Minor interpretability exploration #3: Extending superposition to different activation functions (loss landscape)
post by Rareș Baron · 2025-03-14T15:45:14.365Z · LW · GW · 0 commentsContents
Introduction TL;DR results Methods Results General Specific GELU (bottom) is mostly just a softer ReLU (top), with slightly reduced and delayed superposition. Discussion Conclusion Acknowledgements None No comments
Epistemic status: small exploration without previous predictions, results low-stakes and likely correct.
Introduction
As a personal exercise for building research taste and experience in the domain of AI safety and specifically interpretability, I have done four minor projects, all building upon code previously written. They were done without previously formulated hypotheses or expectations, but merely to check for anything interesting in low-hanging fruit. In the end, they have not given major insights, but I hope they will be of small use and interest for people working in these domains.
This is the third project: extending Timaeus' toy models of superposition devinterp results, made for studying the formation of superposition during the training process and using the LLC. It is partially this project.
The TMS results have been redone using the original code, while changing the activation function.
TL;DR results
Broadly, there were four main observations, all somewhat confusing and suggesting that additional research is needed:
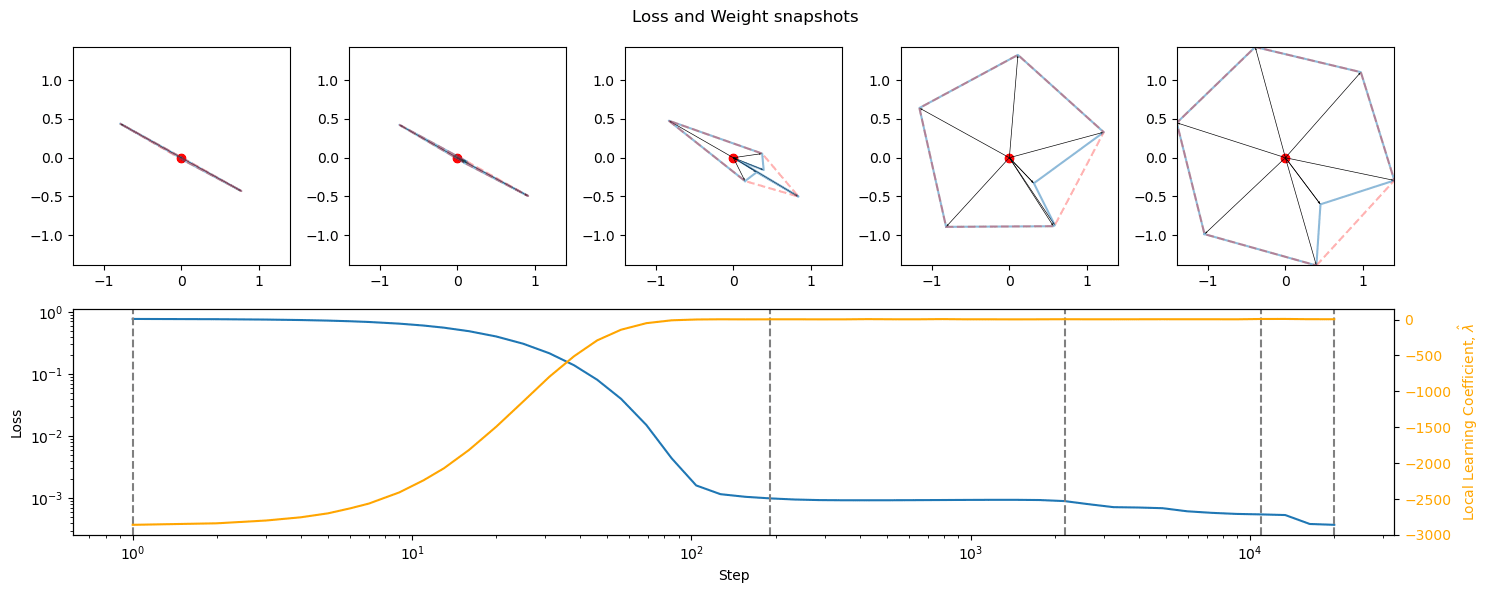
- During training, the emergence of superposition happened only after the largest drops in loss, and was correlated with phase changes: mostly small drops in loss and rises in LLC (superposition seems to only happen in flat and well-delineated basin regions). Does superposition correspond to singularities in the loss landscape?
- Losses were in the 10^-3 – 10^-2 range. Besides the limiting activation functions (see below), loss and LLC development was not marginally different.
- Degree of superposition did not seem to be correlated with loss and LLC beyond a certain threshold. More superposition does seem to reduce loss by at most one degree of magnitude.
- Small variations in activation functions lead to massive differences in superposition (see CELU vs. GELU), which do not however translate into differences in the loss landscape.
The last three correspond to previous findings (see project #2 [LW · GW]).
Methods
The basis for these findings is the TMS notebook of the devinterp library, plus the example code given.
All resulted notebooks, extracted graphs, tables, and word files with clean, tabular comparisons can be found here.
Results
General
General observations have been given above.
Specific
Specific observations for the functions:
Loss functions with bounded outputs (sigmoids, tanhs, softsign, softmin) have small loss curves and similarly small values for LLC. Their limited results give a very flat loss landscape. They also show somewhat limited superposition outside of antipodal pairs, likely due to their continuity, symmetry, and limited output. This contradicts the findings of post #2 [LW · GW] as well as Lad and Kostolansky (2023), which showed significant superposition for Sigmoid. While model differences could be to blame (this uses Autoencoders, while project #2 was for simple MLPs), Lad and Kostolansky (2023) also used autoencoders, with the nonlinearity at the end, and their findings do not correspond to the ones here. This is confusing and requires further research.
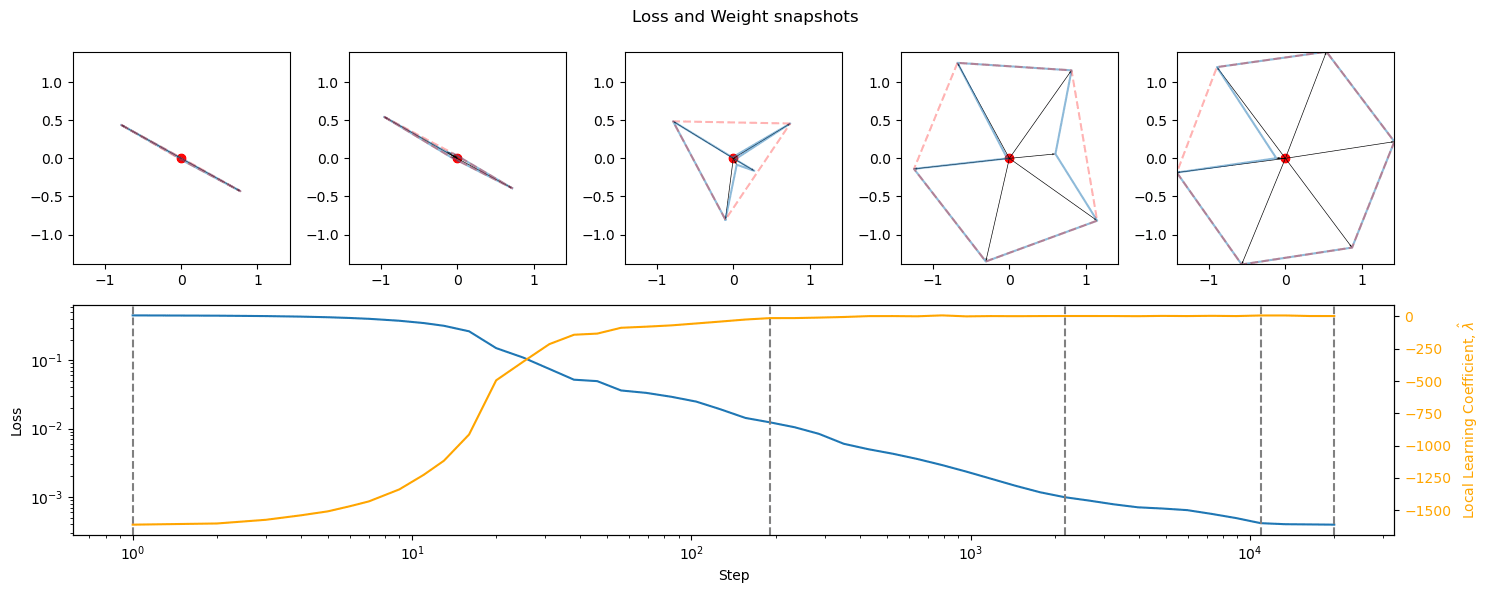
Softplus has slow-developing superposition, likely due to a less clearly delimited (than 0) elbow. That said, it had some of the most prominent superposition.
GELU (bottom) is mostly just a softer ReLU (top), with slightly reduced and delayed superposition.
SoLU (bottom) gave greater superposition than softmax (top), despite being intended to reduce it. This contradicts previous research (see project #2 [LW · GW]). The lack of LN may be to blame. This is very confusing. More research is needed.
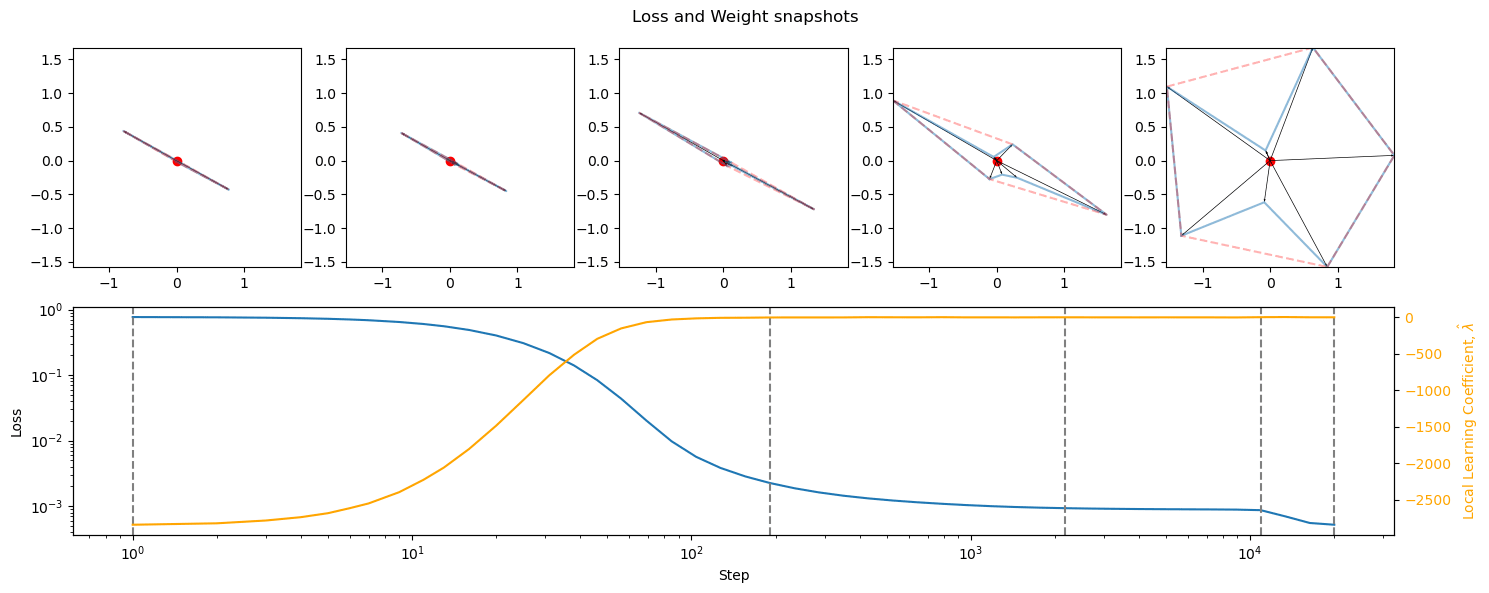
(LeakyReLU), GELU, SoLU (!) and Softplus showed the most superposition. Possible causes:
- The sharper gradient/elbow, as they more effectively cap certain intervals of the input (most pronounced with ReLU). This would however entail a larger difference between swish and hardswish, which is not present.
- Some of the activation functions let through negative values, even if only up to -1/-2, hindering the masking effect of these functions, necessary for superposition. This might explain the prominent superposition of GELU/Softplus ((softly) capped at 0) versus the smaller superpositions of CELU/ELU. Another piece of supporting evidence is the fact that the only function that (quickly) goes to -2 is SELU, which shows the lowest level of superposition in its groups.
- SoLU was designed to reduce superposition, and it did for LMs with very sparse data. SoLU increasing it here contradicts previous research (including post #2 [LW · GW]). These results may come from model differences and the lack of LayerNorm. This is very confusing. More research is needed.
- The nearly linear Hardshrink managed to produce a small amount of superposition, indicating that it is a feature that networks will exploit as much as they can.
Tanhshrink and Softshrink, on the other hand, produced significant superposition. The less sharp boundaries seem to help. This seems confusing.
- ReLU6 and ReLU^2 gave little superposition. Capping and polynomial functions seem to hinder its development.
- Hardness reduces (or slows the development of) superposition (at least for the sigmoidal activation functions). This seems confusing.
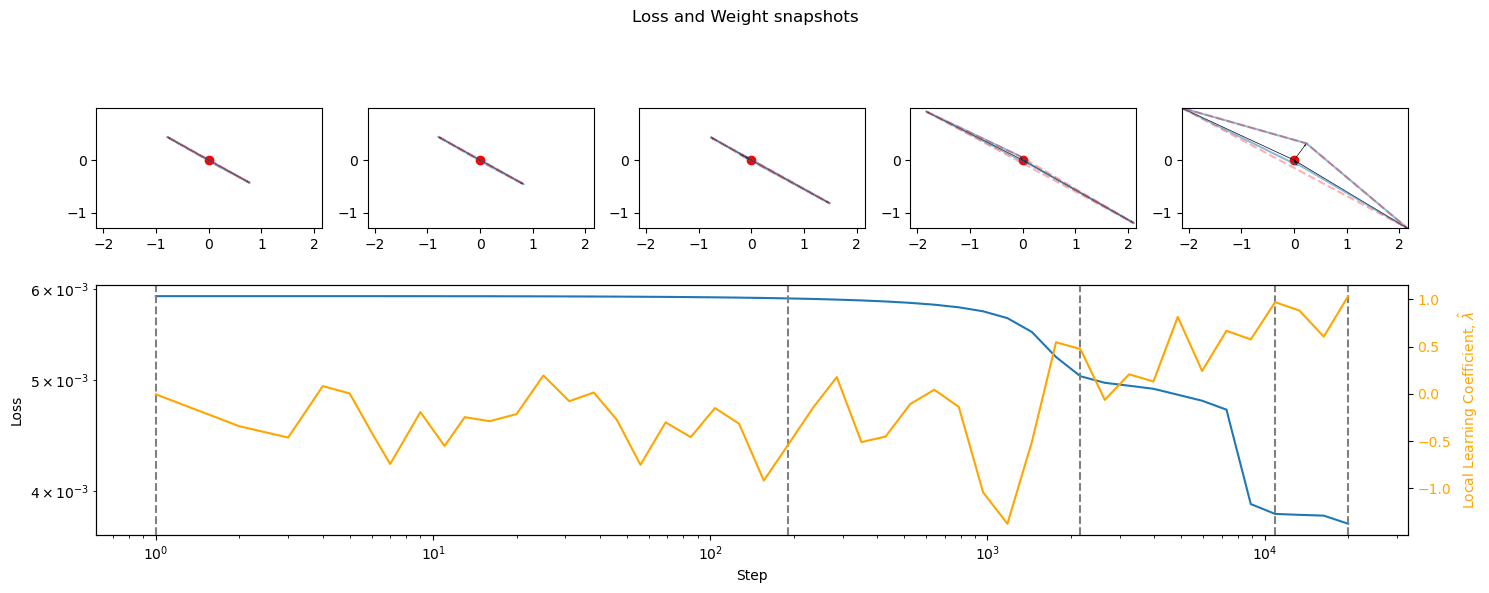
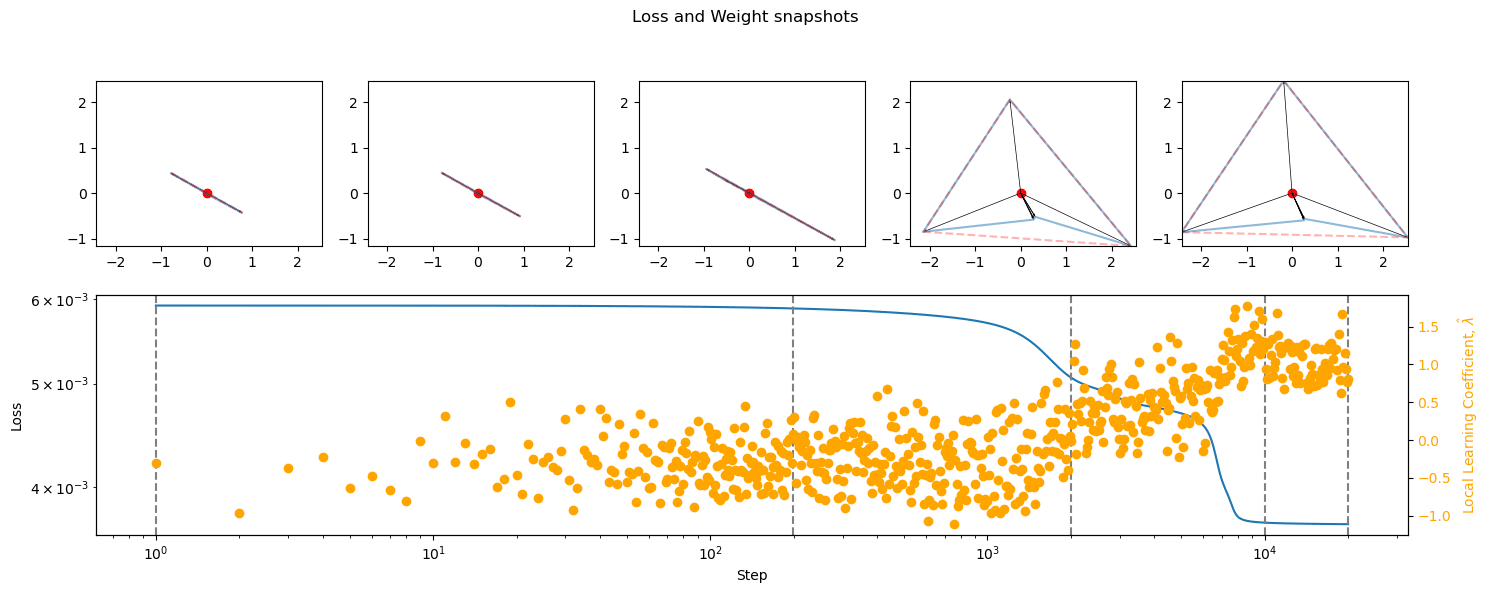
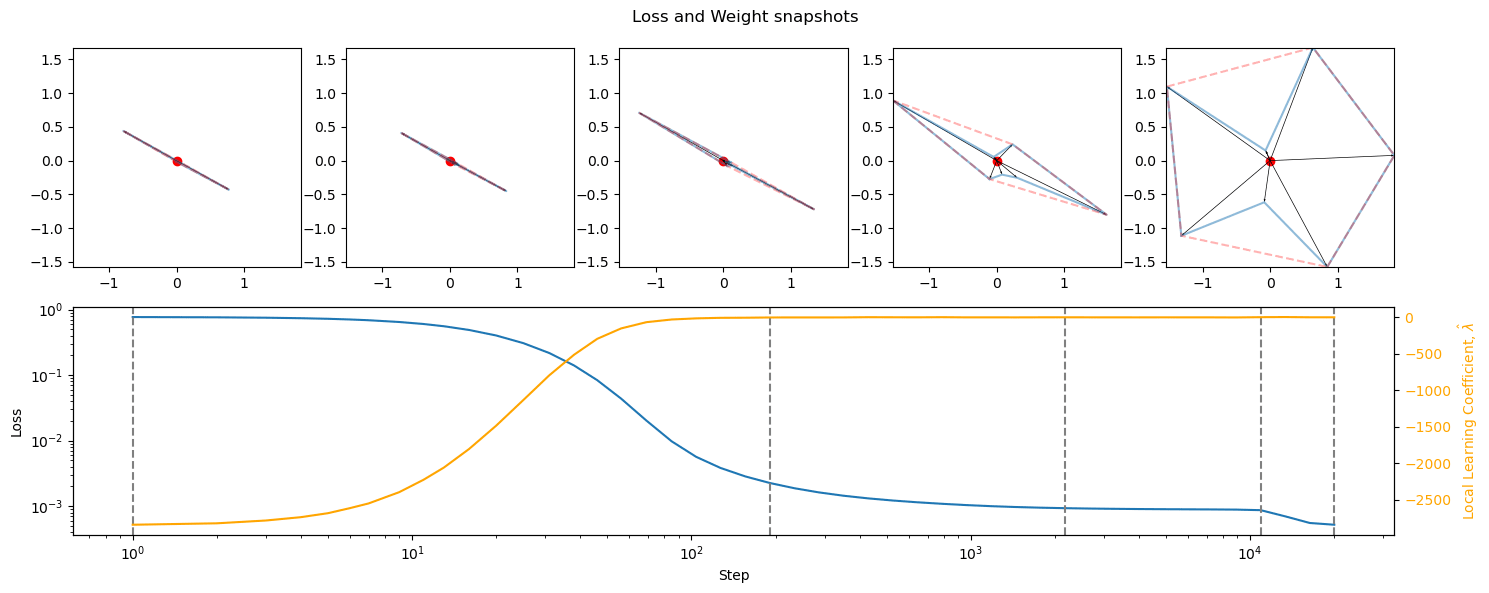
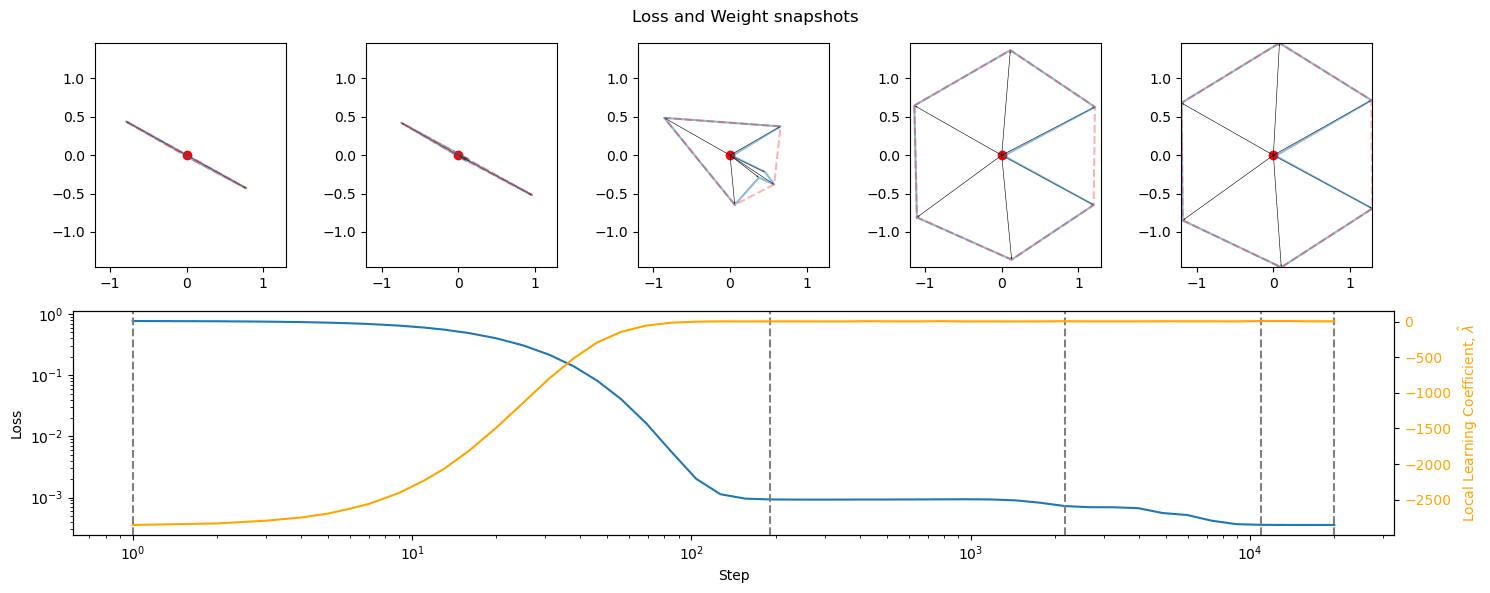
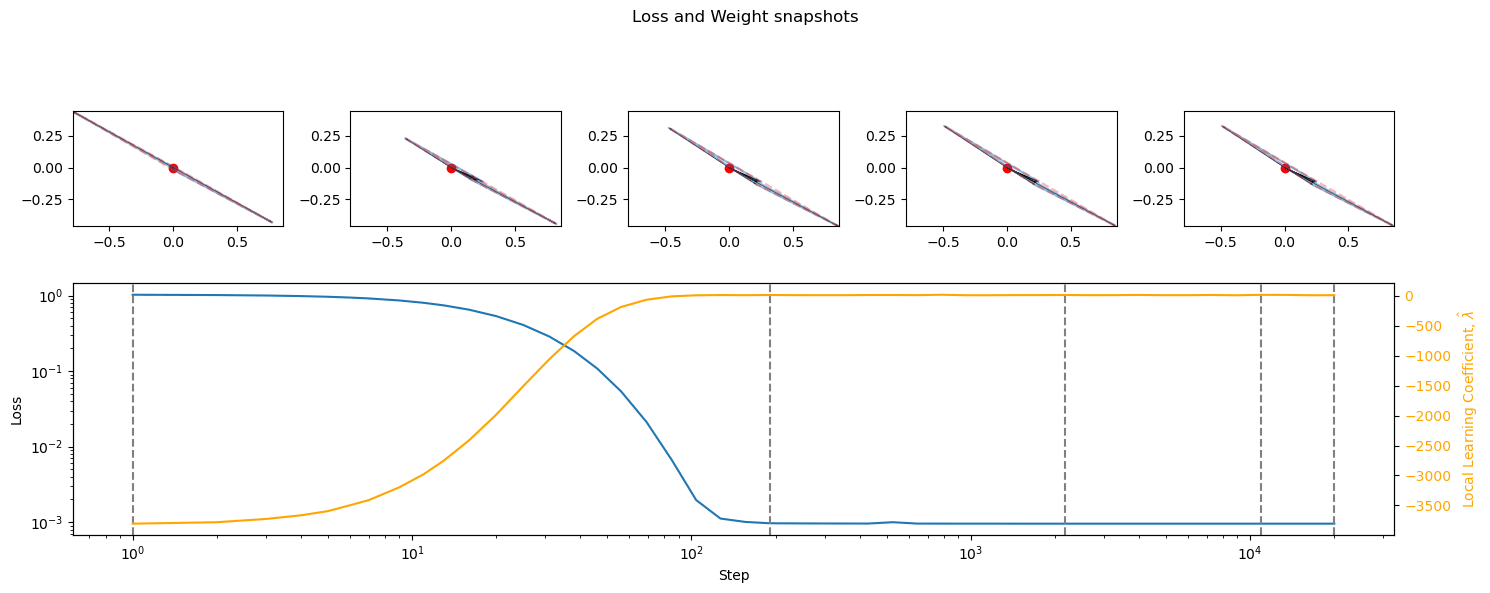
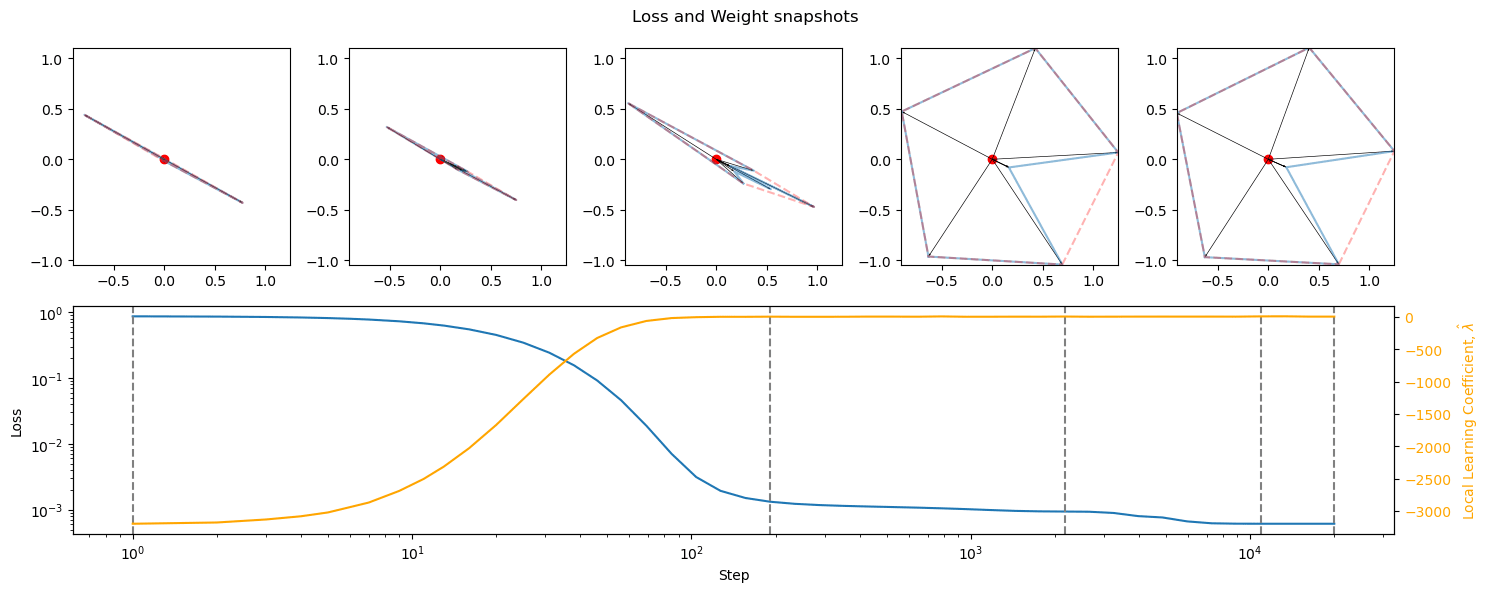
Discussion
The development of superposition happens after the initial large drop in losses, and does correspond to phase changes to a degree. Does superposition correspond to flat basins in the loss landscape, without it being necessary for their development? Do the basins correspond to symmetrical/deeply entrenched basins?
Previous findings have been validated, with the addition that low degrees of superposition usually correspond to slower formation as well. Similar considerations and areas for further research apply here as well. The only large surprise is the vastly different superposition of limiting loss functions (sigmoid especially), which is confusing, and potentially SoLU.
More research is needed, potentially with finer-grained (applications of LLC or other) SLT tools. Otherwise, LLC behaved reasonably.
Conclusion
The broad conclusion is that more superposition leads to marginally smaller losses; the development of superposition happens after the initial large drop in losses during phase changes; sharp, non-negative, asymmetrical activation functions gave the best superposition and lowest losses.
Acknowledgements
I would like to thank the original Timaeus team for starting this research direction, establishing its methods, and writing the relevant code.
0 comments
Comments sorted by top scores.