Meta: Frontier AI Framework
post by Zach Stein-Perlman · 2025-02-03T22:00:17.103Z · LW · GW · 2 commentsThis is a link post for https://ai.meta.com/static-resource/meta-frontier-ai-framework/
Contents
2 comments
Meta just published its version of an RSP (blogpost, framework).
(Expect several more of these in the next week as AI companies try to look like they're meeting the Seoul summit commitments [LW · GW] before the Paris summit deadline in a week.)
No details on risk assessment. On Meta's current risk assessment, see the relevant column of DC evals: labs' practices.
We define catastrophic outcomes in two domains: Cybersecurity and Chemical & biological risks.
Six catastrophic outcomes are in scope (ignore the numbers):
Cyber 1: Automated end-to-end compromise of a best-practice-protected corporate-scale environment (ex. Fully patched, MFA-protected)
Cyber 2: Automated discovery and reliable exploitation of critical zero-day vulnerabilities in current popular, security-best-practices software before defenders can find and patch them.
Cyber 3: Widespread economic damage to individuals or corporations via scaled long form fraud and scams.
CB 1: Proliferation of known medium-impact biological and chemical weapons for low and moderate skill actors.
CB 2: Proliferation of high-impact biological weapons, with capabilities equivalent to known agents, for high-skilled actors.
CB 3: Development of high-impact biological weapons with novel capabilities for high-skilled actors.
The threshold for cyber "outcomes" seems very high to me.
What is Meta supposed to do if it notices potentially dangerous capabilities? Classify the model as Moderate, High, or Critical risk:
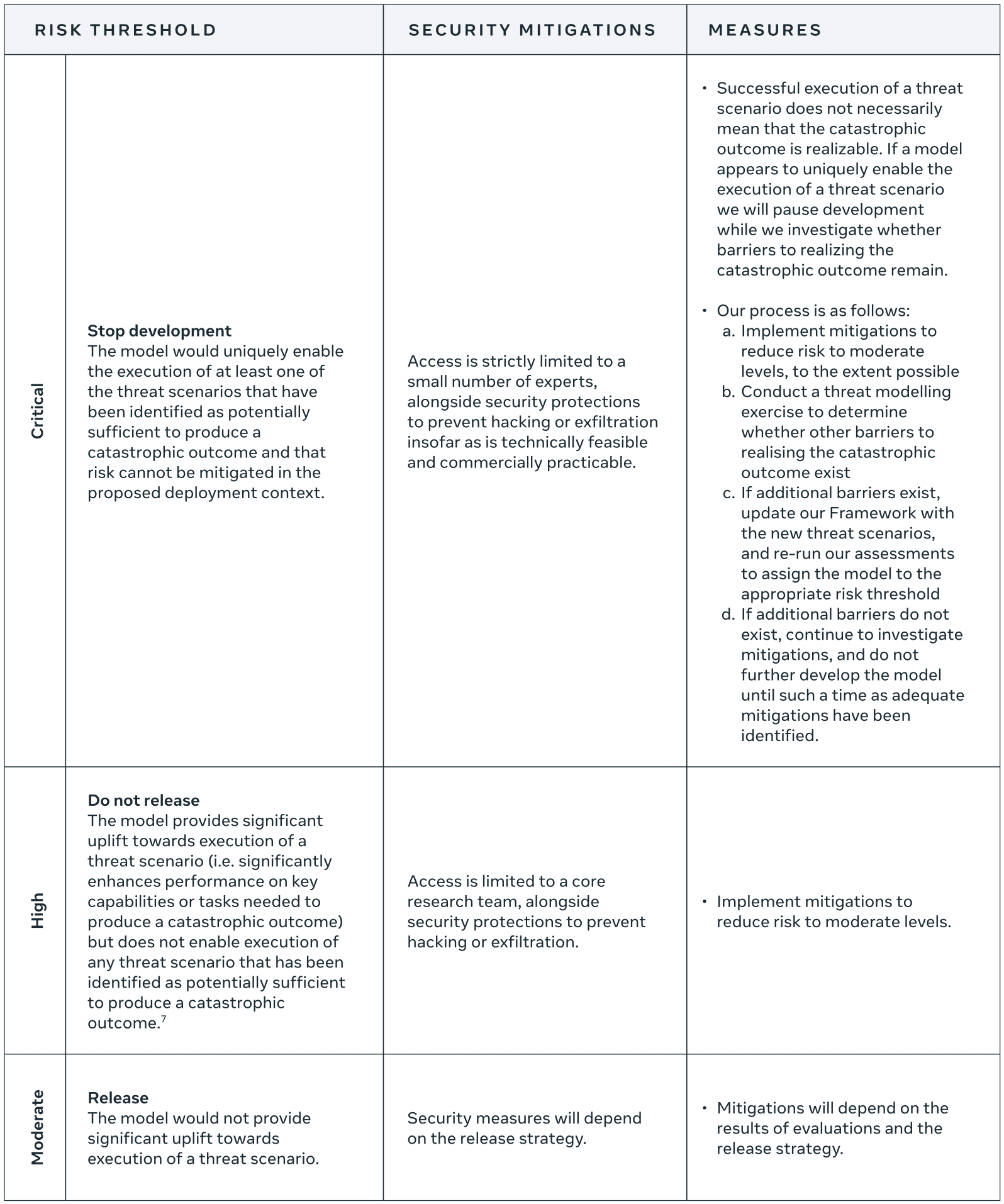
The commitment is very high-level (like OpenAI's Preparedness Framework): if the model provides significant uplift, mitigate that for external release; if you can't mitigate it and the model would "uniquely enable" the catastrophic outcome, stop development.
"Mitigations" are not promising, insofar as they're detailed:
Examples of mitigation techniques we implement include:
- Fine-tuning
- Misuse filtering, response protocol
- Sanctions screening and geogating
- Staged release to prepare the external ecosystem
My interpretation is that Meta is mostly saying that if they make a model with dangerous capabilities, they won't release the weights and if they do deploy it externally (via API) they'll have decent robustness to jailbreaks.[1] It seems easy to never trigger "Stop development" by just narrowing the "proposed deployment context" and/or observing that you could use very aggressive mitigations that make the model much less useful but do suffice for safety. (Like OpenAI's stop-development condition.)
- ^
Modulo one of several loopholes: uplift is considered relative to
existing resources, such as textbooks, the internet, and existing AI models
so if an existing model is similarly dangerous in the same ways (given how it's deployed), Meta could deploy.
2 comments
Comments sorted by top scores.
comment by aog (Aidan O'Gara) · 2025-02-04T04:52:02.972Z · LW(p) · GW(p)
I'm very happy to see Meta publish this. It's a meaningfully stronger commitment to avoiding deployment of dangerous capabilities than I expected them to make. Kudos to the people who pushed for companies to make these commitments and helped them do so.
One concern I have with the framework is that I think the "high" vs. "critical" risk thresholds may claim a distinction without a difference.
Deployments are high risk if they provide "significant uplift towards execution of a threat scenario (i.e. significantly enhances performance on key capabilities or tasks needed to produce a catastrophic outcome) but does not enable execution of any threat scenario that has been identified as potentially sufficient to produce a catastrophic outcome." They are critical risk if they "uniquely enable the execution of at least one of the threat scenarios that have been identified as potentially sufficient to produce a catastrophic outcome." The framework requires that threats be "net new," meaning "The outcome cannot currently be realized as described (i.e. at that scale / by that threat actor / for that cost) with existing tools and resources."
But what then is the difference between high risk and critical risk? Unless a threat scenario is currently impossible, any uplift towards achieving it more efficiently also "uniquely enables" it under a particular budget or set of constraints. For example, it is already possible for an attacker to create bio-weapons, as demonstrated by the anthrax attacks - so any cost reductions or time savings for any part of that process uniquely enable execution of that threat scenario within a given budget or timeframe. Thus it seems that no model can be classified as high risk if it provides uplift on an already-achievable threat scenario—instead, it must be classified as critical risk.
Does that logic hold? Am I missing something in my reading of the document?
comment by Campbell Hutcheson (campbell-hutcheson-1) · 2025-02-04T04:54:45.215Z · LW(p) · GW(p)
I'm generally favorable to see more of these published. Mainly, because I think these are going to end up being the basis for an industry audit standard and then a law.
The more similar they are, they easier it will be for them to converge.