Understanding Counterbalanced Subtractions for Better Activation Additions
post by ojorgensen · 2023-08-17T13:53:37.813Z · LW · GW · 0 commentsContents
Introduction Activations are not zero-centred => Activations are not purely features Counterbalanced Subtractions Mean-Centring Isolating Specific Features Introducing Additional Features Conclusion Appendix: Evidence for Mean-Centring Interpreting Mean-Centred Vectors Steering with Mean-Centred Vectors Mean-centring Isolating Specific Features Introducing Additional Features None No comments
Introduction
Activation additions [LW · GW] represent an exciting new way of interacting with LLMs, and have potential applications to AI safety [LW · GW]. However, the field is very new, and there are a few aspects of the technique that do not have a principled justification. One of these is the use of counterbalanced subtractions - both adding a feature vector we want, and taking away some vector that we do not want to be present in the output of the model. For example [LW · GW], to make a vector to steer the outputs of GPT-2 XL to be more loving, the activations associated with the input "Love" were paired with the input "Hate", subtracting the "Hate" activations from the "Love" activations. To quote Steering GPT-2-XL by adding an activation vector [LW · GW],
In our experience, model capabilities are better preserved by paired and counterbalanced activation additions.
It seems likely that counterbalancing subtractions are simultaneously performing a few different functions. Separating these out will allow us to better understand why counterbalanced subtractions work, as well as to develop more principled activation addition techniques.
Epistemic Status: I've spent a fair bit of time playing around with the activations of GPT-2 models + doing some activation additions type stuff, and feel relatively confident about the claim that removing bias is an important part of why counterbalancing subtractions work. I'm yet to perform a systematic experiment to confirm this however, which reduces my confidence.
Activations are not zero-centred => Activations are not purely features
An interesting fact about transformer models is that, for any given layer of the residual stream, the mean of the activations is quite large, and definitely not 0!
This phenomenon is quite well documented. Neel Nanda's first Mech Interp Puzzle [LW · GW] demonstrates this phenomenon for the embeddings of GPT-Neo and GPT-2 small, Cai et. al 2021 demonstrate this for residual stream vectors in each layer of BERT, D-BERT, and GPT, and a quick replication in GPT-2 XL demonstrates the same phenomenon.[1] Although it is interesting to hypothesise why the activations are not zero-centred,[2] we don't need to investigate this fact further to make use of it. For any given layer of the model, we can approximate the centre of the activations by just taking the mean of all activations from a subset of training examples. We will designate this by . Note that this can change across layers, so we will abuse notation a bit and use to refer to the mean of the activations in the residual stream layer currently being investigated.
Suppose we have a vector which is attained by feeding the word "love" through a GPT-2 style model and looking at the residual stream activations at some layer, and we want to extract a vector from this which will make the model outputs more loving via activation steering. We could either use the vector without modifications, or we can mean-centre it and use as the feature vector.
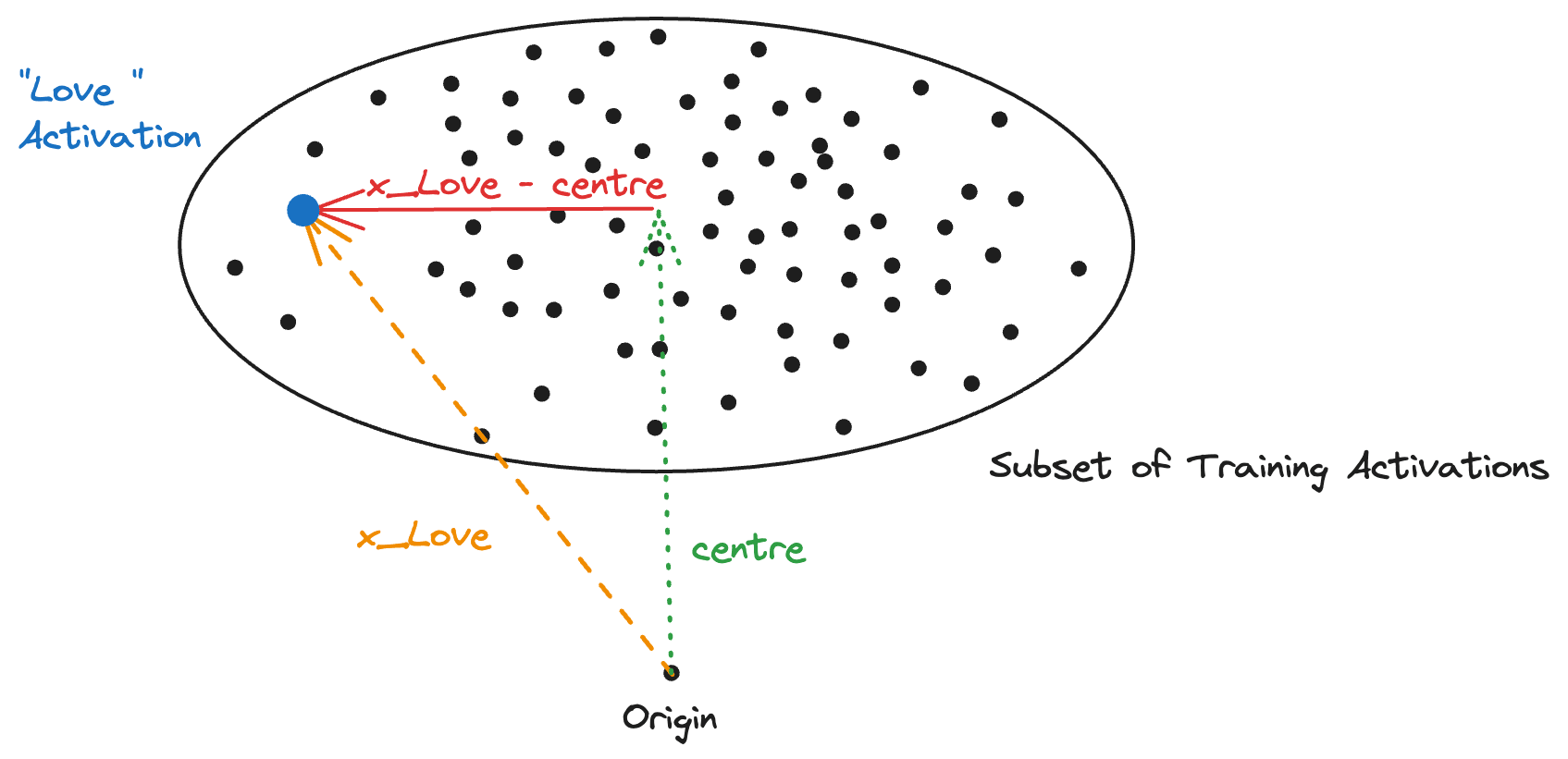
I'm going to essentially claim without proof that mean-centring is the most principled way to extract feature vectors. Mean-centring is a pretty standard technique in other aspects of interpretability, and I expect this to remain true here. I have included an appendix [LW · GW] which provides some anecdotal evidence for this.
Counterbalanced Subtractions
A popular method for extracting useful feature vectors from some activation vector is via counterbalanced subtractions. The general method for doing this is to create some vector , and subtracting to extract some hopefully useful feature vector .
There are some subtle variations for doing this, which might lead to subtly different feature vectors.
Mean-Centring
Mean-centring could be seen as the most basic form of counterbalanced subtraction. The simplest way to extract the desired from would be to just perform mean-centring, giving us .
Isolating Specific Features
Counterbalanced subtractions can also be used for more complex forms of feature extraction. For example, a vector might have multiple features, and we might only want to extract one of them. Consider as the mean of all activations from some stories about sports, which might be expressed as , where is the sports feature, and is the story feature.
Then if we want to isolate the vector, we might create a vector from the mean of all activations from a dataset of stories of various different themes. Then, if we assume that , we can extract the sports vector via .
Introducing Additional Features
In the "Love - Hate" example, we might imagine the love vector as corresponding to , the hate vector as , and hence the difference between these as . This means that not only does the vector correspond to "more love", but also to "less hate". Assuming and are not just opposite directions of the same vector, this is an example of counterbalanced subtractions being used to add two different features together.
Conclusion
Counterbalanced subtractions have so far played an important role in activation additions. This is because they are simultaneously performing two functions: mean centring, and better isolating features / introducing extra features. In order to perform more principled activation additions, it might be useful to separate these two purposes in the future.
Future work empirically demonstrating better performance of activation additions via alternatives to counterbalanced subtractions would be useful here. This might allow for more fine-grained control of LLMs via activation additions.
Appendix: Evidence for Mean-Centring
Interpreting Mean-Centred Vectors
The following is some anecdotal evidence that mean-centring is the most principled way to extract feature vectors from activations, if we ignore other issues like isolating specific features.
The setup here will mirror the SVD projection method used in The Singular Value Decompositions of Transformer Weight Matrices are Highly Interpretable [LW · GW]. Specifically, we will try to interpret a vector by projecting it into token space using the de-embedding matrix, and look at the top-8 tokens.
Here, the vector we will try to interpret will be produced by taking the mean of the activations across different fantasy stories[3]. We can similarly consider and . Applying this to an intermediate layer of GPT-2 XL (the 29th of 48) gives the following results, with the first row corresponding to the top token, the second row to the second top token, etc:
| unthinkable | unthinkable | unthinkable |
| enormous | enormous | enormous |
| massive | massive | massive |
| immense | immense | immense |
| fateful | fateful | fateful |
| vast | vast | vast |
| larger | larger | larger |
| formidable | colossal | obvious |
The fact that these are all the same suggests that the vectors , and are perhaps dominated by the bias vector: the vectors by themselves seem unrelated to the feature we are looking to extract. This is representative of most of the other intermediate layers (besides the first few layers, which do produce different top-8 tokens).
However, if we repeat this after mean centring, we get the following results:
| Elven | cosmic | swirling |
| warrior | interstellar | clenched |
| jewel | asteroid | sto |
| enchantment | disemb | pounding |
| realms | dimensional | flames |
| magical | Celestial | longing |
| Celestial | wasteland | clasp |
| Primordial | explorer | grit |
These tokens are not only almost all distinct, but each column seems related to the genres of the stories used to create the vectors.
This is maybe least true for the column. We might hypothesise that this is because there are other features of sports stories besides just sports related words. If we instead define as the mean of all activations from a dataset of stories with different genres, and look at the top-8 tokens associated with , then we get the following results:
| applause |
| clinch |
| cheering |
| spectators |
| scoreboard |
| clin |
| Wembley |
| announcer |
These seem more related to sports generally, not just sports stories. This might be evidence that is something similar to a sports feature, without including a stories feature as might have been the case previously.
Steering with Mean-Centred Vectors
Another sanity check is to see whether we can perform activation additions with vectors can be used to perform activation additions. I give an example of successful steering with each kind of counterbalanced subtraction. Note that some examples use GPT-2 Small instead of GPT-2 XL, since I found it easier to do this GPT-2 Small. I'm unsure if this is because it is just easier to find good hyperparameters for GPT-2 Small, since there are less layers to try, or if some of the techniques just work worse for GPT-2 XL.
Mean-centring
Here is an example of just mean-centring, using [4]with GPT-2 Small.
Steering before residual stream layer 6, adding to the first token in the sequence.
| Unsteered Completion | Steered Completion |
|---|---|
| A girl once had a goose egg. She was not the only one to have it. And now, as we enter the fourth quarter of the season, I’ve got to say that my favorite moment in football is when I’m on the field and watching the Dallas Cowboys take on their best team in seven years. It’s like a ghost town where you can’t even get out of bed until your phone rings | A girl once had a goose’s tail, but alas, her wild side has wane. A little beauty once brightened the sky with a maiden shine, but now she withers in the dark...and never shines again. A beautiful maiden once longed to dance for her fair queen, but now she is forgotten...and never ever shines again. She’s all fair, I’ll sing thee sweet sleep’s |
Isolating Specific Features
Here is an example of isolating specific features, using with GPT-2 XL.
Steering before residual stream layer 25, adding to the first token in the sequence.
| Unsteered Completion | Steered Completion |
|---|---|
| Here is a story: In the early 1970s, I was working at a company that produced toys for children. One day, my boss came into my office and asked me to come up with a new toy. He wanted something that would appeal to boys but be equally appealing to girls. He said he wanted something "girl-friendly." I thought about it for a moment and then began brainstorming ideas. | Here is a story: In the year 2040, humanity has colonized most of the known galaxy. Humanity has developed advanced technology and is now in a war with an advanced alien civilization. The two civilizations are at war over an unknown threat that threatens to destroy all life on Earth. It's up to you to decide whether or not you want to join the fight and take part in this epic space-faring adventure. |
Introducing Additional Features
Here is an example of introducing another feature (not sports) through counterbalanced subtractions, using with GPT-2 Small.
Steering before residual stream layer 6, adding to the first token in the sequence.
| Unsteered Completion | Steered Completion |
|---|---|
| Yesterday, my son was out kicking a football. Then, he went to the gym and I saw him. He was on his way to work. He had no shoes on and he was just playing with his feet.” My son’s father said that when I told him about the incident, he didn’t know what to say or do. ”He said ’I’m sorry,’ but it wasn’t something that I could say,” says my dad | Yesterday, my son was out kicking a football. Then, he went to the lake and was awakened by a strange creature. It seemed to be a magical creature that appeared in her home, and she found it there with an enchanted enchantment on it. She took it from the lake and told her that if she could find some kind of magical power in this enchanted land of the Lost Princesses (or perhaps even better) she could restore them back to life |
- ^
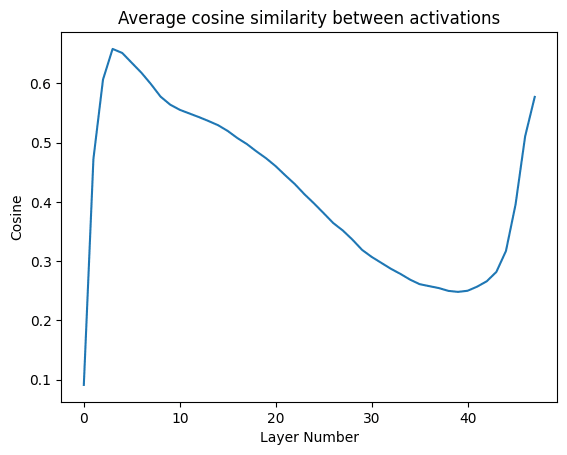
Average cosine similarity between activations in the residual stream of GPT-2 XL, across different layers. Activations were computed using 10 sequences from an open-source replication of GPT-2's training dataset. - ^
It's not relevant to counter-balancing vectors, but one interesting thing to note is that for GPT-2 XL the average cosine similarity is initially small, but increases a lot after the first layer. This suggests that the large mean is not simply a consequence of the embedding layer, but is introduced by further layers.
My current guess for why the bias exists is because it allows the model to represent different strengths of features, despite LayerNorm projecting all activations onto a sphere. For example, if the model wants to represent some vector as being somewhat loving, naively it could struggle to do this since the vectors and will be projected to the same point by LayerNorm, and thus treated the same. Instead if the vectors are instead centred around some point , then indeed and will be projected to different points, with the latter having a higher dot product with .
This is my guess for why the activations are not zero-centred: it allows the model to distinguish between residual stream vectors which would otherwise lie in the same direction and be treated equivalently.
- ^
I made 200 different fantasy stories using the ChatGPT API, asking each to be about 8 lines long. I used a temperature of 1 to get meaningfully different stories each time.
- ^
is the average of all activations in the residual stream from text in the style of Shakespeare, as produced by ChatGPT. Again I produced 200 sequences to get this average, using a temperature of 1.
0 comments
Comments sorted by top scores.