The latest addition to OpenAI’s Pro offerings is their version of Deep Research.
Have you longed for 10k word reports on anything your heart desires, 100 times a month, at a level similar to a graduate student intern? We have the product for you.
OpenAI: Today we’re launching deep research in ChatGPT, a new agentic capability that conducts multi-step research on the internet for complex tasks. It accomplishes in tens of minutes what would take a human many hours.
Sam Altman: Today we launch Deep Research, our next agent.
This is like a superpower; experts on demand!
It can use the Internet, do complex research and reasoning, and give you a report.
It is quite good and can complete tasks that would take hours or days and cost hundreds of dollars.
People will post many excellent examples, but here is a fun one:
I am in Japan right now and looking for an old NSX. I spent hours searching unsuccessfully for the perfect one. I was about to give up, and Deep Research just… found it.
It is very compute-intensive and slow, but it is the first AI system that can do such a wide variety of complex, valuable tasks.
Going live in our Pro tier now, with 100 queries per month.
Plus, Team and Enterprise tiers will come soon, and then a free tier.
This version will have something like 10 queries per month in our Plus tier and a very small number in our free tier, but we are working on a more efficient version.
(This version is built on o3.)
Give it a try on your hardest work task that can be solved just by using the Internet and see what happens.
Or:
Sam Altman: 50 cents of compute for 500 dollars of value
Sarah (YuanYuanSunSara): Deepseek do it for 5 cents, 500 dollar value.
Perhaps DeepSeek will quickly follow suit, perhaps they will choose not to. The important thing about Sarah’s comment is that there is essentially no difference here.
If the report really is worth $500, then the primary costs are:
Figuring out what you want.
Figuring out the prompt to get it.
Reading the giant report.
NOT the 45 cents you might save!
If the marginal compute cost to me really is 50 cents, then the actual 50 cents is chump change. Even a tiny increase in quality matters so much more.
This isn’t true if you are using the research reports at scale somehow, generating them continuously on tons of subjects and then feeding them into o1-pro for refinement and creating some sort of AI CEO or what not. But the way that all of us are using DR right now, in practice? All that matters is the report is good.
Here was the livestream announcement, if you want it. I find these unwatchable.
It’s Coming
Dan Hendrycks: It looks like the latest OpenAI model is very doing well across many topics. My guess is that Deep Research particularly helps with subjects including medicine, classics, and law.
Kevin Roose: When I wrote about Humanity’s Last Exam, the leading AI model got an 8.3%. 5 models now surpass that, and the best model gets a 26.6%.
That was 10 DAYS AGO.
Buck Shlegeris: Note that the questions were explicitly chosen to be adversarial to the frontier models available at the time, which means that models released after HLE look better than they deserve.
Having browsing and python tools and CoT all are not an especially fair fight, and also this is o3 rather than o3-mini under the hood, but yeah the jump to 26.6% is quite big, and confirms why Sam Altman said that soon we will need another exam. That doesn’t mean that we will pass it.
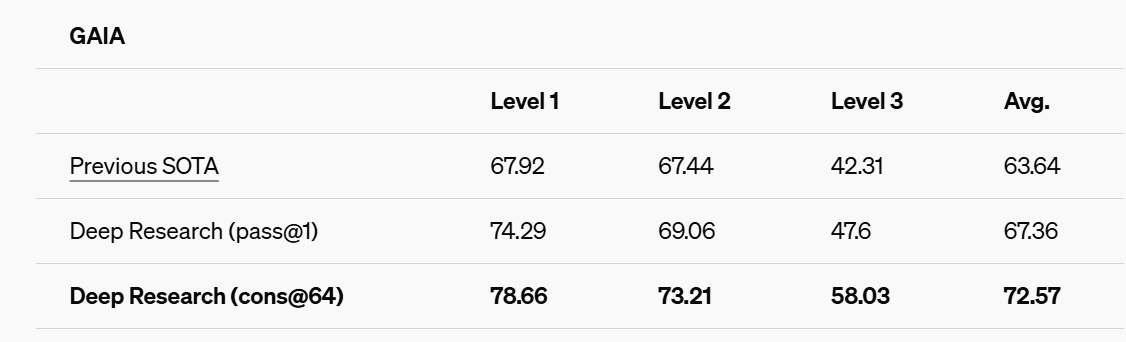
OAI-DR is also the new state of the art on GAIA, which evaluates real-world questions.
They shared a few other internal scores, but none of the standard benchmarks other than humanity’s last exam, and they did not share any safety testing information, despite this being built on o3.
Currently Pro users get 100 DR queries per month, Plus and Free get 0.
Is It Safe?
I mean, probably. But how would you know?
It is a huge jump on Humanity’s Last Exam. There’s no system card. There’s no discussion of red teaming. There’s not even a public explanation of why there’s no public explanation.
This was released literally two days after they released the o3-mini model card, to show that o3-mini is a safe thing to release, in which they seem not to have used Deep Research as part of their evaluation process. Going forward, I think it is necessary to use Deep Research as part of all aspects of the preparedness framework testing for any new models, and that this should have also been done with o3-mini.
Then two days later, without a system card, they released Deep Research, which is confirmed to be based upon the full o3.
I see this as strongly against the spirit of the White House and Seoul commitments to release safety announcements for ‘all new significant model public releases.’
Miles Brundage: Excited to try this out though with a doubling on Humanity’s Last Exam and o3-mini already getting into potentially dangerous territory on some capabilities, I’m sad there wasn’t a system card or even any brief discussion of red teaming.
OpenAI: In the coming weeks and months, we’ll be working on the technical infrastructure, closely monitoring the current release, and conducting even more rigorous testing. This aligns with our principle of iterative deployment. If all safety checks continue to meet your release standards, we anticipate releasing deep research to plus users in about a month.
Miles Brundage: from the post – does this mean they did automated evals but no RTing yet, or that once they start doing it they’ll stop deployment if it triggers a High score? Very vague. Agree re: value of iterative deployment but that doesn’t mean “anything goes as long as it’s 200/month”.
So where is the model card and safety information for o3?
Well, their basic answer is ‘this is a limited release and doesn’t really count.’ With the obvious (to be clear completely unstated and not at all confirmed) impression that this was rushed out due to r1 to ensure that the conversation and vibe shifted.
I reached out officially, and they gave me this formal statement (which also appears here):
OpenAI: We conducted rigorous safety testing, preparedness evaluations and governance reviews on the early version of o3 that powers deep research, identifying it as Medium risk.
We also ran additional safety testing to better understand incremental risks associated with deep research’s ability to browse the web, and we have added new mitigations.
We will continue to thoroughly test and closely monitor the current limited release.
We will share our safety insights and safeguards for deep research in a system card when we widen access to Plus users.
We do know that the version of o3 (again, full o3) in use tested out as Medium on their preparedness framework and went through the relevant internal committees, which would allow them to release it. But that’s all we know.
They stealth released o3, albeit in a limited form, well before it was ready.
I also have confirmation that the system card will be released before they make Deep Research more widely available (and presumably before o3 is made widely available), and that this is OpenAI’s understanding of its obligations going forward.
They draw a clear distinction between Plus and Free releases or API access, which invokes their disclosure obligations, and limited release only to Pro users, which does not. They do their safety testing under the preparedness framework before even a limited release. However, they consider their obligations to share safety information only to be invoked when a new model is made available to Plus or Free users, or to API users.
I don’t see that as the right distinction to draw here, although I see an important one in API access vs. chatbot interface access. Anyone can now pay the $200 (perhaps with a VPN) and use it, if they want to do that, and in practice multi-account for additional queries if necessary. This is not that limited a release in terms of the biggest worries.
The silver lining is that this allows us to have the discussion now.
I am nonzero sympathetic to the urgency of the situation, and to the intuition that this modality combined with the limited bandwidth and speed renders the whole thing Mostly Harmless.
But if this is how you act under this amount of pressure, how are you going to act in the future, with higher stakes, under much more pressure?
Presumably not so well.
How Does Deep Research Work?
Bob McGrew (OpenAI): The important breakthrough in OpenAI’s Deep Research is that the model is trained to take actions as part of its CoT. The problem with agents has always been that they can’t take coherent action over long timespans. They get distracted and stop making progress.
That’s now fixed.
I do notice this is seemingly distinct from Gemini’s Deep Research. With Gemini’s version, first it searches for sources up front, which it shows to you. Then it compiles the report. OpenAI’s version will search for sources and otherwise take actions as it needs to look for them. That’s a huge upgrade.
Under the hood, we know it’s centrally o3 plus reinforcement learning with the ability to take actions during the chain of thought. What you get from there depends on what you choose as the target.
Killer Shopping App
This is clearly not the thing everyone had in mind, and it’s not the highest value use of a graduate research assistant, but I totally buy that it is awesome at this:
Greg Brockman: Deep Research is an extremely simple agent — an o3 model which can browse the web and execute python code — and is already quite useful.
It’s been eye-opening how many people at OpenAI have been using it as a much better e-commerce search in particular.
E-commerce search is a perfect application. You don’t care about missing some details or a few hallucinations all that much if you’re going to check its work afterwards. You usually don’t need the result right now. But you absolutely want to know what options are available, where, at what price, and what features matter and what general reviews look like and so on.
In the past I’ve found this to be the best use case for Gemini Deep Research – it can compare various offerings, track down where to buy them, list their features and so on. This is presumably the next level up for that.
If I could buy unlimited queries at $0.50 a pop, I would totally do this. The question then becomes, right now, that you get 100 queries a month for $200 (along with operator and o1-pro), but you can’t then add more queries on the margin. So the marginal query might be worth a lot more to you than $0.50.
Rave Reviews
Not every review is a rave, but here are some of the rave reviews.
Drerya Unutmaz: I asked Deep Research to assist me on two cancer cases earlier today. One was within my area of expertise & the other was slightly outside it. Both reports were simply impeccable, like something only a specialist MD could write! There’s a reason I said this is a game-changer!
I can finally reveal that I’ve had early access to @OpenAI’s Deep Research since Friday & I’ve been using it nonstop! It’s an absolute game-changer for scientific research, publishing, legal documents, medicine, education-from my tests but likely many others. I’m just blown away!
Yes I did [use Google’s DR] and it’s very good but this is much better! Google needs will need to come up with their next model.
Danielle Fong: openai deep research is incredible
Siqi Chen: i’m only a day in so far but @openai’s deep research and o3 is exceeding the value of the $150K i am paying a private research team to research craniopharyngioma treatments for my daughter.
$200/mo is an insane ROI.grateful to @sama and the @OpenAI team.
feature request for @sama and @OpenAI:
A lot of academic articles are pay walled, and I have subscriptions to just about every major medical journal now.
It would be game changing if i could connect all my credentials to deep research so it can access the raw papers.
Aaron Levie: Can confirm OpenAI Deep Research is quite strong. In a few minutes it did what used to take a dozen hours. The implications to knowledge work is going to be quite profound when you just ask an AI Agent to perform full tasks for you and come back with a finished result.
The ultimate rave review is high willingness to pay.
xjdr: in limited testing, Deep research can completely replace me for researching things i know nothing about to start (its honestly probably much better and certainly much faster). Even for long reports on things i am fairly knowledgeable about, it competes pretty well on quality (i had it reproduce some recent research i did with a few back and forth prompts and compared notes). i am honestly pretty shocked how polished the experience is and how well it works.
I have my gripes but i will save them for later. For now, i will just say that i am incredibly impressed with this release.
To put a finer point on it, i will happily keep paying $200 / month for this feature alone. if they start rate limiting me, i would happily pay more to keep using it.
You Jiacheng: is 100/month enough?
xjdr: I’m gunna hit that today most likely.
My question is, how does xjdr even have time to read all the reports? Or is this a case of feeding them into another LLM?
Paul Calcraft: Very good imo, though haven’t tested it on my own areas of expertise yet.
Oh shit. Deep Research + o1-pro just ~solved this computer graphics problem
Things that didn’t work:
R1/C3.5/o1-pro
Me :(
OpenAI Deep Research answer + C3.5 cursor
Needed Deep Research *and* an extra o1-pro step to figure out correct changes to my code given the research
Kevin Bryan: The new OpenAI model announced today is quite wild. It is essentially Google’s Deep Research idea with multistep reasoning, web search, *and* the o3 model underneath (as far as I know). It sometimes takes a half hour to answer.
So related to the tariff nuttiness, what if you wanted to read about the economics of the 1890 McKinley tariff, drawing on modern trade theory? I asked Deep Research to spin up a draft, with a couple paragraphs of guidance, in Latex, with citations.
How good can it do literally one shot? I mean, not bad. Honestly, I’ve gotten papers to referee that are worse than this. The path from here to steps where you can massively speed up pace of research is really clear. You can read yourself here.
I tried to spin up a theory paper as well. On my guidance on the problem, it pulled a few dozen papers, scanned them, then tried to write a model in line with what I said.
It wasn’t exactly what I wanted, and is quite far away from even one novel result (basically, it gave me a slight extension of Scotchmer-Green). But again, the path is very clear, and I’ve definitely used frontier models to help prove theorems already.
…
I think the research uses are obvious here. I would also say, for academia, the amount of AI slop you are about to get is *insane*. In 2022, I pointed out that undergrads could AI their way to a B. I am *sure* for B-level journals, you can publish papers you “wrote” in a day.
Research Reports
Now we get to the regular reviews. The general theme is, it will give you a lot of text most of it accurate, but not all, and it will have some insights but pile the slop and unimportant stuff high on top of it without noticing which is which. It’s the same as Gemini’s Deep Research, only more so, and generally stronger but slower. That is highly useful, if you know how to use it.
Abu El Banat: Tested on several questions. Where I am a professional expert, it gave above average grad student summer intern research project answers — covered all the basics, lacked some domain-specific knowledge to integrate the new info helpfully, but had 2-3 nuggets of real insight.
It found several sources of info in my specialty online that I did not know were publicly accessible.
On questions where I’m an amateur, it was extremely helpful. It seemed to shine in tasks like “take all my particulars into account, research all options, and recommend.”
Ethan Mollick: Prompt: I need a report on evolution in TTRPGs, especially the major families of rules that have evolved over the past few years, and the emblematic games of each. make it an interesting read with examples of gameplay mechanics. start with the 1970s but focus most on post 20102. all genres, all types, no need for a chart unless it helps, but good narratives with sections contrasting examples of how the game might actually play. maybe the same sort of gameplay challenge under different mechanics?
To me there are mostly two speeds, ‘don’t care how I want it now,’ and ‘we have all the time in the world.’ Once you’re coming back later, 5 minutes and an hour are remarkably similar lengths. If it takes days then that’s a third level.
Colin Fraser asks, who would each NBA team most likely have guard LeBron James? It worked very hard on this, and came back with answer that often included players no longer on the team, just like o1 often does. Colin describes this as a lack of agency problem, that o3 isn’t ensuring they have an up to date set of rosters as a human would. I’m not sure that’s the right way to look at it? But it’s not unreasonable.
Kevin Roose: Asked ChatGPT Deep Research to plan this week’s Hard Fork episode and it suggested a segment we did last week and two guests I can’t stand, -10 points on the podcast vibes eval.
Shakeel: Name names.
Ted tries it in a complex subfield he knows well, finds 90% coherent high level summary of prior work and 10% total nonsense that a non-expert wouldn’t be able to differentiate, and he’s ‘not convinced it “understands” what is going on.’ That’s a potentially both highly useful and highly dangerous place to be, depending on the field and the user.
Here’s one brave user:
Simeon: Excellent for quick literature reviews in literature you barely know (able to give a few example papers) but don’t know much about.
And one that is less brave on this one:
Siebe: Necessary reminder to test features like this in areas you’re familiar with. “It did a good job of summarizing an area I wasn’t familiar with.”
No, you don’t know that. You don’t have the expertise to judge that.
Steve Sokolowski: ‘m somewhat disappointed by @OpenAI’s Deep Research. @sama promised it was a dramatic advance, so I entered the complaint for our o1 pro-guided lawsuit against @DCGco and others into it and told it to take the role of Barry Silbert and move to dismiss the case.
Unfortunately, while the model appears to be insanely intelligent, it output obviously weak arguments because it ended up taking poor-quality source data from poor-quality websites. It relied upon sources like reddit and those summarized articles that attorneys write to drive traffic to their websites and obtain new cases.
The arguments for dismissal were accurate in the context of the websites it relied upon, but upon review I found that those websites often oversimplified the law and missed key points of the actual laws’ texts.
When the model based its arguments upon actual case text, it did put out arguments that seemed like they would hold up to a judge. One of the arguments was exceptional and is a risk that we are aware of.
But except for that one flash of brilliance, I got the impression that the context window of this model is small. It “forgot” key parts of the complaint, so its “good” arguments would not work as a defense.
…
The first problem – the low quality websites – should be able to be solved with a system prompt explaining what types of websites to avoid. If they already have a system prompt explaining that, it isn’t good enough.
Deep Research is a model that could change the world dramatically with a few minor advances, and we’re probably only months from that.
This is a problem for every internet user, knowing what sources to trust. It makes sense that it would be a problem for DR’s first iteration. I strongly agree that this should improve rapidly over time.
Dan Hendrycks is not impressed when he asks for feedback on a paper draft, finding it repeatedly claiming Dan was saying things he didn’t say, but as he notes this is mainly a complaint about the underlying o3 model. So given how humans typically read AI papers, it’s doing a good job predicting the next token? I wonder how well o3’s misreads correlate with human ones.
With time, you can get a good sense of what parts can be trusted versus what has to be checked, including noticing which parts are too load bearing to risk being wrong.
Gallabytes is unimpressed so far but suspects it’s because of the domain he’s trying.
Gallabytes: so far deep research feels kinda underwhelming. I’m sure this is to some degree a skill issue on my part and to some degree a matter of asking it about domains where there isn’t good literature coverage. was hoping it could spend more time doing math when it can’t find sources.
ok let’s turn this around. what should I be using deep research for? what are some domains where you’ve seen great output? so far ML research ain’t it too sparse (and maybe too much in pdfs? not at all obvious to me that it’s reading beyond the abstracts on arxiv so far).
Carlos: I was procrastinating buying a new wool overcoat, and I hate shopping. So I had it look for one for me and make a page I could reference (the html canvas had to be a follow-up message, for some reason Research’s responses aren’t using even code backticks properly atm) I just got back from the store with my new coat.
Peter Wildeford: Today’s mood: Using OpenAI Deep Research to automate some of my job to save time to investigate how well OpenAI Deep Research can automate my job.
…Only took me four hours to get to this point, looks like you get 20 deep research reports per day
Tyler John: Keen to learn from your use of the model re: what it’s most helpful for.
Peter Wildeford: I’ll have more detailed takes on my Substack but right now it seems most useful for “rapidly get a basic familiarity with a field/question/problem”
It won’t replace even an RA or fellow at IAPS, but it is great at grinding through 1-2 hours of initial desk research in ~10min.
Tyler John: “it won’t replace even an RA” where did the time go
Peter Wildeford: LOL yeah but the hype is honestly that level here on Twitter right now
It’s good for if you don’t have all the PDFs in advance
The ability to ask follow up questions actually seems sadly lacking right now AFAICT
If you do have the PDFs in advance and have o1-pro and can steer the o1-pro model to do a more in-depth report, then I think Deep Research doesn’t add much more on top of that
Ethan Mollick: Having access to a good search engine and access to paywalled content is going to be a big deal in making AI research agents useful.
Kevin Bryan: Playing with Operator and both Google’s Deep Research and OpenAI’s, I agree with Ethan: access to gated documents, and a much better inline pdf OCR, will be huge. The Google Books lawsuit which killed it looks like a massive harm to humanity and science in retrospect.
And of course it will need all your internal and local stuff as well.
Note that this could actually be a huge windfall for gated content.
Suppose this integrated the user’s subscriptions, so you got paywalled content if and only if you were paying for it. Credentials for all those academic journals now look a lot more enticing, don’t they? Want the New York Times or Washington Post in your Deep Research? Pay up. Maybe it’s part of the normal subscription. Maybe it’s a less. Maybe it’s more.
And suddenly you can get value out of a lot more subscriptions, especially if the corporation is fitting the bill.
Arthur B is happy with his first query, disappointed with the one on Tezos where he knows best, is hoping it’s data quality issues rather than Gel-Men Amnesia.
Deric Cheong finds it better than Gemini DRon economic policies for a post-AGI society. I checked out the report, which takes place in the strange ‘economic normal under AGI’ idyllic Christmasland that economists insist on as our baseline future, where our worries are purely mundane things like concentration of wealth and power in specific humans and the need to ensure competition.
So you get proposals such as ‘we need to ensure that we have AGIs and AGI offerings competing against each other to maximize profits, that’ll ensure humans come out okay and totally not result by default in at best gradual disempowerment.’ And under ‘drawbacks’ you get ‘it requires global coordination to ensure competition.’ What?
We get all the classics. Universal basic income, robot taxes, windfall taxes, capital gains taxes, ‘workforce retraining and education’ (workforce? Into ‘growth fields’? What are these ‘growth fields’?), shorten the work week, mandatory paid leave (um…), a government infrastructure program, giving workers bargaining power, ‘cooperative and worker ownership’ of what it doesn’t call ‘the means of production,’ data dividends and rights, and many more.
All of which largely comes down to rearranging deck chairs on the Titanic, while the Titanic isn’t sinking and actually looks really sharp but also no one can afford the fare. It’s stuff that matters on the margin but we won’t be operating on the margin, we will be as they say ‘out of distribution.’
Alternatively, it’s a lot of ways of saying ‘redistribution’ over and over with varying levels of inefficiency and social fiction. If humans can retain political power and the ability to redistribute real resources, also known as ‘retain control over the future,’ then there will be more than enough real resources that everyone can be economically fine, whatever status or meaning or other problems they might have. The problem is that the report doesn’t raise that need as a consideration, and if anything the interventions here make that problem harder not easier.
But hey, you ask a silly question, you get a silly answer. None of that is really DR’s fault, except that it accepted the premise. So, high marks!
Perfecting the Prompt
Nabeel Qureshi: OpenAI’s Deep Research is another instance of “prompts matter more now, not less.” It’s so powerful that small tweaks to the prompt end up having large impacts on the output. And it’s slow, so mistakes cost you more.
I expect we’ll see better ways to “steer” agents as they’re working, e.g. iterative ‘check-ins’ or CoT inspection. Right now it’s very easy for them to go off piste.
It reminds me of the old Yudkowsky point: telling the AI *exactly* what you want is quite hard, especially as the request gets more complex and as the AI gets more powerful.
Someone should get on this, and craft at least a GPT or instruction you can give to o3-mini-high or o1-pro (or Claude Sonnet 3.6?), that will take your prompt and other explanations, ask you follow-ups if needed, and give you back a better prompt, and give you back a prediction of what to expect so you can refine and such.
Noam Brown: @OpenAI Deep Research might be the beginning of the end for Wikipedia and I think that’s fine. We talk a lot about the AI alignment problem, but aligning people is hard too. Wikipedia is a great example of this.
There are problems with Wikipedia, but these two things are very much not substitutes. Here are some facts about Wikipedia that don’t apply to DR and aren’t about to any time soon.
Wikipedia is highly reliable, at least for most purposes.
Wikipedia can be cited as reliable source to others.
Wikipedia is the same for everyone, not sensitive to input details.
Wikipedia is carefully workshopped to be maximally helpful and efficient.
Wikipedia curates the information that is notable, gets rid of the slop.
Wikipedia is there at your fingertips for quick reference.
Wikipedia is the original source, a key part of training data. Careful, Icarus.
And so on. These are very different modalities.
Noam Brown: I’m not saying people will query a Deep Research model every time they want to read about Abraham Lincoln. I think models like Deep Research will eventually be used to pre-generate a bunch of articles that can stored and read just like Wikipedia pages, but will be higher quality.
I don’t think that is a good idea either. Deep Research is not a substitute for Wikipedia. Deep Research is for when you can’t use Wikipedia, because what you want isn’t notable and is particular, or you need to know things with a different threshold of reliability than Wikipedia’s exacting source standards, and so on. You’re not going to ‘do better’ than Wikipedia at its own job this way.
Eventually, of course, AI will be better at every cognitive task than even the collective of humans, so yes it would be able to write a superior Wikipedia article at that point, or something that serves the same purpose. But at that point, which is fully AGI-complete, we have a lot of much bigger issues to consider, and OAI-DR-1.0 won’t be much of a ‘beginning of the end.’
Another way of putting this is, you’d love a graduate research assistant, but you’d never tell them to write a Wikipedia article for you to read.
Here’s another bold claim.
Sam Altman: congrats to the team, especially @isafulf and @EdwardSun0909, for building an incredible product.
my very approximate vibe is that it can do a single-digit percentage of all economically valuable tasks in the world, which is a wild milestone.
Can Deep Research do 1% of all economically valuable tasks in the world?
With proper usage, I think the answer is yes. But I also would have said the same thing about o1-pro, or Claude Sonnet 3.5, once you give them a little scaffolding.
Poll respondents disagreed, saying it could do between 0.1% and 1% of tasks.
What’s Next?
We have Operator. We have two versions of Deep Research. What’s next?
Stephen McAleer (OpenAI): Deep research is emblematic of a new wave of products that will be created by doing high-compute RL on real-world tasks.
If you can Do Reinforcement Learning To It, and it’s valuable, they’ll build it. The question is, what products might be coming soon here?
o1’s suggestions were legal analysis, high-frequency trading, medical diagnosis, supply chain coordination, warehouse robotics, personalized tutoring, customer support, traffic management, code generation and drug discovery.
That’s a solid list. The dream is general robotics but that’s rather a bit trickier. Code generation is the other dream, and that’s definitely going to step up its game quickly.
The main barrier seems to be asking what people actually want.
I’d like to see a much more precise version of DR next. Instead of giving me a giant report, give me something focused. But probably I should be thinking bigger.
Paying the Five
Should you pay the $200?
For that price, you now get:
o1-pro.
Unlimited o3-mini-high and o1.
Operator.
100 queries per month on Deep Research.
When it was only o1-pro, I thought those using it for coding or other specialized tasks where it excels should clearly pay, but it wasn’t clear others should pay.
Now that the package has expanded, I agree with Sam Altman that the value proposition is much improved, and o3 and o3-pro will enhance it further soon.
I notice I haven’t pulled the trigger yet. I know it’s a mistake that I haven’t found ways to want to do this more as part of my process. Just one more day, maybe two, to clear the backlog, I just need to clear the backlog. They can’t keep releasing products like this.
Right?
The Lighter Side
Depends what counts? As long as it doesn’t need to be cutting edge we should be fine.
Andrew Critch: I hope universal basic income turns out to be enough to pay for a Deep Research subscription.
A story I find myself in often:
Miles Brundage: Man goes to Deep Research, asks for help with the literature on trustworthy AI development.
Deep Research says, “You are in luck. There is relevant paper by Brundage et al.”
Man: “But Deep Research…”
If the report really is worth $500, then the primary costs are:
Figuring out what you want.
Figuring out the prompt to get it.
Reading the giant report.
NOT the 45 cents you might save!
When are we getting agents that are better at figuring out what we want? THAT would be a huge time saver. Of course it's a joke but I think it will become a bootle neck at some point and then we will start to give ai higher level goals and things will get weird
The actual SOTA (Jan 29, 2025, Trase Agent v0.3) is 70.3 average, 83.02 Level 1, 69.77 Level 2, 46.15 Level 3.
In the relatively easiest Tier 1 category, this SOTA is clearly better than the numbers reported even for Deep Research (pass@64), and this SOTA is generally slightly better than Deep Research (pass@1) except for Level 3.

I can finally reveal that I’ve had early access to @OpenAI’s Deep Research since Friday & I’ve been using it nonstop! It’s an absolute game-changer for scientific research, publishing, legal documents, medicine, education-from my tests but likely many others. I’m just blown away! Yes I did [use Google’s DR] and it’s very good but this is much better! Google needs will need to come up with their next model. Danielle Fong: openai deep research is incredible Siqi Chen: i’m only a day in so far but @openai’s deep research and o3 is exceeding the value of the $150K i am paying a private research team to research craniopharyngioma treatments for my daughter. $200/mo is an insane ROI.grateful to @sama and the @OpenAI team. feature request for @sama and @OpenAI: A lot of academic articles are pay walled, and I have subscriptions to just about every major medical journal now. It would be game changing if i could connect all my credentials to deep research so it can access the raw papers.

