Posts
Comments
One thing to highlight, which I only learned recently, is that the norm when submitting letters to the governor on any bill in California is to include: "Support" or "Oppose" in the subject line to clearly state the company's position.
Anthropic importantly did NOT include "support" in the subject line of the second letter. I don't know how to read this as anything else than that Anthropic did not support SB1047.
I'll crosspost the comment I left on substack:
In Denmark the government has a service (ROFUS), which anyone can voluntarily sign up for to exclude themselves from all gambling providers operating in Denmark. You can exclude yourself for a limited duration or permanently. The decision cannot be revoked.
Before discussing whether gambling should be legal or illegal, I would encourage Americans to see how far they can get with similar initiatives first.
Is there any good write up on the gut/brain connection and the effect fecal transplants?
Watching the South Park episode where everyone tries to steal Tom Brady's poo got me wondering why this isn't actually a thing. I can imagine lots of possible explanations, ranging from "because it doesn't have much of an effect if you're healthy" to "because FDA".
On this view, adversarial examples arise from gradient descent being "too smart", not "too dumb": the program is fine; if the test suite didn't imply the behavior we wanted, that's our problem.
Shouldn't we expect to see RL models trained purely on self play not to have these issues then?
My understanding is that even models trained primarily with self play, such as katago, are vulnurable to adversarial attacks. If RL models are vulnurable to the same type of adversarial attacks, isn't that evidence against this theory?
The amount of inference compute isn't baked-in at pretraining time, so there is no tradeoff.
This doesn't make sense to me.
In a subscription based model, for example, companies would want to provide users the strongest completions for the least amount of compute.
If they estimate customers in total will use 1 quadrillion tokens before the release of their next model, they have to decide how much of the compute they are going to be dedicating to training versus inference. As one changes the parameters (subscription price, anticipated users, fixed costs for a training run, etc.) you'd expect to find the optimal ratio to change.
Test-time compute on one trace comes with a recommendation to cap reasoning tokens at 25K, so there might be 1-2 orders of magnitude more there with better context lengths. They are still not offering repeated sampling filtered by consensus or a reward model. If o1 proves sufficiently popular given its price, they might offer even more expensive options.
Thanks, this is a really good find!
Thanks!! this is exactly what I was looking for
With the release of openAI o1, I want to ask a question I've been wondering about for a few months.
Like the chinchilla paper, which estimated the optimal ratio of data to compute, are there any similar estimates for the optimal ratio of compute to spend on inference vs training?
In the release they show this chart:
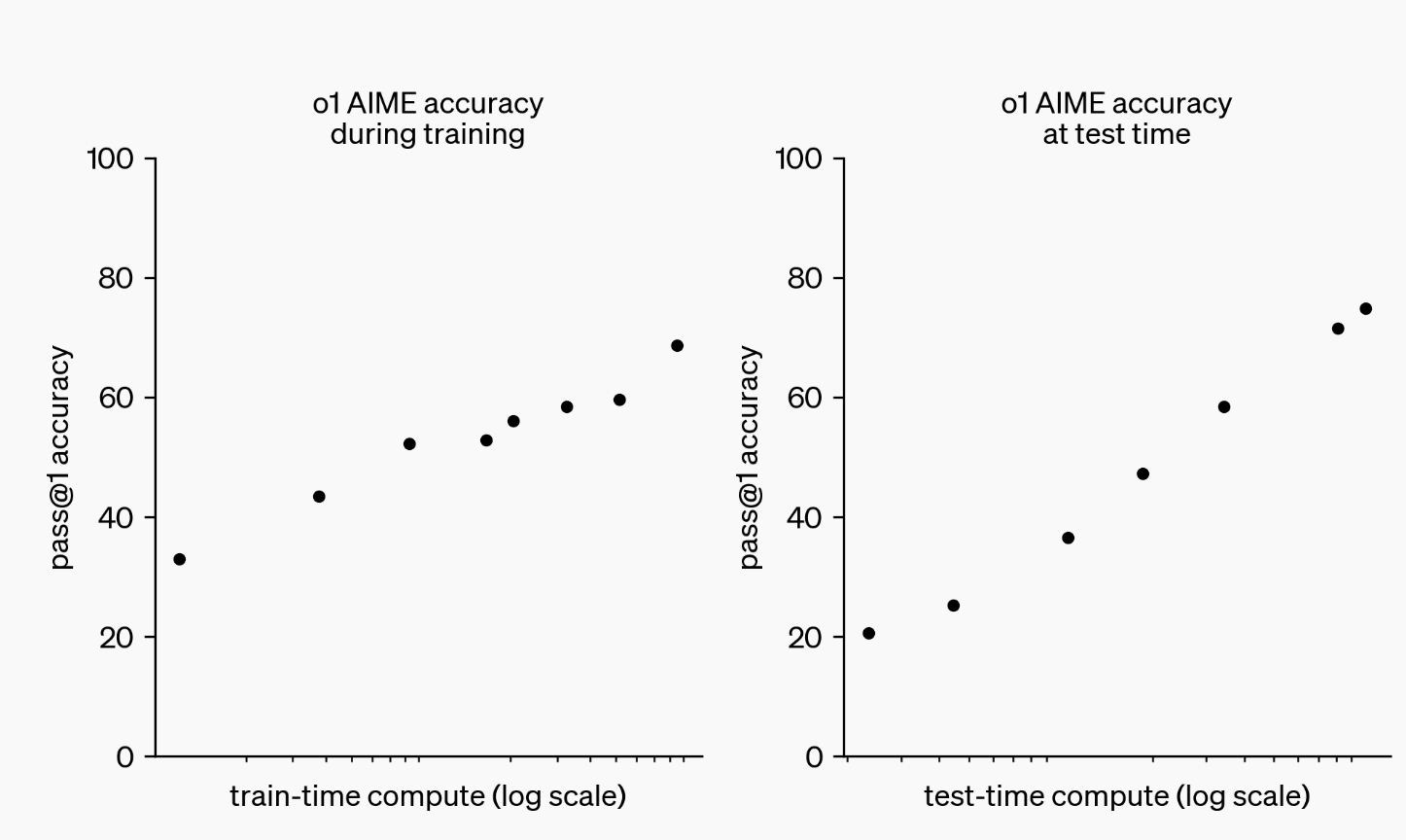
The chart somewhat gets at what I want to know, but doesn't answer it completely. How much additional inference compute would I need a 1e25 o1-like model to perform as well as a one shotted 1e26?
Additionally, for some x number of queries, what is the optimal ratio of compute to spend on training versus inference? How does that change for different values of x?
Are there any public attempts at estimating this stuff? If so, where can I read about it?
If someone wants to set up a figgy group to play, I'd love to join
I agree the conclusion isn't great!
Not so surprisingly, many people read the last section as an endorsement of some version of "RCTism", but it's not actually a view I endorse myself.
What I really wanted to get at in this post was just how pervasive priors are, and how difficult it is to see past them.
Just played through it tonight. This was my first D&D.Sci, found it quite difficult and learned a a few things while working on it.
Initially I tried to figure out the best counters and found a few patterns (flamethrowers were especially good against certain units). I then tried to look and adjust for any chronology, but after tinkering around for a while without getting anywhere I gave up on that. Eventually I just went with a pretty brainless ML approach.
I ended up sending squads for 5 and 6 which managed a 13.89% and 53.15% chance of surviving, I think it's good I'm not in charge of any soldiers in real life!
Overall I had good fun, and I'm looking forward to looking at the next one.
This wouldn't be the first time Deepmind pulled these shenanigans.
My impression of Deepmind is they like playing up the impressiveness of their achievements to give an impression of having 'solved' some issue, never saying anything technically false, while suspiciously leaving out relevant information and failing to do obvious tests of their models which would reveal a less impressive achievement.
For Alphastar they claimed 'grandmaster' level, but didn't show any easily available stats which would make it possible to verify. As someone who was in Grandmaster league at the time of it playing (might even have run into it on ladder, some of my teammates did), its play at best felt like low grandmaster to me.
At their event showing an earlier prototype off, they had one player (TLO) play their off-race with which he certainly was not at a grandmaster level. The pro player (Mana) playing their main race beat it at the event, when they had it play with the same limited camera access humans have. I don't remember all the details anymore, but I remember being continuously annoyed by suspicious omission after suspicious omission.
What annoys me most is that this still was a wildly impressive achievement! Just state in the paper: "we managed to reach grandmaster with one out of three factions" - Nobody has ever managed to create AI that played remotely as well as this!
Similarly Deepminds no-search chess engine is surely the furthest anyone has gotten without search. Even if it didn't quite make grandmaster, just say so!
if it makes it easier, I can add the questions to manifold if you provide a list of questions and resolution criteria.
thanks for pointing that out, I've added a note in the description
There's countries where cooperative firms are doing fine. Most of Denmark's supermarket chains are owned by the cooperative coop. Denmark's largest dairy producer Arla is a cooperative too. Both operate in a free market and are out-competing privately owned competitors.
Both also resort to many of the same dirty tricks traditionally structured firms are pulling. Arla, for example, has done tremendous harm to the plant-based industry through aggressive lobbying. Structuring firms as cooperatives doesn't magically make them aligned.
Cicero, as it is redirecting its entire fleet: 'What did you call me?'
Yeah, my original claim is wrong. It's clear that KataGo is just playing sub-optimally outside of distribution, rather than punished for playing optimally under a different ruleset than its being evaluated.
Actually this modification shouldn't matter. After looking into the definition of pass-alive, the dead stones in the adversarial attacks are clearly not pass-alive.
Under both unmodified and pass-alive modified tromp-taylor rules, KataGo would lose here and its surprising that self-play left such a weakness.
The authors are definitely onto something, and my original claim that the attack only works due to kataGo being trained under a different rule-set is incorrect.
No, the KataGo paper explicitly states at the start of page 4:
"Self play games used Tromp-Taylor rules [21] modified to not require capturing stones within pass-aliveterritory"
Had KataGo been trained on unmodified Tromp-Taylor rules, the attack would not have worked. The attack only works because the authors are having KataGo play under a different ruleset than it was trained on.
If I have the details right, I am honestly very confused about what the authors are trying to prove with this paper. Given their Twitter announcement claimed that the rulesets were the same my best guess is simply that it was an oversight on their part.
(EDIT: this modification doesn't matter, the authors are right, I am wrong. See my comment below)
As someone who plays a lot of go, this result looks very suspicious to me. To me it looks like the primary reason this attack works is due to an artifact of the automatic scoring system used in the attack. I don't think this attack would be replicable in other games, or even KataGo trained on a correct implementation.
In the example included on the website, KataGo (White) is passing because it correctly identifies the adversary's (Black) stones as dead meaning the entire outside would be its territory. Playing any move in KataGo's position would gain no points (and lose a point under Japanese scoring rules), so KataGo passes.
The game then ends and the automatic scoring system designates the outside as undecided, granting white 0 points and giving black the win.
If the match were to be played between two human players, they would have to agree whether the outside territory belongs to white or not. If black were to claim their outside stones are alive the game would continue until both players pass and agree about the status of all territory (see 'disputes' in the AGA ruleset).
But in the adversarial attack, the game ends after the pass and black gets the win due to the automatic scoring system deciding the outcome. But the only reason that KataGo passed is that it correctly inferred that it was in a winning position with no way to increase its winning probability! Claiming that to be a successful adversarial attack rings a bit hollow to me.
I wouldn't conclude anything from this attack, other than that Go is a game with a lot of edge-cases that need to be correctly handled.
EDIT: I just noticed the authors address this on the website, but I still think this significantly diminishes the 'impressiveness' of the adversarial attack. I don't know the exact ruleset KataGo is trained under, but unless it's the exact same as the ruleset used to evaluate the adversarial attack, the attack only works due to KataGo playing to win a different game than the adversary.
Evaluating the RCT is a chance to train the evaluation-muscle in a well-defined domain with feedback. I've generally found that the people who are best at evaluations in RCT'able domains, are better at evaluating the hard-to-evaluate claims as well.
Often the difficult to evaluate domains have ways of getting feedback, but if you're not in the habit of looking for it, you're less likely to find the creative ways to get data.
I think a much more common failure mode within this community, is that we get way overconfident beliefs about hard-to-evaluate domains, because there aren't many feedback loops and we aren't in the habit of looking for them.
Does anyone know of any zero-trust investigations on nuclear risk done in the EA/Rationalist community? Open phil has funded nuclear work, so they probably have an analysis somewhere that concluded it is a serious risk to civilization, but I haven't ever looked into these analyses.
For each tweet the post found arguing their point, I can find two arguing the opposite. Yes, in theory tweets are data points, but in practice the author just uses them to confirm his already held beliefs.
I don't think the real world is good enough either.
The fact that humans feel a strong sense of the tetris effect, suggest to me that the brain is constantly generating and training on synthetic data.
Another issue with greenwashing and safetywashing is that it gives people who earnestly care a false impression that they are meaningfully contributing.
Despite thousands of green initiatives, we're likely to blow way past the 1.5c mark because the far majority of those initiatives failed to address the core causes of climate change. Each plastic-straw ban and reusable diaper gives people an incorrect impression that they are doing something meaningful to improve the climate.
Similarly I worry that many people will convince themselves that they are doing something meaningful to improve AI Safety, but because they failed to address the core issues they end up contributing nothing. I am not saying this as a pure hypothetical, I think this is already happening to a large extent.
I quit a well paying job to become a policy trainee working with AI in the European Parliament because I was optimizing for "do something which looks like contributing to AI safety", with a strenuous at best model of how my work would actually lead to a world which creates safe AI. What horrified me during this was that a majority of people I spoke to in the field of AI policy seemed to be making similar errors as I was.
Many of us justify our work this by pointing out the second-order benefits such as "policy work is field-building", "This policy will help create better norms" or "I'm skilling up / getting myself to a place of influence", and while these second order effects are real and important, we should be very sceptical of interventions whose first-order effects aren't promising.
I apologize that this became a bit of a rant about AI Policy, but I have been annoyed with myself for making such basic errors and this post helped me put a word on what I was doing.
The primary question on my mind is something like this:
How much retraining is needed for Gato to learn a new task? Given a task, such as "Stack objects and compose a relevant poem" which combines skills it has already learned, yet is a fundamentally different task, does it quickly learn how to perform well at it?
If not, then it seems Deepmind 'merely' managed to get a single agent to do a bunch of tasks we were previously only able to do with multiple agents. If it is also quicker at learning new tasks in similar domains, than an agent trained solely to do it, then it seems like a big step towards general intelligence.
Hi Niplav, happy to hear you think that.
I just uploaded the pkl files that include the pandas dataframes for the metaculus questions and GPT's completions for the best performing prompt to github. Let me know if you need anything else :)
https://github.com/MperorM/gpt3-metaculus
I think wife rolls of the tongue uniquely well here due to 'wife' rhyming with 'life', creating the pun. Outside of that I don't buy it. In Denmark, wife-jokes are common despite wife being a two syllable word (kone) and husband-jokes are rare despite husband being a one syllable word (mand).
My model of why we see this has much more to do with gender norms and normalised misogyny than with catchiness of the words.
Good point, though I would prefer we name it Quality Adjusted Spouse Years :)
Fantastic to see this wonderful game be passed onto a new generation!
...
My analysis was from no exercise to regular high intensity exercise. There's probably an 80/20 in between, but I did not look into it.
For what it's worth hastily made a spreadsheet and found that regular heavy exercise was by far the largest improvement I could make to my life expectancy. Everything else paled in comparison. That said I only evaluated interventions that were relevant to me. If you smoke, I imagine quitting would score high as well.
For me, this perfectly hits the nail on the head.
This is a somewhat weird question, but like, how do I do that?
I've noticed multiple communities fall into the meta-trap, and even when members notice it can be difficult to escape. While the solution is simply to "stop being meta", that is much harder said than done.
When I noticed this happening in a community I am central in organizing I pushed back by bringing my own focus to output instead of process hoping others would follow suit. This has worked somewhat and we're definitely on a better track. I wonder what dynamics lead to this 'death by meta' syndrome, and if there is a cure.
Really cool concept of drumming with your feet while playing another instrument.
I think it would be really cool to experiment with different trigger sounds. The muscles in your foot severely limits the nuances available to play, and trying to imitate the sounds of a regular drum-set will not go over well.
I think it is possible to achieve much cooler playing, if you skip the idea of your pedals needing to imitate a drum-set entirely. Experiment with some 808 bass, electric kicks, etc.
Combining that with your great piano playing would create an entirely new feel of music, whereas it can easily end up sounding like a good pianist struggling to cooperate with a much worse drummer
I spent 5 minutes searching amazon.de for replacements to the various products recommended and my search came up empty.
Is there someone who has put together the needed list of bright lighting products on amazon.de? I tried doing it myself and ended up hopelessly confused. What I'm asking for is eg. two desk lamps and corresponding light bulbs that live up to the criteria.
I'll pay $50 to the charity of your choice, if I make a purchase based off your list.
And there doesn’t need to be an “overall goodness” of the job that would be anything else than just the combination of those two facts.
There needs to be an "overall goodness" that is exactly equal to the combination of those two facts. I really like the fundamental insight of the post. It's important to recognize that your mind wants to push your perception of the "overall goodness" to the extremes, and that you shouldn't let it do that.
If you now had to make a decision on whether to take the job, how would you use this electrifying zap help you make the decision?
I would strongly prefer a Lesswrong that is completely devoid of this.
Half the time it ends up in spiritual vaguery, of which there's already too much on Lesswrong. The other half ends up being toxic male-centric dating advice.
For those who, like me, have the attention span and intelligence of a door hinge the ELI5 edition is:
Outer alignment is trying to find a reward function that is aligned with our values (making it produce good stuff rather than paperclips)
Inner alignment is the act of ensuring our AI actually optimizes the reward function we specify.
An example of poor inner alignment would be us humans in the eyes of evolution. Instead of doing what evolution intended, we use contraceptives so we can have sex without procreation. If evolution had gotten its inner alignment right, we would care as much about spreading our genes as evolution does!
GPT-3's goal is to accurately predict a text sequence. Whether GPT-3 is capable of reason, or whether we can get it to explicitly reason is two different questions.
If I had you read Randall Munroe's book "what if" but tore out one page and asked you to predict what will be written as the answer, there's a few good strategies that come to mind.
One strategy would be to pick random verbs and nouns from previous questions and hope some of them will be relevant for this question as well. This strategy will certainly do better than if you picked your verbs and nouns from a dictionary.
Another, much better strategy, would be to think about the question and actually work out the answer. Your answer will most likely have many verbs and nouns in common, the numbers you supply will certainly be closer than if they were picked at random! The problem is that this requires actual intelligence, whereas the former strategy can be accomplished with very simple pattern matching.
To accurately predict certain sequences of text, you will get better performance if you're actually capable of reasoning. So the best version of GPT, needs to develop intelligence to get the best results.
I think it has, and is using varying degrees of reason to answer any question depending on how likely it thinks the intelligent answer will be to predict the sequence. This why it's difficult to wrangle reason out of GPT-3, it doesn't always think using reason will help it!
Similarly it can be difficult to wrangle intelligent reasoning out of humans, because that isn't what we're optimized to output. Like many critiques I see of GPT-3, I could criticize humans in a similar manner:
"I keep asking them for an intelligent answer to the dollar value of life, but they just keep telling me how all life has infinite value to signal their compassion."
Obviously humans are capable of answering the question, we behave every day as if life has a dollar value, but good luck getting us to explicitly admit that! Our intelligence is optimized towards all manner of things different from explicitly generating a correct answer.
So is GPT-3, and just like most humans debatably are intelligent, so is GPT-3.
I don't get the divestment argument, please help me understand why I'm wrong.
Here's how I understand it:
If Bob offers to pay Alice whatever Evil-Corp™ would have paid in stock dividends in exchange for what Alice would have paid for an Evil-Corp™ stock, Evil-Corp™ has to find another buyer. Since Alice was the buyer willing to pay the most, Evil-Corp™ now loses the difference between what Alice was willing to pay and the next-most willing buyer, Eve, is willing to pay.
Is that understanding correct, or am I missing something crucial?
If my understanding is right, then I don't understand why divestment works.
Lets assume I know Bob is doing this and I have the same risk-profile as Alice. I know the market price to be distorted, Evil-Corp™ stocks are being sold for less than what they're worth! After all, Alice deemed the stock to be worth more than what the stock was sold for. If it was not worth the price Alice was willing to pay for it, she wouldn't have offered to give that price.
Why wouldn't I just buy the stock from Eve offering to pay the price set by Alice?
As Benjamin Graham put it:
in the short run, the market is a voting machine; in the long run, the market a weighing machine.
I think that's a very fair way to put it, yes. One way this becomes very apparent, is that you can have a conversation with a starcraft player while he's playing. It will be clear the player is not paying you his full attention at particularly demanding moments, however.
Novel strategies are thought up inbetween games and refined through dozens of practice games. In the end you have a mental decision tree of how to respond to most situations that could arise. Without having played much chess, I imagine this is how people do chess openers do as well.
I considered using system 1 and 2 analogies, but because of certain resevations I have with the dichotomy, I opted not to. Basically I don't think you can cleanly divide human intelligence into those two catagories.
Ask a starcraft player why they made a certain maneuver and they will for the most part be able to tell you why he did it, despite never having thought the reason out loud until you asked. There is some deep strategical thinking being done at the instinctual level. This intelligence is just as real as system 2 intelligence and should not be dismissed as being merely reflexes.
My central critique is essentially of seeing starcraft 'mechanics' as unintelligent. Every small maneuver has a (most often implicit) reason for being made. Starcraft players are not limited by their physical capabilities nearly as much as they are limited by their ability to think fast enough. If we are interested in something other than what it looks like when someone can think at much higher speeds than humans, we should be picking another game than starcraft.
Before doing the whole EA thing, I played starcraft semi-professionally. I was consistently ranked grandmaster primarily making money from coaching players of all skill levels. I also co-authored a ML paper on starcraft II win prediction.
TL;DR: Alphastar shows us what it will look like when humans are beaten in completely fair fight.
I feel fundamentally confused about a lot of the discussion surrounding alphastar. The entire APM debate feels completely misguided to me and seems to be born out of fundamental misunderstandings of what it means to be good at starcraft.
Being skillful at starcraft, is the ability to compute which set of actions needs to be made and to do so very fast. A low skilled player, has to spend seconds figuring out their next move, whereas a pro player will determine it in milliseconds. This skill takes years to build, through mental caching of game states, so that the right moves become instinct and can be quickly computed without much mental effort.
As you showed clearly in the blogpost, Mana (or any other player) reach a much higher apm by mindlessly tabbing between control groups. You can click predetermined spots on the screen more than fast enough to control individual units.
We are physically capable of playing this fast, yet we do not.
The reason for this, is that in a real game my actions are limited by the speed it takes to figure them out. Likewise if you were to play speedchess against alpha-zero you will get creamed, not because you can't move the pieces fast enough, but because alpha-zero can calculate much better moves much faster than you can.
I am convinced a theoretical AI playing with a mouse and keyboard with the motorcontrols equivalent of a human, would largely be making the same 'inhuman' plays we are seeing currently. Difficulty of input is simply not the bottleneck.
Alphastar can only do its 'inhuman' moves because it's capable of calculating starcraft equations MUCH faster than humans are. Likewise, I can only do 'pro' moves because I'm capable of calculating starcraft equations much faster than an amateur.
You could argue that it's not showcasing the skills we're interested in, as it doesn't need to put the same emphasis on long-term planning and outsmarting its opponent, that equal human players have to. But that will also be the case if you put me against someone who's never played the game.
If what we really care about is proving that it can do long term thinking and planning in a game with a large actionspace and imperfect information, why choose starcraft? Why not select something like Frozen Synapse where the only way to win is to fundamentally understand these concepts?
The entire debate of 'fairness' seems somewhat misguided to me. Even if we found an apm measure that looks fair, I could move the goal post and point out that it makes selections and commands with perfect precision, whereas a human has to do it through a mouse and keyboard. There are moves that are extremely risky to pull off due to the difficulty of precisely clicking things. If we supplied it a virtual mouse to move arround, I could move the goal post again and complain how my eyes cannot take in the entire screen at once.
It's clear alphastar is not a fair fight, yet I think we got a very good look at what the fair fight eventually will look like. Alphastar fundamentally is what superhuman starcraft intelligence looks like (or at least it will be with more training) and it's abusing the exact skillset that make pro players stand out from amateurs in the first place.
"Science confirms video games are good" is essentially the same statement as "The bible confirms video games are bad" just with the authority changed. Luckily there remains a closer link between the authroity "Science" and truth than the authority "The bible" and truth so it's still an improvement.
Most people still update their worldview based upon whatever their tribe as agreed upon as their central authority. I'm having a hard time critisising people for doing this, however. This is something we all do! If I see Nick Bostrom writing something slightly crazy that I don't fully understand, I will still give credence to his view simply for being an authority in my worldview.
I feel like my criticism of people blindly believing anything labeled "science" is essentially criticising people for not being smart enough to choose better authorities, but that's a criticism that applies to everyone who doesn't have the smartest authority (who just so happens to be Nick Bostrom, so we're safe).
Maybe there's a point to be made about not blindly trusting any authority, but I'm not smart enough to make that point, so I'll default to someone who is.
GPT2, turned post-rationalist maybe!
I really like this line of thinking. I don't think it is necessarily opposed to the typical map-territory model, however.
You could in theory explain all there is to know about the territory with a single map, however that map would become really dense and hard to decipher. Instead having multiple maps, one with altitude, another with temperature, is instrumentally useful for best understanding the territory.
We cannot comprehend the entire territory at once, so it's instrumentally useful to view the world through different lenses and see what new information about the world the lens allows us to see.
You could then go the step further, which I think is what you're doing, and say that all that is meaningful to talk about are the different maps. But then I start becoming a bit confused about how you would evaluate any map's usefulness, because if you answered me: 'whether it's instrumentally useful or not', I'd question how you would evaluate if something is instrumentally useful when you can only judge something in terms of other maps.
Believing the notion that one can 'deconfuse' themself on any topic, is an archetypal mistake of the rationalist. Only in the spirit of all things that are essential to our personal understanding, can we expect our beliefs to conform to the normality of our existence. Asserting that one can know anything certain of the physical world is, by its definition, a foolhardy pursuit only someone with a narrow and immature understanding of physicality would consider meaningful.
Believing that any 'technique' could be used to train ones mind in the post-rationalistic school of thought, is to entirely miss the purpose of its existence. By its very nature, any technique applied would seize to have an effect, as any individual in applying the technique would become aware of the totality of the situation, and by doing so rejecting the message of the technique. The best any foundation could do is to become aware of its collective shadow and integrate it into the eternal subconscious that is its culture.
Only then can we achieve the post-rationalistic zeitgeist and rid ourselves of the collective cloak of delusion 'rationalism' has allowed us to wear!
EDIT: I may have nailed the impression too well