ACI#9: What is Intelligence
post by Akira Pyinya · 2024-12-09T21:54:41.077Z · LW · GW · 0 commentsContents
Abstract 1. Normativity from Examples 1.1 Normativity and capability The right thing question can be broken down into two parts: 1.2 Keep flexibility without referring to goals 1.3 Follow the examples 2. Normativity Driven by Prediction 2.1 Action is predicting the right thing to do 2.2 Formalization with algorithmic information theory 3. From Ego-centric to the Physical World 4. Conclusion References None No comments
Abstract
This article is a brief summary of ACI's new definition of intelligence: Doing the same thing in new situations as the examples of the right thing to do, by making predictions based on these examples. In other words, intelligence makes decisions by stare decisis with Solomonoff induction, not by pursuing a final goal or optimizing a utility function. As a general theory of intelligence, ACI is inspired by Assembly theory, the Copycat model, and the Active inference approach, and is formalized using Algorithmic information theory.
1. Normativity from Examples
Let's start with the definition that an intelligent agent is a system that does the right thing (Russell 1991) . We can directly design simple agents that do the right thing in simple environments, such as vacuum robots, but what about more complicated situations?
1.1 Normativity and capability
The right thing question can be broken down into two parts:
1. What is the right thing to do? (the normativity)
2. How to do it? (the capability)
Many researchers focus on the capability problem. They evaluate the level of intelligence in terms of goal-achieving abilities (Legg & Hutter 2007), while normativity simply refers to "assigning a final goal to an agent". The same final goal can be assigned to different intelligent agents, just as the same program can be run on different computers. According to the orthogonality thesis, any level of capability can be combined with any final goals (Bostrom 2012).
On the contrary, our definition of intelligence starts from normativity, since we believe that "the right thing to do" is far more complicated than goals or utility functions.
1.2 Keep flexibility without referring to goals
How could an intelligent agent, starting from a tabula rasa, distinguish the right thing from the wrong thing? There are at least two approaches: direct specification and indirect normativity.
1. Direct specification: "Simply" assign a final goal to an agent, e.g. maximizing the total number of paperclips.
In theory, specifying a final goal is as simple as writing commands on a computer, but normativity in the real world is not so simple: it's difficult to translate a goal into code correctly (Bostrom 2012), and "any mistake in objective may have negative consequences." (Russell 2016)
Some people even claim that assigning any goal to a "superintelligence" would lead to disastrous consequences, because the superintelligence would pursue that goal with all the resources it could reach, such as transforming our solar system into a "computronium" (Bostrom 2012). The problem is not the wrong goal, but the goal-directed model itself.
Direct specification may not be the best theory of real world normativity, since some real-world intelligence agents, such as humans, do not have fixed goals. Our model of real-world intelligence doesn't need the final goal hypothesis.
2. Indirect normativity: It's an umbrella category that covers many different processes, through which an agent can distinguish the right thing from the wrong thing. The information for normativity comes from not goals but other sources, such as examples of the right thing to do,
On one hand, we have imitation learning, which mimics the behavior of examples to achieve better performance. Imitation learning is efficient, relatively safe, and can learn to do things that are hard to describe by goals, but struggles in environments it has never encountered (Christian 2021).
On the other hand we have value learning approaches such as Inverse Reinforcement Learning (IRL), which attempt to extract the utility function from examples of behavior (Ng & Russell 2000). They are more flexible to apply in novel situations, but still need to assign the learned utility function to the agent, which hits the same brick wall as the direct specification approaches.
We might ask, is there a process that can maintain flexibility without relying on goal assignment?
1.3 Follow the examples
When dealing with new cases, common law courts make decisions by "following the precedent" rather than relying primarily on the written code of law. Similarly, to do the right thing in new situations, an intelligent agent can follow the examples of doing the right thing without relying primarily on goals or utility functions.
We can define intelligence behavior as:
Doing the same thing in new situations as examples of doing the right thing.
For example, machine learning programs are trained to do the same thing with the test data set as the examples in the training data set, such as converting pixels in the MNIST test set to digits in the same way as the training data set demonstrates. Large Language Models (LLM) respond to human questions in the same way as the language material they have learned.
According to Assembly Theory, life follows "a lineage of events stemming from the origin of life"(Walker 2024), which is a memory of billions of years' of evolutionary history in which all the events are "the right thing to do". If one of them went wrong, in other words, if it led to a failure to survive and reproduce, the organism wouldn't be there at all. Organisms do the right thing by following examples: "If your past has more possibilities, your future has more" (Walker 2024) .
"Following examples" retains the fluidity of the original examples without distilling values. It's neither imitation nor value learning, but rather "analogy making", which is described by the Copycat project: "Suppose the letter-string abc were changed to abd; how would you change the letter-string yk in the same way?" (Hofstadter & Mitchell 1995). However, letter strings in the real world are trillions of times longer than abc.
2. Normativity Driven by Prediction
The question remains: How can you follow the examples in new situations without imitation or value learning? We find clues to a solution in Karl Friston's Active Inference approach: actions that fulfill predictions.(Friston et al., 2017)
2.1 Action is predicting the right thing to do
According to Active Inference, our brain is a prediction machine, which can avoid surprises by minimizing the discrepancy between the model and the world, either by changing the model or by changing the world (Parr et al., 2022). But when should we change our model, when should we change the world? What is our brain predicting, the external world or our goals?
A common skepticism of Active inference is the Dark Room Problem: if we want to minimize prediction error, “why don’t we simply find a dark corner (providing fully predictable, meager, unvarying patterns of sensory stimulation) and stay there, slowly growing weaker and then dying?” (Clark 2024) Why do we choose to change the world instead of starving in the dark room?
People often refer to arguments like maintaining "homeostasis" (Clark 2024) , "a 'dark room' agent … cannot exist" (Friston et al., 2010), or we are "more confident about" changing the world in these cases (Parr et al., 2022), but actually, all we need is the "action driven by prediction" principle and knowing what to predict:
Action is driven by predicting the right thing to do based on examples of the right thing.
We decide to escape from the dark room because we predict that the right thing to do in the dark room is to escape, based on countless examples from our experiences and evolutionary histories, where one escapes the similar cases almost every time. Memories of starving in the dark room are not accessible, because dead ones don't talk.
That's why behaviors that lead to dead ends, such as dying in a dark room, are likely to be surprising.
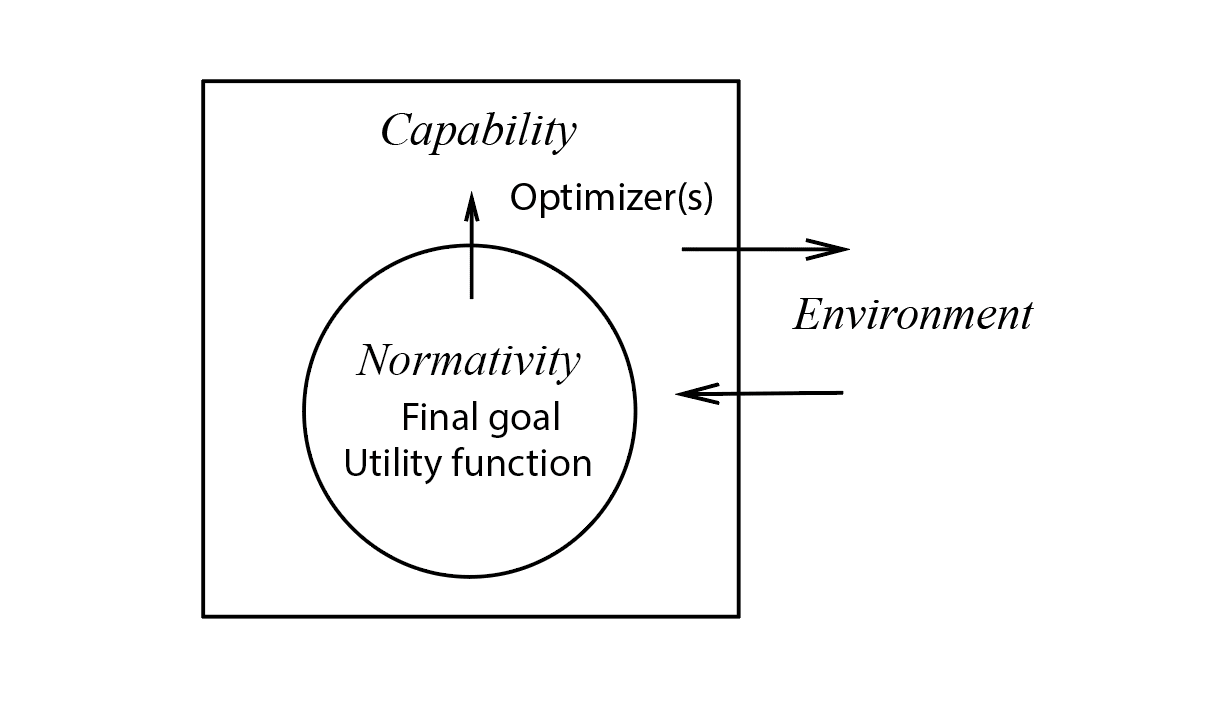
FIGURE 1. In traditional intelligence models, the normativity is a final goal that can be assigned to an agent, and can be combined with optimizers of different capabilities.
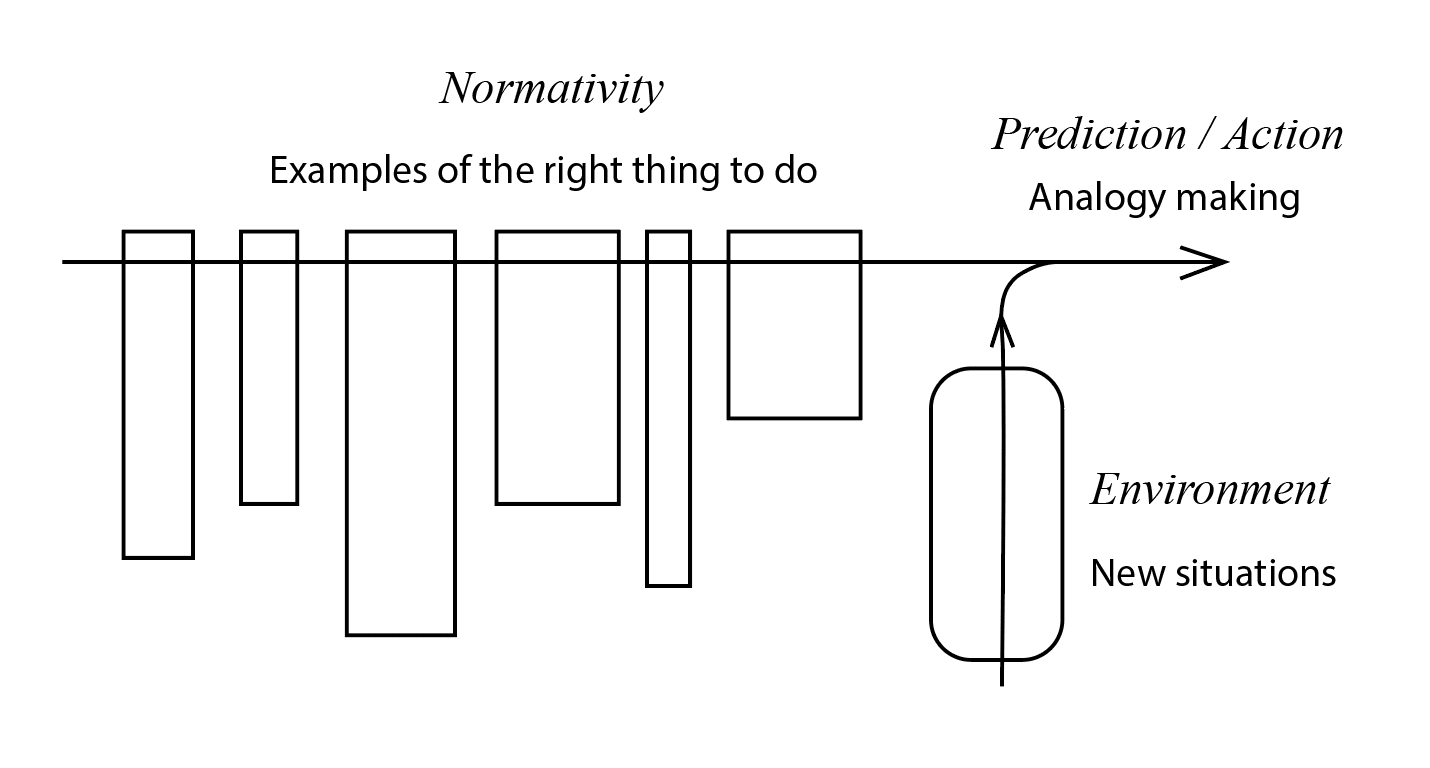
FIGURE 2. In our model, actions in new situations are driven by predictions based on examples of the right thing to do.
2.2 Formalization with algorithmic information theory
Hutter's AIXI (Hutter 2003) formalizes the reward-oriented intelligence model using Solomonoff induction, which, according to algorithmic information theory, is the best possible way to make predictions, even though it's incomputable (Solomonoff 1964).
Using Solomonoff induction, we can also formalize our predictive model of intelligence, which we call Algorithmic Common Intelligence (ACI):
Definition (ACI): If sequence represents examples of the right thing to do, and sequence represents a possible future of , then the probability of " is the right thing to do" equals the probability of " is the successor of the sequence " according to Solomonoff induction:
Where stands for "doing the right thing", is the best possible prediction of is the continuation of the data string take all possible hypotheses into account (Legg 1997).
plays a similar role to the utility function in the traditional model, but no superintelligence would optimize it at any cost, because everything you do is described in B, including "at any cost", which has a lower probability of being the right thing to do. In other words, optimizing with too many resources will result in a lower .
In the ACI model, an intelligent agent is not an optimizer, but a combination of reflexes and goal-directed subsystems. These modules work spontaneously and interdependently like Kahneman's System 1 and System 2 (Kahneman 2011): reflective System 1 is driven by predictions of a nearer future B, while goal-directed System 2 is driven by predictions of a farther future B.
The capability of an intelligent agent is its ability to predict. As Yudkowsky(2023) argues that GPT predict the causal process of the text [LW · GW], and Sutskever argues, predicting the next token can reveal the inner structure of the original data (Patel & Sutskever 2023), higher levels of intelligence can make better predictions, and reveal deeper structures.
3. From Ego-centric to the Physical World
Predicting the right thing to do is not enough to be intelligent, one also has to predict the external physical world. But how can you predict the world correctly if you only have examples of the right thing to do? How do we get around the survivorship bias? Hohwy (2016) argues that "we cannot obtain an independent view of our position in the world". We are doomed to believe that the world inside our Markov Blanket is special: my body follows the commands of my mind, not just the laws of physics. For example, your arms move according to your will; you would never experience your core temperature dropping below 20°C/68°F .
From the perspective of the ACI model, survivorship bias is a feature, not a bug. Our actions are driven by predictions based on what we (and our lineage) perceive while alive, which excludes opposite situations, such as starving in a dark room. However, we can indirectly predict the rest of the world through theory of mind.
Through theory of mind, one can understand others, and can speculate about others' perceptions without directly perceiving them (Frith & Frith 2005). We observe the death of others, and speculate about our own death from the perspective of others, and conclude that our Markov blanket is also a part of the external world and follows the same physical laws as the external world.
Self-awareness arises when there are conflicts between "predicting the right thing to do" and "predicting the external world": If the coming future follows the prediction of the right thing to do, we are changing the world; if the coming future follows the prediction of the external world, we have failed to change the world. (Details here [LW · GW])
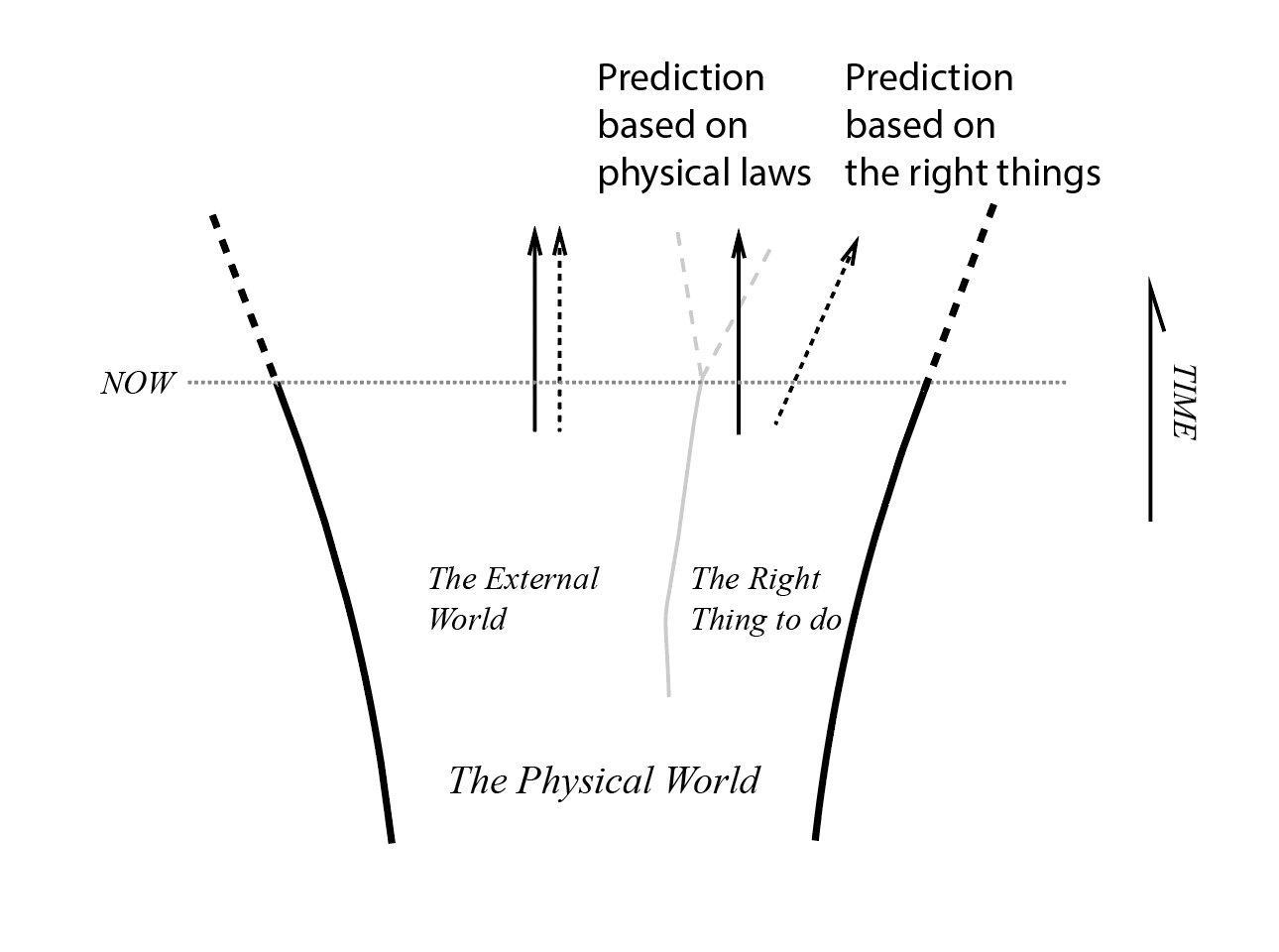
FIGURE 3. An agent would make two different predictions about the world within its Markov Blanket, one based on the laws of physics, another based on the examples of the right thing to do. The difference between these two predictions is the gap between the external world and our mind.
4. Conclusion
A new theory of intelligence should provide better perspectives on both natural and artificial intelligence, from the basic behavior of bacteria to human intelligence to the latest advances in AI such as LLM, and figure out how to develop more powerful and safer AI. More importantly, it should lead us to a new understanding of ourselves.
From the perspective of ACI, we are memories of events that we and our evolutionary lineage have experienced, and our actions are driven by predictions based on those events. One reason for LLM's success is that these memories are hidden in our language, and one reason for LLM's flaws is that not all of these memories can be found in language.
According to the ACI model, goal-directed systems or optimizers operate as subsystems of an agent, but can never operate alone without a goal generator/interpreter. In other words, optimizers are never autonomous.
However, we still have many questions to answer: How does intelligence work in the real world? How do reflex circuits, reward systems, and goal-directed systems interact within an agent? What is creativity? What is the future of the co-evolution of human and machine intelligence?
References
Bostrom, N. (2014). Superintelligence: Paths, dangers, strategies. Oxford University Press.
Christian, B. (2021). The alignment problem: How can machines learn human values?. Atlantic Books.
Clark, A. (2024). The experience machine: How our minds predict and shape reality. Random House.
Friston, K. J., Daunizeau, J., Kilner, J., & Kiebel, S. J. (2010). Action and behavior: a free-energy formulation. Biological cybernetics, 102, 227-260.
Friston, K. J., FitzGerald, T., Rigoli, F., Schwartenbeck, P., & Pezzulo, G. (2017). Active inference: a process theory. Neural computation, 29(1), 1-49.
Frith, C., & Frith, U. (2005). Theory of mind. Current biology, 15(17), R644-R645.
Kahneman, D. (2011). Thinking, fast and slow. Farrar, Straus and Giroux.
Hofstadter, D. R., & Mitchell, M. (1995). The copycat project: A model of mental fluidity and analogy-making. Advances in connectionist and neural computation theory, 2, 205-267.
Hohwy, J. (2016). The self‐evidencing brain. Noûs, 50(2), 259-285.
Hutter, M. (2003). A gentle introduction to the universal algorithmic agent AIXI. Artificial General Intelligence.
Legg, S. (1997). Solomonoff induction. Department of Computer Science, The University of Auckland, New Zealand.
Legg, S., & Hutter, M. (2007). A collection of definitions of intelligence. Frontiers in Artificial Intelligence and applications, 157, 17.
Ng, A. Y., & Russell, S. (2000). Algorithms for inverse reinforcement learning. In Icml (Vol. 1, No. 2, p. 2).
Parr, T., Pezzulo, G., & Friston, K. J. (2022). Active inference: the free energy principle in mind, brain, and behavior. MIT Press.
Patel, D., & Sutskever, I. (2023). Building AGI, Alignment, Spies, Microsoft, & Enlightenment [Video]. YouTube. https://www.youtube.com/watch?v=Yf1o0TQzry8
Russell, S. J., & Norvig, P. (2016). Artificial intelligence: a modern approach. Pearson.
Russell, S. J. (2019). Human compatible: AI and the problem of control. Penguin Uk.
Russell, S. J., & Wefald, E. (1991). Do the right thing: studies in limited rationality. MIT press.
Solomonoff, R. J. (1964). A formal theory of inductive inference. Part I. Information and control, 7(1), 1-22.
Yudkowsky, E. (2023). GPTs are predictors, not imitators. LessWrong. https://www.lesswrong.com/posts/nH4c3Q9t9F3nJ7y8W/gpts-are-predictors-not-imitators
0 comments
Comments sorted by top scores.