Alignment as Function Fitting
post by A.H. (AlfredHarwood) · 2023-05-06T11:38:04.245Z · LW · GW · 0 commentsContents
Justifying Interpolation Justifying Extrapolation The data alone does not tell you what kind of function you should use to model it. The Analogy with AI There is no finite amount of training data that will allow the underlying process (or mathematical function) which generated it to be deduced. In order to extrapolate (or interpolate) from the training data, you need to make an assumption about the form that the extrapolation should take. There is n... In our earlier example, with Hooke's law, we were able 'step back' from the data and use our knowledge of the underlying process in order to decide whether we could justify extrapolating the data. Can an AI do something similar? But surely good behaviour in the training data gives us some reason to believe it will extrapolate? Even if it doesn't guarantee good behaviour, surely it increases the likelihood? Isn't this just the problem of induction disguised as something else? What would a 'solved' alignment problem look like from this point of view? None No comments
In this post, I spell out some fairly basic ideas, that seem important to me. Maybe they are so basic that everyone finds them obvious, but in the spirit of this piece [LW · GW], I thought I would write them up anyway.
tl;dr I start off by looking at using linear regression to model data. I examine how interpolation and extrapolation using a linear model can go wrong and why you need some extra assumptions in order to justify interpolation/extrapolation using a linear model. I write about the analogies between the failure modes of linear regression and AI failure modes. I conclude that problems in AI alignment often boil down to the problem of extrapolating outside of training data, which applies equally to linear regression and complex AI models.
Suppose we have a set of datapoints of the form and we wish to study this set of data and use it to make predictions about unseen datapoints. We will be given a value of that is not in our dataset and attempt to predict the corresponding value of . This is a classic problem for which one would use regression analysis, the simplest form of which is linear regression, fitted using the ordinary least squares method. I will consider a couple of examples where this prediction method goes wrong. These are not unique to linear regression and are indicative of broader failure modes.
Justifying Interpolation
Suppose our data is given on the plot below, in blue. We perform a linear regression and use it to find a line of best fit which minimizes the residual sum of squares (RSS). The regression line is shown in red.
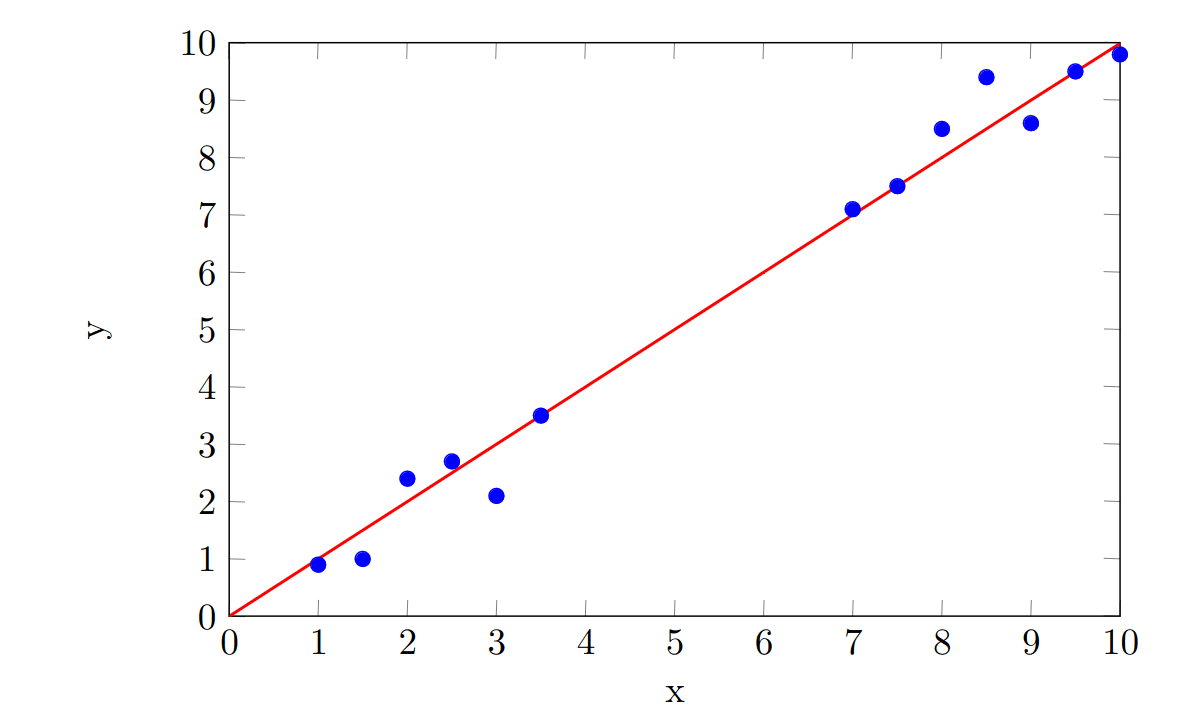
We can get a rough idea of how well our regression line fits the data by seeing how big the RSS is. Since the RSS is not zero, we know that the fit is not perfect, but it is small enough that we might feel happy using our line to make predictions.
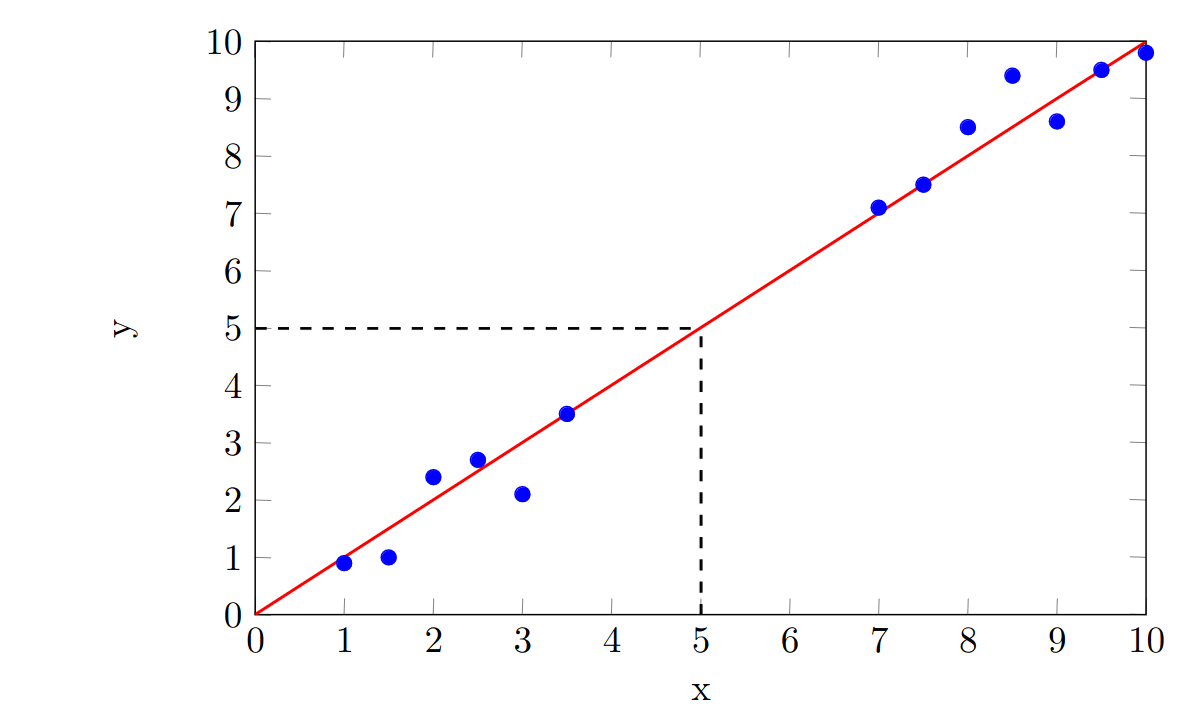
Suppose we are required to predict the value of when . This is an example of interpolation. Interpolation has several strict mathematical definitions, but here I will use it to mean "making predictions of values within the range of the dataset". Since we have datapoints for and , the point lies within this range. We can use the linear regression line to predict the value of when . This is indicated using the black dashed line and gives us a prediction that, corresponds to a -value of .
Now, we collect some more data in the range to see if our prediction is a good one. This new data is shown in green, alongside our old data:
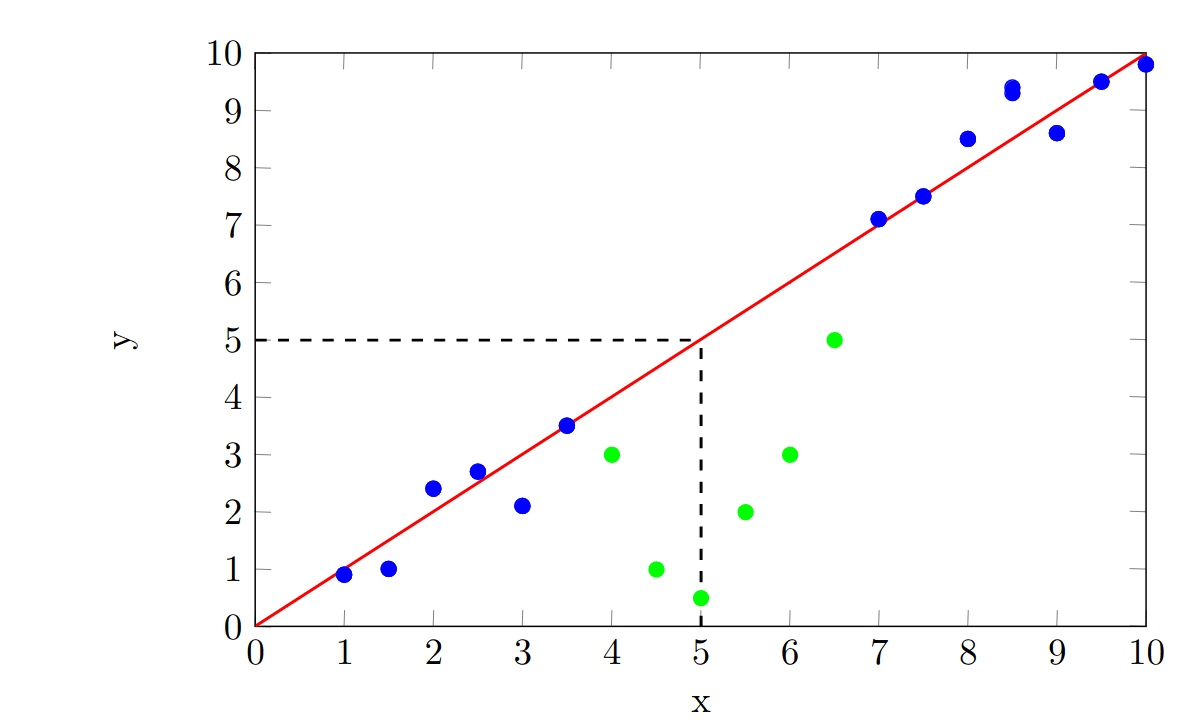
It turns out that our prediction was really bad! We did not foresee that the data would 'slump' in the middle, which led us to make a prediction of , when the true value corresponding to is .
Here are a few takeaways from this problem:
- In using linear regression to predict the value of the missing datapoint, we implicitly assumed that the linear model was a good fit for the whole dataset, but this assumption was wrong.
- Low RSS does not guarantee a good fit to the whole dataset, outside of the original dataset for which it is calculated.
- If we had collected more data in the range , we might have avoided this problem.
We'll return to these points later on, but it is worth dwelling on point 3. now. Collecting more data around would have given us an indication that our previous was not right, but if the only tool at our disposal was linear regression, then we might not be able to do much about it. Computing a new linear regression, including the new datapoints would have given us a new regression line, but this line would not fit the data particularly well. In order to make better predictions, we would have to also change the type of regression we performed, so that we could fit a curved line to the data. But how do we know that we will not just get the same problem again, in a different form? Regardless of how dense our datapoints are, there is no guarantee that the data is well-behaved in the areas between our datapoints. Making interpolative predictions using a model obtained through any kind of regression requires the assumption that the data is well-behaved (ie. doesn't deviate from the model) in the areas between existing datapoints. This might seem bleedingly obvious, but it is an important assumption. It is also important to note that this assumption cannot be justified by the data alone. Making this assumption requires that one claims to understand the underlying process which is generating the data, but knowledge of this process is not included or encoded in the dataset (ie. the set of pairs ).
This problem also manifests itself when performing extrapolation.
Justifying Extrapolation
Suppose we perform a linear regression on a new dataset:
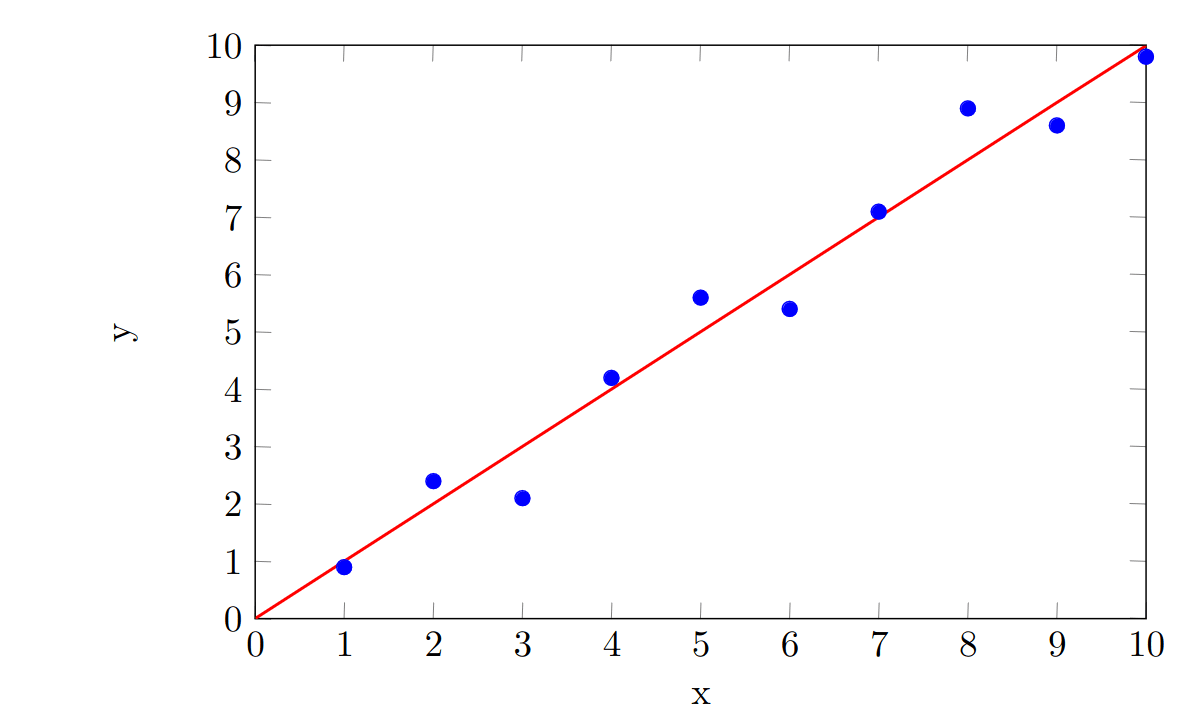
This time, we are asked to predict the -value when . Our linear regression would suggest that our prediction should be . However, suppose that we go to collect new data in the range , and we find that it takes this form:
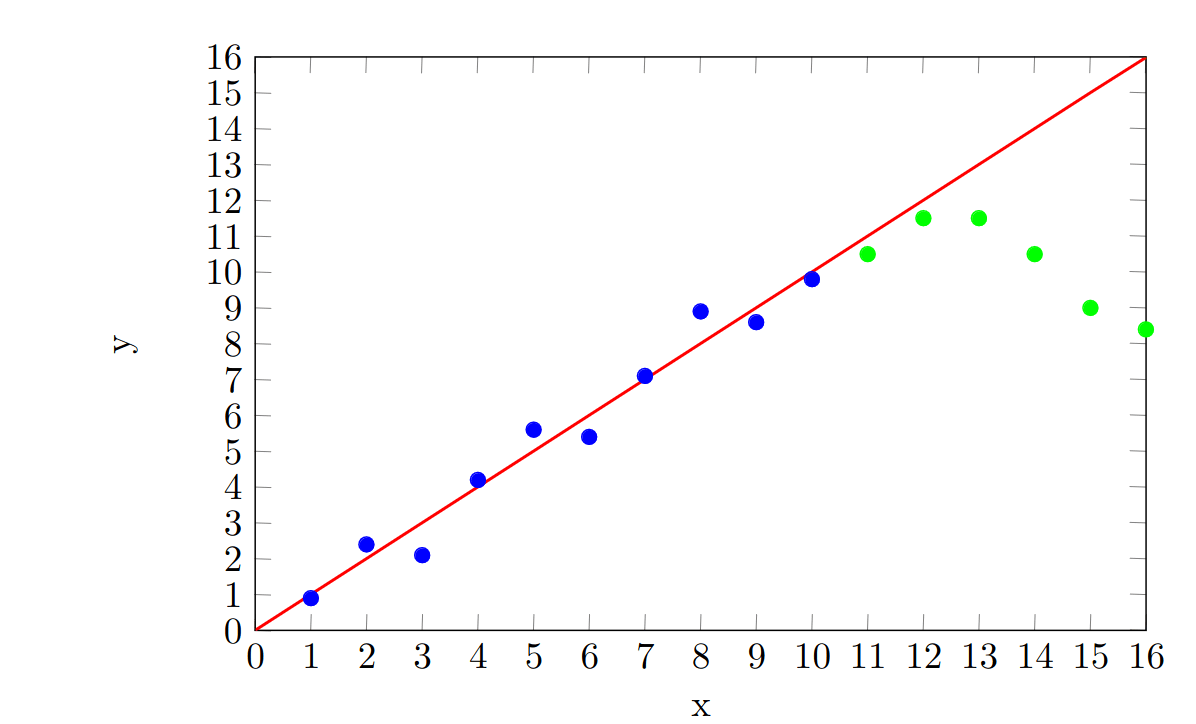
Again, our prediction was bad! This is for broadly the same reasons that our interpolative prediction was bad. We assumed that the data was well-behaved and we assumed that, because our model fitted well with our original dataset, it would fit well with new datapoints. But the fact of the matter is, there is nothing within the original dataset which tells us how the data will behave outside of its range. This needs to be brought in as an extra assumption. Without knowledge of the underlying process the data outside of the original range could plausibly follow any number of trends, such as:
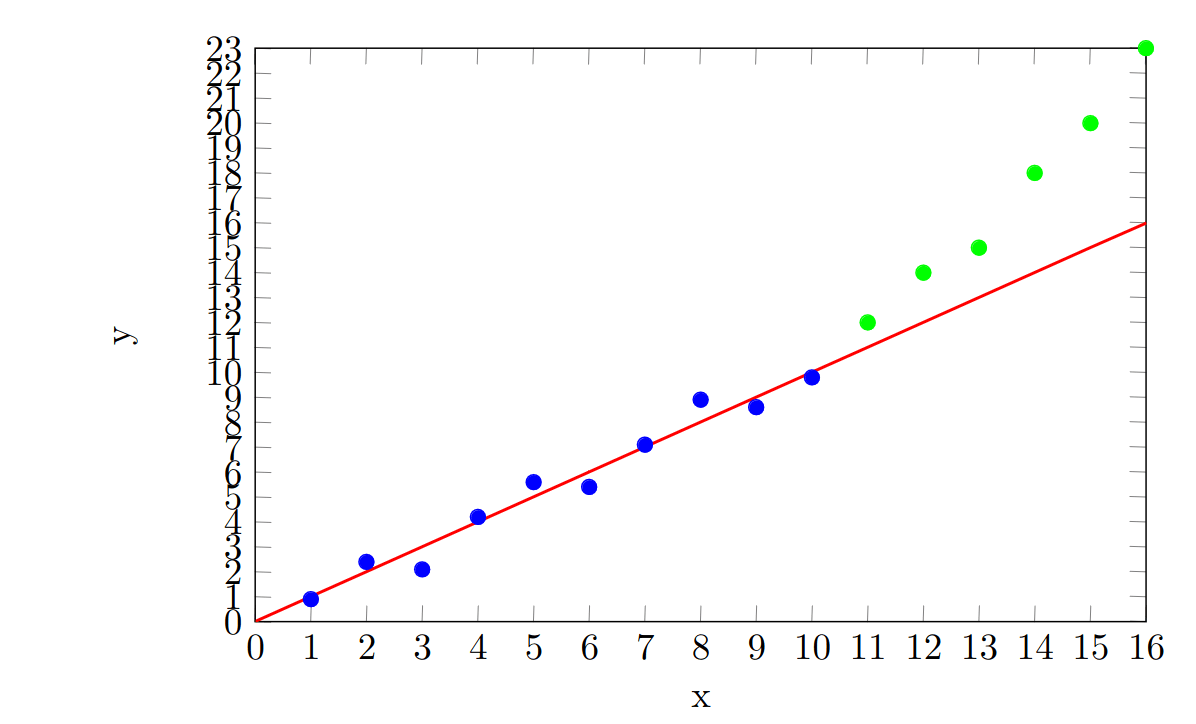
or, it might follow the original trend perfectly:
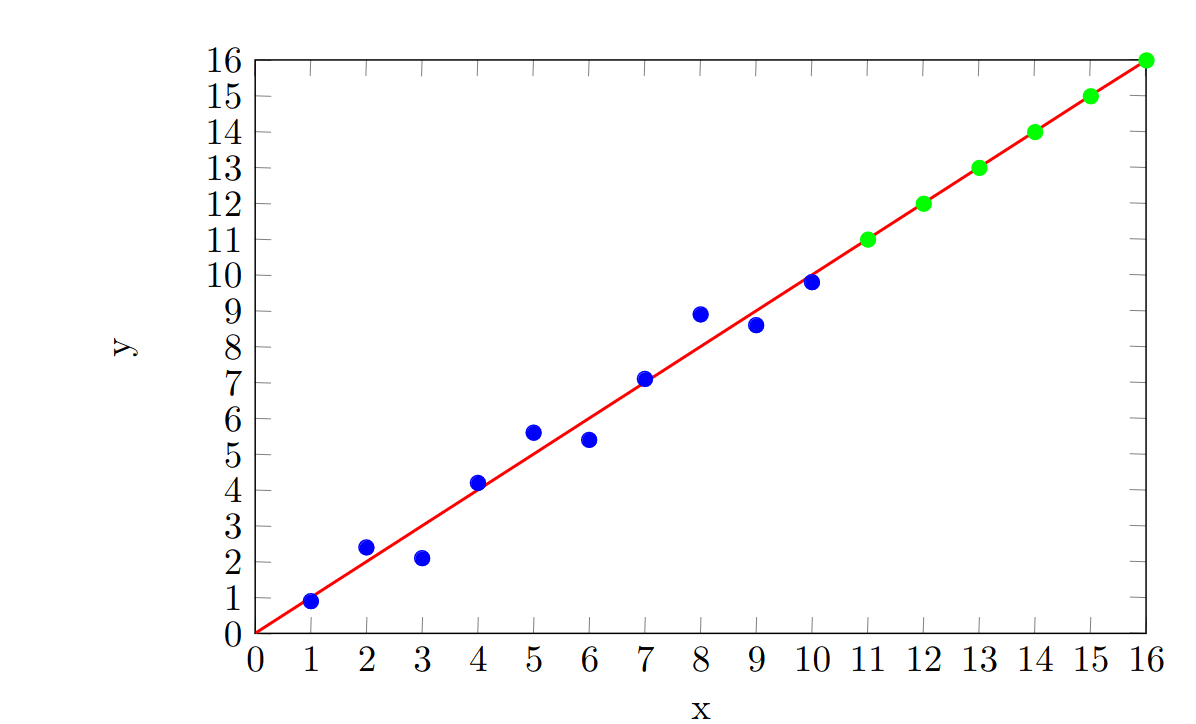
but we would not be able to tell which of these was true before we collected data in the new range.
But surely, if we collected enough data in the original range, we would be able to detect any trends which would continue outside of that range? No! Through Taylor expansion, one can always construct a function which follows one trend to an arbitrary degree within a range, and then diverges to an arbitrary degree outside of that range. If the process generating our data follows such a function, there is no way to tell if we just sample within our original range. There are an infinite number of possible functions which fit our original data and diverge from each other outside of the original range.
Thus, our position regarding extrapolation is similar to our position regarding interpolation. There is no way to guarantee that the data will continue to follow the trend we have observed. In order to make predictions outside of our original dataset, we will have to assume that our data is well-behaved. This assumption, I think, can come is two slightly different flavours.
Firstly, it is possible that we know the form of the trend we expect in the data. In our case, this amounts to assuming that the whole of the data (not just in our original data) will be well-fitted by a linear regression. We are assuming that the full dataset can be well-modelled by an equation of the form . Then, we use the original data to find approximations to and . This assumption could be justified if one understands the origin of the data . For example, the data might come from measurements of the extension of a metal spring. If and
and you know that you are operating in elastic range of the spring, you then know that Hooke's law applies and you can model the relationship as linear with reasonable success. Again, this assumption came from outside the dataset - it is not contained within the data itself.
What if we cannot justify assuming that the data is linear? As an alternative, we could try making the following assumption. We assume that if the original data fits our regression line well then the data will continue to fit our regression well, outside of the original range. More generally, we have to assume that something about the data itself gives us reason to think that our regression will be a good fit. As discussed above, this is often not true: a regression might fit data well, but extrapolate badly. But if we have some extra information about the process generating the data, then maybe a good fit within the original data is enough to justify extrapolation. I cannot think of a clean, 'real-world' example of this assumption (suggestions welcome!), but here is an abstract example. Suppose that, due to your understanding of the origin of the data, you know that your data will either be well-modelled by an equation of the form or an equation of the form . The original dataset may contain enough information that you can rule out one of these possibilities, leaving you with only one option. For example, the data may contain -values greater than 1, leading you to rule out the possibility that [1].
Importantly, both of these assumptions are external to the original dataset. We cannot arrive at either of these assumptions from the data alone. In this piece, up until just now, with the Hooke's law example, I have deliberately avoided specifying the 'real-world' counterparts of and to emphasise this fact. If I gave a real-world example, I think most people would immediately (maybe unconsciously) check to see if either of these assumptions hold.
Another way of framing this problem discussed in the previous section is to say:
The data alone does not tell you what kind of function you should use to model it.
The choice of mathematical function you use to fit your data is something you must choose, based on your understanding of the process underlying the data. There is no a priori correct function to use. Stephen Wolfram puts it nicely in his blogpost/short book What Is ChatGPT Doing … and Why Does It Work?:
It is worth understanding that there’s never a “model-less model”. Any model you use has some particular underlying structure—then a certain set of “knobs you can turn” (i.e. parameters you can set) to fit your data.
I reiterate here that that all arguments so far extend to any attempt attempt to fit a function to data and use it to predict datapoints outside of the original dataset. Due to its simplicity, I have used linear regression for all examples, but could equally have used polynomial regression or some other form of nonlinear regression and all the points I have made would still apply.
The Analogy with AI
At a high enough level of abstraction, what a lot of modern AI systems do is similar to linear regression. They take in some training data and fit a function to it. They then use this function to predict datapoints they have not yet encountered. The ways this function is generated depends on the particular AI, and this is obviously a gross oversimplification of what is going on, but it is an accurate high-level description. As a result, we would expect their to be high-level analogies between AI systems and linear regression. For example, when training, AI algorithms aim towards finding functions which fit the data in a way that minimizes their loss functions. This is analogous to the way in which a linear regression aims to a find a function which fits the data in a way that minimizes the RSS.
Here is a table which summarizes this analogy.
| Linear Regression | AI | |
| The original data used to build a model. | 'Original Dataset' | Training Data |
| The quantity which is minimized to ensure a good fit to the original data | Residual Sum of Squares (RSS) | Loss Function |
| The mathematical function which fits the data | A highly non-linear function mapping inputs to outputs | |
| Inputs | Images, text, etc. | |
| Outputs | Images, text, actions, etc. |
Since we have these analogies, it is instructive to ask whether the failure modes of linear regression we encountered in earlier sections apply to AI. I argue that they do and that they capture some key difficulties of the alignment problem.
In practice, modern ML systems can take in a huge number of inputs such as images and videos with millions of pixels, or large texts containing millions of characters. The range of possible outputs is equally large. Nonetheless, we can parametrize all possible inputs with a single variable, which we will call . Similarly, we can parametrize all possible outputs with a single variable, which we will call . This will be incredibly cumbersome, but is in principle possible. For example consider an image classifier AI which takes as an input a digital image containing 1 million pixels, with each pixel requiring 8 bits of information to describe. There are possible inputs for this AI, so we can parametrize them using a variable which runs from 1 to . Similarly, if the output of the image classifier is a 100 character description, with each character represented by an 8-bit ASCII code, then we can represent each possible output with a variable which runs from 1 to . The AI then attempts to find a function which maps to and fits the pairs given to it in the training data. The resulting function will be highly non-linear. For example, a small section of the data along with the fitted function might look like this:
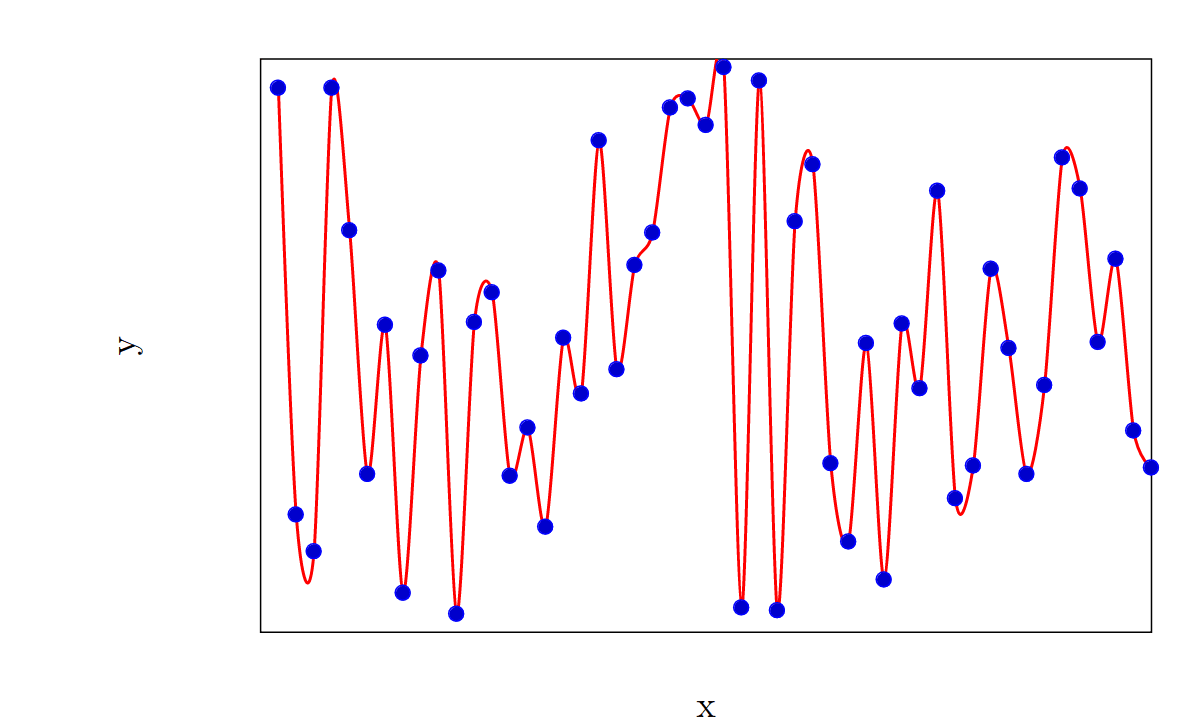
Once the AI has finished its training run, it should have function mapping to which approximately minimizes the loss function when used with the training data. Now, we can see whether this training function performs well when used to predict the values corresponding to -values that are not in the dataset.
The first thing to notice is that, in this case, the difference between extrapolation and interpolation is not as clear cut as it was earlier, since our encoding of the x and y variables is somewhat arbitrary. A particular datapoint outside of the dataset could be predicted either using interpolation or extrapolation, depending on the function used to map the input to a value of . Let us look at extrapolation, but note that what follows can equally apply to interpolation.
We will encounter the same problem with extrapolation that we encountered when doing linear regression: we cannot guarantee that the function we found which fits the training data also fits new data outside of our original dataset. As before, there are an arbitrary number of functions which fit the training data, but diverge outside of the original range:
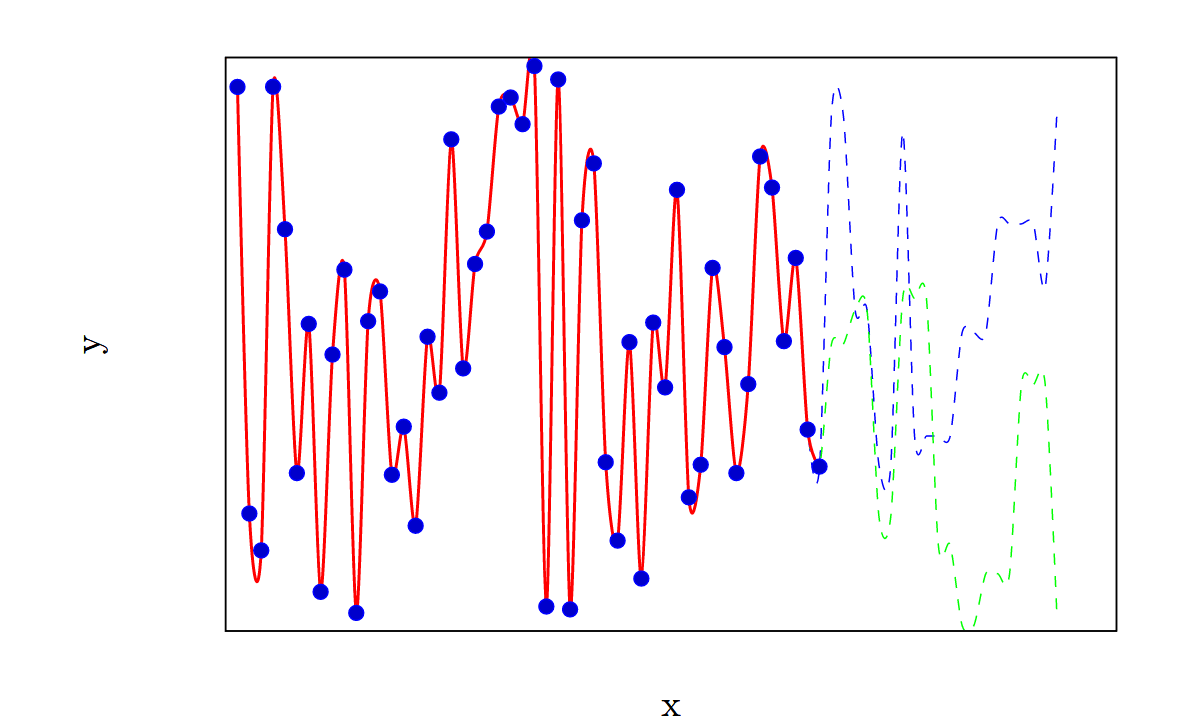
Furthermore, for the reasons discussed earlier, looking at just the data alone, without any extra assumptions, there is no reason to assume that a good fit with the training data guarantees a good fit outside of the range of the original data.
We could frame this problem one of two ways. First, we could frame it as a problem with our AI system. We believe that the AI is optimizing one thing and it does well at this in the training data (as characterized by the red line), but when it is exposed to more data, we find out that it is optimizing something else (maybe the green dashed line indicates what we wanted the AI to do with the new data, and the blue dashed line is what it actually does). Depending on some other details, this could be framed as deceptive alignment [? · GW] and/or a distributional shift [? · GW] problem.
Alternatively, we could frame it as a problem with the data, or rather, the process which generated the data. How do we know that this process is sufficiently well-behaved that having a function which fits the training data allows us to make good predictions by extrapolating it?
I think that it is best to think of the problem as a combination of these two framings. Being 'well-behaved' is a property of the joint AI-Environment system. It means that the environment (read 'data') can be modelled by a function which your AI is able to generate. Suppose you used a linear regression to make predictions when the relationship between and is . Maybe the fit is good for small values of , but if you try to extrapolate far enough, eventually you will realise your model is bad at making predictions. But it isn't particularly helpful to frame this a 'distribution shift' or 'deceptive alignment' or to say that the data is not well-behaved, you are just using a model which doesn't fit with the underlying process generating the data.
This framing of AI misalignment is different from discussing agents and utility functions or ML systems and interpretability. It may be that this framing is too general to be useful, but I feel that it has given me some insight into the problem.
To be clear, my claim is the following:
There is no finite amount of training data that will allow the underlying process (or mathematical function) which generated it to be deduced. In order to extrapolate (or interpolate) from the training data, you need to make an assumption about the form that the extrapolation should take. There is no way of knowing whether this assumption is true from the training data alone. The alignment problem is (at least partially) the problem of not knowing whether this assumption holds.
For example:
- No amount of reasonable conversations with GPT-3 gives you reason to believe that it will give you a sensible answer when you ask it to write a poem about petertodd [LW · GW].
- No amount of helpful, cooperative behaviour when the AGI is in the box allows you to be confident that it will be well-behaved when you let it out of the box [? · GW].
In our earlier example, with Hooke's law, we were able 'step back' from the data and use our knowledge of the underlying process in order to decide whether we could justify extrapolating the data. Can an AI do something similar?
In some cases yes, but in general I don't think so. Any information that the AI has about the 'context' of the data will be encoded in the data itself which it is using. There is no way for the AI to step outside of the totality of the data it has been given. It is perfectly possible that an AI could 'step outside' from a subset of its data and, using the rest of its data, decide whether or not it extrapolates. But this would not apply to the AI as a whole (see this footnote[2] for an example). For what its worth I don't think that humans can ever 'step back' from the totality of our data either...
But surely good behaviour in the training data gives us some reason to believe it will extrapolate? Even if it doesn't guarantee good behaviour, surely it increases the likelihood?
I don't think this is true in general. Newtonian classical mechanics fitted the data collected over 100 years, yet broke down when applied far enough outside of its original range. The outputs of a deceptively aligned AI will perfectly match an aligned AI within the training range, but will diverge drastically outside of that range. Again, I think that you need an extra assumption of 'well-behavedness' in order to make the claim that good behaviour in the training data makes the model more likely to extrapolate. This assumption would presumably be a weaker, probabilistic version of one of the assumptions we required earlier in order to extrapolate from the training data and would also depend on understanding the underlying process generating the data. Finding out when such an assumption applies is an important part of the alignment problem, but we cannot take for granted that it applies in all cases.
Isn't this just the problem of induction disguised as something else?
Yeah, I think it might be. There are definitely strong similarities, but I only realized this halfway through writing. I need to think a bit more about this angle.
What would a 'solved' alignment problem look like from this point of view?
I'll present a couple of tentative suggestions.
First, it might turns out that there is a 'natural' way to fit functions to data, which, if you do it correctly, will always extrapolate in a well-behaved way. This would be equivalent to Wolfram's “model-less model” - you don't need dither around deciding between modelling your data using a linear or exponential function because there exists a procedure which will give you the 'correct' answer. If this was true it would be similar to physicists discovering that all trends in physics can be well-modelled by linear regression (clearly this isn't true, but for some more complex modelling procedure it might be). It strikes me that the Natural Abstractions Hypothesis [LW · GW] claims something similar to this: that all cognitive systems will converge to modelling the world using roughly the same set of abstractions[3]. Maybe such a system would have to be aware when it doesn't have enough data to decide between candidate models, and it would know what data it needed to collect in order to discriminate between them.
Alternatively, a form of AI could be developed that does something that cannot be framed as fitting a function to data. I can't conceive how this would work, but I guess it is possible. Such a system would not experience the extrapolation problems discussed here (but who knows, it might experience new, even worse, problems!)
There are almost certainly other approaches I haven't thought of. Maybe some alignment approaches already address these problems. Either way, going forward, whenever I read about an approach to alignment, I now have a simple question to ask myself: how does it address the problem of extrapolating outside of the training data?
- ^
Of course, if the data is noisy, it is possible that, by a fluke, the linear data ends up fitting the sinusoidal pattern very well (or vice versa), but this doesn't bother me. Introducing noise just adds a layer of uncertainty which can be dealt with using standard Bayesianism.
- ^
Suppose we have an AI where the training data consists of three pieces of data . The data is drawn from the experiments on the extension of a variety of springs where
The AI is trained to predict the extension of each spring when a force is applied. But when the force exceeds the elastic range of the spring, it is trained that the correct answer is to reply with the string "Elastic Range Exceeded", instead of giving a numerical response. Training such an AI is perfectly possible. In this example, the AI is able to 'step-back' from the data and evaluate it using the extra data contained in , analogous to humans. However, the AI cannot step back from the totality of data and ask whether the relationship it has modelled between and, is correct.
- ^
From Natural Abstractions: Key claims, Theorems, and Critiques [LW · GW] :
"an abstraction is then a description or function that, when applied to a low-level system , returns an abstract summary .[1] [LW(p) · GW(p)] can be thought of as throwing away lots of irrelevant information in while keeping information that is important for making certain predictions."
Furthermore "cognitive systems will learn roughly the same abstractions".
There is a subtlety here, since "cognitive systems will learn roughly the same abstractions" is not necessarily the same as "cognitive systems will learn roughly the same abstractions and those abstractions are the correct ones for modelling the world".
However, if we had a good enough understanding of the kind of abstractions an AI was using to model the world, we could say with confidence how it would extrapolate from its training data.
0 comments
Comments sorted by top scores.