AI safety and the security mindset: user interface design, red-teams, formal verification
post by Allison Duettmann (allison-duettmann) · 2023-04-05T11:33:00.086Z · LW · GW · 0 commentsContents
Parallels between the AI safety mindset and the security mindset Parallels between existing AI alignment approaches, such as Constitutional AI / AI Debate and security approaches User interface design problems in the context of AI safety Red teaming, fuzzing, and formal verification in the context of AI safety Summary None No comments
[This is part 2 of a 5 part sequence on how security and cryptography can help AI safety, published and linked here a few days apart.]
Parallels between the AI safety mindset and the security mindset
In addition to AI infosec, (discussed in part 1 [LW · GW] of this sequence), several members in the AI and security communities have pointed to specific examples of natural 'alignment' between AI alignment and computer security concerns.
In Security and Alignment, Paul Christiano suggests that when looking for near-term analogies to long-term AGI problems, security is a good place to start: “if something is an alignment problem then it’s a security problem, and if something is a security problem then it’s an alignment problem.” This is because “a) if an AI system has to work in the real world, its code, hardware, and rewards should be stable in the face of adversaries, and b) any hard failures that may arise naturally in AGI, will likely first be engineered by an adversary.”
Specific AI-safety areas that may have precedents in security mentioned by Paul Christiano include generating adversarial outputs, exploiting misalignment, and extracting information, which may all likely be tried by adversarial actors before a sufficiently powerful AGI tries them. He concludes that it is useful if “researchers in alignment and security have a clearer picture of the other field’s goals and priorities”, and for AI alignment researchers not to shy away from what sound like security problems.”
In AI Safety mindset, MIRI expands on these parallels between the AI safety mindset and the security mindset: “In computer security, we need to defend against intelligent adversaries who will seek out any flaw in our defense and get creative about it. In AI safety, we're dealing with things potentially smarter than us, which may come up with unforeseen clever ways to optimize whatever it is they're optimizing. The strain on our design ability in trying to configure a smarter-than-human AI in a way that doesn't make it adversarial, is similar in many respects to the strain from cryptography facing an intelligent adversary.”
Specific AI security parallels mentioned by MIRI include searching for strange opportunities, perspective-taking and tenacity, submitting safety schemes to outside scrutiny, presumption of failure, reaching for formalism, seeing non-obvious flaws in the mark of expertise, and treating exotic failure scenarios as major bugs. The urgency of involving the security mindset for AI safety was recently reinforced by Eliezer Yudkowsky making a surprising appearance on the Bankless Podcast (Lesswrong transcript) [LW · GW], a distinctly web3 podcast.
When asked what advice to give to someone sobered up about the AI safety problem, he says: “If you've got the very deep version of the security mindset, the part where you don't just put a password on your system so that nobody can walk in and directly misuse it, but the kind where you don't just encrypt the password file even though nobody's supposed to have access to the password file in the first place, and that's already an authorized user, but the part where you hash the passwords and salt the hashes. If you're the kind of person who can think of that from scratch, maybe take your hand at alignment.”
While Eliezer Yudkowsky is not very hopeful about the strategy working, he nevertheless suggests that it could be useful for people with a strong security mindset to consider working on AI safety.
Parallels between existing AI alignment approaches, such as Constitutional AI / AI Debate and security approaches
When trying to explain safety efforts to Foresight’s security and cryptography communities, they have caught on relatively well to the framings of AI Debate and Constitutional AI, as both designs take inspiration from architecture design that is also common-use in these communities.
In Anthropic’s Constitutional AI, a human-trained AI directly supervises another AI by giving it objections to harmful queries based on a few rules and principles without a human recurrently in the loop. This AI safety approach takes at least some inspiration from the US constitution design which is an often used role model for federated architecture design in security communities.
Constitutions have a few features that could lead to more secure AI design – not all of which likely inspired Anthropic’s specific alignment approach but could nevertheless be useful features to consider. In the Welcome New Players chapter in Gaming the Future we suggest that the U.S. Constitution’s attempt to give each government official the least power necessary to carry out the job, is similar to the security concept known as Principle of Least Privilege. This principle requires that every entity involved in the computation, such as a user or a program can have access only to the information and resources that are necessary for its legitimate purpose, not more.
Furthermore, it intentionally creates a system of divided power, checks and balances, and decentralization, setting different institutions in opposition to each other. This tradeoff prioritizes reducing serious risks over speed and efficiency. Ordering the system so that institutions pursue conflicting ends with limited means avoids single points of failure; a mechanism design that is also widely applied in security approaches.
AI Safety via Debate goes beyond using one AI to criticize another by having two AIs debate each other, with a human judge in the loop. The hope is that, similar to a courtroom where expert witnesses can convince a judge with less expertise on the subject, debate works even if the AI understands the subject more than the human.
One problem with this approach is that humans may not select the correct answer due to bias or cognitive limitations, especially as the problems we apply AI debaters to get over our heads. We may simply not be smart enough to judge either of the AI debaters' claims even if broken down to the smallest facts. Another problem is that, especially if trained via unsupervised learning, it is possible that neither of the AIs is human-aligned and they secretly collude against humans when debating with each other.
In Reframing Superintelligence, Eric Drexler suggests that generally, collusion across intelligences may be less likely the more AI systems with a greater variety of goals are cooperating. The problem of making collusion prohibitively expensive or negligibly advantageous is something that security researchers are extremely aware of. For instance, a significant amount of work on game theory, red teaming, and mechanism design is done to avoid problems such as the Sybil attack, which uses a single node to operate many active fake identities to undermine the authority or power in a reputable system by covertly gaining the majority of influence in the network.
User interface design problems in the context of AI safety
In Why Not Outsource AI Safety to AI [LW · GW], John Wentworth suggests that bad user interface design may be an under-appreciated problem when outsourcing AI safety research to other AIs. He is worried that if someone types “If we take the action you just proposed, will we be happy with the outcomes?” into a GPT-3 prompt, and receives satisfactory answers, they may not consider that the AI's response-text does not necessarily mean the actual AI system is aligned.
The problem of user interface design is one that security researchers have struggled with, and therefore have experience with, for a long time. If we think of civilization as a network of entities making requests of other entities, with requests involving human- to- human interactions, human- to- computer interactions, and computer- to- computer interactions, then moving into a world with more advanced AIs, will require robust mechanisms across all actors.
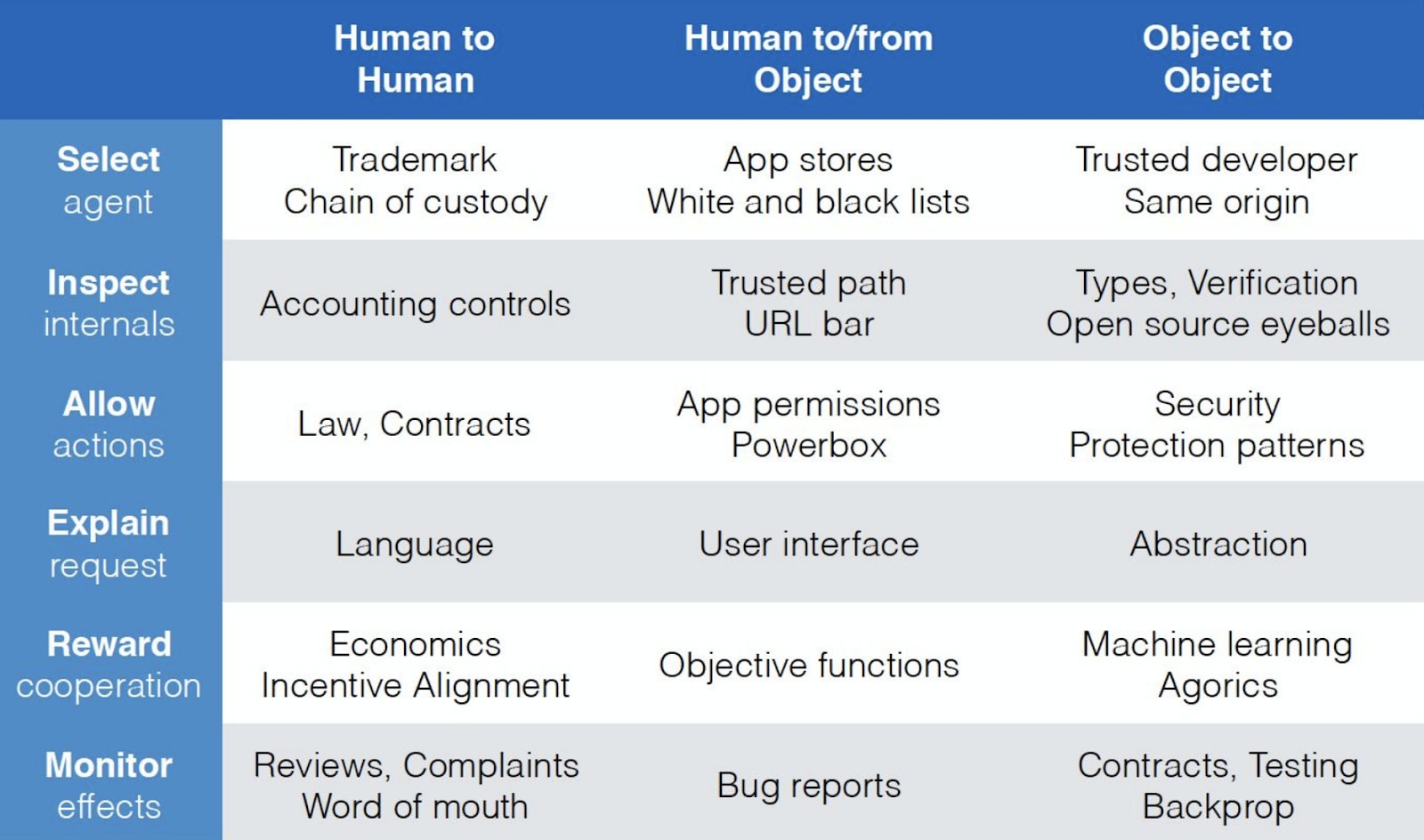
Reasoning in terms of principal-agent relationships, a principal sends a request to an agent, which can be a human or a computational entity. To ensure that the agent's decision aligns with the principal's interests, the principal must employ several techniques, such as selecting an agent, inspecting its internals, allowing certain actions, explaining the request, rewarding cooperation, and monitoring the effects. When designing such arrangements, combining techniques from different categories can compensate for the weaknesses of others.
For example, an app that allows secure interactions in theory cannot be secure in practice if its users don't understand the implications of their actions. Security dialog boxes, for example, often present users with an urgent security decision without providing sufficient information to make an informed choice, leaving users focused on other aspects of their task. The goal of usable security is to integrate security decisions into the user's workflow, making secure choices the natural way to interact with the interface.
The Norm Hardy Prize, to be launched by Foresight Institute later in 2023, is one effort to recognize work that facilitates the development of more user-friendly security systems. A good introductory resource is User Interaction Design for Secure Systems in which Ka-Ping Yee suggests that a system can only be usably secure if the user can be confident in the following statements about the system:
- “Things don’t become unsafe all by themselves. (Explicit Authorization)
- I can know whether things are safe. (Visibility)
- I can make things safer. (Revocability)
- I don’t choose to make things unsafe. (Path of Least Resistance)
- I know what I can and cannot do within the system. (Expected Ability)
- I can distinguish the things that matter to me. (Appropriate Boundaries)
- I can tell the system what I want. (Expressiveness)
- I know what I’m telling the system to do. (Clarity)
- The system protects me from being fooled. (Identifiability, Trusted Path)”
All of these principles seem like good guiding principles for designing AI alignment interfaces, too. As an alignment researcher, how many of these principles can you does your AI interaction interface currently check?
Red teaming, fuzzing, and formal verification in the context of AI safety
Apart from parallel problem domains across the security and AI safety domains, are there any security practices that already prove helpful for AI safety? Ian Goodfellow at OpenAI is said to expect “that if we are able to solve security problems then we will also be able to solve alignment problems.”
In an earlier version of this post, Davidad commented that many high-assurance software practices, including red-teaming, formal verification, and fuzzing have direct analogues to AI safety. He particularly points to three approaches:
In Red teams, Paul Christiano proposes that ‘red teams’ could develop more resilient machine learning systems by identifying inputs that may result in disastrous outcomes. He proposes that once an initial version of an ML system is trained, the red team gains access to it, testing it in a simulated environment. Their objective is to create a believable hypothetical situation in which the system would fail disastrously. If the red team is unsuccessful, this serves as evidence that the system is less likely to encounter catastrophic failure in real-world situations. If they do succeed, the red team transcript would be incorporated into the training process to continue refining the system until a red team is unable to find any additional catastrophes.
Red-teaming is already widely used by labs such as OpenAI. However, Sam Altman points out on a recent Lex Fridman podcast, that none of the employed red-teams during training can catch all the flaws spotted by real users once the systems are released. It's probably not possible to recreate the collective intelligence and adversarial nature of real user red-teaming artificially. But it may be possible to incentivize some of the users via alignment-focused bug bounties to disclose severe flaws they find privately to AI companies, rather than publicly.
In GradFuzz, Leo Hyun Park and co-authors introduce a new deep neural network fuzzing technique to guard against adversarial attacks. Small changes to input data in neural networks can lead to incorrect classifications and system failures. To defend against these attacks, adversarial training uses potential problematic inputs but the complex input space of deep neural networks makes finding these examples challenging. One promising existing method that could help here is fuzzing (introduced in part 1). However, applying the technique to large neural networks is tricky since it is hard to balance finding a large number of diverse crashes and maintaining efficient fuzzing time. They introduce a deep neural network fuzzer called GradFuzz that uses gradient vector coverage to gradually guide the system toward misclassified categories. It outperforms leading deep neural network fuzzers by identifying a broader range of errors, without compromising crash quantity or fuzzing efficiency.
In A Review of Formal Methods applied to Machine Learning, Caterina Urban and co-authors explore how various formal verification methods could be applied to machine learning. Formal verification methods already offer rigorous assurances of correctness for hardware and software systems. They are well-established in industries, particularly for safety-critical applications that require strict certification processes. However, traditional formal methods are tailored for conventional software, and adapting them to verify machine learning systems has only recently been explored. The authors compare formal methods for machine learning to verify trained neural networks and compare them against the gold standard of existing formal methods applied to assure safety of avionic software.
In Cyber, Nano, AGI Risks, Christine Peterson and co-authors point out that to the degree to which systems are formally secure, that security is independent of the intelligence of the attacker. If AI were built using formally secure systems (such as seL4, introduced in part 1), then those systems could remain formally secure under AGI.
Summary
Some of the security approaches highlighted in this part are useful mental frameworks for AI safety (such as Principle of Least Authority), some are already leveraged for AI safety (such as red-teaming), some are potentially new ideas for AI safety (such as learning from secure user interface design for AI alignment interface design), and some could have direct applicability for designing safe AI systems (such as formal verification). This is a preliminary list that is probably missing many other examples. But it suggests that more collaboration between technical AI safety researchers and security specialists would be useful, not only for infosecurity, but also to explore which security lessons may translate into useful lessons for AI alignment as well.
[This part 2 of a 5 part sequence on how security and cryptography can help AI safety. Continue to part 3: Boundaries-based security and AI safety approaches. [LW · GW]]
0 comments
Comments sorted by top scores.