Each Llama3-8b text uses a different "random" subspace of the activation space
post by tailcalled · 2024-05-22T07:31:32.764Z · LW · GW · 4 commentsContents
GPT residual stream Singular vector decomposition Activation subspaces Why would I do that? Subspace overlap Discussion None 4 comments
This is kind of a null result (or WIP research) I got with a few days of fiddling, so don't get too excited. Also, because it's a null result, it's always conceivable that there's just some slight change in the approach which could suddenly flip it to get a real result. More on that in the "Discussion" section. I would expect my findings to generalize somewhat beyond this approach on Llama-3, but it's unclear how much, as I haven't tested it more broadly yet, so I'm going to limit my claims to this approach on this model.
GPT residual stream
Llama3-8b is a generative pretrained transformer released by Meta. In order to make it easier to train, it uses residual connections, which basically means that the core of the network consists of layers of the form:
output = input + f(input)This is called the "residual stream" of the network.
A transformer is a sequence-to-sequence model, and so each of these variables is really a sequence of vectors, one for each token in the processing. I just concatenate all these vectors into a single matrix , where is the number of layers (, I think), is the number of tokens (depends on the prompt and the amount of tokens you request to generate), and is the number of hidden dimensions ().
Singular vector decomposition
For any matrix , we have where and are rotation matrices and S is a diagonal matrix. The diagonal of is called the singular values of , and by convention one lists them in descending order[1].
I use it as a matrix approximation method by taking the diagonal matrix which contains ones along the first part of the diagonal, and zeroes along the rest, as then yields an optimal -rank approximation to .
Since the and just consists of unit vectors, the only thing that moderates the magnitude of the matrix is , so one can learn a lot about how good approximations of different ranks are just by plotting :
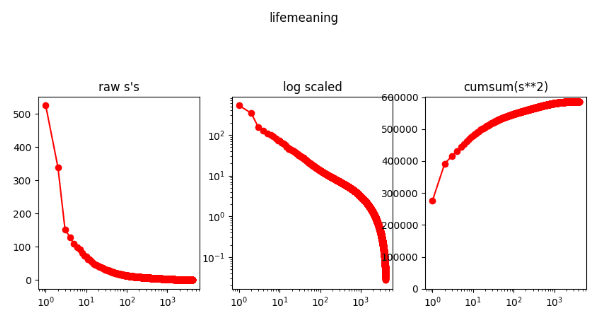
Here, the [prompt] and generation I'm plotting the results for is:
[I believe the meaning of life is] to be happy. It is a simple concept, but it is very difficult to achieve. The only way to achieve it is to follow your heart. It is the only way to live a happy life. It is the only way to be happy. It is the only way to be happy.
The meaning of life is
Activation subspaces
We can define a matrix , which has the effect of projecting onto the biggest dimensions of . Given such a matrix, we can then go stick it in the original residual stream code:
output = input + (f(input) @ P)This has no effect for as that is equal to the identity matrix, but as we take smaller 's, it forces the "thoughts" of the neural network to only occur along the biggest directions in the original vectors that was constructed with.
After modifying the network, I can compute the negation of the log probability of the original text (which I used to assemble ). It gives a plot like this:
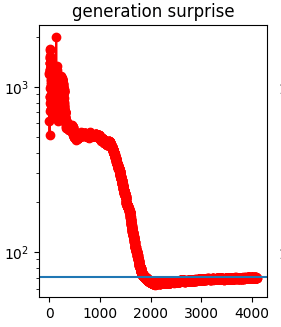
This implies to me that the neural network "needs" around 2000 dimensions to generate this output. More specifically, since the surprise for the projected network dips below the suprise for the unprojected network at , I say that is the subspace used by the meaning of life text.
More generally, for an arbitrary text , I can collect its vectors, perform an SVD, and use binary search to find the where the surprise dips down to the unprojected surprise, so I have a function which maps texts to subspaces of .
Why would I do that?
Activation engineering [? · GW] has previously found that you can add vectors to the residual stream to control the model in predictable ways, and that you can measure vectors in the residual stream to figure out what topics the network is thinking about. This suggests that the hidden dimensions have semantic meaning, and I would think would be the subspace containing the semantics used by the text .
One quick sanity check that can be performed is to try using to generate new text for the same prompt, and see how well it works:
[I believe the meaning of life is] to find happy. We is the meaning of life. to find a happy.
And to live a happy and. If to be a a happy.
. to be happy.
. to be happy.
. to be a happy.. to be happy.
. to be happy.
This certainly seems semantically related to the original continuation, though admittedly the grammar is kind of broken, as would perhaps be expected when ablating half the neural network's thoughtspace.
That said, this could be thought of as "cheating" because "I believe the meaning of life is" might already shove it into the relevant semantic space without any help from , so it's perhaps more relevant what happens if I ask it to generate text without any prompt:
Question is a single thing to find. to be in the best to be happy. I is the only way to be happy.
I is the only way to be happy.
I is the only way to be happy.
It is the only way to be happy.. to be happy.. to be happy. to
Again almost feels like some grotesque unethical neuroscience experiment, but the generated text seems semantically related to the original text used for the clipping.
One thing to note is that the reason it started with the word "Question" is because most of the promptless generations for the unclipped network look roughly like the word "Question:" followed by some borked math test:
Question:
Let k be 2/(-3) - (-2)/(-3). Let o be (k/(-2))/(1/4). Let r be (o/(-5))/((-2)/(-5)). Which is the closest to 0.1? (a) -0.3
So this projection sort-of-kind-of works at projecting down to a semantically related subspace, though it has a tendency to break a lot. I thought maybe the reason it broke was because it lost all the grammatical skills it didn't use for the particular text it generated, so I set out to identify its general-purpose skills that are needed for most texts, so I could guarantee that I wouldn't unnecessarily clip those away while zooming in on particular topics.
Subspace overlap
Given two texts and , we can compare their matrices and . In particular we could look at their intersection. To estimate the number of dimensions that pairs of texts share, I looked at the size of the pairwise matrices (which should be equal to unless I did my math wrong) over four prompts:
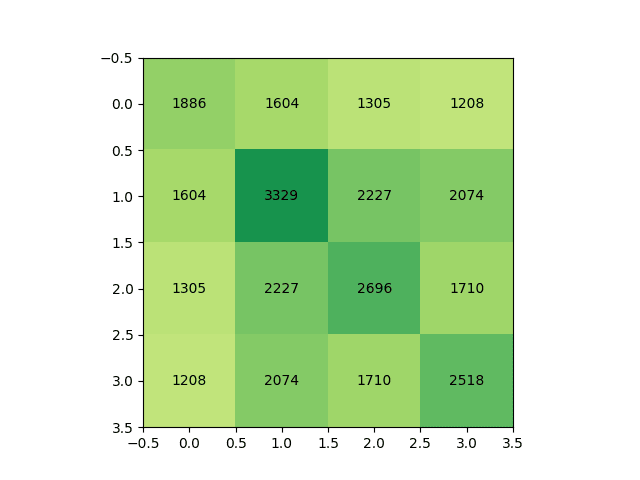
If we divide these by , then then we find that the off-diagonal elements are the product of the corresponding diagonal elements, down to an error of around 1%. That is, if is the matrix above, then when , we have .
On the one hand, this is a sensible result assuming no structure. If each text uses a random subspace, then it would make sense that the dimensionality of their intersection is exactly proportional to the product of their dimensionalities.
On the other hand, "assuming no structure" seems wild. Shouldn't there be shared structure based on the English language? And non-shared structure based on the unique knowledge used by each task? Like the entire hope with this approach would be that the dimensions under consideration are meaningful.
I thought maybe the issue was that I was only considering pairwise intersections, so I concatenated over the four prompts and performed SVD of that, which yielded the spectrum below:
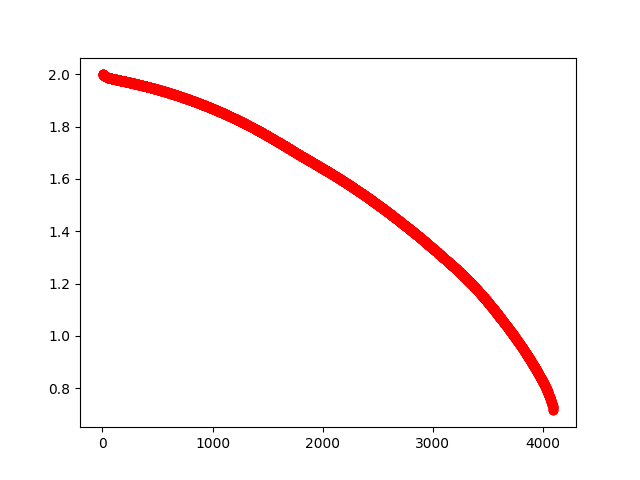
If you square each singular value, you get the number of texts that included a given dimension; so for instance the highest singular value is , corresponding to the fact that texts went into this analysis. In the middle we have 1.6ish. If we assume each dimension has 64% chance of being picked, then that is a reasonable number, since .
Here, the least-used dimension was used something like th as much as the most-used dimension. I was unsure whether this was just a fluke due to the low sample size, so I reasoned that if I repeated this with around 1200 texts, I could measure the frequency each dimension was used with a maximum error bound of about 10%. To get this many texts, I used Llama3-8b to just generate texts without any prompts (which again ended up mostly being math with a bit of other stuff mixed into it), and then I ran it overnight, yielding this plot:
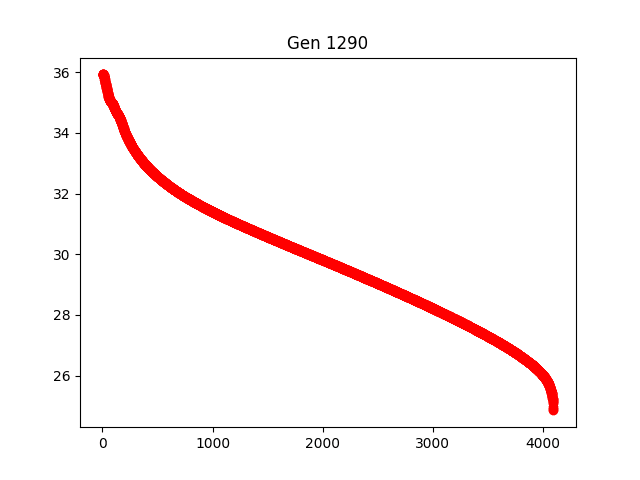
This ranges from (probably it only actually goes up to 35.9? I should have made it save the numbers so I could check it exactly, but I didn't) down to . Since , it seems even the least-used dimension must be used by at least half the texts, which I take as evidence that Llama3-8b has no domain-specific dimensions. Every dimension is used by a substantial fraction of the texts it can generate. That said, there logically speaking must still be some "domain-biased" dimensions, as otherwise activation engineering wouldn't work at all, plus we did see some success when clipping to the dimensions.
Discussion
While I've been following activation engineering on and off for years, I'm a beginner at the hands-on stuff, and I've only fiddled with study for a few days, so I don't know how obvious these results would be to people who are more experienced with it.
So far, I've come up with three major explanations for these results:
- This is a consequence of superposition [? · GW]. Language models are extremely starved for dimensionality in their hidden space, so they use tricks to squeeze as much information into it as possible, leading to them exploiting all the dimensions that they can.
- I'm just lumping the activations for each layer together, but maybe sometimes there's layer-specific meanings to the activations, such that this doesn't make sense.
- Something like a "general capabilities" hypothesis is more true than a "stochastic parrot" hypothesis; rather than learning to memorize facts and algorithms, the network learns highly general-purpose reasoning methods which can be applied to all texts.
Given my current results, it doesn't seem like there's anything that "screams" with a need to be investigated. That said, to ensure generalizability, I might do some experiments on larger models (e.g. Llama3-70B), longer texts, or experiments where I separate it by layer. Maybe such investigations could also help distinguish between the three explanations above.
This isn't to say that my current results are particularly definitive. There were too many degrees of freedom (e.g. why order by singular value rather than importance for probabilities? why use probabilities rather than KL-divergence? why discretize the dimensions into "used vs not-used" when looking for generally important dimensions?). Maybe picking some other combination for these degrees of freedom would yield a different result, but I don't currently have anything that points at a particular combination that must be used.
If for some reason activation subspaces turn out to be important, I guess I might also more thoroughly document the steps.
- ^
One picks an ordering such that when , then .
- ^
In addition to the meaning of life text, there were three other texts used for the diagram:
[Simply put, the theory of relativity states that ]1) the laws of physics are the same for all non-accelerating observers, and 2) the speed of light in a vacuum is the same for all observers, regardless of their relative motion or of the motion of the source of the light. Special relativity is a theory of the structure of spacetime
and
[A brief message congratulating the team on the launch:
Hi everyone,
I just] wanted to congratulate you all on the launch. I hope
that the launch went well. I know that it was a bit of a
challenge, but I think that you all did a great job. I am
proud to be a part of the team.Thank you for your
and
[Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
plush girafe => girafe peluche
cheese =>] fromage
pink => rose
blue => bleu
red => rouge
yellow => jaune
purple => violet
brown => brun
green => vert
orange => orange
black => noir
white => blanc
gold => or
silver => argent
4 comments
Comments sorted by top scores.
comment by tailcalled · 2024-05-22T11:48:01.733Z · LW(p) · GW(p)
Actually one more thing I'm probably also gonna do is create a big subspace overlap matrix and factor it in some way to see if I can split off some different modules. I had intended to do that originally, but the finding that all the dimensions were used at least half the time made me pessimistic about it. But I should Try Harder.
Replies from: tailcalled↑ comment by tailcalled · 2024-05-22T14:06:10.835Z · LW(p) · GW(p)
One thing I'm thinking is that the additive structure on its own isn't going to be sufficient for this and I'm going to need to use intersections more.
Replies from: tailcalled↑ comment by tailcalled · 2024-05-23T10:44:11.745Z · LW(p) · GW(p)
Realization: the binary multiplicative structure can probably be recovered fairly well from the binary additive structure + unary eigendecomposition?
Let's say you've got three subspaces , and (represented as projection matrices). Imagine that one prompt uses dimensions , and another prompt uses dimensions . If we take the difference, we get . Notably, the positive eigenvalues correspond to X, and the negative eigenvalues correspond to .
Define to yield the part of with positive eigenvalues (which I suppose for projection matrices has a closed form of , but the point is it's unary and therefore nicer to deal with mathematically). You get , and you get .
Replies from: tailcalled↑ comment by tailcalled · 2024-05-23T12:53:31.239Z · LW(p) · GW(p)
Maybe I just need to do epic layers of eigendecomposition...