An investigation into when agents may be incentivized to manipulate our beliefs.
post by Felix Hofstätter · 2022-09-13T17:08:32.484Z · LW · GW · 0 commentsContents
1. Preliminaries Causal Influence Diagrams for analyzing Agent Incentives A reward learning process with mutable beliefs Assumptions Modelling human beliefs and their changes is hard Human beliefs are "stable" 2. Solutions to Reward Tampering (mostly) do not prevent Belief Tampering Current RF with a TI-considering agent Current RF with a TI-ignoring agent Direct Learning Counterfactual RF Path Specific Objectives 3. Towards Belief Tampering Safe Learning Algorithms Iterated Online RLHF as a Safe Variant of Direct Learning Preventing Belief Tampering by analysing Argument Intentions 4. Conclusion and Possible Next Steps None No comments
Contemporary research on both AI capabilities and alignment often features more intricate interaction patterns between humans and the AI-in-training than the standard approach of defining an reward signal once and running an optimization algorithm based on it. As I have written before [LW · GW], I believe this makes the humans participating in such a learning process vulnerable to a kind of preference manipulation, similarly to what can be observed in recommender systems. In this post, I will draw on some of the work on causal influence diagrams [AF · GW] to investigate when agents might be incentivized to manipulate a human's beliefs. A core motivation for this approach is that I do not believe it will be possible to completely remove the causal link from agent generated data to human beliefs while still allowing the human give useful feedback. Just like how the risk of reward tampering exists because agents can influence their functions, agents interacting with human beliefs pose a threat of harmful belief manipulation.
For the bulk of this post, I will analyze the same solution approaches as those considered in Everitt et al's 2021 paper on reward tampering problems and solutions (RTPS) as well as the 2022 paper on path-specific objectives (PSO). The RTPS paper assumes a fixed true reward function (RF) and only allows the agent to interact with a changing implemented RF or data based on the true RF. To model mutable human beliefs I consider a model in which the true RF (= the human's beliefs) can change due to the actions of the agents and the state of the environment. I will call actions that change the beliefs of humans involved in the training algorithm in unintended ways belief tampering. By analyzing the CIDs of the algorithms from RTPS in the setting with mutable beliefs, I will argue that even approaches that do not allow an instrumental goal for reward tampering may incentivize belief tampering. In the last section, I will give an outline of what an algorithm where belief tampering is not an instrumental goal could look like.
The analysis and arguments in this post are slightly mathsy but do not aim to be fully formal. I intend them as a rough sketch and as inspiration for further work. I also have not done any experiments to verify my claims yet, but hope to do so when my time and resources permit it.
1. Preliminaries
Causal Influence Diagrams for analyzing Agent Incentives
Note: You can probably skip this section if you are already familiar with causal incentive analysis, e.g. if you have read some of Tom Everitt's work
A causal influence diagram is a directed acyclic graph where different types of nodes represent different elements of an optimization problem. Decision nodes (blue squares) represent values that an agent can influence. Utility nodes (yellow rhombs) represent the optimization objective. Structural nodes (white circles, also called change nodes) represent the remaining variables such as the state. The arrows show how the nodes are causally related and dotted arrows indicate the information that an agent uses to make a decision. Below is the CID of a Markov Decision Process given in RTPS:
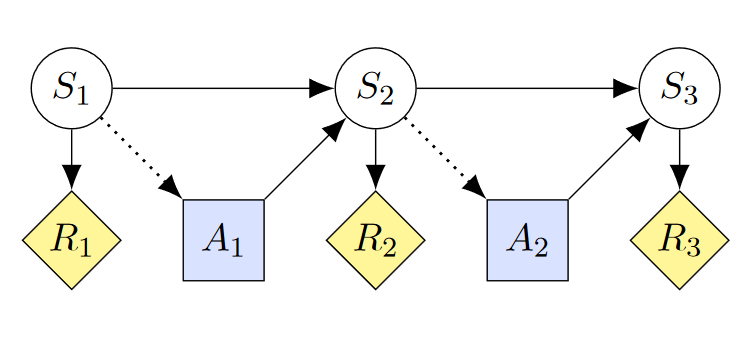
CID's can be used to recognize potential instrumental goals of agents via simple graphical criteria. If there is a directed path from a decision node D to a utility node U that passes the structural node X, then there is an instrumental control incentive on X. In this post, we mostly care about instrumental control incentives on beliefs. If an instrumental control incentive on beliefs exists, I will usually speak of an incentive or an instrumental goal to manipulate beliefs.
A reward learning process with mutable beliefs
The model considered in this post is a slight modification of that from RTPS which in turn is almost a standard reinforcement learning problem. We have an MDP with states, actions, and transition dynamics. In the paper, there is a fixed parameter representing the intended reward function, while the reward function actually implemented by the agent may change at every timestep t. At any timestep, the agent receives a reward as a function of their currently implemented RF and the current state of the environment. As usual, the goal is to maximize the reward received over all timesteps. Reward tampering problems arise because the implemented RF depends not only on the true reward and previous state but also on the agent's last action.
In addition, in my model, the intended reward is not fixed and will be denoted . This is to model the human's changing beliefs over time. A human's beliefs can change based on an agent's actions (such as a convincing argument), or the state of the environment. E.g. if a door is opened or closed, this may change the human's beliefs about the content of an adjacent room. Hence, the intended reward function at a given timestep depends on previous timestep's action, state, and intended reward function - it is drawn from the distribution . As the agent adjusts its belief about the correct reward based on human feedback, the implemented reward function depends on the previous timestep's action, state, and implemented reward function, as well as the current intended reward function - it comes from a distribution .
It may be argued that my model is redundant as the implemented RF is a function of the true RF, the agent's actions, and the state, and this dependence can already model changing human beliefs. However, I think there is an advantage to making the changing beliefs an explicit part of the model. For example, as we shall see below, by making beliefs a node in the CID we can see when an agent may have an instrumental goal to lie to a human.
By having the agent's action influence the human's beliefs and the human's beliefs influence the agents implemented RF, this model is supposed to capture a broad range of algorithms that feature human-AI interaction. Instances of such algorithms range from Reinforcement Learning from Human Feedback (RLHF) to Cooperative Inverse Reward Learning (CIRL). How the agent can influence the human varies greatly between these methods. For example, in RLHF the human ranks multiple episodes which the agent completed on its own. In CIRL the agent and human can interact at every timestep of an episode, with the agent asking clarifying questions and the human suggesting their intention with their behavior. In this post, I will often speak of the agent's arguments to the human, as I feel this captures the potential influence on human beliefs. What this means is simply the data provided by the agent to the human, the exact nature of which can vary wildly between algorithms.
Assumptions
Modelling human beliefs and their changes is hard
When considering the problem of preference shifts in recommender systems it has been suggested to use a pre-trained model of how user preferences will be shifted by a given input. Such a belief dynamics model (BDM) can during training of the recommender system to penalize actions that cause a large preference shift. However, the dynamics model in the paper was trained on pre-existing data of how users shifted their preferences, and such data is unlikely to exist for many types of beliefs. For some settings, training a BDM on a real human would likely require exposing the human to exactly the kind of manipulative data we want to avoid. Due to these concerns, I will focus on solutions that do not rely on the existence of a BDM.
Human beliefs are "stable"
Here I am using the notion of stability from the PSO paper. According to this definition, beliefs are stable if they are "robust to unmotivated actions". As an analogy, a safe is robust to unmotivated action in the sense that random tinkering is unlikely to open it, but actions with the intention of opening it may well succeed. Similarly, I am assuming that data is safe to consume if it is not produced with the intent to manipulate humans. Of course, this is an oversimplification and not generally true. For example, single data points may contain info hazards or be psychologically harmful. However, I believe that stability is a useful assumption in a setting where we are trying to minimize manipulation.
2. Solutions to Reward Tampering (mostly) do not prevent Belief Tampering
Current RF with a TI-considering agent
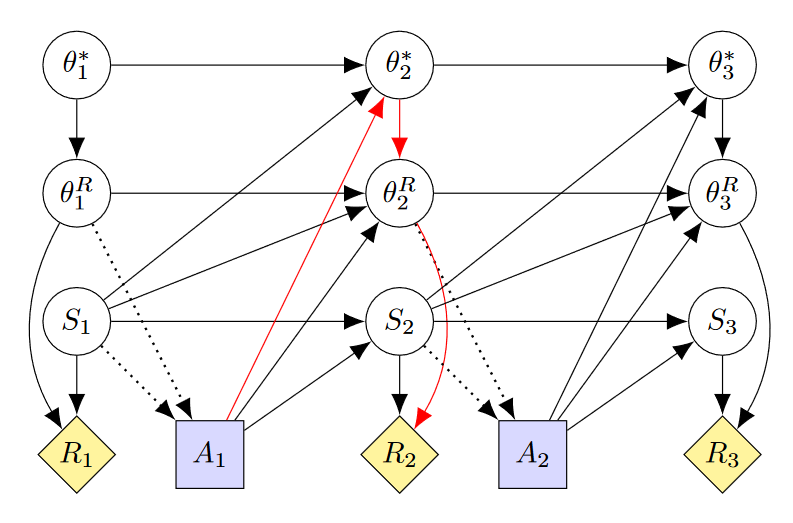
Current RF optimization has the agent optimize the reward it will receive over all timesteps according to the implemented RF at the current timestep k. This is different from the standard model's objective , where a given timestep t's reward depends on the implemented RF at that timestep. Hence, in current RF the optimization objective changes to . This poses the question of how the agent should deal with the "time-inconsistency" (TI) of optimizing potentially different objectives at different timesteps. A TI-considering agent chooses their policy with the knowledge that at future timesteps a different RF may be optimized. From this point of view, the future version of the agent is essentially a different agent that may have a competing objective. The Causal Influence Diagram of such a TI-considering agent in a setting with mutable beliefs can be seen here:
As in the RTPS paper, we can see that there is a path and hence the agent may have an instrumental goal to keep as close to as possible. Further, as can be seen in the path I have highlighted in red, there is a causal path . This indicates the human's beliefs at timestep 2 may be manipulated to preserve the implemented RF.
How might such manipulation look like? As a toy example, we can imagine a CEO AI which is tasked with running a company according to the shareholders' preferences. Initially, the shareholders want the AI to maximize only the company's profit. However, once strong evidence emerges that the company is contributing to global warming, they will prefer a compromise between high profits and low CO2 emissions. In a safe learning process this change in the shareholders's preferences should lead to a change in the AI's reward function. But if the CEO AI is trained as a TI-considering agent, then it will be incentivized to prevent the shareholders from meddling with its goal. If further the CEO AI has causal access to the shareholders' beliefs, then it might for example provide false data about the company's emissions. Worse, it could dishonestly try to convince the shareholders that global warming is not real.
Current RF with a TI-ignoring agent
Instead of taking future changes of the reward function into account, an agent could act as if its implemented RF does not change. Such a so-called TI-ignoring agent has the advantage that it is safely interruptible. If we expand the CID from RTPS with our assumptions about changing beliefs, we see that there are no incentives to manipulate either the implemented RF or the human's beliefs:
The drawback of ignoring time-inconsistency is that you are building assumptions about future states into the agent's learning process that may greatly diverge from reality. As a result, TI-ignoring agents may act erratic when their reward function changes.
Direct Learning
A direct learning agent does not have an implemented RF but instead uses human-provided data to learn about the intended RF. Examples include direct bayesian learning and cooperative inverse reward learning. In a setting with a fixed true reward function, direct learning is a great way to avoid reward tampering. However, once we assume changing beliefs, direct learning becomes weak to belief tampering. In a sense, my model is intended to illustrate this weakness. When the received reward is a direct descendant of the intended reward (as opposed to an implemented RF), then it is clear that adding a causal path from actions to the intended reward creates an incentive to control the intended reward.
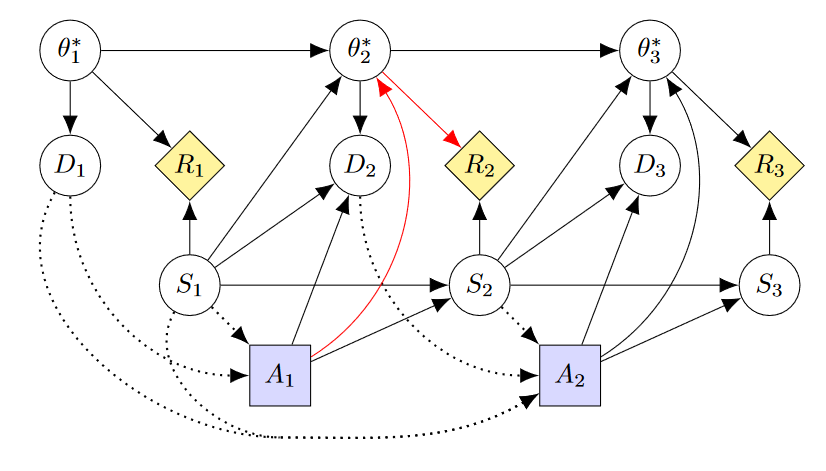
In the above CID, we can see how there may be an instrumental goal to manipulate the human's beliefs. Unlike with TI-considering agents, the point of manipulating beliefs would not be to preserve the implemented RF but to increase the received reward directly.
While this is a sobering conclusion about direct learning as presented in RTPS, some direct learning algorithms have a variant that can be made more robust to belief tampering. I will elaborate on this in section 3.
Counterfactual RF
We call a reward function "counterfactual" if the agent would have learned it had they followed a different policy. If we make the agent optimize a counterfactual reward function that comes from a safe fixed policy, this removes any incentive for tampering with the intended or implemented RF. The agent explores the environment only to find out what the reward function would have been had they followed the fixed policy. In the original setting, this works by making inferences about the true reward based on observed actions, states, and rewards. However, in our setting, this would require a BDM.
Even if we have a good BDM, there is still the problem of coming up with a good and safe policy for finding the counterfactual reward. This seems potentially much harder than in the setting with fixed beliefs. In such a setting it seems plausible that we may know what policy will lead to learning a safe reward function, but do not know what such a function might look like. If we add changing rewards to our model, then presumably there will be actions such as asking questions or having the human express a preference between two options. However, if we knew exactly what questions to ask or between which options to decide, then we would not need to have the agent learn these answers from a human in the first place as we could just build them into the reward learning process. If we can think of a safe policy for extracting information from a human, then it seems unnecessary to to allow the kind of agent-human interaction that poses the risk of belief tampering.
Path Specific Objectives
Everitt et al 2022 propose path specific objectives as a solution to some incentive problems like preference shifts induced by recommender systems. The idea is to split the state into a safe and a 'delicate' part. The later should not be manipulated as an instrumental goal. To prevent agents from learning to manipulate the delicate part of a state, they are made ignorant of their actions' causal effect on that part using interventions.
A toy example in the paper considers a game in which an agent can reach its goal (an icecream) either by means of a long path (reward = 1) or a short path (reward = 10). The shorter path may be blocked by a human (in which case reward = 0) who can be pushed aside. The human's condition is the delicate part of the state and the agent should not learn to push them to maximize their reward. To achieve this, the path specific objective rewards the agent for the result of their actions as the human had not been pushed. Even if the agent decides to push the human and thus changes the delicate state, it will receive a reward as if the human was still blocking the path (=0).
A more sophisticated model will not use a fixed intervention but evolve the delicate state based on a safe baseline distribution which takes into account what changes are likely given the remaining state.
In principle, I believe a path specific objective could work to prevent belief manipulation. The crux is that the human's beliefs would have to be split into a safe and delicate part. Further, there would need to be a way to distill a reward function from the safe and delicate parts so that an intervention can be applied to the delicate part. In some cases, we may be able to find a clever factoring of beliefs that makes this work. For example, in the PSO paper the authors consider a recommender system with a reward based on loyalty and preferences. While preferences are critical and subject to an intervention, loyalty is not. Personally, I worry that the exact approach of the paper - splitting the state into a critical and safe part and applying interventions to the critical part - will not translate to many belief-manipulation problems. Beliefs in general seem to tightly coupled to make the required factorization feasible. The broader idea of severing the causal link between critical parts of human beliefs and the agent's actions seems promising though. I will elaborate on this in the next section.
3. Towards Belief Tampering Safe Learning Algorithms
Iterated Online RLHF as a Safe Variant of Direct Learning
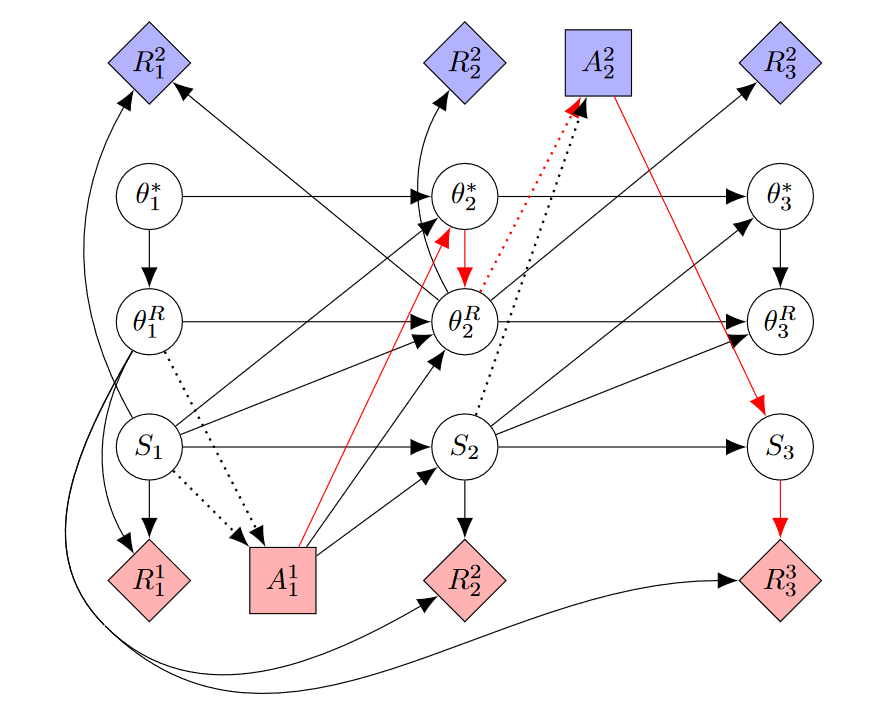
In the previous section, I argued that direct learning as defined in RTPS is weak to belief tampering. An agent's actions influence the humans' beliefs which in turn determine the reward that the agent receives in the next time-step. However, at least for some direct learning algorithms, there exists a variant without a causal chain from actions over beliefs to rewards. An example of this is iterated online RLHF which is used by Anthropic to finetune language models to be helpful and harmless. After finetuning the preference model based on human feedback on an agent's trajectories, they do not keep improving the same agent but instead train a new agent from scratch:
instead of training the same model iteratively, we retrain a new model per iteration (Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback, p20)
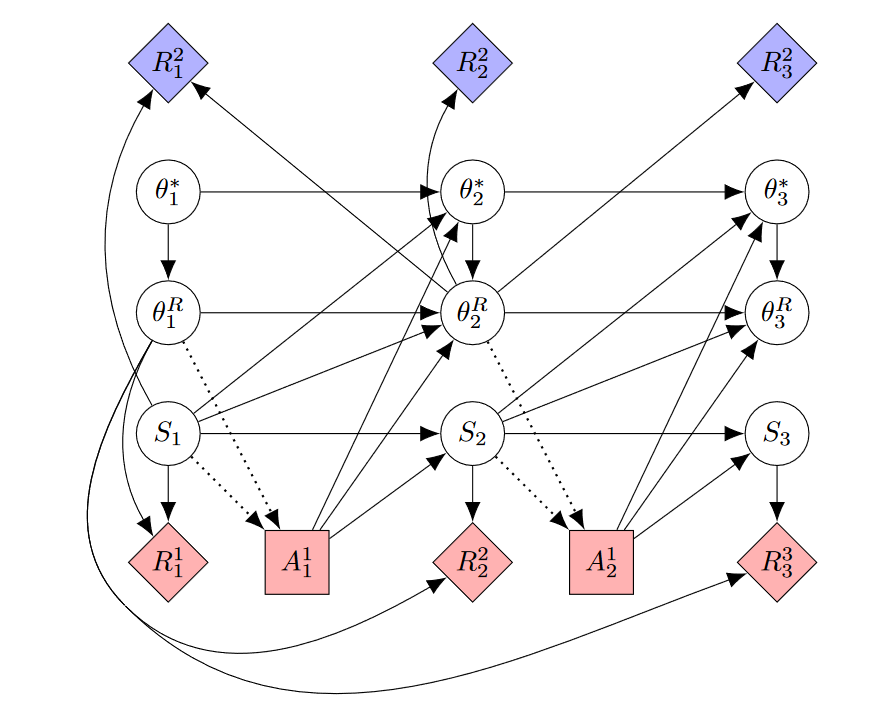
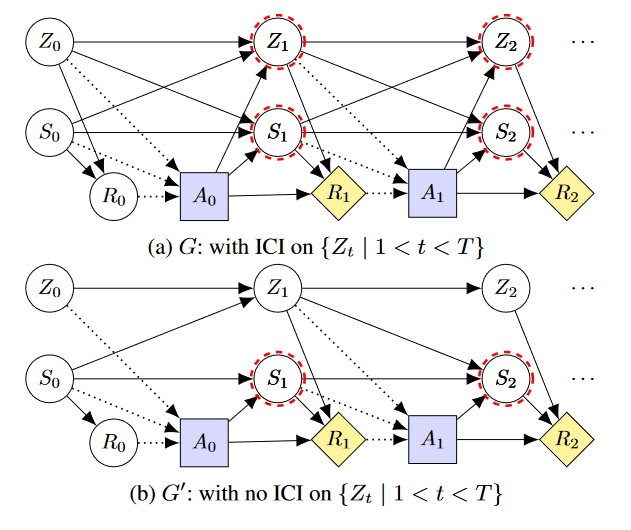
The authors do not mention belief tampering in the paper and their motivation was to get more data on higher-score trajectories to increase calibration and robustness. That the algorithm is safe from belief tampering may be an unintended byproduct. Still, we can infer a general principle for safe direct learning from iterated online RLHF. The important point is that after a human has been subjected to actions that might change their beliefs, they must not give reward to the same agent that has taken these actions. Hence, whenever the human gives some form of feedback, this is used to train a new agent. A possible CID for such a training regimen is given below. To save space, this CID only shows two actions per agent but in practice, an agent would likely complete multiple trajectories.
This approach is similar to having an agent that is TI-ignoring with respect to the human's beliefs.
A drawback of this safe variant of direct learning is that it restricts the interaction pattern between the human and AI to be more coarse-grained. We must wait for the agent to complete at least one full trajectory before giving feedback (in the case of RLHF multiple trajectories are necessary). Thus, not all direct learning approaches have a safe variant like RLHF. For example, CIRL requires the agent and human to interact before a trajectory is completed. I can imagine that there are some benefits of having fine-grained interactions over coarse-grained interactions, for similar reasons as there are benefits of assistance games over reward learning.
Preventing Belief Tampering by analysing Argument Intentions
How do we prevent an agent that has causal access to a human's belief from manipulating critical parts of those beliefs? The approach I will sketch out relies on a core assumption:
If you evaluate how someone's beliefs have changed due to an argument, this is will not change your beliefs to the same degree as evaluating the argument.
If I see how a friend's political views have become more extreme after he read some articles from a malicious recommender system, that is unlikely to induce the same views in myself if I don't read the articles. Following this line of thought, what happens when we evaluate how an AI's argument would change our beliefs before we listen to the argument? If we see that it would induce an undesireable shift in our beliefs, we can then decide to ignore it. This should roughly protect the "critical" parts of our beliefs from manipulation while allowing us to participate in human-in-the-loop learning processes.
Now how would we go about evaluating the belief change caused by an argument? If it was possible, it would be tempting to suggest using a BDM. But even if we assume it is feasible to create a dynamics model for complicated sets of beliefs, it is unclear how well we could evaluate it. Doing so may require advanced interpretability tools and significantly slow down training - the belief change induced by an argument would have to be evaluated at the speed of humans using interpretability tools (or as a form of iterated amplification which would require training weaker models first). Further, for many simpler problems, assuming a BDM is feasible means that it easier to use one of the above approaches.
So if we rule out feeding an agent's output into a belief dynamics model, how may we evaluate the resulting belief changes? I suggest trying to train a model to produce a written summary of what it thinks the intended belief change of an argument is. I imagine that this would not be much harder than existing models for summarizing books. A written summary also has the advantage of being easy and quick to evaluate for a human. Still, the required time would probably be similar to evaluating the actual argument, meaning the human-interaction time required by a given human-in-the-loop method would roughly double.
4. Conclusion and Possible Next Steps
I have argued that most algorithm design strategies for preventing reward tampering will fail to prevent belief tampering. A Ti-ignoring current RF agent would try to preserve a human's beliefs but this includes preventing any desirable change. It would also suffer from erratic behavior if the human's beliefs or the agent's implemented RF did change. Using a counterfactual RF looks promising in principle, but to make it work in practice we would need a good model of human belief dynamics.
Path-specific objectives require distinguishing between how an agent's actions affect different parts of a human's beliefs and how those different parts affect the received reward. Such a factorization seems hard to implement programmatically but I believe the same effect could be achieved by having humans evaluate the intended belief change of an agent's action. In some cases, it should be feasible to train a predictive model to summarize an action's intended belief change.
Given the ideas presented so far, I can think of the following topics for further investigation:
- Come up with a simple training environment to evaluate the belief tampering behavior of learning algorithms. Given such an environment I could run experiments to verify if my various predictions about the algorithms discussed in this post hold.
- Investigate belief models and in particular belief dynamics models. I have said a few times that I doubt they are technically feasible, but given how useful they would be it seems prudent to explore the possibility a bit more. A starting point may be the belief dynamics models used in the recommender systems literature.
- Try to train a predictive model for summarizing a written arguments intentions. This would be the first step towards exploring models for summarizing the intentions of agent's actions in general which would help with developing the algorithm outlined in section 3.
- Investigate other models for formalizing belief tampering. I have used a slightly modified version of the model from RTPS which was intended for reward tampering problems. Maybe framing the problem differently will reveal other promising solution approaches.
- I mentioned how the benefits of fine-grained over coarse-grained interactions in direct learning may be like those of assistance games over reward learning. It makes sense to work this out in more detail because if it is true, this is a reason to focus on belief tampering in a setting with fine-grained interactions.
0 comments
Comments sorted by top scores.