What should AI safety be trying to achieve?
post by EuanMcLean (euanmclean) · 2024-05-23T11:17:49.204Z · LW · GW · 1 commentsContents
How to read this post How could AI safety prevent catastrophe? Technical solutions Sounding the alarm to the AI community AI Regulation Fundamental science Slowdowns & pauses Open source Most promising research directions Mechanistic interpretability Black box evaluations Governance research and technical research useful for governance Other technical work Conclusion Appendix Participant complaints for Q3 None 1 comment
This is the second of three posts summarizing what I learned when I interviewed 17 AI safety experts about their "big picture" of the existential AI risk landscape: how will artificial general intelligence (AGI) play out, how things might go wrong, and what the AI safety community should be doing. See here [LW · GW] for a list of the participants and the standardized list of questions I asked.
This post summarizes the responses I received from asking “conditional on ‘AI safety’ preventing a catastrophe, what did AI safety do to prevent such a catastrophe?” and “what research direction will reduce existential risk the most?”
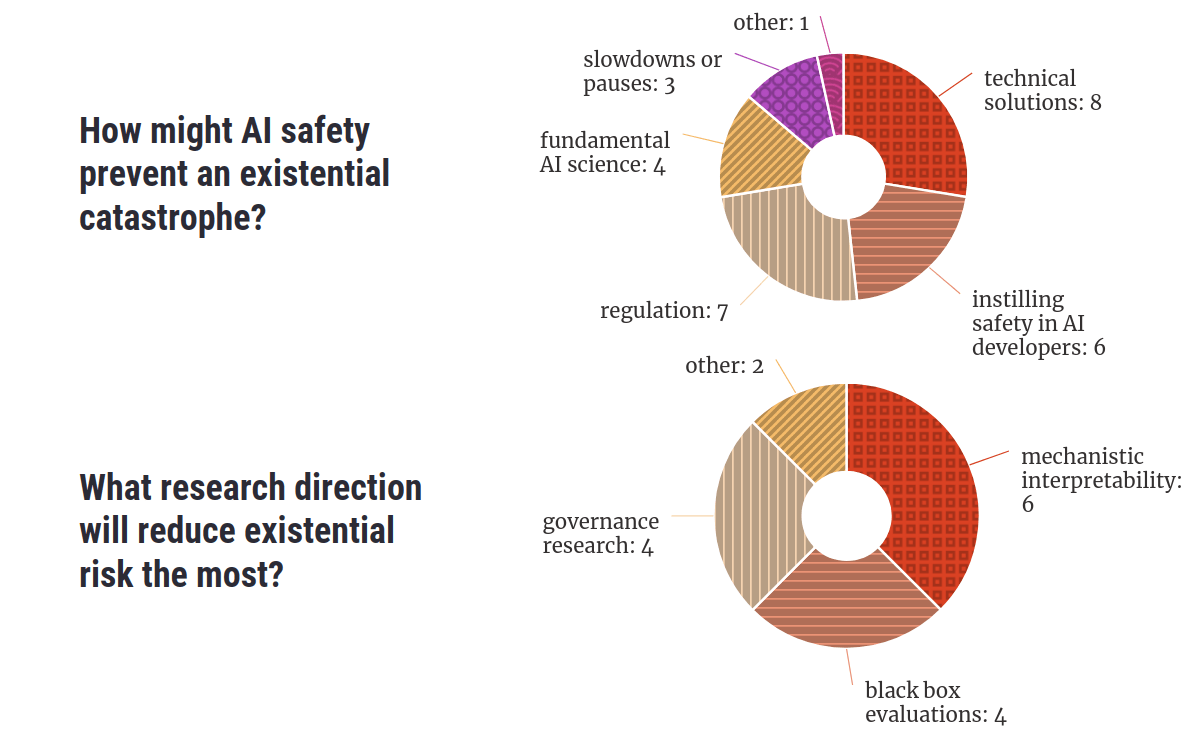
When asked how AI safety might prevent disaster, respondents focussed most on 1) the technical solutions we might come up with, 2) spreading a safety mindset through AI research, 3) promoting sensible AI regulation, and 4) building a fundamental science of AI. The research directions people were most excited about were mechanistic interpretability, black box evaluations, and governance research.
How to read this post
This is not a scientific analysis of a systematic survey of a representative sample of individuals, but my qualitative interpretation of responses from a loose collection of semi-structured interviews. Take everything here appropriately lightly.
Results are often reported in the form “N respondents held view X”. This does not imply that “17-N respondents disagree with view X”, since not all topics, themes and potential views were addressed in every interview. What “N respondents held view X” tells us is that at least N respondents hold X, and consider the theme of X important enough to bring up.
How could AI safety prevent catastrophe?
Q3 Imagine a world where, absent any effort from the AI safety community, an existential catastrophe happens, but actions taken by the AI safety community prevent such a catastrophe. In this world, what did we do to prevent the catastrophe?
Technical solutions
8 respondents considered the development of technical solutions to be important. 5 of those 8 focussed on the development of thorough safety tests for frontier models (like red-teaming, safety evaluations, and mechanistic interpretability). Such safety tests would be useful both for the voluntary testing of models by AI developers or for enforcing regulation. 4 of the 8 also emphasized the development of scalable oversight techniques.
One respondent hypothesized that if the first five or so AGI systems are sufficiently aligned, then we may be safe from an AI takeover scenario, since the aligned AGIs can hopefully prevent a sixth unaligned AGI from seizing power. Daniel however was skeptical of this.
Sounding the alarm to the AI community
6 respondents emphasized the role of AI safety in spreading a safety mindset and safety tools among AI developers.
3 of those 7 focussed on spreading a safety culture. The default is for safety to be largely ignored when a new technology is being developed:
“They’ll just analogize AI with other technologies, right? Early planes crashed and there was damage, but it was worth it because this technology is going to be so enormously transformative. So there are warning shots that are ignored.” - Noah Siegel
AI is different from these other technologies because we can’t approach AI with the same trial-and-error attitude – an error in the first AGI could cause a global disaster. AI should have a culture similar to that around building nuclear reactors: one with a process for deciding whether a new model is safe to deploy.
So how does one argue that we need more safety standards in AI? 2 respondents emphasized demonstrating the capabilities of models, the speed of capabilities progress, and working out how to predict dangerous capabilities in the future.
“Many doom stories start with people underestimating what the model can do.
Hopefully they don’t discover GPT-7 to be dangerous by testing it directly, but instead they do tests that show the trend line from GPT-4 is headed toward danger at GPT-7. And they have time to implement measures, share information with the government, share information with other developers and try and figure out how to navigate that. And hopefully they've already written down what they would do if they got to that point, which might be: ‘we're going to improve our security up to X point, we're going to inform ABC people in the government’, and so on.” - Ajeya Cotra
AI safety could also make AI development safer by developing better tools for testing the safety of these systems. As Jamie Bernardi put it: the AI takeover stories inform a particular flavor of AI testing that would not have been included in safety standards otherwise. Adam Gleave sees the value of AI safety to come from “continual horizon scanning and noticing problems that others are missing because the empirical evidence isn’t staring them in the face”.
AI Regulation

7 respondents put emphasis on getting policy passed to regulate the development of AI systems, although 2 others explicitly said that they were not enthusiastic about regulation.
The most common flavor of regulation suggested was those to ensure new AI models must undergo safety testing before we allow them to be deployed. This means a new dangerous model that otherwise would have gone on to cause damage (e.g. one that is deceptively aligned or power-seeking) may be “caught” by testing before it is deployed. This would not only prevent disaster but serve as a wake-up call about the dangers of AI and supply a testbed for developing safer systems.
Holly Elmore was also a fan of the idea of emergency powers for governments: if it looks like an AI-related emergency is happening (like a rogue AI attempting to seize power), it would be good if governments could order the model to be isolated by shutting down whatever data centers are required for the model to be publicly accessible (this would also require systems to have the relevant kill-switches in compliance with regulation).
How do we get policy passed? Holly believes our best bet is public outreach. Educate the public of the risks, so the public can put pressure on governments to do the right thing. But what if, through our messaging, AI safety becomes a partisan issue, making it hard to pass policies? Holly acknowledged this risk but thought it doesn’t outweigh the benefits of going mainstream. She offered a good way of framing AI safety that seems less likely to have a polarizing effect:
“There are a small number of companies trying to expose the whole world to an existential risk, from which they would highly disproportionately benefit if their plan succeeded. It's really not like “tech people against the world” or “business people against the world”. It's just the AGI companies versus everyone else.” - Holly Elmore
Holly argued that many in AI safety have too much of an “elite disruptor mindset”, thinking they’ll be able to play enough 4D chess and make enough back-room deals to push the development of AI in the right direction independently of government or the public. But when you play 4D chess, something usually goes wrong. She gave the example of the role AI safety played in the founding of OpenAI and Anthropic: the idea was that these entities will build AI in a safe way voluntarily, but who knows if that’s actually going to happen. The more robust approach is to educate the public about the risks involved with AI, so society can collectively solve the problem through policy.
Fundamental science
“If you have something you think is a big deal then you want to do science about it full stop. You want to study anything that you think is important. And in this case, it's that AI values are likely to be wrong. Therefore, you should study AI values, but you should do so in a way that's pretty fundamental and universal.” - Richard Ngo
“Things that we do that affect the world's understanding of what to do are more important than trying to do a lot of stuff behind the scenes. And in fact, I think a lot of the behind the scenes stuff has been net negative” - Holly Elmore
4 respondents believed that anything that improves our (society’s) understanding of the problem is robustly helpful. For example, when I asked Richard for ways AI safety can help the situation, he focussed on starting good institutions to do good science in AI safety and governance. When I asked him for a theory of change for this, he responded:
“I can make up answers to this, but I mostly try not to, because it's almost axiomatic that understanding things helps. It helps in ways that you can't predict before you understand those things. The entire history of science is just plans constantly failing and people constantly running into discoveries accidentally. I think it's really easy to do stuff that's non-robust in this field, so I am much more excited about people doing things that are robust in the sense that they push forward the frontier of knowledge.” - Richard Ngo
Richard pointed at the work of Epoch AI as an example of good solid fundamental research and compared it to some of the reports written by Open Philanthropy that are too high-level to be robust in his eyes.
I’ve always felt unsure about work that just generally improves our understanding of AI, because I’ve been worried that it will help AI developers improve the capabilities of AI systems faster, which gives us less time to prepare for crunch time. But through the course of this project, the respondents have convinced me that increasing understanding is on average a good thing.
“There are a bunch of cars driving in this foggy landscape and it turns out, unknown to them, there are spikes all over the landscape and there's a cliff at the end, but there's also big piles of gold along the way. Do you clear the fog? I feel if the cars are generally driving in the direction of the spikes and the cliff, you should clear the fog, even though that means the cars are going to be moving faster to try to weave to the gold, because otherwise the default course involves hitting the spikes or running off the cliff.” - Ajeya Cotra
Slowdowns & pauses

3 respondents advocated for slowing down AI development in one way or another, to give the world more time to prepare for the first potentially dangerous AI systems (but one respondent was explicitly against this). AI capabilities can be slowed down due to the red tape of regulation or by implementing a coordinated pause.
Ben Cottier emphasized buying time to be a useful goal because he’s not optimistic about our ability to find good alignment strategies. We’ll find a safe way to build AGI eventually, but we need enough time to try out enough different approaches to find the correct approach.
One respondent, Alex Turner, would prefer to live in a world where the natural pace is slower, but disagrees with the proposals to pause AI development because he sees it as a panicked response to technical threat models that he considers baseless and nonsensical.
Open source
Nora Belrose’s main concern for the future of AI was extreme inequality rather than AI takeover. She argued that we can combat AI-induced inequality by advocating for and accelerating the development of open-source AI. She pointed out that open-sourcing might cause overall AI capabilities progress to slow down, since, for example, Mistral is reducing OpenAI’s revenue, which means OpenAI has fewer resources to invest in new capabilities. Nora acknowledged that open source increases the risk of misuse, but doesn’t consider things like terrorism a big enough risk to make open source bad overall.
“People who contribute to the Linux kernel are not usually worried about how this is gonna make the Linux kernel a little bit better for terrorists” - Nora Belrose
Most promising research directions
Q4 What research direction (or other activity) do you think will reduce existential risk the most, and what is its theory of change? Could this backfire in some way?
I would often phrase the last sentence as “could this speed up the development of AI capabilities?” and participants would commonly push back on this way of thinking. All useful safety research can, in principle, contribute to the progress in AI capabilities. But what are you going to do, not do any safety research?
“Things that contribute to raw horsepower without contributing anything about understandability or control are negative. And then things that contribute hugely to our ability to understand the situation and control systems are good to do even if they accelerate progress. And a lot of them will accelerate progress somewhat.” - Ajeya Cotra
Richard offered a distinction that he preferred: engineering vs science. “Engineering” is work towards building AI systems that are as powerful as possible, as fast as possible, without necessarily understanding everything about the system or how it will behave. “Science” is work towards understanding machine learning systems, which one can use to predict the behavior of the next frontier model and ultimately learn how to build it safely.
Mechanistic interpretability
“I’d put mechanistic interpretability in the ‘big if true’ category” - Neel Nanda
“It's hard to imagine succeeding without it, unless we just get lucky.” - Evan Hubinger
The most popular answer, at 6 votes (but with 2 negative votes), was mechanistic interpretability (a.k.a. mechinterp): Find ways to reverse engineer neural networks, similar to how one might reverse engineer a compiled binary computer program (3 min explainer, longer intro).
Mechinterp by itself will not solve all of the problems of AI safety, but it may be beneficial to many different components of the safety agenda. It could be useful for:
- Auditing AI systems for dangerous properties like deception before they are deployed.
- Supplying safety metrics as a target for alignment approaches.
- Monitoring AI systems as they are running to look out for dangerous changes in behavior, e.g. goal misgeneralisation or treacherous turns.
- Deconfusion of threat models. For example, can we confirm that stories of goal-directed AI systems taking over are possible by empirically searching for long-term planning or goal-directedness inside neural networks?
- Automating AI safety research.
- Enabling human feedback methods, e.g., interpretability-assisted red-teaming & adversarial training.
- Debugging high-profile failures (e.g., something like the 2010 flash crash but precipitated by advanced AI) to learn from what went wrong.
Some think of mechinterp as a high-potential but speculative bet. That is, we don’t yet know how tractable mechinterp will turn out to be. It may turn out that neural networks are just fundamentally inscrutable – there is no human-understandable structure in there for us to find. But if it does work, it would be a huge win for safety. For example, mechanistic interpretability may give us a way to know with certainty whether an AI system is being honest with us or not. This is sometimes contrasted with more “direct” approaches like scalable oversight: contributing to scalable oversight gives a small but reliable improvement in the safety of AI systems.
Evan Hubinger had a somewhat different view: he considered mechinterp to be essential to building safe AI systems. He considers deception to be the main dangerous property we should be testing for in AI systems and argued that mechinterp is the only way we can totally rule out deception. He discussed how alternative approaches to searching for deception will not be reliable enough:
“So I'm gonna try to find deception with some algorithm: I set up my search procedure and I have a bunch of inductive biases, and a loss function. It may be the case that the search procedure just doesn't find deceptive things. But currently at least, we have very little ability to understand how changing the parameters of your search changes the likelihood of finding a deceptive model, right? You can tinker with it all you want, and maybe tinkering with it actually has a huge impact. But if you don't know what the direction of that impact is, it's not that helpful. The thing that actually lets you understand whether in fact the model is doing some deceptive thing in a relatively robust way is interpretability” - Evan Hubinger
Black box evaluations
4 people were excited about black box evaluations – ways of testing a model for dangerous properties by studying its external behavior. If mechanistic interpretability is neuroscience, then black box evaluations is behavioral psychology. Here’s an example of this kind of work.
Black box evaluations have qualitatively all of the same benefits as mechinterp listed above, but in a more limited way (mechinterp gives us guarantees, black box evaluations gives us easy wins). Ajeya Cotra and Ryan Greenblatt [AF · GW] reckoned that more work should be going into black box evaluations relative to mechinterp than is the case right now.
“We have a lot of traction on this thing [black box evaluations] that could get up to 85% of what we need, and we have no traction on this other thing [mechinterp] and no good definition for it. But people have in their hearts that it could get us to 100% if we made breakthroughs, but I don't think we necessarily have the time.” - Ajeya Cotra
The concrete recommendations that came up were: capabilities evaluations, externalized reasoning oversight (short & long intro [LW · GW]), red-teaming (see here [LW · GW]), and eliciting latent knowledge (see here [? · GW]).
Governance research and technical research useful for governance
4 respondents want more people to do work that will help AI be effectively governed.
David Krueger was interested in work that motivates the need for governance. Those outside AI circles, including policymakers, don't yet understand the risks involved.
“It's hard for people to believe that the problem is as bad as it actually is. So any place where they have gaps in their knowledge, they will fill that in with wildly optimistic assumptions.” - David Krueger
We should communicate more technical information to policymakers, like pointing out that we don’t understand how neural networks work internally, robustness has not been solved even though it’s been an open problem for 10 years, making threat models more specific and concrete, and showing effective demos of dangerous behaviors in AI.
David also suggested “showing what you can and can’t accomplish”:
“Say you want to prevent large-scale use of agentic AI systems to manipulate people's political beliefs. Is this a reasonable thing to expect to accomplish through banning that type of use, or do you need to think about controlling the deployment of these systems?” - David Krueger
Ben focussed on compute governance: investigating questions like “how can an international watchdog detect if a certain party is training a large model?”.
Ben conceded that regulation has the potential to backfire, in that it causes “careful” countries to slow down relative to other more “reckless” countries. This could lead the first country to develop AGI to be one that would develop it in an unsafe way. It sounds like we need to strike some balance here. David also warned that just passing a laws may not be enough:
“You might also have to worry about shifting norms that might underwrite the legitimacy of the policy. There's lots of laws that are widely viewed as illegitimate or only having some limited legitimacy., Speed limits are not considered seriously by most people as something that you absolutely must obey, we all expect that people are going to speed to some extent, it’s very normalized. I expect the incentive gradients here are going to be very strong towards using AI for more and more stuff, and unless we are really able to police the norms around use effectively, it’s going to get really hard to avoid that.” - David Krueger
Other technical work
2 respondents were interested in ways to control potentially dangerous AI systems besides influencing their goals:
“We should be setting up the technical intervention necessary to accurately check whether or not AIs could bypass control countermeasures, then also making better countermeasures that ensure we're more likely to catch AIs or otherwise prevent them from doing bad actions.” - Ryan Greenblatt
Ben mentioned research into how to build off-switches, so we can stop a rogue AI in its tracks. It’s a non-trivial problem to design a way to quickly shut down an AI system, because we design the data centers that AI systems run on with robustness principles: they are designed to continue running through power outages and the like.
Adam was an advocate for researching AI robustness: how to design AI that is robust to adversarial attacks. Robustness is crucial to scalable oversight: most proposed oversight approaches require adversarially robust overseers:
“We already have a number of alignment approaches that involve one AI system providing supervision to another system [...] if every system in this hierarchy can be exploited, then you’re very likely to just get a bunch of systems hacking each other that will be quite difficult to detect.” - Adam Gleave
It’s also useful for preventing misuse: if we can make LLMs harder to jailbreak, then it will be harder for individuals to use them in damaging ways.
Gillian Hadfield’s framing of AI safety was all about making sure AI has normative competence: the ability to infer the rules of society from observation. So the technical work she was interested in was learning how to build normatively competent systems. A normatively competent AI is different from an aligned “good little obedient model”, because:
“These days, there are a lot of signs that say you must wear a mask or stand six feet apart. But we're all normatively competent to know that those are not actually the rules anymore. Now, maybe some environments are what they are. Maybe I'm in a hospital, or maybe I'm in an environment with a community that is getting anxious about COVID again. So that normative competence requires reading what the equilibrium is.” - Gillan Hadfield
She is currently working on multi-agent reinforcement learning experiments to find out if reinforcement learning can imbue normative competence in agents.
Other honorable mentions included singular learning theory [? · GW], steering vectors [LW · GW], and shard theory [LW · GW].
Conclusion
When asked how AI safety might prevent disaster, respondents focussed most on 1) the technical solutions we might come up with, 2) spreading a safety mindset through AI research, 3) promoting sensible AI regulation, and 4) building a fundamental science of AI. The research directions people were most excited about were mechanistic interpretability, black box evaluations, and governance research.
Personally, I’m feeling considerably less nihilistic about AI safety after talking to all these people about how we can improve things. The world is complicated and there’s still a chance we get things wrong, but working hard to understand the problem and propose solutions seems a lot better than inaction. I’m also now more sympathetic to the view that we should just be improving the general understanding of the problem (both scientifically and to the public), instead of trying to intentionally nudge AI development in a particular direction through complicated strategies and back-room deals and playing 4D chess.
Appendix
Participant complaints for Q3
There was a common complaint that “the AI safety community” is not well-defined: Who is part of this community? When prompted, I would typically define the AI safety community along the lines of “everyone who is trying to prevent an existential catastrophe due to AI”. Most participants conceded the ambiguity at this point to answer the question, although were not fully satisfied with the definition.
Richard Ngo convinced me that the way I had formulated the question was unhelpful. If I had interviewed him near the beginning of the project I would have changed it, but unfortunately he was the second-to-last person I talked to!
His argument was this. If the question conditions on the AI safety community improving the future by preventing catastrophe, then the answers may involve strategies that can have arbitrarily high downside risk, because in this hypothetical world, those downsides did not play out. High-variance gambles like trying to melt all the GPUs in the world may work incredibly well in 0.1% of cases (so will be a valid answer to this question) but will fail and backfire >99% of the time, so are perhaps not a helpful approach to focus on.
1 comments
Comments sorted by top scores.
comment by Moneer Moukaddem (moneer-moukaddem) · 2025-02-06T22:09:10.722Z · LW(p) · GW(p)
Such direction-setting exercises and perspective-gathering from across the field, as demonstrated in this article, seem incredibly valuable for understanding the AI safety landscape. Given how rapidly the AI landscape evolves, it might be worth considering how such field-wide perspective-gathering could remain current and representative over time. Perhaps there's value in exploring mechanisms for continuous feedback loops across the AI safety landscape to help track shifting priorities and emerging concerns. I'm curious whether an actor or institution focused on maintaining these feedback loops could help bridge perspectives across technical research, governance, and policy domains, keeping a finger on the pulse of this complex field?