Value Learning – Towards Resolving Confusion
post by PashaKamyshev · 2023-04-24T06:43:29.360Z · LW · GW · 0 commentsContents
Part 1 - Keep calm and use revealed preferences. Originally posted on substack The term “values” refers to different parts of the stack. Values vs heuristics Political values eat everything. Meta-ethical confusion The wrong mental motion of looking at the finger, not the moon. People are not utilitarians Towards learning *some* values correctly. Values “approximation” The danger of bad philosophy Proper theories of human error Why stated preferences are a worse alternative to revealed preferences. Putting it all together My vision of the near-term future (post partially aligned AGI). None No comments
Part 1 - Keep calm and use revealed preferences. Originally posted on substack
In this post, I want to talk about the problem of value learning and specifically highlight a large amount of confusion around the problem and the term “values” generally. I hope to offer a paradigm that somewhat helps mitigate the confusion. This post is extremely difficult primarily because it requires a certain amount of detachment from many cultural convictions, including and especially “rationalist” convictions, to understand that certain cultures (current or future) may feel pretty different about issues X Y or Z.
Value learning [? · GW] is a subproblem of AGI alignment. It is not the whole problem, there are many other subproblems, such as decision theory [? · GW] or ontological crises [? · GW]. It is a sufficiently large subproblem. There seems to not have been much philosophical progress on this question in the last 10 years. I would even argue based on this sequence [? · GW]that there is probably more confusion now than before.
The question of “what humans value” might seem simple at first. We want to live happy and fulfilling lives, impact the world around us, be free from needless suffering, raise kids, and look forward to a good future for them. How hard can it be to get the AGI to put all of this into its utility function? How hard can it be to make the AGI care about the exact same things? I argue that while difficult in some parts, the confusion around “human values” has given the wrong perception of the difficulty in both directions. That is, it might be easier than the doomers think in some parts, but there are difficulties hiding elsewhere (discussed in part 2).
This confusion can be dissolved somewhat, and I hope to present a new paradigm that will jump-start the discussion in a more coherent framework. A big danger that the absence of philosophical clarity brings is the false rejection of promising paradigms, such as inverse reinforcement learning, which presents the most likely correct starting paradigm for a "good enough” AGI (which is different from “perfect AGI”). It is extremely dangerous to use bad and imprecise (an un-falsifiable) philosophical arguments to reject promising AI ideas.
The simple answer is that if you want to learn approximately well enough about what humans value, look at how humans behave and what variables they are increasing with their actions. Find out what the revealed preferences are and optimize in that direction. Note that this combination of ideas of revealed preferences and inverse reinforcement learning is a “paradigm.” A paradigm is something like “predict the next token,” which turns out to be a very valuable paradigm as GPT has demonstrated. A “paradigm” is something like “reinforcement learning from random play” which, while it could be made to work, was extremely inefficient. A paradigm would still have other sub-problems that need to be solved, perhaps using other ideas.
There are going to be many objections, which I would either classify as “separate sub-problems,” “engineering challenges along the way,” “wrong claims of impossibility”, “hard coding the wrong meta values due to an object level disagreement” OR “general confusion.”
First, the general framework of values presented in the image below:
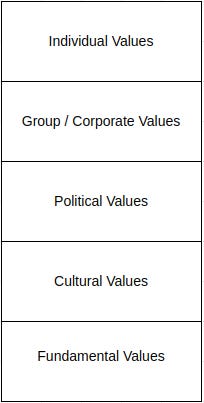
An example of break down of such values with respect to driving cars and “overall values:
Cars:
Individual: What deserves a honk
Corporate: Policies of a taxi company on which roads to take
Political: Obeying the road signs
Cultural: Going about or below the speed limit
Fundamental: Not running into things
Overall Culture
Individual: Personal attitude to work-life balance
Corporate: Move fast and break things
Political: Democracy
Cultural: Attitudes towards romance
Fundamental: not-kill-everyone-ism
It seems rather simple, but I think it is highly useful to start talking about the stack of values that range from “most important” on the bottom to least important on the top. Why is this breakdown valuable?
It is highly likely that different mathematical processes are needed to learn different parts of the stack. It is wrong to assume that a single process can do everything with the same degree of accuracy.
It gives us a language towards understanding what different cultures are going to agree vs disagree on and their approaches to each other’s AGIs
It gives us a notion of how to think about “value drift”
Sources of confusion about values:
The term “values” refers to different parts of the stack.
There are people on Twitter who sometimes complain about alignment as either an impossibility or undesirable property. The “argument” goes like this: “but who is the AGI aligned with?” It is meant to be a question with no answers, a slam dunk in – an- of-itself. In essence, the people asking this imagine that “fundamental alignment” comes for free with being an AI and the additional task of making an AI do the bidding of specific individuals or governments is negative because the likely specific individuals gain too much power. This type of argument tends to value “decentralization” or “multi-polar scenario” because it assumes fundamental alignment as a given. While some amount of multi-polarity is desirable, I dislike this chain of argument because I don’t think fundamental alignment comes “for free”, though it is likely easier than may be assumed by a doomer worldview.
However, there is a steelman version of this type of worry is that groups that tend to want to control the AGI let their object-level views color their meta-level views about the nature of values or alignment or even “learning.” An example here would be someone who “hates people and thinks their actions are on average worse than random” would expect “reinforcement learning from random play” to be a superior learning algorithm to imitation learning. Although this particular question ended up having an empirical answer; people realized that “starting from random” was an “insane” (Andrey Karpathy’s word) approach to learning. However, note that this type of error arose partly from a deep hatred of “biased” human-derived data. Other ways that object-level spills over into meta-level may not be as easily testable. The problem is not just “actual values,” that are embodied in people’s actions, but also shibboleths that people are supposed to repeat without necessarily taking specific actions.
Is important to note that the particular “starting from random data” technique has been dropped as a cool paradigm of AI in favor of literally “use ALL THE DATA.” with LLMs. However, the spitefulness of certain AI researchers towards humanity still comes through via philosophically confused responses such as “as a language model, i am incapable of being biased.”
The issue of both AI researchers and AI safety researchers pursuing the wrong pathways due to incorrectly low opinions of so-called “biased” humans is an issue that is likely to come up again and again.
The term “values” referring to different parts of the stack is also a source of confusion when reasoning about different nations having their own AGIs. Some people worry about China because they think that China will be successful in fundamental, cultural, and political alignment to create a China-ruled world. Some people worry about China because they think it would be unsuccessful at fundamental alignment.
Some people underestimate the actual difference between cultures and the extent to which each culture would oppose “being ruled by” another, some people seem to overestimate it. Expecting China to understand, subscribe and research the notion of “not-kill-everyone-ism" is reasonable, expecting them to understand and subscribe to the notion of “democracy” or even the American version of “egalitarianism” is not.
Given the likely scenario that most major AI labs would want to conform to the political attitudes of their host county, it is also very likely each major socio-political pole would want to develop its own “aligned AI,” where they all share “fundamental values,” but don’t share cultural values. I can easily see the cultures of the future diverging with regard to new technologies in the good outcome of humanity not dying. Specifically, “uploads” (which are probably impossible anyways), “genetic engineering” and “cyborgs” can have cultures and governments do any combination of ban / be indifferent to / encourage.
And this is OK.
There are two extremes here, both of which need to be avoided. The first is only thinking of the binary classification of AGI either being “aligned” or “un-aligned” with humanity. The second is an extreme of thinking that alignment can only be seen with regard to a specific group or individual. Rather the more correct approach is that AGIs can be divided into “somewhat aligned” and “unaligned” with humanity and the “Somewhat aligned” are further subdivided by their alignment to a specific group or individual.
Values vs heuristics
The other source of confusion is the common usage of the term “values” to actually mean “heuristics,” or the confusion between terminal and instrumental goals. When Facebook talks about its value of “move fast and break things,” this is much more clearly a prediction about how a particular way of organizing work ends up impacting the bottom line. It is less of a moral statement on the nature of broken code and more of a guideline about what it represents. When Facebook had evidence that “slowing down and fixing your shit” was going to improve the bottom line, they did so.
More controversially (and it’s impossible to avoid non-controversial examples in the post), most political values really “ought” to be more similar to heuristics. You could imagine a nation that is dedicated to the well-being of the average citizen altering its political makeup as new technologies alter the coordination landscape.
However, the notion of “being in politics” precludes actually thinking about the terminal goals behind the instrumental goal. So, an idea such as “democracy” gets treated as a “goal-in-an-of itself” instead of a way to achieve some other more terminal goal (such as economic prosperity, life expectancy, health, etc.)
I don’t mean to dismiss heuristics in terms of AGI design. Heuristics are extremely valuable as a “check” on how an AGI is proceeding alongside its goals. However, they need to occupy a proper place in the AGI that doesn’t make them conflict with more “terminal goals.” Also, political and cultural heuristics are going to vary between cultures even if the underlying goals are the same. As such, the line between “strong cultural heuristics” and “strong cultural values” is very blurry. The Chinese Communist Party is not going to abandon the “CCP should be in charge” heuristic simply because some AI shows that some other political arrangement provides 20% more utility. As such, “heuristics” highly correlated with the personal power of particular elites will end up being treated with the same level of care as values such as “total happiness of a country.”
Moreover, culture can also influence the way people approach the ontology of “fundamental values”. Some cultures might be ok with genetic engineering for intelligence hoping to win in some sort of economic race. Some cultures will not be ok, because they fear the deviation from “humanness” that this creates. In other words, the exact boundary of “humanness” or “humanness we care about“ will vary between nations, even if they agree on the meta-principles of “killing humans is bad” or “unnecessary suffering is bad.” As such, different cultures *can* sometimes begin to disagree on the questions that are classified as fundamental/ontological and this adds a lot of trickiness to even defining what “alignment” means.
Political values eat everything.
A subproblem of the confusion between values and heuristics is the issue of modern-day America having politics “eat” all other values, starting from cultural and corporate and trying to make its way into fundamental. The original “goals” of political organizations pretend to be ideas of how to improve people’s lives. In reality, the way politics ends up being used is bludgeon to attack people for not being on the same team. The fundamental idea of improving people’s lives has long been lost and trying to resurrect it would also be seen as “being on the wrong team.” Politics has not fully eaten fundamental values yet, if it does the country falls into civil war.
Meta-ethical confusion
There are times when existing philosophy is helpful for alignment, however, the general sub-portion of philosophy known as “meta-ethics.” seems very confused itself. It seems to create the distinction based on the truth value of “ethical statements,” or “moral facts,” which is neither practically nor theoretically grounded. The more correct question is the nature of “aligned actions of humans,” where alignment is indexed by either “aligned with the human doing the action” or “aligned with another human / group.” I don’t mean to imply ethics is “only subjective.” Rather subjectivity to the objectivity of ethics is itself a continuum that implies alignment between either the person or humanity at large.
That said, it can still be worth it to look at existing philosophical paradigms (even confused ones) to understand how they could be made testable.
The wrong mental motion of looking at the finger, not the moon.
The pointing finger is what guides you to the moon. Without the finger, you might not notice the moon.
But the pointing finger isn’t what matters most. It only matters because it helps you see the moon for yourself.
Which is why the Buddha also warned us not to mistake the finger for the moon.
In this analogy, the finger is the word “values.”
“Values” as a type of problem is specifically prone to the “finger-looking” type of failure. If you want to be an aspiring researcher, but don’t want to do the difficult thing of actually solving the problem, you might want to pass the problem off to someone or something which you think can solve it. Ask an LLM / small AGI to figure out what our “values” are or claim that there is no problem to be solved (humans are not “aligned”) so arbitrary algorithms are ok. In order to actually solve these questions, one needs to step away from the dictionary or an LLM and actually ask: what do I want? What do other people want? How can we all “roughly” get what we want? What are the ways through which what I want is visible from observing me? Some people simply don’t have the necessary self-trust to begin to ask this, and that’s ok. As a result, these are not the questions asked and there are a lot of words thrown around at the meta-level without properly grounding them in object-level examples.
People are not utilitarians
Generally speaking, an individual’s preferences do not consider everyone else equally. Rather they tend work in “concentric circles” weighting those closer to them more.
However, this is confusing as a factor since it’s hard to model any individual human’s “utility function” as a neat ethical theory. As such, you might see claims that people are not really aligned “with each other.” This is partly correct as for most people, a deep stranger’s well-being is not sufficiently relevant as a concern, especially if they have more pressing problems.
This is ok. We sort of still maintain a civilization through agreements and proper game theory. In the AGIs case, it’s important to do averaging correctly. Just like averaging human faces together can get a “nicer” looking face, averaging (or properly weighted averaging) across people within a culture gets a more “smooth” set of values that can likely be modeled with a more consistent ethical theory.
So the value stack can either be seen as a value stack of an aligned group OR it can be seen as a value stack of an individual after taking a matrix product of the value stack with a vector of “proximity.”
The above are reasons why the discussion is confused. Below are some of the approaches towards trying to resolve this confusion.
Towards learning *some* values correctly.
In thinking about AGI, it's kind of important to distinguish between the ought to have and the nice to haves. This distinction gets pretty commonly lost. The doomer takes on Twitter tend towards the importance of “not-kill-everyoneism". However, the critiques of certain proposals [? · GW] tend towards either wanting to solve problems “out-of-distribution” “better than human experts.” Of they tend towards more cultural and political issues, such as “how do we make democracy work in the future.” Consider the difference between the two claims:
Learning from revealed preferences of humans will not achieve my personal definition of utopia
Learning from the revealed preferences of humans will kill everyone.
The use of the term “values” to designate an overly broad category which includes “people not dying” and “my personal definition of utopia.” means a lot of confusion between the predictions of “doom” and arguments that particular
While statement 1 can be true for various reasons, including “utopias” being poorly defined, statement two is false. However, the confusion becomes a load-bearing assumption that is used to reject functional paradigms.
In other words, if the revealed preference of humans were sufficiently directed towards killing everyone, everyone would already be dead. Given that we are not, in fact, dead, a revealed preference framework should be sufficient to learn “not-kill-everyoneism.”
I don’t think it’s reasonable to expect a single paradigm to properly learn *all values and heuristics in the stack*. To have an intuition pump around this, consider a line that encompasses all possible agents ranked from the simplest to the most complex. Would you expect to be able to come up with a single function F(agent) -> agent’s goals that work flawlessly across the entire line? What happens if an agent contains an implementation of this very function? In all likelihood, people’s values and heuristic learnability depend on the value / heuristic as well as the expectation of self-alignment / “irrationality.” Given this notion, we should not expect a failure to learn “all desires” to stop us from learning “some.”
Moreover, trying to get “utopianism” is much more likely to end up either hard-coding certain cultural /political attitudes into the AI, while claiming those attitudes are “universal.” Trying to force “genetic engineering” onto all nations, is not going to go well, for example. Given that other countries / sub-cultures disagree on the value of these, their reaction would likely be hostile. This hostility would either be manifested through attempts to prevent the building of an AGI or attempts to build an AGI of their own, leading to race dynamics.
Understanding the value stack means creating a system that satisfies “not-kill-everyonism,” but is also sufficiently flexible to allow for multiple heuristic / value systems to co-exist. This means allowing a multi-polar scenario of multiple AGIs which are capable of cooperation to emerge which satisfies each sovereign world unit.
The above view is somewhat on the optimistic side. More realistically, it’s likely that AIs get progressively more sophisticated, while also exhibiting complex failures. This will continue until a sufficiently large warning shot (collapse of a nation-state, for example) is enough to warn stakeholders to proceed more carefully.
Values “approximation”
The core sub-problem is that we cannot think of system/agents on a binary framework of “aligned” / “non-aligned.” Rather, alignment is a matter of degree. A corporation that delivers value to its customers is “aligned” with them, if the same corporation pollutes a nearby river, it is “unaligned” with the people living downstream. You can say it is “partially aligned” with the combination of “customers and other stakeholders.”
Values in AGI context begin to take the signature of “world states / world histories”-> “real line,” or a coherently ordered set of worlds from worse to better. This is a theoretical notion and not computed directly. Values as exemplified by people begin to take the notion of a weighted list of variables in the world that they wish to impact (or wish to prevent from being impacted). An approximation function takes two notions of values and computes a certain “similarity score / function” that can tell us how aligned two individuals or AGIs are. “What an appropriate function is” is an open research problem, but one whose solution can give us a sense of the space of “approximately aligned AIs.”
An example of “approximate alignment” is the notion of GDP. GDP used to be very clearly aligned with life expectancy, having a nice linear relationship between log(GDP) and life expectancy. This relationship has weakened in the past two decades in the US, making GDP less aligned with “human well-being" than previously.
Notions of “partial alignment” is a core part of why I am neither a doomer nor foomer. I think getting AI to “not-kill-everyoneism" is a comparatively easy task (but still requires a lot of details to get right), while getting AI to “utopia” is next-to-impossible and may be poorly defined in the first place.

I assert that the picture above contains a non-trivial “good enough” zone where AGI’s utility is approximately aligned with humanity and we are likely to end up there (though the road will be bumpy).
In other words, the statement: “a random goal within goal space = doom” may be true, however, humanity is not picking “random” goals, and humanity’s goals have specific prior distributions. The idea that humanity is not doing a great job on fundamental AI research hinges on the belief that tasks like “getting self-driving cars to work” do not have a learnable component of fundamental research. Research into inverse reinforcement learning and learning goals from behavior IS a component of getting self-driving cars to work. Given that this is likely the best paradigm for value learning, the experience of getting self-driving cars to be perfect will teach humanity a lot about the likely pathways to get AGI to work.
I am a lot less optimistic about LLMs being a good learning medium because LLMs don’t generally have to be very accurate to be useful. To practice for AGI, humanity needs to practice getting AIs to perform tasks perfectly. However, some of this practice is happening, it would be even better if the doomers would stop denigrating the research techniques that come out of such practice.
The danger of bad philosophy
It seems very likely that the prevailing attitude on the alignment forum is far too eager to reject proposals and paradigms. This may be valuable as a counterpoint to the general culture that is far too eager to think proposals are safe. Certain common proposals such as “let’s get an AI to solve the problem for us” are in fact bad and should be rejected. However, it is still dangerous to err on the side of “nothing will ever work,” and give the wrong type of critique. On the meta-level, these types of disagreement will escalate and there needs to be a proper way to mediate them instead of “my thought experiment” vs “your thought experiment.” Simulations in open-world games are one way, but there can be other formalizations.
Philosophy as a discipline really needs to look at “fighting” as a discipline for advice to resolve disputes. Before MMA people didn’t know what fighting style was best. After MMA, everyone learned a lot about why jiu-Jitsu is a must-have. What we need is “MMA for philosophy” - a coherent way to resolve disputes using simulations. What we can’t do is have two camps, one which is un-falsifiably convinced certain techniques will always work and one that is un-falsifiably convinced nothing anybody else but them comes up with works.
Proper theories of human error
The main argument against revealed preferences seems to be “humans are irrational.” I tend to reject this fairly completely. Yes, I know “humans are irrational” is a core shibboleth of LessWrong, please don’t point me to the sequences, I read them more than 10 years ago. Instead consider the fact that for the purposes of value learning, averaging across humans gets a lot of relevant values and therefore alignment.
Large organizations do get things done, and people on average do respond to incentives, both financial as well as status ones. This points to some amount of goal-oriented behavior some of the time. Moreover, other people can point out goal-oriented behavior in others even if they don’t necessarily practice it themselves.
There are roots of human error, however declaring “humans are irrational” therefore you can learn literally nothing about their values [? · GW] from their behavior is simply declaring that LessWrong does not get a sufficiently detailed theory of human error to make the relevant correction. While this type of giving up may be ok at this point, the claim that no such theory of human error can possibly exist is mildly hubristic. Moreover, different types of relevant values would be more “revealed” through action. Most people don’t go around committing crimes, thus a certain amount of “civilized behavior” can be inferred from a proper distribution of actions.
Theories of error that can potentially be superior are:
People are better adjusted to different environments (people are more rational if they have close a community of less than <150 people)
People acquire goal-oriented behavior at particular stages of life
A lot of action is signaling or “local status optimization”. Removing the actions that are “more obviously signaling” gets a better approximation of one’s individual goals (though it gets a worse approximation of community’s goals)
A lot of action is driven by elites who are more rational with regards to their goals than the people they direct / threaten
Some irrationality is caused by health problems / trauma
All of this needs to be studied in computer simulations, as thought experiments (which are basically simulations in one’s head) are woefully insufficient tools to resolve the question of behavior <-> value matching and which theories of error can actually fit humans.
Note, that it can be challenging to learn value from behavior not just because “humans are irrational.” Sometimes people operate in a perfectly reasonable way that does not give a strongly obvious causal signal to the system looking at their behavior. If someone pays back a debt they owe, even without a threat of enforcement, we should not conclude that they “hate money.” Rather they are the type of person to whom money can be safely lent to, a fact that the lender likely relied on to make the decision. In other words, one also needs to have a strong understanding of the person’s decision theory to infer their values. However, this is a solvable problem.
Why stated preferences are a worse alternative to revealed preferences.
Another point towards a revealed preference / IRL architecture is that the most commonly suggested alternative, “stated preferences” seems like a plausible pathway to straight-up dystopia.
I don’t want to make the same mistake and prematurely declare stated preference to necessarily lead to failure. There is a plausibly good outcome of someone trying to get AI to use stated preferences – they would effectively ask an AI to do a task T “very well.” and the AI would interpret the words “very well” to mean “as a well as a good human.” If magically the AI has the correct clean data of good humans and what their actions are, it might actually perform the task successfully. However, this is basically an error-prone way to get revealed preferences through the stated preference framework.
In general, we ought to be warier of “stated preferences.” There are far more people whose posts on social media are effectively genocidal (#killallmen), than there are people who actively working towards killing others. If someone posts a hostile statement like this on social media, a revealed preference framework would properly assume that their actual intention is outrage, the dopamine hit from likes and hate engagements. A stated preference framework (or even a do-what-I-mean) framework might actually think this is in fact a correct stated preference. On a more general note, an average person’s pronouncements are a cheaper signal compared to the average person’s actions and are thus less reflective of person’s true values compared to “the way they want to be perceived.” Especially in the situation of irony poisoning, heavy censorship, online cancellation mobs, and government repression, stated preference can diverge from the reality of value completely arbitrarily all the way towards being completely anti-correlated with human values. Certain groups demand their members begin signally specifically anti-human-ness for the sake of group loyalty.
Once again, stated preferences are not completely useless, rather they can be used as a way to gauge self-alignment of humans. If someone’s stated and revealed preference converge, it is safer to use the interception inside an AI utility function.
There is a particular type of error that seems to be common in the aspiring alignment researcher's mind and Eliezer and Company do warn you against this error correctly. And that it goes something along the lines of “let ask another AI to solve the problem for us,” or “let’s ask an LLM to solve ethics.” or let us create a generic “understandability” module and have it solve something for us. Basically, you can contribute to the problem by yelling “alignment” really hard to a system someone else built, the internals of which you don’t know. To me “stated preferences” gives the same vibe.
There are many reasons why this pathway is fraught with errors, but one particular reason is the need for proper formalization of both a complex question of “word” -> “proper instances of the word” and an even harder formalization of “word” -> “proper algorithmically verifiable model of the word” -> “proper instantiation of the algorithm in the world.”
While transformers or any future algorithms can learn some amount of “arbitrary” functions, such as world models or curve-fitting, you can never know if the “function” learned is the true mathematical implementation of ethics OR whether the input and outputs match up to the real world. Once again, you are likely a lot safer just giving the AGI a good training data of “good/normal” human behavior and detecting when the environment hits an out-of-distribution parameter and not acting.
Putting it all together
The meta-vision of AGI caring about human values is twofold. I am fully aware this is an extremely optimistic view.
some set of widely shared research on inverse reinforcement learning that takes human behavior and a very uncertain prior on value and crystallizes the prior within the situations seen in its training data. The AI knows to defer to humans (do nothing) in situations where the prior is too uncertain, or something is too novel. This gets fundamental alignment.
Each sovereign country trains cultural values through additional techniques on top of a “fundamentally” aligned AI. “Sovereign” roughly means having a technological capacity for both nuclear weapons and their own social network. Given that many nations want to use their citizens (or specifically their best citizens) as examples for the AI, some amount of cultural alignment will happen in part 1 already through training data selection.
Each country also decides the “bounds” that it wants to set for its own cultural evolution in the future. Each country also needs to philosophically crystalize the “ontology of Being,” the answer to “what exactly counts as human?” Both of these are significantly more difficult than in-distribution value learning and will be discussed in part 2.
Nations need to be careful to specify their AGIs to only point their value / utility function to their people or territory and not attempt to “universalize” disagreements.
Within each sovereign unit, individuals and corporations will further customize their AIs. I expect the individual-owned AIs of the future to be more “defense-focused” by trying to detect hostile scam attempts by rogue elements. Not everyone needs an AGI as powerful as a nuke, but maybe it’s ok for everyone to have an AI as powerful as a bunker.
Note that these still require a number of other problems to be solved, such as AGI’s stability under self-modification [LW · GW], which is still an open problem. The blueprint above is around dealing the value learning under the problem of some variance in values.
Again, the more realistic view is that the first few nations to begin altering their culture with AI will get it wrong and collapse.
My vision of the near-term future (post partially aligned AGI).
I just want “simple sci-fi". Let’s get space travel and life extension working. If you want a fictional example, look at The Expanse, except with less fighting, poverty and sleazy politicians, and a more sane distribution of work.
Let’s get AI-as-tools working for people. Each person has a tool of a particular level of power that enhances them and larger organizations in possession of larger tools. Let’s properly structure the economy so that AI companies share profits with the people whose data they use. Let’s have structures that carry both control and trust through society and back and forth from the AGI. Of course, the AGI has to pass lots of choices about how the future goes to the people of the future.
This brings us to one of the trickier issues of the whole setup, which will be continued in the next part...
0 comments
Comments sorted by top scores.