UML IX: Kernels and Boosting
post by Rafael Harth (sil-ver) · 2020-02-02T21:51:25.114Z · LW · GW · 1 commentsContents
Kernels I II III Boosting I II III IV V endfor end VI None 1 comment
(This is the ninth post in a sequence on Machine Learning based on this book. Click here [? · GW] for part I.)
Kernels
To motivate this chapter, consider some training sequence with instances in some domain set . Suppose we wish to use an embedding of the kind discussed in the previous post [? · GW] (i.e., to make the representation of our points more expressive, so that they can be classified by a hyperplane). Most importantly, suppose that is significantly larger than . In such a case, we're describing each point in terms of coordinates, even though our space only has points, which means that there can, in some sense, only be "relevant" directions. In particular, let
where is the training sequence without labels, so that . Then is an (at most) -dimensional subspace of , and we would like to prove that we can work in rather than in .
I
As a first justification for this goal, observe that for all . (The symbol for any denotes the set .) Recall that we wish to learn a hyperplane parametrized by some that can then be used to predict a new instance for some by checking whether . The bulk of the difficulty, however, lies in finding the vector ; this is generally much harder than computing a single inner product .
Thus, our primary goals are to show that
(1) will lie in
(2) can somehow be computed by only working in
To demonstrate this, we need to look at how is chosen, which depends on the algorithm we use. In the case of Soft Support Vector Machines (previous post [LW · GW]), we choose
.
This rule shows that we only care about the inner product between and our mapped training points, the . Thus, if we could somehow prove (1), then (2) would seem to follow: if , then, according to the rule above, we would only end up caring about inner products between points that are both in .
Therefore, we now turn to proving (1) formally. To have the result be a bit more general (so that it also applies to algorithms other than Soft Support Vector Machines), we will analyze a more general minimization problem. We assume that
where is any function and is any monotonically non-decreasing function. (You might verify that the original problem is an instance of this one.) Now let be a solution to the above problem. Then we can use extended orthogonal decomposition to write , where is the projection onto that leaves vectors in unchanged and is orthogonal to every vector in . Then, for any , we have
.
In particular, this is true for all the . Furthermore, since is non-decreasing and the norm of is at least as large as the norm of (note that due to the Pythagorean theorem), this shows that is a solution to the optimization problem. Moreover, if is strictly monotonically increasing (as is the case for Soft Support Vector Machines), then if , it would also be better than , which is impossible since is by assumption optimal. Thus, must be , which implies that not only some but all solutions lie in .
[1] Regular orthogonal decomposition, as I've formulated in the previous post [LW · GW], only guarantees that is orthogonal to rather than to every vector in . But the extended version is no harder to prove. Choose some orthonormal basis of , extend it to an orthonormal basis of all of (amazingly, this is always possible), and define by ; i.e., just discard all basis elements that belong to but not . That does the job.
II
We've demonstrated that only the inner products between mapped training points matter for the training process. Another way to phrase this statement is that, if we have access to the function
we no longer have any need to represent the points explicitly. The function is what is called the kernel function, that gives the chapter its name.
Note that takes two arbitrary points in ; it is not restricted to elements in the training sequence. This is important because, to actually apply the predictor, we will have to compute for some , as mentioned above. But to train the predictor, we only need inner products between mapped training points, as we've shown. Thus, if we set
then we can do our training based solely on the (which will lead to a predictor that uses to classify domain points.) Now let's reformulate all our relevant terms to that end. Recall that we have just proved that . This implies that for the right . Also recall that our objective is to find in the set
Now we can reformulate
for all , and
.
Plugging both of those into the term behind the , we obtain
This is enough to establish that one can learn purely based on the . Unfortunately, the Machine Learning literature has the annoying habit of writing everything that can possibly be written in terms of matrices and vectors in terms of matrices and vectors, so we won't quite leave it there. By setting (a row vector), we can further write the above as
or even as , at which point we've successfully traded any conceivable intuition for compactness. Nonetheless, the point that is sufficient for learning still stands. is also called the Gram matrix.
And for predicting a new point , we have
.
At this point, you might notice that we never represented explicitly, but just reformulated everything in terms of inner products. Indeed, one could introduce kernels without mentioning , but I find that thinking in terms of is quite helpful for understanding why all of this stuff works. Note that the above equation (where we predict the label of a new instance) is not an exception to the idea that we're working in . Even though it might not be immediately apparent from looking at it, it is indeed the case that we could first project into without changing anything about its prediction. In other words, it is indeed the case that for all . This follows from the definition of and the fact that all basis vectors outside of are orthogonal to everything in .
III
Kernels allow us to deal with arbitrarily high-dimensional data (even infinitely dimensional) by computing distances, and later do some additional computations to apply the output predictor – under the essential condition that we are able to evaluate the kernel function . Thus, we are interested in embeddings such that is easy to evaluate.
For an important example, consider an embedding for multi-variable polynomials. Suppose we have such a polynomial of the form , i.e. something like
where the above would be a -variable polynomial of degree 5. Now recall that, to learn one-dimensional polynomials with linear methods, we chose the embedding . That way, a linear combination of the image coordinates can do everything a polynomial predictor can do. To do the same for an arbitrary -dimensional polynomial of degree , we need the far more complex embedding
An -dimensional polynomial of degree may have one value for each possible combination of its variables such that at most variables appear in each term. Each defines such a combination. Note that this is a sequence, so repetitions are allowed: for example, the sequence corresponds to the term . We set so that we also catch all terms with degree less than : for example, the sequence corresponds to the term and the sequence to the absolute value of the polynomial.
For large and this target space is extremely high-dimensional, but we're studying kernels here, so the whole point will be that we won't have to represent it explicitly.
Now suppose we have two such instances and . Then,
And for the crucial step, the last term can be rewritten as – both terms include all sequences of length where . Now (recall that ) this means that the above sum simply equals . In summary, this calculation shows that
Thus, even though maps points into the very high-dimensional space , it is nonetheless feasible to learn a multi-polynomial predictor through linear methods, namely by embedding the values via and then ignoring and using instead. The gram matrix will consist of entries, where for each, a term of the form has to be computed. This doesn't look that scary! Even for relatively large values of , , and , it should be possible to compute on a reasonable machine.
If we do approach learning a multi-dimensional polynomial in this way, then (I think) there are strong reasons to question in what sense the embedding actually happens – this question is what I was trying to wrap my head around at the end of the previous post. It seemed questionable to me that is fundamental even if the problem is learned without kernels, but even more so if it is learned with them.
And that is all I have to say about kernels. For the second half of this post, we'll turn to a largely independent topic.
Boosting
Boosting is another item under the "widening the applicability of classes" category [? · GW], much like the from earlier.
I
This time, the approach is not to expand the representation of data and then apply a linear classifier on that representation. Instead, we wish to construct a complex classifier as a linear combination of simple classifiers.
When hyperplanes are visualized, it is usually understood that one primarily cares about hyperplanes in higher-dimensional spaces where they are much more expressive, despite the illustration depicting an instance in -d or -d. But this time, think of the problem instance below in literal 2-d space:
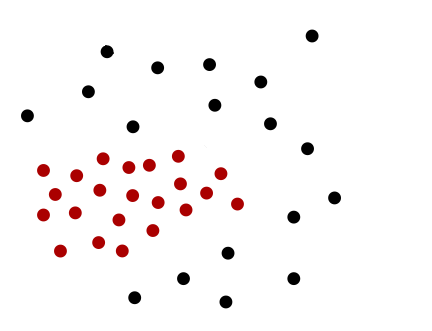
No hyperplane can classify this instance correctly, but consider a combination of these three hyperplanes:
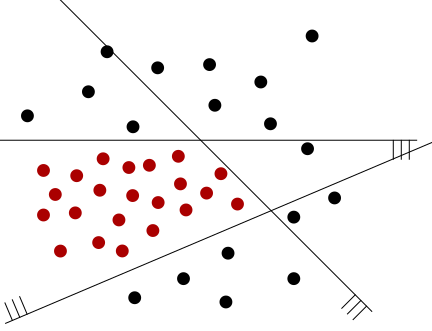
By letting where is the predictor corresponding to the -th hyperplane and is the sign function, we have constructed a predictor which has zero empirical error on this training instance.
Perhaps more surprisingly, this trick can also learn non-convex areas. The instance below,

will be classified correctly by letting , with the (ordered left to right) defined like so:
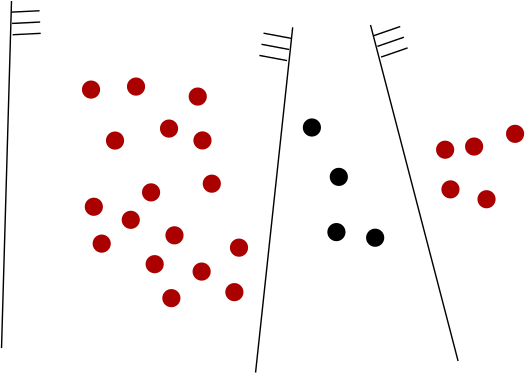
These two examples illustrate that the resulting class is quite expressive. The question is, how to learn such a linear combination?
II
First, note that hyperplanes are just an example; the framework is formulated in terms of a learning algorithm that has access to a weak learner, where
An algorithm is called a -weak learner for a hypothesis class iff there is a function such that, for any probability distribution over and any failure probability , if consists of at least i.i.d. points sampled via , then with probability at least over the choice of , it holds that .
If you recall the definition of PAC learnability back from chapter 1 [LW · GW], you'll notice that this is very similar. The only difference is in the error: PAC learning demands that it be arbitrarily close to the best possible error, while a weak learner merely has to bound it away from by some fixed amount , which can be quite small. Thus, a weak learner is simply an algorithm that puts out a predictor that performs a little bit better than random. In the first example, the upper hyperplane could be the output of a weak learner. The term "boosting" refers to the process of upgrading this one weak learner into a better one, precisely by applying it over and over again under the supervision of a smartly designed algorithm –
– which brings us back to the question of how to define such an algorithm. The second example (the non-convex one) illustrates a key insight here: repeatedly querying the weak learner on the unaltered training instance is unlikely to be fruitful, because the third hyperplane by itself performs worse than random, and will thus not be output by a -weak learner (not for any ). To remedy this, we somehow need to prioritize the points we're currently getting wrong. Suppose we begin with the first two hyperplanes. At this point, we have classified the left and middle cluster correctly. If we then weigh the right cluster sufficiently more strongly than the other two, eventually, will perform better than random. Alas, we wish to adapt our weighting of training points dynamically, and we can do this in terms of a probability distribution over the training sequence.
Now the roadmap for defining the algorithm which learns a predictor on a binary classification problem via boosting is as follows:
- Have access to a training sequence and a -weak learner
- Manage a list of weak predictors which has output in previous rounds
- At every step, hand the training sequence along with some distribution over , and have it output a -weak predictor on the problem , where each point in is taken into account proportional to its probability mass.
- Stop at some point and output a linear combination of the
The particular algorithm we will construct is called Ada-Boost, where "Ada" doesn't have any relation to the programming language, but simply means "adaptive".
III
Let's first look into how to define our probability distribution, which will be the most complicated part of the algorithm. Suppose we have our current distribution based on past predictors output by , and suppose further that we have computed weights such that measures the quality of (higher is better). Now we receive a new predictor with quality . Then we can define a new probability distribution by letting
where we write rather than because the term isn't normalized; it will equal the above scaled such that all probabilities sum to 1.
The term is iff predictor classified correctly. Thus, the right component of the product equals iff the point was classified correctly, and if it wasn't. If is a bad predictor and is small, say , the two terms are both close to 1, and we don't end up changing our weight on very much. But if is good and is large, the old weight will be scaled significantly upward (if it got the point wrong) or downward (if it got the point right). In our second example, the middle hyperplane performs quite well on the uniform distribution, so should be reasonably high, which will cause the probability mass on the right cluster to increase and on the two other clusters to decrease. If this is enough to make the right cluster dominate the computation, then the weak learner might output the right hyperplane next. If not, it might output the second hyperplane again. Eventually, the weights will have shifted enough for the third hyperplane to become feasible.
IV
Now let's look at the weights. Let be the usual empirical error of , i.e., . We would like to be a real number, which starts close to for close to and grow indefinitely for close to 0. One possible choice is . You can verify that it has these properties – in particular, recall that is output by a weak learner so that its error is bounded away from by at least . Because of this, is larger than so that is larger than and is larger than .
V
To summarize,
AdaBoost ( : weak learner, : training sequence, )
for do
endfor
return
end
VI
If one assumes that always returns a predictor with error at most (recall that it may fail with probability ), one can derive a bound on the error of the output predictor. Fortunately, the dependence of the sample complexity on is only logarithmic, so can probably be pushed low enough that is unlikely to fail even if it is called times.
Now the error bound one can derive is . Looking at this, it has exactly the properties one would expect: a higher pushes the error down, and so do more rounds of the algorithm. On the other hand, doing more rounds increases the chance of overfitting to random quirks in the training data. Thus, the parameter allows one to balance the overfitting vs. underfitting tradeoff, which is another nice thing about AdaBoost.The book mentions that Boosting has been successfully applied to the task of classifying gray-scale images into 'contains a human face' and 'doesn't contain a human face'. This implies that human faces can be recognized using a set of quantitative rules – but, importantly, rules which have been generated by an algorithm rather than constructed by hand. (In that case, the weak learner did not return hyperplanes, but simple predictors of another form.) In this case, the result fits with my intuition (that face recognition is the kind of task where a set-of-rules approach will work). It would be interesting to know how well boosting performs on other problems.
1 comments
Comments sorted by top scores.
comment by [deleted] · 2020-02-03T19:23:33.889Z · LW(p) · GW(p)
Just wanted to thank you for writing up this series. I've been slowly going through the book on my own. Just finished Chapter 2 and it's awesome to have these notes to review.