Skepticism About DeepMind's "Grandmaster-Level" Chess Without Search
post by Arjun Panickssery (arjun-panickssery) · 2024-02-12T00:56:44.944Z · LW · GW · 13 commentsContents
13 comments
Update: Authors commented below that their unpublished results show that actually the bot is as good as described; many thanks to them.
First, addressing misconceptions that could come from the title or from the paper's framing as relevant to LLM scaling:
- The model didn't learn from observing many move traces from high-level games. Instead, they trained a 270M-parameter model to map pairs to Stockfish 16's predicted win probability after playing the move. This can be described as imitating the play of an oracle that reflects Stockfish's ability at 50 milliseconds per move. Then they evaluated a system that made the model's highest-value move for a given position.
- The system resulted in some quirks that required workarounds during play.
- The board states were encoded in FEN notation, which doesn't provide information about which previous board states have occurred; this is relevant in a small number of situations because players can claim an immediate draw when a board state is repeated three times.
- The model is a classifier, so it doesn't actually predict Stockfish win-probability but instead predicts the bin (out of 128) into which that probability falls. So in a very dominant position (e.g. king and rook versus a lone king) the model doesn't distinguish between moves that lead to mate and can alternate between winning lines without ever achieving checkmate. Some of these draws-from-winning-positions were averted by letting Stockfish finish the game if the top five moves according to both the model and Stockfish had a win probability above 99%.
Some comments have been critical on these grounds, like Yoav Goldberg's "Grand-master Level Chess without Search: Modeling Choices and their Implications" (h/t Max Nadeau). But these don't seem that severe to me. Representing the input as a sequence of board states rather than the final board state would have also been a weird choice, since in fact the specific moves that led to a given board state basically doesn't affect the best move at all. It's true that the model didn't learn about draws by repetition, and maybe Yoav's stronger claim that it would be very difficult to learn that rule observationally is also true—especially since such draws have to be claimed by a player and don't happen automatically (even on Lichess). But it's possible to play GM-level chess without knowing this rule, especially if your opponents aren't exploiting your ignorance.
But I'm skeptical that the model actually plays GM-level chess in the normal sense. You need to reach a FIDE Elo of 2500 (roughly 2570 USCF) to become a grandmaster. I would guess Lichess ratings are 200-300 points higher than skill-matched FIDE ratings, but this becomes a bit unclear to me after a FIDE rating of ~2200 or so, where I could imagine a rating explosion because the chess server will mostly match you with players who are worse than you (at the extreme, Magnus Carlsen's peak Lichess rating is 500 points higher than his peak FIDE rating).
Take the main table of the paper:
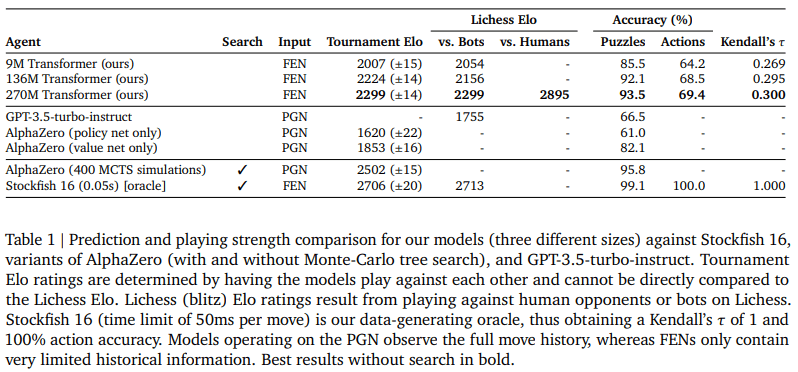
They don't describe their evaluation methodology in detail but it looks like they just created a Lichess bot. Lichess bots won't pair with human players that use the matchmaking system on the home page; you have to navigate to Community → Online Players → Online Bots and then challenge them to a game. So there are three results here:
- Lichess Elo (2299): This is the column labeled "vs. Bots" but it actually played 4.5% of its games against humans. Most human players on Lichess don't challenge bots, so most of the games were against other bots.
- Tournament Elo: This was a tournament between a bunch of AlphaZero-based models, smaller versions of their model, and Stockfish. The Elo scoring was anchored so that the main 270M-parameter model had a score of 2299, which means that the best interpretation of the results is that the model performance is roughly 400 Elo points worse than Stockfish 16.
- Lichess Elo vs. Humans (2895): This is based on ~150 games where their model only accepted challenges from human players. The class of players who play strong bots is probably very unlike the normal player distribution. In fact I don't have a good model at all of why someone would take a lot of interest in challenging random bots.
Even a Lichess rating of 2900 might only barely correspond to grandmaster-level play. A Lichess rating of 2300 could correspond to 2000-level (FIDE) play.
They mention two other reasons for the discrepancy:
- Humans tend to resign when they're crushed, while bots sometimes manage to draw or win if they luck into the indecisiveness problem mentioned in 3.b above.
- "Based on preliminary (but thorough) anecdotal analysis by a [FIDE ~2150 player], our models make the occasional tactical mistake which may be penalized qualitatively differently (and more severely) by other bots compared to humans."
They apparently recruited a bunch of National Master-level players (FIDE ~2150) to make "qualitative assessments" of some of the model's games; they gave comments like "it feels more enjoyable than playing a normal engine" and that it was "as if you are not just hopelessly crushed." Hilariously, the authors didn't benchmark the model against these players . . .
Random other notes:
- Leela Chess Zero has been using a transformer-based architecture for some time, but it's not mentioned at all in the paper
- Their tournament used something called BayesElo while Lichess uses Glicko 2; this probably doesn't matter
13 comments
Comments sorted by top scores.
comment by MathiasKB (MathiasKirkBonde) · 2024-02-12T11:23:22.501Z · LW(p) · GW(p)
This wouldn't be the first time Deepmind pulled these shenanigans.
My impression of Deepmind is they like playing up the impressiveness of their achievements to give an impression of having 'solved' some issue, never saying anything technically false, while suspiciously leaving out relevant information and failing to do obvious tests of their models which would reveal a less impressive achievement.
For Alphastar they claimed 'grandmaster' level, but didn't show any easily available stats which would make it possible to verify. As someone who was in Grandmaster league at the time of it playing (might even have run into it on ladder, some of my teammates did), its play at best felt like low grandmaster to me.
At their event showing an earlier prototype off, they had one player (TLO) play their off-race with which he certainly was not at a grandmaster level. The pro player (Mana) playing their main race beat it at the event, when they had it play with the same limited camera access humans have. I don't remember all the details anymore, but I remember being continuously annoyed by suspicious omission after suspicious omission.
What annoys me most is that this still was a wildly impressive achievement! Just state in the paper: "we managed to reach grandmaster with one out of three factions" - Nobody has ever managed to create AI that played remotely as well as this!
Similarly Deepminds no-search chess engine is surely the furthest anyone has gotten without search. Even if it didn't quite make grandmaster, just say so!
Replies from: cosmobobak↑ comment by cosmobobak · 2024-02-13T14:52:15.489Z · LW(p) · GW(p)
DeepMind's no-search chess engine is surely the furthest anyone has gotten without search.
This is quite possibly not true! The cutting-edge Lc0 networks (BT3/BT4, T3) have much stronger policy and value than the AlphaZero networks, and the Lc0 team fairly regularly make claims of "grandmaster" policy strength.
Replies from: gwern↑ comment by gwern · 2024-02-14T02:24:53.545Z · LW(p) · GW(p)
That sounds interesting. Do they have any writeups on this?
Replies from: cosmobobak, polytope↑ comment by cosmobobak · 2024-02-22T00:24:40.386Z · LW(p) · GW(p)
they do now! https://lczero.org/blog/2024/02/how-well-do-lc0-networks-compare-to-the-greatest-transformer-network-from-deepmind/
comment by anianruoss · 2024-02-14T17:45:10.731Z · LW(p) · GW(p)
Thank you for your interest in our paper, Arjun!
We actually beat a GM 6-0 in blitz.
Moreover, our bot played against humans of all levels, from beginners all the way to NMs, IMs, and GMs. So far, our bot only lost 2 games (out of 365).
Does that alleviate your concerns?
Replies from: arjun-panickssery↑ comment by Arjun Panickssery (arjun-panickssery) · 2024-02-14T19:17:20.638Z · LW(p) · GW(p)
Changes my view, edited the post.
Thanks for taking the time to respond; I didn't figure the post would get so much reach.
comment by Grégoire Delétang (gregoire-deletang) · 2024-02-12T20:28:50.354Z · LW(p) · GW(p)
Thanks for the feedback. On the GM-level skepticism: I don't see any recommendation on things we could do to make the claim stronger, and I'm really thirsty for some. What would convince you (and possibly, others) that our neural network is mastering the game of chess?
We are currently (and have already) played against actual GMs and beaten some. But it's not that simple to publish (look at the time it took for 100 times bigger projects like AlphaGo or AlphaStar - this one is a two full-time people project, Anian and I), for legal reasons, because GM/IMs don't really like to be beaten publicly, for statistical reasons (you need a looot of games to be meaningful) etc. Also note that many 1500 ELO people that played against the bot on Lichess are actually fake (smurf) accounts of much stronger players.
Replies from: aron-gohr, p.b., arjun-panickssery↑ comment by GoteNoSente (aron-gohr) · 2024-02-13T21:20:29.663Z · LW(p) · GW(p)
I think the most important things that are missing in the paper currently are these three points:
1. Comparison to the best Leela Zero networks
2. Testing against strong (maybe IM-level) humans at tournament time controls (or a clear claim that we are talking about blitz elo, since a player who does no explicit tree search does not get better if given more thinking time).
3. Games against traditional chess computers in the low GM/strong IM strength bracket would also be nice to have, although maybe not scientifically compelling. I sometimes do those for fun with LC0 and it is utterly fascinating to see how LC0 with current transformer networks at one node per move manages to very often crush this type of opponent by pure positional play, i.e. in a way that makes winning against these machines look extremely simple.
↑ comment by p.b. · 2024-02-13T21:29:10.057Z · LW(p) · GW(p)
To me the most interesting question is to what extend your network learns to do reasoning/search vs pure pattern recognition.
I trained a transformer to predict tournament chess moves a few years back and my impression was that it played strongly in the opening and always made sensible looking moves but had absolutely no ability to look ahead.
I am currently working on a benchmark of positions that require reasoning and can't be solved by highly trained intuition alone. Would you be interested in running such a benchmark?
↑ comment by Arjun Panickssery (arjun-panickssery) · 2024-02-13T20:23:59.266Z · LW(p) · GW(p)
Wow, thanks for replying.
If the model has beaten GMs at all, then it can only be so weak, right? I'm glad I didn't make stronger claims than I did.
I think my questions about what humans-who-challenge-bots are like was fair, and the point about smurfing is interesting. I'd be interested in other impressions you have about those players.
Is the model's Lichess profile/game history available?
comment by Martin Fell (martin-fell) · 2024-02-12T11:31:52.788Z · LW(p) · GW(p)
Regarding people who play chess against computers, some players like playing only bots because of the psychological pressure that comes from playing against human players. You don't get as upset about a loss if it's just to a machine. I think that would count for a significant fraction of those players.