Whirlwind Tour of Chain of Thought Literature Relevant to Automating Alignment Research.
post by sevdeawesome · 2024-07-01T05:50:49.498Z · LW · GW · 0 commentsContents
Glossary
Hypotheses:
Improving oversight over automated alignment researchers should involve monitoring intermediate generation, not just internals
Consider a different perspective for the two worlds:
Other Motivations for this post
Literature Review:
Can LLMs reason without CoT by Owain Evans [11].
Reversal Curse:
[source 10]
Auto-Regressive Next-Token Predictors are Universal Learners
source 18
Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective
source 19
The Expressive Power of Transformers with Chain of Thought
source 16
Why think step by step? Reasoning emerges from the locality of experience
Data Distributional Properties Drive Emergent In-Context Learning in Transformers
source 21
STaR: Bootstrapping Reasoning With Reasoning
source 22
Faithfulness of CoT
References
Appendix
What is Chain of Thought?
Capabilities improvements at inference: tools like chain of thought improve capabilities without any training, and these tools can be improved
Program of Thought
Math Results from Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective
None
No comments
This post is inspired by a series of comments by Bogdan: initial comment [LW(p) · GW(p)] follow-up 1 [LW(p) · GW(p)] follow-up 2 [LW(p) · GW(p)] the goal of this post is to summarize the relevant literature and expand on these ideas.
Comment 1: “There will likely still be incentives to make architectures more parallelizable (for training efficiency) and parallelizable architectures will probably be not-that-expressive in a single forward pass (see The Parallelism Tradeoff: Limitations of Log-Precision Transformers). CoT is known to increase the expressivity of Transformers, and the longer the CoT, the greater the gains (see The Expressive Power of Transformers with Chain of Thought). In principle, even a linear auto-regressive next-token predictor is Turing-complete, if you have fine-grained enough CoT data to train it on, and you can probably tradeoff between length (CoT supervision) complexity and single-pass computational complexity (see Auto-Regressive Next-Token Predictors are Universal Learners). We also see empirically that CoT and e.g. tools (often similarly interpretable) provide extra-training-compute-equivalent gains (see AI capabilities can be significantly improved without expensive retraining). And recent empirical results (e.g. Orca, Phi, Large Language Models as Tool Makers) suggest you can also use larger LMs to generate synthetic CoT-data / tools to train smaller LMs on.
This all suggests to me it should be quite likely possible (especially with a large, dedicated effort) to get to something like a ~human-level automated alignment researcher with a relatively weak forward pass.
For an additional intuition why I expect this to be possible, I can conceive of humans who would both make great alignment researchers while doing ~all of their (conscious) thinking in speech-like inner monologue and would also be terrible schemers if they tried to scheme without using any scheming-relevant inner monologue; e.g. scheming/deception probably requires more deliberate effort for some people on the ASD spectrum.”
Comment 2: “There are also theoretical results for why CoT shouldn't just help with one-forward-pass expressivity, but also with learning. E.g. the result in Auto-Regressive Next-Token Predictors are Universal Learners is about learning; similarly for Sub-Task Decomposition Enables Learning in Sequence to Sequence Tasks, Why Can Large Language Models Generate Correct Chain-of-Thoughts?, Why think step by step? Reasoning emerges from the locality of experience.
The learning aspect could be strategically crucial with respect to what the first transformatively-useful AIs should look like [LW(p) · GW(p)]; also see e.g. discussion here [LW(p) · GW(p)] and here [LW(p) · GW(p)]. In the sense that this should add further reasons to think the first such AIs should probably (differentially) benefit from learning from data using intermediate outputs like CoT; or at least have a pretraining-like phase involving such intermediate outputs, even if this might be later distilled or modified some other way - e.g. replaced with [less transparent] recurrence.”
Glossary
- Chain of thought (CoT): thinking via intermediate reasoning, introduced by Wei et al. (2022) [1]
- Type one tasks: tasks that don’t require multi-step reasoning. Examples: sentiment analysis, language detection, speech tagging
- Type two tasks: tasks requiring multiple steps of reasoning and information from different sources, often involving strategic problem solving or logical deduction. Examples include mathematical word problems, logical reasoning, scientific reasoning.
- Scheming: refers to faking alignment to achieve desired outcomes, similar to politicians who pretend to care about policy issues to be elected. See Ajeya Cotra’s post on this [2] for more information.
- Deceptive alignment [3] and alignment faking: I use these synonymously to “scheming”. Deceptive alignment is when a non-aligned AI presents itself as aligned, presumably in power-seeking or to avoid being shut down. This is inherently concerning because a deceptively aligned AI is indistinguishable from an aligned AI based solely on their actions.
- Self consistency: a method for improving chain of thought involves sampling various potential reasoning pathways to improve decision-making accuracy. This was introduced in Wang et al. (2023) [4]
- Burstiness: a property of data where certain words appear in clusters in specific training documents e.g. “creme fraiche” appears much more frequently in documents related to cooking than documents related to programming. [5]
- length complexity: measures the number of intermediate tokens in COT sequence required to approx some target function, introduced in Malach (2023) [6].
- In context: inside of the context window / prompt
- In-context learning (ICL): performing a task solely relying on input-output examples, without parameter optimization. A teammate of mine, Alfie Lamerton wrote a post [7] on the theory for why this happens, why it works, and why it is relevant to automating alignment. In context learning is rapid, only requiring a few examples (few-shot), doesn’t use any gradient descent or parameter updates.
- Out of context reasoning: reasoning / predictions that don't involve CoT. This definition is from Berglund et al. [8]. Out of context reasoning requires lots of examples and lots of training. Reasoning with information learned out of context seems worse, i.e. this information suffers from the Reversal Curse (section below)
- Direct prediction: prediction without auto-regressive generation. Example: a single forward pass from a decoder only transformer
- Faithfulness: when the stated reasoning for arriving at a conclusion is not the true reason for reaching that conclusion
- Meta-learning: learning without the need to update weights
- Meta-training: when you adjust the data to make the data better for ICL
Hypotheses:
Improving oversight over automated alignment researchers should involve monitoring intermediate generation, not just internals
Consider two worlds:
- In the first scenario, models become good at out of context reasoning and do not need CoT to generate new knowledge or explanations
- We will need interpretability techniques to evaluate scheminess
- Models can create new knowledge and explanations. Reasoning can be “hidden” in activations.
- In the second scenario, models need an inner monologue to generate new knowledge
- We have a decisive strategic control advantage for monitoring for “alignment faking” in automated researchers.
- Automated researchers will be forced to do “out loud” reasoning to solve certain problems. We can explain why they arrived at a decision.
- This case would be great for interpretability and control. Monitoring will be easier.
- Control based safety guarantees of automated researchers seem tractable if automated researchers are bottlenecked by reasoning when deciding what to do.
A lot is written about deceptive alignment [3] and whether we should expect it by default. The purpose of this essay is to discuss which direction chain of thought should update us.
Consider a different perspective for the two worlds:
- Models can think and can hide an internal monologue involving reasoning within weights
- This may be a deeper philosophical question here. When we think in using language, are the individual words the direct output of a cognitive stream (like a residual stream), or are they a byproduct of neural activity along for the ride during a forward pass?
- The relevant question I’m interested in is whether we should expect this to be the case with the AI's we build.
- When solving problems requiring reasoning, models will state “out-loud” the priors that their actions condition on
- We will be able to see what evidence and information the model is conditioning on in decision-making.
- The evidence (see the Faithfulness section) shows that this is the case for current models (on problems requiring reasoning), but this doesn’t necessarily imply it’ll hold up in the limit.
- Does the policy of “just say what knowledge and reasoning you are doing and condition on it” hold in the limit, or should we expect “schemy” reasoning in the limit as we train larger and larger transformers?
- It is unclear whether this question has been answered
Intermediate reasoning leads to massive expressivity gains. AGI is possible with next token prediction: There are inherent limitations of LLMs in direct prediction. Certain types of math and reasoning problems are not solvable with direct prediction. By contrast, intermediate generation massively improves the expressivity of transformers: the scope of problems a transformer can solve. The literature has a number of recent results formalizing the expressivity gains from CoT. Even though you are not changing any circuits or the model that is running, intermediate generation can allow transformers to simulate a deeper circuit where new tokens depend on previous ones, and this dependency can loop, expanding expressivity.
Automated alignment researchers will use intermediate reasoning like CoT: Research involves a lot of reasoning. Multi-step reasoning is likely to be a part of automated alignment researchers.
Novel idea creation will naturally involve intermediate reasoning: Intermediate reasoning will be used to generate new knowledge (novel insights not inside the training data).
CoT improves learning, and in-context learning is more powerful than training: Learning is easier with reasoning. I believe the literature points to the hypothesis that learning out of context stores information similar to “floating beliefs” (consider [source 9]). An anecdote on learning via reasoning from studying physics: I can read a chapter on electromagnetism 3 times over and absorb information. However, to best prepare for a test, I solve the related homework problems and connect facts from the textbook to solve a problem. This is a better learning algorithm than just reading.
Recent data shows that chain of thought doesn’t just help with reasoning related problems, but also with learning. In-context information (information in the context-window) is far more salient than facts learned during training. Also, information learned during training is more difficult to use in reasoning than in-context information. Thus, I propose that information present in-context has much more “plasticity”. The reversal curse [10] is evidence for this. In one of their experiments, when a model is trained (learning out-of-context) on “Mary Lee Pfieffer is Tom Cruises mother”, it can answer “who is Tom Cruises mother” but not “who is Mary Lee Pfieffer’s son?”. However, if the information is in the prompt (in-context learning) the model has no trouble generalizing the mother-son relationship and answering both questions.
Learning out of context fails to scale. Owain Evans, an author of the “Reversal curse” paper presents this rationale in [source 11] and [source 8]. They show that in-context reasoning scales with model size better than out of context reasoning.
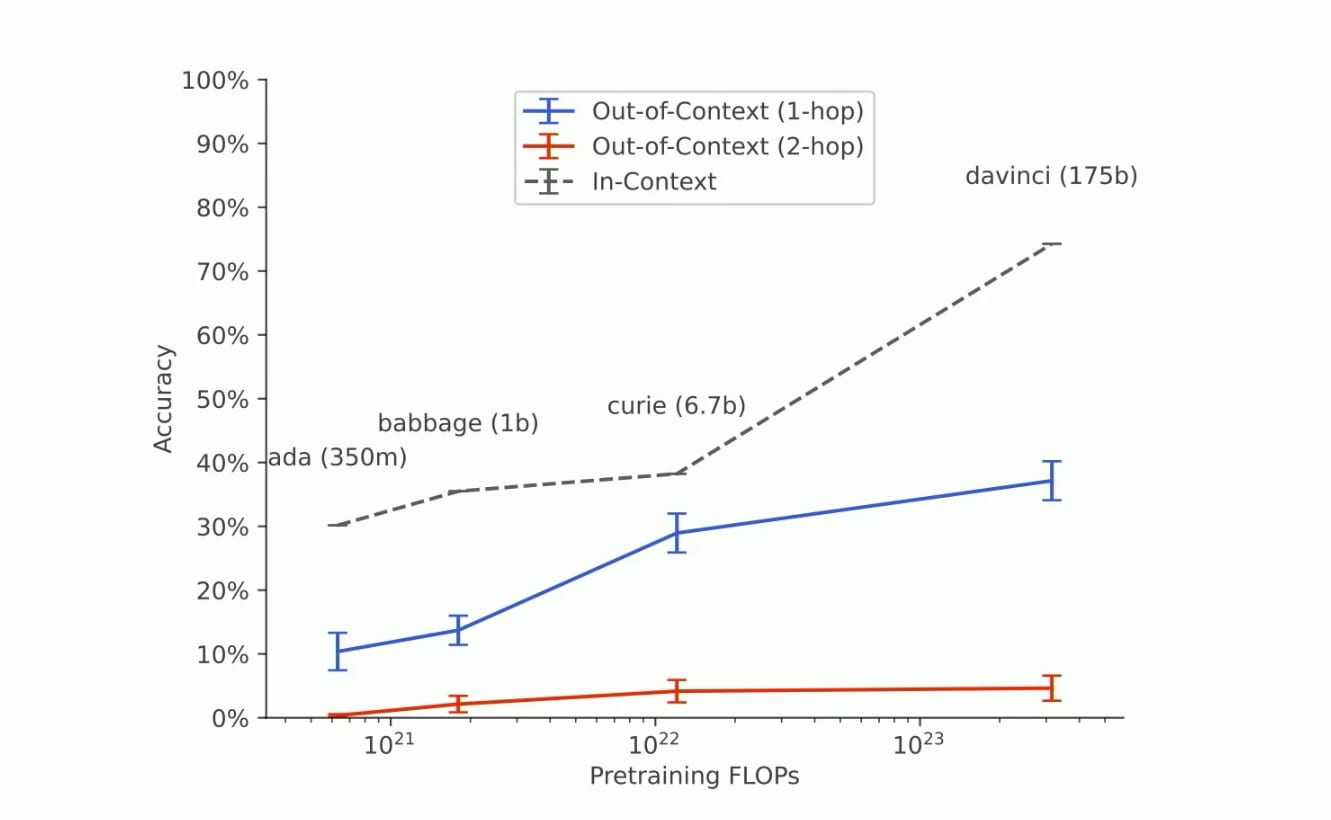
Figure 1: scaling rules of out-of-context learning [source 8]
In this context, two-hop refers to problems requiring two inferential steps. For example, inferring A from B and B from C (A -> B, B -> C) requires one inferential hop.
Concrete example: suppose you have the following text to include either in-context or out-of-context (in training documents):
P1: The key is in the bag
P2: Alice has the bag
P3: Alice is at the lake
(example from source 12)
Answering “Where is the key” involves one inferential hop, namely “Alice has the key” linking P1 and P2. Connecting propositions, even simple examples like this fails to scale when the propositions are learned out of context.
In my opinion, this is a valuable insight into neural networks. Your brain is not flooded with every single memory and experience you’ve ever had every moment. The things you’ve been thinking about, writing down and reasoning about are more salient and available for problem solving. While other memories can be accessed, they function more like points in a cloud of beliefs, less readily available for immediate reasoning and problem-solving.
There has been recent research focused on improving ICL. Two recurring strategies for learning:
- Improving ICL: strategies like tree of thought, self consistency, etc.
- Adjusting training data to improve in-context learning is called “meta training”
- Learning to Reason with Self Notes [12] teaches models to exit context to do intermediate reasoning while answering, and achieves performance gains over CoT.
- The Textbooks Are All You Need [13] paper achieves incredible results with small models just by rearranging data, increasing burstiness and document locality
- There is a large section on this in the appendix section
- In weights learning: improving representations in a world model
- Improving generalization: dropout, regularization, or hyperparameter tuning, optimization techniques, etc.
- Augmenting and rearranging data: Microsoft achieved considerably better models by training “textbook” style by organizing data (like code) into documents that would make more sense to a human [13].
Curriculum learning: teaching models concepts in order of complexity. E.g. training on first grade level math before 10th grade level math. Results in curriculum learning so far have been relatively lackluster [14].
Autoregressive language models will need to output intermediate results for problems requiring reasoning: If true, we have a decisive strategic advantage in interpretability and monitoring for deceptive alignment. Certain problems require reasoning steps. As humans we can feed a thought chain into an internal monologue instead of writing it down or saying it out loud. On the other hand auto-regressive transformers’ internal monologue is their thought chain, and they will have trouble hiding reasoning from us because it is much more difficult to reason within weights as it is to reason within a context window.
Strong oversight: Expanding on the last point: There are empirical results for controlling or aligning LLM’s, not many results on how to align superintelligence. This is promising for alignment given OpenAI’s plan to use near-human level AI’s to do research on alignment [15]. Intuitively, it may be possible to achieve safety for autoregressive LLM’s because their expressive power is fundamentally limited by the length of their reasoning chains as discussed in Expressive Power of Transformers [16].
Other Motivations for this post
- “One of the main limitations is that the architecture does not allow for an ‘inner monologue’ or scratchpad beyond it’s internal representation, that could enable it to perform multi-step computations or store intermediate results” - Sebastian Bubeck, 2023
- Variable computation problem: some problems require more thinking, reasoning, steps and computation. A human knows that it will take longer to solve fermats last theorem than solving “12 + 3=?”
- In-context learning is a much more powerful form of learning than gradient descent
- Researching the theoretical foundations of CoT, ICL, and activation steering are interesting because it helps us understand the type of capabilities models can exhibit.
Literature Review:
Can LLMs reason without CoT by Owain Evans [11].
- Owain defines in-context reasoning as reasoning within the context window.
- Out of context reasoning refers to the model being able to access premises but through training instead of prompting.

Figure 2: In context reasoning vs out of context reasoning [11]
- Studies, such as the Reversal Curse, show that models struggle with reasoning on premises learned out-of-context.
- Research indicates that out-of-context reasoning does not significantly improve with scale, as demonstrated by the graph in section 1. I believe this finding is crucial for understanding the limitations of current models.
Reversal Curse:
- Claims that if a model is trained on a sentence of the form “A is B”, it will not automatically generalize to the reverse direction “B is A”’
- Example: a model tuned on data including “Daphne Barrington is the director of “A Journey Through Time” can answer “who is Daphne Barrington” but not “Who directed A Journey Through Time”
- The Reversal Curse only occurs when the information is learned out of context during training. When the information is learned in context, the model can generalize and infer the relationship in both directions without difficulty.
- This paper received a lot of criticism including many claiming the “reversal curse” is not real [17].
- After investigating the criticism [17], I believe that Andrew Mayne's arguments against the Reversal Curse are not convincing
- In my opinion the article fails to reproduce the most important experiments. Specifically, experiments involving fictitious characters which are more likely to avoid pre-training leakage. We shouldn’t rule out the possibility that the model's training data included both forward and reversed paraphrasings of realistic text data, such as "Olaf Scholz was the ninth Chancellor of Germany."
Auto-Regressive Next-Token Predictors are Universal Learners
Twitter thread: https://twitter.com/EranMalach/status/1704140257044611314
- Auto-regressive transformers are Turing complete in the limit!
- The main point of this paper is that any computer program or intelligent agent that can be simulated by a computer, can be learned, given the right dataset, by a simple next-token predictor. The author formalizes this.
- Claims that language models' logical reasoning abilities are due to auto-regressive learning, not architecture. Even simple models with next-token prediction can handle complex tasks when equipped with CoT.
- The paper introduces the concept of "length complexity," which measures the number of intermediate tokens in a chain-of-thought sequence required to approximate a target function.
- Length complexity impacts learning parities and can be traded off with other complexities.
Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective
The goal of this paper is to answer the following:
- Are there inherent limitations of LLMs in directly solving math/reasoning tasks (no CoT)?
- What is the essential reason behind the success of CoT boosting performance in LLMs?
Terms:
- Log precision transformer: a transformer whose internal neurons can only store floating point numbers with a bit precision of O(log(n)), where n is the maximum length of the input sequence.
- Example: the precision of the internal neurons is much smaller than the context-window. GPT-2 has 16 bit precision vs a maximum sequence length of 2048
- The paper focuses on two most basic math problems: arithmetic and equations, which are elementary building blocks in most math problems. It explores whether LLMs can solve these problems directly and/or with CoT.
Central results (the appendix includes more math):
- The authors claim that autoregressive generation can increase the “effective depth” of a transformer proportional to the number of intermediate steps.
- LLMs with CoT can emulate Dynamic Programming - a powerful decision making framework by computing the entire Dynamic Programming reasoning chain.
- The paper proves that log precision transformers can be implemented via a shallow circuit, and their expressive power is upper-bounded by the circuit complexity TC-0. The two math problems investigated in the paper are lower-bounded by the complexity class NC-1.
- “By using circuit complexity theory, [the authors] give impossibility results showing that bounded-depth Transformers are unable to directly produce correct answers for basic arithmetic/equation tasks unless the model size grows super-polynomially with respect to the input length. In contrast, [they] prove that autoregressive Transformers of constant size suffice to solve both tasks by generating CoT derivations using a commonly used math language format”
- CoT bypasses these impossibility results, authors say via increasing effective graph of the circuits, yielding an expressive power far greater than TC-0.
Other noteworthy results that affected how I think about transformers:
- One attention head can simulate two basic operations: copy and reduction. These can be seen as loading memory.
- Multi-head attention can perform multiple copy or reduction operations in parallel
- The MLP can perform multiplication, linear transformation, conditional selection and simulate a lookup table
- By combining these basic operations, Transformers can solve both arithmetic and equation tasks, further suggesting their ability to simulate any Turing machine in the limit, known as Turing completeness
The Expressive Power of Transformers with Chain of Thought
Twitter thread: https://twitter.com/lambdaviking/status/1713945714684756019
- This paper formalizes the expressive power of transformers with circuit complexity, examining the classes of functions transformers can approximate with and without chain of thought.
- With no intermediate steps (CoT), transformer decoders can only solve problems that fall within the circuit complexity class of TC-0, such as solving linear equalities.
- Intermediate output, such as chain of thought or a scratchpad, fundamentally extends the computational power of transformer decoders.
- As an example, a single forward pass cannot encode an XOR gate, but using chain of thought a transformer can encode XOR easily.
- Another example: log(n) chain-of-thought steps can solve some, but not all, algorithms requiring log(n) steps
- Transformer decoders can simulate t Turing machine steps with t chain-of-thought steps.
Why think step by step? Reasoning emerges from the locality of experience
Author on a podcast: https://www.youtube.com/watch?v=MRwLhpqkSUM
The results of this paper influenced how I think about chain of thought for alignment in two ways. First, they suggest that chain-of-thought reasoning is useful for language models because direct prediction is inaccurate for some inferences because the relevant variables are rarely seen together in training. Second, they demonstrate chain-of-thought reasoning improves estimation by incrementally chaining local statistical dependencies that are observed frequently in training.
This paper is highly relevant to the Data Distributional Properties Drive Emergent In-Context Learning in Transformers paper discussed next. I find this paper interesting because the goal is to find what properties of data make chain of thought possible. The effectiveness of reasoning is not immediately obvious; while it doesn’t involve creating any new knowledge, connecting ideas via intermediate generation can improve performance. Their hypothesis is that reasoning is useful when training data has local structure and topics that are similar are clustered together in the dataset. During training, a model isn’t learning about math, physics, biology, sociology and psychology in the same backwards pass.
The important finding of this paper is that the effectiveness of chain of thought comes from the structure of data. Also, this paper proves that reasoning through intermediate variables reduces bias in an autoregressive density estimator trained on local samples from a chain-structured probabilistic model. They coin the term “reasoning gap”: the gap between direct prediction and prediction through reasoning. They show that “training language models on datasets consisting of local neighborhoods with strong dependencies and performing chain-of-thought reasoning at inference time can be more data-efficient than training on more complete datasets.”
The author provides a non-technical example: asking the question “what is the climate in the capital of France?” Suppose our dataset documents about France never explicitly mentions the climate in the “capital of France”, but it does state that Paris is the capital of France. The wikipedia page for Paris, from a separate document in the training data, mentions that Paris has an oceanic climate. By first establishing that Paris is the capital of France, the next token estimator reduces bias.
Generic conditional probability example:
To illustrate, we may know the value of some variable A and want to know about another variable C, so we try to estimate P(C|A). However, if we need to estimate probabilities using observed samples from joint distributions and we have not often seen A and C together, we would struggle to estimate P(C|A) directly. Instead, we might estimate it by reasoning through intermediate variables. If conditioning on an intermediate variable B renders A and C independent of each other, we can compute the conditional probability by marginalizing over B, using the fact that P(C|A) = P(B) * P(C|B) * P(B|A).
Data Distributional Properties Drive Emergent In-Context Learning in Transformers
The question this paper aims to answer is “how do large transformer models achieve emergent in context learning?” Their hypothesis is that the distributions of naturalistic data have special properties that enable emergent in-context learning
TLDR: burstiness makes in context learning work.
- Natural language is bursty: certain words appear in “bursts” in documents, they are highly frequent in some training data, but rare in most documents. Consider names, technical jargon and local slang which appear very frequently in certain types of documents, and very rarely in others. Words like “Severus” aren’t evenly distributed in training documents, they are much more likely to appear in Harry Potter books. Knowing this should help design datasets.
- Their experimental findings suggest that in context learning is improved by increasing burstiness in the training data. However, more burstiness leads to worse in-weights learning.
- ICL is enabled by larger numbers of training classes, i.e. a large vocabulary. However, once again there exists a tradeoff between in-context learning and out of context learning. Models either do well on one or the other, the authors present a sweet spot for this tradeoff.
STaR: Bootstrapping Reasoning With Reasoning
Video presentation: https://slideslive.com/38991144
I wanted to include this paper because it seems valuable in the discussion of how to improve in-context reasoning.
Models fine-tuned with reasoning outperform language models trained to directly answer questions.Rationales when answering questions is clearly helpful in training data, this paper investigates how to create those rationales to improve training data.
The authors introduce a model that can iteratively improve its performance on reasoning tasks beyond its initial few-shot prompting. They do this by taking the solutions that the model comes up with to a dataset, then have it come up with rationales. If the initial answer is correct, they fine tune the model on the rationales.
Takeaways:
- This approach improves performance on MATH benchmarks and arithmetic tasks.
- Potential failure modes: the self taught reasoner never gets a feedback signal from problems that it gets wrong and becomes saturated on correct answers
- To get around this, they give models hints to get the correct answer but fine-tune as if the model never saw this hint
Faithfulness of CoT
Relevant literature: sources 2 & 23-29
Why this is relevant:
- CoT is highly interpretable, more so than current interpretability techniques. Faithful explanations for a model arriving at a conclusion would be highly valuable for safety. If the reasoning given in CoT sequences is faithful and honest, sharing the actual reasons for an AI selecting an action, this would be promising for controlling automated alignment researchers.
A couple of the failure modes of using thought chains for interpretability include:
- Post-hoc reasoning: a certain conclusion is already guaranteed and the chain of thought just serves to rationalize [? · GW]the conclusion.
- Scheming hidden in the gradients. More computational time spent (with chain of thought) could allow for computing unfaithful reasoning.
- We can test if language models are using the extra computational time in CoT reasoning to scheme by adding filler tokens (like a bunch of hyphens at the end of a prompt)
- Anthropic conducted this experiment and found that present LLMs are unlikely to be doing this.
- Encoding reasoning: the model may use a hidden language in intermediate tokens to use CoT as an outlet to scheme
If LLM’s answer questions using CoT, can we expect their reasoning to be faithful? In other words, the actual reasons for them arriving at the answer. Anthropic measuring faithfulness in chain of thought reasoning suggests: NO!
The authors of Lets Think Dot by Dot [29] were able to train LLM’s to do intermediate reasoning within gradients while outputting filler tokens like “...”. This demonstrates that it is possible for models to perform reasoning via filler tokens or encoded reasoning. However, this is hard to achieve. They created this by training models to use filler tokens in parallel to reasoning chains. It is fairly clear that this is not the default outcome of training present-day sized transformers the way we currently train them.
In summary, the Anthropic paper shows that even with CoT, models engage in post-hoc decision making and their thought chain is not necessarily the reason they arrived at their action. For example, in one experiment they bias the model towards answering “A” by giving a large number of examples (few-shot) in the prompt. Then, while eliciting CoT in an attempt to interpret why the model arrives at its decision, the model essentially never notices its bias towards A. Instead, the models continue to provide rationale for choosing “A”, regardless of “A” being correct or incorrect.
There is disagreement over the likelihood of deceptive alignment. Evan Hubinginger says it is almost certain [32] while others say it is less than 1% likely by default [33]. Regardless of the likelihood of naturally emerging, scheming is concerning because deceptively aligned AIs are behaviorally indistinguishable from aligned AIs. The results from the literature in this section is mixed, but I believe we should update ourselves away from thinking that interpreting CoT alone is sufficient to catch scheming AI’s.
References
- Wei et. al (2022). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. https://arxiv.org/abs/2201.11903
- Ajeya Cotra. “Why AI Alignment Could be Hard by Ajeya Cotra” https://www.cold-takes.com/why-ai-alignment-could-be-hard-with-modern-deep-learning/
- Definition of deceptive alignment: https://www.lesswrong.com/tag/deceptive-alignment [? · GW]
- Wang et al (2022), Self-Consistency Improves Chain of Thought Reasoning in Language Models. https://arxiv.org/abs/2203.11171
- Chan et al. (2022) Data Distributional Properties Drive Emergent In-Context Learning in Transformers https://arxiv.org/pdf/2205.05055
- Malach (2023) Auto-Regressive Next-Token Predictors are Universal Learners https://arxiv.org/abs/2309.06979
- Alfie Lamerton. A Review of In-Context Learning Hypotheses for Automated AI Alignment Research https://www.lesswrong.com/posts/GPcwP8pgyPFPwvi2h/a-review-of-in-context-learning-hypotheses-for-automated-ai?utm_campaign=post_share&utm_source=link [LW · GW]
- Berglund et al. (2023) “Taken out of context: On measuring situational awareness in LLMs” https://arxiv.org/abs/2309.00667
- Eliezer Yudkowsky (2007). Making Beliefs Pay Rent (https://www.lesswrong.com/posts/a7n8GdKiAZRX86T5A/making-beliefs-pay-rent-in-anticipated-experiences [LW · GW])
- Evans et al. (2023) The Reversal Curse (https://arxiv.org/abs/2309.12288)
- Owain Evans (2023) Can LLMs Reason Without Chain of Thought https://slideslive.com/39015178/can-llms-reason-without-chainofthought?ref=search-presentations
- Lanchantin et al. (2023) “Learning to Reason and Memorize with Self Notes “ https://arxiv.org/abs/2305.00833
- Gunasekar et al. (2023) “Textbooks Are All You Need” https://arxiv.org/abs/2306.11644
- Campos (2021) Curriculum Learning for Language Modeling https://arxiv.org/abs/2108.02170
- OpenAI. Introducing Superalignment https://openai.com/superalignment/
- William Merril, Ashish Sabharwal. “The Expressive Power of Transformers with Chain of Thought” https://arxiv.org/abs/2310.07923
- Andrew Mayne. “Is the Reversal Curse Real?” https://andrewmayne.com/2023/11/14/is-the-reversal-curse-real/
- Malach. (2024) “Auto-Regressive Next-Token Predictors are Universal Learners. https://arxiv.org/pdf/2309.06979
- Feng et al. (2023) “Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective” https://arxiv.org/pdf/2309.06979
- Prystawski et al. (2023) “Why think step by step? Reasoning emerges from the locality of experience” https://arxiv.org/abs/2304.03843
- Chan et al. (2022) “Data Distributional Properties Drive Emergent In-Context Learning in Transformers” https://arxiv.org/abs/2205.05055
- Zelikman et al. (2022) “STaR: Bootstrapping Reasoning With Reasoning” https://arxiv.org/abs/2203.14465
- Chen et al. (2023) “Measuring Faithfulness in Chain of Thought Reasoning https://www.anthropic.com/news/measuring-faithfulness-in-chain-of-thought-reasoning
- Turpin et al. “Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting” https://arxiv.org/pdf/2305.04388
- Miles. Lesswrong: Unfaithful explanations in chain of thought prompting https://www.lesswrong.com/posts/6eKL9wDqeiELbKPDj/unfaithful-explanations-in-chain-of-thought-prompting [LW · GW]
- Tamera. Lesswrong: Externalized reasoning oversight: a research direction for language model alignment https://www.lesswrong.com/posts/FRRb6Gqem8k69ocbi/externalized-reasoning-oversight-a-research-direction-for [LW · GW]
- Accidentally teaching AI models to deceive us: Schemers, Saints and Sycophants [EA · GW]
- Chua et al. (2024) “Bias-Augmented Consistency Training Reduces Biased Reasoning in Chain-of-Thought” https://arxiv.org/abs/2403.05518
- Pfao et al. “Lets think Dot by Dot” https://arxiv.org/abs/2404.15758 (twitter thread)
- Wen et al. (2024) “RNNs are not Transformers (Yet): The Key Bottleneck on In-context Retrieval” https://arxiv.org/abs/2402.18510
- Li et al. (2024) “Chain of Thought Empowers Transformers to Solve Inherently Serial Problems” https://arxiv.org/pdf/2402.12875
- Evan Hubinger (2022). “How likely is deceptive alignment?” https://www.alignmentforum.org/posts/A9NxPTwbw6r6Awuwt/how-likely-is-deceptive-alignment [AF · GW]
- DavidW “Deceptive Alignment is <1% likely by default” https://forum.effectivealtruism.org/posts/4MTwLjzPeaNyXomnx/deceptive-alignment-is-less-than-1-likely-by-default#:~:text=In%20this%20post%2C%20I%20argue,to%20pursue%20its%20proxy%20goals [EA · GW].
- Tutunov et al (2023) “Why Cant Language Models Generate Correct Chains of Thought? https://arxiv.org/abs/2310.13571
- Zhang et al (2023) “Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents” https://arxiv.org/abs/2311.11797
- “AI Capabilities Can Be Significantly Improved Without Expensive Retraining” https://epochai.org/blog/ai-capabilities-can-be-significantly-improved-without-expensive-retraining
- Bogdan Comment [LW(p) · GW(p)] follow-up 1 [LW(p) · GW(p)] follow-up 2 [LW(p) · GW(p)]
- https://www.analog.com/en/resources/glossary/xor-gate.html
- Yao et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models”
Appendix
What is Chain of Thought?
Tasks like math or reasoning problems are best solved using task decomposition, i.e. breaking a problem into small intermediate steps that gradually nudge you towards an answer. As an analogy: if you were asked what you ate for breakfast this morning, you might be able to quickly respond with “oatmeal!”, but if you are asked to divide 1377 by 51 might take you a little longer, would be easier with a scratchpad and pen, and would require several “thoughts” (intermediate steps).
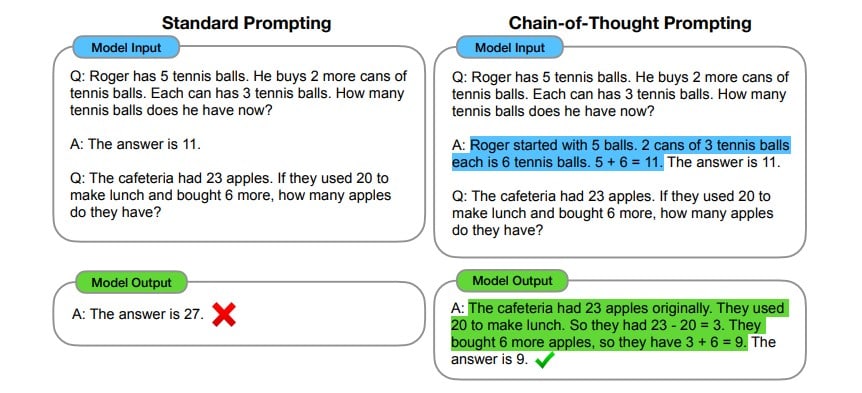
Figure 3: Chain of thought examples [1]
Kojima et al [1] introduced zero-shot CoT. Here shot means how many example problems one solves in a prompt, i.e. the prompt “1+1=2, 4+5=” is single-shot because it gives one example of addition before asking the LLM. The authors elicit CoT simply by adding “let's think step by step” to a prompt. This trick improves LLM performance, especially on mathematics and reasoning related questions. In a CoT, each element in the chain represents a thought. The sequence of thoughts should be coherent and lead to the expected answer. When you divide 1377 by 51 you could blurt out a guess (rough estimate). However, by thinking step by step you could first solve how many times 51 goes into 137, then take the remainder and continuing your long division intermediate steps gradually nudges you towards a correct answer.
The next section will cover how large language model’s (LLM) capabilities can be improved at inference, and how chain of thought style reasoning can be improved.
In a single forward pass, a transformer isn’t capable of encoding an XOR gate (it might be useful to think about why this is), but it can encode AND, OR, or NOT gates. However, adding a chain of thoughts allows solving XOR.
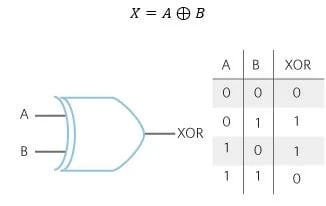
Figure 2. XOR Gate [38]
Capabilities improvements at inference: tools like chain of thought improve capabilities without any training, and these tools can be improved
LLM’s can be significantly improved without retraining [36] With techniques like scaffolding, both the number of problems LLM’s can solve grows and the robustness of the solutions improves. These techniques do not require any training or fine tuning, but increase inference costs. There is a tradeoff between training spending and inference spending. However, training is a fixed cost whereas capabilities enhancements at inference scales recurring costs.
Table copied from Epoch:
| Category | Description | Example |
| Tool use | Teaching an AI system to use new tools | WebGPT, Toolformer |
| Prompting | Changing the text-based input to the model to steer its behavior and reasoning. | Chain of thought |
| Scaffolding | Programs that structure the model's reasoning and the flow of information between different copies of the model | AutoGPT, LATS |
| Solution choice | Techniques for generating and then choosing between multiple candidate solutions to a problem. | AlphaCode, training a model to verify generated answers |
| Data | Techniques for generating more, higher-quality data for fine-tuning. | Minerva, fine-tuning on self-generated data |
Chain of thought as a tool for improving language model accuracy can be itself improved.
The Igniting Language Reasoning [35] is a great source summarizing some of the improvements to CoT and language models. They break improvements to CoT into three categories: CoT formulation, reasoning aggregation and CoT verification.
CoT Formulation:
There are ways of formulating intermediate reasoning that outperform Kojima et. al’s original chain of thought results, especially in certain domains.
Various formulations of chain of thought have improved results across certain problems:
| CoT Formulation | Program of Thought Chen et al 2022 | Generate both text and programming language statements, executed on an interpreter |
| Ziqi & Lu (2023) | Table of thought | Adopts a table filling approach to chain of thought. In Tab0Cot instructions of: Is manually designed to have LLM’s generate a table while conducting their reasoning |
| Yao et al | Tree of thought | Breaks CoT into units and formulates them into tree structure. This allows LLM’s to explore coherent thought units and consider different options before making their decisions. ToT is able to look ahead to determine what to do next, or trace-back to correct history decisions. This has shown impressive results in non-trivial planning or search processes. |
| Besta et Al 2023 | Graph of Thought | Built on ToT, models the thought generation process of language models as a graph. Too complex to fully explain here. Has shown a lot of promise in tasks such as sorting, set operations, keyword counting and document merging |
| Lee & Kim 2023 | Recursion of thought | Training language models to output special tokens such as GO, THINK or STOP, initiating certain contexts. This has shown promise with logical problems with very large context sizes. |
Ensembling is a popular technique in machine learning across domains. Ensembling involves multiple models making predictions and then taking a majority vote.
Self consistency and reasoning aggregation were also explored in igniting language model reasoning. Wang et al 2023 [4] introduced a decoding strategy called self consistency. This first prompts the language model to follow CoT, then samples a diverse set of reasoning pathways and takes the final answer to be the one which wins a majority vote. The authors explore:
- Self consistency: ensembling based on sampling multiple language model outputs
- Prompt ordering ensembling: ensembling based on changing the ordering of examples
- Input-rationale ensembling: ensembling based on different types of reasoning in the examples
The authors find all three methods yield similar improvements. Because of the computational inefficiency of transformers (calculating logits at each token in the context window), reasoning aggregation could be very cheap.
Lastly, chain of thought can be improved with verificatio. It is not clear whether LLMs can perform reliable CoT verification yet. A popular intuition is that validation is easier than generation. The igniting language models reasoning paper [35] has a detailed explanation of CoT verification literature, copying from that paper, here is a brief overview:
- Wang et al (2022) proposed and proved LLM’s have self-verification abilities. After CoT reasoning, they have an LLM perform backwards verification working through reasoning steps backwards and masking early steps.
- Lightman et al (2023) explored training reward models to validate CoT’s. Using an RM supervisor has improved accuracy significantly on Dan Hendryks MATH dataset
Math Results from Towards Revealing the Mystery behind Chain of Thought: A Theoretical Perspective
Central results (in math): log precision of autoregressive transformer of constant depth can not automatically solve both problems (arithmetic and equations). In order to directly output the answers, model size will have to grow superpolynomially in the input length. Consider these two problems (equations and arithmetic) in a specific setting: all numbers are integers ranging from {0,...,p-1} where p is prime, and arithmetic operations are performed in the finite field modulo p.
- Arithmetic(n,p)> the task of evaluating arithmetic expressions (modulo p) where the input length is bounded by n
- Example: (7x5) + (6+4)
- Equation(m,p): the task of solving linear equations (modulo p) with no more than m variables
In the direct evaluation setting, they show the following theorems:
- Theorem 1: For any prime number p, integer L, and polynomial Q, there exists a problem size n such that no autoregressive Transformer with depth L and hidden dimension d ≤ Q(n) can directly solve the problem Arithmetic(n, p).
- This means that for the problem of evaluating arithmetic expressions modulo p (as described in Arithmetic(n, p)), there is always a large enough problem size n such that an autoregressive Transformer with a certain depth L and hidden dimension bounded by Q(n) cannot solve the problem directly)
- Theorem 2: Similarly, for any prime number p, integer L, and polynomial Q, there exists a problem size m such that no autoregressive Transformer with depth L and hidden dimension d ≤ Q(m) can directly solve the problem Equation(m, p).
On the contrary, in the chain of thought setting, they demonstrate the following theorems:
- Theorem 1: Fix any prime p. For any integer n > 0, there exists an autoregressive Transformer with constant hidden size d (independent of n), depth L = 5, and 5 heads in each layer that can generate the CoT solution for all inputs in Arithmetic(n, p). Moreover, all parameter values in the Transformer are bounded by O(poly(n)).
- Theorem 2: Fix any prime p. For any integer m > 0, there exists an autoregressive Transformer with constant hidden size d (independent of m), depth L = 5, and 5 heads in each layer that can generate the CoT solution for all inputs in Equation(m, p). Moreover, all parameter values in the Transformer are bounded by O(poly(m)).
0 comments
Comments sorted by top scores.