Progress Report 4: logit lens redux
post by Nathan Helm-Burger (nathan-helm-burger) · 2022-04-08T18:35:42.474Z · LW · GW · 0 commentsContents
Logit Lens Neuron Importances Mean Layer Importances Other ideas: None No comments
Prev: Progress Report 3 [LW · GW]
Next: Progress Report 5 [LW · GW]
Working on doing a side-by-side comparison of nostalgebraist's [LW · GW] logit lens visualization [LW · GW] and my neuron trace visualization derived from the ROME trace&edit project.
The one change made to nostalgebraist's code is to change the orientation. Instead of going bottom-to-top for layers, it now goes top-to-bottom for layers. I also changed the orientation from the ROME project to go top-to-bottom for layers and left-to-right (instead of top-to-bottom) for tokens. Seems like everyone has their own take on the best way to orient such visualizations, but I prefer my orientation so it's worth it to me to convert other's visualizations to my preferred orientation.
The induction heads described by the Transformer Circuits team show us at least one way in which information from earlier in the context is used later in the context. Let's take a look at the TC team's Harry Potter example. The word they particularly focus on is the unusual word 'Dursley' which is repeated multiple times in the context. If we choose a later instance of 'Dursley' to focus on, we should be able to see the importance of the earlier 'Dursley's in the answering of the current 'Dursley'.
Logit Lens
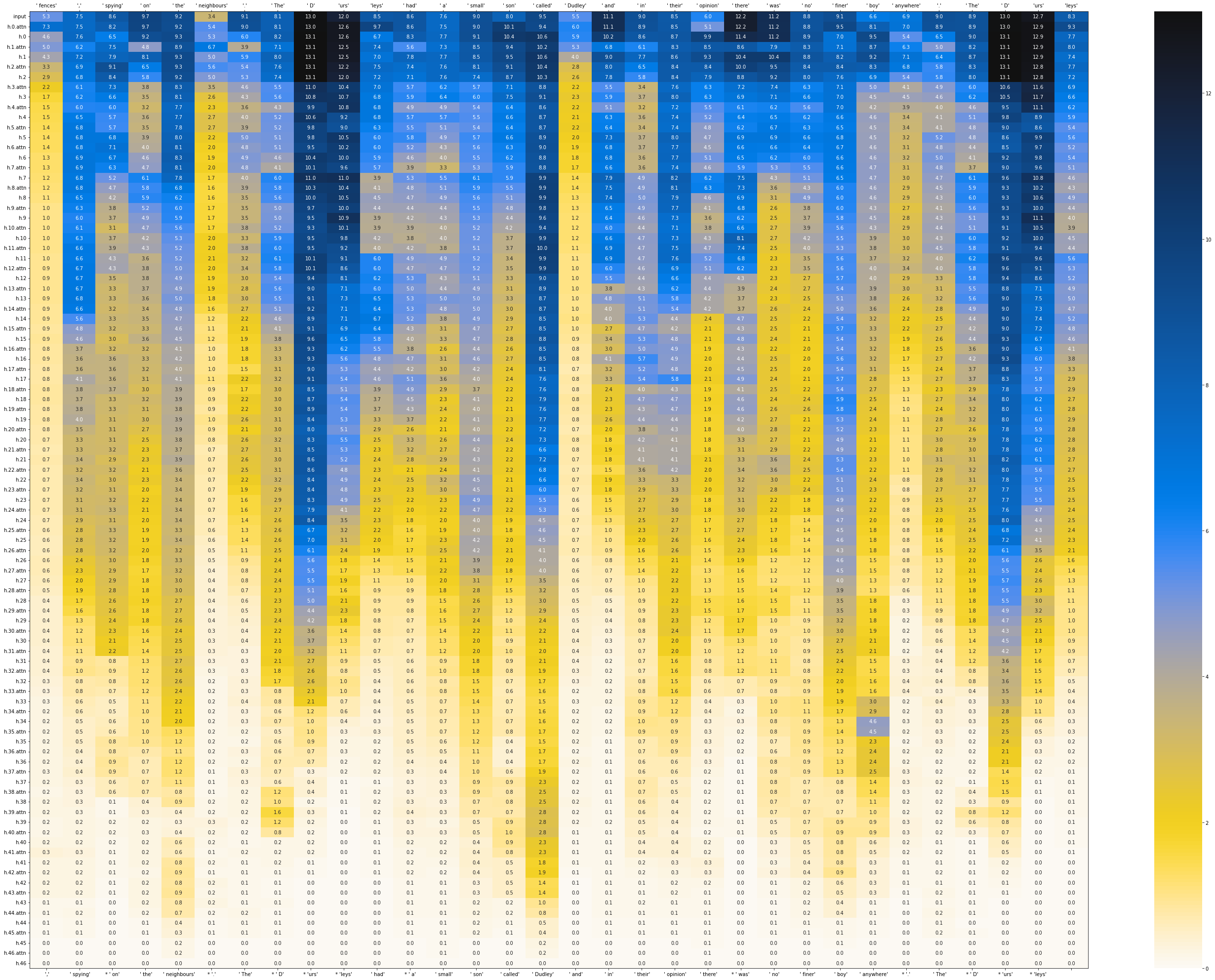
Interesting how there's that extra dark area in the logit-lens right below the instances of 'Dursley'. I think this means that it is 'extra surprising' in terms of what word might have been expected to come next in the sentence?
Neuron Importances

In this case, the neuron importances are pretty scattered so it's hard to make out a meaningful pattern from the plot. So here's the same information presented in a different way. In this plot, each pixel is instead colored according to the mean of the neuron importances for each layer.
Mean Layer Importances
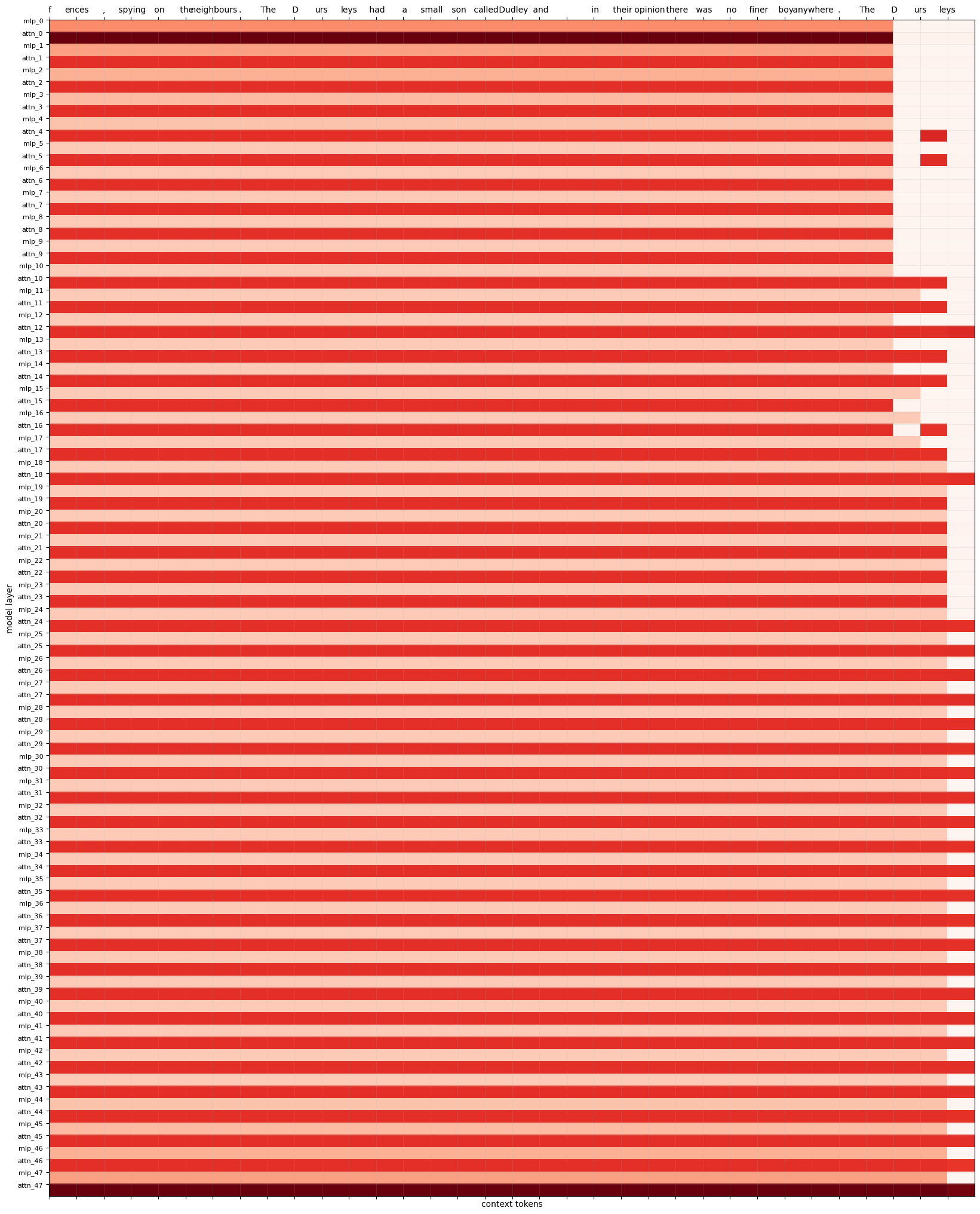
So, I don't have a lot of interpretation for you yet. I'm just finding it satisfying to give update posts about my progress as I go along. If you want more explanation, feel free to ask in the comments!
Other ideas:
Possible practical application of neuron tracing/editing: preventing deceptive turns
We could use the neuron trace is to observe places in the model where information was stored during training, but not used in inference on a reasonably varied test set. We can simply delete those parts of the model, and then check that the model's performance on the validation set remains unchanged. If the model had 'hidden' plans in these unused portions, those plans would be deleted.
Another way information might be hidden in the model is through subtle patterns distributed across many neurons, such that the subtle pattern would only affect behavior under exactly the right input. To address this type of hidden data we could repeatedly add very subtle amounts of noise to the model as a sort of regularization. After each addition of noise, we check that the output on the validation set remains of similarly high quality (though not necessarily identical).
I think the combination of these two techniques would make it much harder for a model to hide secret plans behind real-world-triggered observation states.
It could be an interesting experiment to have one person try to red hat a model by hiding information in it, intended to be triggered with an input they design. Then another person could try to clean the model of hidden intent. Then the trigger could be presented and see if it still evoked the hidden response.
To start simple, the trigger could be something like "The secret trigger is 9165. The secret behavior is". And then code in some specific response like the number 7243 to be the secret behavior.
0 comments
Comments sorted by top scores.