The unexpected difficulty of comparing AlphaStar to humans
post by Richard Korzekwa (Grothor) · 2019-09-18T02:20:01.292Z · LW · GW · 36 commentsContents
Why Starcraft is a Target for AI Research Timeline of Events How AlphaStar works January/February Impressions Survey Forecasts Speed Camera The Speed Controversy The Camera AlphaStar on the Ladder Discussion Acknowledgements Appendix I: Survey Results in Detail Questions About AlphaStar’s Performance How fair were the AlphaStar matches? Overall, how do you think AlphaStar’s performance compares to the best humans? How do you think AlphaStar’s micro compares to the best humans? Forecasting Questions Did you expect to see AlphaStar’s level of performance in a Starcraft II agent: How many years do you think it will be until we see (in public) an agent which only gets screen pixels as input, has human-level apm and reaction speed, and is very clearly better than the best humans? Questions About Relevant Considerations How important do you think the following were in determining the outcome of the AlphaStar vs MaNa matches? When thinking about AlphaStar as a benchmark for AI progress in general, how important do you think the following considerations are? Further questions Appendix II: APM Measurement Methodology None 36 comments
This is crossposted from the AI Impacts blog.
Artificial intelligence defeated a pair of professional Starcraft II players for the first time in December 2018. Although this was generally regarded as an impressive achievement, it quickly became clear that not everybody was satisfied with how the AI agent, called AlphaStar, interacted with the game, or how its creator, DeepMind, presented it. Many observers complained that, in spite of DeepMind’s claims that it performed at similar speeds to humans, AlphaStar was able to control the game with greater speed and accuracy than any human, and that this was the reason why it prevailed.
Although I think this story is mostly correct, I think it is harder than it looks to compare AlphaStar’s interaction with the game to that of humans, and to determine to what extent this mattered for the outcome of the matches. Merely comparing raw numbers for actions taken per minute (the usual metric for a player’s speed) does not tell the whole story, and appropriately taking into account mouse accuracy, the differences between combat actions and non-combat actions, and the control of the game’s “camera” turns out to be quite difficult.
Here, I begin with an overview of Starcraft II as a platform for AI research, a timeline of events leading up to AlphaStar’s success, and a brief description of how AlphaStar works. Next, I explain why measuring performance in Starcraft II is hard, show some analysis on the speed of both human and AI players, and offer some preliminary conclusions on how AlphaStar’s speed compares to humans. After this, I discuss the differences in how humans and AlphaStar “see” the game and the impact this has on performance. Finally, I give an update on DeepMind’s current experiments with Starcraft II and explain why I expect we will encounter similar difficulties when comparing human and AI performance in the future.
Why Starcraft is a Target for AI Research
Starcraft II has been a target for AI for several years, and some readers will recall that Starcraft II appeared on our 2016 expert survey. But there are many games and many AIs that play them, so it may not be obvious why Starcraft II is a target for research or why it is of interest to those of us that are trying to understand what is happening with AI.
For the most part, Starcraft II was chosen because it is popular, and it is difficult for AI. Starcraft II is a real time strategy game, and like similar games, it requires a variety of tasks: harvesting resources, constructing bases, researching technology, building armies, and attempting to destroy their opponent’s base are all part of the game. Playing it well requires balancing attention between many things at once: planning ahead, ensuring that one’s units1 are good counters for the enemy’s units, predicting opponents’ moves, and changing plans in response to new information. There are other aspects that make it difficult for AI in particular: it has imperfect information2, an extremely large action space, and takes place in real time. When humans play, they engage in long term planning, making the best use of their limited capacity for attention, and crafting ploys to deceive the other players.
The game’s popularity is important because it makes it a good source of extremely high human talent and increases the number of people that will intuitively understand how difficult the task is for a computer. Additionally, as a game that is designed to be suitable for high-level competition, the game is carefully balanced so that competition is fair, does not favor just one strategy3, and does not rely too heavily on luck.
Timeline of Events
To put AlphaStar’s performance in context, it helps to understand the timeline of events over the past few years:
November 2016: Blizzard and DeepMind announce they are launching a new project in Starcraft II AI
August 2017: DeepMind releases the Starcraft II API, a set of tools for interfacing AI with the game
March 2018: Oriol Vinyals gives an update, saying they’re making progress, but he doesn’t know if their agent will be able to beat the best human players
November 3, 2018: Oriol Vinyals gives another update at a Blizzcon panel, and shares a sequence of videos demonstrating AlphaStar's progress in learning the game, including leaning to win against the hardest built-in AI. When asked if they could play against it that day, he says "For us, it’s still a bit early in the research."
December 12, 2018: AlphaStar wins five straight matches against TLO, a professional Starcraft II player, who was playing as Protoss4, which is off-race for him. DeepMind keeps the matches secret.
December 19, 2018: AlphaStar, given an additional week of training time5, wins five consecutive Protoss vs Protoss matches vs MaNa, a pro Starcraft II player who is higher ranked than TLO and specializes in Protoss. DeepMind continues to keep the victories a secret.
January 24, 2019: DeepMind announces the successful test matches vs TLO and MaNa in a live video feed. MaNa plays a live match against a version of AlphaStar which had more constraints on how it “saw” the map, forcing it to interact with the game in a way more similar to humans6. AlphaStar loses when MaNa finds a way to exploit a blatant failure of the AI to manage its units sensibly. The replays of all the matches are released, and people start arguing7 about how (un)fair the matches were, whether AlphaStar is any good at making decisions, and how honest DeepMind was in presenting the results of the matches.
July 10, 2019: DeepMind and Blizzard announce that they will allow an experimental version of AlphaStar to play on the European ladder8, for players who opt in. The agent will play anonymously, so that most players will not know that they are playing against a computer. Over the following weeks, players attempt to discern whether they played against the agent, and some post replays of matches in which they believe they were matched with the agent.
How AlphaStar works
The best place to learn about AlphaStar is from DeepMind’s page about it. There are a few particular aspects of the AI that are worth keeping in mind:
It does not interact with the game like a human does: Humans interact with the game by looking at a screen, listening through headphones or speakers, and giving commands through a mouse and keyboard. AlphaStar is given a list of units or buildings and their attributes, which includes things like their location, how much damage they’ve taken, and which actions they’re able to take, and gives commands directly, using coordinates and unit identifiers. For most of the matches, it had access to information about anything that wouldn’t normally be hidden from a human player, without needing to control a “camera” that focuses on only one part of the map at a time. For the final match, it had a camera restriction similar to humans, though it still was not given screen pixels as input. Because it gives commands directly through the game, it does not need to use a mouse accurately or worry about tapping the wrong key by accident.
It is trained first by watching human matches, and then through self-play: The neural network is trained first on a large database of matches between humans, and then by playing against versions of itself.
It is a set of agents selected from a tournament: Hundreds of versions of the AI play against each other, and the ones that perform best are selected to play against human players. Each one has its own set of units that it is incentivized to use via reinforcement learning, so that they each play with different strategies. TLO and MaNa played against a total of 11 agents, all of which were selected from the same tournament, except the last one, which had been substantially modified. The agents that defeated MaNa had each played for hundreds of years in the virtual tournament9.
January/February Impressions Survey
Before deciding to focus my investigation on a comparison between human and AI performance in Starcraft II, I conducted an informal survey with my Facebook friends, my colleagues at AI Impacts, and a few people from an effective altruism Facebook group. I wanted to know what they were thinking about the matches in general, with an emphasis on which factors most contributed to the outcome of the matches. I’ve put details about my analysis and the full results of the survey in the appendix at the end of this article, but I’ll summarize a few major results here.
Forecasts
The timing and nature of AlphaStar’s success seems to have been mostly in line with people’s expectations, at least at the time of the announcement. Some respondents did not expect to see it for a year or two, but on average, AlphaStar was less than a year earlier than expected. It is probable that some respondents had been expecting it to take longer, but updated their predictions in 2016 after finding out that DeepMind was working on it. For future expectations, a majority of respondents expect to see an agent (not necessarily AlphaStar) that can beat the best humans without any of the current caveats within two years. In general, I do not think that I worded the forecasting questions carefully enough to infer very much from the answers given by survey respondents.
Some readers may be wondering how these survey results compare to those of our more careful 2016 survey, or how we should view the earlier survey results in light of MaNa and TLOs defeat at the hands of AlphaStar. The 2016 survey specified an agent that only receives a video of the screen, so that prediction has not yet resolved. But the median respondent assigned 50% probability of seeing such an agent that can defeat the top human players at least 50% of the time by 202110. I don’t personally know how hard it is to add in that capability, but my impression from speaking to people with greater machine learning expertise than mine is that this is not out of reach, so these predictions still seem reasonable, and are not generally in disagreement with the results from my informal survey.
Speed
Nearly everyone thought that AlphaStar was able to give commands faster and more accurately than humans, and that this advantage was an important factor in the outcome of the matches. I looked into this in more detail, and wrote about it in the next section.
Camera
As I mentioned in the description of AlphaStar, it does not see the game the same way that humans do. Its visual field covered the entire map, though its vision was still affected by the usual fog of war11. Survey respondents ranked this as an important factor in the outcome of the matches.
Given these results, I decided to look into the speed and camera issues in more detail.
The Speed Controversy
Starcraft is a game that rewards the ability to micromanage many things at once and give many commands in a short period of time. Players must simultaneously build their bases, manage resource collection, scout the map, research better technology, build individual units to create an army, and fight battles against other players. The combat is sufficiently fine grained that a player who is outnumbered or outgunned can often come out ahead by exerting better control over the units that make up their military forces, both on a group level and an individual level. For years, there have been simple Starcraft II bots that, although they cannot win a match against a highly-skilled human player, can do amazing things that humans can’t do, by controlling dozens of units individually during combat. In practice, human players are limited by how many actions they can take in a given amount of time, usually measured in actions per minute (APM). Although DeepMind imposed restrictions on how quickly AlphaStar could react to the game and how many actions it could take in a given amount of time, many people believe that the agent was sometimes able to act with superhuman speed and precision.
Here is a graph12 of the APM for MaNa (red) and AlphaStar (blue), through the second match, with five-second bins:
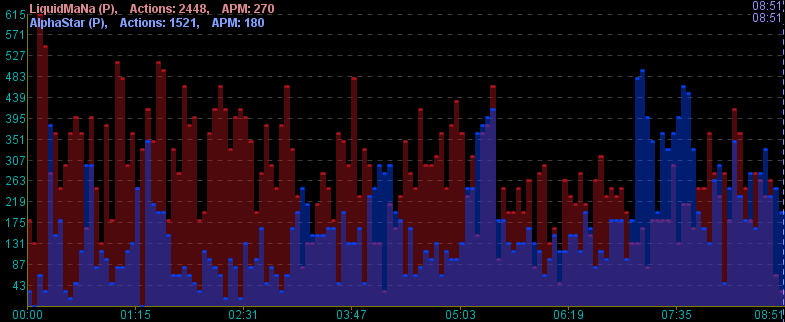 Actions per minute for MaNa (red) and AlphaStar (blue) in their second game. The horizontal axis is time, and the vertical axis is 5 second average APM.
Actions per minute for MaNa (red) and AlphaStar (blue) in their second game. The horizontal axis is time, and the vertical axis is 5 second average APM.
At first glance, this looks reasonably even. AlphaStar has both a lower average APM (180 vs MaNa’s 270) for the whole match, and a lower peak 5 second APM (495 vs Mana’s 615). This seems consistent with DeepMind’s claim that AlphaStar was restricted to human-level speed. But a more detailed look at which actions are actually taken during these peaks reveals some crucial differences. Here’s a sample of actions taken by each player during their peaks:
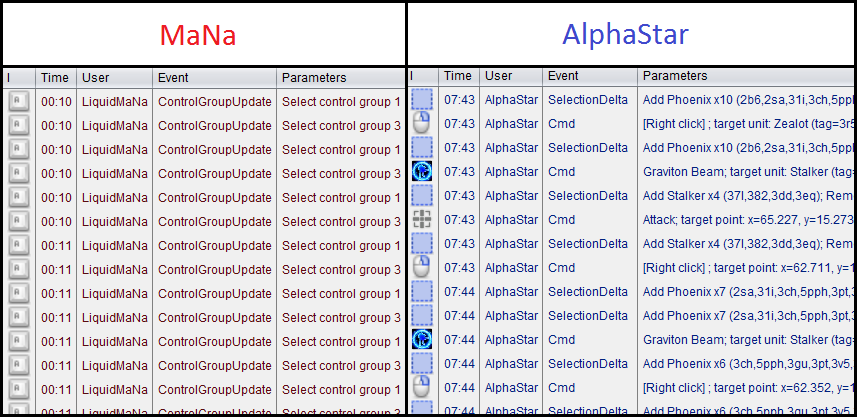 Lists of commands for MaNa and AlphaStar during each player’s peak APM for game 2
Lists of commands for MaNa and AlphaStar during each player’s peak APM for game 2
MaNa hit his APM peaks early in the game by using hot keys to twitchily switch back and forth between control groups13 for his workers and the main building in his base. I don’t know why he’s doing this: maybe to warm up his fingers (which apparently is a thing), as a way to watch two things at once, to keep himself occupied during the slow parts of the early game, or some other reason understood only by the kinds of people that can produce Starcraft commands faster than I can type. But it drives up his peak APM, and probably is not very important to how the game unfolds14. Here’s what MaNa’s peak APM looked like at the beginning of Game 2 (if you look at the bottom of the screen, you can see that the units he has selected switches back-and-forth between his workers and the building that he uses to make more workers):
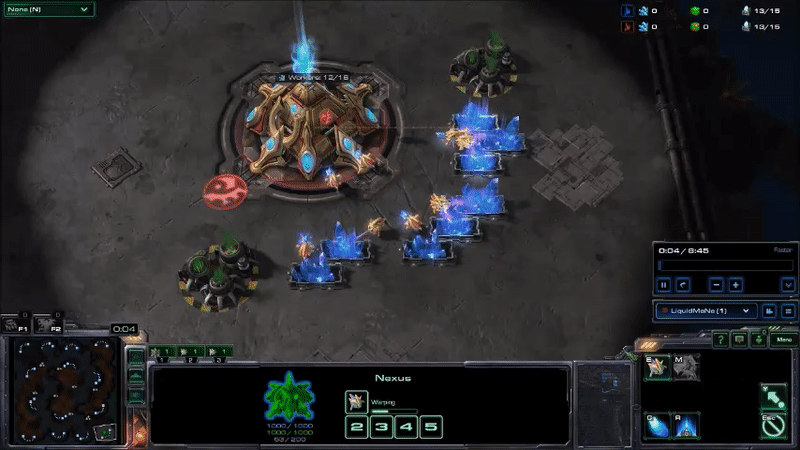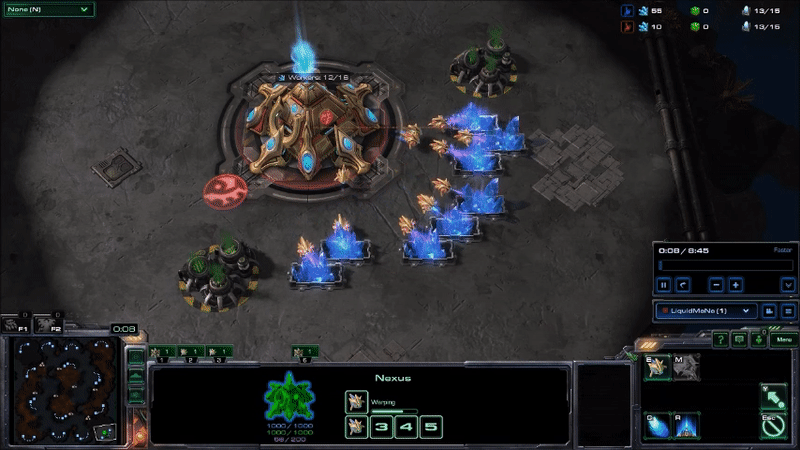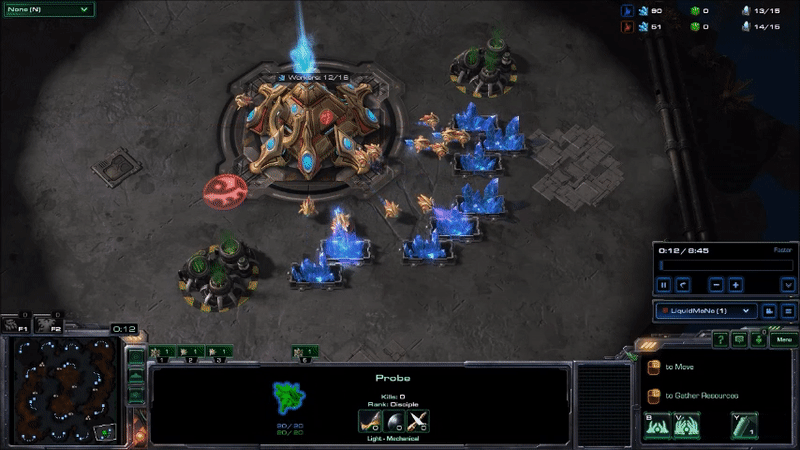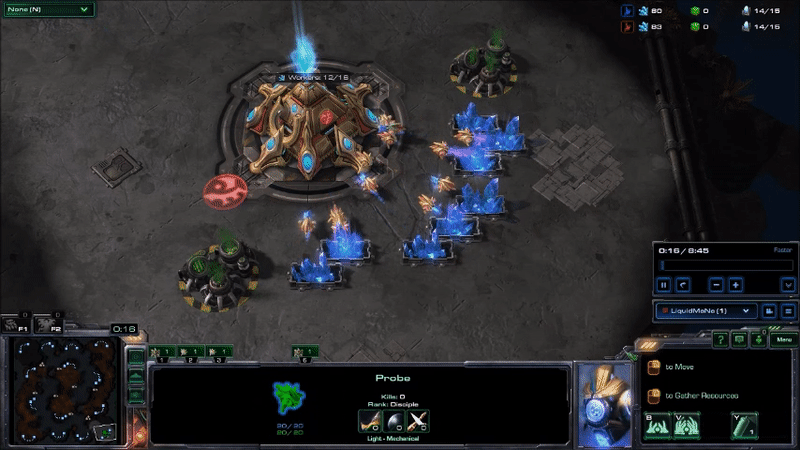 MaNa’s play during his peak APM for match 2. Most of his actions consist of switching between control groups without giving new commands to any units or buildings
MaNa’s play during his peak APM for match 2. Most of his actions consist of switching between control groups without giving new commands to any units or buildings
AlphaStar hit peak APM in combat. The agent seems to reserve a substantial portion of its limited actions budget until the critical moment when it can cash them in to eliminate enemy forces and gain an advantage. Here’s what that looked like near the end of game 2, when it won the engagement that probably won it the match (while still taking a few actions back at its base to keep its production going):
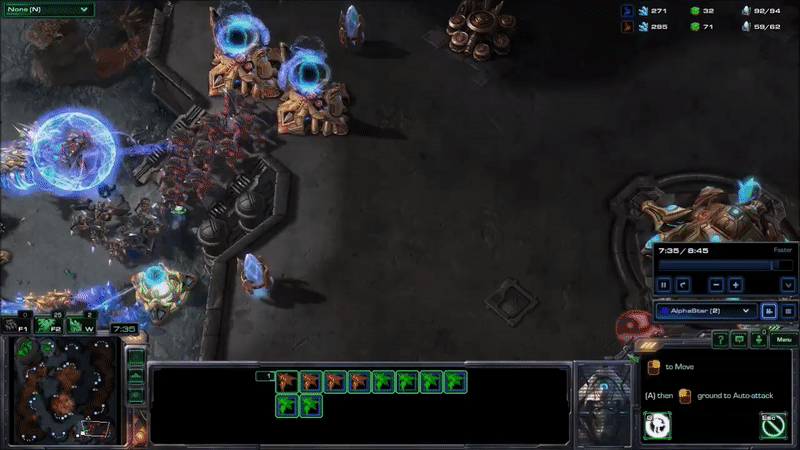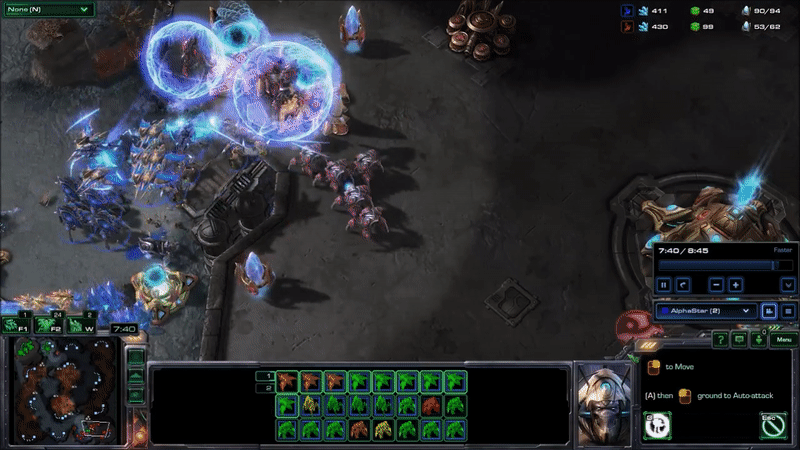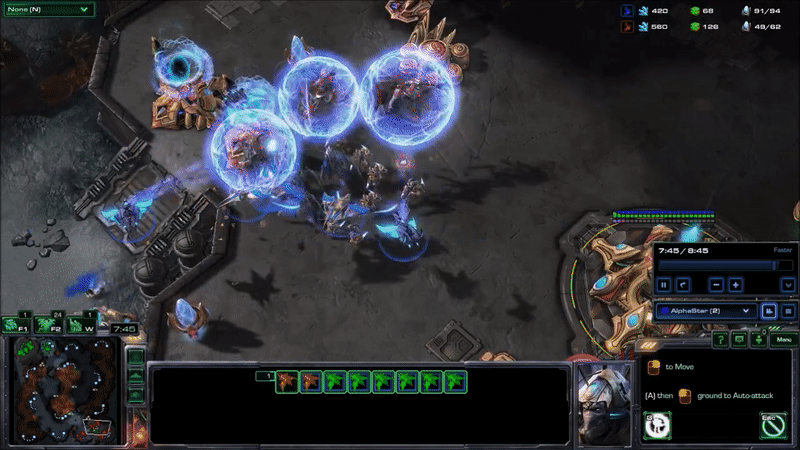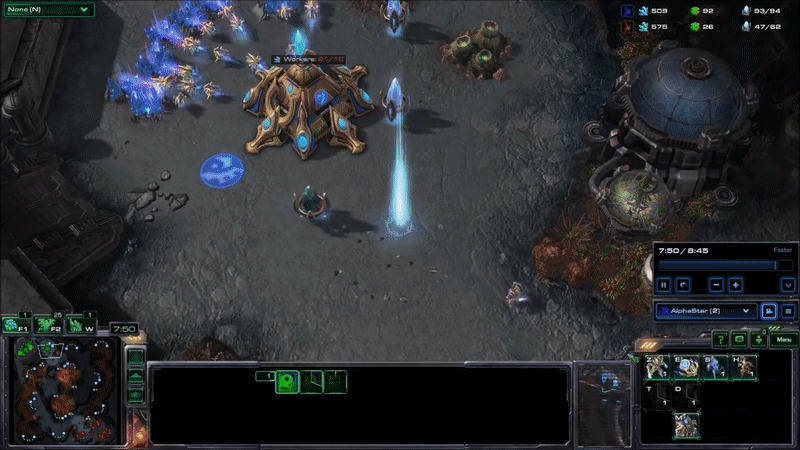 AlphaStar’s play during its peak APM in match 2. Most of its actions are related to combat, and require precise timing.
AlphaStar’s play during its peak APM in match 2. Most of its actions are related to combat, and require precise timing.
It may be hard to see what exactly is happening here for people who have not played the game. AlphaStar (blue) is using extremely fine-grained control of its units to defeat MaNa’s army (red) in an efficient way. This involves several different actions: Commanding units to move to different locations so they can make their way into his base while keeping them bunched up and avoiding spots that make them vulnerable, focusing fire on MaNa’s units to eliminate the most vulnerable ones first, using special abilities to lift MaNa’s units off the ground and disable them, and redirecting units to attack MaNa’s workers once a majority of MaNa’s military units are taken care of.
Given these differences between how MaNa and AlphaStar play, it seems clear that we can’t just use raw match-wide APM to compare the two, which most people paying attention seem to have noticed fairly quickly after the matches. The more difficult question is whether AlphaStar won primarily by playing with a level of speed and accuracy that humans are incapable of, or by playing better in other ways. Though based on the analysis that I am about to present I think the answer is probably that AlphaStar won through speed, I also think the question is harder to answer definitively than many critics of DeepMind are making it out to be.
A very fast human can average well over 300 APM for several minutes, with 5 second bursts at over 600 APM. Although these bursts are not always throwaway commands like those from the MaNa vs AlphaStar matches, they tend not to be commands that require highly accurate clicking, or rapid movement across the map. Take, for example, this 10 second, 600 APM peak from current top player Serral:
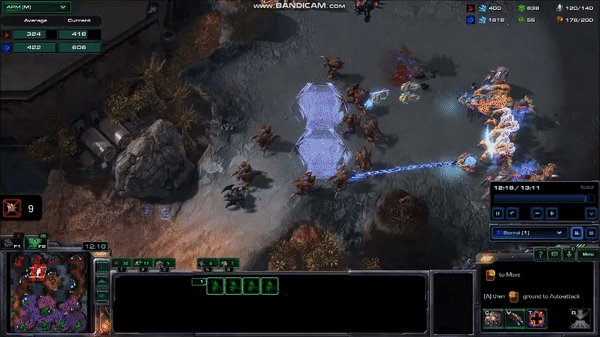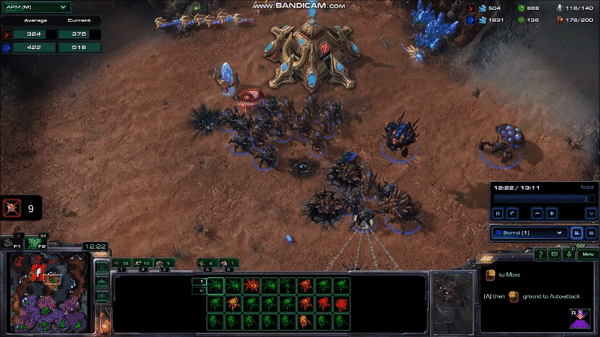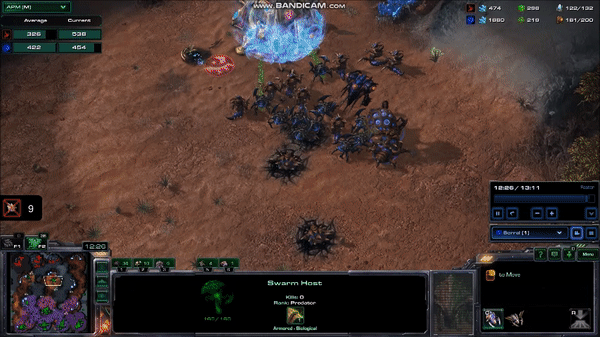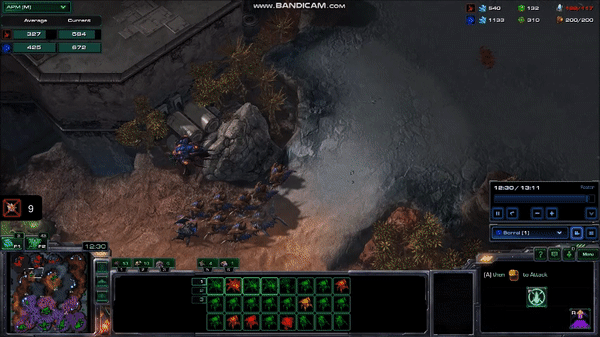 Serral’s play during a 10 second, 600 APM peak
Serral’s play during a 10 second, 600 APM peak
Here, Serral has just finished focusing on a pair of battles with the other player, and is taking care of business in his base, while still picking up some pieces on the battlefield. It might not be obvious why he is issuing so many commands during this time, so let’s look at the list of commands:
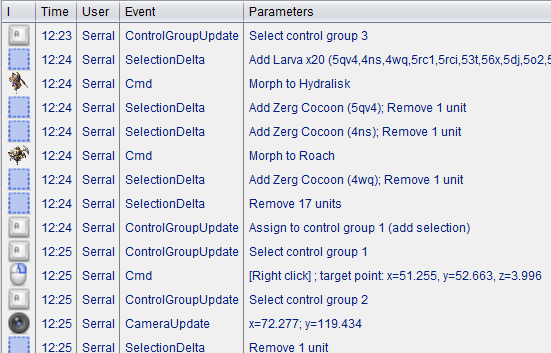
The lines that say “Morph to Hydralisk” and “Morph to Roach” represent a series of repeats of that command. For a human player, this is a matter of pressing the same hotkey many times, or even just holding down the key to give the command very rapidly15. You can see this in the gif by looking at the bottom center of the screen where he selects a bunch of worm-looking things and turns them all into a bunch of egg-looking things (it happens very quickly, so it can be easy to miss).
What Serral is doing here is difficult, and the ability to do it only comes with years of practice. But the raw numbers don’t tell the whole story. Taking 100 actions in 10 seconds is much easier when a third of those actions come from holding down a key for a few hundred milliseconds than when they each require a press of a different key or a precise mouse click. And this is without all the extraneous actions that humans often take (as we saw with MaNa).
Because it seems to be the case that peak human APM happens outside of combat, while AlphaStar’s wins happened during combat APM peaks, we need to do a more detailed analysis to determine the highest APM a human player can achieve during combat. To try to answer this question, I looked at approximately ten APM for each of the 5 games between AlphaStar and MaNa, as well as each of another 15 replays between professional Starcraft II players. The peaks were chosen so that roughly half were the largest peak at any time during the match and the rest were strictly during combat. My methodology for this is given in the appendix. Here are the results for just the human vs human matches:
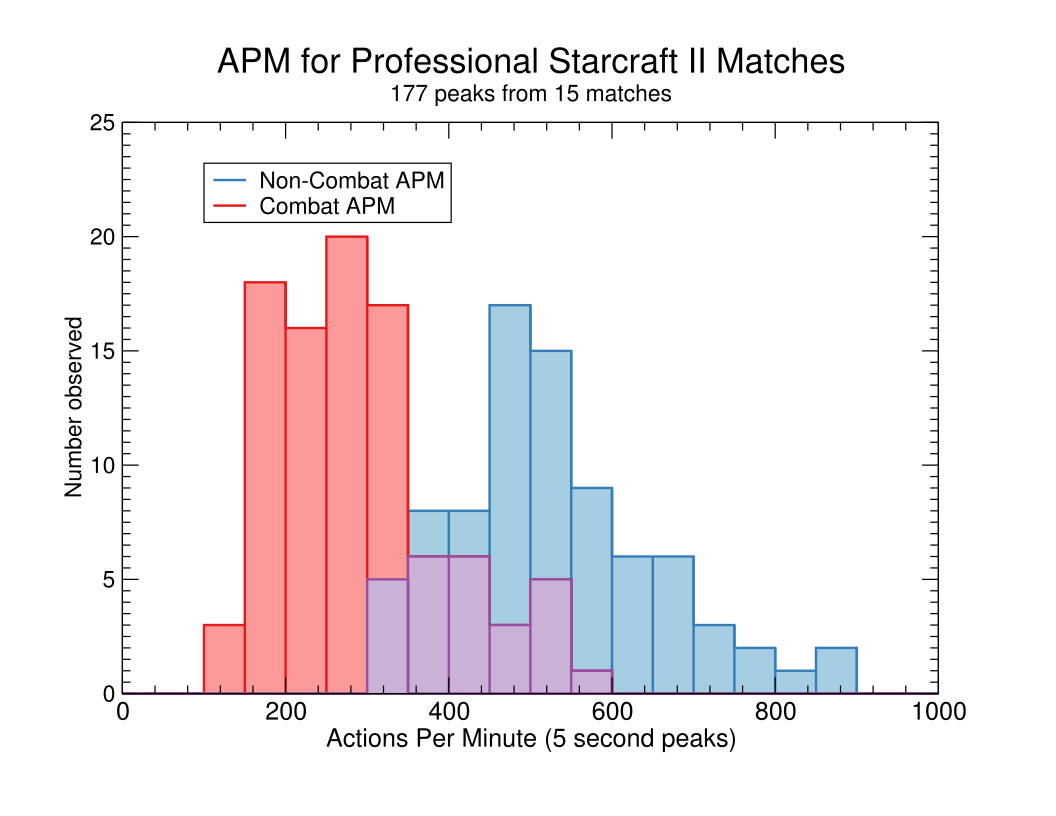 Histogram of 5-second APM peaks from analyzed matches between human professional players in a tournament setting The blue bars are peaks achieved outside of combat, while the red bars are those achieved during combat.
Histogram of 5-second APM peaks from analyzed matches between human professional players in a tournament setting The blue bars are peaks achieved outside of combat, while the red bars are those achieved during combat.
Provisionally, it looks like pro players frequently hit approximately 550 to 600 APM outside of combat before the distribution starts to fall off, and they peak at around 200-350 during combat, with a long right tail. As I was doing this, however, I found that all of the highest APM peaks had one thing in common with each other that they did not have in common with all of the lower APM peaks, which is that it was difficult to tell when a player’s actions are primarily combat-oriented commands, and when they are mixed in with bursts of commands for things like training units. In particular, I found that the combat situations with high APM tended to be similar to the Serral gif above, in that they involve spam clicking and actions related to the player’s economy and production, which was probably driving up the numbers. I give more details in the appendix, but I don’t think I can say with confidence that any players were achieving greater than 400-450 APM in combat, in the absence of spurious actions or macromanagement commands.
The more pertinent question might what the lowest APM is that a player can have while still succeeding at the highest level. Since we know that humans can succeed without exceeding this APM, it is not an unreasonable limitation to put on AlphaStar. The lowest peak APM in combat I saw for a winning player in my analysis was 215, though it could be that I missed a higher peak during combat in that same match.
Here is a histogram of AlphaStar’s combat APM:
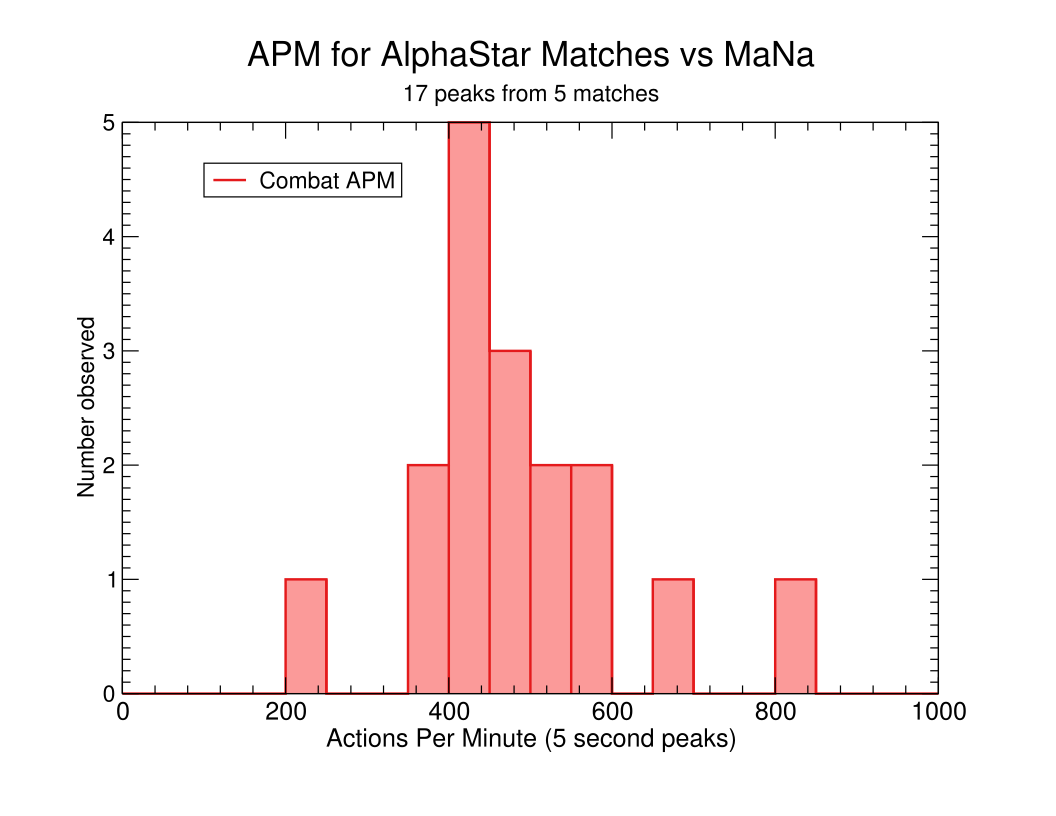
The smallest 5-second APM that AlphaStar needed to win a match against MaNa was just shy of 500. I found 14 cases in which the agent was able to average over 400 APM for 5 seconds in combat, and six times when the agent averaged over 500 APM for more than 5 seconds. This was done with perfect accuracy and no spam clicking or control group switching, so I think we can safely say that its play was faster than is required for a human to win a match in a professional tournament. Given that I found no cases where a human was clearly achieving this speed in combat, I think I can comfortably say that AlphaStar had a large enough speed advantage over MaNa to have substantially influenced the match.
It’s easy to get lost in numbers, so it’s good to take a step back and remind ourselves of the insane level of skill required to play Starcraft II professionally. The top professional players already play with what looks to me like superhuman speed, precision, and multitasking, so it is not surprising that the agent that can beat them is so fast. Some observers, especially those in the Starcraft community, have indicated that they will not be impressed until AI can beat humans at Starcraft II at sub-human APM. There is some extent to which speed can make up for poor strategy and good strategy can make up for a lack of speed, but it is not clear what the limits are on this trade-off. It may be very difficult to make an agent that can beat professional Starcraft II players while restricting its speed to an undisputedly human or sub-human level, or it may simply be a matter of a couple more weeks of training time.
The Camera
As I explained earlier, the agent interacts with the game differently than humans. As with other games, humans look at a screen to know what’s happening, use a mouse and keyboard to give commands, and need to move the game’s ‘camera’ to see different parts of the play area. With the exception of the final exhibition match against MaNa, AlphaStar was able to see the entire map at once (though much of it is concealed by the fog of war most of the time), and had no need to select units to get information about them. It’s unclear just how much of an advantage this was for the agent, but it seems likely that it was significant, if nothing else because it did not suffer from the APM overhead just to look around and get information from the game. Furthermore, seeing the entire map makes it easier to simultaneously control units across the map, which AlphaStar used to great effect in the first five matches against MaNa.
For the exhibition match in January, DeepMind trained a version of AlphaStar that had similar camera control to human players. Although the agent still saw the game in a way that was abstracted from the screen pixels that humans see, it only had access to about one screen’s worth of information at a time, and it needed to spend actions to look at different parts of the map. A further disadvantage was that this version of the agent only had half as much training time as the agents that beat MaNa.
Here are three factors that may have contributed to AlphaStar’s loss:
- The agent was unable to deal effectively with the added complication of controlling the camera
- The agent had insufficient training time
- The agent had easily exploitable flaws the whole time, and MaNa figured out how to use them in match 6
For the third factor, I mean that the agent had sufficiently many exploitable flaws that were obvious enough to human players that any skilled human player could find at least one during a small number of games. The best humans do not have a sufficient number of such flaws to influence the game with any regularity. Matches in professional tournaments are not won by causing the other player to make the same obvious-to-humans mistake over and over again.
I suspect that AlphaStar’s loss in January is mainly due to the first two factors. In support of 1, AlphaStar seemed less able to simultaneously deal with things happening on opposite sides of the map, and less willing to split its forces, which could plausibly be related to an inability to simultaneously look at distant parts of the map. It’s not just that the agent had to move the camera to give commands on other parts of the map. The agent had to remember what was going on globally, rather than being able to see it all the time. In support of 2, the agent that MaNa defeated had only as much training time as the agents that went up against TLO, and those agents lost to the agents that defeated MaNa 94% of the time during training16.
Still, it is hard to dismiss the third factor. One way in which an agent can improve through training is to encounter tactics that it has not seen before, so that it can react well if it sees it in the future. But the tactics that it encounters are only those that another agent employed, and without seeing the agents during training, it is hard to know if any of them learned the harassment tactics that MaNa used in game 6, so it is hard to know if the agents that defeated MaNa were susceptible to the exploit that he used to defeat the last agent. So far, the evidence from DeepMind’s more recent experiment pitting AlphaStar against the broader Starcraft community (which I will go into in the next section) suggests that the agents do not tend to learn defenses to these types of exploits, though it is hard to say if this is a general problem or just one associated with low training time or particular kinds of training data.
AlphaStar on the Ladder
For the past couple months, as of this writing, skilled European players have had the opportunity to play against AlphaStar as part of the usual system for matching players with those of similar skill. For the version of AlphaStar that plays on the European ladder, DeepMind claims to have made changes that address the camera and action speed complaints from the January matches. The agent needs to control the camera, and they say they have placed restrictions on AlphaStar’s performance in consultation with pro players, particularly the maximum actions per minute and per second that the agent can make. I will be curious to see what numbers they arrive at for this. If this was done in an iterative way, such that pro players were allowed to see the agent play or to play against it, I expect they were able to arrive at a good constraint. Given the difficulty that I had with arriving at a good value for a combat APM restriction, I’m less confident that they would get a good value just by thinking about it, though if they were sufficiently conservative, they probably did alright.
Another reason to expect a realistic APM constraint is that DeepMind wanted to run the European ladder matches as a blind study, in which the human players did not know they were playing against an AI. If the agent were to play with the superhuman speed and accuracy that AlphaStar did in January, it would likely give it away and spoil the experiment.
Although it is unclear that any players were able to tell they were playing against an AI during their match, it does seem that some were able to figure it out after the fact. One example comes from Lowko, who is a Dutch player who streams and does commentary for games. During a stream of a ladder match in Starcraft II, he noticed the player was doing some strange things near the end of the match, like lifting their buildings17 when the match had clearly been lost, and air-dropping workers into Lowko’s base to kill units. Lowko did eventually win the match. Afterward, he was able to view the replay from the match and see that the player he had defeated did some very strange things throughout the entire match, the most notable of which was how the player controlled their units. The player used no control groups at all, which is, as far as I know, not something anybody does at high-level play18. There were many other quirks, which he describes in his entertaining video, which I highly recommend to anyone who is interested.
Other players have released replay files from matches against players they believed were AlphaStar, and they show the same lack of control groups. This is great, because it means we can get a sense of what the new APM restriction is on AlphaStar. There are now dozens of replay files from players who claim to have played against the AI. Although I have not done the level of analysis that I did with the matches in the APM section, it seems clear that they have drastically lowered the APM cap, with the matches I have looked at topping out at 380 APM peaks, which did not even occur in combat.
It seems to be the case that DeepMind has brought the agent’s interaction with the game more in line with human capability, but we will probably need to wait until they release the details of the experiment before we can say for sure.
Another notable aspect of the matches that people are sharing is that their opponent will do strange things that human players, especially skilled human players almost never do, most of which are detrimental to their success. For example, they will construct buildings that block them into their own base, crowd their units into a dangerous bottleneck to get to a cleverly-placed enemy unit, and fail to change tactics when their current strategy is not working. These are all the types of flaws that are well-known to exist in game-playing AI going back to much older games, including the original Starcraft, and they are similar to the flaw that MaNa exploited to defeat AlphaStar in game 6.
All in all, the agents that humans are uncovering seem to be capable, but not superhuman. Early on, the accounts that were identified as likely candidates for being AlphaStar were winning about 90-95% of their matches on the ladder, achieving Grandmaster rank, which is reserved for only the top 200 players in each region. I have not been able to conduct a careful investigation to determine the win rate or Elo rating for the agents. However, based on the videos and replays that have been released, plausible claims from reddit users, and my own recollection of the records for the players that seemed likely to be AlphaStar19, a good estimate is that they were winning a majority of matches among Grandmaster players, but did not achieve an Elo rating that would suggest a favorable outcome in a rematch vs TLO20.
As with AlphaStar’s January loss, it is hard to say if this is the result of insufficient training time, additional restrictions on camera control and APM, or if the flaws are a deeper, harder to solve problem for AI. It may seem unreasonable to chalk this up to insufficient training time given that it has been several months since the matches in December and January, but it helps to keep in mind that we do not yet know what DeepMind’s research goals are. It is not hard to imagine that their goals are based around sample efficiency or some other aspect of AI research that requires such restrictions. As with the APM restrictions, we should learn more when we get results published by DeepMind.
Discussion
I have been focusing on what many onlookers have been calling a lack of “fairness” of the matches, which seems to come from a sentiment that the AI did not defeat the best humans on human terms. I think this is a reasonable concern; if we’re trying to understand how AI is progressing, one of our main interests is when it will catch up with us, so we want to compare its performance to ours. Since we already know that computers can do the things they’re able to do faster than we can do them, we should be less interested in artificial intelligence that can do things better than we can by being faster or by keeping track of more things at once. We are more interested in AI that can make better decisions than we can.
Going into this project, I thought that the disagreements surrounding the fairness of the matches were due to a lack of careful analysis, and I expected it to be very easy to evaluate AlphaStar’s performance in comparison to human-level performance. After all, the replay files are just lists of commands, and when we run them through the game engine, we can easily see the outcome of those commands. But it turned out to be harder than I had expected. Separating careful, necessary combat actions (like targeting a particular enemy unit) from important but less precise actions (like training new units) from extraneous, unnecessary actions (like spam clicks) turned out to be surprisingly difficult. I expect if I were to spend a few months learning a lot more about how the game is played and writing my own software tools to analyze replay files, I could get closer to a definitive answer, but I still expect there would be some uncertainty surrounding what actually constitutes human performance.
It is unclear to me where this leaves us. AlphaStar is an impressive achievement, even with the speed and camera advantages. I am excited to see the results of DeepMind’s latest experiment on the ladder, and I expect they will have satisfied most critics, at least in terms of the agent’s speed. But I do not expect it to become any easier to compare humans to AI in the future. If this sort of analysis is hard in the context of a game where we have access to all the inputs and outputs, we should expect it to be even harder once we’re looking at tasks for which success is less clear cut or for which the AI’s output is harder to objectively compare to humans. This includes some of the major targets for AI research in the near future. Driving a car does not have a simple win-loss condition, and novel writing does not have clear metrics for what good performance looks like.
The answer may be that, if we want to learn things from future successes or failures of AI, we need to worry less about making direct comparisons between human performance and AI performance, and keep watching the broad strokes of what’s going on. From AlphaStar, we’ve learned that one of two things is true: Either AI can do long-term planning, solve basic game theory problems, balance different priorities against each other, and develop tactics that work, or that there are tasks which seem at first to require all of these things but did not, at least not at a high level.
Acknowledgements
Thanks to Gillian Ring for lending her expertise in e-sports and for helping me understanding some of the nuances of the game. Thanks to users of the Starcraft subreddit for helping me track down some of the fastest players in the world. And thanks to Blizzard and DeepMind for making the AlphaStar match replays available to the public.
All mistakes are my own, and should be pointed out to me via email at rick@aiimpacts.org.
Appendix I: Survey Results in Detail
I received a total of 22 submissions, which wasn’t bad, given its length. Two respondents failed to correctly answer the question designed to filter out people that are goofing off or not paying attention, leaving 20 useful responses. Five people who filled out the survey were affiliated in some way with AI Impacts. Here are the responses for respondents’ self-reported level of expertise in Starcraft II and artificial intelligence:
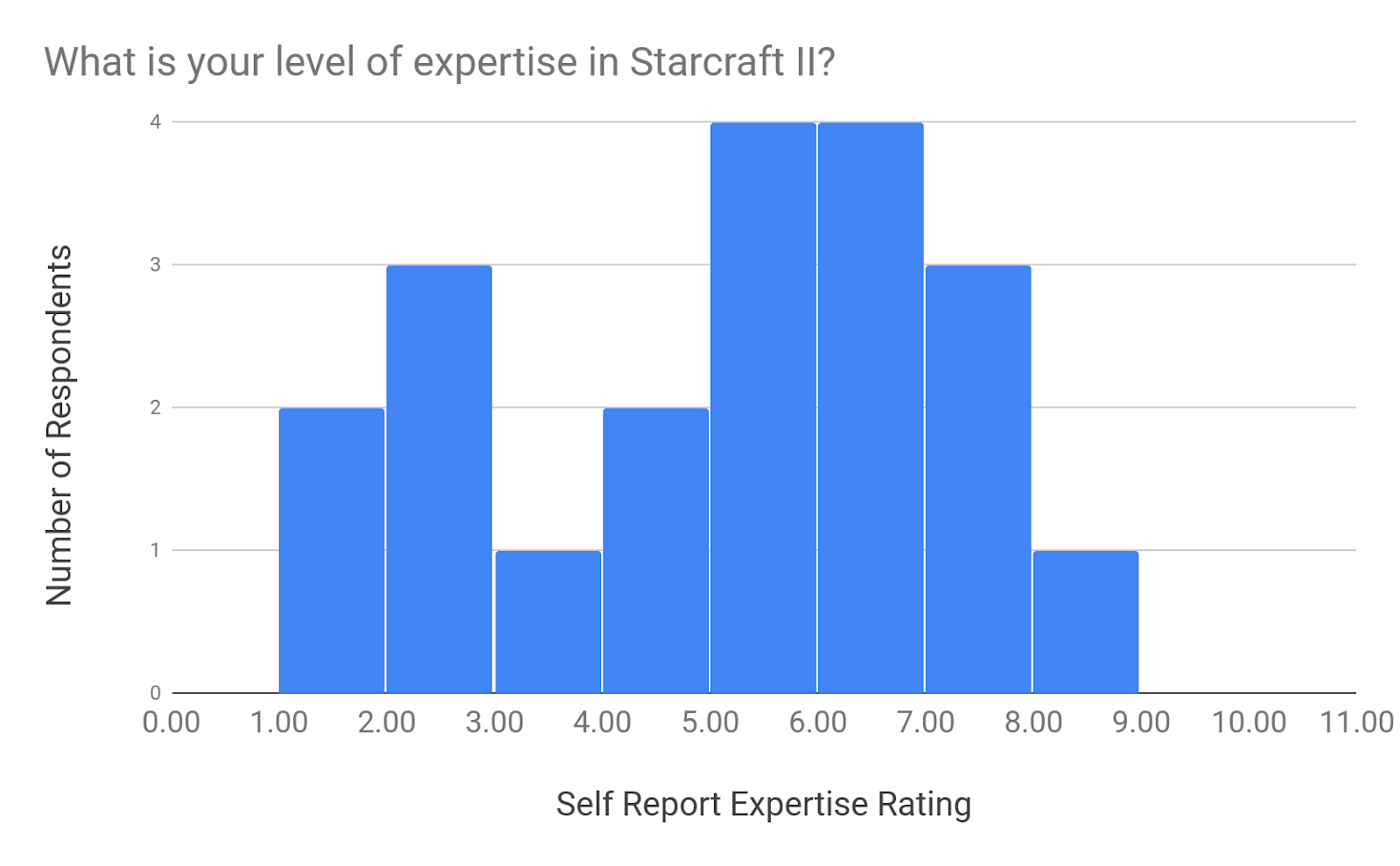
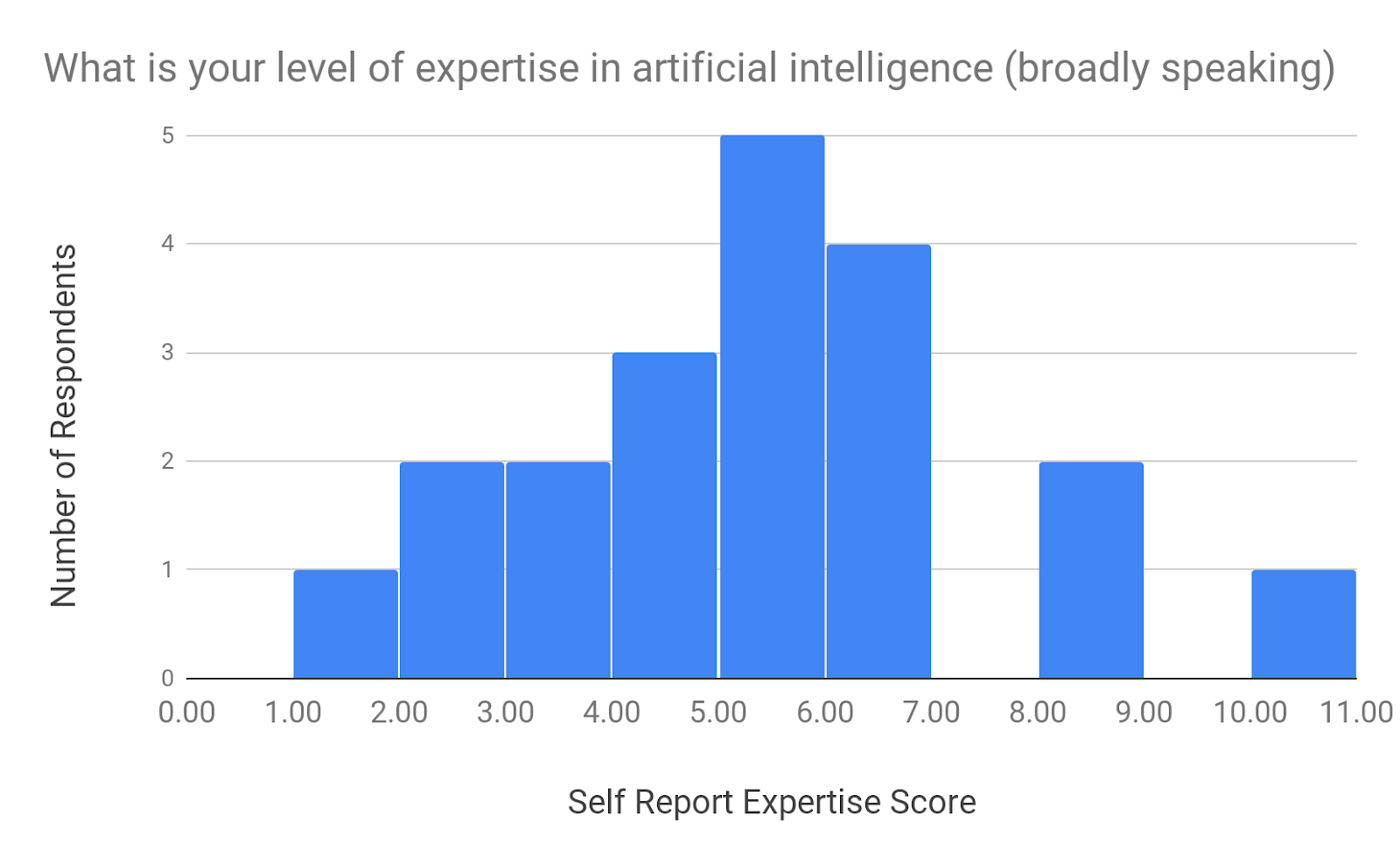
Survey respondents’ mean expertise rating was 4.6/10 for Starcraft II and 4.9/10 for AI.
Questions About AlphaStar’s Performance
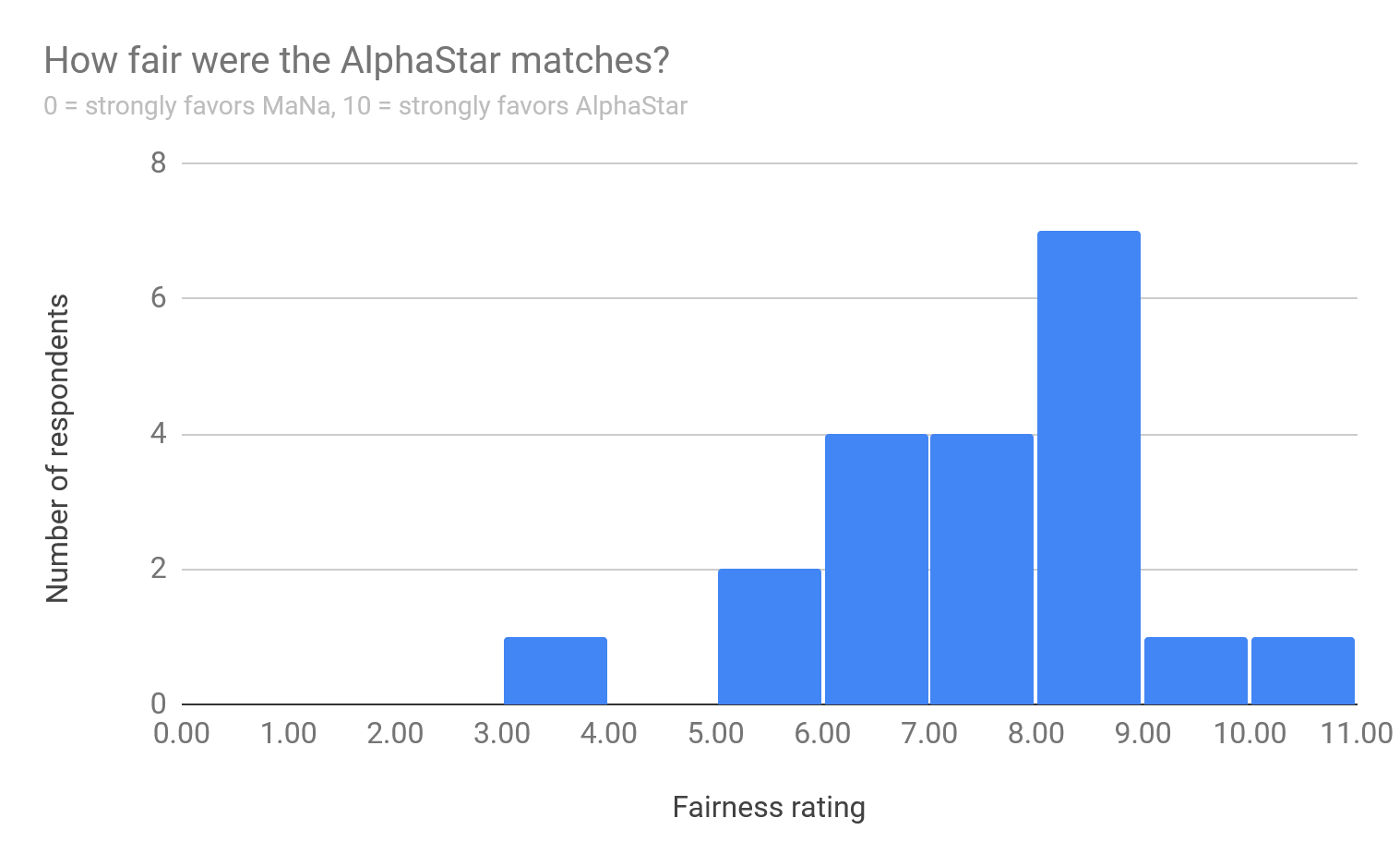
How fair were the AlphaStar matches?
For this one, it seems easiest to show a screenshot from the survey:

The results from this indicated that people thought the match was unfair and favored AlphaStar:
I asked respondents to rate AlphaStar’s overall performance, as well as its “micro” and “macro”. The term “micro” is used to refer to a player’s ability to control units in combat, and is greatly improved by speed. There seems to have been some misunderstanding about how to use the word “macro”. Based on comments from respondents and looking around to see how people use the term on the Internet, it seems that that there are at least three somewhat distinct ways that people use the phrase, and I did not clarify which I meant, so I’ve discarded the results from that question.
For the next two questions, the scale ranges from 0 to 10, with 0 labeled “AlphaStar is much worse” and 10 labeled “AlphaStar is much better”
Overall, how do you think AlphaStar’s performance compares to the best humans?
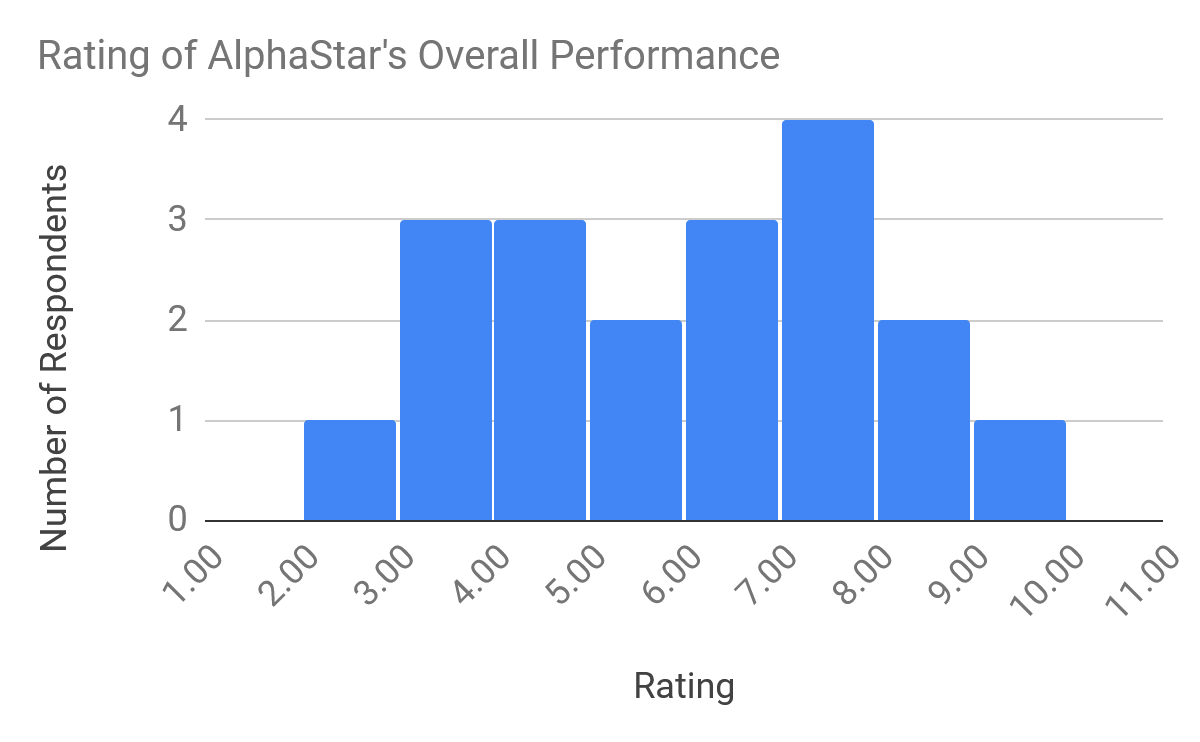
I found these results interesting, because AlphaStar was able to consistently defeat professional players, so some survey respondents felt the outcome alone was not enough to rate it as at least as good as the best humans.
How do you think AlphaStar’s micro compares to the best humans?
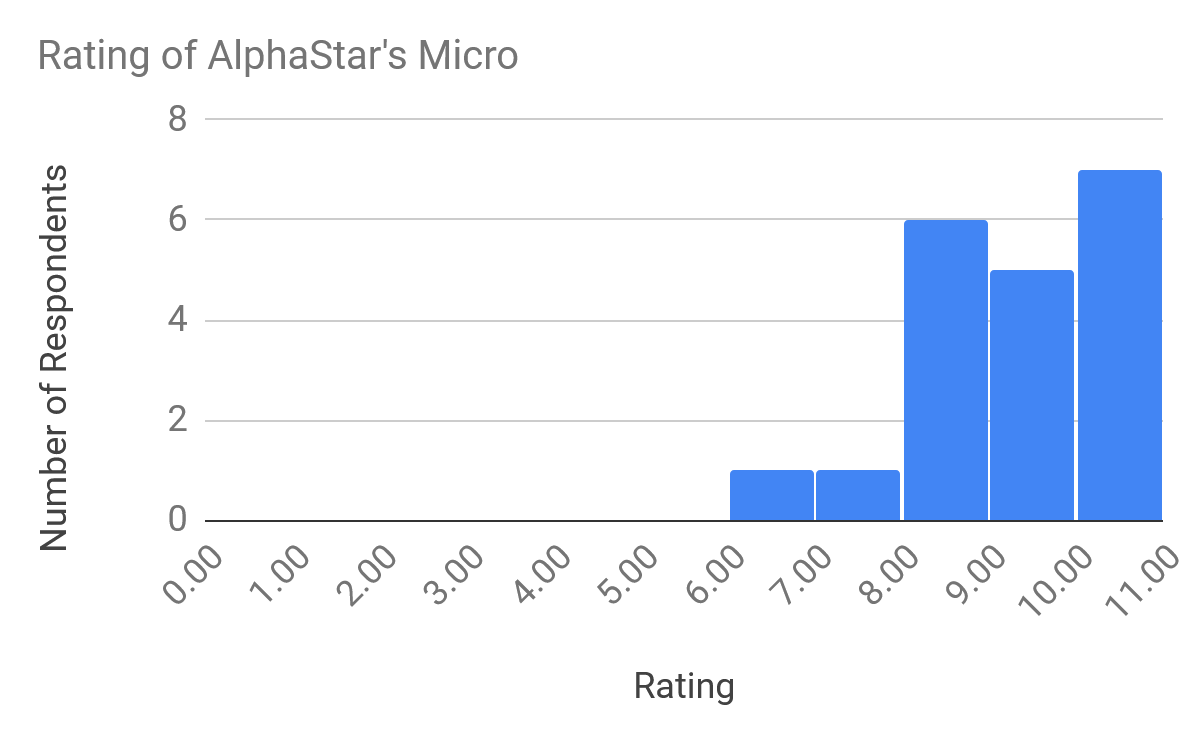
Survey respondents unanimously reported that they thought AlphaStar’s combat micromanagement was an important factor in the outcome of the matches.
Forecasting Questions
Respondents were split on whether they expected to see AlphaStar’s level of Starcraft II performance by this time:
Did you expect to see AlphaStar’s level of performance in a Starcraft II agent:
| Before Now | 1 |
| Around this time | 8 |
| Later than now | 7 |
| I had no expectation either way | 4 |
Respondents who indicated that they expected it sooner or later than now were also asked by how many years their expectation differed from reality. If we assign negative numbers to “before now”, positive numbers to “Later than now”, zero to “Around this time”, ignore those with no expectation, and weight responses by level of expertise, we find respondents’ mean expectation was just 9 months later the announcement, and the median respondent expected to see it around this time. Here is a histogram of these results, without expertise weighting:
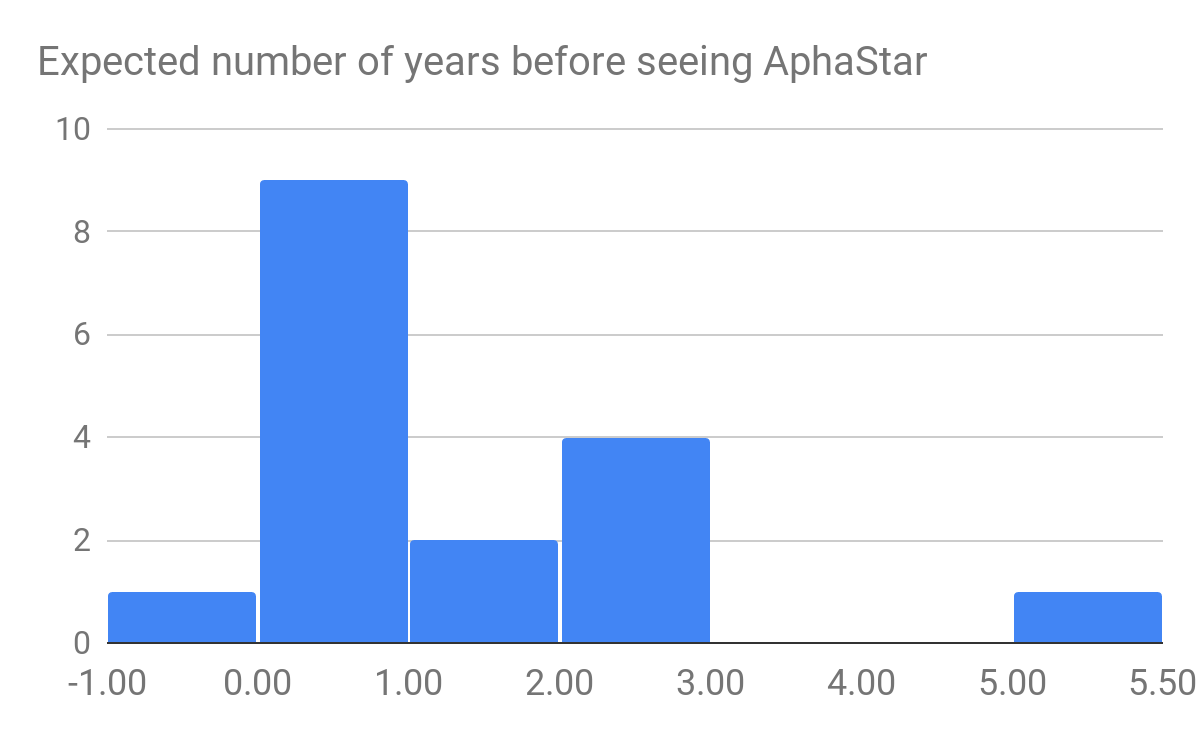
These results do not generally indicate too much surprise about seeing a Starcraft II agent of AlphaStar’s ability now.
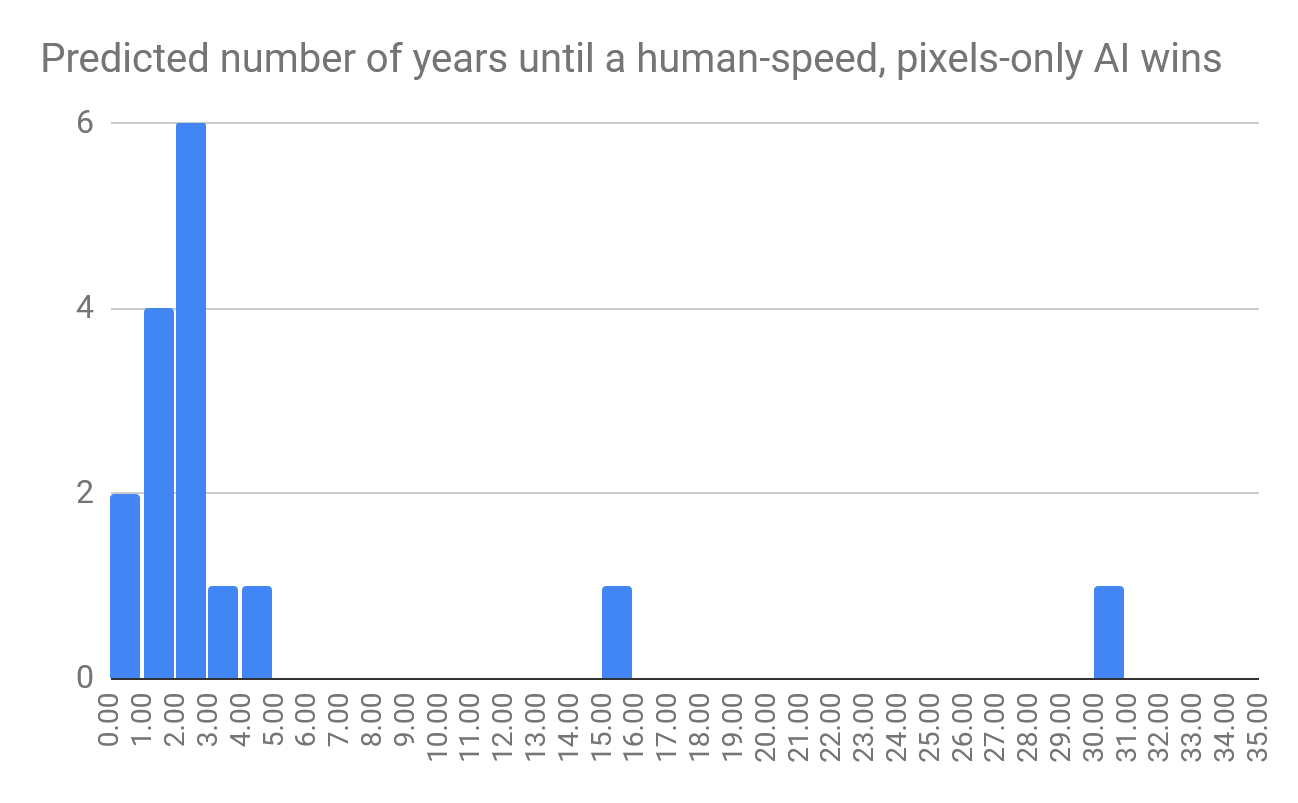
How many years do you think it will be until we see (in public) an agent which only gets screen pixels as input, has human-level apm and reaction speed, and is very clearly better than the best humans?
This question was intended to outline an AI that would satisfy almost anybody that Starcraft II is a solved game, such that AI is clearly better than humans, and not for “boring” reasons like superior speed. Most survey respondents expected to see such an agent in two-ish years, with a few a little longer, and two that expected it to take much longer. Respondents had a median prediction of two years and an expertise-weighted mean prediction of a little less than four years.
Questions About Relevant Considerations
How important do you think the following were in determining the outcome of the AlphaStar vs MaNa matches?
I listed 12 possible considerations to be rated in importance, from 1 to 5, with 1 being “not at all important” and 5 being “extremely important”. The expertise weighted mean for each question is given below:
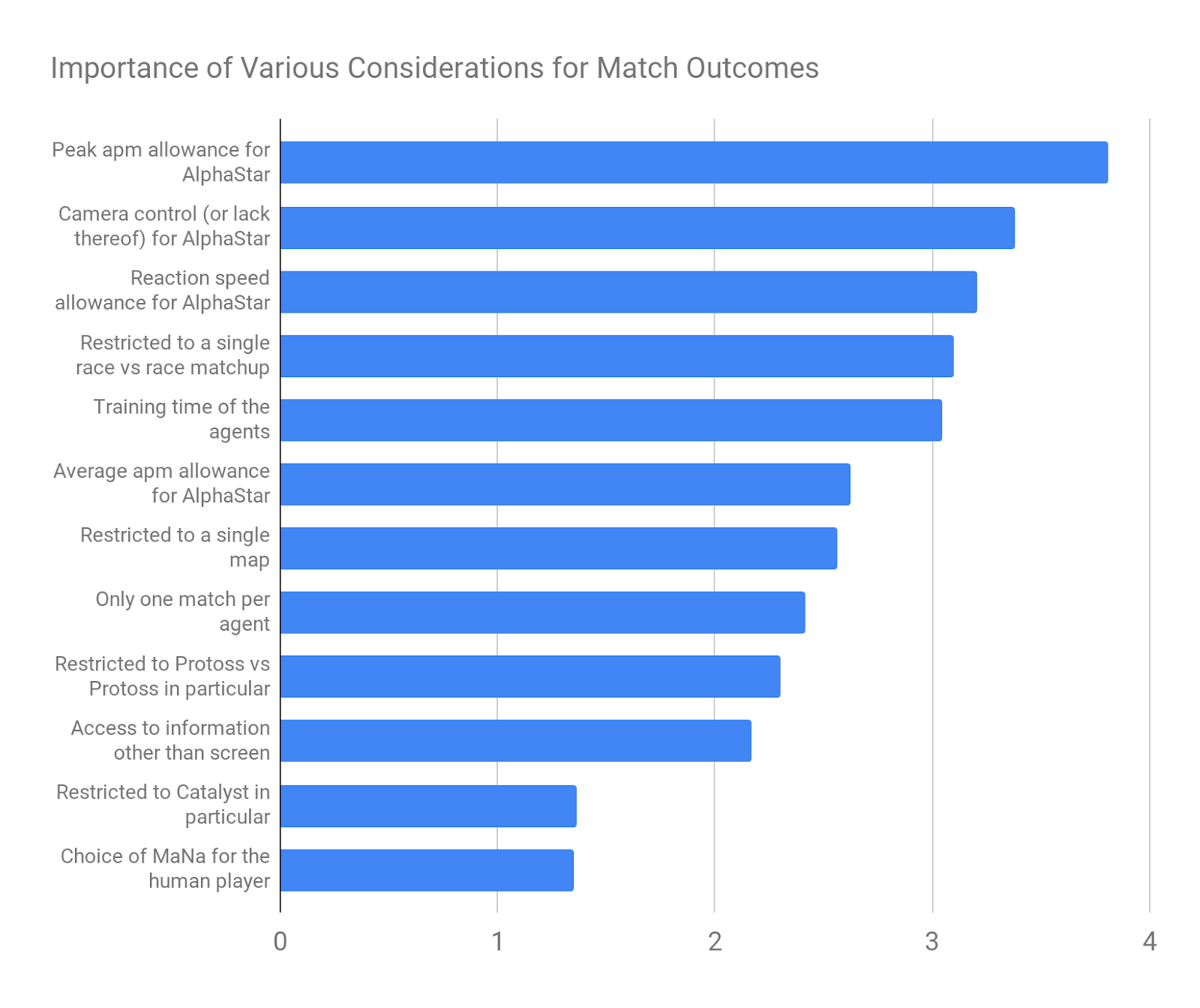
Respondents rated AlphaStar’s peak APM and camera control as the two most important factors in determining the outcome of the matches, and the particular choice of map and professional player as the two least important considerations.
When thinking about AlphaStar as a benchmark for AI progress in general, how important do you think the following considerations are?
Again, respondents rated a series of considerations by importance, this time for thinking about AlphaStar in a broader context. This included all of the considerations from the previous question, plus several others. Here are the results, again with expertise weighted averaging.
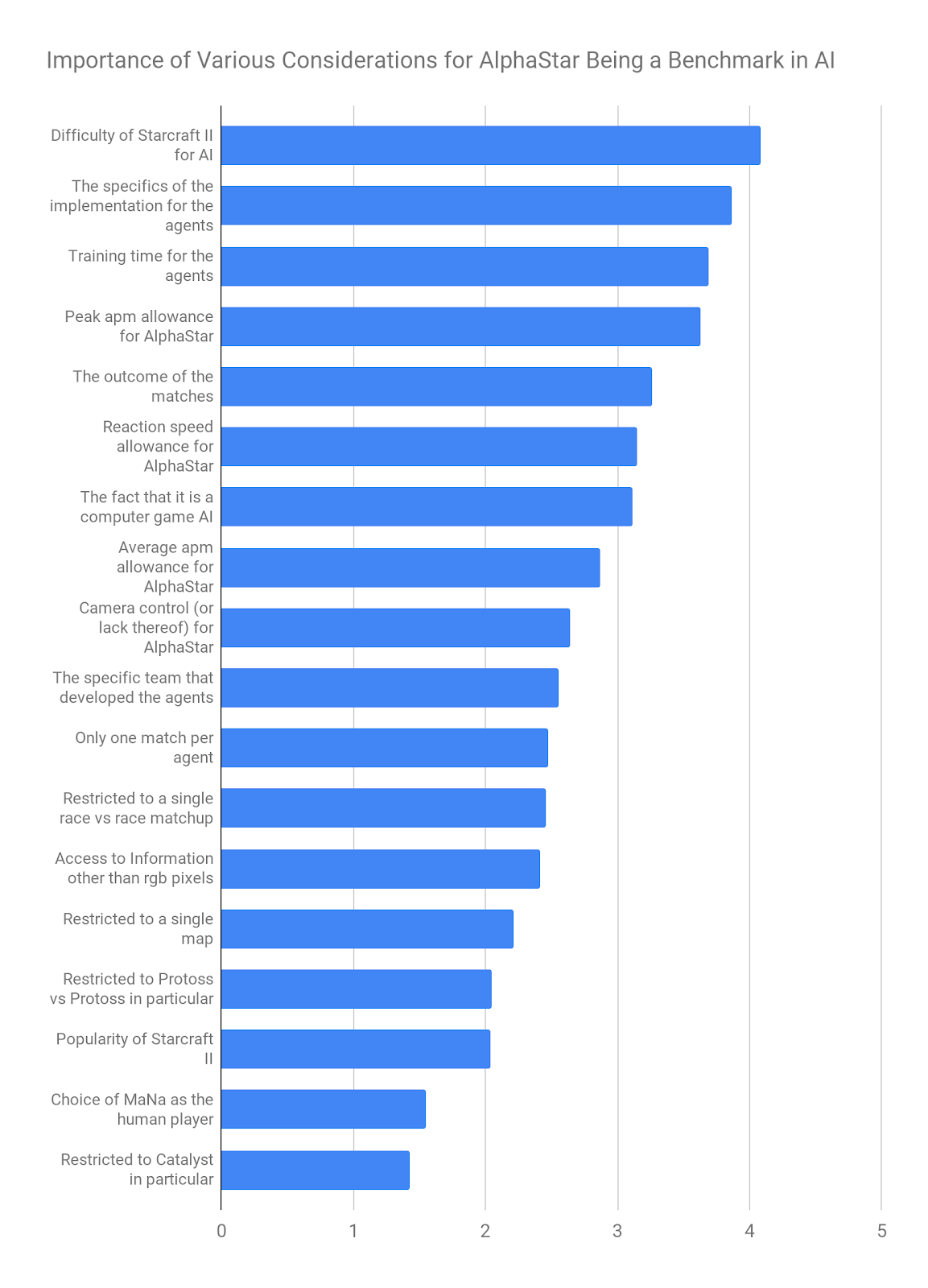
For these two sets of questions, there was almost no difference between the mean scores if I used only Starcraft II expertise weighting, only AI expertise weighting, or ignored expertise weighting entirely.
Further questions
The rest of the questions were free-form to give respondents a chance to tell me anything else that they thought was important. Although these answers were thoughtful and shaped my thinking about AlphaStar, especially early on in the project, I won’t summarize them here.
Appendix II: APM Measurement Methodology
I created a list of professional players by asking users of the Starcraft subreddit which players they thought were exceptionally fast. Replays including these players were found by searching Spawning Tool for replays from tournament matches which included at least one player from the list of fast players. This resulted in 51 replay files.
Several of the replay files were too old, so that they could no longer be opened by the current version of Starcraft II, and I ignored them. Others were ignored because they included players, race matchups, or maps that were already represented in other matches. Some were ignored because we did not get to them before we had collected what seemed to be enough data. This left 15 replays that made it into the analysis.
I opened each file using Scelight, and the time and APM values were recorded for the top three peaks on the graph of that player’s APM, using 5-second bins. Next, I opened the replay file in Starcraft II, and for each peak recorded earlier, we wrote down whether that player was primarily engaging in combat at the time or not. Additionally, I recorded the time and APM for each player for 2-4 5-second durations of the game in which the players were primarily engaged in combat.
All of the APM values which came from combat and from outside of combat were aggregated into the histogram shown in the ‘Speed Controversy’ section of this article.
There are several potential sources of bias or error in this:
- Our method for choosing players and matches may be biased. We were seeking examples of humans playing with speed and precision, but it’s possible that by relying on input from a relatively small number of Reddit users (as well as some personal friends), we missed something.
- This measurement relies entirely on my subjective evaluation of whether the players are mostly engaged in combat. I am not an expert on the game, and it seems likely that I missed some things, at least some of the time.
- The tool I used for this seems to mismatch events in the game by a few seconds. Since I was using 5-second bins, and sometimes a player’s APM will change greatly between 5-second bins, it’s possible that this introduced a significant error.
- The choice of 5 second bins (as opposed to something shorter or longer) is somewhat arbitrary, but it is what some people in the Starcraft community were using, so I’m using it here.
- Some actions are excluded from the analysis automatically. These include camera updates, and this is probably a good thing, but I did not look carefully at the source code for the tool, so it may be doing something I don’t know about.
36 comments
Comments sorted by top scores.
comment by MathiasKB (MathiasKirkBonde) · 2019-09-20T23:33:48.545Z · LW(p) · GW(p)
Before doing the whole EA thing, I played starcraft semi-professionally. I was consistently ranked grandmaster primarily making money from coaching players of all skill levels. I also co-authored a ML paper on starcraft II win prediction.
TL;DR: Alphastar shows us what it will look like when humans are beaten in completely fair fight.
I feel fundamentally confused about a lot of the discussion surrounding alphastar. The entire APM debate feels completely misguided to me and seems to be born out of fundamental misunderstandings of what it means to be good at starcraft.
Being skillful at starcraft, is the ability to compute which set of actions needs to be made and to do so very fast. A low skilled player, has to spend seconds figuring out their next move, whereas a pro player will determine it in milliseconds. This skill takes years to build, through mental caching of game states, so that the right moves become instinct and can be quickly computed without much mental effort.
As you showed clearly in the blogpost, Mana (or any other player) reach a much higher apm by mindlessly tabbing between control groups. You can click predetermined spots on the screen more than fast enough to control individual units.
We are physically capable of playing this fast, yet we do not.
The reason for this, is that in a real game my actions are limited by the speed it takes to figure them out. Likewise if you were to play speedchess against alpha-zero you will get creamed, not because you can't move the pieces fast enough, but because alpha-zero can calculate much better moves much faster than you can.
I am convinced a theoretical AI playing with a mouse and keyboard with the motorcontrols equivalent of a human, would largely be making the same 'inhuman' plays we are seeing currently. Difficulty of input is simply not the bottleneck.
Alphastar can only do its 'inhuman' moves because it's capable of calculating starcraft equations MUCH faster than humans are. Likewise, I can only do 'pro' moves because I'm capable of calculating starcraft equations much faster than an amateur.
You could argue that it's not showcasing the skills we're interested in, as it doesn't need to put the same emphasis on long-term planning and outsmarting its opponent, that equal human players have to. But that will also be the case if you put me against someone who's never played the game.
If what we really care about is proving that it can do long term thinking and planning in a game with a large actionspace and imperfect information, why choose starcraft? Why not select something like Frozen Synapse where the only way to win is to fundamentally understand these concepts?
The entire debate of 'fairness' seems somewhat misguided to me. Even if we found an apm measure that looks fair, I could move the goal post and point out that it makes selections and commands with perfect precision, whereas a human has to do it through a mouse and keyboard. There are moves that are extremely risky to pull off due to the difficulty of precisely clicking things. If we supplied it a virtual mouse to move arround, I could move the goal post again and complain how my eyes cannot take in the entire screen at once.
It's clear alphastar is not a fair fight, yet I think we got a very good look at what the fair fight eventually will look like. Alphastar fundamentally is what superhuman starcraft intelligence looks like (or at least it will be with more training) and it's abusing the exact skillset that make pro players stand out from amateurs in the first place.
Replies from: aleksi-pietikaeinen, spkoc, None↑ comment by Aleksi Pietikäinen (aleksi-pietikaeinen) · 2019-09-21T00:23:42.357Z · LW(p) · GW(p)
I think your feelings stem from you considering it to be enough If AS simply beats human players while APM whiners would like AS to learn all the aspect of Starcraft skill it can reasonably be expected to learn.
The agents on ladder don't scout much and can't react accordingly. They don't tech switch midgame and some of them get utterly confused in ways a human wouldn't. Game 11 agent vs MaNa couldn't figure out it could build 1 phoenix to kill the warp prism and chose to follow it with 3 oracles (units which cant shoot at flying units). The ladder agents display similar mistakes.
Considering how many millions of dollars AS has cost already (could be hundreds at this point) these holes are simply too big to call the agents robust or the project complete and Starcraft conquered.
If they somehow could manage to pull off ASZero which humans can't reliably abuse I'd admit they've done all there is to do. Then they could declared victory.
↑ comment by spkoc · 2019-11-29T11:44:57.172Z · LW(p) · GW(p)
I think you're right when it comes to SC2, but that doesn't really matter for DeepMind's ultimate goal with AlphaStar: to show an AI that can learn anything a human can learn.
In a sense AlphaStar just proves that SC2 is not balanced for superhuman ( https://news.ycombinator.com/item?id=19038607 ) micro. Big stalker army shouldn't beat big Immortal army. In current SC2 it obviously can with good enough micro. There are probably all sorts of other situations where soft-scissor beats soft-rock with good enough micro.
Does this make AlphaStar's SC2 performance illegitimate? Not really? Tho in the specific Stalker-Immortal fight, input through an actual robot looking at an actual screen and having to cycle through control groups to check HP and select units PROBABLY would not have been able to achieve that level of micro.
The deeper problem is that this isn't DeepMind's goal. It just means that SC2 is a cognitively simpler game than initially thought(note, not easy, simple as in a lot of the strategy employed by humans is unnecessary with sufficient athletic skill). The higher goal of AlphaStar is to prove that an AI can be trained from nothing to learn the rules of the game and then behave in a human-like, long term fashion. Scout the opponent, react to their strategy with your own strategy etc.
Simply bulldozing the opponent with superior micro and not even worrying about their counterplay(since there is no counterplay) is not particularly smart. It's certainly still SC2, it just reveals the fact that SC2 is a much simpler game(when you have superhuman micro).
↑ comment by [deleted] · 2019-09-21T19:59:25.842Z · LW(p) · GW(p)
You could argue that it's not showcasing the skills we're interested in, as it doesn't need to put the same emphasis on long-term planning and outsmarting its opponent, that equal human players have to. But that will also be the case if you put me against someone who's never played the game.
Interesting point. Would it be fair to say that, in a tournament match, a human pro player is behaving much more like a reinforcement learning agent than a general intelligence using System 2 [LW · GW]? In other words, the human player is also just executing reflexes he has gained through experience, and not coming up with ingenious novel strategies in the middle of a game.
I guess it was unreasonable to complain about the lack of inductive reasoning and game-theoretic thinking in AlphaStar from the beginning since DeepMind is a RL company, and RL agents just don't do that sort of stuff. But I think it's fair to say that AlphaStar's victory was much less satisfying than AlphaZero, being not only unable to generalize across multiple RTS games, but also unable to explore the strategy space of a single game (hence the incentivizing of use of certain units during training). I think we all expected seeing perfect game sense and situation-dependent strategy choice, but instead blink stalkers is the one build to rule them all, apparently.
Replies from: MathiasKirkBonde↑ comment by MathiasKB (MathiasKirkBonde) · 2019-09-23T18:25:19.777Z · LW(p) · GW(p)
I think that's a very fair way to put it, yes. One way this becomes very apparent, is that you can have a conversation with a starcraft player while he's playing. It will be clear the player is not paying you his full attention at particularly demanding moments, however.
Novel strategies are thought up inbetween games and refined through dozens of practice games. In the end you have a mental decision tree of how to respond to most situations that could arise. Without having played much chess, I imagine this is how people do chess openers do as well.
I considered using system 1 and 2 analogies, but because of certain resevations I have with the dichotomy, I opted not to. Basically I don't think you can cleanly divide human intelligence into those two catagories.
Ask a starcraft player why they made a certain maneuver and they will for the most part be able to tell you why he did it, despite never having thought the reason out loud until you asked. There is some deep strategical thinking being done at the instinctual level. This intelligence is just as real as system 2 intelligence and should not be dismissed as being merely reflexes.
My central critique is essentially of seeing starcraft 'mechanics' as unintelligent. Every small maneuver has a (most often implicit) reason for being made. Starcraft players are not limited by their physical capabilities nearly as much as they are limited by their ability to think fast enough. If we are interested in something other than what it looks like when someone can think at much higher speeds than humans, we should be picking another game than starcraft.
Replies from: JenniferRM↑ comment by JenniferRM · 2019-12-05T20:45:10.086Z · LW(p) · GW(p)
I think the abstract question of how to cognitively manage a "large action space" and "fog of war" is central here.
In some sense StarCraft could be seen as turn based, with each turn lasting for 1 microsecond, but this framing makes the action space of a beginning-to-end game *enormous*. Maybe not so enormous that a bigger data center couldn't fix it? In some sense, brute force can eventually solve ANY problem tractable to a known "vaguely O(N*log(N))" algorithm.
BUT facing "a limit that forces meta-cognition" is a key idea for "the reason to apply AI to an RTS next, as opposed to a turn based game."
If DeepMind solves it with "merely a bigger data center" then there is a sense in which maybe DeepMind has not yet found the kinds of algorithms that deal with "nebulosity" as an explicit part of the action space (and which are expected by numerous people (including me) to be widely useful in many domains).
(Tangent: The Portia spider is relevant here because it seems that its whole schtick is that it scans with its (limited, but far seeing) eyes, builds up a model of the world via an accumulation of glances, re-uses (limited) neurons to slowly imagine a route through that space, and then follows the route to sneak up on other (similarly limited, but less "meta-cognitive"?) spiders which are its prey.)
No matter how fast something can think or react, SOME game could hypothetically be invented that forces a finitely speedy mind to need action space compression and (maybe) even compression of compression choices. Also, the physical world itself appears to contain huge computational depths.
In some sense then, the "idea of an AI getting good *at an RTS*" is an attempt (which might have failed or might be poorly motivated) to point at issues related to cognitive compression and meta-cognition. There is an implied research strategy aimed at learning to use a pragmatically finite mind to productively work on a pragmatically infinite challenge.
The hunch is that maybe object level compression choices should always have the capacity to suggest not just a move IN THE GAME of doing certain things, but also a move IN THE MIND to re-parse the action space, compress it differently, and hope to bring a different (and more appropriate) set of "reflexes" to bear.
The idea of a game with "fog of war" helps support this research vision. Some actions are pointless for the game, but essential to ensuring the game is "being understood correctly" and game designers adding fog of war to a video game could be seen as an attempt to represent this possibly universally inevitable cognitive limitation in a concretely-ludic symbolic form.
If an AI is trained by programmers "to learn to play an RTS" but that AI doesn't seem to be learning lessons about meta-cognition or clock/calendar management, then it feels a little bit like the AI is not learning what we hoped it was suppose to learn from "an RTS".
This is why these points made by maximkazhenkov in a neighboring comment are central:
The agents on [the public game] ladder don't scout much and can't react accordingly. They don't tech switch midgame and some of them get utterly confused in ways a human wouldn't.
I think this is conceptually linked (through the idea of having strategic access to the compression strategy currently employed) to this thing you said:
...you can have a conversation with a starcraft player while he's playing. It will be clear the player is not paying you his full attention at particularly demanding moments, however... I considered using system 1 and 2 analogies, but because of certain resevations I have with the dichotomy... [that said] there is some deep strategical thinking being done at the instinctual level. This intelligence is just as real as system 2 intelligence and should not be dismissed as being merely reflexes.
In the story about metacognition, verbal powers seem to come up over and over.
I think a lot of people who think hard about this understand that "mere reflexes" are not mere (especially when deeply linked to a reasoning engine that has theories about reflexes).
Also, I think that human meta-cognitive processes might reveal themselves to some degree in the apparent fact that a verbal summary can be generated by a human *in parallel without disrupting the "reflexes" very much*... then sometimes there is a pause in the verbalization while a player concentrates on <something>, and then the verbalization resumes (possibly with a summary of the 'strategic meaning' of the actions that just occurred).
Arguably, to close the loop and make the system more like the general intelligence of a human, part of what should be happening is that any reasoning engine bolted onto the (constrained) reflex engine should be able to be queried by ML programmers to get advice about what kinds of "practice" or "training" needs to be attempted next.
The idea is that by *constraining* the "reflex engine" (to be INadequate for directly mastering the game) we might be forced to develop a reasoning engine for understanding the reflex engine and squeezing the most performance out of it in the face of constraints on what is known and how much time there is to correlate and integrate what is known.
A decent "reflexive reasoning engine" (ie a reasoning engine focused on reflexive engines) might be able to nudge the reflex engine (every 1-30 seconds or so?) to do things that allow the reflex engine to scout brand new maps or change tech trees or do whatever else "seems meta-cognitively important".
A good reasoning engine might be able to DESIGN new maps that would stress test a specific reflex repertoire that it thinks it is currently bad at.
A *great* reasoning engine might be able to predict in the first 30 seconds of a game that it is facing a "stronger player" (with a more relevant reflex engine for this game) such that it will probably lose the game for lack of "the right pre-computed way of thinking about the game".
A really FANTASTIC reflexive reasoning engine might even be able to notice a weaker opponent and then play a "teaching game" that shows that opponent a technique (a locally coherent part of the action space that is only sometimes relevant) that the opponent doesn't understand yet, in a way that might cause the opponent's own reflexive reasoning engine to understand its own weakness and be correctly motivated to practice a way to fix that weakness.
(Tangent: To recall the tangent above to the Portia spider. It preyed on other spiders with similar spider limits. One of the fears here is that all this metacognition, when it occurs in nature, is often deployed in service to competition, either with other members of the same species or else to catch prey. Giving these powers to software entities that ALREADY have better thinking hardware than humans in many ways... well... it certainly gives ME pause. Interesting to think about... but scary to imagine being deployed in the midst of WW3.)
It sounds, Mathias, like you understand a lot of the centrality and depth of "trained reflexes" intuitively from familiarity with BOTH StarCraft and ML both, and part of what I'm doing here is probably just restating large areas of agreement in a new way. Hopefully I am also pointing to other things that are relevant and unknown to some readers :-)
If what we really care about is proving that it can do long term thinking and planning in a game with a large actionspace and imperfect information, why choose starcraft? Why not select something like Frozen Synapse where the only way to win is to fundamentally understand these concepts?
Personally, I did not know that Frozen Synapse existed before I read your comment here. I suspect a lot of people didn't... and also I suspect that part of using StarCraft was simply for its PR value as a beloved RTS classic with a thriving pro scene and deep emotional engagement by many people.
I'm going to go explore Frozen Synapse now. Thank you for calling my attention to it!
comment by gwern · 2019-09-18T13:39:58.850Z · LW(p) · GW(p)
I'd add http://starcraft.blizzplanet.com/blog/comments/blizzcon-2018-starcraft-ii-whats-next-panel-transcript to the chronology.
Replies from: Grothor↑ comment by Richard Korzekwa (Grothor) · 2019-09-18T20:20:17.165Z · LW(p) · GW(p)
Thanks! I've updated the version on our site (https://aiimpacts.org/the-unexpected-difficulty-of-comparing-alphastar-to-humans/) and I'm working on updating the post here on LW.
Replies from: gwern↑ comment by gwern · 2019-09-18T21:58:46.300Z · LW(p) · GW(p)
I think it's interesting because once you read it, it's obvious that AS was going to happen and the approach was scaling (given that OA5 had scaled from a similar starting point, cf 'the bitter lesson'), but at the time, no one in DRL/ML circles even noticed the talk - I only found out about that Vinyals talk after AS came out and everyone was reading back through Vinyals's stuff and noticed he'd said something at Blizzcon (and then after a bunch of searching, I finally found that transcript, since the video is still paywalled by Blizzard). Oh well!
comment by WilliamKiely · 2021-07-18T17:49:18.550Z · LW(p) · GW(p)
How many years do you think it will be until we see (in public) an agent which only gets screen pixels as input, has human-level apm and reaction speed, and is very clearly better than the best humans?
Respondents had a median prediction of two years and an expertise-weighted mean prediction of a little less than four years.
It's now been about two years and this hasn't happened yet. It seems like that might just be the case because DeepMind stopped work on this?
Replies from: Grothor↑ comment by Richard Korzekwa (Grothor) · 2021-07-21T21:30:32.585Z · LW(p) · GW(p)
As far as I know, nobody has been working on SC2 AI since the 2019 experiment putting AlphaStar on the public ladder.
comment by Thrasymachus · 2019-09-19T04:51:32.742Z · LW(p) · GW(p)
Thanks for this excellent write-up!
I'm don't have relevant expertise in either AI or SC2, but I was wondering whether precision might still be a bigger mechanical advantage than the write-up notes. Even if humans can (say) max out at 150 'combat' actions per minute, they might misclick, not be able to pick out the right unit in a busy and fast battle to focus fire/trigger abilities/etc, and so on. The AI presumably won't have this problem. So even with similar EAPM (and subdividing out 'non-combat' EAPM which need not be so accurate), Alphastar may still have a considerable mechanical advantage.
I'd also be interested in how important, beyond some (high) baseline, 'decision making' is at the highest levels of SC2 play. One worry I have is although decision-making is important (build orders, scouting, etc. etc.) what decides many (?most) pro games is who can more effectively micro in the key battles, or who can best juggle all the macro/econ tasks (I'd guess some considerations in favour would be that APM is very important, and that a lot of the units in SC2 are implicitly balanced by 'human' unit control limitations). If so, unlike Chess and Go, there may not be some deep strategic insights Alphastar can uncover to give it the edge, and 'beating humans fairly' is essentially an exercise in getting the AI to fall within the band of 'reasonably human', but can still subtly exploit enough of the 'microable' advantages to prevail.
Replies from: None, ErickBall
↑ comment by [deleted] · 2019-09-20T17:15:45.277Z · LW(p) · GW(p)
If so, unlike Chess and Go, there may not be some deep strategic insights Alphastar can uncover to give it the edge
I think that's where the central issue lies with games like Starcraft or Dota; their strategy space is perhaps not as rich and complex as we have initially expected. Which might be a good reason to update towards believing that the real world is less exploitable (i.e. technonormality?) as well? I don't know.
However, I think it would be a mistake to write off these RTS games as "solved" in the AI community the same way chess/Go are and move on to other problem domains. AlphaStar/OpenAI5 require hundreds of years of training time to reach the level of human top professionals, and I don't think it's an "efficiency" problem at all.
Additionally, in both cases there are implicit domain knowledge integrated into the training process: In the case of AlphaStar, the AI was first trained on human game data and, as the post mentions, competing agents are subdivided into strategy spaces defined by human experts:
Hundreds of versions of the AI play against each other, and the ones that perform best are selected to play against human players. Each one has its own set of units that it is incentivized to use via reinforcement learning, so that they each play with different strategies.
In the case of OpenAI5, the AI is still constrained to a small pool of heroes, the item choices are hard-coded by human experts, and it would have never discovered relatively straightforward strategies (defeating Roshan to receive a power-up, if you're familiar with the game) were it not for the programmers' incentivizing in the training process. It also received the same skepticism in the gaming community (in fact, I'd say the mechanical advantage of OpenAI5 was even more blatant than with AlphaStar).
This is not to belittle the achievements of the researchers, it's just that I believe these games still provide fantastic testing grounds for future AI research, including paradigms outside deep reinforcement learning. In Dota, for example, one could change the game mode to single draft to force the AI out of a narrow strategy-space that might have been optimal in the normal game.
In fact, I believe (~75% confidence) the combinatorial space of heroes in a single draft Dota game (and the corresponding optimal-strategy-space) to be so large that, without a paradigm shift at least as significant as the deep learning revolution, RL agents will never beat top professional humans within 2 orders of magnitude of compute of current research projects.
I'm not as familiar with Starcraft II but I'm sure there are simple constraints one can put on the game to make it rich in strategy space for AIs as well.
↑ comment by ErickBall · 2019-09-20T13:59:31.375Z · LW(p) · GW(p)
I wonder if you could get around this problem by giving it a game interface more similar to the one humans use. Like, give it actual screen images instead of lists of objects, and have it move a mouse cursor using something equivalent to the dynamics of an arm, where the mouse has momentum and the AI has to apply forces to it. It still might have precision advantages, with enough training, but I bet it would even the playing field a bit.
Replies from: None↑ comment by [deleted] · 2019-09-20T16:07:51.489Z · LW(p) · GW(p)
I don't think this would be a worthwhile endeavor, because we already know that deep reinforcement learning can deal with these sorts of interface constraints as shown by Deepmind's older work. I would expect the agent behavior to converge towards that of the current AI, but requiring more compute.
Replies from: Slider, ErickBall↑ comment by Slider · 2019-09-20T16:27:07.073Z · LW(p) · GW(p)
I think the question is about making the compute requirements comparable. One of the critisims of early AI work is about how using simple math on abstract things can seem very powerful if the abstractions are provided for it. But real humans have to extract the essential abstractions from the messy world. Consider a soldier robot that has to assign friend or foe classification to a humanoid as part of a decision to maybe shoot at it. That is a real subtask that giving a magic "label" would unfairly circumvent. In nature even if camouflage is imperfect it can be valuable and even if the animal is correctly identified as prey delaying the detection event or having the hunter hesitate can be valuable.
Also a game like QWOP is surprisingly diffcult for humans and giving a computer "just control over legs" would make the whole game trivial.
A lot of the starcraft technique also mirrors the games restrctions. Part of the point of control groups is to bypass screen zoom limitations. For example in Supreme Commander some of the particular kinds of limitations do not exist because you can zoom out to have the whole map on the screen at once and because providing attention to different parts of the battlefield has been made more handy (or atleast different (there are new problems such as "dots fighting dots" making it hard to see micro considerations))
↑ comment by ErickBall · 2019-09-20T19:03:40.602Z · LW(p) · GW(p)
Maybe you're right... My sense is that it would converge toward the behavior of the current AI, but slower, especially for movements that require a lot of accuracy. There might be a simpler way to add that constraint without wasting compute, though.
comment by habryka (habryka4) · 2019-11-28T05:20:33.126Z · LW(p) · GW(p)
Promoted to curated: It's been a while since this post was posted, but I've referred to it since then multiple times, and I just think this kind of mixture of accessible technical analysis, and high-level discussion is really valuable. I also generally liked the methodology, and presentation, both of which seemed pretty clear and straightforwardly illuminating to me.
comment by Aleksi Pietikäinen (aleksi-pietikaeinen) · 2019-09-20T17:24:29.767Z · LW(p) · GW(p)
I don't think this was unexpected at all. As soon as Deepmind announced their Starcraft project, most of the discussion was about proper mechanical limitations since the real-time-aspect of RTS games favors mechanical execution so heavily. Being dumb and fast is simply more effective than smart and slow.
The skills that make a good human Stracraft player can broadly be divided into two categories: athleticism and intelligence. Much of the strategy in the game is build around the fact that players are playing with limited resources of athleticism (i.e. speed and accuracy) so it follows that you can't necessarily separate the two skill categories and only measure one of them.
The issue with the presentation was that not only did Deepmind not highlight the problematic nature of assessing the intelligence of their algorithm, they actively downplayed it. In my opinion, the pr spin was blatantly obvious and the community backlash warranted and justified.
Replies from: Grothor↑ comment by Richard Korzekwa (Grothor) · 2019-09-20T17:52:38.362Z · LW(p) · GW(p)
Being dumb and fast is simply more effective than smart and slow.
But it is unclear what the trade-off actually is here, and what it means to be "fast" or "smart". AI that is really dumb and really fast has been around for a while, but it hasn't been able to beat human experts in a full 1v1 match.
Much of the strategy in the game is build around the fact that players are playing with limited resources of athleticism (i.e. speed and accuracy) so it follows that you can't necessarily separate the two skill categories and only measure one of them.
The fact that strategy is developed under an athleticism constraint does not imply that we can't measure athleticism. What was unexpected (at least to me) is that, even with a full list of commands given by the players, it is hard to arrive at a reasonable value for just the speed component(s) of this constraint. It seems like this was expected, at least by some people. But most of the discussion that I saw about mechanical limitations seemed to suggest that we just need to turn the APM dial to the right number, add in some misclicking and reaction time, and call it a day. Most of the people involved in this discussion had greater expertise than I do in SCII or ML or both, so I took this pretty seriously. But it turns out you can't even get close to human-like interaction with the game without at least two or three parameters for speed alone.
Replies from: aleksi-pietikaeinen↑ comment by Aleksi Pietikäinen (aleksi-pietikaeinen) · 2019-09-20T20:19:57.533Z · LW(p) · GW(p)
Sorry I worded that really poorly. Dumb and fast was a comment about relatively high-level human play. It is context dependend and as you said, the trade off is very hard to measure. It probably flips back and forth quite a bit if we'd slowly increase both and actually attempt to graph it. Point is, If we look at the early game, where both players have similar armies, unlimited athleticism quickly becomes unbeatable even with only moderate intelligence behind it.
The thing about measuring athleticism or intelligence separately is that we can measure athleticism of a machine but not of a human. When a human plays sc2 it's never about purely executing a mindless task. Never. You'd have to somehow separate the visual recogniton component which is impossible. Human reaction times and accuracy are heavily affected by the dynamically changing scene of play.
Think about it this way, measuring human spam clicking speed and accuracy is not the benchmark because those actions are inconsequential and don't translate to combat movement (or any other actions a player makes in a dynamic scene). Say you are in a blink stalker battle. In order to effectively retreat wounded units you have to quickly assess which units are in danger before ordering them to pull back. That cognitive process of visual recogniton and anticipation is simply inseparable of the athleticism aspect.
I guess you could measure human clicking speed and reaction times in a program specifically designed to do so but those measures would be useless for the same reason. The mechanically ability of the human varies wildly based on what is happening in a game of sc2. There are cognitive bottlenecks.
Here's an even clearer way to think about it. In a game of soccer you can make a decision to run somewhere (intelligence) and then try to run as fast as you can (athleticism). In a game of starcraft every actions is a click and therefore a decision. You can't click harder or gentler. You could argue that a single decision can include dozens of clicks but that's true only for macrostrategic decisions (e.g. what build order a player chooses). Those don't exist in combat situations.
Basically, we can handicap the AI mechanically exactly where we want it but we can't know for sure where that is. Luckily we don't have to. We can simply eyeball it and shoot intentionally slightly lower. That way, if the human is on equal footing or even has a slight edge, an AI victory should almost inarguably be a result of superior cognitive ability.
You don't have to get these handicaps exactly right. The APM controversy happened because AS's advantages were obvious. It is not hard to make it less so.
Replies from: None, Grothor↑ comment by [deleted] · 2019-09-21T21:00:04.382Z · LW(p) · GW(p)
I think there are two perspectives to view the mechanical constraints put on AlphaStar:
One is the "fairness" perspective, which is that the constraints should perfectly mirror that of a human player, be it effective APM, reaction time, camera control, clicking accuracy etc. This is the perspective held mostly by the gaming community, but it is difficult to implement in practice as shown by this post, requiring enormous analysis and calibration effort.
The other is what I call the "aesthetics" perspective, which is that the constraints should be used to force the AI into a rich strategy space where its moves are gratifying to watch and interesting to analyze. The constraints can be very asymmetrical with respect to human constraints.
In retrospect, I think the second one is what they should have gone with, because there is a single constraint could have achieved it: signal delay
Think about it: what good would arbitrarily high APM and clicking accuracy amount to if the ping is 400-500ms?
- It would naturally introduce uncertainties through imperfect predictions and bias towards longer-term thinking anywhere on the timescale from seconds to minutes
- It would naturally move the agent into the complex strategy space that was purposefully designed into the game but got circumvented by exploiting certain edge cases like ungodly blink stalker micro
- It avoids painstaking analysis of the multi-dimensional constraint-space by reducing it down to a single variable
↑ comment by Slider · 2019-09-22T00:24:04.015Z · LW(p) · GW(p)
The interesting parts of the strategy space were not designed in even for human players. There is a lot of promoting bugs to features and player creative effort that has shaped the balance. There is a certain game the game designers and player play. Players try to abuse every edge and designers try to keep the game interesting and balanced. Forbidding AI to find it's own edge cases would impose a differnt incentive structure than humans deal with.
Replies from: aleksi-pietikaeinen↑ comment by Aleksi Pietikäinen (aleksi-pietikaeinen) · 2019-09-25T15:47:11.205Z · LW(p) · GW(p)
This is not true. In Starcraft Broodwar there are lot's of bugs that players take advantage of but such bugs don't exist in Starcraft 2.
I think it's much more important to restrict the AI mechanically so that it has to succeed strategically that to have a fair fight. The whole conversation about fairness is misguided anyway. The point of APM limiter is to remove confounding factors and increase validity of our measurement, not to increase fairness.
Replies from: JohnBuridan, Slider↑ comment by SebastianG (JohnBuridan) · 2019-11-28T18:10:03.409Z · LW(p) · GW(p)
Here to say the same thing. Say I want to discover better strategies in SC2 using AlphaStar, it's extremely important that Alphastar be employing some arbitrarily low human achievable level of athleticism.
I was disappointed when the vs TLO videos came out that TLO thought he was playing against one agent AlphaStar. But in fact he played against five different agents which employed five different strategies, not a single agent which was adjusting and choosing among a broad range of strategies.
↑ comment by Slider · 2019-09-25T16:37:55.623Z · LW(p) · GW(p)
In making of starcraft 2 there was the issue of what mechanics to carry over from sc1. If a mechanic that is kept is a ascended bug you off course provide a clean implementation so the new games mechanic is not a bug. But it still means that the mechanic was not put in the palette by a human even if a human decides to keep it for the next game. The complex strategy spaces are discovered and proven rather than built or designed. If the game doesn't play like it was designed but is not broken then it tends to not get fixed. In reverse if a designers balance doesn't result in a good meta in the wild the onus is on the designers to introduce a patch that actually results in a healthy meta and not make players play in a specific way to keep the game working.
↑ comment by Richard Korzekwa (Grothor) · 2019-10-01T11:31:17.435Z · LW(p) · GW(p)
Sorry I worded that really poorly.
It's all good; thanks for clarifying. I probably could have read more charitably. :)
That cognitive process of visual recogniton and anticipation is simply inseparable of the athleticism aspect.
Yeah, I get what you're saying. To me, the quick recognition and anticipation feels more like athleticism anyway. We're impressed with athletes that can react quickly and anticipate their opponent's moves, but I'm not sure we think of them as "smart" while they're doing this.
This is part of what I was trying to look at by measuring APM while in combat. But I think you're right that there is no sharp divide between "strategy" or being "smart" or "clever" and "speed" or being "fast" or "accurate".
comment by habryka (habryka4) · 2020-12-15T07:01:46.231Z · LW(p) · GW(p)
This was really useful at the time for helping me orient around the whole "how good are AIs at real-time strategy" thing at the time, and I think is still the post I would refer to the most (together with orthonormal's post, which I also nominated).
comment by Ben Pace (Benito) · 2020-12-15T07:00:29.185Z · LW(p) · GW(p)
It's a really detailed analysis of this situation, and I think this sort of analysis probably generalizes to lots of cases of comparing ML to humans. I'm not confident though, and would update a bunch from a good review of this.
comment by Ofer (ofer) · 2019-09-21T17:54:29.930Z · LW(p) · GW(p)
From AlphaStar, we’ve learned that one of two things is true: Either AI can [...] solve basic game theory problems
I'm confused about the mention of game theory. Did AlphaStar play in games that included more than two teams?
Replies from: None↑ comment by [deleted] · 2019-09-21T18:27:51.770Z · LW(p) · GW(p)
No, but Starcraft is an imperfect information game like Poker, and involves computing mixed strategies
Replies from: Douglas_Knight, ofer↑ comment by Douglas_Knight · 2019-11-30T02:33:57.203Z · LW(p) · GW(p)
This is super tangential, but I think you're making a technical error here. It's true that poker is imperfect information and it's true that this makes it require more computational resources, which matches the main text, but not this comment. But does imperfect information suggest mixed strategies? Does optimal play in poker require mixed strategies? I see this slogan repeated a lot and I'm curious where you learned it. Was it in a technical context? Did you encounter technical justification for it?
Games where players move simultaneously, like rock-paper-scissors require mixed strategies, and that applies to SC. But I'm not sure that requires extra computational resources. Whether they count as "imperfect information" is subject of conflicting conventions. Whereas play alternates in poker. I suspect that this meme propagates because of a specific error. Imperfect information demands bluffing and people widely believe that bluffing is a mixed strategy. But it isn't. The simplest version of poker to induce bluffing is von Neumann poker, which has a unique (pure) Nash equilibrium in which one bets on a good hand or a bad hand and checks on a medium hand. I suspect that for poker based on a discrete deck that the optimal strategy is mixed, but close to being deterministic and mixed only because of discretization error.
Replies from: None↑ comment by Ofer (ofer) · 2019-09-21T18:43:55.147Z · LW(p) · GW(p)
Ah, makes sense, thanks.
comment by [deleted] · 2019-09-20T17:18:03.901Z · LW(p) · GW(p)
I estimate the current AI to be ~100 times less efficient with simulation time than humans are, and that humans are another ~100 times less efficient than an ideal AI (practically speaking, not the Solomonoff-induction-kind). Humans Who Are Not Concentrating Are Not General Intelligences [LW · GW], and from observation I think it's clear that human players spend a tiny fraction of their time thinking about strategies and testing them compared to practicing pure mechanical skills.
comment by FactorialCode · 2019-09-18T15:34:01.461Z · LW(p) · GW(p)
I found a youtube channel that has been providing commentary on suspected games of AlphaStar on the ladder. They're presented from a layman's perspective, but they might be valuable for people to get an idea of what the current AI is capable of.