What's going on with Per-Component Weight Updates?
post by 4gate · 2024-08-22T21:22:46.728Z · LW · GW · 0 commentsContents
What This Is Why We Might Care About This The Scope of This Exploration The ResNet Zoomed In: First 2K Steps (Looks Smoother for that reason) Double Descent? FC Is Monotonic WTF Is Going on With Batch Norm? Induction Heads 2L Log Plot, Global Weight-Change Norm 1L, 2L, 3L Regular Plot, Global Weight-Change Norm 1L, 2L, 3L Regular Plot, Per-Head Weight-Change Norm (Zoomed into the phase change section, elsewhere it looks like the global one) Discussion None No comments
Hi all, this is my first post on LW. It's a small one, but I want improve my writing, get into the habit of sharing my work, and maybe exchange some ideas in case anyone has already gotten further along some projection of my trajectory.
TLDR: I looked at the L2 norm of weight updates/changes to see if it correlates with Grokking. It doesn't seem to trivially, but something non-obvious might be happening.
What This Is
In this post I'm mainly just sharing a small exploration I did into the way weights change over training. I was inspired by some of the older Grokking/phase change work (i.e. on modular addition [AF · GW] and induction heads). Broadly, this previous work finds that sometimes deep learning models suddenly "grok"—a phenomenon in which the model suddenly starts to improve its performance after exhibiting diminishing returns, usually associated with some algorithmic improvement in how it processes/represents data as well as potentially the usage of composition. My guess is that Grokking occurs when components in a model find a way to compose, creating a virtuous cycle of gradient updates towards a new algorithmic paradigm. My guess is also that on some level, once some concept has been Grokked, its substrate (roughly) ceases to change and in the short term other components, instead, change to be able to best utilize the concept. For example, in vision models I'm guessing that some of the first components to be learned are simple edge detectors and color/frequency detectors, and that once they are learned, they change little and most gradient updates affect users of those components. AFAIK some research supports these ideas[1], but I don't think it's conclusive. If this hypothesis is true, we should be able to see that for known phase changes, the gradient updates per-component become diminished for the components that grokked around the same time the grokking occurs and so I went out to test two toy examples: one based on the great induction heads tutorial from transformer lens and one based on the default Pytorch ResNet.
The rest of this post is structured in the following way:
- Why We Might Care About This
- Scope of This Exploration
- The ResNet
- Induction Heads
- Discussion
Why We Might Care About This
I think this question of Grokking is primarily of scientific interest, and so any benefits would be further downstream. However, you could in principle use a grokking detector to:
- Help guide efforts for intrinsic interpretability or increased performance. This comes in a few flavors.
- Cut off training or freeze layers early: this could be good for efficiency.
- Guide architecture search for faster Grokking: this could be good for both performance, (sample) efficiency, and intrinsic interpretability (since we would probably have to have a more in-depth understanding of the types of algorithms encouraged by the encoded inductive biases and/or they would be more narrow than they are now).
- Detect when a DL model may be gaining human-level or super intelligence, when other signals such as eyeballing loss or test-set accuracy may not be informative (i.e. due to saturation). This could be a useful tool in the safety toolbox when we start to wade into increasingly unknown territory. It could also help measure model capabilities increases in a more principled way than, say, FLOPs or dollars.
- Help guide interpretability efforts. For example, if we can isolate where in the network the Grokking happened, then we can narrow down our search for circuits. A broader understanding of grokking, also, could also potentially help us extract discoveries (i.e. for Physics) from the models, meaning that automated Physics/Biology/Material Science labs' solutions (to problems such as generating a protein that does X or a laser firing pattern that optimally cools down a gas under some circumstances) would be (a little) less of a black box, and therefore safer and more useful.
The Scope of This Exploration
The core question I'm trying to answer here is pretty basic: is it easy to detect Grokking and/or is there any obvious pattern that brings up compelling questions? Per the TLDR, it seems like sort of but not really.
Below you can access all my code on github.
The ResNet
I trained the default Resnet from Pytorch with lr=0.01, momentum=0.9, weight_decay=5e-4, batch_size=128, shuffle=True, and random horizontal flips (look at the github for more details) for 800 epochs on CIFAR-10. Every 20 steps I logged the norm of the gradient per-parameter. I smoothed the plots using an exponential running average (0.08 weight to previous values) and the gradient norm is passed through a logarithm.
Generally I found:
- The expected:
- Early layers tend to have their gradient norm converge to zero faster than later layers (i.e. each set of parameters has an initial massive drop, and that initial drop happens slightly earlier in the earlier layers, something more visible in one of the smaller plots).
- After the initial massive drop, once the gradients hit zero (within variance) they move more slowly.
- Gradients are extremely noisy
- The unforeseen
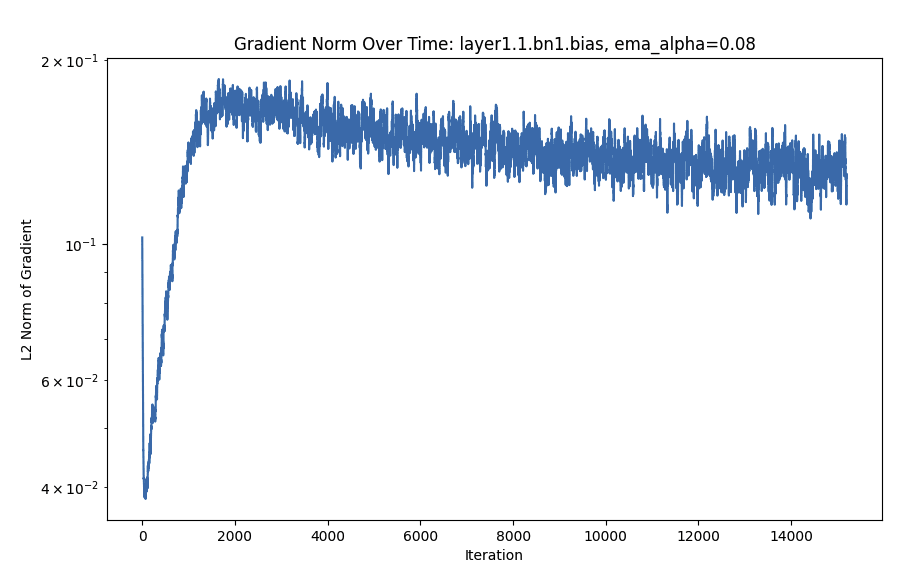
- Batch norm and downsample layers have gradients that consistently increase quite a bit after a steep initial drop.
- The gradient L2 values often follow a sort of deep double-descent curve. Interestingly, this is more marked for later layers. Sometimes, the descent has not yet gone down the second time (even after 800 epochs).
- Some layers, specifically, seem to have a noiser signal. The noise level appears to depend on layer?
- The final FC layer gradient goes down consistently.
I reproduced this multiple times with consistent qualitative results. Below are some of the plots.
Zoomed In: First 2K Steps (Looks Smoother for that reason)
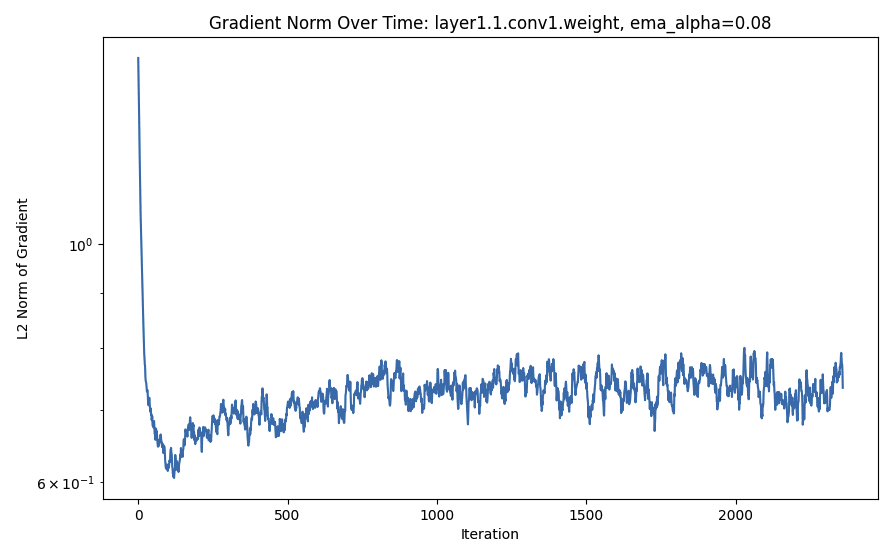
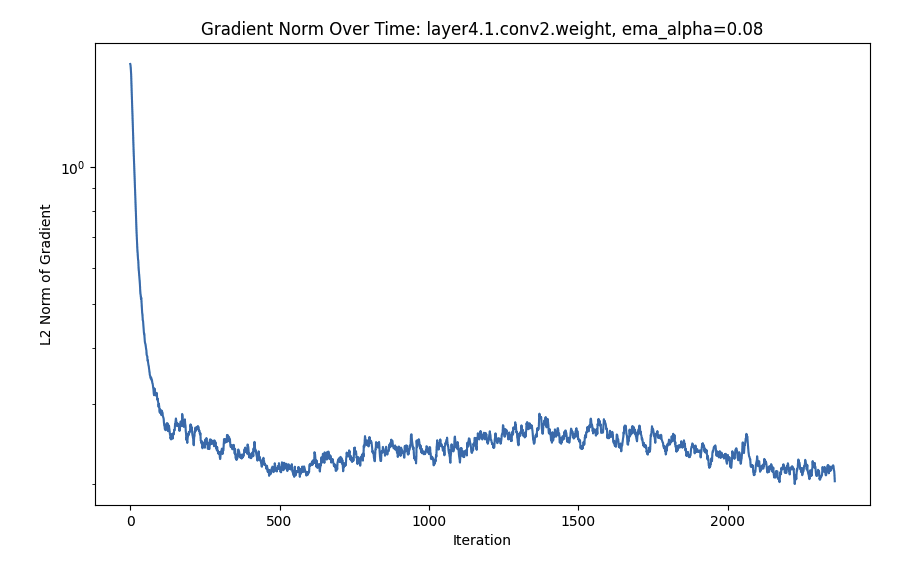
Double Descent?
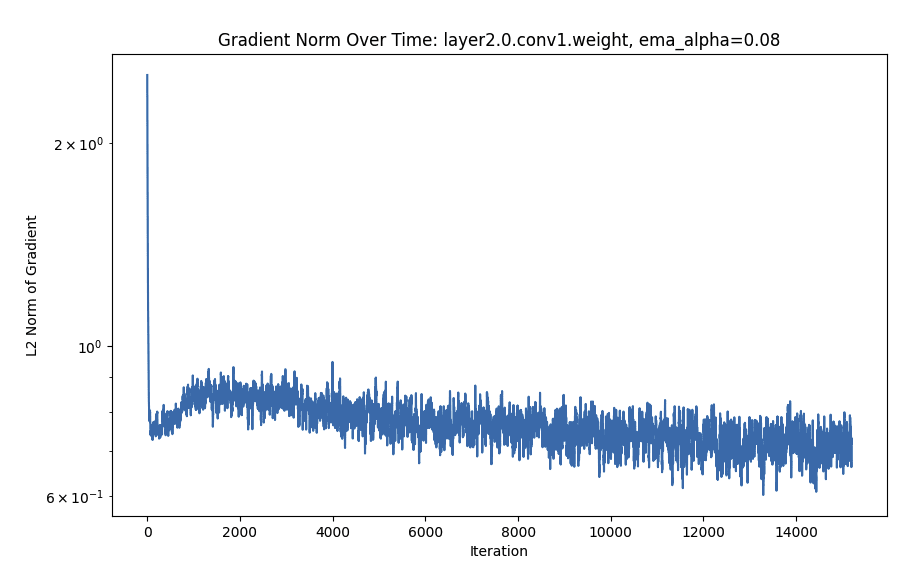
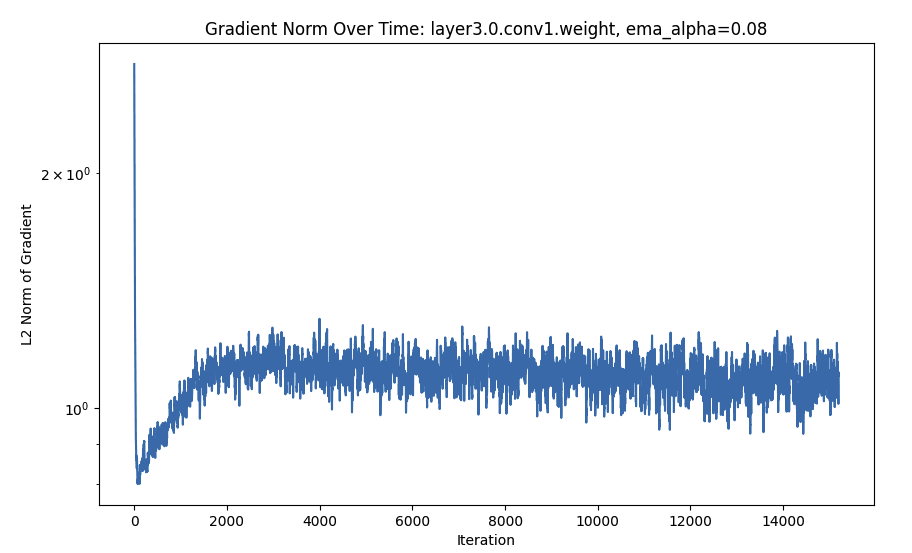
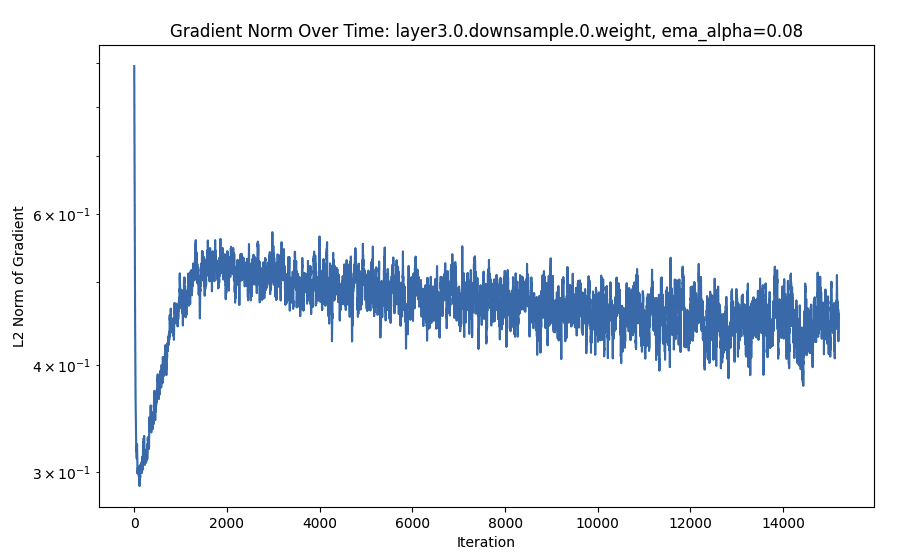
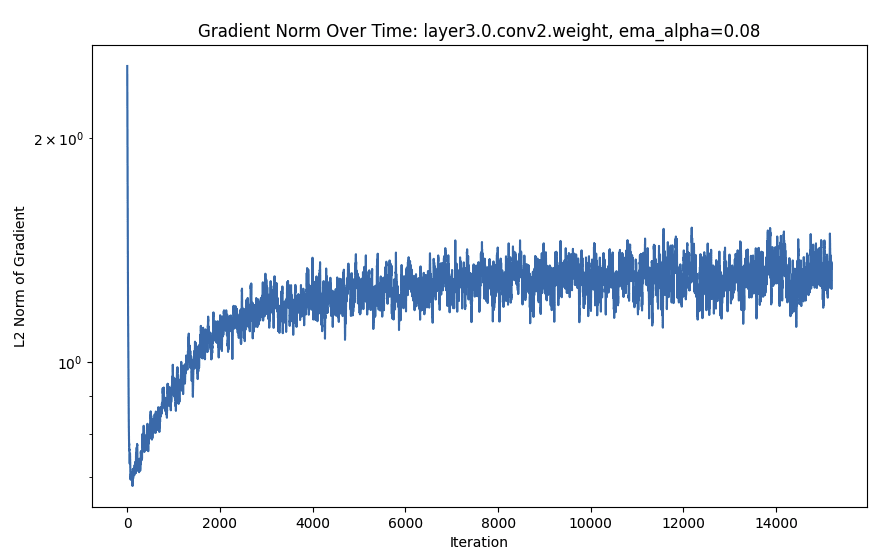
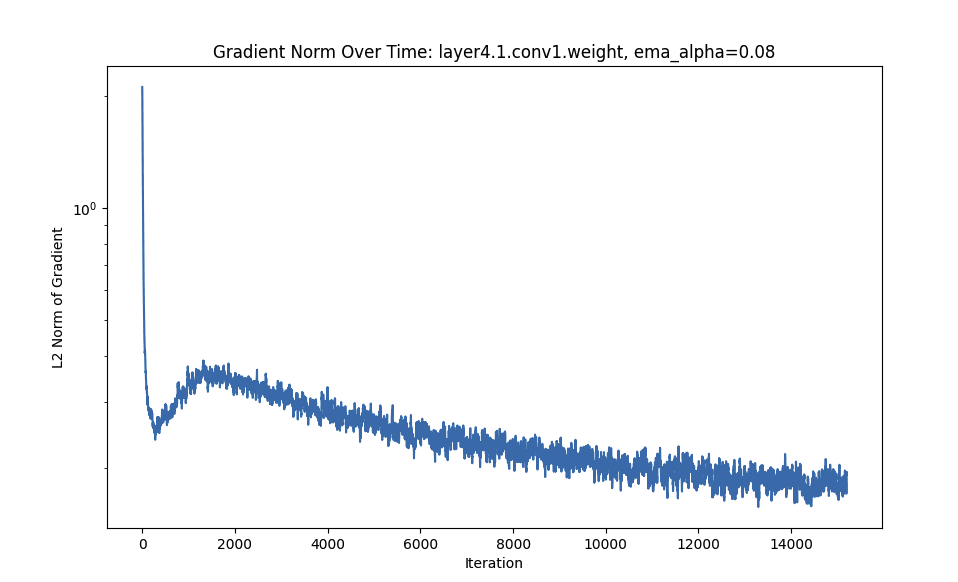
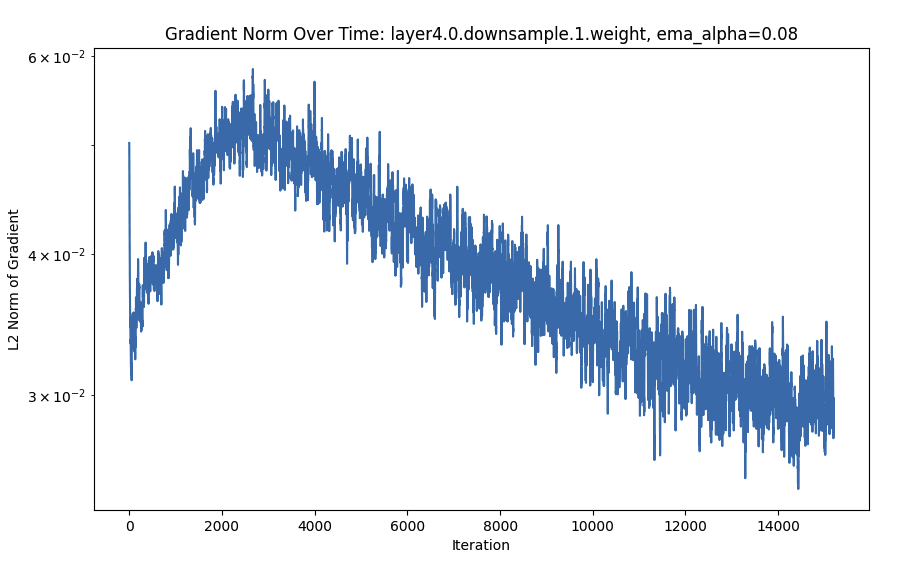
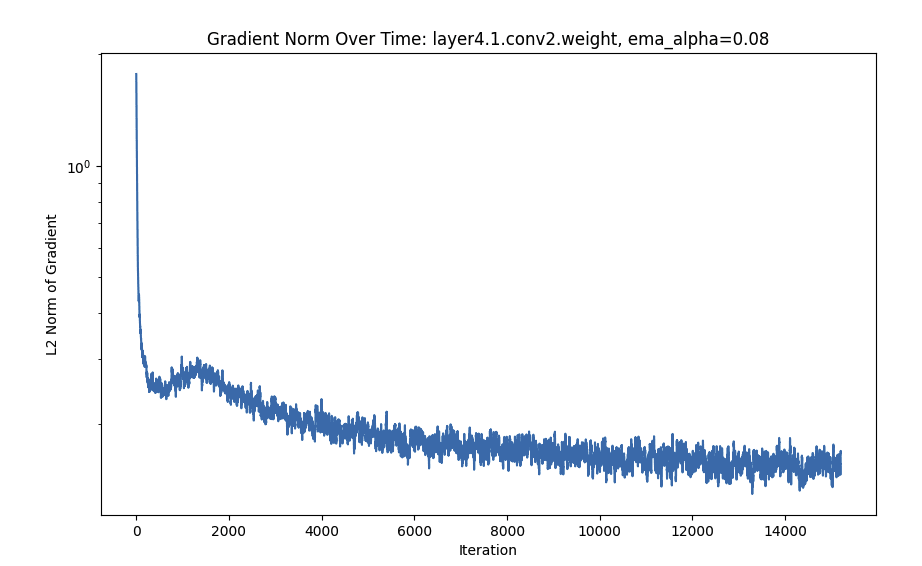
FC Is Monotonic
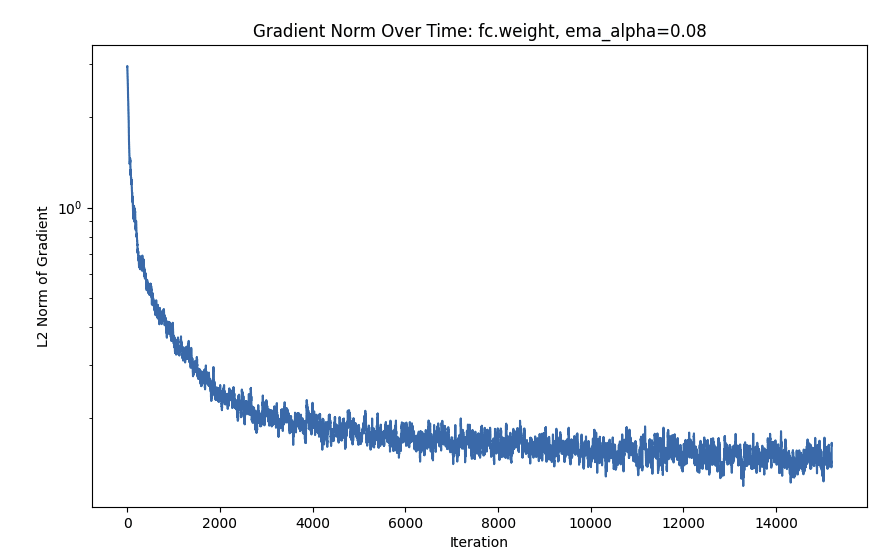
WTF Is Going on With Batch Norm?
Induction Heads
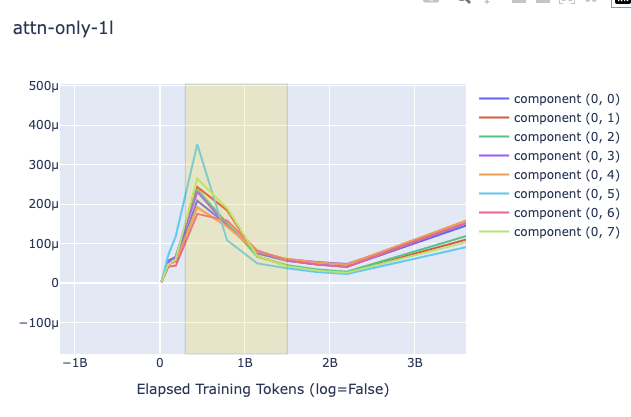
Because I have a relatively small training budget, I used the pre-existing 1L, 2L, and 3L models from Neel Nanda as used in the aforementioned induction heads tutorial. Because there is likely shuffling and other sources of randomness, I used the squared difference in the weights between all pairs of consecutive checkpoints (instead of the gradient) for the plots, as a proxy. I plotted on a regular plot (i.e. not log) to showcase the differences, since the checkpoints are not arithmetically uniform. I averaged all L2's of those distances by the number of parameters, which depended on the granularity (i.e. when using per-head analysis, I divided, for each head's weight L2 distance, the sum of those squares by the number of parameters in the heads' part of the computation graph). I looked at the L2 globally and per-head (and in the latter case I ignored the output bias since it was not clear which head to attribute it to).
The key question on my mind was do the 2L and 3L transformers showcase a different pattern in the change of (proxy) gradient L2 from the 1L around the time induction heads show up? Plots are below. The relevant heads that end up learning induction (have high induction score) are 1.6 and 1.7 for the 2L transformer (zero-indexed) and 2.3 and 2.7 for the 3L transformer. As you can see below, induction heads seem to have the highest gradient norms, but in 1L there is another head that has a much higher value as well, and sometimes they do not clearly "beat" the other heads. Around the time of the phase change there is a big change in the direction of the gradient magnitude, but it happens in 1L as well and is dwarfed by other sources of variation later (probably due to the known learning rate scheduling changes happening near 5B tokens).
In all plots, the yellow box corresponds to roughly when the phase change (for the creation of induction heads) is occurring.
2L Log Plot, Global Weight-Change Norm
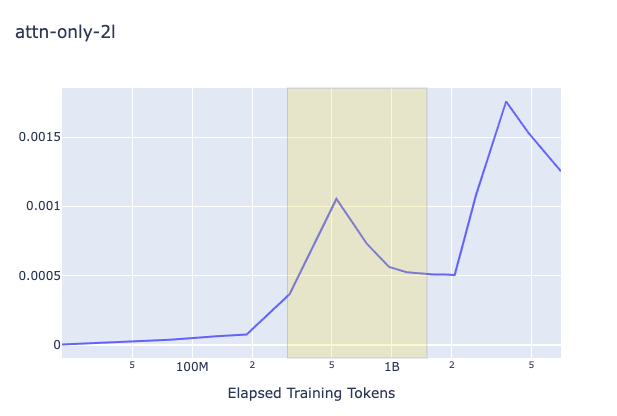
1L, 2L, 3L Regular Plot, Global Weight-Change Norm
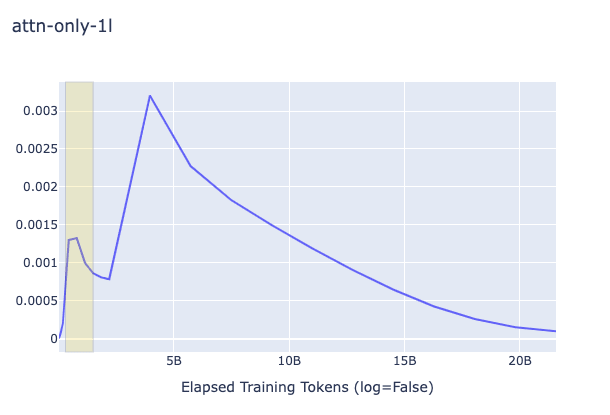
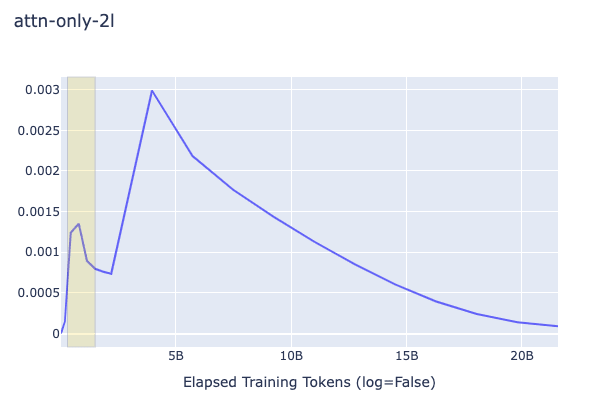
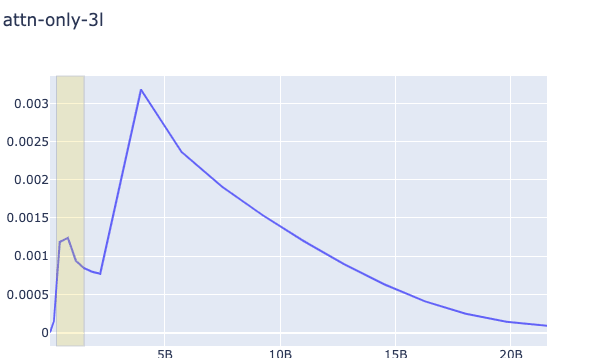
1L, 2L, 3L Regular Plot, Per-Head Weight-Change Norm (Zoomed into the phase change section, elsewhere it looks like the global one)
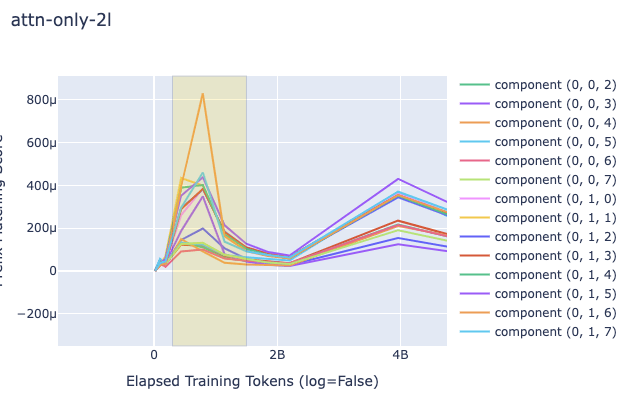
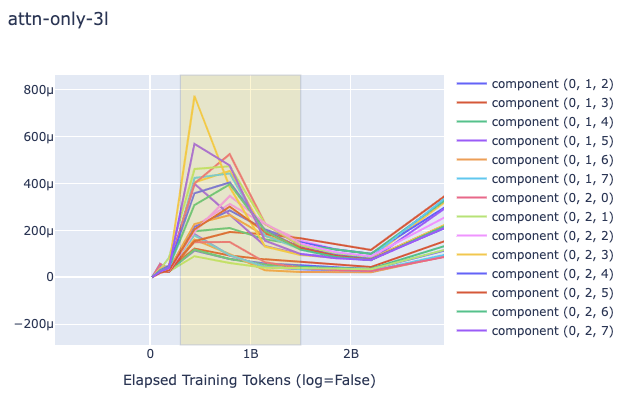
Discussion
As you can see in the above plots for induction heads, there is not a significantly clearer signal that grokking is occurring, simply due to the L2 of the change of the weights of the attention heads. It is striking, nonetheless, that the gradient norm drops in that way. I'm guessing that like in the ResNet case, these growths and subsequent drops in gradient norms may be part of a double-descent phenomenon, and it would be intuitive to think that this is caused by a grok/composition/algorithmic phase change of some form, but what then would the 1L model be learning? Could it be that induction heads are actually brought about by the grokking of some prior mechanism which is also present in the 1L model? Given that the heads gradients do the up-down motion more than and before others it doesn't seem likely. It might be due to 300M token warmup, but as you can see in the log plot, that point doesn't exactly match the shape of the curve.
Generally it seems that if there is something to be learned about grokking from the L2 norms of gradients it may require more work than this. I also think it would require a good dataset of known Groks along with metrics to detect them and the models they occur in, to be able to, in a more automated fashion, look for interesting phenomena. Some next steps to pursue are obviously to train the induction heads models myself and reproduce the algorithmic tasks examples prior MI work explored (such as modular addition) including these sorts of metrics. For the ResNet we also probably want some way to do the same: some sort of "curve matching" and "high-low frequency" (etc...) score, so that we can tell whether the network has grokked known visual features.
One unknown is whether the split of components by model DAG is OK—maybe there is a better weight-space basis to use, in which case partitioning into subspaces by component may not be ideal. For example, activation subspaces that are not in the standard basis may become linked in some way across components, and this would probably best be analyzed as pertaining to weights that are not in the standard weight basis either. Something that is more likely is that the hyperparameters are in large part to blame for some of this behavior, so that requires some experimentation.
Overall, it seems rather unclear how to derive utility or information from this sort of stuff without doing larger scale experiments. I'm curious if anyone has any ideas, because Grokking is of scientific interest, and I think looking where the network changes might not be a terrible idea in principle to find where Grokking may be occurring, but just looking at the L2 naively does not showcase any clearly useful findings.
- ^
I also distinctly remember reading a paper at some point where the authors found that it was possible to freeze layers in sequence by depth, during the training of ResNet, keeping the final accuracy equal (within variance). For example, after training on epochs they would cease to perform gradient updates on the first layer/block, after they would cease to perform updates on the first two layers, and so on. This was pursued out of an interest in training cost/speed, but I couldn't find the specific link after a cursor search. If anyone finds this it would be cool. I am curious if you could train smaller networks and concatenate layers instead.
0 comments
Comments sorted by top scores.