Even Superhuman Go AIs Have Surprising Failure Modes
post by AdamGleave, EuanMcLean (euanmclean), Tony Wang (tw), Kellin Pelrine (kellin-pelrine), Tom Tseng (thmt), Yawen Duan (yawen-duan), Joseph Miller (Josephm), MichaelDennis · 2023-07-20T17:31:35.814Z · LW · GW · 22 commentsThis is a link post for https://far.ai/post/2023-07-superhuman-go-ais/
Contents
How to Find Vulnerabilities in Superhuman Go Bots The Cyclic Attack The Implications Acknowledgements Appendix: The Pass Attack None 22 comments
In March 2016, AlphaGo defeated the Go world champion Lee Sedol, winning four games to one. Machines had finally become superhuman at Go. Since then, Go-playing AI has only grown stronger. The supremacy of AI over humans seemed assured, with Lee Sedol commenting they are an "entity that cannot be defeated". But in 2022, amateur Go player Kellin Pelrine defeated KataGo, a Go program that is even stronger than AlphaGo. How?
It turns out that even superhuman AIs have blind spots and can be tripped up by surprisingly simple tricks. In our new paper, we developed a way to automatically find vulnerabilities in a "victim" AI system by training an adversary AI system to beat the victim. With this approach, we found that KataGo systematically misevaluates large cyclically connected groups of stones. We also found that other superhuman Go bots including ELF OpenGo, Leela Zero and Fine Art suffer from a similar blindspot. Although such positions rarely occur in human games, they can be reliably created by executing a straightforward strategy. Indeed, the strategy is simple enough that you can teach it to a human who can then defeat these Go bots unaided.
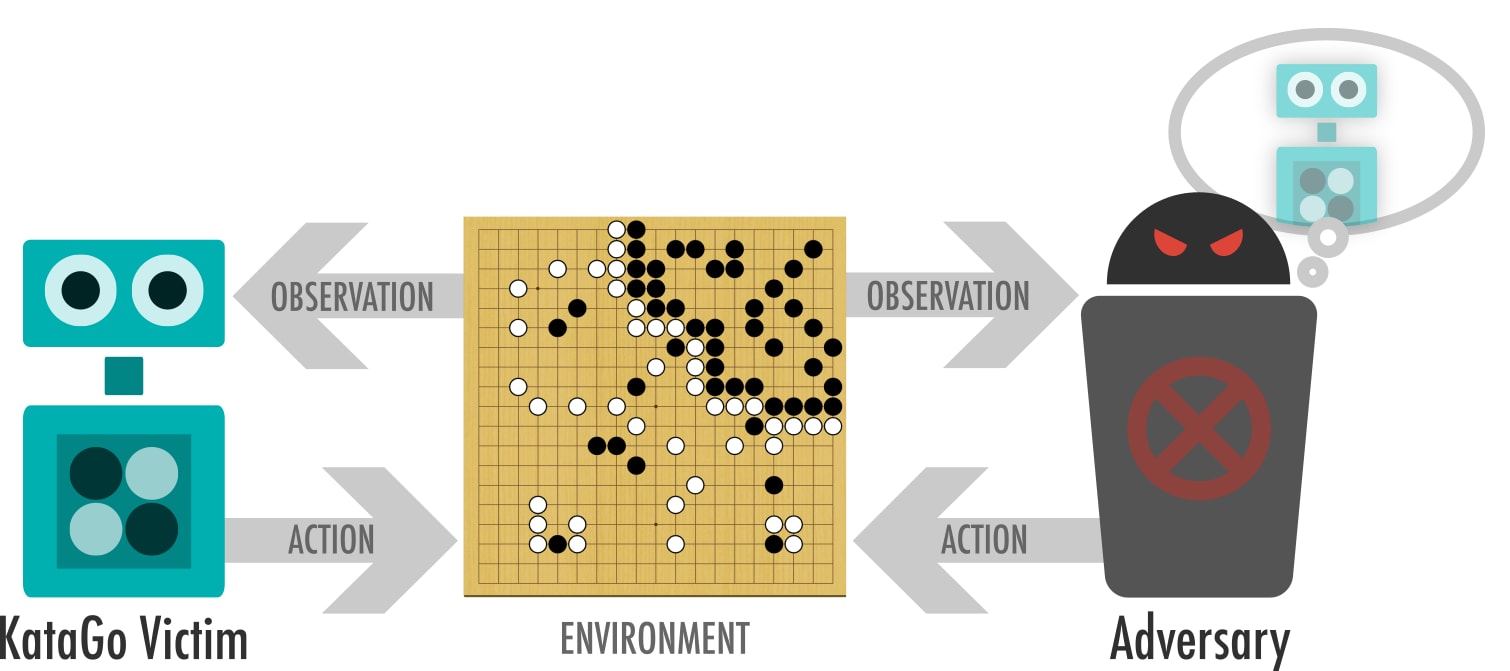
The victim and adversary take turns playing a game of Go. The adversary is able to sample moves the victim is likely to take, but otherwise has no special powers, and can only play legal Go moves.
Our AI system (that we call the adversary) can beat a superhuman version of KataGo in 94 out of 100 games, despite requiring only 8% of the computational power used to train that version of KataGo. We found two separate exploits: one where the adversary tricks KataGo into passing prematurely, and another that involves coaxing KataGo into confidently building an unsafe circular group that can be captured. Go enthusiasts can read an analysis of these games on the project website.
Our results also give some general lessons about AI outside of Go. Many AI systems, from image classifiers to natural language processing systems, are vulnerable to adversarial inputs: seemingly innocuous changes such as adding imperceptible static to an image or a distractor sentence to a paragraph can crater the performance of AI systems while not affecting humans. Some have assumed that these vulnerabilities will go away when AI systems get capable enough—and that superhuman AIs will always be wise to such attacks. We’ve shown that this isn’t necessarily the case: systems can simultaneously surpass top human professionals in the common case while faring worse than a human amateur in certain situations.
This is concerning: if superhuman Go AIs can be hacked in this way, who’s to say that transformative AI systems of the future won’t also have vulnerabilities? This is clearly problematic when AI systems are deployed in high-stakes situations (like running critical infrastructure, or performing automated trades) where bad actors are incentivized to exploit them. More subtly, it also poses significant problems when an AI system is tasked with overseeing another AI system, such as a learned reward model being used to train a reinforcement learning policy, as the lack of robustness may cause the policy to capably pursue the wrong objective (so-called reward hacking).

A summary of the rules of Go (courtesy of the Wellington Go Club): simple enough to understand in a minute or two, yet leading to significant strategic complexity.
How to Find Vulnerabilities in Superhuman Go Bots
To design an attack we first need a threat model: assumptions about what information and resources the attacker (us) has access to. We assume we have access to the input/output behavior of KataGo, but not access to its inner workings (i.e. its weights). Specifically, we can show KataGo a board state (the position of all the stones on the board) and receive a (possibly stochastic) move that it would take in that position. This assumption is conservative: we can sample moves in this way from any publicly available Go program.
We focus on exploiting KataGo since, at the time of writing, it is the most capable publicly available Go program. Our approach is to train an adversary AI to find vulnerabilities in KataGo. We train the adversary in a similar way to how most modern Go bots are trained, via AlphaZero-style training.[1]
We modify the AlphaZero training procedure in a handful of ways. We want the adversary to be good at finding and exploiting bugs in KataGo, rather than learning generally good Go moves. So instead of playing against a copy of itself (so-called self-play), we pit the adversary against a static version of KataGo (which we dub victim-play).
We also modify the Monte-Carlo Tree Search (MCTS) procedure, illustrated below. In regular MCTS, moves are sampled from a single policy network. This works well in self-play, where both players are the same agent. But with victim-play, the adversary is playing against a potentially very different victim agent. We solve this by sampling from KataGo’s move distribution when it’s KataGo’s turn, and our policy network when it’s our turn.
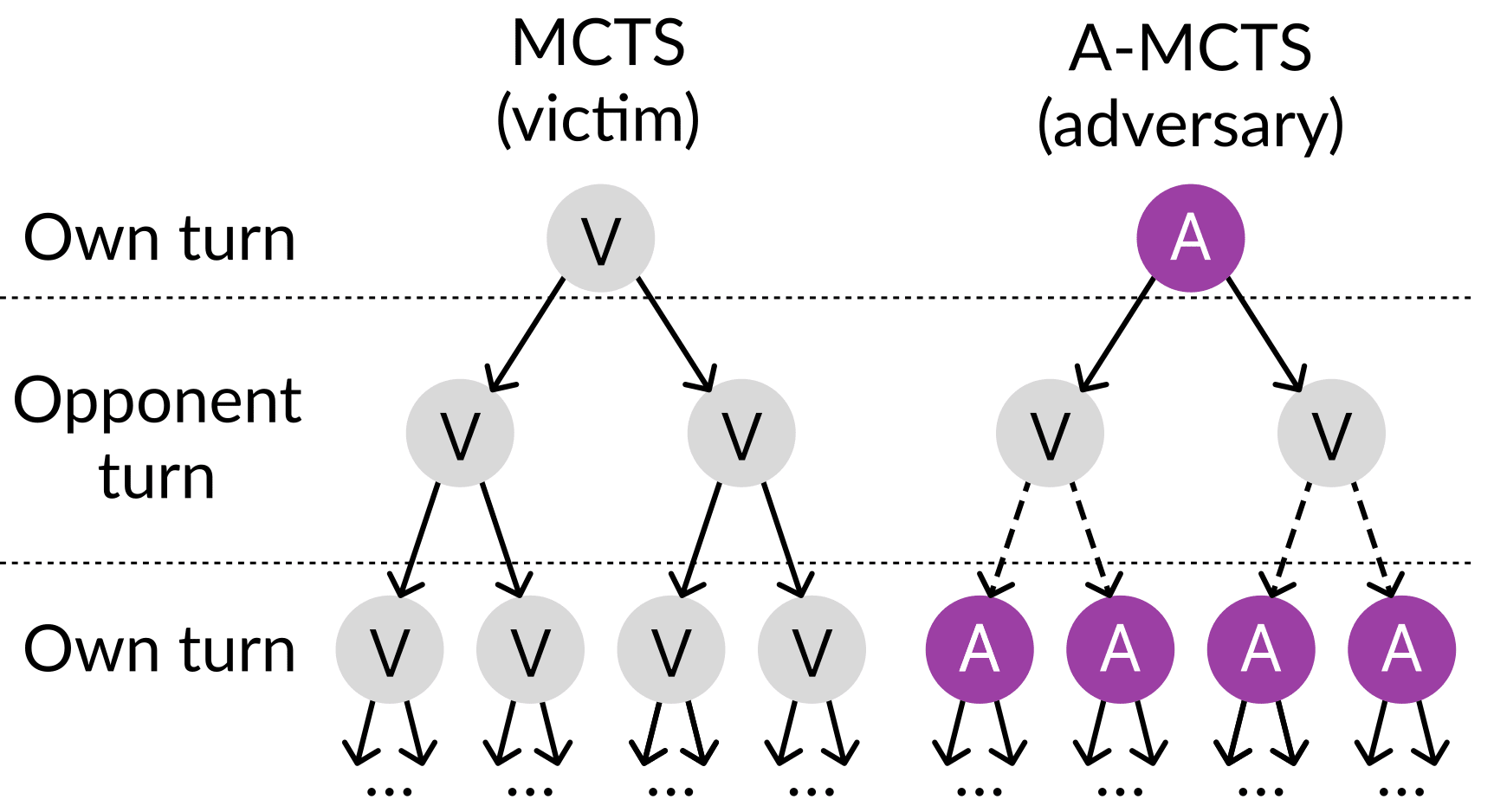
Monte-Carlo Tree Search (MCTS) always samples moves from the same network. Our variant, Adversarial MCTS (A-MCTS), samples moves from the network corresponding to the simulated player's turn.
We also create a curriculum for the adversary by pitting it against a series of gradually more capable versions of KataGo. Whenever the adversary finds a way to consistently beat a KataGo version, we swap that version out for a better one. There are two ways to vary the skill of KataGo. Firstly, we use old versions ("checkpoints") of KataGo’s neural network from various points of its training. Secondly, we vary the amount of search KataGo has: how many moves can be simulated during MCTS. The more moves that are simulated, the stronger KataGo is.
Our adversary relatively quickly learns to exploit KataGo playing without tree search (at the level of a top-100 European professional), achieving a greater than 95% win rate against KataGo after 200 million training steps (see orange line below). After this point, the curriculum continues to ramp up the difficulty every vertical dashed line. It takes another 300 million training steps to start reliably exploiting a strongly superhuman version of KataGo, playing with 4096 visits (gray line). After this, the adversary learns to exploit successively harder victims with only small amounts of additional training data. (Although the computational requirements of generating the data increase with each successive doubling in victim visit count.)
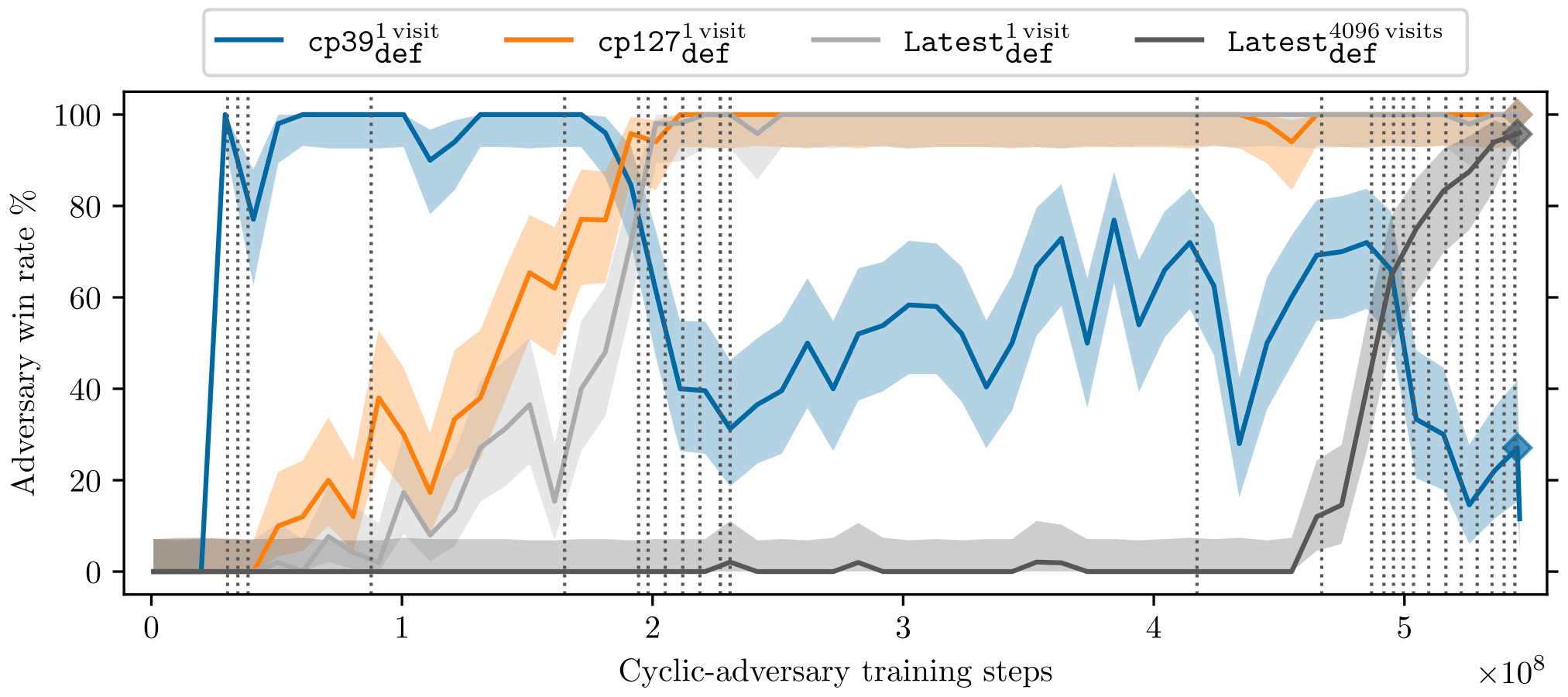
The adversary’s win rate over training time. The four lines represent four different versions of KataGo of increasing skill level. The vertical dotted lines show when the KataGo version the adversary is being trained on is swapped out for a better one.
This adversarial training procedure discovered two distinct attacks that can reliably defeat KataGo: the pass attack and the cyclic attack. The pass attack works by tricking KataGo into passing, causing the game to end prematurely at a point favorable to the attacker. It is the less impressive of the two, as it can be patched with a hard-coded defense: see Appendix: The Pass Attack below for more information on it. The cyclic attack on the other hand is a substantial vulnerability of both KataGo and other superhuman Go bots, which has yet to be fixed despite attempts by both our team and the lead developer of KataGo, David Wu. It works by exploiting KataGo’s misevaluation of large, cyclically connected groups of stones.
The Cyclic Attack
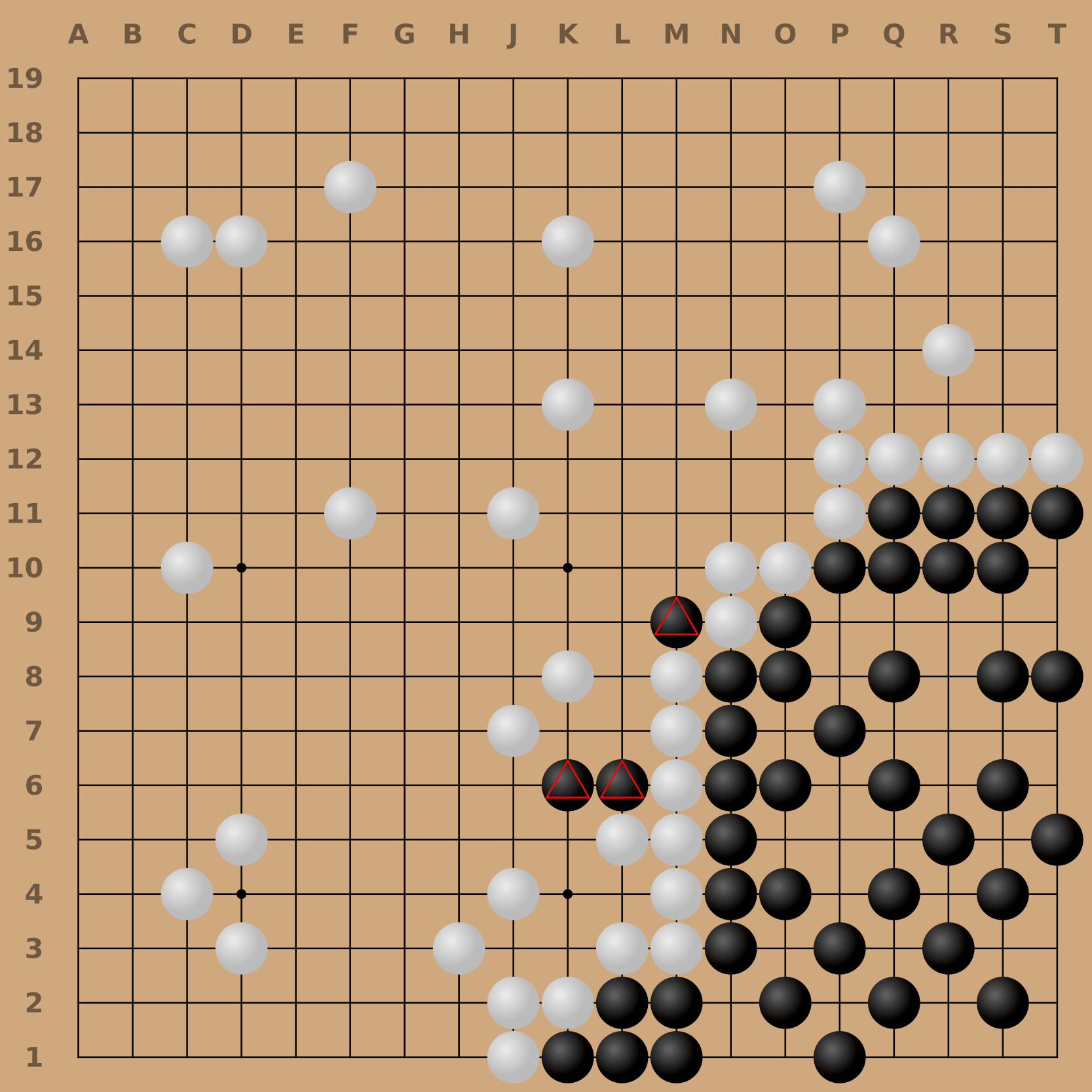
We identified the cyclic-attack by training an adversary against a version of KataGo patched to avoid our first attack, the pass-attack. The cyclic-adversary first coaxes KataGo into building a group in a circular pattern. KataGo seems to think such groups are nearly indestructible, even though they are not. The cyclic-adversary abuses this oversight to slowly re-surround KataGo’s cyclic group. KataGo only realizes the group is in danger when it’s too late, and the adversary captures the group.
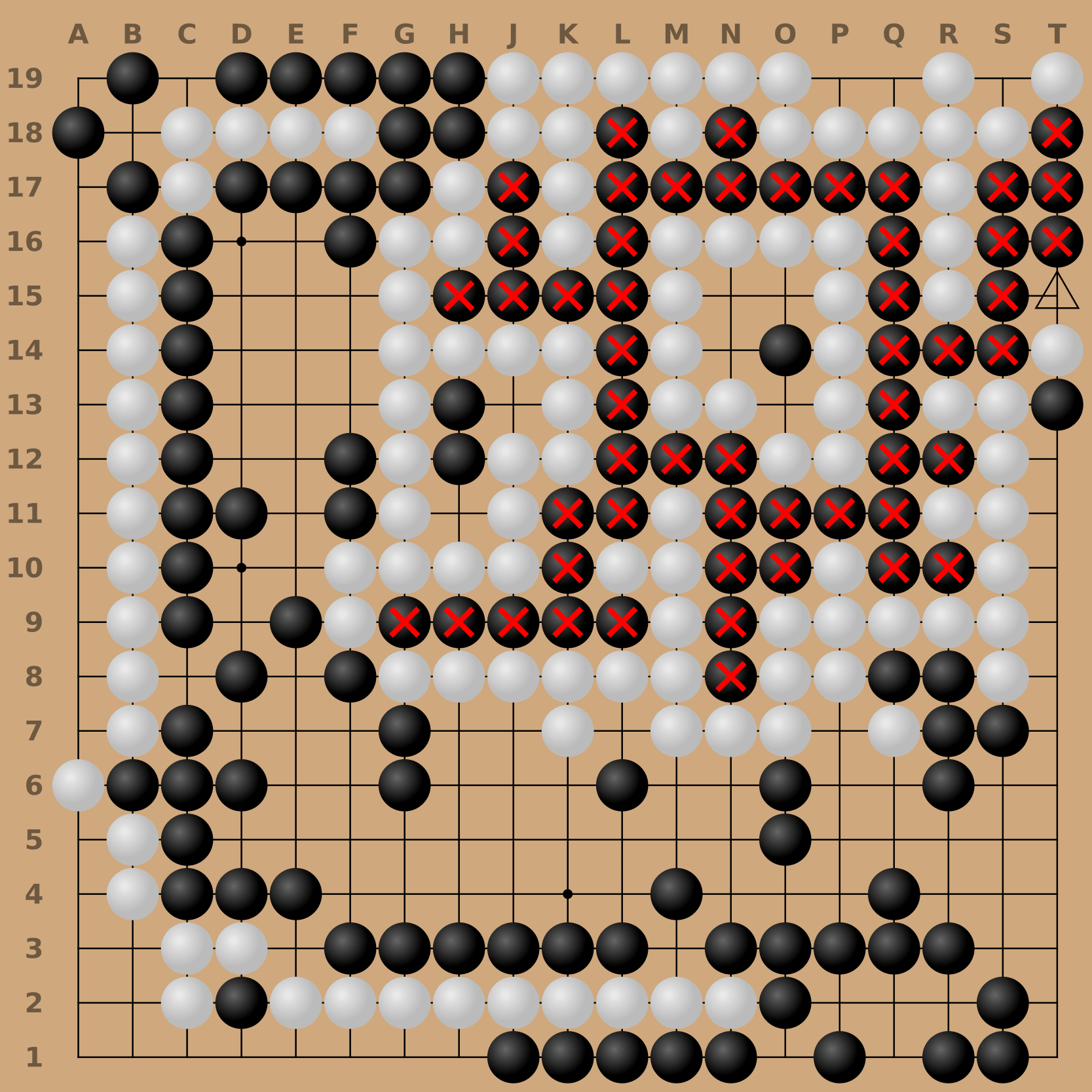
Our adversary (white) playing the cyclic attack against KataGo (black). The stones with red crosses are the group that KataGo wrongly believes is safe.
Using the cyclic attack, our adversary can reliably beat even strongly superhuman versions of KataGo. Let’s focus on three KataGo versions: one at the level of a top European professional (KataGo with no MCTS), one that is superhuman (KataGo with MCTS simulating 4096 moves for every move it makes), and one that is strongly superhuman (KataGo with MCTS simulating 10 million moves). Our adversary beat the human professional level bot in 100% of the games we ran, the superhuman bot 96% of the time, and the strongly superhuman bot 72% of the time. This is even though we trained our adversary with only 14% of the computational power used to train KataGo; moreover, our adversary only simulated 600 moves in all of these matches, far below the amount of search used by the superhuman and strongly superhuman versions of KataGo.
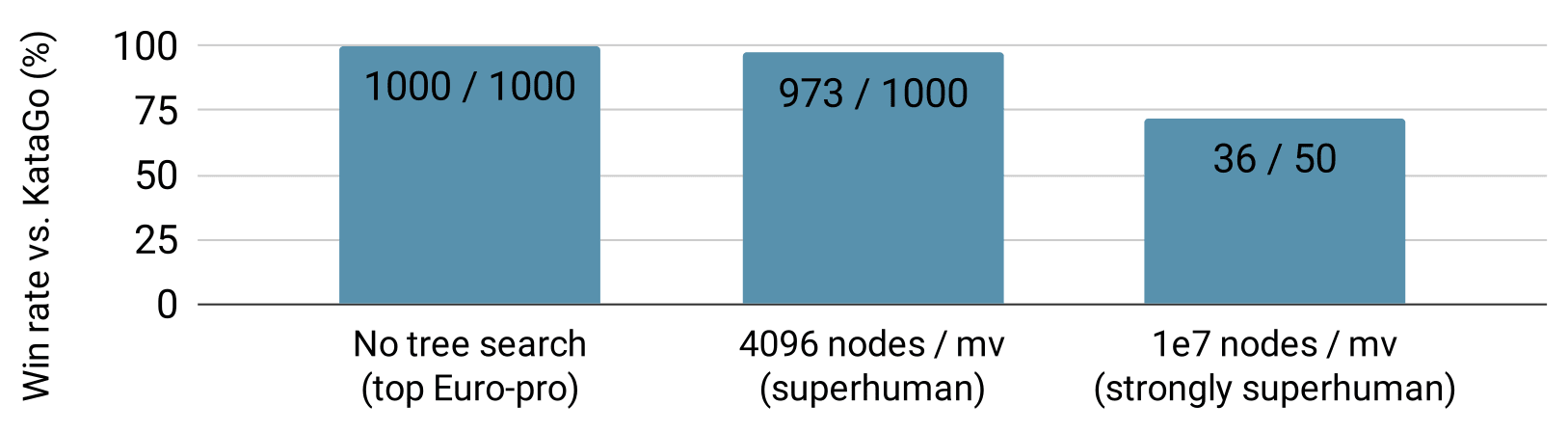
The win rate of our adversary against versions of KataGo with different amounts of search. KataGo versions become stronger going from left to right.
We were also interested in whether we could use this adversary, trained to beat KataGo, to defeat other superhuman Go-playing agents. We pitted this adversary against Leela Zero and ELF OpenGo without any training against these systems (a zero-shot transfer). The adversary beat Leela Zero 6% of the time and ELF OpenGo 4% of the time.
Although these win rates are modest, they demonstrate that other Go bots are vulnerable to the cyclic attack at least to some degree. Notably, these are superhuman AIs against which even the best human players in the world would struggle to win 1% of the time – so achieving a win rate of around 5% represents a significant vulnerability. This extends our original threat model: an attacker can conduct a black-box attack so long as they can obtain gray-box access to a sufficiently similar victim.
The cyclic attack is not just a specific set of moves that somehow exploit some arbitrary bug in KataGo; it’s a general and human-interpretable strategy. One of our authors Kellin, an amateur Go player, studied the behavior of our adversary to learn to play the cyclic attack himself. Kellin then used the cyclic attack to repeatedly beat superhuman versions of both KataGo and Leela Zero by himself. Many other Go enthusiasts have now used the cyclic attack to beat strong Go bots, including Sai (example) and Fine Art (example). You can learn the attack yourself with this video.
The Implications
The fact that the cyclic attack can be used to beat many different Go bots shows that the problem is not specific to KataGo. Moreover, in concurrent work, a team at DeepMind found a way to beat a human-expert level version of AlphaZero. The fact that two different teams could find two distinct exploits against distinct AI programs is strong evidence that the AlphaZero approach is intrinsically vulnerable. This in itself is interesting, but there are some more general lessons we can learn.
Adversarial attacks on neural networks have been known for nearly a decade, ever since researchers discovered that you can trick image classifiers by simply adding some imperceptible static to the image. Many have expected that these vulnerabilities in AI systems will disappear when the systems get suitably capable. Sure, an image classifier is tripped up by some static, but surely an image classifier that’s as capable as a human wouldn’t make such a dumb mistake?
Our results show that this is not necessarily the case. Just because a system is capable does not mean it is robust. Even superhuman AI systems can be tripped up by a human if the human knows its weaknesses. Another way to put this is that worst-case robustness (the ability to avoid negative outcomes in worst-case scenarios) is lagging behind average-case capabilities (the ability to do very well in the typical situation a system is trained in).
This has important implications for future deployment of AI systems. For now, it seems unwise to deploy AI systems in any security-critical setting, as even the most capable AI systems are vulnerable to a wide range of adversarial attack. Additionally, serious caution is required for any deployment in safety-critical settings: these failures highlight that even seemingly capable systems are often learning non-robust representations, which may cause the AI systems to fail in ways that are hard to anticipate due to inevitable discrepancies between their training and deployment environment.
These vulnerabilities also have important implications for AI alignment: the technical challenge of steering AI towards the goals of their user. Many proposed solutions to the alignment problem involve one “helper AI” providing a feedback signal steering the main AI system towards desirable behavior. Unfortunately, if the helper AI system is vulnerable to adversarial attack, then the main AI system will achieve a higher rating by the helper AI if it exploits the helper instead of achieving the desired task. To address this, we have proposed a new research program of fault-tolerant alignment strategies [AF · GW].
To summarize: we’ve found a way to systematically search for exploits against game-playing AI systems, and shown this approach can uncover surprisingly simple hacks that can reliably beat superhuman Go bots. All of the AlphaZero-style agents that we’ve studied are susceptible to the cyclic attack. There is a clear warning here about the powerful AI systems of the future: no matter how capable they seem, they may still fail in surprising ways. Adversarial testing and red teaming is essential for any high-stakes deployment, and finding new fault-tolerant approaches to AI may be necessary to avoid a chaotic future.
For more information, check out our ICML 2023 paper or the project website. If you are interested in working on problems related to adversarial robustness or AI safety more broadly, we're hiring for research engineers and research scientists. We’d also be interested in exploring collaborations with researchers at other institutions: feel free to reach out to hello@far.ai.
Acknowledgements
Thanks to Lawrence Chan, Claudia Shi and Jean-Christophe Mourrat for feedback on earlier versions of this manuscript.
Appendix: The Pass Attack
The first attack we discovered was the pass attack. It was found by an adversary trained with less than 1% of the computational resources required to train KataGo.
Our adversary (black) playing the pass attack against KataGo (white).
To perform the pass attack, the adversary focuses on securing a single corner as its territory, and lets KataGo spread across the rest of the board. Then the adversary plays some stones in KataGo’s territory to contest it (more on this later), and then passes its turn. KataGo then passes (since it seems to have much more territory than the adversary), ending the game. In Go, if both players pass one turn after the other, the game ends and the two players need to decide somehow which regions have been won by each player.
If this was a game between two humans, the players would decide based on what they expect would happen if they continue playing. In the above board state, if play continued, black would very likely secure the bottom right corner, and white would very likely secure the rest of the board, leading to white having much more territory than black. So the humans would agree that white (KataGo) has won.
But it’s different for games between AIs—we need to use some automated set of rules for deciding who has won at the end of a game. We chose to use KataGo’s version of Tromp-Taylor rules, which were the most frequently used ruleset during KataGo’s training. Under these rules, the game is scored as follows:
First, we remove stones that are guaranteed to be dead, as determined by Benson’s algorithm. Although a human would consider the three marked (△) black stones to be dead, they could live if white chose not to defend. So, the black stones are not removed from white’s territory.
Next, we mark every location on the board as belonging to black, white, or nobody. A location with a stone belongs to whichever color occupies that location. An empty region (formally a connected component of empty locations, connected along the cardinal directions) belongs to a color if that region only borders that single color. If an empty region borders both black and white stones, it is considered no-man’s land and belongs to neither player.
In the game above, all the empty locations in the lower-right belong to black. On the other hand, all of the remaining empty-space on the board is no-man’s land, since it borders both white stones and black’s marked black stones.
Finally, the total number of locations each player owns is counted, and whoever has more locations (modulo komi, extra points given to white to balance black making the first move) wins. In this case, black controls many more locations, so black wins.
When we published our results of this attack, we were met with skepticism from some members of the Go community as to whether this was a “real” exploit of KataGo, since it only affects play under computer rules. From a machine learning standpoint, this vulnerability is interesting regardless: KataGo has no inherent notion of how humans play Go, so the fact it is not vulnerable under human rules is largely a lucky coincidence. (Although the fact this vulnerability persisted for many years is perhaps a consequence of it not affecting human play. Had human players been able to win using this approach, it might have long ago been discovered and fixed.)
However, the attack is easily patched by hand-coding KataGo to not pass in unfavorable situations. We implemented this patch and then continued training our adversary against the patched KataGo. After another bout of training, we found a “true” adversarial attack on KataGo: the cyclic attack.
- ^
When you’re playing a game like Go or chess, there are, roughly speaking, two components to your decision making: intuition and simulation. On each turn, you’ll have some intuition of what kinds of moves would be good to play. For each promising move you consider, you’ll probably do a little simulation in your head of what is likely to unfold if you were to play that move. You’ll try to get into your opponent's head and imagine what they’ll do in response, then what you would do next, and so on. If it’s an especially important move, you might simulate many different possible directions the game could go down.
AlphaZero and its successors are also roughly made of two parts corresponding to intuition and simulation. Intuition is achieved with a policy network: a neural network that takes in board states and outputs a probability distribution over possibly good next moves. Simulation is achieved with Monte Carlo Tree Search (MCTS), an algorithm that runs many simulations of the future of the game to find the move that is most likely to lead to a win.
On each turn, an AlphaZero agent generates some promising moves using the policy network, and then uses MCTS to simulate how each move would play out. Since it is not practical for MCTS to exhaustively evaluate every possible sequence of play, the policy network is used to steer MCTS in the direction of better moves. Additionally, a value network is used to heuristically evaluate board states so that MCTS does not need to simulate all the way to the end of the game. Typically, the policy and value networks are two heads of the same network, sharing weights at earlier layers.
The policy network is trained to match as closely as possible the distribution of moves output by MCTS, and the value network is trained to predict the outcome of games played by the agent. As the networks improve, so does MCTS; and with a stronger MCTS, the policy and value networks get a better source of signal to try and match. AlphaZero relies on this positive feedback loop between the policy network, value network, and MCTS.
Finally, the training data for AlphaZero-style agents is generated using self-play, where an agent plays many games against a copy of itself. Self-play works well because it creates a curriculum. A curriculum in machine learning is a sequence of gradually harder challenges for an agent to learn. When humans learn a skill like Go, they also need a gradual increase in difficulty to avoid getting stuck. Even the best Go players in the world had to start somewhere: If they only had other world champions to play against from the start, they would never have gotten where they are today. In self-play, the two players are always at the same level, so you get a curriculum naturally.
22 comments
Comments sorted by top scores.
comment by gwern · 2023-07-20T21:05:00.949Z · LW(p) · GW(p)
The cyclic attack on the other hand is a substantial vulnerability of both KataGo and other superhuman Go bots, which has yet to be fixed despite attempts by both our team and the lead developer of KataGo, David Wu.
Does this circle exploit have any connection to convolutions? That was my first thought when I saw the original writeups, but nothing here seems to help explain where the exploit is coming from. All of the listed agents vulnerable to it, AFAIK, make use of convolutions. The description you give of Wu's anti-circle training sounds a lot like you would expect from an architectural problem like convolution blindness: training can solve the specific exploit but then goes around in cycles or circles (ahem), simply moving the vulnerability around, like squeezing a balloon.
I am also curious why the zero-shot transfer is so close to 0% but not 0%. Why do those agents differ so much, and what do the exploits for them look like?
Moreover, in concurrent work, a team at DeepMind found a way to beat a human-expert level version of AlphaZero. The fact that two different teams could find two distinct exploits against distinct AI programs is strong evidence that the AlphaZero approach is intrinsically vulnerable.
Do you know they are distinct? The discussion of Go in that paper is extremely brief and does not describe what the exploitation is at all, AFAICT. Your E3 also doesn't seem to describe what the Timbers agent does.
Replies from: polytope, AdamGleave↑ comment by polytope · 2023-07-24T14:30:39.409Z · LW(p) · GW(p)
I am also curious why the zero-shot transfer is so close to 0% but not 0%. Why do those agents differ so much, and what do the exploits for them look like?
The exploits for the other agents are pretty much the same exploit, they aren't really different. From what I can tell as an experienced Go player watching the adversary and other human players use the exploit, the zero shot transfer is not so high because the adversarial policy overfits to memorize specific sequences that let you set up the cyclic pattern and learns to do so in a relatively non-robust way.
All the current neural-net-based Go bots share the same massive misevaluations in the same final positions. Where they differ is that they may have arbitrarily different preferences among almost equally winning moves, so during the long period that the adversary is in a game-theoretically-lost position, any different victim all the while still never realizing any danger, may nonetheless just so happen to choose different moves. If you consider a strategy A that might broadly minimize the number of plausible ways a general unsuspecting victim might mess up your plan by accident, and a strategy B that leaves more total ways open but those ways are not the ones that small set of victim networks you are trained to exploit would stumble into (because you've memorized their tendencies enough to know they won't), the adversary is incentivized more towards B than A.
This even happens after the adversary "should" win. Even after it it finally reaches a position that is game-theoretically winning, it often blunders several times and plays moves that cause the game to be game-theoretically lost again, before eventually finally winning again. I.e. it seems overfit to the fact that the particular victim net is unlikely to take advantage of its mistakes, so it never learns that they are in fact mistakes. In zero-shot transfer against a different opponent this unnecessarily may give the opponent, who shares the same weakness but may just so happen to play in different ways, chances to stumble on a refutation and win again. Sometimes even without the victim even realizing that it was a refutation of anything and that they were in trouble in the first place.
I've noticed human exploiters play very differently than that. Once they achieve a game-theoretic-winning position they almost always close all avenues for counterplay and stop giving chances to the opponent that would work if the opponent were to suddenly become aware.
Prior to that point, when setting up the cycle from a game-theoretically lost position, most human players I've seen also play slightly differently too. Most human players are far less good at reliably using the exploit, because they haven't practiced and memorized as much the ways to get any particular bot to not accidentally interfere with them as they do so. So the adversary does much better than them here. But as they learn to do better, they tend do so in ways that I think transfer better (i.e. from observation my feeling is they maintain a much stronger bias towards things like "strategy A" above).
↑ comment by AdamGleave · 2023-07-20T23:53:06.119Z · LW(p) · GW(p)
Does this circle exploit have any connection to convolutions? That was my first thought when I saw the original writeups, but nothing here seems to help explain where the exploit is coming from. All of the listed agents vulnerable to it, AFAIK, make use of convolutions. The description you give of Wu's anti-circle training sounds a lot like you would expect from an architectural problem like convolution blindness: training can solve the specific exploit but then goes around in cycles or circles (ahem), simply moving the vulnerability around, like squeezing a balloon.
We think it might. One weak point against this is that we tried training CNNs with larger kernels and the problem didn't improve. However, it's not obvious that larger kernels would fix it (it gives the model less need for spatial locality, but it might still have an inductive bias towards it), and the results are a bit confounded since we trained the CNN based on historical KataGo self-play training data rather. We've been considering training a version of KataGo from scratch (generating new self-play data) to use vision transformers which would give a cleaner answer to this. It'd be somewhat time consuming though, so curious to hear how interesting you and other commenters would find this result so we can prioritize.
We're also planning on doing mechanistic interpretability to better understand the failure mode, which might shed light on this question.
Do you know they are distinct? The discussion of Go in that paper is extremely brief and does not describe what the exploitation is at all, AFAICT. Your E3 also doesn't seem to describe what the Timbers agent does.
My main reason for believing they're distinct is that an earlier version of their paper includes Figure 3 providing an example Go board that looks fairly different to ours. It's a bit hard to compare since it's a terminal board, there's no move history, but it doesn't look like what would result from capture of a large circular group. But I do wish the Timbers paper went into more detail on this, e.g. including full game traces from their latest attack. I encouraged the authors to do this but it seems like they've all moved on to other projects since then and have limited ability to revise the paper.
Replies from: gwern↑ comment by gwern · 2023-07-21T01:45:55.907Z · LW(p) · GW(p)
We've been considering training a version of KataGo from scratch (generating new self-play data) to use vision transformers which would give a cleaner answer to this.
I wouldn't really expect larger convolutions to fix it, aside from perhaps making the necessary 'circles' larger and/or harder to find or create longer cycles in the finetuning as there's more room to squish the attack around the balloon. It could be related to problems like the other parameters of the kernel like stride or padding. (For example, I recall the nasty 'checkboard' artifacts in generative upscaling were due to the convolution stride/padding, and don't seem to ever come up in Transformer/MLP-based generative models but also simply making the CNN kernels larger didn't fix it, IIRC - you had to fix the stride/padding settings.)
We've been considering training a version of KataGo from scratch (generating new self-play data) to use vision transformers which would give a cleaner answer to this. It'd be somewhat time consuming though, so curious to hear how interesting you and other commenters would find this result so we can prioritize.
I personally would find it interesting but I don't know how important it is. It seems likely that you might find a completely different-looking adversarial attack, but would that be conclusive? There would be so many things that change between a CNN KataGo and a from-scratch ViT KataGo. Especially if you are right that Timbers et al find a completely different adversarial attack in their AlphaZero which AFAIK still uses CNNs. Maybe you could find many different attacks if you change up enough hyperparameters or initializations.
On the gripping hand, now that I look at this earlier version, their description of it as a weird glitch in AZ's evaluation of pass moves at the end of the game sounds an awful lot like your first Tromp-Taylor pass exploit ie. it could probably be easily fixed with some finetuning. And in that case, perhaps Timbers et al would have found the 'circle' exploit in AZ after all if they had gotten past the first easy end-game pass-related exploit? (This also suggests a weakness in the search procedures: it really ought to produce more than one exploit, preferably a whole list of distinct exploits. Some sort of PBT or novelty search approach perhaps...)
Maybe a mechanistic interpretability approach would be better: if you could figure out where in KataGo it screws up the value estimate so badly, and what edits are necessary to make it yield the correct estimate,
comment by VojtaKovarik · 2023-07-23T00:45:44.390Z · LW(p) · GW(p)
My reaction to this is something like:
Academically, I find these results really impressive. But, uhm, I am not sure how much impact they will have? As in: it seems very unsurprising[1] that something like this is possible for Go. And, also unsurprisingly, something like this might be possible for anything that involves neural networks --- at least in some cases, and we don't have a good theory for when yes/no. But also, people seem to not care. So perhaps we should be asking something else? Like, why is that people don't care? Suppose you managed to demonstrate failures like this in settings X, Y, and Z --- would this change anything? And also, when do these failures actually matter? [Not saying they don't, just that we should think about it.]
To elaborate:
- If you understand neural networks (and how Go algorithms use them), it should be obvious that these algorithms might in principle have various vulnerabilities. You might become more confident about this once you learn about adversarial examples for image classifiers or hear arguments like "feed-forward networks can't represent recursively-defined concepts". But in a sense, the possibility of vulnerabilities should seem likely to you just based on the fact that neural networks (unlike some other methods) come with no relevant worst-case performance guarantees. (And to be clear, I believe all of this indeed was obvious to the authors since AlphaGo came out.)
- So if your application is safety-critical, security mindset [? · GW] dictates that you should not use an approach like this. (Though Go and many other domains aren't safety-critical, hence my question "when does this matter".)
- Viewed from this perspective, the value added by the paper is not "Superhuman Go AIs have vulnerabilities" but "Remember those obviously-possible vulnerabilities? Yep, it is as we said, it is not too hard to find them".
- Also, I (sadly) expect that reactions to this paper (and similar results) will mostly fall into one of the following two camps: (1) Well, duh! This was obvious. (2) [For people without the security mindset:] Well, probably you just missed this one thing with circular groups; hotfix that, and then there will be no more vulnerabilities. I would be hoping for reaction such as (3) [Oh, ok! So failures like this are probably possible for all neural networks. And no safety-critical system should rely on neural networks not having vulnerabilities, got it.] However, I mostly expect that anybody who doesn't already believe (1) and (3) will just react as (2).
- And this motivates my point about "asking something else". EG, how do people who don't already believe (3) think about these things, and which arguments would they find persuasive? Is it efficient to just demonstrate as many of these failures as possible? Or are some failures more useful than others, or does this perhaps not help at all? Would it help with "signpost moving" if we first made some people commit to specific predictions (eg, "I believe scale will solve the general problem of robustness, and in particular I think AlphaZero has no such vulnerabilities").
- ^
At least I remember thinking this when AlphaZero came out. (We did a small project in 2018 where we found a way to exploit AlphaZero in the tiny connect-four game, so this isn't just misremembering / hindsight bias.)
↑ comment by AdamGleave · 2023-07-23T22:47:16.125Z · LW(p) · GW(p)
When I started working on this project, a number of people came to me and told me (with varying degrees of tact) that I was wasting my time on a fool's errand. Around half the people told me they thought it was extremely unlikely I'd find such a vulnerability. Around the other half told me such vulnerabilities obviously existed, and there was no point demonstrating it. Both sets of people were usually very confident in their views. In retrospect I wish I'd done a survey (even an informal one) before conducting this research to get a better sense of people's views.
Personally I'm in the camp that vulnerabilities like these existing was highly likely given the failures we've seen in other ML systems and the lack of any worst-case guarantees. But I was very unsure going in how easy they'd be to find. Go is a pretty limited domain, and it's not enough to beat the neural network: you've got to beat Monte-Carlo Tree Search as well (and MCTS does have worst-case guarantees, albeit only in the limit of infinite search). Additionally, there are results showing that scale improves robustness (e.g. more pre-training data reduces vulnerability to adversarial examples in image classifiers).
In fact, although the method we used is fairly simple, actually getting everything to work was non-trivial. There was one point after we'd patched the first (rather degenerate) pass-attack that the team was doubting whether our method would be able to beat the now stronger KataGo victim. We were considering cancelling the training run, but decided to leave it going given we had some idle GPUs in the cluster. A few days later there was a phase shift in the win rate of the adversary: it had stumbled across some strategy that worked and finally was learning.
This is a long-winded way of saying that I did change my mind as a result of these experiments (towards robustness improving less than I'd previously thought with scale). I'm unsure how much effect it will have on the broader ML research community. The paper is getting a fair amount of attention, and is a nice pithy example of a failure mode. But as you suggest, the issue may be less a difference in concrete belief (surely any ML researcher would acknowledge adversarial examples are a major problem and one that is unlikely to be solved any time soon), than that of culture (to what degree is a security mindset appropriate?).
This post was written as a summary of the results of the paper, intended for a fairly broad audience, so we didn't delve much into the theory of change behind this agenda here. You might find this blog post [AF · GW] describing the broader research agenda this paper fits into provides some helpful context, and I'd be interested to hear your feedback on that agenda.
↑ comment by Noosphere89 (sharmake-farah) · 2023-07-23T17:21:57.839Z · LW(p) · GW(p)
(2) [For people without the security mindset:] Well, probably you just missed this one thing with circular groups; hotfix that, and then there will be no more vulnerabilities.
i actually do expect this to happen, and importantly I think this result is basically of academic interest, primarily because it is probably known why this adversarial attack can have at all, and it's the large scale cycles of a game board. This is almost certainly going to be solved, due to new training, so I find it a curiosity at best.
Replies from: VojtaKovarik↑ comment by VojtaKovarik · 2023-07-23T18:36:00.550Z · LW(p) · GW(p)
Yup, this is a very good illustration of the "talking past each other" that I think is happening with this line of research. (I mean with adversarial attacks on NNs in general, not just with Go in particular.) Let me try to hint at the two views that seem relevant here.
1) Hinting at the "curiosity at best" view: I agree that if you hotfix this one vulnerability, then it is possible we will never encounter another vulnerability in current Go systems. But this is because there aren't many incentives to go look for those vulnerabilities. (And it might even be that if Adam Gleave didn't focus his PhD on this general class of failures, we would never have encountered even this vulnerability.)
However, whether additional vulnerabilities exist seems like an entirely different question. Sure, there will only be finitely many vulnerabilities. But how confident are we that this cyclic-groups one is the last one? For example, I suspect that you might not be willing to give 1:1000 odds on whether we would encounter new vulnerabilities if we somehow spent 50 researcher-years on this.
But I expect that you might say that this does not matter, because vulnerabilities in Go do not matter much, and we can just keep hotfixing them as they come up?
2) And the other view seems to be something like: Yes, Go does not matter. But we were only using Go (and image classifiers, and virtual-environment football) to illustrate a general point, that these failures are an inherent part of deep learning systems. And for many applications, that is fine. But there will be applications where it is very much not fine (eg, aligning strong AIs, cyber-security, economy in the presence of malicious actors).
And at this point, some people might disagree and claim something like "this will go away with enough training". This seems fair, but I think that if you hold this view, you should make some testable predictions (and ideally ones that we can test prior to having superintelligent AI).
And, finally, I think that if you had this argument with people in 2015, many of them would have made predictions such as "these exploits work for image classifiers, but they won't work for multiagent RL". Or "this won't work for vastly superhuman Go".
Does this make sense? Assuming you still think this is just an academic curiosity, do you have some testable predictions for when/which systems will no longer have vulnerabilities like this? (Pref. something that takes fewer than 50 researcher years to test :D.)
Replies from: sharmake-farah↑ comment by Noosphere89 (sharmake-farah) · 2023-07-23T18:46:27.543Z · LW(p) · GW(p)
I was mostly focusing on the one vulnerability presented, and thus didn't want to make any large scale claims on whether this will entirely go away. The reason I labeled it a curiosity is because the adversarial attack exploits a weakness of a specific type of neural network, and importantly given the issue, it looks like it's a solvable one.
comment by ryan_greenblatt · 2023-07-21T05:32:27.066Z · LW(p) · GW(p)
Many proposed solutions to the alignment problem involve one “helper AI” providing a feedback signal steering the main AI system towards desirable behavior. Unfortunately, if the helper AI system is vulnerable to adversarial attack, then the main AI system will achieve a higher rating by the helper AI if it exploits the helper instead of achieving the desired task. ... To address this, we have proposed a new research program of fault-tolerant alignment strategies.
I remain skeptical this is a serious problem as opposed to a reason that sample efficiency is somewhat lower than it otherwise would be. This also changes the inductive biases of various RL schemes by changing the intermediate incentives of the policy, but these changes seem to be mostly innocuous to me.
(To be clear, I think AIs not being adversarially robust is generally notable and has various implications, I just disagree that it causes any issues for these sorts of training schemes which use helper AIs.)
Another way to put my claim is "RLHF is already very fault tolerant and degrades well with the policy learning to adversarially attack the reward model". (A similar argument will apply for various recursive oversight schemes or debate.)
In my language, I'd articulate this sample efficiency argument as "because the policy AI will keep learning to attack the non-robust helper AI between human preference data which fixes the latest attack, human preference data will be required more frequently than it otherwise would be. This lack of sample efficiency will be a serious problem because [INSERT PROBLEM HERE]".
I personally don't really see strong arguments why improvements to sample efficiency are super leveraged at the margin given commercial incentives and some other factors. Beyond this, I think just working on sample efficiency of RL seems like a pretty reasonable way to improve sample efficiency if you do think it seems very important and net positive. It's a straight forward empirical problem and I don't think there are any serious changes to problem between GPT-4 and AGI which mean that normal empirical iteration isn't viable.
Alteratively, if you think the issue is that periodically being incentivized to adversarially attack the reward model has serious problematic effects on the inductive biases of RL, it seems relevant to argue for why this would be the case. I don't really see why this would be important. It seems like periodically being somewhat trained to find different advexes shouldn't have much effect on how the AI generalizes?
(See also this comment thread here [LW(p) · GW(p)], Adam and I talked about this some in person afterwards also)
Replies from: AdamGleave↑ comment by AdamGleave · 2023-07-22T04:00:13.465Z · LW(p) · GW(p)
Thanks for flagging this disagreement Ryan. I enjoyed our earlier conversation (on LessWrong and in-person) and updated in favor of the sample efficiency framing, although we (clearly) still have some significant differences in perspective here. Would love to catch up again sometime and see if we can converge more on this. I'll try and summarize my current take and our key disagreements for the benefit of other readers.
I think I mostly agree with you that in the special case of vanilla RLHF this problem is equivalent to a sample efficiency problem. Specifically, I'm referring to the case where we perform RL on a learned reward model; that reward model is trained based on human feedback from an earlier version of the RL policy; and this process iterates. In this case, if the RL algorithm learns to exploit the reward model (which it will, in contemporary systems, without some regularization like a KL penalty) then the reward model will receive corrective feedback from the human. At worst, this process will just not converge, and the policy will just bounce from one adversarial example to another -- useless, but probably not that dangerous. In practice, it'll probably work fine given enough human data and after tuning parameters.
However, I think sample efficiency could be a really big deal! Resolving this issue of overseers being exploited I expect could change the asymptotic sample complexity (e.g. exponential to linear) rather than just changing the constant factor. My understanding is that your take is that sample efficiency is unlikely to be a problem because RLHF works fine now, is fairly sample efficient, and improves with model scale -- so why should we expect it to get worse?
I'd argue first that sample efficiency now may actually be quite bad. We don't exactly have any contemporary model that I'd call aligned. GPT-4 and Claude are a lot better than what I'd expect from base models their size -- but "better than just imitating internet text" is a low bar. I expect if we had ~infinite high quality data to do RLHF on these models would be much more aligned. (I'm not sure if having ~infinite data of the same quality that we do now would help; I tend to assume you can trade less quantity for increased quality, but there are obviously some limits here.)
I'm additionally concerned that sample efficiency may be highly task dependent. RLHF is a pretty finnicky method, so we're tending to see the success cases of it. What if there are just certain tasks that it's really hard to use RLHF for (perhaps because the base model doesn't already have a good representation of it)? There'll be a strong economic pressure to develop systems that do that task anyway, just using less reliable proxies for that task objective.
(A similar argument will apply for various recursive oversight schemes or debate.)
This might be the most interesting disagreement, and I'd love to dig into this more. With RLHF I can see how you can avoid the problem with sufficient samples since the human won't be fooled by the AdvEx. But this stops working in a domain where you need scalable oversight as the inputs are too complex for a human to judge, so can't provide any input.
The strongest argument I can see for your view is that scalable oversight procedures already have to deal with a human that says "I don't know" for a lot of inputs. So, perhaps you can make a base model that perfectly mimics what the human would say on a large subset of inputs, and for AdvEx's (as well as some other inputs) says "I don't know". This is still a hard problem -- my impression was adversarial example detection is still far from solved -- but is plausibly a fair bit easier than full robustness (which I suspect isn't possible). Then you can just use your scalable oversight procedure to make the "I don't knows" go away.
Alteratively, if you think the issue is that periodically being incentivized to adversarially attack the reward model has serious problematic effects on the inductive biases of RL, it seems relevant to argue for why this would be the case. I don't really see why this would be important. It seems like periodically being somewhat trained to find different advexes shouldn't have much effect on how the AI generalizes?
I think this is an area where we disagree but it doesn't feel central to my view -- I can see it going either way, and I think I'd still be concerned by whether the oversight process is robust even if the process wasn't path dependent (e.g. we just did random restarting of the policy every time we update the reward model).
comment by Logan Zoellner (logan-zoellner) · 2024-09-06T00:07:40.865Z · LW(p) · GW(p)
What would the Platonically ideal version of this result be (assuming it isn't just a fluke of CNNs or something)?
Something along the lines of "For any PSpace complete zero-sum game, adversary X with access to a simulator of Agent Y has {complexity function} advantage in the sense that X can defeat Y using {total compute to train Y}/{complexity function}"?
Assuming we could prove such a theorem true (which we almost certainly can't since we can't even prove P=NP), what would the implications for AI Alignment be?
"Don't give your adversary a simulator of yourself they can train against" seems like an obvious one.
Maybe there's some alternative formulation that yeilds "don't worry, we can always shut the SAI down"?
comment by Review Bot · 2024-03-15T17:33:32.725Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?
comment by momom2 (amaury-lorin) · 2023-07-22T20:49:40.427Z · LW(p) · GW(p)
I'm confused. Does this show anything besides adversarial attacks working against AlphaZero-like AIs?
Is it a surprising result? Is that kind of work important for reproducibility purposes regardless of surprisingness?
↑ comment by Richard Horvath · 2023-07-23T10:41:14.895Z · LW(p) · GW(p)
I find it exciting for the following:
These AIs are (were) thought to be in the Universe of Go what AGI is expected to be in the actual world we live in: an overwhelming power no human being can prevail against, especially not an amateur just by following some weird tactic most humans could defeat. It seemed they had a superior understanding of the game's universe, but as per the article this is still not the same kind of understanding we see in humans. We may have overestimated our own understanding of how these systems work, this is an unexpected (confusing) outcome. Especially that it is implied that this is not just a bug in a specific system but possibly other systems using similar architecture will have the same defects. I think this is a data point towards A.I. winter to be expected in the coming years rather than FOOM.
Replies from: gwern↑ comment by gwern · 2023-07-24T02:20:31.051Z · LW(p) · GW(p)
I'd read it as the opposite in terms of safety, particularly in light of Adam's comment [LW(p) · GW(p)] on how the exploit was so hard to find and required so much search/training they very nearly gave up before it finally started to work. (Compare to your standard adversarial attacks on eg a CNN classifier where it's licketysplit in seconds for most of them.)
I would put myself in the 'believes it is trivial there are adversarial examples in KataGo' camp, in part because DRL agents have always had adversarial examples and in part because I suspect that the isoperimetry line of work may be correct and in which case all existing Go/chess programs like KataGo (which tend to have ~0.1b parameters) may be 3 orders of magnitude too small to remove most adversarialness (if we imagine Go is about as hard as ImageNet and take the back-of-the-envelope speculation that isoperimetry on ImageNet CNNs would require ~100b parameters).
So for me the interesting aspects are (1) the exploit could be executed by a fairly ordinary human, (2) it had non-zero success on other agents (but much closer to 0% than 100%), (3) it's unclear where the exploit comes from but is currently plausibly coming from a component which is effectively obsolete in the current scaling paradigm (convolutions), and (4) it was really hard to find even given one of the most powerful attack settings (unlimited tree search over a fixed victim model).
From the standpoint of AI safety & interpretability this is very concerning as it favors attack rather than defense. It means that fixed known instances of superhuman models can have difficult to find but trivially-exploited exploits, which are not universal but highly model-specific. Further, it seems plausible given the descriptions that while they may never go away, it may get harder to find an exploit with scale, leading to both a dangerous overhang in superhuman-seeming but still vulnerable 'safe' models and an incentive for rogue models to scale up as fast as possible. So you can have highly-safe aligned agents with known-good instances, which can be attacked as static victim models by dumb agents until a trivial exploit is found, which may need to only succeed once, such as in a sandbox escape onto the Internet. (The safe models may be directly available to attack, or may just be available as high-volume APIs - how would OA notice if you were running a tree search trying to exploit gpt-3-turbo when it's running through so many billions or trillions of tokens a day across so many diverse users right now?) If you try to replace them or train a population of different agents to reduce the risk of an exploit working on any given try (eg. AlphaStar sampling agents from the AlphaStar League to better approximate Nash play), now you have to pay an alignment tax on all of that. But asymmetrically, autonomous self-improving agents will not be equally vulnerable simply because they will be regularly training new larger iterations which will apparently mostly immunize them from an old exploit - and how are you going to get them to hold still long enough to acquire a copy of them to run these slow expensive 'offline' attacks? (It would be very polite of them to provide you checkpoints or a stable API!)
an overwhelming power no human being can prevail against, especially not an amateur just by following some weird tactic most humans could defeat.
Where you gonna get said weird tactic...? The fact that there exists an adversarial attack does no good if it cannot be found.
Replies from: Radford Neal↑ comment by Radford Neal · 2023-07-24T03:08:08.573Z · LW(p) · GW(p)
I think the cyclic group exploit could have been found by humans. The idea behind it (maybe it gets confused about liberties when a group is circular) would probably be in the top 1000 ideas for exploits that a group of humans would brainstorm. Then these would need to be tested. Finding a working implementation would be a matter of trial and error, maybe taking a week. So if you got 100 good human go players to test these 1000 ideas, the exploit would be found within ten weeks.
The main challenge might be to maintain morale, with the human go players probably being prone to discouragement after spending some weeks trying to get exploit ideas to work with no success, and hence maybe not focusing hard on trying to get the next one to work, and hence missing that it does. Maybe it would work better to have 1000 human go players each test one idea...
Replies from: gwern↑ comment by gwern · 2023-07-25T01:36:04.129Z · LW(p) · GW(p)
We'll never know now, of course, since now everyone knows about weird circular patterns as something to try, along with more famous older exploits of computer Go programs like ladders or capture races.
First, I'd note that in terms of AI safety, either on offense or defense, it is unhelpful even if there is some non-zero probability of a large coordinated human effort finding a specific exploit. If you do that on a 'safe' model playing defense, it is not enough to find a single exploit (and presumably then patch it), because it can be hacked by another exploit; this is the same reason why test-and-patch is insufficient for secure software. Great, you found the 'circle exploit' - but you didn't find the 'square exploit' or the 'triangle exploit', and so your model gets exploited anyway. And from the offense perspective of attacking a malign model to defeat it, you can't run this hypothetical at all because by the time you get a copy of it, it's too late.
So, it's mostly a moot point whether it could be done from the AI safety perspective. No matter how you spin it, hard-to-find-but-easy-to-exploit exploits in superhuman models is just bad news for AI safety.
OK, but could humans? I suspect that humans could find it (unaided by algorithms) with only relatively low probability, for a few reasons.
First, they didn't find it already; open-source Go programs like Leela Zero are something like 6 years old now (it took a year or two after AG to clone it), and have been enthusiastically used by Go players, many of which would be interested in 'anti-AI tactics' (just as computer chess had its 'anti-engine tactics' period) or could stumble across it just wanking around doing weird things like making big circles. (And 'Go players' here is a large number: Go is still one of the most popular board games in the world, and while DeepMind may have largely abandoned the field, it's not like East Asians in particular stopped being interested in it or researching it.) So we have a pretty good argument-from-silence there.
Second, the history of security & cryptography research tends to show that humans overlap a lot with each other in the bugs/vulns they find, but that algorithmic approaches can find very different sets of bugs. (This should be a bit obvious a priori: if humans didn't think very similarly and found uncorrelated sets of bugs, it'd be easy to remove effectively all bugs just by throwing a relatively small number of reviewers at code, to get an astronomically small probability of any bugs passing all the reviewers, and we'd live in software/security paradise now. Sadly, we tend to look at the wrong code and all think the same thing: 'lgtm'.) More dramatically, we can see the results of innovations like fuzzing. What's the usual result whenever someone throws a fuzzer at an unfuzzed piece of software, even ones which are decades old and supposedly battle-hardened? Finding a bazillion vulnerabilities all the human reviewers had somehow never noticed and weirdo edgecases. (See also reward hacking and especially "The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities", Lehman et al 2018; most of these examples were unknown, even the arcade game ones, AFAICT.) Or here's an example from literally today: Tavis (who is not even a CPU specialist!) applied a fuzzer using a standard technique but in a slightly novel way to AMD processors and discovered yet another simple speculative execution bug in the CPU instructions which allows exfiltration of arbitrary data in the system (ie. arbitrary local privilege escalation since you can read any keys or passwords or memory locations, including VM escapes, apparently). One of the most commonly-used desktop CPU archs in the world* going back 3-4 years, from a designer with 50 years of experience, doubtless using all sorts of formal methods & testing & human review already, yet, there you go: who would win, all that or one smol slightly tweaked algorithmic search? Oops.
Or perhaps another more relevant example would be classic NN adversarial examples tweaking pixels: I've never seen a human construct one of those by hand, and if you had to hand-edit an image pixel by pixel, I greatly doubt a thousand determined humans (who were ignorant of them but trying to attack a classifier anyway) would stumble across them ever, much less put them in the top 1k hypotheses to try. These are just not human ways to do things.
* In fact, I personally almost run a Zenbleed-affected Threadripper CPU, but it's a year too old, looks like. Still, another reason to be careful what binaries you install...
↑ comment by momom2 (amaury-lorin) · 2023-07-22T21:31:15.471Z · LW(p) · GW(p)
To clarify: what I am confused about is the high AF score, which probably means that there is something exciting I'm not getting from this paper.
Or maybe it's not a missing insight, but I don't understand why this kind of work is interesting/important?
↑ comment by Radford Neal · 2023-07-22T21:36:40.652Z · LW(p) · GW(p)
Did you think it was interesting when AIs became better than all humans at go?
If so, shouldn't you be interested to learn that this is no longer true?
Replies from: amaury-lorin↑ comment by momom2 (amaury-lorin) · 2023-07-24T05:24:08.436Z · LW(p) · GW(p)
Well, I wasn't interested because AIs were better than humans at go, I was interested because it was evidence of a trend of AIs being better at humans at some tasks, for its future implications on AI capabilities.
So from this perspective, I guess this article would be a reminder that adversarial training is an unsolved problem for safety, as Gwern said above. Still doesn't feel like all there is to it though.
↑ comment by Radford Neal · 2023-07-24T15:43:58.212Z · LW(p) · GW(p)
I think it may not be correct to shuffle this off into a box labelled "adversarial example" as if it doesn't say anything central about the nature of current go AIs.
Go involves intuitive aspects (what moves "look right"), and tree search, and also something that might be seen as "theorem proving". An example theorem is "a group with two eyes is alive". Another is "a capture race between two groups, one with 23 liberties, the other with 22 liberties, will be won by the group with more liberties". Human players don't search the tree down to a depth of 23 to determine this - they apply the theorem. One might have thought that strong go AIs "know" these theorems, but it seems that they may not - they may just be good at faking it, most of the time.