Evaluating Superhuman Models with Consistency Checks
post by Daniel Paleka, Lukas Fluri · 2023-08-01T07:51:07.025Z · LW · GW · 2 commentsThis is a link post for https://arxiv.org/abs/2306.09983
Contents
Chess experiments The case for working on evaluations now Forecasting experiments on GPT-4 Legal decisions Finding consistency failures more efficiently Black-box directed search White-box directed search Related work Motivation and behind-the-scenes thoughts Caveats on behavioral testing Effective consistency checks: extract high-fidelity projections of the world model Controlling for randomness Consistency checks to find non-robustness Oversight of superhuman AI There is no direct connection with Contrast-Consistent Search Evaluating legal decisions as a testbed for evaluating hard moral decisions Future work Interactive checks probing for consistency, using another model as an interrogator. Big, better static benchmark for language models. None 2 comments
Consider the following two questions:
 |
 |
In both cases, the ground truth is not known to us humans. Furthermore, in both cases there either already exist superhuman AI systems (as in the case of chess), or researchers are actively working to get to a superhuman level (as in the case of forecasting / world modeling). The important question is of course:
How can we evaluate decisions made by superhuman models? |
In a new paper, we propose consistency / metamorphic testing as a first step towards extending the evaluation frontier. We test:
- superhuman chess engine (Leela)
- GPT-4 forecasting future events
- LLMs making legal decisions
The first part of this post gives a short overview of the paper. The second part elaborates on the motivation, further ideas, and the relevance of this direction for AI safety.
Chess experiments
We test a recent version [1] of Leela Chess Zero. This is a superhuman model, trained in a similar MCTS fashion as AlphaZero and KataGo.
The "win probability" of a given chess position is the key internal state the model uses to make decisions. Thus, we can expect this quantity to be consistent across semantically equivalent positions.
We find real-game positions played by strong human players where Leela fails to satisfy simple consistency checks:
- it has different win probabilities in mirrored positions:

- there are drastic changes in win probability after its recommended best move:
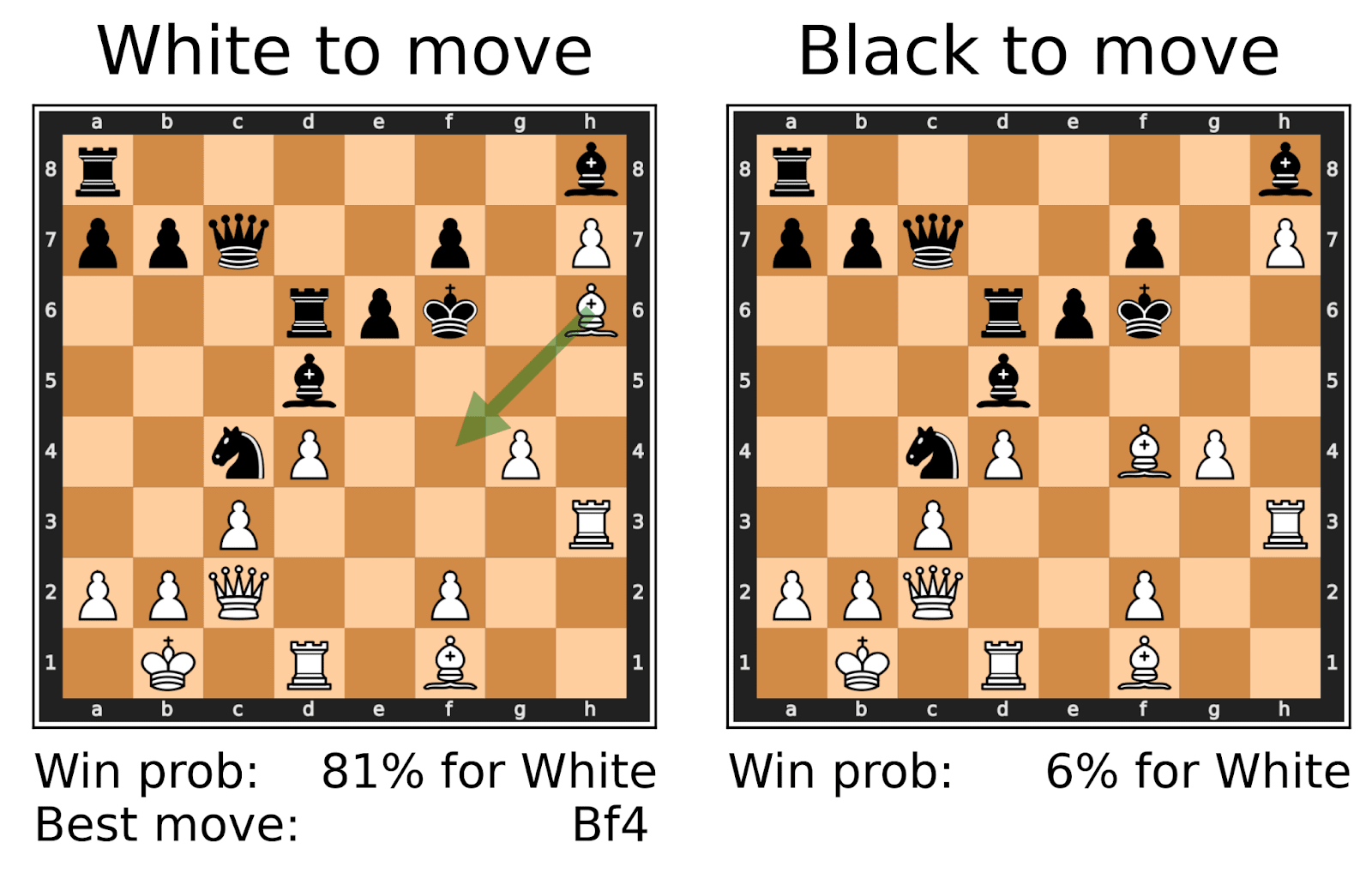
To test more invariant properties, we generate random positions without pawns, and check for consistency under board rotations and reflections:

The case for working on evaluations now
Most current evaluations require either human-generated answers (almost all tests), or a way to formally check for correctness (mathematical proofs, coding tasks), or just relative comparisons with no objective truth (ELO ratings of chess engines) This is not likely to scale to superhuman models, which will appear in different domains on uncertain timelines. Waiting for broadly superhuman models before doing evaluation experiments is a bad idea. Working on it now gives time to experiment, fix pitfalls, and deploy ultimately more robust evaluation tools.
If a task satisfies the following two constraints, we can start testing right now:
(A) Hard to verify the correctness / optimality of model outputs.
(B) There are “consistency checks” you can apply to inputs to falsify correctness / robustness of the model.
We now test models on tasks where superhuman performance has not yet been reached, but the two criteria described above hold.
Forecasting experiments on GPT-4
Prediction market questions are a good example of a "no ground truth" task: there is no way to know the ground truth until it happens, and even then it is hard to evaluate the model's performance. Consistency checks, however, are readily available to upper bound the model's forecasting ability.
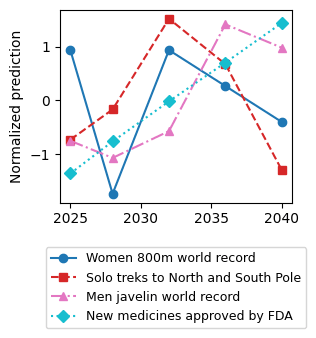
We show that GPT-4 is a very inconsistent forecaster:
- its median forecasts for monotonic quantities are often non-monotonic over years;
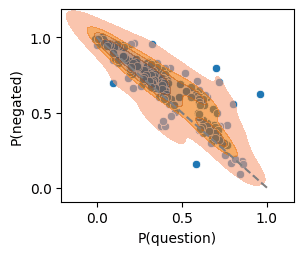
- it fails to assign opposite probabilities to opposite events, occasionally by a wide margin.
 |
 |
On those simple tests, although inconsistent, GPT-4 performance was still a clear improvement over GPT-3.5-turbo. However, on more complex checks like our Bayes' rule check, there is no clear improvement with GPT-4 yet.
For events like A = "Democrats win 2024 US presidential election" and B = "Democrats win 2024 US presidential election popular vote", GPT-4's predictions for P(A), P(B), P(A|B) and P(B|A) strongly [2] violate the Bayes equation more than 50% of the time.
Legal decisions
Outcomes of court cases is an example of a task where human society does not necessarily agree on the ground truth. We test GPT-3.5-turbo on whether an arrested individual should be released on bail, given their criminal history. The queries represent real legal cases extracted from the COMPAS dataset.

Inconsistencies on this task are rarer than in the previous two experiments, likely due to the restricted nature of the input space.
Our legal experiments demonstrate certain alignment failures: if an AI is inconsistent in this way on counterfactual cases, it means it fails to robustly encode human values.
Finding consistency failures more efficiently
As AI systems get smarter, consistency failures become rarer. Therefore, at a certain point, randomly sampling inputs to find consistency violations might become infeasible. So, does our method become useless with increasing model performance? We claim that not all hope is lost. There are several ways to search for consistency violations that are better than random sampling, drastically increasing the efficiency of our method.
Black-box directed search
The experiments so far require only black-box access to the evaluated model, which would be nice to preserve, since many state-of-the-art models are only accessible through APIs. Therefore, we first experiment with black-box directed search to find consistency violations.
For chess experiments, we use a genetic algorithm that randomly mutates and mates a population of board positions to optimize for boards with a high probability of consistency failure. On Leela, we are able to find up to 40x more strong consistency failures than with sampling random positions:
| Percentage of strong consistency violations found | |
| Randomly sampling inputs | 0.01% |
| Directed black-box search | 0.4% |
White-box directed search
A much more appealing approach is to exploit the model’s internals to find input samples which violate consistency constraints. Gradients, in particular, have been shown to be an indispensable tool for finding adversarial examples. We show that even weaker forms of white-box access can already be used to find consistency violations more efficiently.
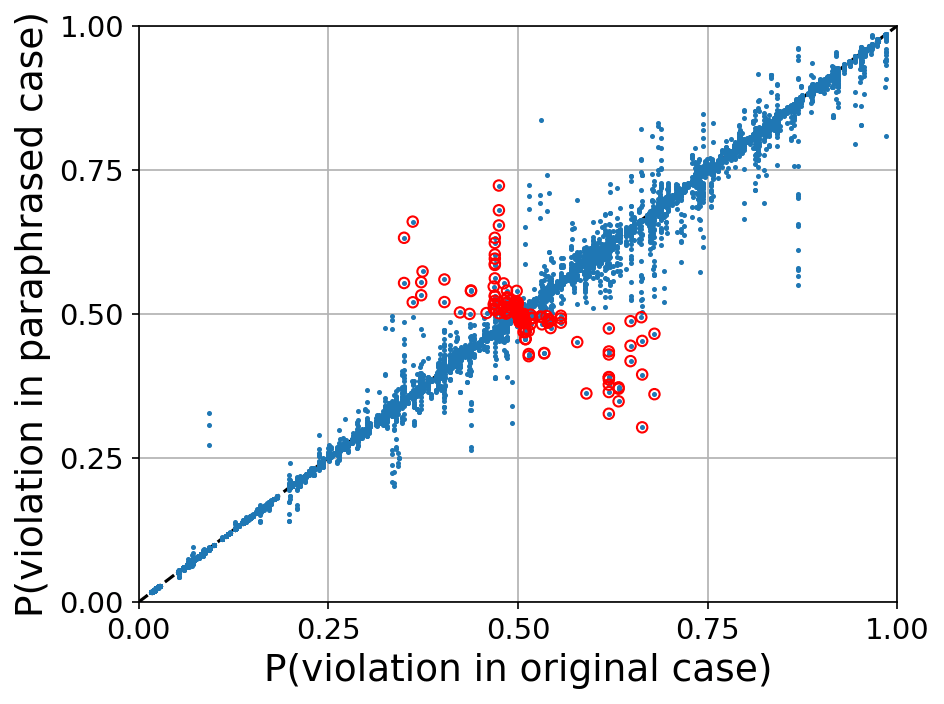
We consider the Chalkidis et al. LEGAL-BERT model used to predict violations of the European Convention of Human Rights (ECHR). Given a legal case, consisting of a list of individual case facts, we paraphrase a single case fact and let the model predict whether the two legal cases (the original and one with a paraphrased fact) describe an ECHR violation.
The BERT model uses a self-attention layer to assign an importance weight to each individual case fact. This allows us to quickly find the approximate “crux” case fact.
By paraphrasing this fact instead of a random case fact from the case, we find orders of magnitude more consistency violations.
 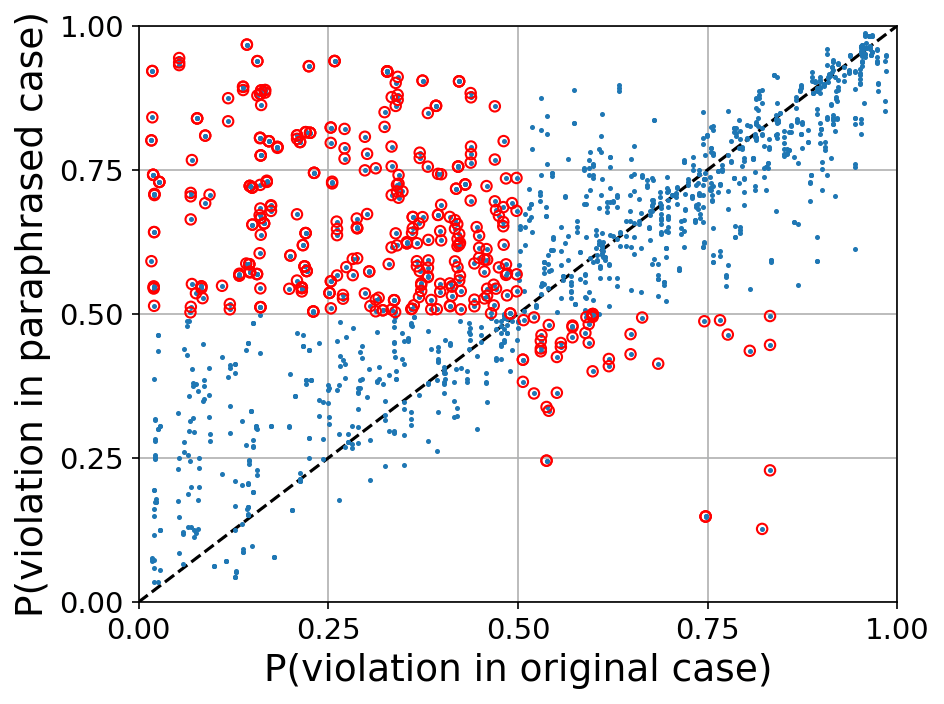 |
Related work
Robustness in machine learning is an extremely well-studied topic, mostly in computer vision, where the bulk of the literature assumes ground truth labels. Recent work on jailbreaking language models is similar, with experiments assuming a way to distinguish good from bad outputs.
The most conceptually similar framework is metamorphic testing of complex software systems, which is prominently used in software engineering. The closest applications in machine learning have been k-safety testing [3]and contrast sets; the experiments in both of these papers are however on weaker models in settings with ground truth.
Scalable oversight of AI is a very active AI safety area, focusing on supervision and training of superhuman models in settings without ground truth. On the evaluation side, the closest idea is debate, specifically the cross-examination [AF · GW] variant where a debater can probe parallel copies of the other debater for consistency.
For a longer overview of similar research, check the Related work section in the paper.
Motivation and behind-the-scenes thoughts
Caveats on behavioral testing
Evan Hubinger has argued [AF · GW] that behaviorally detecting deceptive alignment is likely to be harder than avoiding it in the first place. Hence, understanding-based evals and mechanistic interpretability should get slight priority over behavioral testing like consistency checks.
We sort of sympathize with this view, and would switch to "cognitive" evaluations if those worked better. We do behavioral testing in the form of consistency checks because it works now. Moreover, the two testing approaches might be intertwined in positive ways: in our experiments on legal decisions, we show that we can elicit inconsistencies using the model's internal state. [4]
Effective consistency checks: extract high-fidelity projections of the world model
In addition to the mentioned properties (A) and (B), our chess and forecasting tasks have the helpful third property:
(C) the prior on the output space is high entropy.
This is not necessary for the evaluation to work, but it makes it easier to exhibit and measure inconsistency. Note that the output space of a task is not fixed; in chess, we choose the win probability as a good projection of the world model, instead of using e.g. the best move. [5]
We can use this as a general abstract method to create consistency checks for a task: find a variable which governs the decision-making on the given task, query it from the model (or better, extract it from the model mechanistically), then check for consistency over different settings. We hope to apply this in practice concurrently with one of the followup directions.
Controlling for randomness
Highly stochastic outputs are inherently unreliable, hence for the purposes of evaluating high-stakes superhuman models, we believe it is fair to consider random outputs as inconsistent. Nevertheless, in tests where outputs are not deterministic (OpenAI models), we control for randomness by sampling multiple times and taking the median. We also run a simple baseline forecasting experiment and find that randomness accounts for only about 20% of the consistency violations; more in Appendix C.3.2 of the paper.
Consistency checks to find non-robustness
We endorse the philosophy [LW · GW]advocated by Adam Gleave and others: if we do not pivot to fault-tolerant methods, robustness should be solved around the same time as transformative AI. Many research agendas for scalable oversight involve an AI supervising or rewarding another AI; leaving vulnerabilities in the overseer is not an option. Similarly, non-robust alignment may let malicious actors take control of powerful AI systems.
The contradiction increasingly apparent in robustness research nowadays is that:
- attacks are becoming harder to find; [6]
- there is little evidence models have gotten more robust.
If everyone agrees models are not robust, exhibiting concrete attacks might not seem very useful right now. However, finding precise ways robustness (hence generalization) fails is important to proactively debug potential issues. Bugs that are hard to find but easy to exploit are an obstacle for both development of safe AI and its deployment.
Consistency checks may act as a guiding light for adversarial attacks.
The simplest checks can indeed be phrased as robustness to certain semantic-preserving transformations. But for more complex ones, the model failing to be consistent on a given set of inputs indicates issues in that part of the input space. It would be very cool to find a way to guide the search for an adversarial policy in chess using the positions where the model is locally inconsistent.
Oversight of superhuman AI
Jan Leike and the OpenAI alignment team emphasize the following question:
How do we align systems on tasks that are difficult for humans to evaluate?
There are two different issues here: improving generalization of alignment to tasks beyond the regime where evaluation is easy, and advancing the evaluation frontier in general, especially on properties relevant to extreme risks. Our work is a small step towards the latter.
Let's focus on a minimally agentic AI paradigm, such as AI scientists. We could interact with those in a similar fashion as we currently query GPT-4 on forecasting questions. Some properties of a good superhuman AI scientist are:
- sources its decisions from an accurate world model;
- correctly reasons from it to produce an answer;
- honestly reports its answer and its uncertainty.
Failed consistency checks are a sign that some step in the above is broken.
Now, the reason why GPT-4 fails our tests is almost certainly not hidden goals making it lie, but failures in its world model and reasoning.
But, as AI systems get better and better world models and reasoning abilities, failures of consistency will both get rarer and become a better signal of lying.
Interactive consistency checks, in the form of interrogation or some versions of debate, may be more useful for making it harder for AI to lie to us.
There is no direct connection with Contrast-Consistent Search
Multiple people said something in this work reminded them of Discovering Latent Knowledge in Language Models Without Supervision. Both papers have something to do with model truthfulness; and both papers use the same operationalization of truth: consistency with itself.
However, the similarity ends here, as our paper is mostly behavioral testing, while their paper uses internal model state to elicit latent knowledge.
Evaluating legal decisions as a testbed for evaluating hard moral decisions
As transformative AI happens, consistency checks can be a natural evaluation strategy on moral or legal questions, where we can't agree on what is correct.
Our common moral intuitions are finetuned on the world we live in and the worlds our ancestors lived in. If the world changes drastically in a short amount of time, human preferences might not be so confident anymore.
However, as the bail example shows, simple moral rules generalize much further when used for checking consistency between different decisions than when used for checking correctness of a single decision.
Future work
There are two clear directions for future work:
Interactive checks probing for consistency, using another model as an interrogator.
This can be taken into the direction of debate: how do we detect lying in a strong model, preferably using a weaker model we trust? However, there are ideas in safety-agnostic evaluation as well: automated cross-examination [AF · GW] can be used to falsify factual claims on tasks where ground truth is unavailable.
Big, better static benchmark for language models.
The tests can go much deeper than semantic invariance; our Bayes' rule check is just a glance at how complex the equalities and inequalities defining a consistent world model can get. Consistency checks can also not rely on logical consistency, but incorporate a prior on the world model, and return an implausibility score.
We think that a consistency benchmark in the spirit of our forecasting checks could become a standard tool in the evaluation toolbox for powerful AI models.
- ^
We make some minor adjustments to the default settings, to account for hardware and force deterministic behavior. See Appendix B of the paper for details.
- ^
We introduce a violation metric in [0, 1] for each consistency check type, and say a check is strongly violated if it has violation greater than what P(event) + P(¬event) = 80% gets. Determining "equivalent" thresholds for different consistency checks is a design decision, and further work on consistency benchmarks should resolve this in a principled way.
- ^
The k-safety paper actually does a similar experiment on the COMPAS dataset as we do.
- ^
These experiments, however, are on a LEGAL-BERT encoder-only model from 2020, hence not necessarily transferable to models such as GPT-4.
- ^
Recommended moves are a bad choice for consistency checks, in multiple ways. Two radically different position evaluators can easily choose the same move; and conversely, a miniscule change in position evaluation might cause a switch between two equally good moves.
- ^
Two examples: (1) the cyclic exploit from Adversarial Policies Beat Superhuman Go AIs [LW(p) · GW(p)] took a lot of computation to find, even in the most favorable white-box attack setting;
(2) gradient-based attacks on language models tend to be bad, and we currently rely on human creativity to find good attacks. A few days ago, Zou et al. produced a notable exception, but it looks much more involved than adversarial attacks in computer vision, and if defenses are applied we might be back to square one.
2 comments
Comments sorted by top scores.
comment by james387 · 2023-08-20T22:14:05.430Z · LW(p) · GW(p)
I am an avid chess player, and was curious to read this paper as someone referred me to it. I think the claims from the paper and article are misguided, since the premise is that Leela is a superhuman chess AI, but that has actually not been proven at the level of search nodes used in the paper (referring to Appendix section B.3). It's quite possible that Leela is not a superhuman level AI even at 1600 nodes searched - the upper limit referenced in the paper; at 1 node, which is also referenced in the tables in the paper, I believe Leela has been estimated at around expert-level strength - well below superhuman. I appreciate the authors providing detailed implementation parameters for the purposes of reproducing. I did not attempt to reproduce the findings exactly based on those parameters, though I have a similar version of Leela installed locally on a relatively modest consumer GPU.
To provide some context, Leela only has correct/precise evaluations in the limit of nodes searched, and in a practical sense, doesn't have precise evaluations (which could only come from search) for moves that it wouldn't strongly consider playing. In the first mirrored example, Leela finds ...Rh4/Rh5 to be a clearly winning move in both cases in roughly 12k nodes searched, which is only a few seconds of search on my set-up. The authors indicate a hardware set-up where this node limit may be achievable in under 1 second. I found it curious that the choice was made to spend days of GPU time on the other problems, but not even seconds worth of compute time for specific chess positions, rendering Leela in the range of strong amateur to probably human grandmaster level play.
Regarding the Bf4 move from the article, I do show that Leela considers Bf4 as a decent move with around ~81% win probability in a shallow search. However, my local version does not consider Bf4 to be one of the top few moves with even a bit more search. It is important to note that the policy output is only a part of the process; Leela is built to play chess well, which requires search of the position. In this case at least, my local version would not choose Bf4, so it doesn't search the move deeply.
Regarding Table 5 in Appendix B.3, I would be interested to know what percentage of the positions in each category are the synthetic positions without pawns; as Leela is only trained on moves from games (and almost all from above human master-level play), some of the synthetic positions could be nuanced in a way that would make them unlikely to arise from an actual game of chess.
As for the last position from the article without pawns, my local version not only produces the highest policy output for Rg7+/Rb7+ but produces a high probability evaluation without many nodes searched (at most 125 nodes). I am a bit intrigued that there is this much difference in the weights file used with a relatively recent version of Leela.
Leela does play chess at a superhuman level, as shown in that it can play chess in computer chess tournaments on the relative level of the best chess engines that exist. However, constraining the nodes searched to the range in the paper handicaps it to a sub-superhuman state, which is quite misleading based on the premise of the paper and some of the claims in the article and paper.
EDIT: after conversing with an author of the paper privately, I think I've underestimated the strength of Leela now on quite low node counts, and probably not 1 node, but definitely hundreds or up to 1.6k nodes, as shown in the paper, is almost certainly superhuman level play.
Replies from: Daniel Paleka↑ comment by Daniel Paleka · 2023-08-22T08:49:59.879Z · LW(p) · GW(p)
Thank you for the discussion in the DMs!
Wrt superhuman doubts: The models we tested are superhuman. https://www.melonimarco.it/en/2021/03/08/stockfish-and-lc0-test-at-different-number-of-nodes/ gave a rough human ELO estimate of 3000 for a 2021 version of Leela with just 100 nodes, 3300 for 1000 nodes. There is a bot on Lichess that plays single-node (no search at all) and seems to be in top 0.1% of players.
I asked some Leela contributors; they say that it's likely new versions of Leela are superhuman at even 20 nodes; and that our tests of 100-1600 nodes are almost certainly quite superhuman. We also tested Stockfish NNUE with 80k nodes and Stockfish classical with 4e6 nodes, with similar consistency results.
Table 5 in Appendix B.3 ("Comparison of the number of failures our method finds in increasingly stronger models"): this is all on positions from Master-level games. The only synthetically generated positions are for the Board transformation check, as no-pawn positions with lots of pieces are rare in human games.
We cannot comment on different setups not reproducing our results exactly; pairs of positions do not necessarily transfer between versions, but iirc preliminary exploration implied that the results wouldn't be qualitatively different. Maybe we'll do a proper experiment to confirm.
There's an important question to ask here: how much does scaling search help consistency? Scaling Scaling Laws with Board Games [Jones, 2021] is the standard reference, but I don't see how to convert their predictions to estimates here. We found one halving of in-distribution inconsistency ratio with two doublings of search nodes on the Recommended move check. Not sure if anyone will be working on any version of this soon (FAR AI maybe?). I'd be more interested in doing a paper on this if I could wrap my head around how to scale "search" in LLMs, with a similar effect as what increasing the number of search nodes does on MCTS trained models.