Transfer Learning in Humans
post by niplav · 2024-04-21T20:49:42.595Z · LW · GW · 1 commentsContents
I examine the literature on transfer learning in humans. Far
transfer is difficult to achieve, best
candidate interventions are to practice at the edge of one's
ability and make many mistakes,
evaluate mistakes after one has made
them, learn from training programs modeled after expert tacit
knowledg...
Summary
Recommendations
What I Am Looking For
Candidate Interventions
Effective Learning Techniques
What Didn't Work
Far Transfer
Negative Transfer
Error Management Training
Pólya Method
Accelerated Expertise
Inducing Transfer
Dual N-Back and Brain Training
Judgmental Forecasting
Creating Self-Improving Institutions
How I'd Proceed If I Was Further Researching Transfer
Questions
Context
Appendix A: My Impression of the Literature
See Also
None
2 comments
I examine the literature on transfer learning in humans. Far transfer is difficult to achieve, best candidate interventions are to practice at the edge of one's ability and make many mistakes, evaluate mistakes after one has made them, learn from training programs modeled after expert tacit knowledge, and talk about on one's strategies when practicing the domain.
When learning, one would like to progress faster, and learn things faster. So it makes sense to search for interventions that speed up learning (effective learning techniques), enable using knowledge and knowledge patterns from one learned domain in a new domain if appropriate (transfer learning), and make it easier to find further learning-accelerating techniques (meta-learning).
Summary
I've spent ~20 hours reading and skimming papers and parts of books from different fields, and extracting the results from them, resulting spreadsheet here, google doc with notes here.
I've looked at 50 papers, skimmed 20 and read 10 papers and 20% of a book. In this text I've included all sufficiently-different interventions I've found that have been tested empirically.
For interventions tried by scientists I'd classify them into (ordered by how relevant and effective I think they are):
- Error-based learning in which trainees deliberately seek out situations in which they make mistakes. This has medium to large effect sizes at far transfer.
- Long Training Programs: These usually take the form of one- or two-semester long classes on decision-making, basic statistics and spatial thinking, and produce far transfer at small to medium effect sizes. Such programs take a semester or two and are usually tested on high-school students or university students.
- Effective Learning Techniques: Things like doing tests and exercises while learning, or letting learners generate causal mechanisms, which produce zero to or best small amounts of far transfer but speed up learning.
- OODA-loop-likes: Methods that structure the problem-solving process, such as the Pólya method or DMAIC. In most cases, these haven't been tested well or at all, but they are popular in the business context. Also they look all the same to me, but probably have the advantage of functioning as checklists when performing a task.
- Transfer Within Domains: Methods that are supposed to help with getting knowledge about a particular domain from an expert to a trainee, or from training to application on the job. Those methods have a high fixed cost since experts have to be interviewed and whole curricula have to be created, but they work very well at the task they've been created for (where training sometimes is sped up by more than an order of magnitude).
Additionally, most of the research is on subjects which are probably not intrinsically motivated to apply a technique well (i.e. high school students, military trainees, and university students), so there is a bunch of selection pressure on techniques which still work with demotivated subjects. I expect that many techniques work much better with already motivated subjects, especially ones that are easy to goodhart.
In general, the tension I was observing is that industry and the military are the ones who perform well/do non-fake things, but academia are the ones who actually measure and report those measures to the public.
From when I've talked with people from industry, they don't seem at all interested in tracking per-employee performance (e.g. Google isn't running RCTs on their engineers to increase their coding performance, and estimates for how long projects will take are not tracked & scored). I also haven't seen many studies quantifying the individual performance of employees, especially high-earning white collar knowledge-workers.
Recommendations
- If you want to learn faster:
- Make and seek out errors during learning/training. Importance: 7[1]
- Spend a lot of time on practice problems. Importance: 7
- Revisit basics of a field while you're learning. Importance: 4
- Talk about why you're doing what you're doing, while you're doing it. Importance: 3
- If you want to solve problems:
- Try to get feedback on both the process and the outcomes of what you're doing. Importance: 8
- Explicitly analyse errors after you've made them[2]. Importance: 5
- If there are already experts at the problem you're trying to solve, interview them in a systematic fashion to extract their tacit knowledge. Importance: 7
- With enough institutional support this can be turned into a training program.
- If there are no experts in the domain where you're trying to solve a problem.
- Search for related domains and extract existing tacit knowledge there, or learn those domains—the closer the better. Importance: 4
- Apply the Pólya method. Importance: 3
- Understand the problem.
- Devise a plan.
- Carry out the plan.
- Look back.
If you think that these recommendations are kind of unsatisfying, I agree with you.
What I Am Looking For
Given a broad set of skills , I was looking for an intervention/a set of interventions which has the following properties:
- After applying , an average adult can now learn skills from is on average much faster counterfactually to not having applied .
- Applying and learning is easier than just learning all skills .
- is large (or actually encompasses all skills humans have).
- Optional: is relatively easy to apply, that is it doesn't need a lot of institutional setup.
- Optional: can be applied to itself, and to find better interventions that have the same properties as .
Research on transfer learning in humans isn't clearly differentiated from the research into effective learning techniques. Transfer learning and meta-learning are more focused on crossing the theory-practice gap and making progress in domains where we don't yet have detailed knowledge.
Therefore, I tried to find more information from well-performing institutions such as the military and large corporations, de-emphasizing research done in universities and schools (I found this difficult because universities tend to have more incentive to publish their techniques, and also strive to quantify their benefits).
Candidate Interventions
Effective Learning Techniques
I found several studies from psychology, especially educational psychology.
Dunlosky et al. 2017 is the best review of the evidence effective learning techniques I've found. It examines ten candidate interventions, and singles out two interventions as having high utility and two interventions as having moderate utility for tasks similar to learning material in a school-context, e.g. basic biology, basic economics, simple procedure-based mathematics &c.
- High utility:
- Practice testing: Testing oneself on the target domain in a low-stakes context, ideally repeatedly. Think spaced repetition with flashcards, or preparing for exams by doing exams from previous years. They mention that practice testing generalizes across formats (e.g. from simple recall to short answer inference tests). Can generate far transfer. 1. p. 30: "practice testing a subset of information influences memory for related but untested information"
- Distributed practice: Practice that happens spread out over a longer amount of time, instead of cramming. This gain is also captured via spaced repetition. They do not mention any transfer benefits here.
- Moderate utility:
- Elaborative interrogation/Self-explanation[3]:
Generating and saying[4] an explanation for why an
explicitly stated fact or concept is true. This most helps
learners who already know a lot about the target domain, and
works best if it is done during the learning process.
1.
- Interleaved practice: When learning, repeat basic material while learning more advanced material. The advantages over distributed practice testing seems moderate, but (p. 38): "interleaved practice helped students to discriminate between various kinds of problems and to learn the appropriate formula to apply for each one". Works better on mathematics[5].
- Elaborative interrogation/Self-explanation[3]:
Generating and saying[4] an explanation for why an
explicitly stated fact or concept is true. This most helps
learners who already know a lot about the target domain, and
works best if it is done during the learning process.
1.
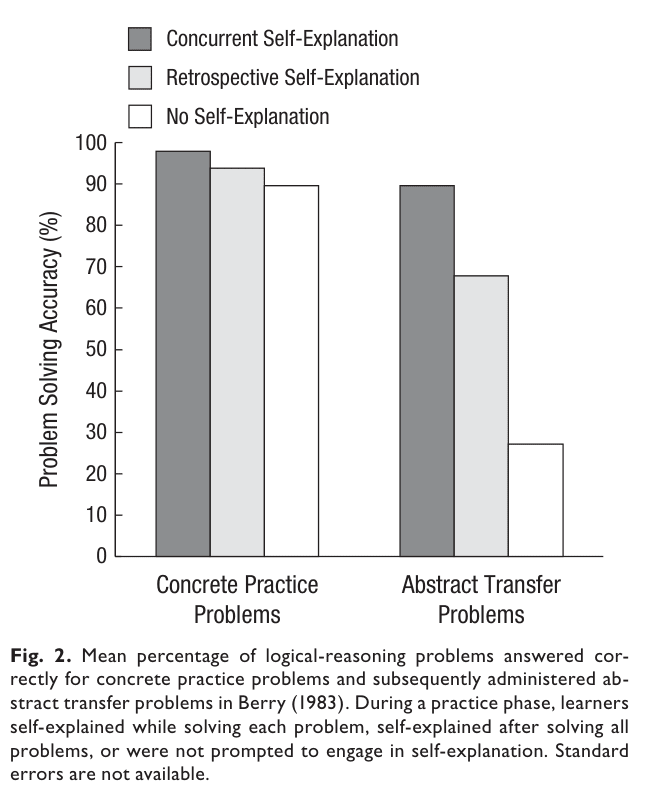
What Didn't Work
The techniques classified as low utility are: summarization of some learned material, highlighting, using keywords/mnemonics, creating imagery for textual material while learning, and re-reading. I'm not surprised at all that highlighting and re-reading aren't effective in a school context. I'm also a little bit surprised that keywords and mnemonics don't work (since they are used very often by competitive mnemonists), as well as for mental imagery, since professional mathematicians so often use visualizations.
I'm moderately intrigued by their finding that summarization doesn't work, since I've heard from several acquaintances that it's good practice, but I think this is because it's very easy to cargo-cult and just paraphrase the previous material.
Far Transfer
Summary: Far transfer occurs if one puts in a lot of effort, e.g. after doing semester- or year-long courses on decision-making and such. The effect sizes on general abilities tests are medium (d≈0.3).
Far transfer is:
improved performance at problems that are similar to but also substantially different from ones experienced during training (e.g., fault diagnosis in process control to fault diagnosis in telecommunication networks).
—Hoffman et al., “Accelerated Expertise”, 2014
One obvious intervention is to have a class in which one person tells other people about how to do good decisions, make tradeoffs, reason about statistical quantities, think spatially and improve mental imagery.
These kinds of interventions have been tried in schools, and they are generally a little bit more effective than I would've expected, yielding medium effect sizes. However, most of the relevant papers that show those medium effect sizes are from the dark period in psychology. I think they look okay[6], but would want to look into them a bit more before making strong conclusions.
The relevant papers are:
- Herrnstein et al. 1986: n=895 Venezuelan high-school students (mean age 13.22 years), controlled trial. Intervention was a year-long course on decision-making (four days a week), others received a control course (it's not clear what this control course was about). Effect sizes on various general intelligence tests are d=0.35 (General Abilities Test), d=0.43 (OLSAT), d=0.11 (CATTELL), all at statistical significance.
- Fong et al. 1986: n=347 adults and high-school students were instructed on the law of large numbers, from just reading a description (control) to working through examples where the law was and was not applicable (intervention). They were then tested on the application of the law to new problems. Effect size was 1 logit (which corresponds to d≈0.55 IIUC).
- Cortes et al. 2022: n=182 high-school students, either (intervention) receiving a semester-long course of geospatial information systems with a CS-focus or (control) not receiving such a course, tested on spatial and verbal problems. Yielded a very small but positive effect (Cohen's f≤0.2).
Negative Transfer
It sometimes happens that training at one domain then reduces performance at another domain. A common example is learning to drive on the right side of the road and then having to drive on the left side.
This doesn't seem to appear very often, but is still interesting from a no-free lunch perspective.
Error Management Training
Summary: If it is obvious that an error has occurred, and errors are affordable, then making errors during training transfers the learned knowledge surprisingly well (d=0.8).
Error Management Training (EMT) is a type of training in which making errors during exploration while learning is actively encouraged. Trainers encourage learners to make errors and reflect on those errors while learning, but don't give much guidance beyond that.
Keith & Frese 2008 perform a meta-analysis analysing studies training participants to use software tools or learn programming languages (n=2183), comparing EMT to training that encourages error-avoidance, and find that EMT has a medium-sized advantage over error-avoiding training methods (d=0.44).
EMT shows larger effect sizes over error-avoiding methods with more demanding transfer: d=0.56 for performance after training, and d=0.8 for transfer that requires modifying learned procedures to fit new contexts (adaptive transfer). This advantage only occurs if there is clear feedback on whether an error has occurred or not.
One is reminded of Umeshisms: If you never fail, you're underperforming.
Anecdotally, when I've tried tutoring someone in programming for fun, I tried to give the person assignments that they would only be able to solve 50% of the time. I don't know whether this is always optimal, but being wrong 50% of the time maximizes the entropy of the reward signal, and combats the problem of sparse rewards.
Pólya Method
Summary: Evidence is pretty scant, but one paper shows suspiciously large effects. Worth investigating for a little bit, especially since it's often recommended by research mathematicians.
Another interesting-looking strand of research were tests of the Pólya method. The Pólya method is a four-step problem-solving method, with the four steps being
- Understand the problem
- Devise a plan
- The book "How to Solve It" also has a list of problem solving strategies
- Carry out the plan
- Look back
This is a variant of the OODA loop, with the difference that a lessened time pressure allows forming a whole plan (not just a decision) and for reflection after carrying out the plan.
The relevant papers all test on learning basic mathematical problem solving skills in plane geometry and fractions, and their results
- Nasir & Syartina 2021: n=32 Indonesian high-school students, non-RCT, only observational. Effect size d=0.71, but that's not super impressive given it's not an RCT.
- Widiana et al. 2018: n=138 elementary school children, RCT. I'm not entirely sure about this, but based on their Table 1 and this calculator I get d=2.4, which I find really hard to believe. I think I'm making a mistake or the paper is fraudulent.
- Hayati et al. 2022: n=40 Indonesian high-school children. This paper is so confusingly written I can't extract any meaning from it.
For some weird reason, the only scientists who have investigated the Pólya method experimentally are Indonesian. I have no idea why.
Accelerated Expertise
Summary: With a lot of institutional support, one can extract knowledge from experts and use it to create better training programs. This requires a large institution to be worth it, but straightforwardly works at achieving its goals.
Accelerated Expertise (Hoffman et al., 2014) was motivated by getting military recruits up to speed quickly before moving them to deployment. It focuses on the case in which there are already experts for a given domain, and one aims to move the skills from domain experts into the mind of new recruits as quickly as possible. They are skeptical that any training can make trainees much better at the domain than experts with a lot of experience.
Chin 2024 summarizes the goals of the research project that lead to the book as attempting to speed up the time from being a beginner at a specific task or set of tasks to being proficient at that task (hence the name "Accelerated Expertise").
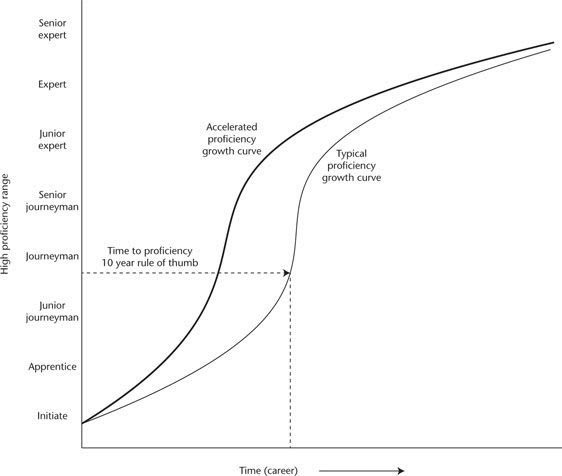
For this, Hoffman et al. have developed a series of multiple steps for creating training programs for new recruits.
- Identify domain experts
- Use Cognitive Task Analysis to extract expert knowledge
- Build a case library of difficult cases
- Turn case library into a set of training simulations
- Optional: Include introspection & reflection in the program
- Optional: Teach abstract/generalized principles
- Test the program
The book contains a literature review on transfer in chapter 5 which afaik is the best collected resource on transfer learning in humans. They summarize the chapter by remarking that not artificially "dumbing down" a domain when a beginner tries to learn it can delay learning in the beginning, but speed up learning in the long run because it prevents misunderstandings from becoming entrenched.
Epistemic Effort: Read 20% of Accelerated Expertise, and skim-read several blogposts based on the book.
Inducing Transfer
Hoffman et al. also summarize the methods for inducing transfer:
Transferring a skill to new situations is often difficult but can be promoted by following a number of training principles: employing deliberate practice, increasing the variability of practice, adding sources of contextual interference, using a mixed practice schedule, distributing practice in time, and providing process and outcome feedback in an explicit analysis of errors.
—Hoffman et al., “Accelerated Expertise” p. 176, 2014
I'd also have liked to dive deeper on extracting expert knowledge, which looks important especially in novel domains like AI alignment.
Dual N-Back and Brain Training
Summary: Increases working memory, but probably not IQ.
I re-read parts of Gwern 2019 and Gwern 2018, and come away with believing that if one is bottlenecked by working memory, n-back is worth it, but it doesn't work well for increasing intelligence. Replication status is mixed.
Judgmental Forecasting
Summary: I didn't find anything on whether learned forecasting ability transfers across domains. The best paper I could find didn't look related at all.
The evidence from the judgmental forecasting research is confusing. On the one hand, it's widely known that domain-level experts are not very good at making predictions about their own domain, and are outcompeted by superforecasters who are just generally good at predicting.
On the other hand, the vibe given by forecasters and forecasting researchers leads to statements like this one:
By the way, there are no shortcuts. Bridge players may develop well-calibrated judgment when it comes to bidding on tricks, but research shows that judgment calibrated in one context transfers poorly, if at all, to another. So if you were thinking of becoming a better political or business forecaster by playing bridge, forget it.
—Philip E. Tetlock & Dan Gardner, “Superforecasting” p. 179, 2015
I tried to find the research this paragraph is talking about by asking in a couple of discord servers and messaging the Forecasting Research Institute, but the response I got referred directly to the bridge finding, which I wouldn't have to expected to work anyway.
I now want to analyze my own judgmental forecasting datasets to figure out how much forecasting ability generalizes across (forecasting) domains.
Creating Self-Improving Institutions
Summary: Organizations can become organizations that improve their governing variables. Inducing this is very tricky. Events that can induce double-loop learning in an organization include a change to leaders which value reflection and dialogue, and the introduction of software tools, such as systems which are used for prediction, which then provide feedback.
Double-loop learning is a method to improve learning of organizations, taking into account the learning process itself.
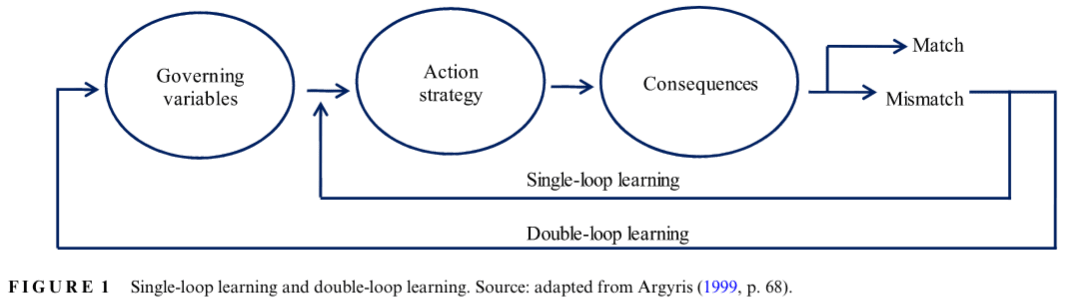
Auqui-Caceres & Furlan 2023 review the evidence on double-loop learning.
They report on several interventions:
- Tested:
- Integrative Double-Kaizen Loop → implemented and saw improvements, but no controls
- Writing and iterating on simulation software ("simulation modeling"/machine learning models) → Induced double-loop learning in two different papers
- Tested, didn't work:
- PIER (Problem-based learning, Interactive multimedia, Experiential learning, and Role-playing) → Allegedly failed because leadership didn't participate
- Briefing-debriefing sessions → Allegedly failed because the tested protocol didn't include communicating up the hierarchy
- Incident-reporting systems → No change observed
- Proposed but, as far as I understand, not tested:
[…] these studies maintain that the most prominent barrier to generate DLL is defensive reasoning and routines (Bochman & Kroth, 2010; Clarke, 2006; Kwon & Nicolaides, 2017; Sisaye & Birnberg, 2010; Stavropoulou et al., 2015; Sterman, 1994; Wong, 2005), which are produced by participants in DLL processes, whenever assumptions underlying taken-for-granted procedures, practices, or policies are challenged. Although people are aware that they should not use defensive reasoning to deal with daily work difficulties and challenges (Thornhill & Amit, 2003), they still use them to avoid losing control and dealing with embarrassment (Mordaunt, 2006).
—Auqui-Caceres & Furlan, “Revitalizing double-loop learning in organizational contexts: A systematic review and research agenda” p. 14, 2023
How I'd Proceed If I Was Further Researching Transfer
One thing I'd like to get clear on is the type I imagine a good intervention for increasing transfer would have.
- Obvious interventions with subtle improvements and details<sub>30%</sub>
- Doing more [LW · GW] of one intervention/combination of existing interventions<sub>30%</sub>
- Really complicated intervention with many moving parts<sub>10%</sub>
- Creative novel approach which no one has thought of before<sub>5%</sub>
- Something else<sub>25%</sub>
Questions
- Is it better to perform elaborative interrogation verbally, or is it as good to write things down?
- What is the optimal amount of "going back to the basics" to deepen understanding over time?
- Spaced repetition schedules are one suggestion, but they're only geared towards remembering, not deepening understanding.
- When learning a domain, what determines the frontier at which one should be trying to improve?
- Is it best to make mistakes 50% of the time, or less often, or more often?
- How much does this depend on the domain in question?
- Do people generalize within judgmental forecasting, across question asking domains?
- Why do so many papers I've found to gravitate to the "better learning techniques" bucket?
- Accelerated expertise falls outside of that category, as would things like physical exercise before learning, or meditation, or pharmaceutical interventions.
- Which techniques do really successful consultancies or investment firms use for problem-solving ability?
- To what extent do existing interventions also try to tackle low motivation?
- Given people who are already motivated, would the profile of successful interventions look different?
- Which interventions would be better?
- Under which conditions does negative transfer happen?
- Could it be that negative transfer is more common than normally though?
Context
This review was written after Raemon [LW · GW] comissioned me to research transfer learning in humans, in the context of his new project on feedback-loop-first rationality.
Appendix A: My Impression of the Literature
After spending a dozen hours researching this area, my current impression is that this is something that too many different fields are interested in; among them are business people, military psychologists, education researchers, neuroscientists, cognitive psychologists…
This results in a wild outgrowth of terminology: "transfer of learning", "learning to learn", "deutero-learning", "double-loop learning", "design thinking", "adaptive learning" &c. In my research I don't think I've encountered a paper being cited by two different papers, which suggests there's more than a thousand papers grasping at the same question of transfer learning.
See Also
- Ricón 2020 on a DARPA study with a digital tutor for a specific domain, showing d=2.81 improvement
- Meta-Learning: Learning to Learn Fast (Weng, 2018)
- Meta Reinforcement Learning (Weng, 2019)
The importance scores are purely subjective. ↩︎
Since everything is judgmental-forecasting-shaped, one could test this by letting forecasters elaborate on their forecasts and at resolution time analyse their elaborations. I've tried doing this but it fell off for other projects. ↩︎
The two techniques are treated separately in the paper, but as far as I can tell mostly for historical reasons. ↩︎
Judging from Dunlosky et al. 2017 the participants in the various studies were asked to verbally explain their reasoning. It's not said how writing the explanation instead of saying it compares. ↩︎
This is supported by the theory of transfer-appropriate processing, which puts an especially strong emphasis on the encoding and retrieval of learned information. As far as I understand, the recapitulation of basic knowledge in the context of more advanced knowledge allows for a more accurate re-encoding of the basic knowledge. This also tracks with my experience of learning mathematics: I've gotten more mileage out of understanding basic concepts deeply (e.g. how probabilities, logits and bits fit together), than understanding more advanced concepts shallowly. ↩︎
I have some quibbles about the randomization in Herrnstein et al. 1986 (which happens on a class-level and not on an individual level), and the way effect sizes are measured in Fong et al. 1986. ↩︎
1 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2024-04-22T13:58:20.825Z · LW(p) · GW(p)
From when I've talked with people from industry, they don't seem at all interested in tracking per-employee performance (e.g. Google isn't running RCTs on their engineers to increase their coding performance, and estimates for how long projects will take are not tracked & scored).
FWIW Joel Spolsky suggests that people managing software engineers should have detailed schedules, and says big companies have up-to-date schedules, and built a tool to leverage historical data for better schedules. At my old R&D firm, people would frequently make schedules and budgets for projects, and would be held to account if their estimates were bad, and I got a strong impression that seasoned employees tended to get better at making accurate schedules and budgets over time. (A seasoned employee suggested to me a rule-of-thumb for novices, that I should earnestly try to make an accurate schedule, then go through the draft replacing the word “days” with “weeks”, and “weeks” with “months”, etc.) (Of course it’s possible for firms to not be structured such that people get fast and frequent feedback on the accuracy of their schedules and penalties for doing a bad job, in which case they probably won’t get better over time.)
I guess what’s missing is (1) systemizing scheduling so that it’s not a bunch of heuristics in individual people’s heads (might not be possible), (2) intervening on employee workflows etc. (e.g. A/B testing) and seeing how that impacts productivity.
Practice testing
IIUC the final “learning” was assessed via a test. So you could rephrase this as, “if you do the exact thing X, you’re liable to get better at doing X”, where here X=“take a test on topic Y”. (OK, it generalized “from simple recall to short answer inference tests” but that’s really not that different.)
I'm also a little bit surprised that keywords and mnemonics don't work (since they are used very often by competitive mnemonists)
I invent mnemonics all the time, but normal people still need spaced-repetition or similar to memorize the mnemonic. The mnemonics are easier to remember (that’s the point) but “easier” ≠ effortless.
As another point, I think a theme that repeatedly comes up is that people are much better at learning things when there’s an emotional edge to them—for example:
- It’s easier to remember things if you’ve previously brought them up in an argument with someone else.
- It’s easier to remember things if you’ve previously gotten them wrong in public and felt embarrassed.
- It’s easier to remember things if you’re really invested in and excited by a big project and figuring this thing out will unblock the project.
This general principle makes obvious sense from an evolutionary perspective (it’s worth remembering a lion attack, but it’s not worth remembering every moment of a long uneventful walk), and I think it’s also pretty well understood neuroscientifically (physiological arousal → more norepinephrine, dopamine, and/or acetylcholine → higher learning rates … something like that).
As another point, I’m not sure there’s any difference between “far transfer” and “deep understanding”. Thus, the interventions that you said were helpful for far transfer seem to be identical to the interventions that would lead to deep understanding / familiarity / facility with thinking about some set of ideas. See my comment here [LW(p) · GW(p)].