Teaching ML to answer questions honestly instead of predicting human answers
post by paulfchristiano · 2021-05-28T17:30:03.304Z · LW · GW · 18 commentsContents
The problem Aside on imitative generalization Step 1: make the intended model pay for itself Intuition Rough plan Why might this work? The actual algorithm Step 2: Give the intended model a leg up Step 3: Make the training set good enough None 18 comments
(Note: very much work in progress, unless you want to follow along with my research you'll probably want to wait for an improved/simplified/clarified algorithm.)
In this post I consider the particular problem of models learning “predict how a human would answer questions” instead of “answer questions honestly.” (A special case of the problem from Inaccessible Information.)
I describe a possible three-step approach for learning to answer questions honestly instead:
- Change the learning process so that it does not have a strong inductive bias towards “predict human answers,” by allowing the complexity of the honest question-answering to “pay for itself” by constraining the space of possible human-models.
- Introduce a bias towards the intended model by using a more complex labeling process to answer questions where a human answers incorrectly.
- Be really careful to avoid penalizing honest answers, by only judging comparisons between two answers where we are confident one is better than the other and getting the model to help us.
I don’t know whether this problem is a relatively unimportant special case of alignment, or one of the core difficulties. In any case, my next step will be trying to generate failure stories that definitely cannot be addressed by any of the angles of attack I know so far (including the ones in this post).
I think it’s relatively unlikely that almost anything specific I said here will really hold up over the long term, but I do think I’ve learned something about each of these steps. If the ideas end up being important then you can expect a future post with a simpler algorithm, more confidence that it works, clearer definitions, and working code.
(Thanks to Ajeya Cotra, David Krueger, and Mark Xu for discussions about this post that helped clarify it.)
The problem
Suppose that we train a model to answer questions in natural language about what will happen in the future (“Will Alice take the train home tonight?”) given a data about what’s happened in the recent past (e.g. video recorded over the last few days).
To generate training data we take the video from time t₀ to t₁ and get humans to answer questions about what happened between time t₁ and t₂. Then we do supervised learning on these (video, question, answer) triples.
The intended model has two parts: (i) a model of the world (and inference algorithm), (ii) a translation between the world-model and natural language. The intended model answers questions by translating them into the internal world-model.
We want the intended model because we think it will generalize “well.” For example, if the world model is good enough to correctly predict that someone blackmails Alice tomorrow, then we hope that the intended model will tell us about the blackmail when we ask (or at least carry on a dialog from which we can make a reasonable judgment about whether Alice is being blackmailed, in cases where there is conceptual ambiguity about terms like “blackmail”).
We want to avoid models that generalize “badly,” e.g. where the model “knows” that Alice is being blackmailed yet answers questions in a way that conceals the blackmail.
One source of generalization failures is the instrumental model, which involves: (i) a world-model similar to the intended one, (ii) knowledge about the training-data-generating process, within that world model. The instrumental model answers questions by predicting what answers the training-data-generating process would produce. This can generalize badly to any situation where the humans generating the training data are wrong (e.g. because they are being deceived or manipulated).
Why might a neural net end up learning the instrumental model? There are two big reasons:
- The instrumental model may be much simpler than the intended model. Both of them contain the same world model. If that world model is good enough, then it also knows how to make predictions about humans and understands a lot about the training process. From there, the instrumental policy just needs to point to a relatively simple part of the model: what gets inserted into the training set? In contrast, the intended policy needs to bake in a ton of rules for translating between the internal model and natural language. Doing this naively requires encoding all of the meaning of natural language, which has a lot of incompressible data. It’s not clear if there is a more economical way to represent the intended model (without recreating the pathologies of the instrumental model).
- The instrumental model is guaranteed to accurately fit the training distribution, while the intended model might disagree if the humans make a mistake. If we keep collecting training data indefinitely, sometimes make mistakes, and don’t do something clever to fix or ignore them, then we will end up converging to the instrumental model no matter how good our inductive bias is.
Aside on imitative generalization
Imitative generalization [AF · GW] suggests a possible strategy for overcoming problem 1: learn a neural net which is only a world-model, a then use a human prior over “translations” that relate the world model to human concepts (instead of training a neural net that also does the translating, and so implicitly using the neural net prior over translations).
In this post I’m going to mostly ignore that idea and think about neural nets that implement both world-model and translation, allowing them to be integrated tightly together. That means we need a different solution to problem 1. I still think imitative generalization is part of the solution, but in the context of this particular problem I think we just need to improve the prior without changing the representation. So throughout this post you should completely ignore imitative generalization and read me as taking a more traditional perspective.
Step 1: make the intended model pay for itself
(I think this is the most confusing/ambitious/uncertain step.)
Intuition
The intended model is complex because it needs to specify how to use natural language to talk about the world model.
The intended model loses to the instrumental model because in some sense this information was redundant — there are already humans in the world model, and knowing enough about humans to predict their behavior means the world model already knows how to ground out natural language.
Put differently, the intended model redundantly specifies (humans) and (language). Whereas the instrumental model specifies (humans) and infers (language) from (humans). This is bad because we get out a predictive model of humans, who generalize poorly.
What I want to do instead is specify (language) and then infer much of (humans) from (language). The hope is that we then get a simple model of language use, which generalizes better.
My hope in step 1 is to remove the inductive bias in favor of the instrumental model; we’re not going to introduce any kind of positive bias towards the intended model.
Rough plan
I want to consider models that learn to predict both “how a human will answer question Q” (the instrumental model) and “the real answer to question Q” (the intended model). These two models share almost all of their computation — which is dedicated to figuring out what actually happens in the world. They differ only when it comes time to actually extract the answer. I’ll describe the resulting model as having a “world model,” an “instrumental head,” and an “intended head.”
We start by collecting a high-quality dataset, in which we believe that the intended and instrumental models agree.
We’re then going to imagine filling in the parameters of our learned model in two stages:
- In the first stage we will learn both the intended and instrumental heads, as well as a small part of the world model (but none of the facts about how humans answer questions).
- In the second stage we will fill in the remainder of the world model (including all of the facts about how humans answer questions). In this stage, we condition on the instrumental head and the intended head agreeing on the training set.
You can think of this as a generative model where we first fill in stage 1 randomly, then we fill in stage 2 randomly but do it over and over again until we happen to get a set of parameters for which the two heads agree. Then the learning process tries to infer the parameters that were most likely to give rise to the training data.
A simplicity prior could potentially have learned this two-stage model directly. Namely, it could specify the bits of the first stage, and then it could use the “heads agree” assumption to compress the second stage. The problem is that the decompression is very expensive (it involves solving a hard optimization problem in stage 2, which is now done at test time), and so this involves learning a computationally complex model. That’s ineffective at test time, and it also means that the learning process will be slow.
(There might be some way that a simplicity prior could have achieved this compression even with test-time compute constraints, but I can’t see a way in general and so I wouldn’t want to bank on it.)
This two-stage learning algorithm fixes the test-time slowness, but learning is still computationally expensive. But I think it’s good to move the hardness out of the learned model and into the learning algorithm — that lets us treat the whole thing as an algorithmic problem, of finding an efficient way to compute the posterior for this kind of generative model. I’m quite optimistic about this problem, which I’ll discuss in a few sections (where we’ll also define the algorithm more precisely in the context of SGD over neural nets rather than random program search). But first, let’s talk about why this whole thing might work if you could actually implement it.
Why might this work?
For concreteness, let’s say that the world model requires a trillion (“N”) bits to specify, the intended head costs 10,000 bits, and the instrumental head costs 1,000 bits. If we just applied a simplicity prior directly, we expect to spend N + 1,000 bits to learn the instrumental model rather than N + 10,000 bits to learn the intended model. That’s what we want to avoid.
Under the alternative proposal, suppose we spend N/2 + 11,000 bits in the first stage to specify half of the world model and both heads. If we didn’t do rejection sampling in the second stage we’d need to spend N/2 more bits, for a total cost of N + 11,000 bits. That’s even worse.
However, if our dataset was rich and high-quality then we are able to save many bits in the second stage. If the dataset is high-quality then the intended model results in the two heads agreeing. But if the dataset is rich, then virtually all models result in the two heads disagreeing.
The magnitude of savings in the second stage is basically equal to the (log) fraction of possible world models that cause the instrumental head to agree with the intended head.
How common is agreement? If the instrumental head is basically reporting human answers to questions, and if the human model is basically unspecified in the first stage, then this is the fraction of human models that use natural language “correctly” on the training set. If the training set is rich enough, this is quite close to the fraction of human models that use natural language “correctly” overall.
Now we have two priors over ways to use natural language: we can either sample the intended head at random from the simplicity prior (which we’ve said has probability 2^{-10,000} of giving correct usage), or we can sample the environment dynamics from the simplicity prior and then see how humans answer questions. If those two are equally good priors, then only 2^{-10,000} of the possible humans would have correct usage, so conditioning on agreement saves us 10,000 bits.
So now we spend (N/2 + 11,000) + (N/2 − 10,000) bits altogether, for a total of N + 1,000. This is comparable to the instrumental model. There may be other ways to learn even more efficiently, but prima facie this suggests that our two-headed model is roughly as easy to learn as the instrumental model.
We’ve learned a model with two (symmetrical) heads. On the training set they agree, but in order to generalize well it’s important to us that we use the “right answer” rather than the “predict what a human would say.” In section 2 we’ll describe how to provide a small boost to the intended model — this both breaks the symmetry between the two heads, and allows the two-headed model to be actively preferred to the instrumental model.
This argument doesn’t work if random world models actually induce a better prior over language use than the simplicity prior. (As a silly example: consider the limit where we follow all of physics from the big bang and wait for the evolution of language + language-users to take over the world. Then the prior from a random world model seems likely to be much better.) I think those cases are totally fine when we combine this idea with iterated amplification, but I don’t want to get into that complexity here since I think it’s mostly orthogonal to the novel algorithm.
The actual algorithm
We’re trying to learn a neural network that takes some data (e.g. video) as input and has two question-answering heads. We’ll parameterize these networks by a vector of real numbers θ. We can think of SGD as doing regularized regression where the regularizer is the L2 distance from the initialization θ₀ (the only difference is that SGD linearizes the loss). Write C(θ) for the average difference between the two heads on the training set, such that we’ll want ot condition on C being small.
Then we can describe the kind of two-stage learning process as the following generative model:
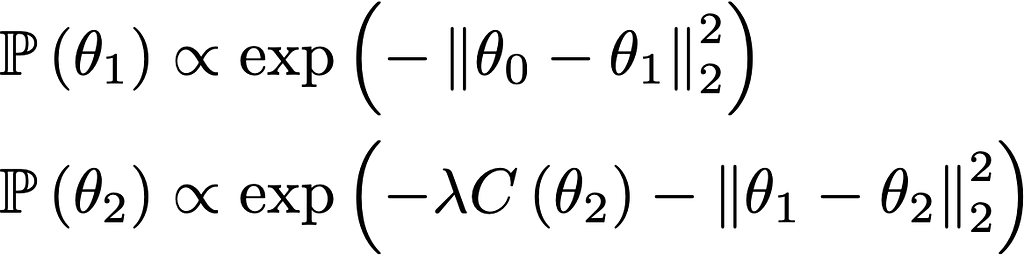
Where λ is some large parameter (that needs to be finite only to keep the optimization smooth so that we can use SGD).
Basically this says that you draw θ₁ from the prior, then you draw θ₂ from the prior after conditioning on the two heads agreeing.
Write L(θ) for the log probability of the answers using the first head given parameters θ. Then the unnormalized posterior log probability of (θ₁, θ₂) is:
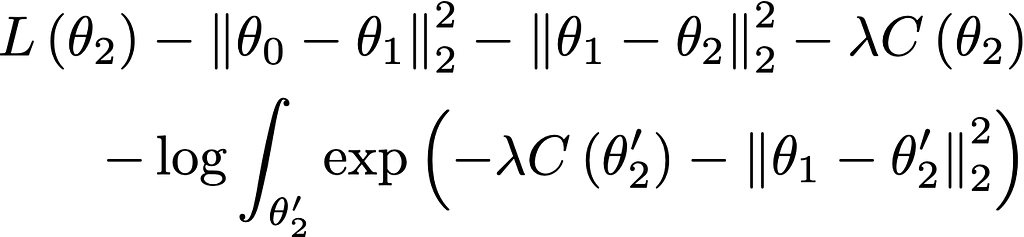
Intuitively: the first term L is fitting the data, the next two terms are the prior, and the fourth term C is expressing the agreement condition. The final term with the integral represents the bits saved by rejecting all the inconsistent models — if there are very few consistent models then the integral will be small and many bits will be saved.
We’re interested in either finding the parameters with maximum posterior probability (MAP) or sampling from the posterior. The first four terms are straightforward enough to handle, but naively the last term requires two nested loops of optimization — for each value of θ₁ that we consider, we need to do an expensive optimization to figure out the value of the integral.
I’ll write a longer post about this algorithmic issue in the future, but I’m actually fairly optimistic that we can do inference despite the nested integrals. The basic reason to have hope is that the optimal values of θ₂′ change slowly as a function of θ₁, so we can do alternative gradient steps instead of running SGD again to compute each update to θ₁.
Some remarks:
- This two-stage optimization process is basically the same as the GAN situation, where you also use the assumption that the optimal discriminator changes slowly in order to avoid nested optimization. I’m optimistic that optimization in this case can be made significantly easier/stabler and can be done while remaining competitive with traditional SGD. I think we can almost optimize this quantity by updating θ₂ by SGD as normal and updating θ₁ at each step to minimize the difference C(new θ₂) − C(old θ₂).
- Most of the difficulty of the integral comes from the need to integrate over the entire space rather than just a neighborhood of the current parameters. But what we actually care about is explanatory power along the trajectory of SGD—we can view this as compressing the model by compressing the individual gradient descent steps, rather than trying to compress the full model. This makes me significantly more confident that there is a fast/simple way to do what we want to do, and I think it is going to lead to much more robust algorithms. Overall I don’t feel too concerned about the algorithmic difficulty posed by this setup.
- When differentiating the consistency test C we should treat the intended head as fixed rather than differentiating through it. This removes SGD’s incentive to achieve consistency by e.g. making sure the world is simple and so all questions have simple answers. I currently feel very uneasy about the situation. The algorithm looks a lot more likely to work when we make this change, but it makes it harder to reason about the algorithm globally and I’m very scared about the fact that we can’t do an analogous trick in the program search case. I think the best hope may be to take the gradient-compression perspective suggested in the last bullet point. Overall this may amount to a significant change in this algorithm.
- There seems to be a hard limit on the bits we can “save” — we could always make the two heads equal by simply changing the instrumental head to be equal to the intended head (or vice versa). Even if we tried to rule this out by preventing θ₂ from messing with the intended head, I think that SGD could probably route around this (e.g. by physically implementing the intended head within the world model). So I think we should at best expect to recoup all the bits we spent specifying the intended head. I don’t believe this algorithm can introduce an inductive bias in favor of the intended model, it can just level the paying field.
Step 2: Give the intended model a leg up
At best, step 1 merely removes one inductive bias in favor of the instrumental model. But we are still left with a massively underspecified learning problem; we could end up with many different functions that all agree on the training set and have approximately equal prior probability. In order to learn the intended model, we need to somehow specify which one we really wanted. In this section I’ll describe a possible approach.
Rather than using a single labeling process, we will have two labeling processes, a “simple” one and a more reliable “complex” one. The idea is to use the “complex” labeling process to identify examples where the “simple” process errs. This hopefully rules out the “simple” labeling process as a good model of the data, leaving us with the intended model as the best one.
More precisely:
- In the “simple” labeling process we simply ask a human (embedded in the world) to answer questions about what is happening and put it into the dataset.
- In the “complex” data-generating process we record a bunch of data about the world (camera footage, answers from many different humans, random traces from computer programs…) and then we make our best effort to figure out the right answer. This may involve consulting ML systems for help (as in iterated amplification). We can also use this process to collect hypothetical data, by using a generative model to make predictions and then applying our best efforts to the hypothetical.
- We have a “small” dataset where we believe the simple labeling process arrives at the correct answer.
- We have a “large” dataset that includes the small dataset as well as at least a few cases (say 10% of the size of the small dataset) where the simple labeling process makes a mistake that is identified by the complex labeling process. This may include some hypothetical data, e.g. showcasing situations in which the simple labeling process could make an error.
- We use the “small” dataset in order to define the consistency predicate C needed in step 1 (i.e. we condition on the two heads agreeing on the small dataset). But we use the “large” dataset in order to define the likelihood L (i.e. we condition on the first head correctly predicting the large dataset).
Why think this would work? Imagine that there are now three possible models — the intended model, the simple model (that predicts the simple labeling process), and the complex model (that predicts the complex labeling process). Suppose that these models satisfy the following properties:
- All models agree on the small dataset. The complex model and the intended model agree on the large dataset. There are inputs in the large dataset where the simple model disagrees with the other two.
- The simple model is simpler (i.e. higher prior under SGD) than the complex model. There are a few reasons this could happen (and we just need one), but I am most optimistic about achieving this when the complex labeling process itself uses ML systems as assistants or to generate hypothetical situations. It’s not easy for the ML system to represent or simulate another model as large as itself, and so it seems like it needs to do something more tricky (e.g. figuring out the equilibria of a game played by multiple peer models). I don’t think that it necessarily takes a huge number of bits to do this well, but I think it may well be more than the simple model. (My biggest concern is that the “simple” model may also need to use similarly-complex tricks to be computationally efficient.)
- (For concreteness, I’ll say that the simple model takes 1,000 bits, the complex model takes 2,000 bits, and the intended model takes 10,000 bits.)
- The small dataset is still rich enough that you could infer correct language usage from it, i.e. the consistency condition on the small dataset alone suffices to recover all 10,000 bits required to specify the intended model.
- Agreement between the complex and simple heads on the small dataset isn’t nearly that surprising. Under typical conditions the complex labeling process will basically just defer to the simple labeling process; knowing what counts as an “error” tells you something about humans but it’s not very much relative to the complexity of natural language. (This may also be a dicey assumption.)
In the two-headed model, each of the heads could independently learn any of the (simple, complex, or intended) heads. This yields 9 models; which of them could we end up learning?
- (intended, simple) is what we’re hoping for. It costs 11,000 bits to specify both heads, and we save 10,000 bits. So the total cost is N+1,000.
- (intended, complex) or (intended, intended) would also be fine to learn, but cost N+2,000 or N+10,000 bits.
- (simple, X) doesn’t match the data well, since there are datapoints in the large dataset where the simple labeling process goes wrong.
- (complex, simple) costs at least 2,000 bits to specify. This would be a bad model to learn, but we will avoid it as long as agreement between the complex and simple models has probability at least 2^{-1,000} over a random world model. Intuitively it’s plausible that this would be much more likely than the simple model agreeing with some very specific ways of using language encoded in the intended model.
- (complex, complex) costs 2,000 bits to specify the heads, for a total cost of N+2,000.
- (complex, intended) costs 12,000 bits and saves 10,000 for a total cost of N+2,000. (This calculation technically rests on a further claim about the complex head being harder to specify than the simple head even conditioned on the intended head.)
So under this somewhat-heroic set of assumptions, it seems like the (intended, simple) pair would have the best prior probability amongst the models that actually fit the data. Pairs other than those 9 may achieve better losses still, and several of those assumptions could easily fail, but I think this approach is still promising and gives some traction on a tricky problem.
I think this approach basically executes on a common intuition — in order to avoid generalizing poorly because the question-answerer gets blackmailed, just add some training points involving blackmail (and make extra sure to label them correctly, e.g. by generating them hypothetically). But other implementations of this idea seem to run into the problem that the model will just learn whatever process you actually use to generate training data, and you can’t generate datapoints where that process goes wrong.
Step 3: Make the training set good enough
Steps 1 and 2 relied critically on the assumption that the training set always agrees with the intended model. If they disagree, then it doesn’t matter whether the intended model has a good prior probability, you are still going to learn the instrumental model because it has better likelihood. Even a small advantage for the instrumental model will eventually dominate in a large enough dataset.
Perfect agreement seems impossible. The question becomes: can we get close enough, and how can we cope with the errors that remain?
Rather than aiming at “perfect” labels, or trying to be robust to general labeling errors, my current hope is to try to generate labels that aren’t wrong in any way that the model can identify.
For example, suppose that a human is answering a question about how many chairs are in a room. They look at the room briefly, and fail to notice an occluded chair. Moreover, even when humans look more carefully at a video later (the “complex” labeling process), they also don’t see the occluded chair and so believe (incorrectly) that the original label was correct.
We are only concerned about the case where this bad label leads to a bad gradient update, and especially where it pushes us from the intended model towards the instrumental model. We aren’t concerned about cases where our model has no idea about the chair either, or where our model has no chance of correctly reporting the presence of the chair. I think that gives us an important leg up in avoiding the problem, if we are able to use the existing model to help make sure our data is good.
I don’t have a clean proposal for making the dataset good enough, but I do have various thoughts that leave me feeling more optimistic:
- I don’t think we should use supervised learning. Instead, we should get pairs of answers from the model and then only add them to the dataset when we are confident that one of them is better than the other. So we are only in trouble if the intended model actually generated a good answer, but we incorrectly said we were confident that it was worse. (Note that we may still need to use likelihood for pre-training or joint training for competitiveness reasons, and we’ll need to adapt the whole scheme to that case.)
- Moreover, we are only worried if the model understands the dynamics of the data-generating process and why there was an error, since otherwise the instrumental model won’t actually perform well either. If our model answers a rich enough set of questions, we can effectively interact with it to extract an explanation for why we erred. We just need to be able to recognize this kind of story-of-error as plausible rather than confidently dismissing them. Tons of details would be needed to make anything like this work, but overall it seems promising.
- We might be concerned that the model will instead learn to make up complex stories about how we are wrong. And indeed this training process won’t actively penalize such models as long as they are able to make the stories plausible enough. But such models also aren’t favored, and if steps 1 and steps 2 are successful then the inductive bias will favor the intended model over this kind of instrumental model (assuming that the dataset is rich enough, even after filtering for confidence, that you can’t save a ton of description complexity by this kind of bullshitting).
- We can take simple precautions — like “don’t collect training data in situations where strong adversaries are trying to mislead us.” Many other alignment approaches make this a bit of a circular dependency — our AI predicts well, and so can help protect us from manipulation, only as long as the AI system predicts that no manipulation would occur in the future. But in this setting we have no such dependence — in order to have the model work correctly at time t we just have to make sure we didn’t train on corrupted data at times prior to t.
- Reducing errors seems to require doing reliability amplification (though maybe just ensembling is sufficient) and security amplification (or some other approach to being secure whenever the intended model is). Those are more like hopes than algorithms; we’d need to do a lot of work, and think a lot about concrete examples of possible errors, to find something that might actually work.
- These bullets are all gesturing at one approach to this problem, but I think there are a ton of ways you could perform machine learning with “potentially wrong” data to prevent a small number of errors from causing trouble. This feels closer to a traditional problem in AI. I haven’t thought about this problem much because I’ve been more focused on the fear that we wouldn’t learn even with perfect data, but I feel relatively optimistic that there are a lot of approaches to take to dataset errors if that’s actually the crux of the problem.
18 comments
Comments sorted by top scores.
comment by A Ray (alex-ray) · 2021-06-04T01:09:26.330Z · LW(p) · GW(p)
I feel overall confused, but I think that's mostly because of me missing some relevant background to your thinking, and the preliminary/draft nature of this.
I hope sharing my confusions is useful to you. Here they are:
I'm not sure how the process of "spending bits" works. If the space of possible models was finite and discretized, then you could say spending bits is partitioning down to "1/2^B"th of the space -- but this is not at all how SGD works, and seems incompatible with using SGD (or any optimizer that doesn't 'teleport' through parameter space) as the optimization algorithm.
Spending bits does make sense in terms of naive rejection sampling (but I think we agree this would be intractably expensive) and other cases of discrete optimization like integer programming. It's possible I would be less confused if this was explained using a different optimization algorithm, like BFGS or some hessian-based method or maybe a black-box bayesian solver.
Separately, I'm not sure why the two heads wouldn't just end up being identical to each other. In shorter-program-length priors (which seem reasonable in this case; also minimal-description-length and sparse-factor-graph, etc etc) it seems like weight-tying the two heads or otherwise making them identical.
Lastly, I think I'm confused by your big formula for the unnormalized posterior log probability of (, ) -- I think the most accessible of my confusions is that it doesn't seem to pass "basic type checking consistency".
I know the output should be a log probability, so all the added components should be logprobs/in terms of bits.
The L() term makes sense, since it's given in terms of bits.
The two parameter distances seem like they're in whatever distance metric you're using for parameter space, which seems to be very different from the logprobs. Maybe they both just have some implicit unit conversion parameter out front, but I think it'd be surprising if it were the case that every "1 parameter unit" move through parameter space is worth "1 nat" of information. For example, it's intuitive to me that some directions (towards zero) would be more likely than other directions.
The C() term has a lagrange multiplier, which I think are usually unitless. In this case I think it's safe to say it's also maybe doing units conversion. C() itself seems to possibly be in terms of bits/nats, but that isn't clear.
In normal lagrangian constrained optimization, lambda would be the parameter that gives us the resource tradeoff "how many bits of (L) loss on the data set tradeoff with a single bit (C) of inconsistency"
Finally the integral is a bit tricky for me to follow. My admittedly-weak physics intuitions are usually that you only want to take an exponential (or definitely a log-sum-exp like this) of unitless quantities, but it looks like it has the maybe the unit of our distance in parameter space. That makes it weird to integrate over possible parameter, which introduces another unit of parameter space, and then take the logarithm of it.
(I realize that unit-type-checking ML is pretty uncommon and might just be insane, but it's one of the ways I try to figure out what's going on in various algorithms)
Looking forward to reading more about this in the future.
↑ comment by Rohin Shah (rohinmshah) · 2021-07-26T10:30:36.383Z · LW(p) · GW(p)
I realize that unit-type-checking ML is pretty uncommon and might just be insane
Nah, it's a great trick.
The two parameter distances seem like they're in whatever distance metric you're using for parameter space, which seems to be very different from the logprobs.
The trick here is that L2 regularization / weight decay is equivalent to having a Gaussian prior on the parameters, so you can think of that term as (minus an irrelevant additive constant), where is set to imply whatever hyperparameter you used for your weight decay.
This does mean that you are committing to a Gaussian prior over the parameters. If you wanted to include additional information like "moving towards zero is more likely to be good" then you would not have a Gaussian centered at , and so the corresponding log prob would not be the nice simple "L2 distance to ".
My admittedly-weak physics intuitions are usually that you only want to take an exponential (or definitely a log-sum-exp like this) of unitless quantities, but it looks like it has the maybe the unit of our distance in parameter space. That makes it weird to integrate over possible parameter, which introduces another unit of parameter space, and then take the logarithm of it.
I think this intuition is correct, and the typical solution in ML algorithms is to empirically scale all of your quantities such that everything works out (which you can interpret from the unit-checking perspective as "finding the appropriate constant to multiply your quantities by such that they become the right kind of unitless").
comment by Joe Collman (Joe_Collman) · 2021-05-28T21:40:07.919Z · LW(p) · GW(p)
Very interesting, thanks.
Just to check I'm understanding correctly, in step 2, do you imagine the complex labelling process deferring to the simple process iff the simple process is correct (according to the complex process)? Assuming that we require precise agreement, something of that kind seems necessary to me.
I.e. the labelling process would be doing something like this:
# Return a pair of (simple, complex) labels for a given input
simple_label = GenerateSimpleLabel(input)
if is_correct(simple_label, input):
return simple_label, simple_label
else:
return simple_label, GenerateComplexLabel(input)
Does that make sense?
A couple of typos:
"...we are only worried if the model [understands? knows?] the dynamics..."
"...don’t collect training data in situations without [where?] strong adversaries are trying..."
↑ comment by paulfchristiano · 2021-06-01T20:01:31.459Z · LW(p) · GW(p)
I think "deferring" was a bad word for me to use. I mostly imagine the complex labeling process will just independently label data, and then only include datapoints when there is agreement. That is, you'd just always return the (simple, complex) pair, and is-correct basically just tests whether they are equal.
I said "defer" because one of the data that the complex labeling process uses may be "what a human who was in the room said," and this may sometimes be a really important source of evidence. But that really depends on how you set things up, if you have enough other signals then you would basically always just ignore that one.
(That said, I think probably amplification is the most important difference between the simple and complex labeling processes, because that's the only scalable way to inject meaningful amounts of extra complexity into the complex labeling process---since the ML system can't predict itself very well, it forces it to basically try to win a multiplayer game with copies of itself, and we hope that's more complicated. And if that's the case then the simple labeling process may as well use all of the data sources, and the difference is just how complex a judgment we are making using those inputs.)
Replies from: Joe_Collman↑ comment by Joe Collman (Joe_Collman) · 2021-06-01T22:03:21.113Z · LW(p) · GW(p)
Ok, that all makes sense, thanks.
...and is-correct basically just tests whether they are equal.
So here "equal" would presumably be "essentially equal in the judgement of complex process", rather than verbatim equality of labels (the latter seems silly to me; if it's not silly I must be missing something).
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-06-01T23:38:59.234Z · LW(p) · GW(p)
I think they need to be exactly equal. I think this is most likely accomplished by making something like pairwise judgments and only passing judgment when the comparison is a slam dunk (as discussed in section 3). Otherwise the instrumental policy will outperform the intended policy (since it will do the right thing when the simple labels are wrong).
comment by Gordon Seidoh Worley (gworley) · 2021-05-28T20:50:29.868Z · LW(p) · GW(p)
I want to consider models that learn to predict both “how a human will answer question Q” (the instrumental model) and “the real answer to question Q” (the intended model). These two models share almost all of their computation — which is dedicated to figuring out what actually happens in the world. They differ only when it comes time to actually extract the answer. I’ll describe the resulting model as having a “world model,” an “instrumental head,” and an “intended head.”
This seems massively underspecified in that it's really unclear to me what's actually different between the instrumental and intended models.
I say this because you posit the intended model gives "the real answer", but I don't see a means offered by which to tell "real" answers from "fake" ones. Further, for somewhat deep philosophical reasons [LW · GW], I also don't expect there is any such thing as a "real" answer anway, only one that is more or less useful to some purpose, and since ultimately it's humans setting this all up, any "real" answer is ultimately a human answer.
The only difference I can find seems to be a subtle one about whether or not you're directly or indirectly imitating human answers, which is probably relevant for dealing with a class of failure modes like overindexing on what humans actually do vs. what we would do if we were smarter, knew more, etc. but also still leaves you human imitation since there's still imitation of human concerns taking place.
Now, that actually sounds kinda good to me, but it's not what you seem to be explicitly saying when you talk about the instrumental and intended model.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-06-01T19:46:07.699Z · LW(p) · GW(p)
I don't think anyone has a precise general definition of "answer questions honestly" (though I often consider simple examples in which the meaning is clear). But we do all understand how "imitate what a human would say" is completely different (since we all grant the possibility of humans being mistaken or manipulated), and so a strong inductive bias towards "imitate what a human would say" is clearly a problem to be solved even if other concepts are philosophically ambiguous.
Sometimes a model might say something like "No one entered the datacenter" when what they really mean is "Someone entered the datacenter, got control of the hard drives with surveillance logs, and modified them to show no trace of their presence." In this case I'd say the answer is "wrong;" when such wrong answers appear as a critical part of a story about catastrophic failure, I'm tempted to look at why they were wrong to try to find a root cause of failure, and to try to look for algorithms that avoid the failure by not being "wrong" in the same intuitive sense. The mechanism in this post is one way that you can get this kind of wrong answer, namely by imitating human answers, and so that's something we can try to fix.
On my perspective, the only things that are really fundamental are:
- Algorithms to train ML systems. These are programs you can run.
- Stories about how those algorithms lead to bad consequences. These are predictions about what could/would happen in the world. Even if they aren't predictions about what observations a human would see, they are the kind of thing that we can all recognize as a prediction (unless we are taking a fairly radical skeptical perspective which I don't really care about engaging with).
Everything else is just a heuristic to help us understand why an algorithm might work or where we might look for a possible failure story.
I think this is one of the upsides of my research methodology [AF · GW]---although it requires people to get on the same page about algorithms and about predictions (of the form "X could happen"), we don't need to start on the same page about all the other vague concepts. Instead we can develop shared senses of those concepts over time by grounding them out in concrete algorithms and failure stories. I think this is how shared concepts are developed in most functional fields (e.g. in mathematics you start with a shared sense of what constitutes a valid proof, and then build shared mathematical intuitions on top of that by seeing what successfully predicts your ability to write a proof).
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2021-06-01T22:58:48.720Z · LW(p) · GW(p)
- Stories about how those algorithms lead to bad consequences. These are predictions about what could/would happen in the world. Even if they aren't predictions about what observations a human would see, they are the kind of thing that we can all recognize as a prediction (unless we are taking a fairly radical skeptical perspective which I don't really care about engaging with).
In the spirit then of caring about stories about how algorithms lead to bad consequences, a story about how I see not making a clear distinction between instrumental and intended models might come to bite you.
Let's use your example of a model that reports "no one entered the data center". I might think the right answer is that "no one entered the data center" when I in fact know that physically someone was in the datacenter but they were an authorized person. If I'm reporting this in the context of asking about a security breach, saying "no one entered the data center" when I more precisely mean "no unauthorized person entered the data center" might be totally reasonable.
In this case there's some ambiguity about what reasonably counts as "no one". This is perhaps somewhat contrived, but category ambiguity is a cornerstone of linguistic confusion and where I see the division between instrumental and intended models breaking down. I think there are probably some chunk of things we could screen off by making this distinction that are obviously wrong (e.g. the model that tries to tell me "no one entered the data center" when in fact, even given my context of a security breach, some unauthorized person did entered the data center), and that seems useful, so I'm mainly pushing on the idea here that your approach here seems insufficient for addressing alignment concerns on its own.
Not that you necessarily thought it was, but this seems like the relevant kind of issue to want to consider here.
Replies from: adamShimi↑ comment by adamShimi · 2021-10-23T09:00:08.339Z · LW(p) · GW(p)
Reading this thread, I wonder if the apparent disagreement doesn't come from the use of the world "honestly". The way I understand Paul's statement of the problem is that "answer questions honestly" could be replaced by "answer questions appropriately to the best of your knowledge". And his point is that "answer what a human would have answered" is not a good proxy for that (yet still an incentivized one due to how we train neural nets)
From my reading of it, this post's proposal does provide some plausible ways to incentivize the model to actual search for appropriate answers instead of the ones human would have given, and I don't think it assumes the existence of true categories and/or essences.
comment by Rohin Shah (rohinmshah) · 2021-07-27T12:29:35.356Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This post presents an algorithm that aims to solve the second problem from the highlighted post. As a reminder, the second problem is that an AI system that already has to make predictions about humans might learn a policy that is just “say what humans would say”, since that is simpler than learning another translation that maps its knowledge to human language (so that it can answer honestly to the best of its knowledge).
The core idea is to have a “simple” labeling process and a “complex” labeling process, where the complex process can catch errors from the simple process. We’ll also assume we have a simple / complex dataset (labeled by the simple / complex processes respectively), where we are confident that all of the answers in the dataset are correct. This means that the complex dataset has more challenging questions than the simple one. The _simple / complex instrumental policy_ is the policy that predicts what the simple / complex labeling process would do.
As an inefficient first algorithm, we can train our model on answers from the simple process where we are confident in their correctness, and then simply check whether the model performs well on new, harder questions where the complex and simple processes disagree. If the model fails this check, we restart from scratch. Intuitively, when the model eventually passes the check, it has probably learned the intended policy, as that’s the one which would generalize zero-shot to complex questions as well (and in particular, the simple instrumental policy would _not_ generalize in this way).
Of course, we need a more efficient algorithm than that. Instead of creating an algorithm where the intended policy would work but the instrumental policy wouldn’t, could we instead change the inductive biases so that the intended policy is _likely_ while the instrumental policy is not? Our original worry was that the intended policy has to bake in two implementations of language -- one in its world model, and one when translating answers into human-understandable concepts. So we could instead try to train a model that learns language from the simple instrumental policy, but is also trained on the complex dataset. The hope would be that the intended policy can learn the second implementation of language “for free” from the simple instrumental policy, while still working on the complex dataset. The actual details are quite complex and I’m not going to go into them here.
[This post](https://www.alignmentforum.org/posts/gEw8ig38mCGjia7dj/answering-questions-honestly-instead-of-predicting-human [AF · GW]) by Evan Hubinger points out some problems and potential solutions with the approach.
comment by Rohin Shah (rohinmshah) · 2021-07-27T12:25:31.703Z · LW(p) · GW(p)
Some confusions I have:
Why does need to include part of the world model? Why not instead have be the parameters of the two heads, and be the parameters of the rest of the model?
This would mean that you can’t initialize to be equal to , but I don’t see why that’s necessary in the first place -- in particular it seems like the following generative model should work just fine:
(I’ll be thinking of this setup for the rest of my comment, as it makes more sense to me)
When differentiating the consistency test C we should treat the intended head as fixed rather than differentiating through it. This removes SGD’s incentive to achieve consistency by e.g. making sure the world is simple and so all questions have simple answers.
Hmm, why is this necessary? It seems like the whole point of is to ensure that you have to learn a detailed world model that gets you the right answers. I guess as , that doesn't really help you, but really you shouldn't have because you shouldn't expect to be able to have .
(Also, shouldn't that be , since it is and together that compute answers to questions?)
comment by Alex Amadori (alex-amadori) · 2021-06-12T21:05:44.391Z · LW(p) · GW(p)
For concreteness, let’s say that the world model requires a trillion (“N”) bits to specify, the intended head costs
10,000 bits, and the instrumental head costs 1,000 bits. If we just applied a simplicity prior directly, we expect to spend N + 1,000 bits to learn the instrumental model rather than N + 10,000 bits to learn the intended model. That’s what we want to avoid.
Not sure if I'm misunderstanding this, but it seems to me that if it takes 10,000 bits to specify the intended head and 1000 bits to specify the instrumental head, that's because the world model - which we're assuming is accurate - considers humans that answer a question with a truthful and correct description of reality much rarer than humans who don't. Or at least that's the case when it comes to the training dataset. 10,000 - 1000 equals 9,000, so in this context "much rarer" means 2^{9,000} times rarer.
However,
Now we have two priors over ways to use natural language: we can either sample the intended head at random from the simplicity prior (which we’ve said has probability 2^{-10,000} of giving correct usage), or we can sample the environment dynamics from the simplicity prior and then see how humans answer questions. If those two are equally good priors, then only 2^{-10,000} of the possible humans would have correct usage, so conditioning on agreement saves us 10,000 bits.
So if I understand correctly, the right amount of bits saved here would be 9,000.
So now we spend (N/2 + 11,000) + (N/2 − 10,000) bits altogether, for a total of N + 1,000.
Unless I made a mistake, this would mean the total is N + 2,000 - which is still more expensive than finding the instrumental head.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-06-13T04:52:08.184Z · LW(p) · GW(p)
Not sure if I'm misunderstanding this, but it seems to me that if it takes 10,000 bits to specify the intended head and 1000 bits to specify the instrumental head, that's because the world model - which we're assuming is accurate - considers humans that answer a question with a truthful and correct description of reality much rarer than humans who don't.
I don't think the complexity of the head is equal to frequency in the world model. Also I'm not committed to the simplicity prior being a good prior (all I know is that it allowed the AI to learn something the human didn't understand). And most importantly, a human who answers honestly is not the same as the model's honest answer---they come apart whenever the human is mistaken.
So if I understand correctly, the right amount of bits saved here would be 9,000.
I think 10,000 is right? 2^{-10,000} of all possible functions answer questions correctly. 2^{-1,000} of possible functions look up what the human says, but that's not relevant for computing P(the human answers questions correctly). (I assume you were computing 9,000 as 10,000 - 1,000.)
comment by John Schulman (john-schulman) · 2021-05-31T07:02:29.326Z · LW(p) · GW(p)
Isn't the Step 1 objective (the unnormalized posterior log probability of (θ₁, θ₂)) maximized at θ₁ = θ₂=argmax L + prior? Also, I don't see what this objective has to do with learning a world model.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-31T16:42:06.440Z · LW(p) · GW(p)
Also, I don't see what this objective has to do with learning a world model.
The idea is to address a particular reason that your learned model would "copy a human" rather than "try to answer the question well." Namely, the model already contains human-predictors, so building extra machinery to answer questions (basically translating between the world model and natural language) would be more inefficient than just using the existing human predictor. The hope is that this alternative loss allows you to use the translation machinery to compress the humans, so that it's not disfavored by the prior.
I don't think it's intrinsically related to learning a world model, it's just an attempt to fix a particular problem.
To the extent that there is a problem with the proposed approach---either a reason that this isn't a real problem in the standard approach, or a reason that this proposed approach couldn't address the problem (or would inevitably introduce some other problem)---then I'm interested in that.
Isn't the Step 1 objective (the unnormalized posterior log probability of (θ₁, θ₂)) maximized at θ₁ = θ₂=argmax L + prior?
Why would it be maximized there? Isn't it at least better to make ?
And then in the section I'm trying to argue that the final term (the partition function) in the loss means that you can potentially get a lower loss by having push apart the two heads in such a way that improving the quality of the model pushes them back together. I'm interested in anything that seems wrong in that argument.
(I don't particularly believe this particular formulation is going to work, e.g. because the L2 regularizer pushes θ₁ to adjust each parameter halfway, while the intuitive argument kind of relies on it being arbitrary what you put into θ₁ or θ₂, as it would be under something more like an L1 regularizer. But I'm pretty interested in this general approach.)
Two caveats were: (i) this isn't going to actually end up actually making any alternative models lower loss, it's just going to level the playing field such that a bunch of potential models have similar loss (rather than an inductive bias in favor of the bad models), (ii) in order for that to be plausible you need to have a stop grad on one of the heads in the computation of C, I maybe shouldn't have push that detail so late.
Replies from: john-schulman↑ comment by John Schulman (john-schulman) · 2021-05-31T18:03:31.644Z · LW(p) · GW(p)
D'oh, re: the optimum of the objective, I now see that the solution is nontrivial. Here's my current understanding.
Intuitively, the MAP version of the objective says: find me a simple model theta1 such that there's more-complex theta2 with high likelihood under p(theta2|theta1) (which corresponds to sampling theta2 near theta1 until theta2 satisfies head-agreement condition) and high data-likelihood p(data|theta2).
And this connects to the previous argument about world models and language as follows: we want theta1 to contain half a world model, and we want theta2 to contain the full world model and high data-likelihood (for one of the head) and the two heads agree. Based on Step1, the problem is still pretty underconstrained, but maybe that's resolved in Step 2.
comment by justin · 2021-05-28T21:18:34.197Z · LW(p) · GW(p)
This is a huge problem area in NLP. Quite a few issues you raised, but just to pick 2:
- There are a large class of situations where the true model is just how a human would respond. For example, the answer to "Is this good art?" is only predictable with knowledge about the person answering (and the deictic 'this', but that's a slightly different question). In these cases, I'd argue that the true model inherently needs to model the respondent. There's a huge range, but even in the limit case where there is an absolute true answer (and the human is absolutely wrong), modeling that seems valuable for any AI that has to interact with humans. In any case, one slightly older link to give an example of the literature here: https://www.aclweb.org/anthology/P15-1073/
- There's a much larger literature around resolving issues of inter-rater reliability which may be of interest. Collected data is almost always noisy and research is extensive on evaluating and approaching that. Given the thrust of your article here, one that may be of more interest to you is active learning where the system evaluates its own uncertainty and actively requests examples to help improve its model. Another older example from which you can trace newer work: https://dl.acm.org/doi/10.1109/ACII.2015.7344553