A Framework of Prediction Technologies
post by isaduan · 2021-10-03T10:26:34.928Z · LW · GW · 2 commentsContents
Summary Some warnings of my epistemic status: A Framework of Prediction Technologies [1] Data Analysis Pipelines 1.1. Classifiers and regressions Four use-cases 1.2 Agent-based models Two types of models, and how AI comes in [2] Augmented Human Forecasters Two ways of augmentation [3] General-purpose AI Prediction Services Embeddedness required? Notes None 2 comments
Summary
This is the first piece of a blog post series that explores how AI prediction services affect the risks of war. It is based on my 10-week summer research project at Stanford Existential Risk Institute.
In this post, I will discuss different prediction technologies - how they might be relevant to nation-state governments and what their development trajectories might look like. The second post [LW · GW] borrows from international relations literature to examine what implications follow for the risk of war. The third post [LW · GW] concludes with three possible world scenarios and a few final remarks.
Some warnings of my epistemic status:
- I have tried to survey different prediction technologies, but I am still by no means intimately familiar with them. I probably miss out on things and misjudge others.
- I have focused on rationalist models of wars and analyzed two pathways in which prediction services could change the general probability of wars:
The amount of private information, which affects the probability of reaching peace agreements;
The cost of wars, including offense-defense balance, international institutions, and the influence of domestic audiences.
However, wars break out for various reasons and for no reason. Further research that distinguishes different types of war (e.g. great power fringe war, nuclear war, high causality war) will likely be more useful, but that is beyond the scope of this analysis.
- Overall, I hope to provoke discussions, not to come to any conclusion. I make no rigorous quantifying model. I mostly just read, think, and talk to people. When I give my guess, it should be taken with the highest degree of reservation.
So, here’s an overarching guess: AI prediction services could gradually reduce the generic risk of war, not by reducing private information in peace bargaining, but by increasing the cost of war relative to peace.
A Framework of Prediction Technologies
Prediction is about generating new information from known information.[1] I understand prediction technologies as modeling tools. They structure known information in ways that generate useful new information. I outline a framework to understand different prediction technologies involving AI.[2]
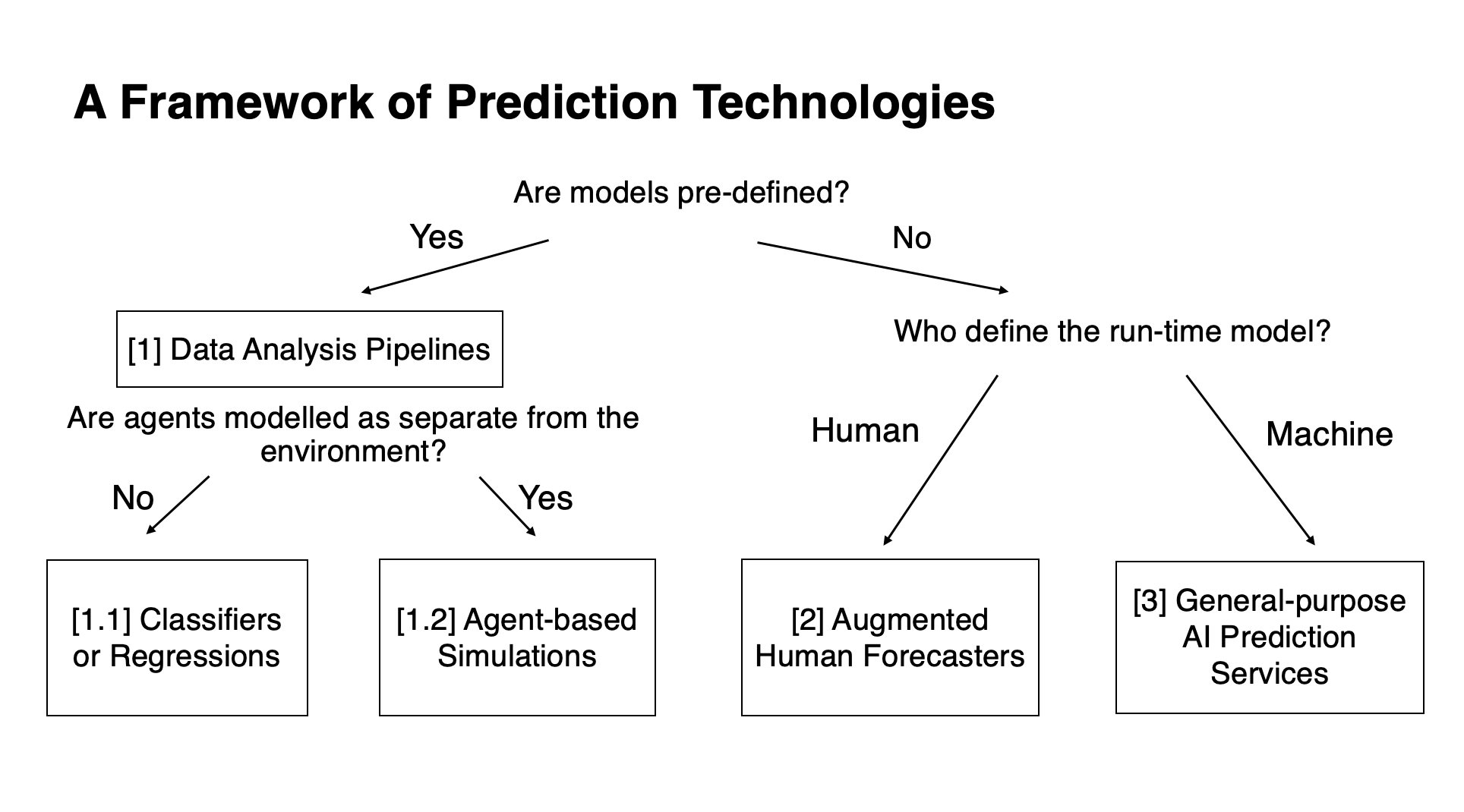
[1] Data Analysis Pipelines
1.1. Classifiers and regressions
Four use-cases
- Early warnings of social unrest, terrorist activities, or foreign adversaries’ military action. Governments can leverage large-scale surveillance data to generate early warnings of disruptive societal events, such as insurgency, violence, disease outbreaks, and resource shortages. Operating since 2014, the IARPA’s EMBERS system analyzes data from news, blogs, tweets, machine-coded events, currency rates, and food prices in ten Latin-American countries and delivers warnings of civil unrest at city-level spatial resolution and daily-level temporal resolution. It is built on several models and is said to be fault-tolerant. It successfully predicted many civil unrests including the Brazilian Spring and the Venezuelan Protests, with a mean lead-time of 10 days, a mean probability score of 0.88, and an average accuracy score of 75%.[3] It missed only two events of civil unrest due to a lack of linguistic and cultural understanding. In addition to open-source data, governments can leverage classified data, e.g. the US collects data from foreign targets' communication networks, radars, weapon systems, to detect terrorist activities and foreign adversaries' military actions.[4] The DOD’s GIDE program could predict adversaries’ moves in preparing for war with a few days’ lead-time.
- Suggesting profitable trade and investment opportunities. Hedge fund managers are using these technologies to find alpha streams that are less correlated, therefore slower to become crowded and more persistent, diversifying investment portfolios and adapting to changes in market conditions on an ongoing basis. Similarly, governments may have an interest in finding new economic partnerships, diversifying supply chains and buyer markets, and adjusting partnerships promptly.
- Monitoring law enforcement. Financial service industries as well as legal and regulatory institutions are using these technologies to detect anomalies, frauds, and inconsistencies with standards. Similarly, governments may have a shared interest in installing real-time monitors to enforce a coordinated policy action, for example on climate change or pandemics.
- Gathering rapport and reputation. Public relations and communication consultancies are using these technologies to construct persuasive advertisements and campaigns. Similarly, governments may have an interest in controlling norms and projecting influence over the domestic and international audience.
Development trajectory. My guess is that the development of data-driven classifiers and regressions are likely to see a performance boost in the next 5 years but face diminishing marginal returns to research efforts, with a wide range of variance for different prediction tasks.
- Near-term boost. The boost results from the growing importance of the internet-of-things and recent advancements in data collection and processing techniques such as natural language processing, computer vision, and speech recognition. It might also be facilitated by expanded sources of “alternative data” such as digital sensors, satellites, smartphones, by secured data transmission and storage techniques such as blockchain-enabled encryption, by improved processing techniques, and by integrated digital infrastructure such as the IARPA’s ongoing AGILE program.
- Diminishing marginal returns. This is commonly observed in ML.[5] I expect this to hold for data pipelines for three reasons:
- Better performing models are harder to find under the “stepping-on-toes” effect: increasing the complexity of prediction models only marginally increases accuracy, and the extra accuracy from complexity may be counterbalanced by overfitting the training data, given many sources of uncertainty such as changing population, sample selection bias, changing classification and concepts, and changing evaluation criteria.
- There are also practical challenges of data quality, data uncertainty, and data availability: streaming data could cause unpredictable changes to the stored data and models, and their quality and structures are unknown until runtime; moreover, regulation and prohibition of surveillance and data use could tamper the quality and availability of data.
- Separate from the insufficiency of models and data, complex social systems may exhibit some intrinsic unpredictability: simulation shows that even with unlimited data about users, followers, content, past performance, the state-of-the-art algorithm could only predict less than 50% of the variance in popularity of Tweets. When relaxing the perfect information assumption, even a small degree of uncertainty in one variable could lead to substantially more restrictive bounds on predictability.[6] This suggests that, for some prediction tasks, a marginal performance improvement can be prohibitively expensive and unlikely to be pursued even when theoretically possible.
Variance among tasks. Certain prediction tasks can be easier than others:
if skill, the stable, intrinsic attributes of studied object, relative to luck, the systemic randomness independent of the object, contributes to the outcomes of interests;
if as population-level outcomes, randomness among individual components balances out each other;
if there is less incentive to misrepresent the outcomes or if the misrepresentation is difficult, e.g. using vocal characteristics of presidential candidates, possibly an unconscious, difficult-to-manipulate cue, to predict the outcome of actual elections; [7]
if quasi-experiments are possible, data abundant, and feedback cycles short, e.g. using social media data to model individual and collective viewpoints, preferences, sentiments, networks, attention to events, and responses to shocks.
Future research could distill this in more detail.
1.2 Agent-based models
Two types of models, and how AI comes in
- Solve games fast and smart. For example, the problem of how to optimally allocate limited security resources to protect infrastructure targets of varying importance can be modeled as a Bayesian Stackelberg game. Since 2007, ARMOR has provided an optimal hour-by-hour randomized patrolling schedule for the Los Angeles World Airport police forces, building upon an efficient algorithm for solving such a game fast.[8] Pluribus is an algorithm that beats professional human players in a six-player, no-limit Texas Hold’em poker game in 2019. Using RL, it learns to look ahead for a few moves instead of to the end of the game.
- Automated mechanism design. This research program, instead of taking rules as given and analyzing outcomes, computes the optimal incentive-compatible rules for voting protocols, auctions, resource allocations in a given multi-agent setting.[9] For example, using a two-level deep reinforcement learning framework, the AI Economist simulates the productivity-equality trade-off under differing tax schedules and finds a tax policy that improves the trade-off by 16% compared to a prominent optimal tax policy theory.[10]
Development trajectory. My guess is that in the next 5 to 10 years, applications of game theory or other multi-agent systems might be restricted to narrow settings where the structure of local strategic interaction is relatively stable.
- Slow and limited real-world applicability. To be more applicable, adversarial models may need to address adversaries' bounded rationality for exploitation, players' uncertainty about each other's preference or each other's surveillance capability, coordinated attack or defense, all requiring slow, detailed study of specific real-world problems by human researchers.
- Scalability. This may remain another key challenge even with AI. Computational complexity grows exponentially with an increase in the number of players, their strategies, and their types.
[2] Augmented Human Forecasters
Two ways of augmentation
- Effectively aggregate forecasters’ probabilistic forecasts. One example is the ACE program under the IARPA, “the brain of the American intelligence community”. It is said to reduce errors by more than 50% than the previous methods for geopolitical events forecasts with a lead-time from 0.5 to 24 months. It has a Brier score around 0.15, on average giving a probability of 72% for binary events that happened (100%) and 28% for events that did not (0%).[11] Another example is Metaculus Prediction, an ML algorithm that calibrates and weights each forecaster’s prediction after training on forecaster-level predictions and track records. From 2015 to 2021, it outperformed the median forecast in the Metaculus community by 24% on binary questions and by 9% on continuous questions.
- Augment an individual forecaster’s prediction capability. AI can provide ML tools like time series models.[12] It can discover historical analogies given an event of interest.[13] It can suggest relevant information to read and catalog incoming information according to the individual knowledge base.[14] It can support qualitative reasoning by decomposing a prediction question into measurable subquestions, becoming “a thought partner” of an individual.[15] It leads to better causal theories, better interpersonal knowledge transfer, shorter discovery cycles for each prediction task.
Development trajectory. My guess is that its development may be modest in the next 5 years, with substantive potentials possibly realized in the next 5 to 20 years but not guaranteed.
- Lack of interest and incentive to change. Although the IARPA shows some interests, it’s unclear how keen such interests are to survive the valley of death.[16] In general, governments are not very enthusiastic about the existing forecasting tools like decision markets. Leaders use heuristics instead of rational, statistical information when making high-stake strategic decisions under uncertainty.[17] Intelligence analysts try to avoid subjective probabilities.[18]
- Human-machine interaction. Even with politicians’ and analysts’ interests and willingness to change, human adaptation to the hybrid systems takes time; tools and designs that facilitate human-machine interaction will be developed gradually. Beyond the next 20 years, progress in brain-machine interfaces might realize a possible design of human-swarm intelligence systems, in which semi-autonomous sub-swarms interacting locally with the information environment, for example computing from the Cloud, are integrated into the human’s low-level nervous systems.[19]
- Scalability. The SAGE platform which aggregates geopolitical forecasts of non-expert human participants provided with time series models only expects to handle 500 forecasting problems a year.[20]
[3] General-purpose AI Prediction Services
**AI forecasters? **
It might be possible to train an AI forecaster to represent raw data from the Internet like a human forecaster on CSET’s Foretell or Metaculus by training it on different prediction tasks.
- Some optimism:
- GPT-3 trained with a small sample of resolved binary forecasting questions on Metaculus seems to be able to discriminate between non-occurring events from occurring ones.
- RL agents using knowledge graphs can build effective, hierarchical representations of the environment in text-based games. They show the ability to perform common-sense reasoning with temporal and relational awareness.[21]
- Memory-augmented neural networks trained on a sequence of similar classification tasks show the ability of meta-learning: they seem to learn an abstract method for obtaining useful representation from the raw data and, when presented a new task, to leverage a small amount of new data to make an accurate prediction.
Embeddedness required?
However, it could be that general-purpose superhuman prediction capability requires open-ended learning in the real world or a simulated environment sufficiently resembling the real world. If so, AI prediction services would become agent-like. Like DeepMind’s Agent57 and MuZero, they might have intrinsic reward functions separate from the extrinsic reward provided by the environment to encourage exploration of the environment; they might also have meta-controllers adaptively adjusting the exploration/exploitation trade-off.
- Things to watch:
- The progress of human-machine interaction and the accumulation of feedback data;
- The capability of simulated environments resembling some narrow strategic settings of the real world;
- The rate at which relevant settings of "real-world" move into augmented and virtual realities.
Development trajectory. Hard to say. If a superhuman text-based AI forecaster is possible, and there is a consistent effort pushing towards it, then it might happen within the next 15 to 20 years.
Notes
Ajay K. Agrawal, Joshua S. Gans, and Avi Goldfarb, ‘Prediction, Judgment and Complexity: A Theory of Decision Making and Artificial Intelligence’ (National Bureau of Economic Research, 29 January 2018), https://doi.org/10.3386/w24243. ↩︎
Nuño Sempere proposes an alternative framework: [1] human forecasters; [2] transparent data analysis systems; [3] black-box ML systems (e.g. weather forecasting systems); [4] black-box ML systems which have direct effects on the world (e.g. automated trading systems, automated missile detection systems). I benefit from his suggestion and think that his framework is better for understanding the technical side of prediction technologies. But I choose to structure the discussion here using my framework because I find it helpful when thinking about my research question, the geopolitical implications of those technologies. ↩︎
Sathappan Muthiah et al., ‘EMBERS at 4 Years: Experiences Operating an Open Source Indicators Forecasting System’, ArXiv:1604.00033 [Cs], 31 March 2016, http://arxiv.org/abs/1604.00033. ↩︎
Tamay Besiroglu, ‘Are Models Getting Harder to Find?’ Master’s Thesis. University of Cambridge, 2020. ↩︎
Travis Martin et al., ‘Exploring Limits to Prediction in Complex Social Systems’, Proceedings of the 25th International Conference on World Wide Web, 11 April 2016, 683–94, https://doi.org/10.1145/2872427.2883001. ↩︎
Irena Pavela Banai, Benjamin Banai, and Kosta Bovan, ‘Vocal Characteristics of Presidential Candidates Can Predict the Outcome of Actual Elections’, Evolution and Human Behavior 38, no. 3 (May 2017): 309–14, https://doi.org/10.1016/j.evolhumbehav.2016.10.012. ↩︎
Milind Tambe, Security and Game Theory: Algorithms, Deployed Systems, Lessons Learned (Cambridge ; New York: Cambridge University Press, 2012). ↩︎
Vincent Conitzer and Tuomas Sandholm, ‘Self-Interested Automated Mechanism Design and Implications for Optimal Combinatorial Auctions’, in Proceedings of the 5th ACM Conference on Electronic Commerce - EC ’04 (the 5th ACM conference, New York, NY, USA: ACM Press, 2004), 132, https://doi.org/10.1145/988772.988793. ↩︎
Stephan Zheng et al., ‘The AI Economist: Improving Equality and Productivity with AI-Driven Tax Policies’, ArXiv:2004.13332 [Cs, Econ, q-Fin, Stat], 28 April 2020, http://arxiv.org/abs/2004.13332. ↩︎
See slide 19 of “HFC Proposers’ Day. ↩︎
Fred Morstatter et al., ‘SAGE: A Hybrid Geopolitical Event Forecasting System’, in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence (Twenty-Eighth International Joint Conference on Artificial Intelligence {IJCAI-19}, Macao, China: International Joint Conferences on Artificial Intelligence Organization, 2019), 6557–59, https://doi.org/10.24963/ijcai.2019/955. ↩︎
Yue Ning et al., ‘Spatio-Temporal Event Forecasting and Precursor Identification’, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’19: The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Anchorage AK USA: ACM, 2019), 3237–38, [https://doi.org/10.1145/3292500.3332291] ↩︎
I owe this point to Nuño Sempere. ↩︎
See, for example, Keren Yarhi-Milo, Knowing the Adversary: Leaders, Intelligence, and Assessment of Intentions in International Relations (Princeton University Press, 2014), https://press.princeton.edu/books/hardcover/9780691159157/knowing-the-adversary. ↩︎
Jeffrey A. Friedman, War and Chance: Assessing Uncertainty in International Politics (Oxford University Press, 2019). ↩︎
My wild conjecture inspired by Jonas D Hasbach and Maren Bennewitz, ‘The Design of Self-Organizing Human–Swarm Intelligence’, Adaptive Behavior, 3 July 2021, 10597123211017550, https://doi.org/10.1177/10597123211017550. ↩︎
Fred Morstatter et al., ‘SAGE: A Hybrid Geopolitical Event Forecasting System’. ↩︎
Yunqiu Xu et al., ‘Deep Reinforcement Learning with Stacked Hierarchical Attention for Text-Based Games’, n.d., 13. ↩︎
2 comments
Comments sorted by top scores.
comment by SimonM · 2021-10-04T10:31:08.512Z · LW(p) · GW(p)
tl;dr - I don't believe the Metaculus prediction is materially better than the community median.
Another example is Metaculus Prediction, an ML algorithm that calibrates and weights each forecaster’s prediction after training on forecaster-level predictions and track records. From 2015 to 2021, it outperformed the median forecast in the Metaculus community by 24% on binary questions and by 9% on continuous questions.
This is at best a misleading way of describing the performance of the Metaculus prediction vs the community (median) prediction.
We can slice the data in any number of ways, and I can't find any way to suggest the Metaculus prediction outperformed the median prediction by 24%.
Looking at (for all time):
| Brier | Resolve | Close | All Times |
| Community median | 0.121 | 0.123 | 0.153 |
| Metaculus | 0.116 | 0.116 | 0.146 |
| Difference | 4.3% | 6.0% | 4.8% |
| Log | Resolve | Close | All |
| Community median | 0.42 | 0.412 | 0.274 |
| Metaculus | 0.431 | 0.431 | 0.295 |
| Difference | 2.6% | 4.6% | 7.7% |
None of these are close to 24%. I also think that given the Metaculus algorithm only came into existence in June 2017, we should really only look at performance more recently. For example, the same table looking at everything from July 2018 onwards looks like:
| Brier | Resolve | Close | All Times |
| Community median | 0.107 | 0.105 | 0.147 |
| Metaculus | 0.108 | 0.113 | 0.156 |
| Difference | -0.9% | -7.1% | -5.8% |
| Log | Resolve | Close | All |
| Community median | 0.462 | 0.463 | 0.26 |
| Metaculus | 0.448 | 0.426 | 0.226 |
| Difference | -3.0% | -8.0% | -13.1% |
Now the community median outperforms every time!
For continuous questions the Metaculus forecast has more consistently outperformed out-of-sample, but still smaller differences than what you've claimed:
| Continuous | Resolve | Close | All |
| Community | 2.26 | 2.22 | 1.69 |
| Metaculus | 2.32 | 2.32 | 1.74 |
| Difference | 2.7% | 4.5% | 3.0% |
| Continuous (July '18 -) | Resolve | Close | All |
| Community | 2.28 | 2.27 | 1.73 |
| Metaculus | 2.35 | 2.38 | 1.79 |
| Difference | 3.1% | 4.8% | 3.5% |
I would also note that %age difference here is almost certainly the wrong metric for measuring the difference between Brier scores.
Replies from: isaduan↑ comment by isaduan · 2021-10-09T17:53:56.195Z · LW(p) · GW(p)
Thanks for checking! I think our main difference is that you use data from Metaculus prediction whereas I used Metaculus postdiction, which "uses data from all other questions to calibrate its result, even questions that resolved later." Right now, this gives Metaculus an average log score of 0.519 vs. the community's 0.419 (total questions: 885) for binary questions, 2.43 vs. 2.25 for 537 continuous questions, evaluated at resolve time.