On AI Scaling
post by harsimony · 2025-02-05T20:24:56.977Z · LW · GW · 3 commentsThis is a link post for https://splittinginfinity.substack.com/p/on-ai-scaling
Contents
Scaling laws The asymptote is the entropy of the data Models are only as good as the dataset Method errors Overtraining Model distillation Data distillation Synthetic data RLHF and filtering synthetic data Test-time scaling Self-play and bootstrapping Iteratively compressing CoT models Dataset size and quality are the only bottleneck Grinding our way to AGI Appendix Further reading Blogs Papers Easy data None 3 comments
I’ve avoided talking about AI, mostly because everyone is talking about it. I think the implications of AI scaling were clear a while ago, and I mostly said my piece back [LW · GW] then [LW · GW].
It’s time to take another crack at it.
Scaling laws
Scaling laws are a wonderful innovation[1]. With large enough training runs, performance is often a smooth function of the inputs you used for training. This is true over many orders of magnitude change in the inputs.
Major inputs include:
- Money
- Compute
- Training time
- Dataset size
- Dataset quality
- Number of parameters
- Training algorithm
- Researcher hours
Many of these factors are related. Money gets spent buying more compute and researchers. Total compute is a function of training time.
Let’s look at the relationship between compute, dataset size (of a fixed quality), and number of parameters. Here’s the correct Chinchilla scaling law:

L is the pre-training loss, N is the number of parameters, and D is the dataset size. This is the compute optimal scaling law. That is, if you used a fixed amount of compute optimally, this is how N and D contribute to the loss. Where compute is roughly 6*N*D.
Two things to notice about this function. First, there are diminishing returns: as you increase N or D they shrink their respective terms and the 1.82 becomes dominant. Second, 1.82 is the best loss you can get, the law asymptotes to that value, even with infinite compute, parameters, and data. We’ll come back to that later.
With this law, we can see how the ratio between dataset size (tokens) and number of parameters changes for larger compute budgets[2].
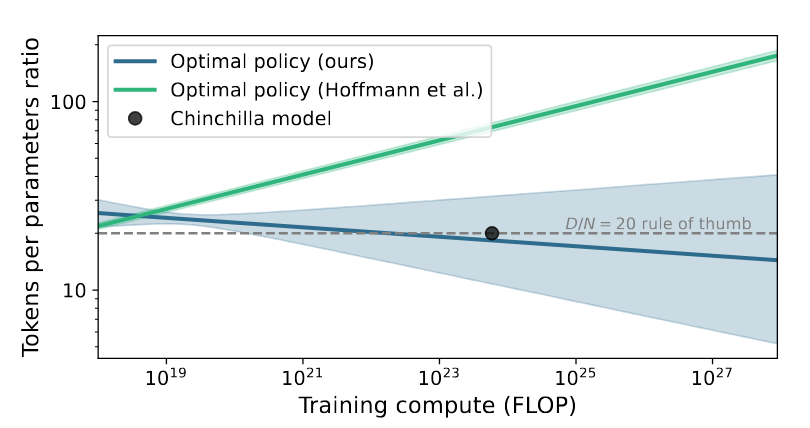
The takeaway is that number of parameters is a fixed or falling fraction of the dataset size. N is not a free variable, it’s determined by the amount of data and compute you have.
The asymptote is the entropy of the data
The N and D term tell you how adding more parameters or data reduces the loss. The number in front, E, tells you what the loss would asymptote to if you had an infinite amount of N and D (and thus compute).
In other words, it’s how unpredictable the dataset would be even with infinite resources. Another way of saying that is that E tells you the intrinsic randomness or entropy of the dataset.
If the data was a bunch of independent coinflips, each point would have an entropy of 1 bit. If I’m understanding the cross-entropy loss metric correctly, the scaling law implies that there are 1.82 bits of information per token of internet text. In other words, an ideal compression system could compress internet text down to 1.82 bits per token.
I speculate that this has implications for how fast a model can learn from a dataset. If the current loss is 10 bits/token and the irreducible loss is 2 bits/token, then each token provides 8 bits of information and 2 bits of noise. By taking enough samples, you can sift the signal from the noise and update your parameters. When the model loss falls to 3 bits/token there’s much less information per token and learning slows down.
The information required to specify a 32-bit float is, er, 32 bits. So larger models with more parameters need more training examples to find a set of weights that performs well[3].
What would it mean for different datasets to have different E?
Models are only as good as the dataset
Let’s start with some hypotheticals:
- If you train on a dataset of 2000 ELO chess moves, your model will learn to output better and better moves, asymptotically approaching ELO 2000[4].
- If you take your 2000 ELO model and start training it on ELO 1000 moves, the model will get worse at chess, converging to ELO 1000.
- If you train a model on both 2000 ELO and 1000 ELO moves, it will settle at an ELO somewhere in between.
The lesson here is that the model can only be as good as the data it’s provided with. There are fundamental limits on how well any model can learn a dataset. So if you want high performance, you need datasets that are 1. large, 2. useful, and 3. low E.
This is a more nuanced statement than it might seem. Let’s look at the details.
Method errors
The quality of your model is another component of E. If the dataset has an entropy of 2 bits/token but the best possible choice of model parameters has a loss of 2.1 bits/token then E is 2.1 bits/token.
For instance, if you don’t give your chess model an option to en passant during a game, it won’t reach the best possible performance.
With a large enough model and a good training procedure, these model errors probably don’t add much to the loss.
Overtraining
Overtraining is when you use the same data multiple times during training. Studies suggest that you can 5x your dataset before hitting diminishing returns. This doesn’t contradict the rule, it merely suggests that models are not learning optimally from each datapoint.
Model distillation
Model distillation is when you train a larger model, and then train a smaller model on the outputs of the larger one. Often, the smaller model can outperform the larger one on the same dataset!
We can get higher performance without changing the dataset, but tha doesn’t break the rule. The data sets the ultimate limit for model performance, but it can’t save you if your approach is crap.
Why does distillation work? The best explanation I’ve seen is that the smaller model regularizes the larger model. There are examples in classical statistics where regularization automatically gets you higher performance. For instance, the James-Stein estimator has you shrink your guess for the mean vector towards the origin a little. This improves your guess regardless of the data!
Data distillation
I’m using this term a little differently than everyone else. By data distillation, I mean identifying the most valuable parts of your dataset and training exclusively on those. Corpuses like Common Crawl need extensive cleaning before being used in training. Going back to chess example #3 where the dataset had both ELO 2000 and ELO 1000 moves, you can select only the ELO 2000 moves and train on those.
Sometimes your model can do this automatically. Language models have learned to emulate all sorts of different writing styles found in the corpus. Prompting them to produce high-quality writing is sufficient to distill the high quality writing from the dataset in some sense.
Synthetic data
Synthetic data is when you have a language model produce text, and train the model on the text it generated. It’s not a panacea, but training on model outputs can increase your dataset by about 5x.
Synthetic data alone cannot lead to recursive self improvement. The model is not generating new, useful information to train on. In other words, perpetual motion machines are not allowed in statistics.
But a new opportunity arises if you can apply some external source of information to the synthetic data.
RLHF and filtering synthetic data
Using humans to filter synthetic data for quality gives you a new source of information. Now you have a higher quality dataset without needing people to write it themselves!
RLHF and related techniques go a step further, incorporating lots of human feedback to train a reward model, and using this model to train the base model.
These approaches don’t refute the rule, they merely produce new data for the model to train on. Every time we filter something from the synthetic dataset, we’re creating new information. Every chunk of human preference data creates information for the model to train on.
As you make your filter more selective, each datapoint becomes more informative, but the dataset gets smaller.
Test-time scaling
Test-time compute, test-time training, test time search, and chain-of-thought all get at something similar. Have the model think more before answering. It’s a good idea; looped transformers are computationally universal.
But it still doesn’t refute the primacy of the dataset. Models can squeeze more performance out of multiple tries on a question, and they can get more performance by thinking more, but that performance is based on the quality of the base model and the dataset used to train the model to think. You build a dataset to teach it to think. It does not teach itself to think.
Self-play and bootstrapping
Can’t models create their own dataset? Yes, in verifiable domains like chess, the model can self-play and quickly learn if it succeeded or failed. It can write code and check that it runs, write proofs and check that they are valid.
As long as you have clear success criteria, there’s no limit to what you can do with this method. Have a model use chain-of-thought on a bunch of word problems and check against the answers. Have robot arms fiddle around in the real world until they complete a particular task.
There’s no noise, so there’s no limit to what the model can learn. E is zero, and the model can learn to perfectly match the dataset or complete any task.
In practice, verifying that something was done correctly or specifying goals is hard. Like everything else, self-play has diminishing returns. A chess bot with ELO 4000 makes very few mistakes, learning less and less each game. Even though it doesn’t asymptote, it may take indefeasibly long to reach a particular level of performance.
Nobody really knows where the diminishing returns start to bite for these systems. But this sort of bootstrapping should be sufficient to do just about anything.
Iteratively compressing CoT models
Gwern claims [LW · GW] (more discussion here) that the point of CoT models like Open AI’s o1 can be used to generate training data for a smaller model like o3-mini. o3-mini can then reach a similar performance to o1, but reach conclusions faster by virtue of being smaller. Then o3-mini can learn to think better with self-play. You can repeat this process, making the model faster so it can learn faster[5].
Is this the singularity everyone’s talking about? The previous discussion prepared us for this.
- While training on o1 outputs, o3-mini asymptotes to the performance of o1.
- While training on verifiable data, o3-mini is subject to the same diminishing returns with self-play. Though it should travel up the curve faster than o1 because it’s smaller.
- There’s only so much information a model can hold. As training continues on verifiable data, smaller models will asymptote sooner and eventually parameter count will have to increase again to get more performance.
- Training on imperfect data means that o3-mini is subject the same data limitations as everything else.
So this iterative process is a faster way to find the asymptote of self-play data. But it still leaves us at the mercy of data quality and quantity.
In fact, Gwern doesn’t think OpenAI has solved AGI, or that they’re close. The data seem to bear this out, o3-mini achieves similar performance to o1, at a 100x cost reduction, scales a little faster, but still has sharply diminishing returns.
The question remains where the asymptote is and how much self-play transfers elsewhere.

Dataset size and quality are the only bottleneck
The dataset is the only thing that matters. The optimal number of parameters is determined by the amount of compute and the dataset. The compute is determined by the size and quality of the dataset.
What about algorithm quality? Modern transformer models can learn ~everything and the field is converging around a few tweaks to the existing paradigm. Theories like tensor programs suggest that past a certain size, there’s a correct setting for the hyperparameters. No need to experiment.
These factors reduce the importance of researcher hours and algorithmic improvements. Just stack more layers lol. If the promises of an automated AI researcher pan out, we’ll quickly wring out the last bits of method error. Then we’re stuck with E, dataset quality.
Grinding our way to AGI
So if Data Is All You Need, what does that mean for AI development? A large and low-error dataset is sufficient to train a model to perform any task.
John von Neumann had it right; we can make an AI that can do anything so long as we can specify it. We’ll push forward the only way we know how, with bigger datasets and better benchmarks. We’ll find better methods by GitHub Descent. We’ll beg Scott Alexander for training data.

We’re literally doing this. And that’s good. (Source)
Once a benchmark is saturated we’ll make a new one. The benchmark doesn’t teach valuable skills? A stock trading benchmark! A benchmark can’t capture romantic love? A sexbot benchmark! Benchmark can’t identify AGI? ARC-AGI_final_v5!
This why machine learning took off in the first place. The culture of openness, competitive benchmarks, and easy-to-steal ideas created a singularity of self-improvement. There’s no limit to what our hive mind can do. Simulate all of biology from gene sequencing data. Strap a Go Pro to everyone’s head to emulate human behavior. Send robots to the stars and start iterating.
All takes is the entire semiconductor industry, half of academia, a solar-industrial revolution, and everyone who ever posted on the internet.

Appendix
Further reading
Blogs
chinchilla's wild implications [LW · GW] (note the scaling law is wrong, but the conclusion is the same).
Nostalgebraist on the mindset shift of scaling laws.
The “it” in AI models is the dataset.
Papers
Inference Scaling fLaws: The Limits of LLM Resampling with Imperfect Verifiers
Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
Time Matters: Scaling Laws for Any Budget
gzip Predicts Data-dependent Scaling Laws
Entropy Law: The Story Behind Data Compression and LLM Performance
Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic
Easy data
I would guess that basically all high quality human thought is written down as long form text[6]. How much easily available high-quality data is still out there? Not enough. Some estimates of untapped datasets:
Library of Congress: from this footnote I assume there are at most 100 million books worth of text in the LoC and from this page I assume that books are 100k words, giving 10T words at most.
Research papers: this page estimates ~4m papers are published each year, at 10k words per paper with 100 years of research this amounts to 4T words total.
There are about 1.3 tokens per word, so together these are 18.2T tokens. Llama-3 dataset was 15 trillion tokens, so adding these would roughly double it. But there is probably substantial overlap between the two.
Datasets like Common Crawl are larger (~100T), but contain so much low-quality text that the usable size is much smaller. Epoch estimates larger amounts of public text are available, but I’d guess it’s mostly low-quality. This MR post and this post suggest other data sources.
We can overtrain to increase the dataset size by about 5x before hitting diminishing returns. Synthetic data seems to provide another 5x boost. After that, we’re out of available data.
But don’t underestimate the elasticity of supply! We’ll find lots of ways to squeeze data from unconventional sources. Verifiable domains like math, code, and games will have self-generated data. Robots can use a combination of simulations and real world interaction. And for the squishy domains that require human judgement, we’ll use an army of philosophers to create datasets.
- ^
Arguably the best mindset shift since Moore’s law, but that’s a topic for another time.
- ^
It’s interesting in their fit that N falls as D gets larger. Perhaps there’s a maximum number of parameters beyond which there’s no performance benefit? But you can’t reject the hypothesis of D/N = 20 either.
- ^
The volume of parameter space that’s close to a low loss singularity should be related to the Real Log Canonical Threshold [? · GW]. I wonder if anyone has made the relationship between training loss, entropy, RLCT, and the number (and size) of batches required to get a certain loss.
- ^
Regularization can help it find a ELO 3000 hypothesis, but with further training it will return to ELO 2000. During training it can fluctuate above or below ELO 2000 as well.
- ^
This process is reminiscent of iterated distillation-amplification.
- ^
Mainly because people think best when they actually write something down. Most conversations, podcasts, and presentations are repeating things that were written better elsewhere.
3 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2025-02-05T22:07:14.072Z · LW(p) · GW(p)
Chinchilla's 20 tokens/param (at 6e23 FLOPs) change significantly when working with different datasets, architectures, or amounts of compute. For Llama-3-405B, it's 37 tokens/param at 4e25 FLOPs and increasing 1.5x for every 1000x of compute (Figure 3). When training on data repeated 60 times, optimal tokens/param increase about 2.5x (Figure 3).
For MoE models with 87% (1:8) sparsity, optimal tokens/param increase 3x, and at 97% (1:32) sparsity by 6x (Figure 12, left). This suggests that if Llama-3-405B was instead a MoE model with 97% sparsity, it would have 220 tokens/param optimal and not 37.
Overtraining or undertraining is use of a suboptimal tokens/param ratio. The effect is not that large, rule of thumb is that a compute multiplier penalty is given by a degree of overtraining raised to the power 1/3. So 30x overtraining (using 600 tokens/param instead of 20 tokens/param) results in the same penalty as training a compute optimal model with 3x less compute, and 10x overtraining (or undertraining) corresponds to using 2x less compute (which can be compensated by using 2x more compute instead, in order to maintain the same performance).
This curiously suggests that original GPT-4 was also undertrained, similarly to GPT-3. Rumored compute is 2e25 FLOPs, and rumored architecture is 1.8T total parameter MoE with 2:16 sparsity, so 220B params for active experts, and say another 40B for non-expert params, for the total of 260B. This gives 13T tokens or 50 tokens/param. If the dataset has Llama-3's 37 tokens/param optimal for a dense model at 2e25 FLOPs, then with 1:8 sparsity the optimal ratio would be 110 tokens/param, so at 50 tokens/param it's undertrained about 2x. The effect of this is losing 1.3x in effective compute, not a whole lot but more than nothing.
Replies from: harsimony↑ comment by harsimony · 2025-02-05T22:44:13.389Z · LW(p) · GW(p)
Wonderful to get more numbers on this!
These examples seem to contradict note 2 where D/N falls for larger C. Now I'm not sure what the trend should be.
It feels like you could derive a rule of thumb based on the loss and the entropy of the dataset e.g. "If my model starts at a loss of 4 bits/token and the asymptote is 2 bits/token, I need X tokens of data to fully specify a model with Y bits stored in the parameters."
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2025-02-05T23:06:13.412Z · LW(p) · GW(p)
For scaling to larger training systems, the trend is probably increasing, since larger datasets have lower quality, and soon repetition in training will become necessary, lowering quality per trained-on token. Also, MoE is a large compute multiplier (3x-6x, Figure 11 in the above MoE scaling paper), it's not going to be ignored if at all possible. There are other studies that show a decreasing trend, but this probably won't hold up in practice as we get to 250T and then 750T tokens [LW · GW] within a few years even for a dense model.
For 1:32 MoE at 5e28 FLOPs (5 GW $150bn training systems of 2028), we get maybe 700 tokens/param optimal (counting effect of sparsity, effect of repetition, and effect of more compute), so that's 3.5T active and 110T total params trained for 2.5e15 tokens (maybe 80T tokens repeated 30 times). Not sure if this kind of total params can be made to work.