Personal forecasting retrospective: 2020-2022
post by elifland · 2022-07-21T00:07:03.511Z · LW · GW · 4 commentsThis is a link post for https://www.foxy-scout.com/retro/
Contents
Overview Platform track records Metaculus GJOpen INFER Manifold Markets Selected tournaments Arising Intelligence OpenPhil / Metaculus Forecasting AI Progress COVID tournaments Interesting mistakes AI benchmarks COVID waves General reflections Acknowledgments None 4 comments
Overview
I’ve been forecasting with some level of activity for over 2 years now, so I’m overdue for a retrospective.[1]
I discuss:
- My overall track record on each platform: My track record is generally strong, though my tails on continuous questions are systematically not fat enough.
- Selected tournament performances: My tournament track record seems pretty mediocre.
- A few interesting mistakes I made: I badly underestimated progress on AI benchmarks and the ferocity of COVID waves after much of the population was vaccinated and/or naturally immune.
- General reflections: Some quick intuitions and hot takes I have based on my time forecasting
Platform track records
Metaculus
I started forecasting fairly actively on Metaculus in 2020 when I got interested due to COVID forecasting, though recently I have mostly just been predicting on particularly interesting questions every once in a while. I’m currently 9th on the overall leaderboard, due to me trying to predict on ~every question for about a year.
My binary calibration:

I might be a little underconfident? The blue rectangle in each bin represents the 50% confidence interval, and it looks like about 11 of the 20 rectangles contain the bin.
My continuous calibration:

From Metaculus: “We define the surprisal at the resolution to be the total probability assigned to all possible (in-range) resolution values that were thought to be more likely than the resolution itself. A resolution at the mode (peak) of the distribution has a surprisal of zero, whereas a resolution at the minimum of the distribution is maximally surprising.”
I’m guessing the spike at 0-5% surprisal is mostly due to the cases where the value was effectively known before the question closed.
On the other hand, the spike at 95-100% surprisal is conveying something real: my tails are, on average, not long enough. This is an interesting contrast to my binary predictions where ~all my 0-5% and 95-100% predictions look to have been right. Forming calibrated continuous distributions is tricky; in Metaculus’ interface it might be wise to add high variance low weight components, to generally account for unknown unknowns.
I’m not sure what’s going on with the drop at 5-10%, but otherwise this looks pretty good and the overall average surprisal of 46% seems decent.
My average log score (higher is better) vs. the community predictions are as follows:
| My score | Community score | |
| Binary (close time) | .478 | .472 |
| Binary (all times) | .305 | .265 |
| Continuous (close time) | 1.95 | 2.04 |
| Continuous (all times) | 1.52 | 1.54 |
It’s hard to really know what to make of these because:
- I’m 96% sure evaluating at “all times” gives me an unfair advantage because it compares my score over only the time I predicted vs. the community score over the life of the question, which means it’s not very useful.
- Because I was trying to predict on almost every question for a little while, I haven’t kept most of my predictions up to date, which hurts significantly as opposed to if I was just comparing to the community at the time of prediction. This hurts more for “all times” than “close time” as I tried to update right before the question ended[2], but it still hurts some for “close time” when I failed to do this or the question closed “early” as is somewhat common (e.g. when a question asks “Will X happen by 2025”, then it happens in 2022”.)
Given (2) above, I’m pretty happy about performing approximately the same as the community on questions evaluated at close time.
GJOpen
GJOpen was the first platform I predicted on after reading Superforecasting in ~2018, but I was fairly inactive for a while. I was a bit more active for about a year in 2020-2021.
My calibration across 3,293 data points from 964 forecasts on 139 questions, displayed by this app:[3]

This overall looks pretty good, but perhaps I have a bit of a bias toward predicting events are more likely to occur than they actually are?
My overall Brier score is 0.23 vs. a median of 0.301 from other predictors (lower is better); I’m pretty happy about this overall. The difference is a bit inflated as I sometimes selected questions based on the community seeming very wrong, after having received tips from other forecasters.
INFER
I predicted on Foretell, now INFER, during the 2020 and 2021 seasons.
I’m first on the overall leaderboard, and my team Samotsvety Forecasting placed first on the leaderboard for the first 2 seasons.
While I’m pretty happy about being first here given that there were ~50 pro forecasters during the 2021 season:
- The placement is likely partially due to activity/effort (though note that it is based on relative score, so one only accumulates negative points by doing better than the median forecaster).
- I owe some credit to my teammates Loki and yagudin, who discussed many forecasts with me and are 2nd and 3rd as pictured above.
Manifold Markets
I’ve traded actively on Manifold Markets since Feb 2022; I find the interface enjoyable and it’s fun/addictive to accumulate more Manifold dollars (Mana).
Overall I’m doing pretty well; I’m 13th on the profit leaderboard and think I have one of the highest percentage returns. I’ve turned M$1,000 into M$8,420 so far.
My biggest (resolved) profits thus far come from correcting NBA markets to real money betting odds, correcting a high school science bowl market that was for some reason highly traded and off, and betting against Carrick Flynn winning the Democratic primary (this feels like the most real epistemic win).
Selected tournaments
Arising Intelligence
I got 70th/146 forecasters on Arising Intelligence 2022 on Hypermind, slightly above average despite missing badly on 2 of the questions (the crowd also missed very badly). Will be interesting to see how I do in 2023-2025; my updated forecasts are here, and my previous round of forecasts is here.
OpenPhil / Metaculus Forecasting AI Progress
I’m in 15th place overall on the overall leaderboard for the Forecasting AI Progress tournament, which seems not great relative to the number of predictors per question. As I’ve previously described [EA · GW], the tournament felt like it was mostly testing the skill of forming continuous distributions from trend extrapolation. I believe I made a basic error of not accounting for seasonality when extrapolating ArXiv paper counts in at least one of the rounds.
COVID tournaments
I did fairly well in the Metaculus COVID tournaments that I actively participated in: I’m in first place in the Salk tournament regarding vaccines and got first place in the first COVID lightning round tournament (but 12th in the second).
Interesting mistakes
AI benchmarks
I (and the crowd) badly underestimated progress on MATH and MMLU. For more details on the mistake, see Jacob Steinhardt’s blog post [? · GW] and my clarifying comment [LW · GW].
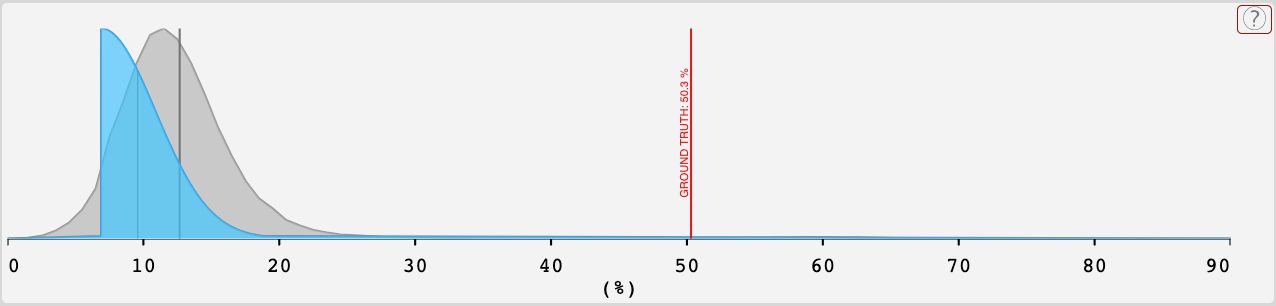
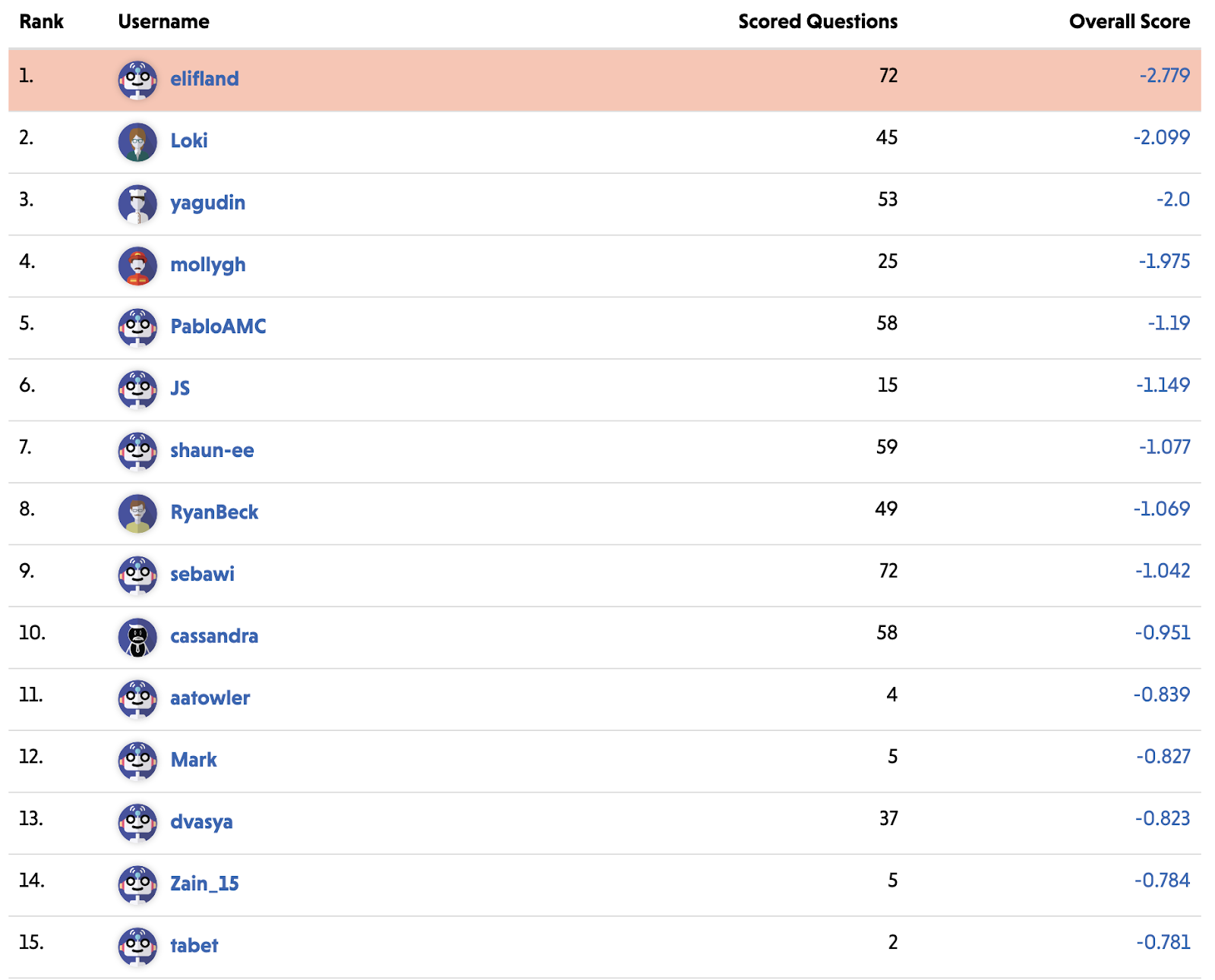
A mistake I made applicable to both benchmarks was underestimating the low-hanging fruits of improvement that were likely to be picked following the surge of interest in LMs after GPT-3.
- In the MATH case, Minerva employs “chain of thought or scratchpad prompting, and majority voting” and builds on PaLM, which is significantly bigger and better than GPT-3.
- Notably, according to the paper just the improvements OpenAI has made to GPT-3 accessible via their API would have increased accuracy to 19.1%!
- In the MMLU case, Chinchilla took advantage of updated scaling laws with a smaller model trained on more data.
Additionally, I didn’t respect the base rate for fast progress on new NLP benchmarks enough. Owain Evans comments on this here [LW · GW]; I haven’t seen a thorough analysis done but my guess is that since transformers have been introduced progress is often very fast after the release of a benchmark; see e.g. SuperGLUE having human performance beaten in ~1.5 years.
I made a few additional mistakes in the MATH case:
- The SOTA at the time of benchmark release was obtained by fine-tuning GPT-2. While few-shot GPT-3 didn’t improve upon fine-tuned GPT-2, I should have given more weight to fine-tuned models much larger than GPT-2 doing much better than fine-tuned GPT-2.
- I had a vague intuition that the task seemed really hard and would require substantial advances. I think I didn’t seriously consider whether this intuition retrodicted the past well; e.g. some of the tasks in SuperGLUE also seem pretty hard.
- The paper argued: “While scaling Transformers is automatically solving most other text-based tasks, scaling is not currently solving MATH. To have more traction on mathematical problem solving we will likely need new algorithmic advancements from the broader research community.” I think I anchored on this claim, not seriously considering the likelihood that it was just flat out wrong.
My updated predictions on these questions can be found here. I’ve also updated from median 2047 to 2033 on AI winning an IMO gold medal.
On AGI/TAI timelines, I still feel somewhat skeptical that (approximately) GPT-n will scale to AGI but my skepticism has reduced a bit, and I think the MATH result indicates a speedup for this pathway. I should also update a bit on the meta level regarding the reliability of my skepticisms. Before my TAI timelines were roughly similar to Holden’s here: “more than a 10% chance we'll see transformative AI within 15 years (by 2036); a ~50% chance we'll see it within 40 years (by 2060); and a ~2/3 chance we'll see it this century (by 2100)”. I’m now at ~20% by 2036; my median is now ~2050 though still with a fat right tail.
My timelines shortening should also increase my p(AI doom by 2100) a bit, though I’m still working out my views here. I’m guessing I’ll land somewhere between 20 and 60%.
I’m also generally confused about how to translate progress on tangible benchmarks like MATH into updated bottom line forecasts. My current method feels very brittle in that I’m making some intuitive adjustment based on “surprisingness”, but I don’t have a clear model of which capabilities are missing and what would make me update on their feasibility. I’m working on building up a more robust model of AI progress to get better at this, but it will probably take a little while. My sense is that very few people have anything close to a good enough model here to reliably differentiate how to update on new evidence.
COVID waves
I consistently underestimated future COVID waves after the initial one, and especially after much of the population was vaccinated and/or naturally immune; I had a naive model of how herd immunity would work and failed to account enough for substantially increased transmission, re-infections, vaccine escape, etc. I probably would have done well to study past pandemics more in depth and take lessons from them. I should also perhaps generally be skeptical of simplistic models like “we’ll have herd immunity and things will peter out indefinitely”.
For example, on When will the US pass 1 million cumulative deaths from COVID-19? I predicted as far to the right edge as I was allowed to, then lost 212 points. I was very skeptical deaths would continue this rapidly after vaccinations.
General reflections
Some quick intuitions and hot takes I have based on my time forecasting include:
- Some EAs overrate the epistemic superiority of (super)forecasters.
- To exaggerate a little: forecasters are just people who are more willing to put wild guess numbers on things and try to improve the guesses.
- Sometimes I feel like people have this idea that forecasters have “magical forecasting techniques” that get them an awesome answer, but I think they’re just reasonable people who in fact choose to forecast a decent amount.
- On most forecasting questions it’s hard to improve much from a reasonable-ish baseline, and for most questions the value of minor improvements isn’t that large.
- I feel intuitively skeptical that forecasting training/practice beyond a few hours helps that much compared to innate abilities and domain expertise.
- I’d guess it has very diminishing returns; I think calibration training and “always start with the base rate / reference class” gets a large fraction of the gains and many more hours of practice don’t help as much.[4]
- I don’t feel like I’m really a significantly better forecaster than 2 years ago, despite trying to become one via things like this retrospective.
- It varies based on the question/domain how much domain expertise matters, but ultimately I expect reasonable domain experts to make better forecasts than reasonable generalists in many domains.
- There’s an extreme here where e.g. forecasting what the best chess move is obviously better done by chess experts rather than superforecasters.
- So if we think of a spectrum from geopolitics to chess, it’s very unclear to me where things like long-term AI forecasts land.
- This intuition seems to be consistent with the lack of quality existing evidence described in Arb’s report [EA · GW].
- That being said, reasonable domain experts (or their time) might be in short supply! In cases where there aren’t many reasonable experts, reasonable generalists may still be useful.
- (Related to above) It’s very unclear how much skill at Tetlock-style judgmental forecasting translates to making progress on the most important big picture forecasts, e.g. those relevant to AI risk strategic decisions.
- A lot of the mental moves involved in predicting the average 1-2 year out geopolitical question seem different from even predicting AI benchmark progress on a similar timescale, and very different from predicting the probability of an AI catastrophe in the next 50 years.
- I’m sure there’s some correlation here, but I’m not sure how much information you get from short term prediction success besides a strong correlation with being generally smart.
Acknowledgments
Thanks to Nuño Sempere and Molly Hickman for feedback.
- ^
I’d really liked to have gone more in-depth, especially with more case studies and learnings, but the writing of this already dragged on too long.
- ^
due to the recently discontinued final forecast bonus
- ^
Which seems to be broken as of July 15, 2022 when I’m revising this?
- ^
From a quick search, my understanding of the literature is that it shows some improvement from one hour training. This paper also reports an improvement from training but doesn’t specify how long was spent on the training. I’m not aware of any papers studying whether improvement can continue to occur from lots of training/practice.
4 comments
Comments sorted by top scores.
comment by jsteinhardt · 2022-07-21T19:07:27.500Z · LW(p) · GW(p)
Thanks for writing this!
Regarding how surprise on current forecasts should factor into AI timelines, two takes I have:
* Given that all the forecasts seem to be wrong in the "things happened faster than we expected" direction, we should probably expect HLAI to happen faster than expected as well.
* It also seems like we should retreat more to outside views about general rates of technological progress, rather than forming a specific inside view (since the inside view seems to mostly end up being wrong).
I think a pure outside view would give a median of something like 35 years in my opinion (based on my very sketchy attempt of forming a dataset of when technical grant challenges were solved), and then ML progress seems to be happening quite quickly, so you should probably adjust down from that.
Actually pretty interested how you get to medians of 40 years, that seems longer than I'd predict without looking at any field-specific facts about ML, and then the field-specific facts mostly push towards shorter timelines.
Replies from: elifland↑ comment by elifland · 2022-07-24T05:25:16.955Z · LW(p) · GW(p)
Given that all the forecasts seem to be wrong in the "things happened faster than we expected" direction, we should probably expect HLAI to happen faster than expected as well.
I don't think we should update too strongly on these few data points; e.g. a previous analysis of Metaculus' AI predictions [EA · GW] found "weak evidence to suggest the community expected more AI progress than actually occurred, but this was not conclusive". MATH and MMLU feel more relevant than the average Metaculus AI prediction but not enough to strongly outweigh the previous findings.
It also seems like we should retreat more to outside views about general rates of technological progress, rather than forming a specific inside view (since the inside view seems to mostly end up being wrong)
I think a pure outside view would give a median of something like 35 years in my opinion (based on my very sketchy attempt of forming a dataset of when technical grant challenges were solved), and then ML progress seems to be happening quite quickly, so you should probably adjust down from that.
I'd be interested to check out that dataset! Hard for me to react too much to the strategy without more details, but outside-view-ish reasoning about predicting things far-ish in the future that we don't know much about (and as you say, have often been wrong on the inside view) seems generally reasonable to me.
Actually pretty interested how you get to medians of 40 years, that seems longer than I'd predict without looking at any field-specific facts about ML, and then the field-specific facts mostly push towards shorter timelines.
I mentioned in the post that my median is now ~2050 which is 28 years out; as for how I formed my forecast, I originally roughly start with Ajeya's report [LW · GW], added some uncertainty and had previously shifted further out due to intuitions I had about data/environment bottlenecks, unknown unknowns, etc. I still have lots of uncertainty but my median has moved sooner to 2050 due to MATH forcing me to adjust my intuitions some, reflections on my hesitations against short-ish timelines [EA · GW], and Daniel Kokotajlo's work [? · GW].
comment by peterslattery · 2025-04-04T18:21:51.604Z · LW(p) · GW(p)
I think you should make a new version of this for your website. You are now becoming more of a public figure, and better communicating your forecasting record will help make you, and outputs like AI 2027, more credible.