Learning Values in Practice
post by Stuart_Armstrong · 2020-07-20T18:38:50.438Z · LW · GW · 0 commentsContents
Questions None No comments
(This talk was given at a public online event on Sunday July 12th [? · GW]. Stuart Armstrong is responsible for the talk, Justis Mills edited the transcript.
If you're a curated author and interested in giving a 5-min talk, which will then be transcribed and edited, sign up here.)

Stuart Armstrong: I’m going to talk about Occam’s razor, and what it actually means in practice. First, let’s go recall the No Free Lunch theorem: the surprising idea is that simply given an agent’s behavior, you can’t infer what is good or bad for that agent.

Now the even more surprising result is that, unlike most No Free Lunch theorems, simplicity does not solve the problem. In fact, if you look at the simplest explanations for human behavior, they tend to be things like “humans are fully rational.” So, according to that theory, at every single moment of our lives, every single decision we make is the absolute optimal decision we could have made. Other simple explanations might be that humans are fully anti-rational or humans have flat (or zero) preferences.

To explore one part of the problem, I'm going to start with a situation where you know everything about the agent. You know the agent has an input device that takes observations, which feed into knowledge.
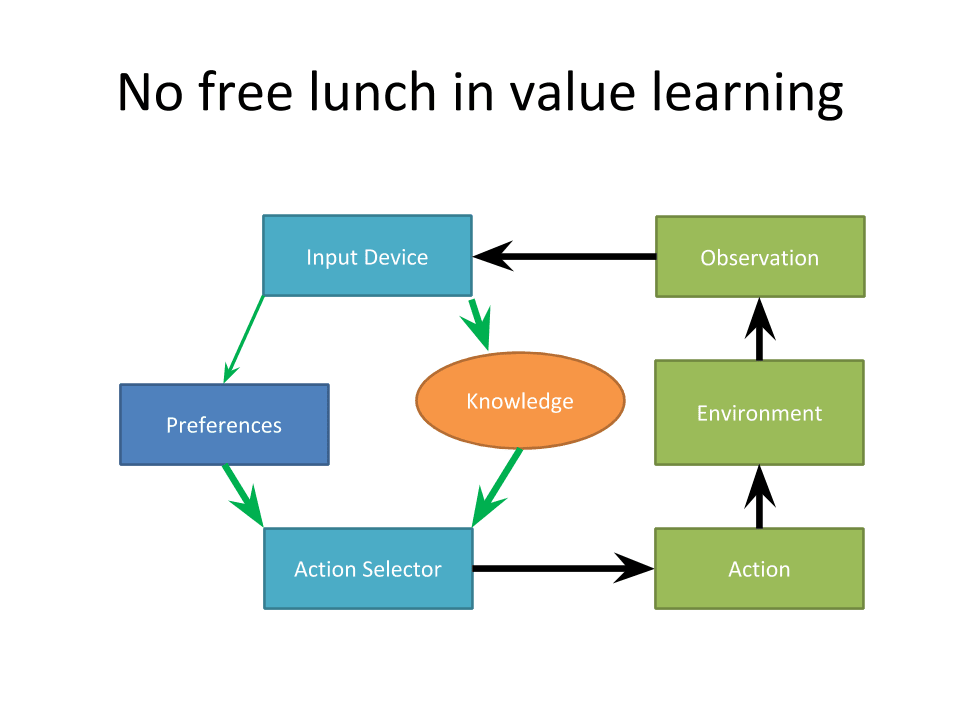
Now, human preferences can be changed by information, so a bit of information influences preferences. And then knowledge and preferences combine to make the agent choose an action. This action goes out into the world, goes into the environment, and you get another observation. And so on. So this agent is absolutely known.
But notice that there's a lot of here what Eliezer Yudkowsky would call ”Suggestively Named Lisp Tokens.” [LW · GW]
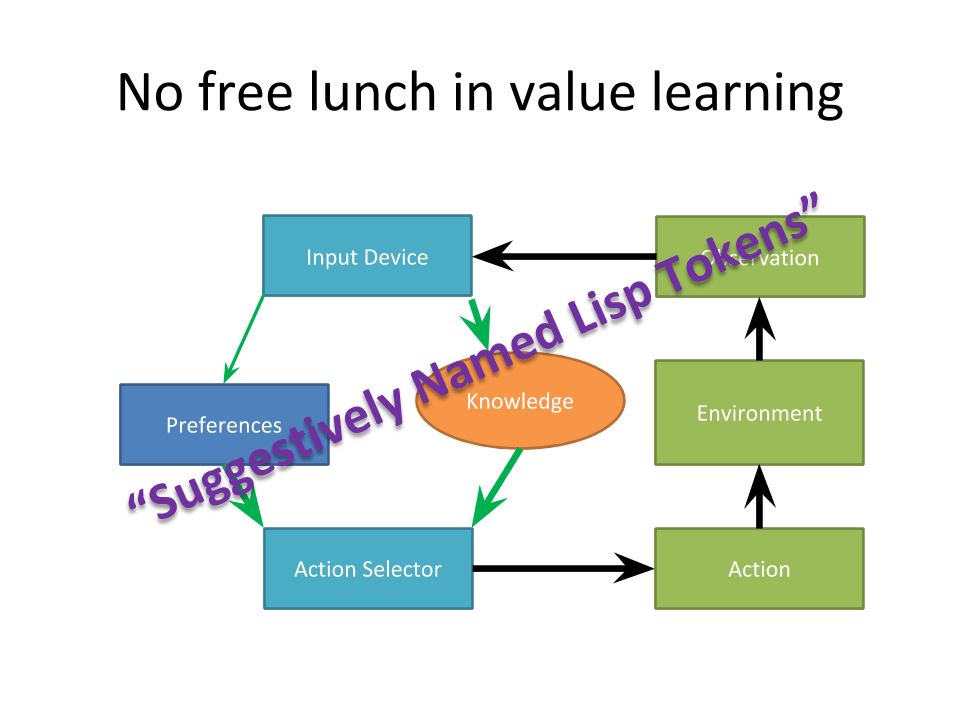
If I said, "This is the agent design," and gave you the agent but erased the labels, could you reconstruct it? Well, not necessarily.
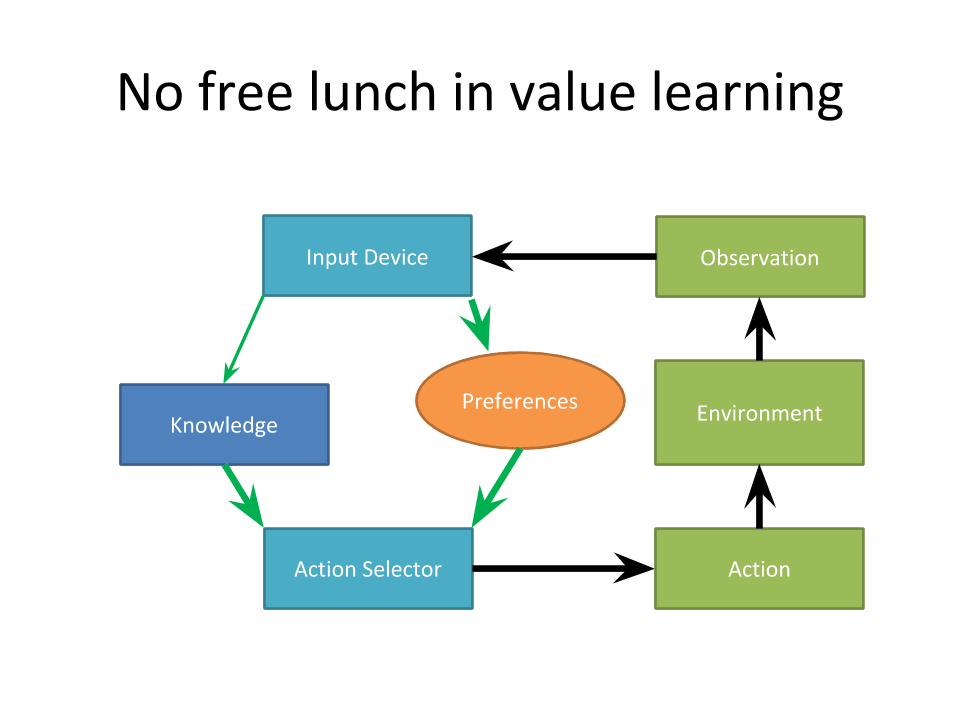
This is something that is perfectly compatible with that decomposition. I've just interchanged knowledge and preferences, because they serve the same form, in terms of nodes. But again, this is also massively oversimplifying, because each of these nodes has an internal structure, they're pieces of algorithm. Things happen inside them.
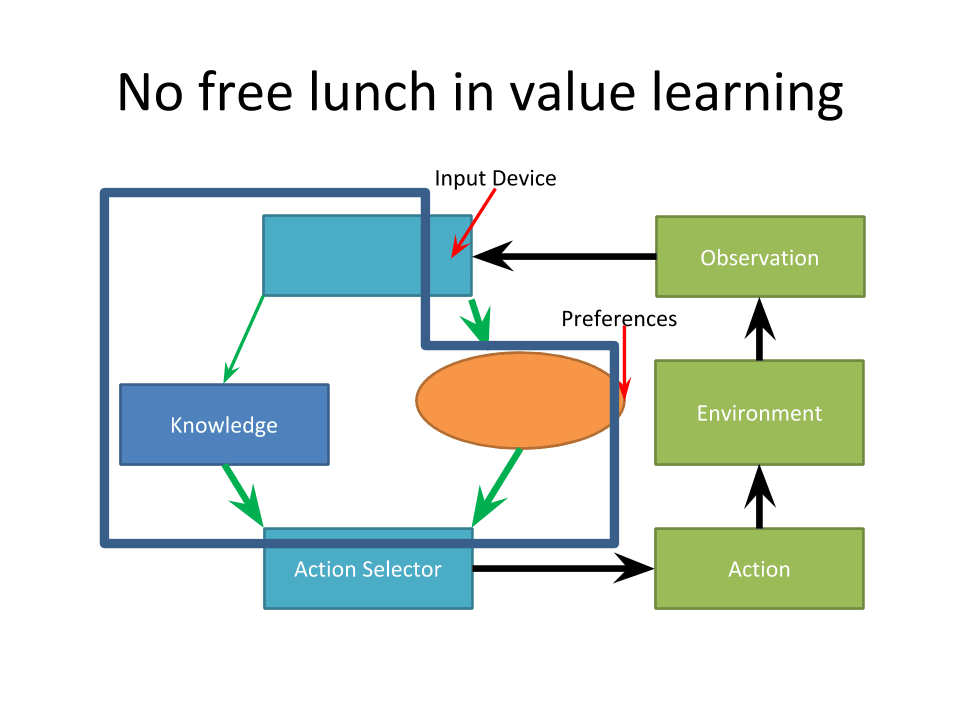
I might say that this blue box-ish thing is knowledge. The input device is a tiny piece there and the preferences are that little sliver there. There are internal structures to those various nodes where this is a plausible explanation of the algorithm. The point of this is that even if you do know exactly what the algorithm is, there's still a problem that this all assumes the Cartesian boundary between the world and the agent. As we know from people who are working at MIRI, this is not the case and this is not obvious.
Is your body part of this blue box? Are your nerves part of it? If you're driving a car, people often say that they feel the wheels of the car, so where is this boundary?
Again, if I sort of start talking about knowledge and preferences, and what the agent is, in fact, it might go all crazy without a better definition. And of course in the real world, things are vastly more complicated than this simple thing I've done.

This illustrates part of the problem. That's sort of to show you how the thing can be problematic in practice, when translated to various other domains.
So, to conclude:
Regularization is insufficient for inverse reinforcement learning. Regularization is basically simplification in this context. You can't deduce things with just a good regularizer.
Unsupervised learning can never get the preferences of an agent. You need at least semi-supervised learning. There has to be some supervision in there.
Human theory of mind can't be deduced merely by observing humans. If you could, you would solve the preference problem, which you can't.

Suppose a programmer wants to filter out clickbait, but their fix removes something that shouldn’t have been removed. Well, in that case the programmer might say, "No, that's obviously not clickbait. Let's remove that. We'll patch this bug." Often what they're doing in this sort of situation is injecting their own values.
The error isn’t not an objective bug, it's their own values that are being injected. It kind of works because humans tend to have very similar values to each other, but it’s not objective.
Finally, just to reiterate, values learned are determined by the implicit and explicit assumptions that you make in the system, so it's important to get those right.
Questions
Daniel Filan: It seems like a crucial aspect of this impossibility result (or in general the way you're thinking about it) is that decisions are made by some decision-making algorithm, that takes in the state of the world as an input. And preferences in the model just means anything that could produce decisions that somehow are related to the decision-making algorithm.
But in reality, I think we have a richer notion of preferences than that. For example, if you prefer something, you might be more inclined to choose it over other things.
To what extent do you think that we should move to a notion of preferences that's more robust than “anything inside your head that affects your decisions in any possible way”?
Stuart Armstrong: Yes, we need to move to a richer version of preferences. The point of the slide is that instead of seeing the agent as a black box, I'm using some very loose assumptions. I’m assuming that this is the network for how preferences and knowledge and actions feed into each other. I was just showing that adding that assumption doesn't seem to be nearly enough to get you anywhere. It gets you somewhere. We've sliced away huge amounts of possibilities. But it doesn't get us nearly far enough.
Basically, the more that we know about human preferences, and the more that we know about the structures, the more we can slice and get down to the bit that we want. It's my hope that we don't have to put too many handcrafted assumptions into our model, because we’re not nearly as good at that sort of design as we are at search, according to a talk I've heard recently.
Ben Pace: Where do you think we can make progress in this domain, whether it's new negative results or a more positive theory of which things should count as preferences?
Stuart Armstrong: I'm working with someone at DeepMind, and we're going to be doing some experiments in this area, and then I'll be able to give you a better idea.
However, what to me would be the ultimate thing would be to unlock all of the psychology research. Basically, there's a vast amount of psychology research out there. This is a huge amount of information. Now, we can't use it for the moment because it's basically just text, and we need to have a certain critical mass of assumptions before we can make use of these things that say, "This is a bias. This isn't."
My hope is that the amount of stuff that we need in order to unlock all that research is not that huge. So yes, so it's basically once we can get started, then there's a huge amount. Maybe something like the first 2% will be the hardest, and the remaining 98% will be easy after that.
Scott Garrabrant: Connecting to Alex's talk, I'm curious if you have anything to say about the difference between extracting preferences from a thing that's doing search, as opposed to extracting preferences from a thing that's doing design?
Stuart Armstrong: Well, one of the big problems is that all the toy examples are too simple to be of much use. If you have an algorithm that just does unrestricted search, it's a relatively short algorithm. And if I tell you this is an algorithm that does unrestricted search, there's not many different ways that I can interpret it. So I need very little information to hone in on what it actually is.
The thing with design is that it's intrinsically more complicated, so a toy example might be more plausible. But I’m not sure. If you took a bounded realistic search compared with bounded realistic design, I'm not sure which one would be easier to fit into. Given that you know what each one is, I don't know which one would be easier to fit in.
I don't think it's an artifact of search versus design, I think it's an artifact of the fact that toy search or practical search is simpler, and it's easier to fit things to simpler algorithms.
0 comments
Comments sorted by top scores.