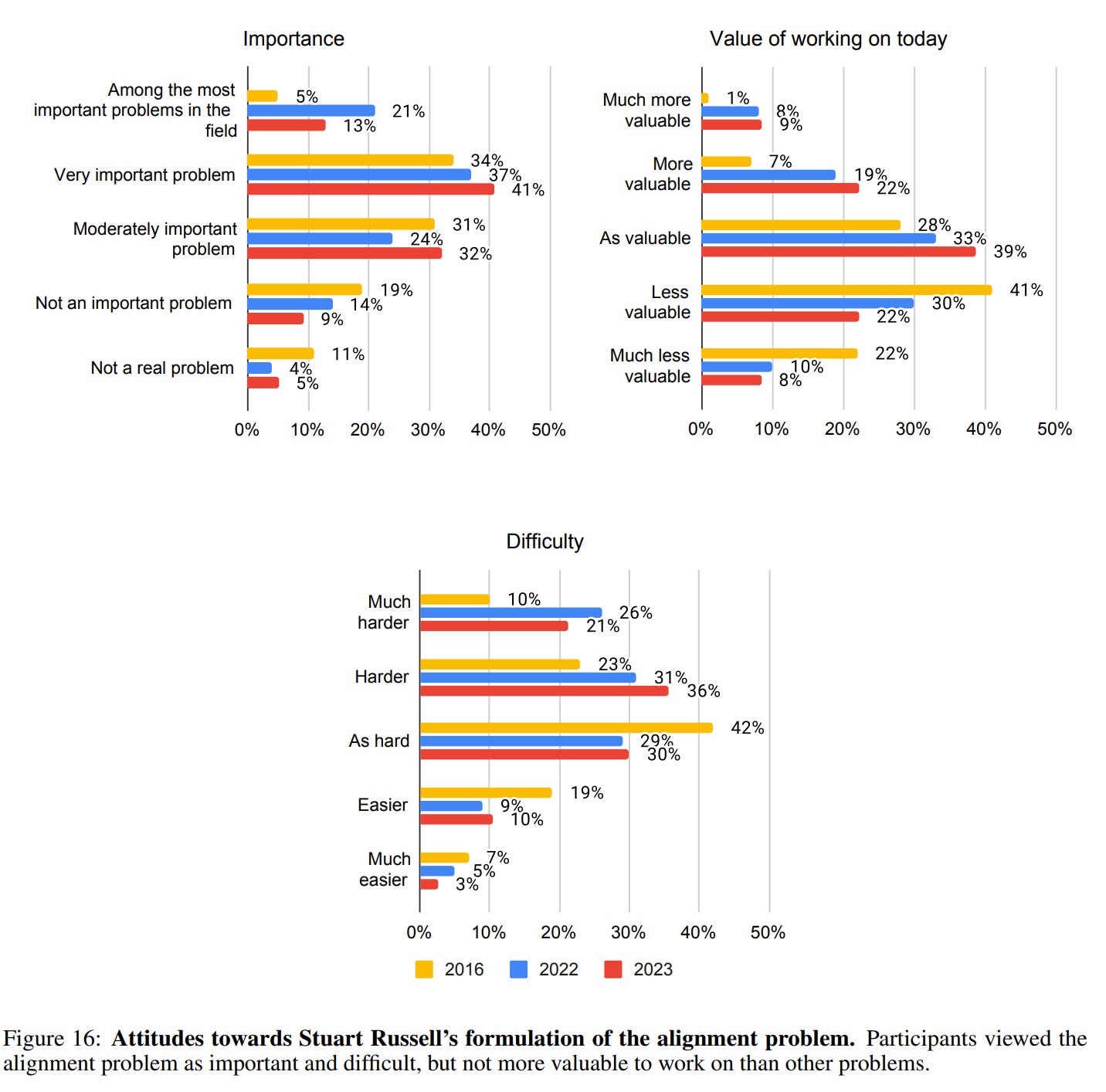
I can understand someone thinking alignment is easy. I think it is a super wrong thing to believe, but I have seen actual arguments, and I can imagine such worlds where the Russell formulation is super doable, whereas other AI problems are far harder. So, sure, on some level that is reasonable disagreement, or at least I see how you got there. I will note that estimates of alignment difficulty went modestly up over 2023, as did estimates of the value of working on it.
We do see 41% treat it as a ‘very important problem’ but it seems crazy not to think of it as ‘among the most important problems in the field.’ And I am confused why that answer declined so much, from 21% to 13%, especially given other answers, perhaps this is merely noise. Still, it should be vastly higher. Unless perhaps people are saying this is a wrong problem formulation?
In general, it seems like researchers are trying to be ‘more moderate’ and give neutral answers across the board. Perhaps this is due to entry and going more mainstream, and people trying to give social cognition answers.
Questions for Next Season
As with many such surveys, I would love to see more clarifying questions, and more attempt to be able to measure correlations. Which future expectations correspond to which worries? Why are we seeing the Conjunction Fallacy? What changed people’s minds over the past year, or what do people think did it? What kind of future are people expecting? How do researchers describe things like the automation of all human labor, and what do they think such worlds would look like?
In terms of what brand new questions to ask for the 2024 edition, wow are things moving fast, so maybe ask again in six months?
6 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2024-01-05T16:21:14.572Z · LW(p) · GW(p)
I can’t see why one wouldn’t think that more safety work would be good for the world.
More safety work would be bad if it's not useful for improving actual safety, and is instead used to empower lobbying for terrible policy that destroys good things or ensures regulatory capture.
comment by Vladimir_Nesov · 2024-01-05T16:36:26.826Z · LW(p) · GW(p)
Stuart Russell’s formulation of the alignment problem [...] We do see 41% treat it as a ‘very important problem’ but it seems crazy not to think of it as ‘among the most important problems in the field.’
"It's not the consequence that makes a problem important, it is that you have a reasonable attack."
Replies from: gwerncomment by faul_sname · 2024-01-05T17:53:59.399Z · LW(p) · GW(p)
As I will expand upon later, this contrast makes no sense. We are not going to have machines outperforming humans on every task in 2047 and then only fully automating human occupations in 2116. Not in any meaningful sense.
Maybe people are interpreting "task" as "bounded, self-contained task", and so they're saying that machines will be able to outperform humans on every "task" but not on the parts of their jobs that are not "tasks".
The exact wording of the question was
Say we have ‘high-level machine intelligence’ when unaided machines can accomplish every task better and more cheaply than human workers. Ignore aspects of tasks for which being a human is intrinsically advantageous, e.g. being accepted as a jury member.
It does not appear that the survey had any specific guidance on how to interpret the word "task", so it wouldn't surprise me that much if people consider their job to be composed of both things that are tasks and also things that are not tasks, and that the things that are not tasks will take longer to automate.
comment by PeterMcCluskey · 2024-01-05T17:49:51.202Z · LW(p) · GW(p)
I don't quite see this logical contradiction that your Twitter poll asks about.
I wouldn't be surprised if the answers reflect framing effects. But the answers seem logically consistent if we assume that some people believe that severe disempowerment is good.
Replies from: PeterMcCluskey↑ comment by PeterMcCluskey · 2024-01-05T20:40:58.509Z · LW(p) · GW(p)
Oops. I misread which questions you were comparing.
Now that I've read the full questions in the actual paper, it looks like some of the difference is due to "within 100 years" versus at any time horizon.
I consider it far-fetched that much of the risk is over 100 years away, but it's logically possible, and Robin Hanson might endorse a similar response.