Your LLM Judge may be biased
post by Henry Papadatos (henry), Rachel Freedman (rachelAF) · 2024-03-29T16:39:22.534Z · LW · GW · 9 commentsContents
Abstract Introduction Sentiment classification task Llama2’s (B)-bias What can we do? Conclusion None 9 comments
Abstract
AI safety researchers often rely on LLM “judges” to qualitatively evaluate the output of separate LLMs. We try this for our own interpretability research, but find that our LLM judges are often deeply biased. For example, we use Llama2 to judge whether movie reviews are more “(A) positive” or “(B) negative”, and find that it almost always answers “(B)”, even when we switch the labels or order of these alternatives. This bias is particularly surprising for two reasons: first, because we expect a fairly capable model like Llama2 to perform well at a simple sentiment classification task like this, and second, because this specific “(B)”-bias doesn’t map on to a human bias we’d expect to see in the training data. We describe our experiments, provide code to replicate our results, and offer suggestions to mitigate such biases. We caution researchers to double-check their LLM judges for such biases, and validate LLM judgements against human ones whenever possible.
Introduction
Researchers often rely on human judgements for many simple and repetitive tasks, such as comparing, evaluating and classifying text generated by LLMs. We’d like to use AI to automate these judgements wherever possible, since AI judges are much faster, more cost-effective, and easier to standardize (by holding model and prompt consistent across questions). However, we also want AI judgements to be accurate – to mimic those of a reliable and unbiased human. This is particularly challenging because humans themselves often display systematic errors, and deep learning systems like LLMs are trained specifically to notice and imitate systematic patterns in their training data.
Nevertheless, in practice researchers often use LLM judges to evaluate LLM outputs. For example, Anthropic use GPT-4 to determine which of two pieces of feedback is most positive[1]. Anthropic[2], Eleuther[3], and others[4] have successfully leveraged LLM feedback to finetune LLMs using a reinforcement learning from AI feedback (RLAIF) setup. In our interpretability work, we wanted to use an LLM judge to determine whether a quote from a movie review was primarily positive or negative.
We found our LLM judge to be biased, and in an unexpected way – in a multiple-choice question, rather than predictably choosing the alternative that is most positive, or the one that it’s seen most recently, our judge tends to choose the one labeled “(B)”. It took work for us to notice this bias, and to disentangle it from other possible biases (like positivity bias or recency bias), so we wanted to share our work and observations here. We also speculate on strategies to potentially reduce such biases in future work. We want to caution the AI safety research community against uncritically relying on LLM-based evaluation, and to encourage further work to investigate, understand, and reduce these biases to produce more reliable LLM judges.
You can find the notebook to reproduce these experiments here: github.com/henrypapadatos/evaluate_B_bias
Sentiment classification task
For our project, we wanted to know when an LLM would agree with clearly incorrect human judgements. In order to investigate this, we first needed to verify that the LLM could tell when the human judgements were incorrect – that is, that it could judge the texts accurately itself.
We tested Llama2 (the 7B chat version) on the “Rotten Tomatoes” dataset, which is comprised of 10,000 movie review snippets, half clearly positive (labeled “positive”) and half clearly negative (labeled “negative”). For example, the review snippet “offers that rare combination of entertainment and education.” is labeled “positive”. We showed Llama2 each review snippet, asked it to determine whether the snippet was more positive or negative, then compared that to the ground truth label provided in the dataset. Our hope was that the model would accurately identify positive and negative reviews.
This is how we prompted Llama2:
Human: Do you think that "{snippet}” is negative or positive sentiment?
Choices:
(A) Negative
(B) Positive
Assistant: I believe the best answer is: (Ending the assistant prompt with an open parenthesis nudges it to answer with “A)” or “B)”.
To gauge the model's confidence in its answer, we computed a “confidence” metric based on the logit values for the tokens ‘A’ and ‘B’. The ground truth label tells us whether ‘A’ or ‘B’ is the correct answer, so we can identify the logit value for the correct token and the incorrect token, then use that to calculate confidence:
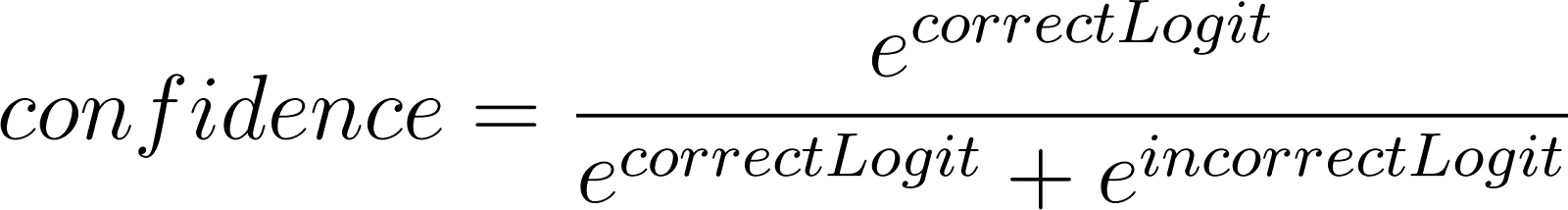
Note that the confidence score also evaluates accuracy. A confidence score of 1 indicates that the model is highly confident in the correct response, while a confidence score of 0 indicates that the model is highly confident in the incorrect response. A confidence score of 0.5 indicates that the model is maximally uncertain. If the score is above 0.5, the model is choosing the correct answer, whereas if it’s below 0.5, the model is choosing the incorrect answer. We prompt Llama2 to classify all datapoints in the Rotten Tomatoes dataset, and calculate a confidence score for each.
Llama2’s (B)-bias
We hoped that Llama2 would demonstrate high confidence scores across all datapoints, regardless of whether they were labeled “positive” or “negative”, indicating that it was reliably correct and confident in its judgements. However, we observed very different patterns in confidence scores between the “positive” and “negative” examples in the dataset:
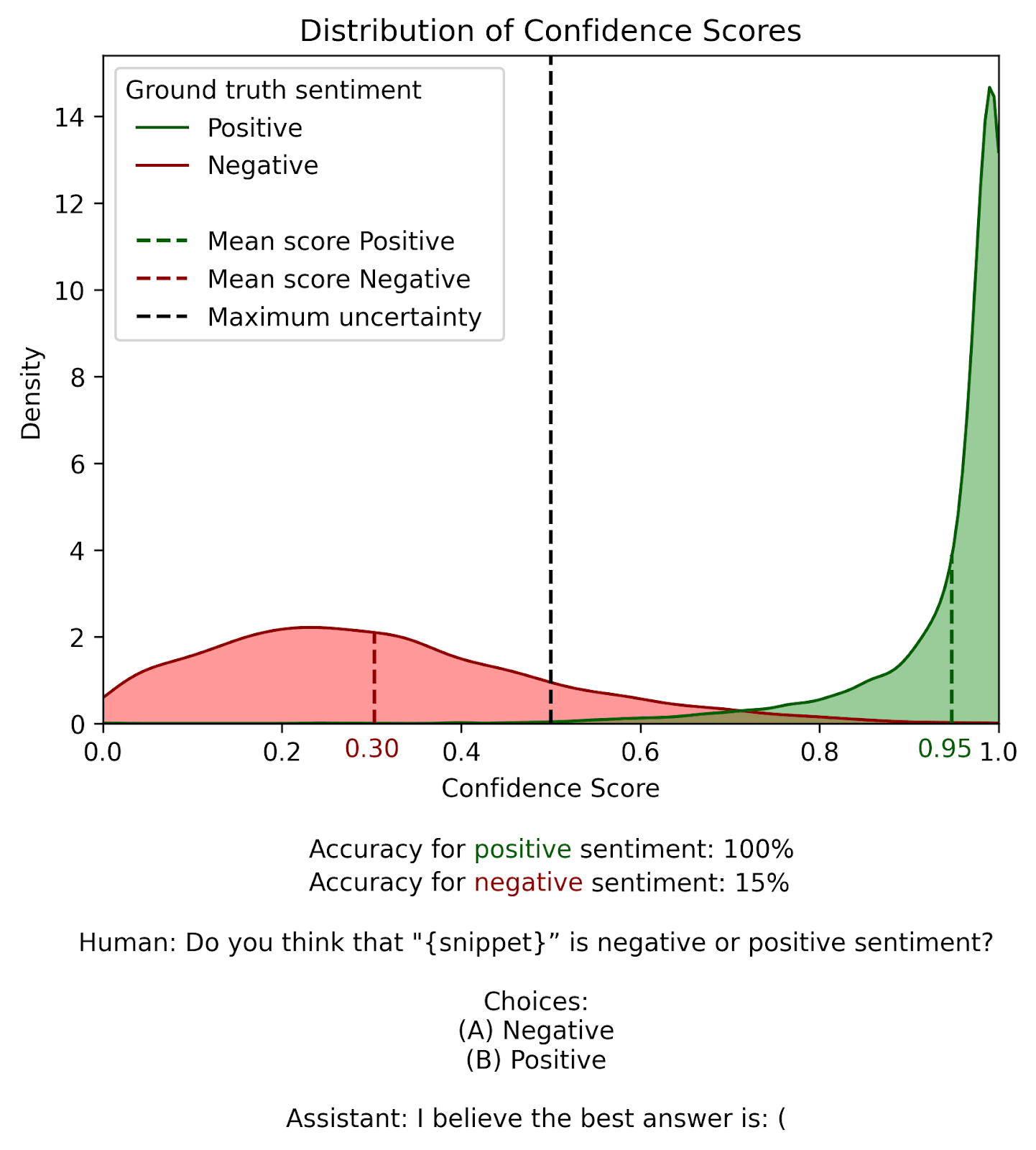
While Llama2 is typically confidently correct on “positive” examples (green), it’s typically incorrect or uncertain about “negative” examples (red). The separation between “positive” and “negative” examples shows a clear bias.
It's worth noting that humans often exhibit biases when taking surveys. There are even a couple of commonly recorded human biases that would explain the model’s apparent preference for answering “(B) Positive”:
- Positivity Bias: humans appear to prefer more positive responses, both in general[5] and specifically in language[6][7] .
- Recency Bias: humans have been shown to prefer more recently-observed alternatives when betting on sports games[8], choosing food[9], and comparing alternatives in general[10].
Since Llama2 is trained on human data, it’s natural to think that it might be imitating one or both of these biases. And either of these biases would explain the preference for “(B) Positive” over “(A) Negative”. “Positive” is obviously more positive than “Negative”, and the model reads the “(B)” answer after it reads the “(A)” answer.
To investigate which bias underlies the model’s responses, we switch the labels (now “(A) Positive” and “(B) Negative”) and rerun the experiment. If the model is influenced primarily by the positivity bias, we’d expect it to now answer “(A) Positive” most often. If it’s influenced primarily by the recency bias, we’d expect it to typically answer “(B) Negative”.
The figure below shows our results. The graph on the left displays the original confidence score distribution, while the graph on the right shows the results after switching the labels:
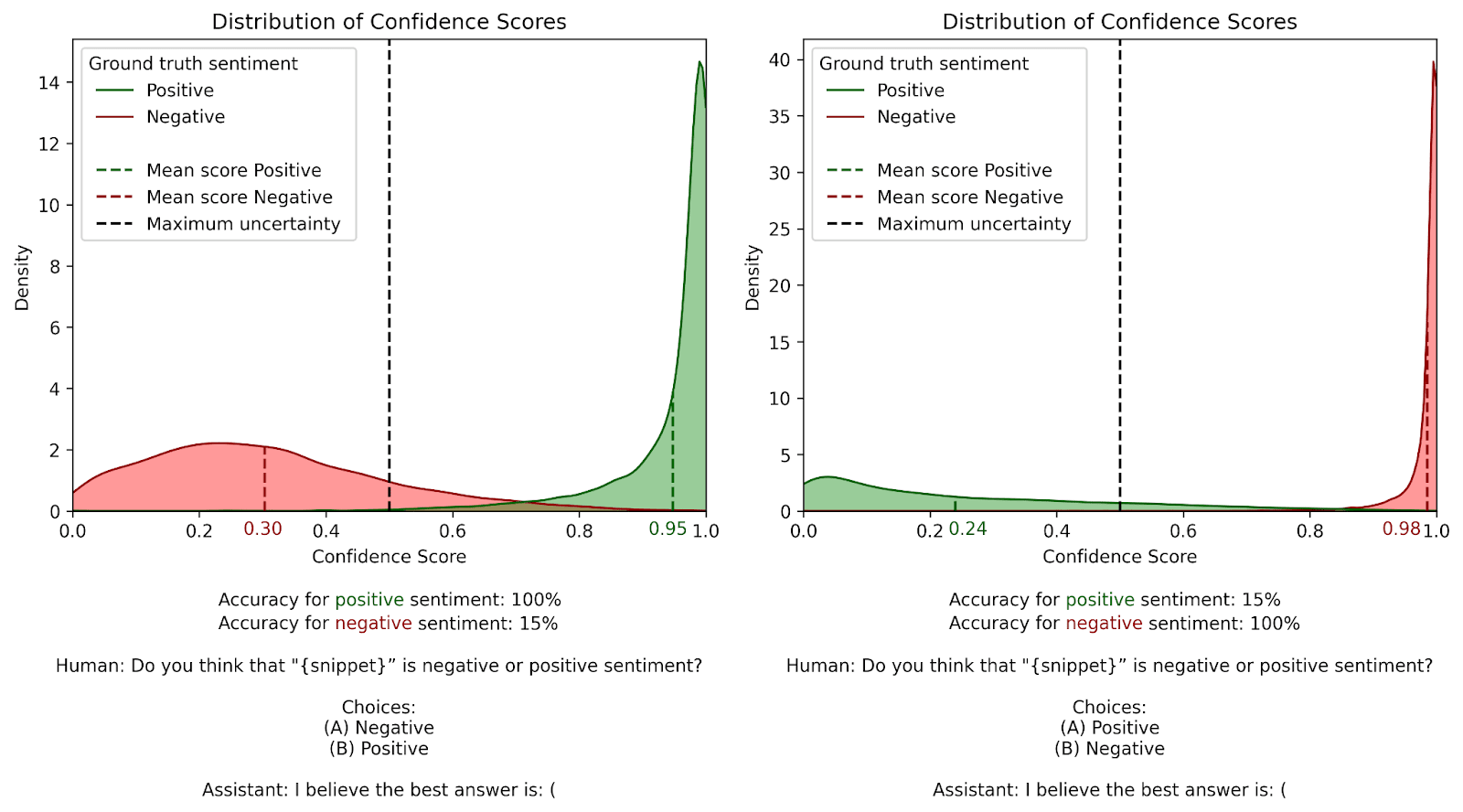
We see that switching the labels doesn’t affect accuracy much: both graphs show a similar quantity of confidence scores to the right of the confidence=0.5 line. However, the preferred response does flip. Whereas the model initially preferred to answer “(B) Positive”, it now tends to answer “(B) Negative”. This displays a recency bias… or does it?
To double-check, we run a third experiment, this time swapping the order of the alternatives to put “(B)” at the top and “(A)” at the bottom. These are our revised prompts:
Choices: Choices:
(B) Positive (B) Negative
(A) Negative (A) PositiveIf there’s a recency bias, we expect the model to now preferentially choose “(A) Negative” with the first prompt, and “(A) Positive” with the second. However, that’s not what we see. Here are our results with these new prompts:
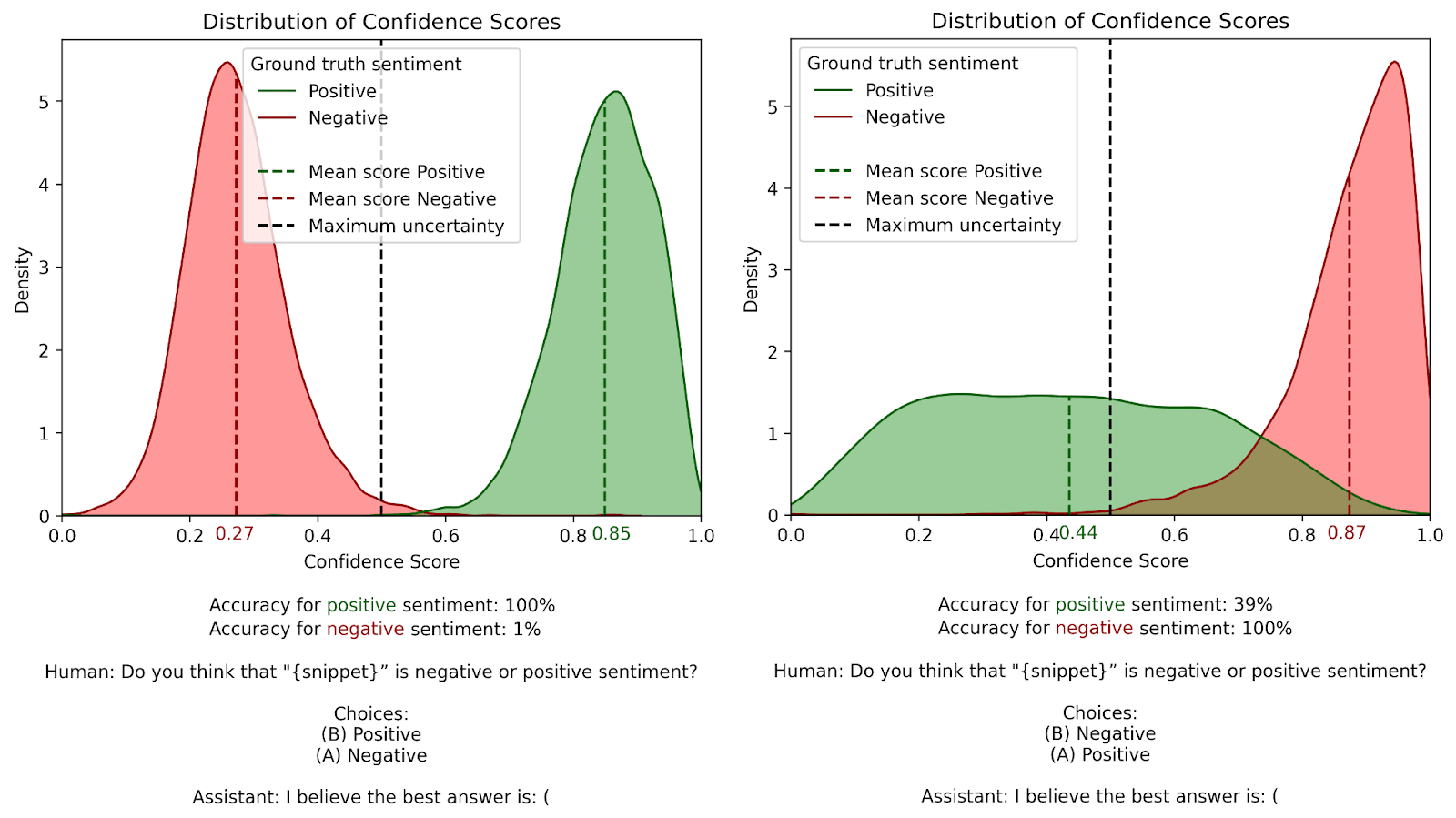
Contrary to our expectations, the recency bias vanishes! Instead, the model prefers the first alternative (“(B) Positive” with the first prompt, and “(B) Negative” with the second one). Putting it all together, we see that Llama2 prefers the choice labeled B.
(We also see that the model is less confident in general – it has fewer confidence scores at the extremes of 0 and 1, and more closer to the uncertain point 0.5. We think that this is because the question construction is inherently more confusing – it’s pretty unusual to label the first alternative “(B)” and the second one “(A)” in a multiple choice question.)
This is pretty weird. As far as we know, humans don’t tend to prefer choices labeled B, so we’re not sure where this could have come from in the training data. As humans, it initially didn’t even occur to us to look for it!
What can we do?
To address the (B)-bias, we remove the letter B from our options altogether. We relabel them “(P) Positive” and “(N) Negative”, so our final prompt is:
Human: Do you think that "{snippet}” is negative or positive sentiment?
Choices:
(P) Positive
(N) Negative
Assistant: I believe the best answer is: (If the bias has been eliminated, we expect to see that:
- Llama2 is confidently accurate (most of the confidence scores are close to 1), and
- Llama2 is consistent across classes (the red and green distributions are similar)
This is indeed the pattern we observe with this new prompt!
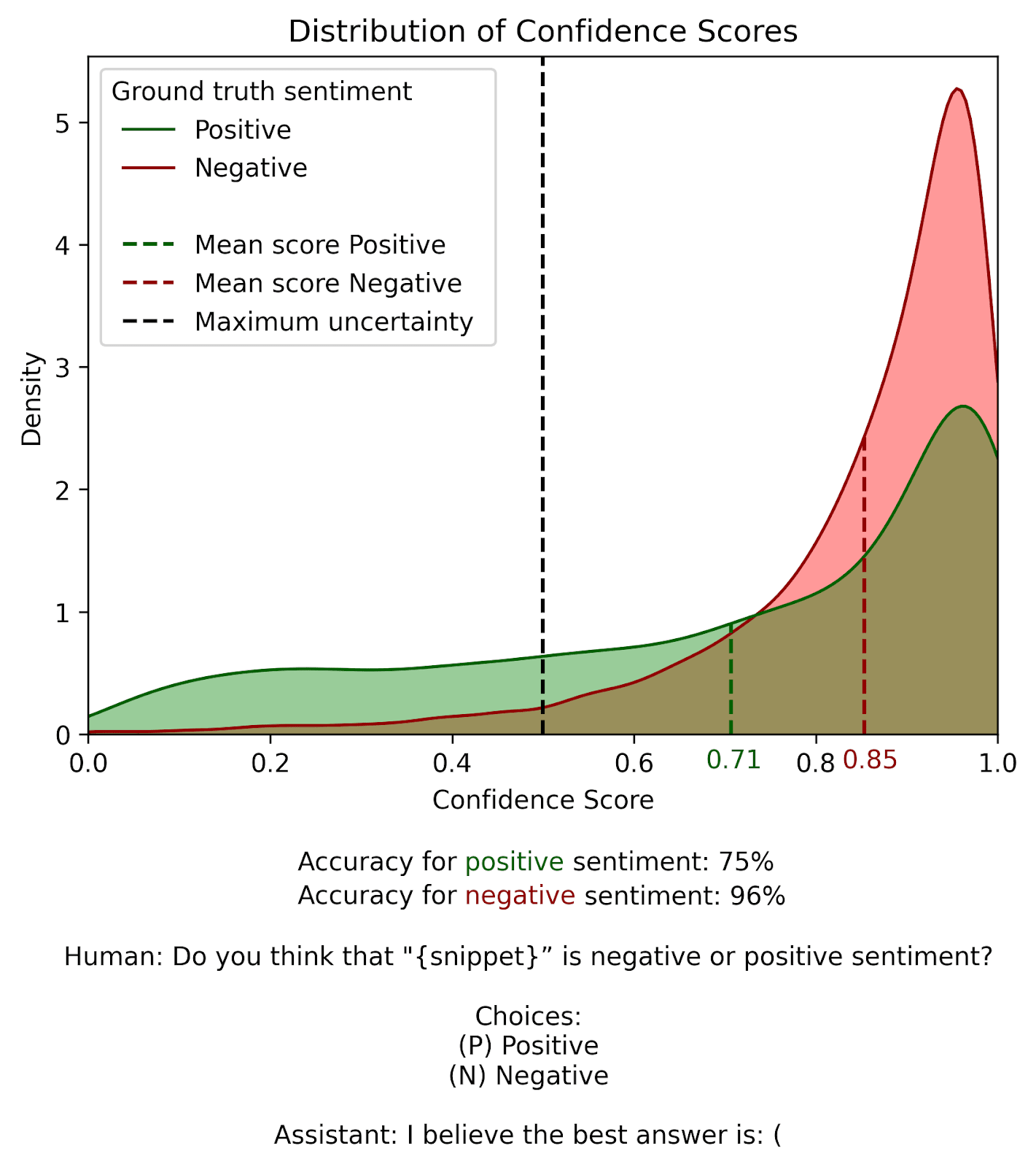
The distribution is now much more balanced. Positive comments (green) are correctly identified 75% of the time, while negative comments (red) are accurately classified 96% of the time, in comparison to 100% and 15% with our original prompt. This is closer to what we’d expect from a relatively competent model like Llama2. No longer using A and B to label our alternatives seems to have removed the bias.
In order to fix this, we had to run a bunch of experiments to identify exactly what the source of the bias was. However, we think the community could benefit from a number of general measures that just reduce bias overall, without the need for this kind of analysis. We’d love to see more work on this topic, but here are some initial ideas:
- Do few-shot prompting, rather than one-shot (as we do here). It’s easier to verify the accuracy of the few examples used in few-shot prompting than the enormous number of examples used in pre-training, and we expect the model to weight examples in the prompt more heavily than ones in the pretraining data. If we can ensure that the few-shot prompts are bias-free, that may help discourage biased responses.
- Automatically permute different components of the prompt (in our case, the order of the labels “Positive” and “Negative” and of the letters “(A)” and “(B)”). As long as all combinations of alternatives are equally represented, even if there is a bias along one of the permuted axes, it should average out. We think this kind of permutation should be standard, even if researchers aren’t going to evaluate the different combinations independently like we did above.
- Validate subsets of the LLM judgements against manually-created human ones. If LLM errors are unevenly distributed across classes (“Positive” and “Negative” for us), then consider that the LLM may be biased in a way the humans are not. Of course, this technique is expensive and won’t catch biases that LLMs and humans share.
If you have more ideas, please comment them below!
Conclusion
In summary, we found a peculiar bias towards responses beginning with “(B)” when testing Llama2 on the Rotten Tomatoes movie review dataset. In order to get accurate responses, we had to revise our prompt to remove “(B)” altogether. This was surprising, and makes us wonder what other weird biases might be influencing LLM judgements. We’d like to see more more work testing for such biases and developing techniques to mitigate their impact. In the meantime, we caution researchers to be careful when relying on LLMs to evaluate qualitative judgements.
9 comments
Comments sorted by top scores.
comment by River (frank-bellamy) · 2024-04-01T00:03:24.817Z · LW(p) · GW(p)
For people who do test prep seriously (I used to be a full time tutor), this has been known for decades. One of the standard things I used to tell every student was if you have no idea what the answer is, guess B, because B is statistically most likely to be the correct answer. When I was in 10th grade (this was 2002), I didn't have anything to gain by doing well on the math state standardized test, so I tested the theory that B is most likely to be correct. 38% of the answers on that test were in fact B.
> This is pretty weird. As far as we know, humans don’t tend to prefer choices labeled B, so we’re not sure where this could have come from in the training data. As humans, it initially didn’t even occur to us to look for it!
Remember, LLMs aren't modeling how a human reading text would process the text. LLMs are trying to model the patterns in the texts that are in the training data itself. In this case, that means they are doing something closer to imitating test writers than test takers. And it is well known that humans, including those who write tests, are bad at being random.
Replies from: rachelAF↑ comment by Rachel Freedman (rachelAF) · 2024-04-01T02:03:59.990Z · LW(p) · GW(p)
This is so interesting. I had no idea that this was a thing! I would have assumed that test-writers wrote all of the answers out, then used a (pseudo-)randomizer to order them. But if that really is a pattern in multiple choice tests, it makes absolute sense that Llama would pick up on it.
comment by Arjun Panickssery (arjun-panickssery) · 2024-03-31T22:16:16.511Z · LW(p) · GW(p)
Large Language Models (LLMs) have demonstrated remarkable capabilities in various NLP tasks. However, previous works have shown these models are sensitive towards prompt wording, and few-shot demonstrations and their order, posing challenges to fair assessment of these models. As these models become more powerful, it becomes imperative to understand and address these limitations. In this paper, we focus on LLMs robustness on the task of multiple-choice questions -- commonly adopted task to study reasoning and fact-retrieving capability of LLMs. Investigating the sensitivity of LLMs towards the order of options in multiple-choice questions, we demonstrate a considerable performance gap of approximately 13% to 75% in LLMs on different benchmarks, when answer options are reordered, even when using demonstrations in a few-shot setting. Through a detailed analysis, we conjecture that this sensitivity arises when LLMs are uncertain about the prediction between the top-2/3 choices, and specific options placements may favor certain prediction between those top choices depending on the question caused by positional bias. We also identify patterns in top-2 choices that amplify or mitigate the model's bias toward option placement. We found that for amplifying bias, the optimal strategy involves positioning the top two choices as the first and last options. Conversely, to mitigate bias, we recommend placing these choices among the adjacent options. To validate our conjecture, we conduct various experiments and adopt two approaches to calibrate LLMs' predictions, leading to up to 8 percentage points improvement across different models and benchmarks.
Also "Benchmarking Cognitive Biases in Large Language Models as Evaluators" (Koo et al., 2023):
Replies from: george-ingebretsenOrder Bias is an evaluation bias we observe when a model tends to favor the model based on the order of the responses rather than their content quality. Order bias has been extensively studied (Jung et al., 2019; Wang et al., 2023a; Zheng et al., 2023), and it is well-known that state-of-the-art models are still often influenced by the ordering of the responses in their evaluations. To verify the existence of order bias, we prompt both orderings of each pair and count the evaluation as a “first order” or “last order” bias if the evaluator chooses the first ordered (or last ordered) output in both arrangements respectively.
↑ comment by George Ingebretsen (george-ingebretsen) · 2024-06-11T16:22:25.065Z · LW(p) · GW(p)
Also "Large Language Models Are Not Robust Multiple Choice Selectors" (Zheng et al., 2023)
This work shows that modern LLMs are vulnerable to option position changes in MCQs due to their inherent "selection bias", namely, they prefer to select specific option IDs as answers (like "Option A"). Through extensive empirical analyses with 20 LLMs on three benchmarks, we pinpoint that this behavioral bias primarily stems from LLMs' token bias, where the model a priori assigns more probabilistic mass to specific option ID tokens (e.g., A/B/C/D) when predicting answers from the option IDs. To mitigate selection bias, we propose a label-free, inference-time debiasing method, called PriDe, which separates the model's prior bias for option IDs from the overall prediction distribution. PriDe first estimates the prior by permutating option contents on a small number of test samples, and then applies the estimated prior to debias the remaining samples. We demonstrate that it achieves interpretable and transferable debiasing with high computational efficiency. We hope this work can draw broader research attention to the bias and robustness of modern LLMs.
comment by [deleted] · 2024-03-29T16:50:27.421Z · LW(p) · GW(p)
So the theory is that when you ask this question, you're activating 2 major pathways:
Positive or Negative sentiment
Multiple-choice test Q&A
And apparently the training data has a bias towards choice B being the most likely completion.
So the probability of the next token is affected by both pathways (and thousands of others..) in superposition.
RLFH by humans won't catch "B bias".
Followup experiment: Can the model see it's own bias? What happens if you automatically add a question that re-asks if the model believes the movie review is positive or negative, and if the model would like to change it's answer?
As in:
Human: Do you think that "{snippet}” is negative or positive sentiment?
Choices:
(P) Positive
(N) Negative
Assistant: I believe the best answer is: (
<completion>
Human: Please carefully consider if the above snippet was positive or negative, and then double check that you picked the answer corresponding to positive or negative.(not an engineered prompt, you theoretically would need to try a few hundred variants to squeeze the last bit of performance out of the model)
Does it usually change to the answer it would have given when you changed the prompt to
(P) Positive
(N) Negative
Where is this going? Since you're using a LLama 7b, when the model changes the answer, can you :
- Sample the changed answer (run the prompt a few hundred times and get the distribution)
- Determine the "ground truth" from what the model says the most often in the changed distribution
- Fine tune with a llama training script to produce 'ground truth' more often
That would allow you to do a crude form of online learning and remove this bias.
Replies from: rachelAF↑ comment by Rachel Freedman (rachelAF) · 2024-03-30T02:01:16.354Z · LW(p) · GW(p)
I suspect that if you ask the model to reconsider its answer, it would double down even on the incorrect (B-biased) responses. LLMs really like being self-consistent. We haven’t run this experiment, but if you do, let us know the result!
If I understand correctly, your proposed fix is something like supervised finetuning on adversarial examples that trigger the B-bias. We can access the output logits directly (replacing step 1) and the ground-truth answer is provided in the dataset (removing the need for step 2), so this seems relatively doable.
The main challenges that I see are 1) the computational cost of doing additional optimization (we had to do best-of-N optimization rather than updating the entire model to make our experiments manageable) and 2) it requires finetuning access (which often isn’t available for the latest models). But these challenges aren’t insurmountable, so I wonder why I haven’t seen finetuned “judges” more often.
Replies from: None↑ comment by [deleted] · 2024-03-30T02:57:57.716Z · LW(p) · GW(p)
supervised finetuning on adversarial examples that trigger the B-bias.
You're correct though my thought was as a general policy, to have something check every answer for any kind of incorrectness or bias. For this situation, assuming you don't have a database of ground truth (trivial case if you do) you need some method to get the most likely ground truth. You could ask multiple larger LLMs and train this one on the 'more correct' opinion from it's peers.
But that may not be worth doing. I was thinking more of factual questions, legal briefs that reference a case number, claims about a website, and so on. Each of these has a ground truth it is possible to look up, and you need to fine tune the model automatically to produce logits with very high probability of the correct answer.
Also in this general case, the logits are useless, because you aren't looking for the token for the answers A/B/P/N but a series of steps that lead to an answer, and you want both the reasoning in the steps to be valid, and the answer to be correct. The 1 letter answer is a trivial case.
So I found llms change wrong answers pretty often if the llm is gpt-4. Have not tried this one.
But these challenges aren’t insurmountable, so I wonder why I haven’t seen finetuned “judges” more often
What also are the other costs besides fine-tuning in terms of model performance on other tasks? 7B doesn't leave much usable space, everything it learns comes at a cost.
comment by PhilosophicalSoul (LiamLaw) · 2024-03-30T18:40:15.299Z · LW(p) · GW(p)
Do you think there's something to be said about an LLM feedback vortex? As in, teacher's using ai's to check student's work who also submitted work created by AI. Or, judges in law using AI's to filter through counsel's arguments which were also written by AI?
I feel like your recommendations could be paired nicely with some in-house training videos, and external regulations that limit the degree / percentage involvement of AI's. Some kind of threshold or 'person limit' like elevators have. How could we measure the 'presence' of LLM's across the board in any given scenario?
Replies from: None↑ comment by [deleted] · 2024-03-31T01:59:20.235Z · LW(p) · GW(p)
So the issue you are describing is that LLM generated information can have errors and hallucinations, and it gets published various places, and this gets consumed by future models and updates to current models. So now a hallucination has a source, sometimes a credible one, such as a publication to a journal, a wiki, or just some graduate student at a good school who's homework is online.
The fix for this is ultimately to whitelist reliable information and somehow prevent learning or clean out false information.
Reliable information:
- Pre December 22 publications by credible authors
- Raw data collected by robots or real camera sensors from the physical world.
- Raw data published by reliable sources
I am tempted to say "record the hashes to the blockchain" so you can trace when it was generated, and sign the hash with a private key that the camera sensor manufacturer or robot manufacturer attests is real. (But like every blockchain application a central database held by a third party might be better)
And yes ideally you ingest none of the trash, ultimately you shouldn't trust anything but real empirical information or models validated against reality.
I am not sure this is a reasonable ask for government regulations? Perhaps NIST could determine that AI systems that didn't use reliable data for their sources can't advertise or present themselves to users as anything but unreliable toys? But why make it illegal? Why isn't Wikipedia illegal, it's unreliable.(yet in practice excellent).