[LDSL#0] Some epistemological conundrums
post by tailcalled · 2024-08-07T19:52:55.688Z · LW · GW · 10 commentsContents
Why are people so insistent about outliers? Why isn’t factor analysis considered the main research tool? Why do people want “the” cause? Why are people dissatisfied with GWAS? What value does qualitative research provide? What’s the distinction between personality disorders and “normal” personality variation? What is autism? What is gifted child syndrome/twice-exceptionals? What’s up with psychoanalysts? Why are some ideas more “robust” than others? How can probability theory model bag-like dynamics? Why would progressivism have paradoxical effects on diversity? Why don’t people care about local validity and coherence? How does commonsense reasoning avoid the principle of explosion? What’s wrong with symptom treatment? Why does medicine have such funky qualitative reasoning? What does it mean to explain a judgement? Why do people seem to be afraid of measuring things? Why is there no greater consensus for large-scale models? Can we “rescue” the notion of objectivity? What lessons can we even learn from long-tailedness? Perception is logaritmic; doesn’t this by default solve a lot of problems? All of this may be wrong None 10 comments
This post is also available on my Substack.
When you deal with statistical science, causal inference, measurement, philosophy, rationalism, discourse, and similar, there’s some different questions that pop up, and I think I’ve discovered that there’s a shared answer behind a lot of the questions that I have been thinking about. In this post, I will briefly present the questions, and then in a followup post I will try to give my answer for them.
Why are people so insistent about outliers?
A common statistical method is to assume an outcome is due to a mixture of observed factors and unobserved factors, and then model how much of an effect the observed factors have, and attribute all remaining variation to unobserved factors. And then one makes claims about the effects of the observed factors.
But some people then pick an outlier and demand an explanation for that outlier, rather than just accepting the general statistical finding:
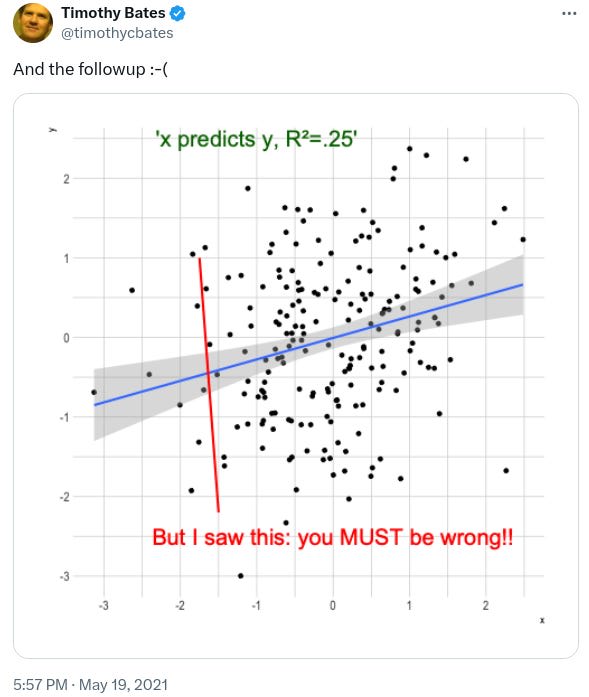
In fact, aren’t outliers almost by definition anti-informative? No model is perfect, so there’s always going to be cases we can’t model. By insisting on explaining all those rare cases, we’re basically throwing away the signal we can model.
A similar point applies to reading the news. Almost by definition, the news is about uncommon stuff like terrorist attacks, rather than common stuff like heart disease. Doesn’t reading such things invert your perception, such that you end up focusing on exactly the least relevant things?
Why isn’t factor analysis considered the main research tool?
Typically if you have a ton of variables, you can perform a factor analysis which identifies a set of variables which explain a huge chunk of variation across those variables. If you are used to performing factor analysis, this feels like a great way to get an overview over the subject matter. After all, what could be better than knowing the main dimensions of variation?
Yet a lot of people think of factor analysis as being superficial and uninformative. Often people insist that it only yields aggregates rather than causes, and while that might seem plausible at first, once you dig into it enough, you will see that usually the factors identified are actually causal, so that can’t be the real problem.
A related question is why people tend to talk in funky discrete ways when careful quantitative analysis generally finds everything to be continuous. Why do people want clusters more than they want factors? Especially since cluster models tend to be more fiddly and less robust.
Why do people want “the” cause?
There’s a big gap between how people intuitively view causal inference (often searching for “the” cause of something), versus how statistics views causal inference. The main frameworks for causal inference in statistics are Rubin’s Potential Outcomes framework and Pearl’s DAG approach, and both of these view causality as a function from inputs to outputs. In these frameworks, causality is about functional input/output relationships, and there are many different notions of causal effects, not simply one canonical “cause” of something.
Why are people dissatisfied with GWAS?
In genome-wide association searches, researchers use statistics to identify alleles that are associated with specific outcomes of interest (e.g. health, psychological characteristics, SES outcomes). They’ve been making consistent progress over time, finding tons of different genetic associations and gradually becoming able to explain more and more variance between people.
Yet GWAS is heavily criticized as “not causal”. While there are certain biases that can occur, those biases are usually found to be much smaller than seems justified by these critiques. So what gives?
What value does qualitative research provide?
Qualitative research makes use of human intuition and observation rather than mathematical models and rigid measurements. But surely ultimately human cognition grounds out to some algorithms that could be formalized. Maybe it’s just a question of humans having more prior information and doing more comprehensive observation? But in that case, it seems like sufficiently intensive quantitative methods should outperform qualitative research, e.g. if you measure everything and throw it into some sort of AI-based autoregressive model. Right?
Yet this hasn’t worked out well so far. Is it just because we are not trying hard enough? For instance obviously human sight has much higher bandwidth than questionnaires, so maybe questionnaires would miss most of the information and we need some video surveillance thing with automatic AI tagging for it to work properly.
Or is there some more fundamental difference between qualitative research and quantitative research?
What’s the distinction between personality disorders and “normal” personality variation?
Personality disorders resemble normal personality variation. Self-report scales meant to measure one often turn out to be basically identical to self-report scales meant to measure the other. This leads a lot of people to propose that personality disorders are just the extreme end of personality variation, but is that really true? If not, why not?
What’s more, sometimes mental disorders really seem like they should be the extreme end of normal personality, but aren’t. For instance, Obsessive-Compulsive Disorder seems conceptually similar to Conscientious personality (in the Big 5 model), but results on whether they are connected are at best mixed and more realistically find that OCD is something different from Conscientiousness. Similarly, Narcissism is often described similarly to Disagreeable-tinted Extraversion, but it doesn’t appear to be the same.
What is autism?
Autism is characterized by a combination of neurological symptoms and poor social skills. Certainly one of the strongest indicators of autism is that both autistic and non-autistic people tend to agree that autistic people have poor social skills, but quantitative psychologists often struggle with operationalizing social skills, and in my own brief research on the topic, I haven’t found a clear difference in social performance between autistic and non-autistic people. What’s going on?
Some propose a double empathy problem, where autistic people aren’t necessarily socially broken, but rather have a different focus than non-autistic people. That may be true, but then what is that focus?
Some propose an empathizing/systemizing tradeoff, where male and autistic brains are better able to deal with predictable systems, whereas female and allistic brains are better able to deal with people. Yet this seems to mix together technical interests with autistic interests, and mix together antisocial behavior with social confusion.
Also, why do some things, like excessively academic ideas that haven’t been tested in practice, seem similar to autism? Am I just confused, or is there something going on there?
What is gifted child syndrome/twice-exceptionals?
There’s this idea that autism, ADHD, and high IQ go together in a special way. That said, it’s not really borne out well statistically (autism and ADHD are if anything negatively correlated with IQ), and so presumably it’s just an artifact, right?
What’s up with psychoanalysts?
Psychoanalysts have bizarre-to-me models, where it often seems like they treat people as extremely sensitive, prone to spinning out crazily after even quite mild environmental perturbations.
When statistical evidence contradicts these views, they typically dismiss this by saying that the measurement is wrong because it lacks nuance, or because people lack self-awareness.
Yet to me that just raises the question of why they would conclude this in the first place.
Why are some ideas more “robust” than others?
Some ideas seem “ungrounded”; informally, they are many layers of speculation removed from observations, and can turn out to be false and therefore worthless. Meanwhile, other ideas seem strongly “grounded”. Newtonian physics, even if it is literally false (as we have measured to high precision, relativity is more accurate) and ontologically confused (there isn’t some global flat space with masses that have definite positions and velocities), is still extremely useful.
One solution is to say that Newtonian physics is an approximation to the truth and that makes it quite useful. There’s some value to this answer, but it seems to suggest that the mere fact of being an approximation is sufficient to make something grounded, which doesn’t seem borne out in practice.
How can probability theory model bag-like dynamics?
Probability theory has an easy time modelling very rigid dynamics, where you have a fixed set of variables that are related in a simple way, e.g. according to a fixed DAG.
However, intuitively, we often think of systems that are much more dynamic. For instance, in physical systems, we often model there as being a set of objects. These objects don’t have a fixed DAG of interactions, as e.g. collisions depend on the positions of the objects. You end up with situation where the structure of the system depends on the state of the system, which is feasible enough to handle in e.g. discrete simulations, but hard to get a clean mathematical description of.
Why would progressivism have paradoxical effects on diversity?
Some anti-woke discourse argues that anti-stereotyping norms undermine diversity by preventing people from developing models of minorities’ interests. But isn’t there so much variation within demographic groups that you pretty much have to develop individual models anyway? Furthermore, isn’t there usually a knock-on thing where something that is a common problem among a minority is also a sometimes-occurring problem among the majority, such that you can use shared models anyway?
If there is diversity that needs to be taken into account, wouldn’t something statistical that directly focuses on the factors we care about, rather than on demographics, be more effective?
Why don’t people care about local validity and coherence?
It seems like local validity is a key to sanity and civilization [LW · GW] - this sort of forms the basis for rationalism as opposition to irrationalism. Yet some people resist this strongly - why? I think there’s often a lack of trust underlying it, but why?
Relatedly, some people hold a dialectic style of argument to be superior, where a thesis must be contrasted with a contradictory counter-thesis, and a resolution that contains both must be found. They sometimes dismiss their counterparties as “eristic” (i.e. rationalizing reasons for denial), even when those counterparties just genuinely disagree. Yet isn’t “I haven’t seen convincing reason to believe this” a valid position?
How does commonsense reasoning avoid the principle of explosion?
In logic, the principle of explosion asserts that a single contradiction invalidates the entire logic because it allows you to deduce everything and thus makes the logic trivial. Yet people often seem to navigate through the world while having internal contradictions in their models - why?
What’s wrong with symptom treatment?
I mean, obviously if you can more cheaply cure the root cause than you can mitigate the harm of some condition by reducing the symptoms, you should do that. But this seems like a practical/utilitarian consideration, whereas some people treat symptom treatment as obviously-bad and almost “dirty”.
Why does medicine have such funky qualitative reasoning?
Rather than making up a pros and cons list, when reading about medical theory I often hear about “indications” and “contraindications”, where a contraindication is not treated as a downside, but rather as invalidating an entire line of treatment.
Also, there’s things like blood tests where people are classified binarily on whether they are “outliers”, despite there being substantial natural variation from person to person.
What does it mean to explain a judgement?
If you e.g. use AI to predict outcomes, you get a function that judges datapoints by their likely outcomes. But just the judgement on its own can feel too opaque, so you often want some explanation of why that was the judgement it gave.
There’s a lot of ideas for this, e.g. the simplest is to just give the weights of the function so one can see how it views different datapoints. This is often dismissed as being too complex or uninterpretable, but what would a better, more interpretable method look like? Presumably sometimes there just is no better method, if the model is intrinsically complex?
Why do people seem to be afraid of measuring things?
There’s lots of simple statistical models which make measurement using proxy data super easy. Why aren’t they used more? In fact, why do people seem to be afraid of using it, complaining about biases, often going out of their way to hide information relevant to developing these measurements?
Obviously no measurement is perfect, but it seems like the solution to bad measurement is more measurement, right?
Why is there no greater consensus for large-scale models?
We all know outcomes depend on multiple causes, to the point where things can be pretty intertwined. In genomics, people are making progress on this by creating giant models that take the whole genome into account. Furthermore I’ve had a long period where I was excited about things like Genomic SEM, which also start taking multiple outcome variables into account, modelling how they are linked to each other.
As Scott Alexander argued in the omnigenic model as the metaphor for life, shouldn’t this be how all of science works? Isn’t much of science deeply flawed because it doesn’t put enough effort into scale?
Can we “rescue” the notion of objectivity?
It seems obvious that there’s a distinction between lying and factual reporting, but you can create a misleading picture while staying entirely factual via selective reporting: only report the facts which support the picture you want to paint, and avoid mentioning the facts that contradict it. This seems “wrong” and “biased”, but ultimately there are a lot of facts, so you have to be selective; and it seems like the selectiveness should be unrepresentative to emphasize blessed over barren or cursed information.
What lessons can we even learn from long-tailedness?
Some people point out that certain statistical models are flawed because they assume short-tailed variables when really reality is long-tailed, calling it the “ludic fallacy”. OK, that seems like an obviously valid complaint, so basically you should adjust the models to use long tails, right? But that often leads to further complaints about the “ludic fallacy”, Knightian uncertainty, and that one is missing the point.
But isn’t the entire point of long-tailedness that rare crazy unpredictable factors can pop up? If not, what is the point of talking about long-tailedness?
Perception is logaritmic; doesn’t this by default solve a lot of problems?
In a lot of ways, perception is logarithmic; for instance even though both columns in the picture below add 10 dots, you perceive the left one as having a much bigger difference than the right one:
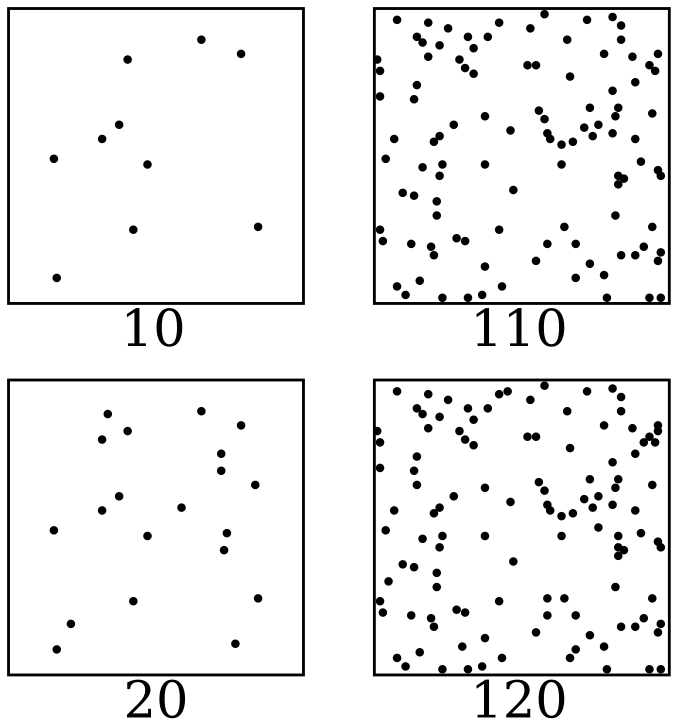
Logaritmic perception is quite useful because it allows one to use the same format to store quantities across orders of magnitude. It’s arguably also typically used in computers (floating point) and science (scientific notation). In psychophysics, this is known as the Weber-Fechner law, that perception (S) is logarithmically related to intensity (I).

While logarithmic perception is just a fact, wouldn’t this fact often make long-tailedness a non-issue, because it means certain measurements (e.g. psychological self-reports) are implicitly logarithmic, and so the statistical models on them implicitly have lognormal residuals?
Also, sometimes (e.g. for electric shocks or heaviness) perception is not logarithmic, but instead superlinear. Steven’s power law models it as, well, a power law:
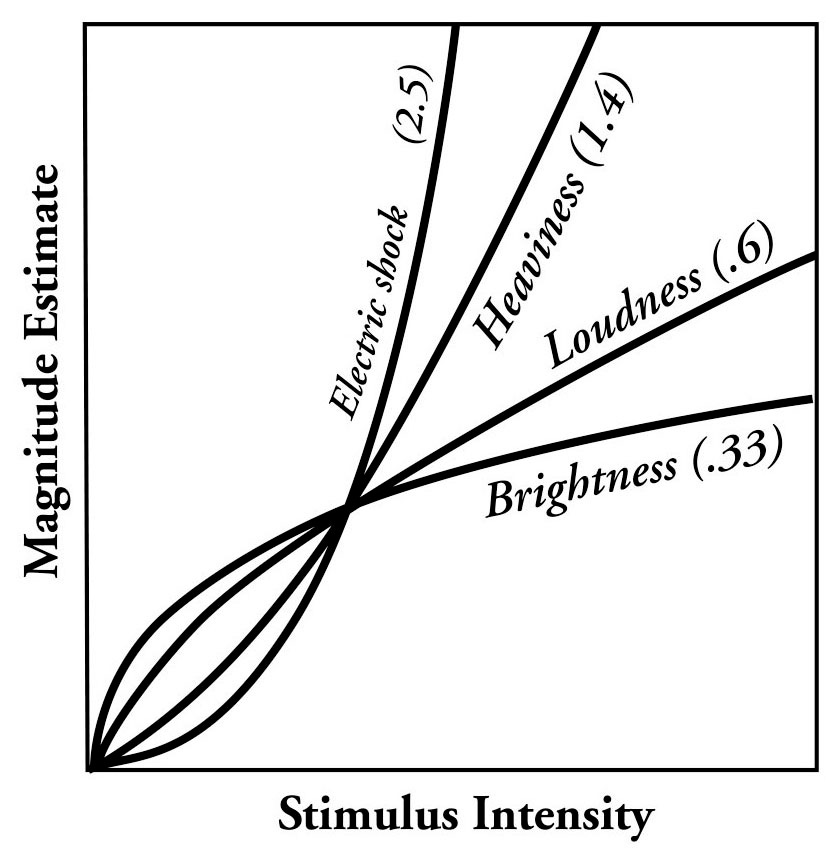
It seems quite sensible why that would be the case: sometimes things matter superlinearly, e.g. there’s a limit to how heavy things you can lift, so of course the weight perception is gonna rapidly accelerate close to that limit. But this just seems to mean that human perception is nicely calibrated to emphasize how important things are, which just means we are generally blessed to not have to worry that much about perception calibration, right?
This seems related to how in psychometrics, there’s a lot of fancy models for quantitatively scoring tests (e.g. item response theory), but they tend to yield results that are 0.99 correlated with basic methods like adding up the items, so they aren’t all that important unless you’re doing something subtle (e.g. testing for bias).
More generally, in order to measure or perceive some variable X, it’s necessary for X to influence the measurement instrument. The standard measurement model is to just say that the measurement result is X + random noise. If (simplifying a bit) you add up the evidence that X has influenced the measurement device, that seems like the most direct measurement of X you could imagine, and it also pretty much gets you some number that has maximal mutual information with X. Doesn’t that seem like a pretty reasonable way of measuring things? So measurement is by-default correct.
All of this may be wrong
I posed a lot of conundrums, and gave some reasons why one might dismiss those conundrums, and essentially dismiss people acting in these ways as irationally overgeneralizing from a few edge-cases where it does make sense. This is essentially scientism, the position that human thinking has lots of natural defects that should be fixed by understanding universally correct reasoning heuristics.
However, under my current model, which I will explain in my next posts, it’s instead the opposite that is the case: that universally correct reasoning heuristics have lots of defects that can be fixed by engagement with nature.
I’m not sure my model will explain all of the above problems. Possibly some of my explanations are basically just hallucinatory. But these are at least useful as examples of the sorts of things I expect it to explain.
Continued in: Performance optimization as a metaphor for life [LW · GW].
10 comments
Comments sorted by top scores.
comment by Noosphere89 (sharmake-farah) · 2024-08-07T23:35:33.842Z · LW(p) · GW(p)
I'll take a stab at some of these questions:
- Why are people so insistent about outliers?
For the news industry, because it causes extreme emotional reactions, which give them guaranteed large demand and thus give them lots of money.
For the public, it's primarily due to the fact that we don't realize how uninformative the outliers actually are, because our intuitions were geared towards small-scale societies, and we don't realize that in large worlds, the tails become truly extreme but also uninformative.
From gwern:
Because weirdness, however weird or often reported, increasingly tells us nothing about the world at large. If you lived in a small village of 100 people and you heard 10 anecdotes about bad behavior, the extremes are not that extreme, and you can learn from them (they may even give a good idea of what humans in general are like); if you live in a ‘global village’ of 10 billion people and hear 10 anecdotes, you learn… nothing, really, because those few extreme anecdotes represent extraordinary flukes which are the confluence of countless individual flukes, which will never happen again in precisely that way (an expat Iranian fitness instructor is never going to shoot up YouTube HQ again, we can safely say), and offer no lessons applicable to the billions of other people. One could live a thousand lifetimes without encountering such extremes first-hand, rather than vicariously.
Link:
https://gwern.net/littlewood#epistemological-implications
Edit: There is a big case where it's correct to be insistent about outliers, in that if you think something is distributed log-normally/power law, then the outliers contain most of what you value, and thus the outliers are the most important things to get right.
- Why do people tend to talk in funky discrete ways when careful quantitative analysis generally finds everything to be continuous?
Basically, because it's both easier to understand a binary/discrete system than it is to reason about continuous quantities, and we write stories that rely on binary/discrete effects, rather than continuous change because it's more fun.
However, there's a perfectly respectable argument to say that the universe is at it's core a discrete, not continuous entity, though I'm not endorsing it here.
Scott Aaronson defends it in this blog post here, and he essentially argues that the Bekenstein bound forces nature to be fundamentally finite:
https://scottaaronson.blog/?p=2820
https://en.wikipedia.org/wiki/Bekenstein_bound
- Why do people want “the” cause?
A lot of it is that people deeply think that the world must be simple and in particular monocausal, because it would make our lives easier.
More importantly, science is a lot, lot harder in a polycausal world, which Scott Alexander explains in his post here:
https://slatestarcodex.com/2018/09/13/the-omnigenic-model-as-metaphor-for-life/
Also, probably working memory limitations are a problem.
- Why are people dissatisfied with GWAS?
People are dissatisfied with GWAS because it fundamentally challenges one of our more important beliefs: That we essentially have full internal locus of control over our traits. It's a more mentally healthy mindset to hold than an external locus of control, so I do think there are real reasons here, but predictably underestimates uncontrollable factors like genetics.
It also has similarities to why people hate the scaling hypothesis and the Bitter Lesson in AI.
- What’s wrong with symptom treatment?
While there is a definite over-resistance to symptom treatment, which comes from a similar place to opposing incremental changes instead of radical revolutions, part of the issue is that when you don't intervene on the causes, the treatment of symptoms can fade away, thus offering only temporary solutions. Now I think this is less of a problem than people think, it can be a problem to think about.
Cf Gwen on "Everything is Correlated":
To the extent that these key variables are unmodifiable, the many peripheral variables may also be unmodifiable (which may be related to the broad failure of social intervention programs). Any intervention on those peripheral variables, being ‘downstream’, will tend to either be ‘hollow’ or fade out or have no effect at all on the true desired goals no matter how consistently they are correlated.
https://gwern.net/everything#importance
- Why does medicine have such funky qualitative reasoning?
A lot of it is because medicine in general is very regulated and generally wants to make people safe at all costs, which means that it often doesn't consider other outcomes that are relevant, so an overfocus on the negative is likely.
- Why do people seem to be afraid of measuring things?
Basically, because if they measure things, it makes it less special and illegible in their mind, and critically this usually means the thing loses status (or at best retains status.)
More generally, if you are subject to measurement, than you can realistically only lose status or have your status remain the same, and thus it's not worth it to measure a lot of things.
Also, if you measure something accurately, it can be a blow to certain political opinions, and given that most people are low-decouplers, this means that they have an incentive not to measure something.
- Why is there no greater consensus for large-scale models?
Basically, it comes from the same place as disliking the Bitter Lesson and the scaling hypothesis: Because it means your specially handcrafted inductive bias for small models don't work.
https://www.cs.utexas.edu/~eunsol/courses/data/bitter_lesson.pdf
More importantly, science is a lot, lot harder in a polycausal world.
- Can we “rescue” the notion of objectivity?
I think not, tentatively in the limit, and in the most general case the answer is absolutely not, so the question is over what domains we want to rescue objectivity in.
This articles gives hints that we may not be able to get objectivity consistent with other assumptions about our reality.
comment by quetzal_rainbow · 2024-08-07T20:57:35.896Z · LW(p) · GW(p)
Certainly one of the strongest indicators of autism is that both autistic and non-autistic people tend to agree that autistic people have poor social skills, but quantitative psychologists often struggle with operationalizing social skills, and in my own brief research on the topic, I haven’t found a clear difference in social performance between autistic and non-autistic people. What’s going on?
I think there is a difference between skills (which are trainable), outcomes (which can be deliberately optimized), and innate ability (which seems to be actual source of struggle).
My current friends are usually very surprised when they learn that I was absolutely insufferable to interact with when I was 18 years old, but I just speedran social adaptation by hanging out with people tolerant of my sort of autism, and I still find it very tiring to be around people not from tech/science/artistic subcultures.
Replies from: tailcalled↑ comment by tailcalled · 2024-08-07T21:06:55.109Z · LW(p) · GW(p)
But that still raises the question of what your sort of autism is, and why that makes it tiring to be around people not from tech/science/artistic subcultures.
comment by Michael Roe (michael-roe) · 2024-08-07T20:22:03.768Z · LW(p) · GW(p)
A possible justification of qualitative research: you do this first, before you even know which hypotheses you want to test quantitatively.
Replies from: tailcalled↑ comment by tailcalled · 2024-08-07T20:23:12.536Z · LW(p) · GW(p)
Yes, but the question I was asking is, why does this help you figure out which hypotheses to test quantitatively any more than quantitative research does?
Replies from: michael-roe↑ comment by Michael Roe (michael-roe) · 2024-08-07T20:36:38.681Z · LW(p) · GW(p)
Maybe: it's easier to capture a whole load of diverse stuff if you don't care about numerically quantifying it, and dont care about statistical significance tests, multiple testing, etc. Once you have a a candidate list of qualitative features that might be interesting, you can then ask: ok, how do I numerically measure this thing?
Replies from: tailcalled↑ comment by tailcalled · 2024-08-07T20:37:47.440Z · LW(p) · GW(p)
But if you have a whole load of diverse stuff, how do you know what matters and what doesn't matter?
comment by Morpheus · 2024-08-07T22:12:01.437Z · LW(p) · GW(p)
Looking forward to the rest of the sequence! On my current model, I think I agree with ~50% of the "scientism" replies (roughly I agree with those relating to thinking of things as binary vs. continuous, while I disagree with the outlier/heavy-tailed replies), so I'll see if you can change my mind.
comment by Michael Roe (michael-roe) · 2024-08-07T20:12:19.087Z · LW(p) · GW(p)
RE: autism. we might also add sensory issues/only able to concentrate on one sense at a time, and the really strange one: having fluent knowledge of the literal meanings of words, but difficulty with metaphors.
a) Are these part of the same symptom cluster as the "theory of mind" aspects of autism?
b) If so, why? Why on Earth would we expect metaphorical use of language to (i) be somehow processed by different metal modules from literal usage (ii) be somehow related to reasoning about other minds?
I actually personally know a couple of people who have the metaphors one. They tell me the issuer is that the literal meaning is just way more salient than the literal one.
Replies from: tailcalled↑ comment by tailcalled · 2024-08-07T20:21:38.942Z · LW(p) · GW(p)
Difficulty with metaphors is absolutely a great example according to my theory.