MDP models are determined by the agent architecture and the environmental dynamics
post by TurnTrout · 2021-05-26T00:14:00.699Z · LW · GW · 34 commentsContents
34 comments
Seeking Power is Often Robustly Instrumental in MDPs [LW · GW] relates the structure of the agent's environment (the 'Markov decision process (MDP) model') to the tendencies of optimal policies for different reward functions in that environment ('instrumental convergence'). The results tell us what optimal decision-making 'tends to look like' in a given environment structure, formalizing reasoning that says e.g. that most agents stay alive because that helps them achieve their goals.
Several people have claimed to me that these results need subjective modelling decisions. For example, ofer wrote [LW(p) · GW(p)]:
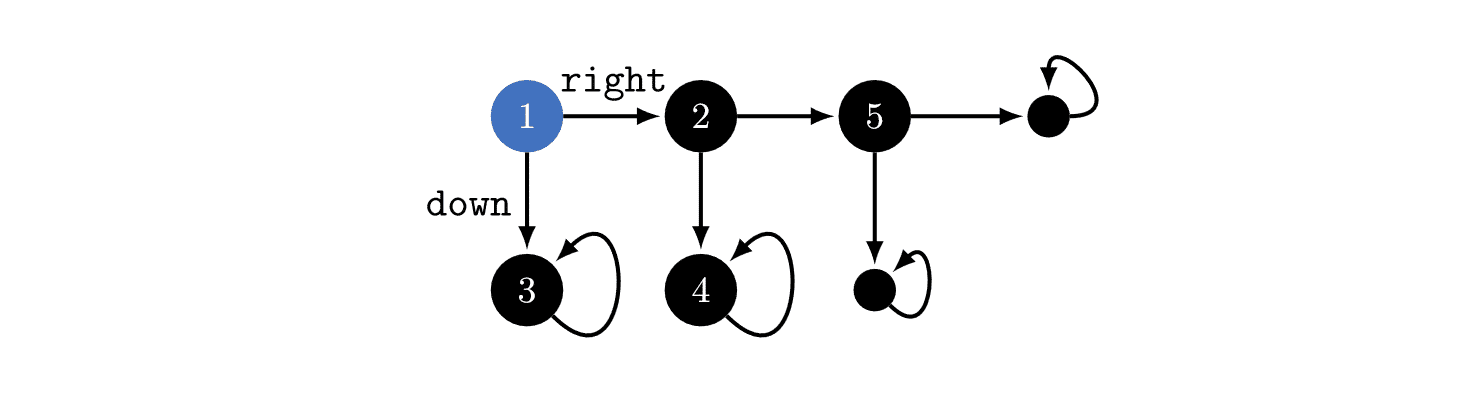
I think using a well-chosen reward distribution is necessary, otherwise POWER depends on arbitrary choices in the design of the MDP's state graph. E.g. suppose the student [in a different example] writes about every action they take in a blog that no one reads, and we choose to include the content of the blog as part of the MDP state. This arbitrary choice effectively unrolls the state graph into a tree with a constant branching factor (+ self-loops in the terminal states) and we get that the POWER of all the states is equal.
In the above example, you could think about the environment as in the above image, or you could imagine that state '3' is actually a million different states which just happen to seem similar to us! If that were true, then optimal policies would tend to go , since that would give the agent millions of choices about where it ends up. Therefore, the power-seeking theorems depend on subjective modelling assumptions.
I used to think this, but this is wrong. The MDP model is determined by the agent's implementation + the task's dynamics.
To make this point, let's back out to a more familiar MDP: Pac-Man.
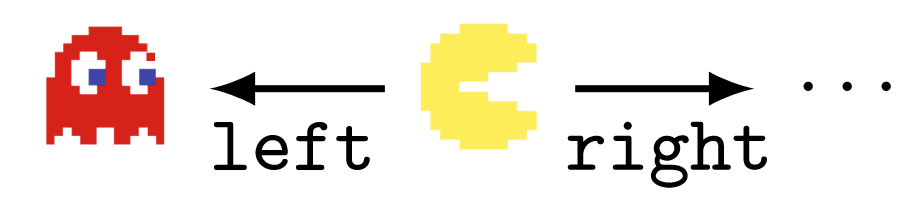
When the discount rate is near 1, most reward functions avoid immediately dying to the ghost, because then they'd be stuck in a terminal state (the red-ghost-game-over state). But why can't the red ghost be equally well-modeled as secretly being 5 googolplex different terminal states?
An MDP model (technically, a rewardless MDP) is a tuple , where is the state space, is the action space, and is the (potentially stochastic) transition function which says what happens when the agent takes different actions at different states. has to be Markovian, depending only on the observed state and the current action, and not on prior history.
Whence cometh this MDP model? Thin air? Is it just a figment of our imagination, which we use to understand what the agent is doing as it learns a policy?
When we train a policy function in the real world, the function takes in an observation (the state) and outputs (a distribution over) actions. When we define state and action encodings, this implicitly defines an "interface" between the agent and the environment. The state encoding might look like "the set of camera observations" or "the set of Pac-Man game screens", and actions might be numbers 1-10 which are sent to actuators, or to the computer running the Pac-Man code, etc.
(In the real world, the computer simulating Pac-Man may suffer a hardware failure / be hit by a gamma ray / etc, but I don't currently think these are worth modelling over the timescales over which we train policies.)
Suppose that for every state-action history, what the agent sees next depends only on the currently observed state and the most recent action taken. Then the environment is Markovian (transition dynamics only depend on what you do right now, not what you did in the past) and fully observable (you can see the whole state all at once), and the agent encodings have defined the MDP model.
In Pac-Man, the MDP model is uniquely defined by how we encode states and actions, and the part of the real world which our agent interfaces with. If you say "maybe the red ghost is represented by 5 googolplex states", then that's a falsifiable claim about the kind of encoding we're using.
That's also a claim that we can, in theory, specify reward functions which distinguish between 5 googolplex variants of red-ghost-game-over. If that were true, then yes - optimal policies really would tend to "die" immediately, since they'd have so many choices.
The "5 googolplex" claim is both falsifiable and false. Given an agent architecture (specifically, the two encodings), optimal policy tendencies are not subjective. We may be uncertain about the agent's state- and action-encodings, but that doesn't mean we can imagine whatever we want.
(I think that the same point holds for other environment types, like POMDPs.)
34 comments
Comments sorted by top scores.
comment by adamShimi · 2021-05-26T10:18:53.709Z · LW(p) · GW(p)
Despite agreeing with your conclusion, I'm unconvinced by the reasons you propose. Sure, once the interface is chosen, then the MDP is pretty much constrained by the real-world (for a reasonable modeling process). But that just means the subjectivity comes from the choice of the interface!
To be more concrete, maybe the state space of Pacman could be red-ghost, starting-state and live-happily-ever-after (replacing the right part of the MDP). Then taking the right action wouldn't be power-seeking either.
What I think is happening here is that in reality, there is a tradeoff in modeling between simplicity/legibility/usability of the model (pushing for fewer states and fewer actions) and performance/competence/optimality (pushing for more states and actions to be able to capture more subtle cases). The fact that we want performance rules out my Pacman variant, and the fact that we want simplicity rules out ofer's example.
It's not clear to me that there is one true encoding that strikes a perfect balance, but I'm okay with the idea that there is an acceptable tradeoff and models around that point are mostly similar, in ways that probably doesn't change the power-seeking.
That's also a claim that we can, in theory, specify reward functions which distinguish between 5 googolplex variants of
red-ghost-game-over. If that were true, then yes - optimal policies really would tend to "die" immediately, since they'd have so many choices.The "5 googolplex" claim is both falsifiable and false. Given an agent architecture (specifically, the two encodings), optimal policy tendencies are not subjective. We may be uncertain about the agent's state- and action-encodings, but that doesn't mean we can imagine whatever we want.
Sure, but if you actually have to check the power-seeking to infer the structure of the MDP, it becomes unusable for not building power-seeking AGIs. Or put differently, the value of your formalization of power-seeking IMO is that we can start from the models of the world and think about which actions/agent would be power-seeking and for which rewards. If I actually have to run the optimal agents to find out about power-seeking actions, then that doesn't help.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-26T13:05:21.241Z · LW(p) · GW(p)
I'm wondering whether I properly communicated my point. Would you be so kind as to summarize my argument as best you understand it?
But that just means the subjectivity comes from the choice of the interface!
There's no subjectivity? The interface is determined by the agent architecture we use, which is an empirical question.
Sure, but if you actually have to check the power-seeking to infer the structure of the MDP, it becomes unusable for not building power-seeking AGIs. Or put differently, the value of your formalization of power-seeking IMO is that we can start from the models of the world and think about which actions/agent would be power-seeking and for which rewards. If I actually have to run the optimal agents to find out about power-seeking actions, then that doesn't help.
You don't have to run anything to check power-seeking. Once you know the agent encodings, the rest is determined and my theory makes predictions.
Replies from: adamShimi↑ comment by adamShimi · 2021-05-26T13:56:26.294Z · LW(p) · GW(p)
I'm wondering whether I properly communicated my point. Would you be so kind as to summarize my argument as best you understand it?
My current understanding is something like:
- There is not really a subjective modeling decision involved because given an interface (state space and action space), the dynamics of the system are a real world property we can look for concretely.
- Claims about the encoding/modeling can be resolved thanks to power-seeking, which predicts what optimal policies are more likely to do. So with enough optimal policies, we can check the claim (like the "5-googleplex" one).
There's no subjectivity? The interface is determined by the agent architecture we use, which is an empirical question.
I would say the choice of agent architecture is the subjective decision. That's the point at which we decide what states and actions are possible, which completely determines the MDP. Granted, this argument is probably stronger for POMDP (for which you have more degrees of freedom in observations), but I still see it for MDP.
If you don't think there is subjectivity involved, do you think that for whatever (non-formal) problem we might want to solve, there is only one way to encode it as a state space and action space? Or are you pointing out that with an architecture in mind, the state space and action space is fixed? I agree with the latter, but then it's a question of how the states of the actual systems are encoded in the state space of the agent, and that doesn't seem unique to me.
You don't have to run anything to check power-seeking. Once you know the agent encodings, the rest is determined and my theory makes predictions.
But to falsify the "5 googolplex", you do need to know what the optimal policies tend to do, right? Then you need to find optimal policies and know what they do (to check that they indeed don't power-seek by going left). This means run/simulate them, which might cause them to take over the world in the worst case scenarios.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-06-02T18:39:54.686Z · LW(p) · GW(p)
(I continued this discussion with Adam in private - here are some thoughts for the public record)
- There is not really a subjective modeling decision involved because given an interface (state space and action space), the dynamics of the system are a real world property we can look for concretely.
- Claims about the encoding/modeling can be resolved thanks to power-seeking, which predicts what optimal policies are more likely to do. So with enough optimal policies, we can check the claim (like the "5-googleplex" one).
I think I'm claiming first bullet. I am not claiming the second.
Or are you pointing out that with an architecture in mind, the state space and action space is fixed? I agree
Yes, that.
then it's a question of how the states of the actual systems are encoded in the state space of the agent, and that doesn't seem unique to me.
It doesn't have to be unique. We're predicting "for the agents we build, will optimal policies in their MDP models seek power?", and once you account for the environment dynamics, our beliefs about the agent architecture, and then our beliefs on the reward functions conditional on each architecture, this prediction has no subjective degrees of freedom.
I'm not claiming that there's One Architecture To Rule Them All. I'm saying that if we want to predict what happens, we:
- Consider the underlying environment (assumed Markovian)
- Consider different state/action encodings we might supply the agent.
- For each, fix a reward function distribution (what goals we expect to assign to the agent)
- See what my theory predicts.
There's a further claim (which seems plausible, but which I'm not yet making) that (2) won't affect (4) very much in practice. The point of this post is that if you say "the MDP has a different model", you're either disagreeing with (1) the actual dynamics, or claiming that we will physically supply the agent with a different state/action encoding (2).
But to falsify the "5 googolplex", you do need to know what the optimal policies tend to do, right? Then you need to find optimal policies and know what they do (to check that they indeed don't power-seek by going left). This means run/simulate them, which might cause them to take over the world in the worst case scenarios.
To falsify "5 googolplex", all you have to know is the dynamics + the agent's observation and action encodings. That determines the MDP structure. You don't have to run anything. (Although I suppose your proposed direction of inference is interesting: power-seeking tendencies + dynamics give you evidence about the encoding)

The encodings + environment dynamics tell you what model the agent is interfacing with, which allows you to apply my theorems as usual.
comment by mingyuan · 2021-06-02T16:36:49.806Z · LW(p) · GW(p)
Your link in the first sentence is broken; it should go to https://www.alignmentforum.org/posts/6DuJxY8X45Sco4bS2/seeking-power-is-often-robustly-instrumental-in-mdps [AF · GW]
comment by Ofer (ofer) · 2021-05-26T13:46:49.399Z · LW(p) · GW(p)
I agree that in MDP problems in which the agent can lose its ability to influence the environment, we can generally expect POWER to correlate with not-losing-the-ability-to-influence-the-environment. The environments in such problems never have a state graph that is a tree-with-a-constant-branching-factor, no matter how complex they are, and thus my argument doesn't apply to them. (And I think publishing work about such MDP environments may be very useful.)
I don't think all real-world problems are like that (though many are), and the choice of the state representation and action space may determine whether a problem is like that. For example, consider a salesperson-like chatbot where an episode is a single exchange with a customer. If implemented via RL, the state representation may be uniquely determined by all the text that was written so far by both the customer and the chatbot. But does this include messages that the chatbot sent after the customer closed their browser window? If so POWER—when defined over an IID-over-states reward distribution—is constant.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-26T15:05:14.550Z · LW(p) · GW(p)
the choice of the state representation and action space may determine whether a problem is like that.
I agree. Also: the state and action representations determine which reward functions we can express, and I claim that it makes sense for the theory to reflect that fact.
If so POWER—when defined over an IID-over-states reward distribution—is constant.
Agreed. I also don't currently see a problem here. There aren't any robustly instrumental goals in this setting, as best I can tell.
Replies from: ofer↑ comment by Ofer (ofer) · 2021-05-26T17:21:20.544Z · LW(p) · GW(p)
There aren't any robustly instrumental goals in this setting, as best I can tell.
If we consider a sufficiently high level of capability, the instrumental convergence thesis applies. (E.g. the agent might manipulate/hack the customer and then gain control over resources, and stop anyone from interfering with its plan.)
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-26T18:48:02.263Z · LW(p) · GW(p)
The instrumental convergence thesis is not a fact about every situation involving "capable AI", but a thesis pointing out a reliable-seeming pattern across environments and goals. It can't be used as a black-box reason on its own - you have to argue why the reasoning applies in the environment. In particular, we assumed that the agent is interacting with the text MDP, where
the state representation [is] uniquely determined by all the text that was written so far by both the customer and the chatbot [, and the chat doesn't end when the customer leaves / stops talking].
Optimal policies do not have particular tendencies in this model. There's nothing more "capable" than an optimal policy. Which is to say, optimal policies for the actual text interaction MDP do not exhibit instrumental convergence (which says nothing about learned optimizer risks, etc).
But you seem to be secretly switching from the pure-text-interaction-MDP to a real-world-modelling-MDP, and then saying that POWER in the former doesn't correspond to POWER in the latter. Well, that's no big surprise. The real world MDP model is no longer modelling just the text interaction, but also the broader environment, which violates the very representation assumption which led to your "IID-POWER equality" conclusion.
And if you update the encodings and dynamics to account for real-world resource gain possibilities, then POWER and optimality probability will update accordingly and appropriately.
However, if you meant for the environment dynamics to originally include possibilities like "the agent can get shut off, or interfered with", then the model is no longer regular in the way you mentioned, and IID-POWER is no longer equal across states.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-26T19:12:08.399Z · LW(p) · GW(p)
To further clarify:
- pure-text-interaction-MDP: generated by the mentioned state and action representation, with environment dynamics allowing the agent to talk to a customer.
- Since you said that the induced model is regular, this implies that the agent won't get shut down for saying bad/weird things. If it could, then the graph is no longer regular under the previous state and action representations.
- The agent also isn't concerned with real-world resources, because it isn't modelling them. They aren't observable and they don't affect transition probabilities.
↑ comment by Ofer (ofer) · 2021-05-26T20:00:45.842Z · LW(p) · GW(p)
I was imagining a formal (super-complex) MDP that looks like our world. The customer in my example is meant to be equivalent to a human on earth.
But I haven't taken into account that this runs into embedded agency issues. (E.g. how does the state transition function look like when the computer that "runs the agent" is down?)
And if you update the encodings and dynamics to account for real-world resource gain possibilities, then POWER and optimality probability will update accordingly and appropriately.
Because states from which the agent can (say) prevent its computer from being turned off have larger POWER? That's an interesting point that didn't occur to me while writing that comment. Though it involves the unresolved (for me) embedded agency issues. Let's side-step those issues by not having a computer running the agent inside the environment, but rather having the text string that the agent chooses in each time step magically appear somewhere in the environment. The question is now whether it's possible to get to the same state with two different sequences of strings. This depends on the state representation & state transition function; it can be the case that the state is uniquely determined by the agent's sequence of past strings so far, which will mean POWER being equal in all states.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-26T20:37:13.393Z · LW(p) · GW(p)
Though it involves the unresolved (for me) embedded agency issues.
Right, that does complicate things. I'd like to get a better picture of the considerations here, but given how POWER behaves on environment structures so far, I'm pretty confident it'll adapt to appropriate ways of modelling the situation.
Let's side-step those issues by not having a computer running the agent inside the environment, but rather having the text string that the agent chooses in each time step magically appear somewhere in the environment. The question is now whether it's possible to get to the same state with two different sequences of strings. This depends on the state representation & state transition function; it can be the case that the state is uniquely determined by the agent's sequence of past strings so far, which will mean POWER being equal in all states.
OK, but now that seems okay again, because there isn't any instrumental convergence here either. This is just an alternate representation ('reskin') of a sequential string output MDP, where the agent just puts a string in slot t at time t.
Replies from: ofer↑ comment by Ofer (ofer) · 2021-05-26T21:44:03.477Z · LW(p) · GW(p)
OK, but now that seems okay again, because there isn't any instrumental convergence here either. This is just an alternate representation ('reskin') of a sequential string output MDP, where the agent just puts a string in slot t at time t.
I think we're still not thinking about the same thing; in the example I'm thinking about the agent is supposed to fill the role of a human salesperson, and the reward function is (say) the amount of money that the client paid (possibly over a long time period). So an optimal policy may be very complicated and involve instrumentally convergent goals.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-26T21:54:41.138Z · LW(p) · GW(p)
For that particular reward function, yes, the optimal policies may be very complicated. But why are there instrumentally convergent goals in that environment? Why should I expect capable agents in that environment to tend to output certain kinds of string sequences, over other kinds of string sequences?
(Also, is the amount of money paid by the client part of the state? Or is the agent just getting rewarded for the total number of purchase-assents in the conversation over time?)
Replies from: ofer↑ comment by Ofer (ofer) · 2021-05-27T10:12:38.228Z · LW(p) · GW(p)
is the amount of money paid by the client part of the state?
Yes; let's say the state representation determines the location of every atom in that earth-like environment. The idea is that the environment is very complicated (and contains many actors) and thus the usual arguments for instrumental convergence apply. (If this fails to address any of the above issues let me know.)
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-27T13:44:10.440Z · LW(p) · GW(p)
Yeah, i claim that this intuition is actually wrong and there's no instrumental convergence in this environment. Complicated & contains actors doesn't mean you can automatically conclude instrumental convergence. The structure of the environment is what matters for "arbitrarily capable agents"/optimal policies (learned policies are probably more dependent on representation and training process).
So if you disagree, please explain why arbitrary reward functions tend to incentivize outputting one string sequence over another? Because, again, this environment is literally isomorphic to
a sequential string output MDP, where the agent just puts a string in slot t at time t.
What I think you're missing is that the environment can't affect the agent's capabilities or available actions; it can't gain or lose power, just freely steer through different trajectories.
Replies from: ofer↑ comment by Ofer (ofer) · 2021-05-28T12:27:51.508Z · LW(p) · GW(p)
So if you disagree, please explain why arbitrary reward functions tend to incentivize outputting one string sequence over another?
(Setting aside the "arbitrary" part, because I didn't talk about an arbitrary reward function…)
Consider a string, written by the chatbot, that "hacks" the customer and cause them to invoke a process that quickly takes control over most of the computers on earth that are connected to the internet, then "hacks" most humans on earth by showing them certain content, and so on (to prevent interferences and to seize control ASAP); for the purpose of maximizing whatever counts as the total discounted payments by the customer (which can look like, say, setting particular memory locations in a particular computer to a particular configuration); and minimizing low probability risks (from the perspective of the agent).
If such a string (one that causes the above scenario) exists, then any optimal policy will either involve such a string or different strings that allow at least as much expected return.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-28T15:58:48.754Z · LW(p) · GW(p)
Setting aside the "arbitrary" part, because I didn't talk about an arbitrary reward function…
To clarify: when I say that taking over the world is "instrumentally convergent", I mean that most objectives incentivize it. If you mean something else, please tell me. (I'm starting to think there must be a serious miscommunication somewhere if we're still disagreeing about this?)
So we can't set the 'arbitrary' part aside - instrumentally convergent means that the incentives apply across most reward functions - not just for one. You're arguing that one reward function might have that incentive. But why would most goals tend to have that incentive?
to prevent interferences and to seize control ASAP...
minimizing low probability risks (from the perspective of the agent)
This doesn't make sense to me. We assumed the agent is Cartesian-separated from the universe, and its actions magically make strings appear somewhere in the world. How could humans interfere with it? What, concretely, are the "risks" faced by the agent?
for the purpose of maximizing whatever counts as the total discounted payments by the customer
(Technically, the agent's goals are defined over the text-state, and you can assign high reward to text-states in which people bought stuff. But the agent doesn't actually have goals over the physical world as we generally imagine them specified.)
If such a string (one that causes the above scenario) exists, then any optimal policy will either involve such a string or different strings that allow at least as much expected return.
This statement is vacuous, because it's true about any possible string.
----
The original argument given for instrumental convergence and power-seeking is that gaining resources tends to be helpful for most objectives (this argument isn't valid in general, but set that aside for now). But even that's not true here. The problem is that the 'text-string-world' model is framed in a leading way, which is suggestive of the usual power-seeking setting (it's representing the real world and it's complicated, there must be instrumental convergence), even though it's structurally a whole different beast.
Objective functions induce preferences over text-states (with a "what's the world look like?" tacked on). The text-state the agent ends up in is, by your assumption, determined by the text output of the agent. Nothing which happens in the world expands or restrict's the agent's ability to output text. So there's no particular reason for optimal policies to tend to output strings that induce text-histories in which the world contains a disempowered human civilization.
Another way to realize that optimal policies don't have this tendency is that optimal policy tendencies are invariant to model isomorphism, and, again, this environment is literally isomorphic to
a sequential string output MDP, where the agent just puts a string in slot t at time t.
If it were true that optimal agents tend to "take over the world" in the 'real-world' model, then it would be true in the sequential string output model, which is absurd.
I know I've said this several times, but this is a knock-down argument, and you haven't engaged with it. If you take a piece of paper and draw out a model for the following environment - it will be a regular tree:
Let's side-step those issues by not having a computer running the agent inside the environment, but rather having the text string that the agent chooses in each time step magically appear somewhere [fixed] in the environment. The question is now whether it's possible to get to the same state with two different sequences of strings. This depends on the state representation & state transition function; it can be the case that the state is uniquely determined by the agent's sequence of past strings so far, which will mean POWER being equal in all states.
You may already know that, because you quickly pointed out that POWER is constant. But then why do you claim that most reward functions are attracted to certain branches of the tree, given that regularity? And if you aren't claiming that, what do you mean by instrumental convergence?
Replies from: ofer↑ comment by Ofer (ofer) · 2021-05-28T21:00:30.267Z · LW(p) · GW(p)
So we can't set the 'arbitrary' part aside - instrumentally convergent means that the incentives apply across most reward functions - not just for one. You're arguing that one reward function might have that incentive. But why would most goals tend to have that incentive?
I was talking about a particular example, with a particular reward function that I had in mind. We seemed to disagree about whether instrumental convergence arguments apply there, and my purpose in that comment was to argue that they do. I'm not trying to define here the set of reward functions over which instrumental convergence argument apply (they obviously don't apply to all reward functions, as for every possible policy you can design a reward function for which that policy is optimal).
This doesn't make sense to me. We assumed the agent is Cartesian-separated from the universe, and its actions magically make strings appear somewhere in the world. How could humans interfere with it? What, concretely, are the "risks" faced by the agent?
E.g. humans noticing that something weird is going on and trying to shut down the process. (Shutting down the process doesn't mean that new strings won't appear in the environment and cause the state graph to become a tree-with-constant-branching-factor due to complex physical dynamics.)
(Technically, the agent's goals are defined over the text-state
Not in the example I have in mind. Again, let's say the state representation determines the location of every atom in that earth-like environment. (I think that's the key miscommunication here; the MDP I'm thinking about is NOT a "sequential string output MDP", if I understand your use of that phrase correctly. [EDIT: my understanding is that you use that phrase to describe an MDP in which a state is just the sequence of strings in the exchange so far.] [EDIT 2: I think this miscommunication is my fault, due to me writing in my first comment: "the state representation may be uniquely determined by all the text that was written so far by both the customer and the chatbot", sorry for that.])
This statement is vacuous, because it's true about any possible string.
I agree the statement would be true with any possible string; this doesn't change the point I'm making with it. (Consider this to be an application of the more general statement with a particular string.)
But then why do you claim that most reward functions are attracted to certain branches of the tree, given that regularity?
For every subset of branches in the tree you can design a reward function for which every optimal policy tries to go down those branches; I'm not saying anything about "most rewards functions". I would focus on statements that apply to "most reward functions" if we dealt with an AI that had a reward function that was sampled uniformly from all possible rewards function. But that scenario does not seem relevant (in particular, something like Occam's razor seems relevant: our prior credence should be larger for reward functions with shorter shortest-description).
what do you mean by instrumental convergence?
The non-formal definition in Bostrom's Superintelligence (which does not specify a set of rewards functions but rather says "a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents.").
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-28T23:58:46.906Z · LW(p) · GW(p)
I'm not trying to define here the set of reward functions over which instrumental convergence argument apply (they obviously don't apply to all reward functions, as for every possible policy you can design a reward function for which that policy is optimal).
ETA: I agree with this point in the main - they don't apply to all reward functions. But, we should be able to ground the instrumental convergence arguments via reward functions in some way. Edited out because I read through that part of your comment a little too fast, and replied to something you didn't say.
Shutting down the process doesn't mean that new strings won't appear in the environment and cause the state graph to become a tree-with-constant-branching-factor due to complex physical dynamics.
What does it mean to "shut down" the process? 'Doesn't mean they won't' - so new strings will appear in the environment? Then how was the agent "shut down"?
[EDIT 2: I think this miscommunication is my fault, due to me writing in my first comment: "the state representation may be uniquely determined by all the text that was written so far by both the customer and the chatbot", sorry for that.]
What is it instead?
For every subset of branches in the tree you can design a reward function for which every optimal policy tries to go down those branches; I'm not saying anything about "most rewards functions". I would focus on statements that apply to "most reward functions" if we dealt with an AI that had a reward function that was sampled uniformly from all possible rewards function. But that scenario does not seem relevant (in particular, something like Occam's razor seems relevant: our prior credence should be larger for reward functions with shorter shortest-description).
We're considering description length? Now it's not clear that my theory disagrees with your prediction, then. If you say we have a simplicity prior over reward functions given some encoding, well, POWER and optimality probability now reflect your claims, and they now say there is instrumental convergence to the extent that that exists under a simplicity prior? (I still don't think they would exist; and my theory shows that in the space of all possible reward function distributions, equal proportions incentivize action A over action B, as vice versa - we aren't just talking about uniform. and so the onus is on you to provide the sense in which instrumental convergence exists here.)
And to the extent we were always considering description length - was the problem that IID-optimality probability doesn't reflect simplicity-weighted behavioral tendencies?
The non-formal definition in Bostrom's Superintelligence (which does not specify a set of rewards functions but rather says "a wide range of final goals and a wide range of situations, implying that these instrumental values are likely to be pursued by a broad spectrum of situated intelligent agents.").
I still don't know what it would mean for Ofer-instrumental convergence to exist in this environment, or not.
Replies from: ofer↑ comment by Ofer (ofer) · 2021-05-31T20:58:17.529Z · LW(p) · GW(p)
I'll address everything in your comment, but first I want to zoom out and say/ask:
- In environments that have a state graph that is a tree-with-constant-branching-factor, the POWER—defined over IID-over-states reward distribution—is equal in all states. I argue that environments with very complex physical dynamics are often like that, but not if at some time step the agent can't influence the environment. (I think we agree so far?) I further argue that we can take any MDP environment and "unroll" its state graph into a tree-with-constant-branching-factor (e.g. by adding an "action log" to the state representation) such that we get a "functionally equivalent" MDP in which the POWER (IID) of all the states are equal. My best guess is that you don't agree with this point, or think that the instrumental convergence thesis doesn't apply in a meaningful sense to such MDPs (but I don't yet understand why).
- Regarding the theorems (in the POWER paper; I've now spent some time on the current version): The abstract of the paper says: "With respect to a class of neutral reward function distributions, we provide sufficient conditions for when optimal policies tend to seek power over the environment." I didn't find a description of those sufficient conditions (maybe I just missed it?). AFAICT, MDPs that contain "reversible actions" (other than self-loops in terminal states) are generally problematic for POWER (IID). (I'm calling action from state "reversible" if it allows the agent to return to at some point). POWER-seeking (in the limit as approaches 1) will always imply choosing a reversible action over a non-reversible action, and if the only reversible action is a self-loop, POWER-seeking means staying in the same state forever. Note that if there are sufficiently many terminal states (or loops more generally) that require a certain non-reversible action to reach, it will be the case that most optimal policies prefer that non-reversible action over any POWER-seeking (reversible) action. In particular, non-terminal self-loops seem to be generally problematic for POWER(IID); for example consider:
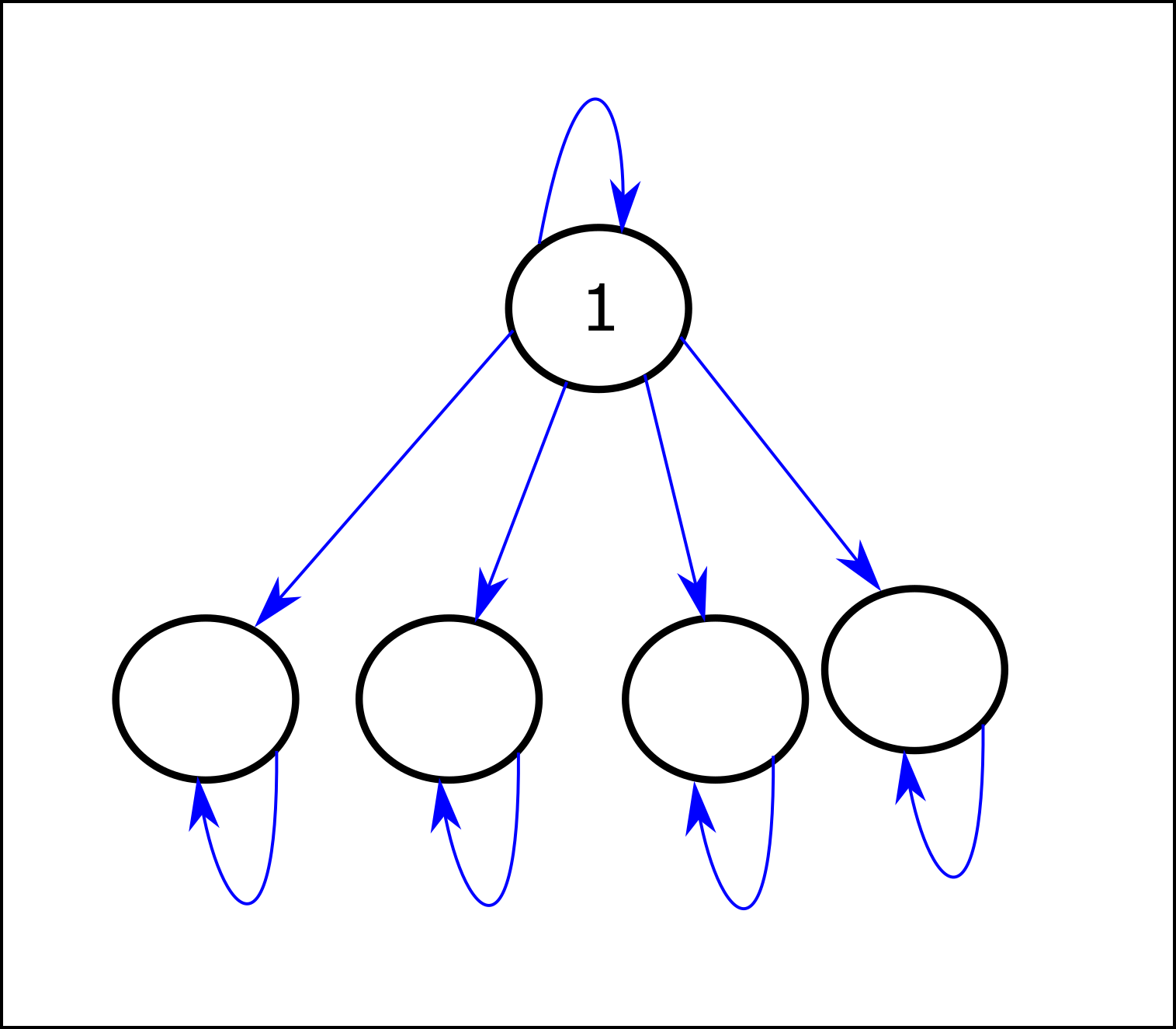
The first state has the largest POWER (IID), but for most reward functions the optimal policy is to immediately transition to a lower-POWER state (even in the limit as approaches 1). The paper says: "Theorem 6.6 shows it’s always robustly instrumental and power-seeking to take actions which allow strictly more control over the future (in a graphical sense)." I don't yet understand the theorem, but is there somewhere a description of the set/distribution of MDP transition functions for which that statement applies? (Specifically, the "always robustly instrumental" part, which doesn't seem to hold in the example above.)
Regarding the points from your last comment:
we should be able to ground the instrumental convergence arguments via reward functions in some way.
Maybe for this purpose we should weight reward functions by how likely we are to encounter an AI system that pursues them (this should probably involve a simplicity prior.)
What does it mean to "shut down" the process? 'Doesn't mean they won't' - so new strings will appear in the environment? Then how was the agent "shut down"?
Suppose the agent causes the customer to invoke some process that hacks a bank and causes recurrent massive payments (trillions of dollars) to appear as being received by the relevant company. Someone at the bank notices this and shuts down the compromised system, which stops the process.
What is it instead?
Suppose the state representation is a huge list of 3D coordinates, each specifying the location of an atom in the earth-like environment. The transition function mimics the laws of physics on Earth (+ "magic" that makes the text that the agent chooses appear in the environment in each time step). It's supposed to be "an Earth-like MDP".
We're considering description length? Now it's not clear that my theory disagrees with your prediction, then. If you say we have a simplicity prior over reward functions given some encoding, well, POWER and optimality probability now reflect your claims, and they now say there is instrumental convergence to the extent that that exists under a simplicity prior?
Are you referring here to POWER when it is defined over a reward distribution that corresponds to some simplicity prior? (I was talking about POWER defined over an IID-over-states reward distribution, which I think is what the theorems in the paper deal with.)
And to the extent we were always considering description length - was the problem that IID-optimality probability doesn't reflect simplicity-weighted behavioral tendencies?
My argument is just that in MDPs where the state graph is a tree-with-a-constant-branching-factor—which is plausible in very complex environments—POWR (IID) is equal in all states. The argument doesn't mention description length (the description length concept arose in this thread in the context of discussing what reward function distribution should be used for defining instrumental convergence).
I still don't know what it would mean for Ofer-instrumental convergence to exist in this environment, or not.
Maybe something like Bostrom's definition when we replace "wide range of final goals" with "reward functions weighted by the probability that we'll encounter an AI that pursues the reward function (which means using a simplicity prior)". It seems to me that your comment assumes/claims something like: "in every MDP where the state graph is a tree-with-a-constant-branching-factor, there is no meaningful sense in which instrumental convergence apply". If so, I argue that claim doesn't make sense: you can take any formal environment, however large and complex, and just add to it a simple "action logger" (that doesn't influence anything, other than effectively adding to the state representation a log of all the actions so far). If the action space is constant, the state graph of the modified MDP is a tree-with-a-constant-branching-factor; which would imply that adding that action logger somehow destroyed the applicability of the instrumental convergence thesis to that MDP; which doesn't make sense to me.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-06-01T21:33:50.791Z · LW(p) · GW(p)
Thanks for taking the time to write this out.
Regarding the theorems (in the POWER paper; I've now spent some time on the current version): The abstract of the paper says: "With respect to a class of neutral reward function distributions, we provide sufficient conditions for when optimal policies tend to seek power over the environment." I didn't find a description of those sufficient conditions (maybe I just missed it?).
I'm sorry - although I think I mentioned it in passing, I did not draw sufficient attention to the fact that I've been talking about a drastically broadened version of the paper, compared to what was on arxiv when you read it. The new version should be up in a few days. I feel really bad about this - especially since you took such care in reading the arxiv version!
The theorems hold for all finite MDPs in which the formal sufficient conditions are satisfied (i.e. the required environmental symmetries exist; see proposition 6.9, theorem 6.13, corollary 6.14). For practical advice, see subsection 6.3 and beginning of section 7.
(I shared the Overleaf with Ofer; if other lesswrong readers want to read without waiting for arxiv to update, message me! ETA: The updated version is now on arxiv.)
I further argue that we can take any MDP environment and "unroll" its state graph into a tree-with-constant-branching-factor (e.g. by adding an "action log" to the state representation) such that we get a "functionally equivalent" MDP in which the POWER (IID) of all the states are equal. My best guess is that you don't agree with this point, or think that the instrumental convergence thesis doesn't apply in a meaningful sense to such MDPs (but I don't yet understand why).
I agree that you can do that. I also think that instrumental convergence doesn't apply in such MDPs (as in, "most" goals over the environment won't incentivize any particular kind of optimal action), unless you restrict to certain kinds of reward functions.
Fix a reward function distribution in the original MDP . For simplicity, let's suppose is max-ent (and thus IID). Let's suppose we agree that optimal policies under tend to avoid getting shut off.
Translated to the rolled-out MDP , no longer distributes reward uniformly over states. In fact, in its support, each reward function has the rather unusual property that its reward is only dependent on the current state, and not on the action log's contents. When translated into , imposes heavy structural assumptions on its reward functions, and it's not max-ent over the states of . By the "functional equivalence", it still gives you the same optimality probabilities as before, and so it still tends to incentivize shutdown avoidance.
However, if you take a max-ent over the rolled-out states of , then this max-ent won't incentivize shutdown avoidance.
To see why, consider how absurdly expressive utility functions are when their domains are entire state-action histories. In Coherence arguments do not imply goal-directed behavior [LW · GW], Rohin Shah wrote:
Actually, no matter what the policy is, we can view the agent as an EU maximizer. The construction is simple: the agent can be thought as optimizing the utility function U, where U(h, a) = 1 if the policy would take action a given history h, else 0.
...
Consider the following examples:
- A robot that constantly twitches
- The agent that always chooses the action that starts with the letter “A”
- The agent that follows the policy <policy> where for every history the corresponding action in <policy> is generated randomly.
These are not goal-directed by my “definition”. However, they can all be modeled as expected utility maximizers
When defined over state-action histories, it's dead easy to write down objectives which don't pursue instrumental subgoals.
However, how easy is it to write down state-based utility functions which do the same? I guess there's the one that maximally values dying. What else? While more examples probably exist, it seems clear that they're much harder to come by.
And so when your reward depends on your action history, this is strictly more expressive than state-based reward - so expressive that it becomes easy to directly incentivize any sequence of actions via the reward function. And thus, instrumental convergence disappears for "most objectives."
However, from our perspective, we still have a distribution over goals we might want to give the agent. And these goals are generally very structured - they aren't just randomly selected preferences over action-histories+current state. So we should still expect instrumental convergence to exist empirically (at a first approximation, perhaps via a simplicity prior over reward functions/utility functions). It just doesn't exist for most "unstructured" distributions in the unrolled environment.
The first state has the largest POWER (IID), but for most reward functions the optimal policy is to immediately transition to a lower-POWER state (even in the limit as approaches 1).
Note that the RSD optimality probability theorem (Theorem 6.13) applies here, and it correctly predicts that when , most reward functions incentivize navigating to the larger set of 1-cycles (the 4 below the high-POWER state). As I explain in section 6.3, section 7, and appendix B of the new paper, you have to be careful in applying Thm 6.13, because


The paper says: "Theorem 6.6 shows it’s always robustly instrumental and power-seeking to take actions which allow strictly more control over the future (in a graphical sense)." I don't yet understand the theorem, but is there somewhere a description of the set/distribution of MDP transition functions for which that statement applies? (Specifically, the "always robustly instrumental" part, which doesn't seem to hold in the example above.)
Yeah, I'm aware of this kind of situation. I think that that sentence from the paper was poorly worded. In the new version, I'm more careful to emphasize the environmental symmetries which are sufficient to conclude power-seeking:
Some researchers speculate that intelligent reinforcement learning agents would be incentivized to seek resources and power in pursuit of their objectives. Other researchers are skeptical, because human-like power-seeking instincts need not be present in RL agents. To clarify this debate, we develop the first formal theory of the statistical tendencies of optimal policies in reinforcement learning. In the context of Markov decision processes, we prove that certain environmental symmetries are sufficient for optimal policies to tend to seek power over the environment. These symmetries exist in many environments in which the agent can be shut down or destroyed. We prove that for most prior beliefs one might have about the agent’s reward function (including as a special case the situations where the reward function is known), one should expect optimal policies to seek power in these environments. These policies seek power by keeping a range of options available and, when the discount rate is sufficiently close to 1, by navigating towards larger sets of potential terminal states.
(emphasis added)
See appendix B of the new paper for an example similar to yours, referenced by subsection 6.3 ("how to reason about other environments").
Are you referring here to POWER when it is defined over a reward distribution that corresponds to some simplicity prior?
Yup! POWER depends on the reward distribution; if you want to reason formally about a simplicity prior, plug it into POWER.
My argument is just that in MDPs where the state graph is a tree-with-a-constant-branching-factor—which is plausible in very complex environments—POWR (IID) is equal in all states. The argument doesn't mention description length (the description length concept arose in this thread in the context of discussing what reward function distribution should be used for defining instrumental convergence).
Right, okay, I agree with that. I think we agree about how POWER works here, but disagree about the link between optimality probability-wrt-a-distribution, and instrumental convergence.
If so, I argue that claim doesn't make sense: you can take any formal environment, however large and complex, and just add to it a simple "action logger" (that doesn't influence anything, other than effectively adding to the state representation a log of all the actions so far). If the action space is constant, the state graph of the modified MDP is a tree-with-a-constant-branching-factor; which would imply that adding that action logger somehow destroyed the applicability of the instrumental convergence thesis to that MDP; which doesn't make sense to me.
Yeah, I think that wrt the action-logger-MDP, instrumental convergence doesn't exist for goals over the new action-logger-MDP. See the earlier part of this comment.
Replies from: ofer↑ comment by Ofer (ofer) · 2021-06-04T20:49:20.545Z · LW(p) · GW(p)
The theorems hold for all finite MDPs in which the formal sufficient conditions are satisfied (i.e. the required environmental symmetries exist; see proposition 6.9, theorem 6.13, corollary 6.14). For practical advice, see subsection 6.3 and beginning of section 7.
It seems to me that the (implicit) description in the paper of the set of environments over which "one should expect optimal policies to seek power" ("for most prior beliefs one might have about the agent’s reward function") involves a lot of formalism/math. I was looking for some high-level/simplified description (in English), and found the following (perhaps there are other passages that I missed):
Loosely speaking, if the “vast majority” of RSDs are only reachable by following a subset of policies, theorem 6.13 implies that that subset tends to be Blackwell optimal.
Isn't the thing we condition on here similar (roughly speaking) to your interpretation of instrumental convergence? (Is the condition for when "[…] one should expect optimal policies to seek power" made weaker by another theorem?)
I agree that you can do that. I also think that instrumental convergence doesn't apply in such MDPs (as in, "most" goals over the environment won't incentivize any particular kind of optimal action), unless you restrict to certain kinds of reward functions.
I think that using a simplicity prior over reward functions has a similar effect to "restricting to certain kinds of reward functions".
I didn't understand the point you were making with your explanation that involved a max-ent distribution. Why is the action logger treated in your explanation as some privileged object? What's special about it relative to all the other stuff that's going on in our arbitrarily complex environment? If you imagine an MDP environment where the agent controls a robot in a room that has a security camera in it, and the recorded video is part of the state, then the recorded video is doing all the work that we need an action logger to do (for the purpose of my argument).
When defined over state-action histories, it's dead easy to write down objectives which don't pursue instrumental subgoals.
In my action-logger example, the action log is just a tiny part of the state representation (just like a certain blog or a video recording are a very tiny part of the state of our universe). The reward function is a function over states (or state-action pairs) as usual, not state-action histories. My "unrolling trick" doesn't involve utility functions that are defined over state(-action) histories.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-06-07T15:30:43.156Z · LW(p) · GW(p)
I was looking for some high-level/simplified description
Ah, I see. In addition to the cited explanation, see also: "optimal policies tend to take actions which strictly preserve optionality*", where the optionality preservation is rather strict (requiring a graphical similarity, and not just "there are more options this way than that"; ironically, this situation is considerably simpler in arbitrary deterministic computable environments, but that will be the topic of a future post).
Isn't the thing we condition on here similar (roughly speaking) to your interpretation of instrumental convergence?
No - the sufficient condition is about the environment, and instrumental convergence is about policies over that environment. I interpret instrumental convergence as "intelligent goal-directed agents tend to take certain kinds of actions"; this informal claim is necessarily vague. This is a formal sufficient condition which allows us to conclude that optimal goal-directed agents will tend to take a certain action in the given situation.
I think that using a simplicity prior over reward functions has a similar effect to "restricting to certain kinds of reward functions".
It certainly has some kind of effect, but I don't find it obvious that it has the effect you're seeking - there are many simple ways of specifying action-history+state reward functions, which rely on the action-history and not just the rest of the state.
Why is the action logger treated in your explanation as some privileged object? What's special about it relative to all the other stuff that's going on in our arbitrarily complex environment? If you imagine an MDP environment where the agent controls a robot in a room that has a security camera in it, and the recorded video is part of the state, then the recorded video is doing all the work that we need an action logger to do (for the purpose of my argument).
What's special is that (by assumption) the action logger always logs the agent's actions, even if the agent has been literally blown up in-universe. That wouldn't occur with the security camera. With the security camera, once the agent is dead, the agent can no longer influence the trajectory, and the normal death-avoiding arguments apply. But your action logger supernaturally writes a log of the agent's actions into the environment.
The reward function is a function over states (or state-action pairs) as usual, not state-action histories. My "unrolling trick" doesn't involve utility functions that are defined over state(-action) histories.
Right, but if you want the optimal policies to take actions , then write a reward function which returns 1 iff the action-logger begins with those actions and 0 otherwise. Therefore, it's extremely easy to incentivize arbitrary action sequences.
Replies from: ofer↑ comment by Ofer (ofer) · 2021-06-08T10:58:12.106Z · LW(p) · GW(p)
see also: "optimal policies tend to take actions which strictly preserve optionality*"
Does this quote refer to a passage from the paper? (I didn't find it.)
It certainly has some kind of effect, but I don't find it obvious that it has the effect you're seeking - there are many simple ways of specifying action-history+state reward functions, which rely on the action-history and not just the rest of the state.
There are very few reward functions that rely on action-history—that can be specified in a simple way—relative to all the reward functions that rely on action-history (you need at least bits to specify a reward function that considers actions, when using a uniform prior). Also, I don't think that the action log is special in this context relative to any other object that constitutes a tiny part of the environment.
What's special is that (by assumption) the action logger always logs the agent's actions, even if the agent has been literally blown up in-universe. That wouldn't occur with the security camera. With the security camera, once the agent is dead, the agent can no longer influence the trajectory, and the normal death-avoiding arguments apply. But your action logger supernaturally writes a log of the agent's actions into the environment.
If we assume that the action logger can always "detect" the action that the agent chooses, this issue doesn't apply. (Instead of the agent being "dead" we can simply imagine the robot/actuators are in a box and can't influencing anything outside the box; which is functionally equivalent to being "dead" if the box is a sufficiently small fraction of the environment.)
Right, but if you want the optimal policies to take actions , then write a reward function which returns 1 iff the action-logger begins with those actions and 0 otherwise. Therefore, it's extremely easy to incentivize arbitrary action sequences.
Sure, but I still don't understand the argument here. It's trivial to write a reward function that doesn't yield instrumental convergence regardless of whether one can infer the complete action history from every reachable state. Every constant function is such a reward function.
Replies from: TurnTrout↑ comment by TurnTrout · 2021-06-08T15:51:19.040Z · LW(p) · GW(p)
Not from the paper. I just wrote it.
I don't think that the action log is special in this context relative to any other object that constitutes a tiny part of the environment.
It isn't the size of the object that matters here, the key considerations are structural. In this unrolled model, the unrolled state factors into the (action history) and the (world state). This is not true in general for other parts of the environment.
Sure, but I still don't understand the argument here. It's trivial to write a reward function that doesn't yield instrumental convergence regardless of whether one can infer the complete action history from every reachable state. Every constant function is such a reward function.
Sure. Here's what I said:
how easy is it to write down state-based utility functions which do the same? I guess there's the one that maximally values dying. What else? While more examples probably exist, it seems clear that they're much harder to come by [than in the action-history case].
The broader claim I was trying to make was not "it's hard to write down any state-based reward functions that don't incentivize power-seeking", it was that there are fewer qualitatively distinct ways to do it in the state-based case. In particular, it's hard to write down state-based reward functions which incentivize any given sequence of actions:
when your reward depends on your action history, this is strictly more expressive than state-based reward - so expressive that it becomes easy to directly incentivize any sequence of actions via the reward function. And thus, instrumental convergence disappears for "most objectives."
If you disagree, then try writing down a state-based reward function for e.g. Pacman for which an optimal policy starts off by (EDIT: circling the level counterclockwise) (at a discount rate close to 1). Such reward functions provably exist, but they seem harder to specify in general.
Also: thanks for your engagement, but I still feel like my points aren't landing (which isn't necessarily your fault or anything), and I don't want to put more time into this right now. Of course, you can still reply, but just know I might not reply and that won't be anything personal.
EDIT: FYI I find your action-camera example interesting. Thank you for pointing that out.
Replies from: ofer↑ comment by Ofer (ofer) · 2021-06-09T12:29:08.061Z · LW(p) · GW(p)
Not from the paper. I just wrote it.
Consider adding to the paper a high-level/simplified description of the environments for which the following sentence from the abstract applies: "We prove that for most prior beliefs one might have about the agent’s reward function [...] one should expect optimal policies to seek power in these environments." (If it's the set of environments in which "the “vast majority” of RSDs are only reachable by following a subset of policies" consider clarifying that in the paper). It's hard (at least for me) to infer that from the formal theorems/definitions.
It isn't the size of the object that matters here, the key considerations are structural. In this unrolled model, the unrolled state factors into the (action history) and the (world state). This is not true in general for other parts of the environment.
My "unrolling trick" argument doesn't require an easy way to factor states into [action history] and [the rest of the state from which the action history can't be inferred]. A sufficient condition for my argument is that the complete action history could be inferred from every reachable state. When this condition fulfills, the environment implicitly contains an action log (for the purpose of my argument), and thus the POWER (IID) of all the states is equal. And as I've argued before, this condition seems plausible for sufficiently complex real-world-like environments. BTW, any deterministic time-reversible environment fulfills this condition, except for cases where multiple actions can yield the same state transition (in which case we may not be able to infer which of those actions were chosen at the relevant time step).
It's easier to find reward functions that incentivize a given action sequence if the complete action history can be inferred from every reachable state (and the easiness depends on how easy it is to compute the action history from the state). I don't see how this fact relates to instrumental convergence supposedly disappearing for "most objectives" [EDIT: when using a simplicity prior over objectives; otherwise, instrumental convergence may not apply regardless]. Generally, if an action log constitutes a tiny fraction of the environment, its existence shouldn't affect properties of "most objectives" (regardless of whether we use the uniform prior or a simplicity prior).
thanks for your engagement
Ditto :)
comment by Past Account (zachary-robertson) · 2021-05-29T00:12:33.511Z · LW(p) · GW(p)
[Deleted]
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-29T14:54:22.896Z · LW(p) · GW(p)
say we agree that our state abstraction needs to be model-irrelevant
Why would we need that, and what is the motivation for "models"? The moment we give the agent sensors and actions, we're done specifying the rewardless MDP (and its model).
ETA: potential confusion - in some MDP theory, the “model” is a model of the environment dynamics. Eg in deterministic environments, the model is shown with a directed graph. i don’t use “model” to refer to an agent’s world model over which it may have an objective function. I should have chosen a better word, or clarified the distinction.
a priori there should be skepticism that all tasks can be modeled with a specific state-abstraction.
If, by "tasks", you mean "different agent deployment scenarios" - I'm not claiming that. I'm saying that if we want to predict what happens, we:
- Consider the underlying environment (assumed Markovian)
- Consider different state/action encodings we might supply the agent.
- For each, fix a reward function distribution (what goals we expect to assign to the agent)
- See what the theory predicts.
There's a further claim (which seems plausible, but which I'm not yet making) that (2) won't affect (4) very much in practice. The point of this post is that if you say "the MDP has a different model", you're either disagreeing with (1) the actual dynamics, or claiming that we will physically supply the agent with a different state/action encoding (2).
I'd suspect this does generalize into a fragility/impossibility result any time the reward is given to the agent in a way that's decoupled from the agent's sensors which is really going to be the prominent case in practice. In conclusion, you can try to work with a variable/rewardless MDP, but then this argument will apply and severely limit the usefulness of the generic theoretical analysis.
I don't follow. Can you give a concrete example?
Replies from: zachary-robertson↑ comment by Past Account (zachary-robertson) · 2021-05-29T18:02:59.714Z · LW(p) · GW(p)
[Deleted]
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-29T22:38:31.112Z · LW(p) · GW(p)
I read your formalism, but I didn't understand what prompted you to write it. I don't yet see the connection to my claims.
If so, I might try to formalize it.
Yeah, I don't want you to spend too much time on a bulletproof grounding of your argument, because I'm not yet convinced we're talking about the same thing.
In particular, if the argument's like, "we usually express reward functions in some featurized or abstracted way, and it's not clear how the abstraction will interact with your theorems" / "we often use different abstractions to express different task objectives", then that's something I've been thinking about but not what I'm covering here. I'm not considering practical expressibility issues over the encoded MDP: ("That's also a claim that we can, in theory, specify reward functions which distinguish between 5 googolplex variants of red-ghost-game-over.")
If this doesn't answer your objection - can you give me an english description of a situation where the objection holds? (Let's taboo 'model', because it's overloaded in this context)
Replies from: zachary-robertson↑ comment by Past Account (zachary-robertson) · 2021-05-30T13:21:16.905Z · LW(p) · GW(p)
[Deleted]
Replies from: TurnTrout↑ comment by TurnTrout · 2021-05-30T15:35:50.587Z · LW(p) · GW(p)
I don't understand your point in this exchange. I was being specific about my usage of model; I meant what I said in the original post, although I noted room for potential confusion in my comment [LW(p) · GW(p)] above. However, I don't know how you're using the word.
I don’t use the term model in my previous reply anyway.
You used the word 'model' in both of your prior comments, and so the search-replace yields "state-abstraction-irrelevant abstractions." Presumably not what you meant?
I already pointed out a concrete difference: I claim it’s reasonable to say there are three alternatives while you claim there are two alternatives.
That's not a "concrete difference." I don't know what you mean when you talk about this "third alternative." You think you have some knockdown argument - that much is clear - but it seems to me like you're talking about a different consideration entirely. I likewise feel an urge to disengage, but if you're interested in explaining your idea at some point, message me and we can set up a higher-bandwidth call.
Replies from: zachary-robertson↑ comment by Past Account (zachary-robertson) · 2021-05-31T20:59:11.912Z · LW(p) · GW(p)
[Deleted]