UML XII: Dimensionality Reduction
post by Rafael Harth (sil-ver) · 2020-02-23T19:44:23.956Z · LW · GW · 0 commentsContents
I II III IV V VI VII VIII IX X None No comments
(This is the twelfth post in a sequence on Machine Learning based on this book. Click here [? · GW] for part I.)
This post will be more on the mathy side (all of it linear algebra). It contains orthonormal matrices, eigenvalues and eigenvectors, and singular value decomposition.
I
Almost everything I've written about in this series thus far has been about what is called supervised learning, which just means "learning based on a fixed amount of training data." This even includes most of the theoretical work from chapters I-III, such as the PAC learning model. On the other side, there is also unsupervised learning, which is learning without any training data.
Dimensionality reduction is about taking data that is represented by vectors in some high-dimensional space and converting them to vectors in a lower-dimensional space, in a way that preserves meaningful properties of the data. One use case is to overcome computational hurdles in supervised learning – many algorithms have runtimes that increase exponentially with the dimension. In that case, we would essentially be doing the opposite of what we've covered in the second half of post VIII [LW · GW], which was about increasing the dimensionality of a data set to make it more expressive. However, dimensionality reduction can also be applied to unsupervised learning – or even to tasks that are outside of machine learning altogether. I once took a class on Information Visualization, and they covered the technique we're going to look at in this post (although "covered" did not include anyone understanding what happens on a mathematical level). It is very difficult to visualize high-dimensional data; a reasonable approach to deal with this problem is to map it into 2d space, or perhaps 3d space, and then see whether there are any interesting patterns.
The aforementioned technique is called principal component analysis. I like it for two reasons: one, linear algebra plays a crucial role in actually finding the solution (rather than just proving some convergence bound); and two, even though the formalization of our problem will look quite natural, the solution turns out to have highly elegant structure. It's an example of advanced concepts naturally falling out of studying a practical problem.
II
Here is the outline of how we'll proceed:
- Define the setting
- Specify a formal optimization problem that captures the objective "project the data into a lower-dimensional space while losing as little information as possible"
- Prove that the solution has important structure
- Prove that it has even more important structure
- Repeat steps #3 and #4
At that point, finding an algorithm that solves the problem will be trivial.
III
Let with and let be some data set, where for all . We don't assume the data has labels this time since we'll have no use for them. (As mentioned, dimensionality reduction isn't restricted to supervised learning.)
We now wish to find a linear map that will project our data points into the smaller space while somehow not losing much information and another linear map that will approximately recover it.
The requirement that be linear is a pretty natural one. The sets and are bijective, so if arbitrary functions are allowed, it is possible to define in such a way that no information is lost. However, if you've ever seen a bijection between and written out, you'll know that this is a complete non-starter (such functions do not preserve any intuitive notion of structure).
Another way to motivate the requirement is by noting how much is gained by prescribing linearity. The space of all functions between two sets is unfathomably vast, and linearity is a strong and well-understood property. If we assume a linear map, we can make much faster progress.
IV
Since we are assuming linearity, we can represent our linear maps as matrices. Thus, we are looking for a pair , where is an matrix and a matrix.
The requirement that the mapping loses as little information as possible can be measured by how well we can recover the original data. Thus, we assume our data points are first mapped to according to , then mapped back to according to , and we measure how much the points have changed. (Of course, also we square every distance because mathematicians love to square distances.) This leads to the objective
.
We say that the pair is a solution to our problem iff it is in the argmin above.
V
Before we go about establishing the first structural property of our solution, let's talk about matrices and matrix multiplication.
There are (at least) two different views one can take on matrices and matrix multiplication. The common one is what I hereby call the computational view because it emphasizes how matrix-vector and matrix-matrix multiplication is realized – namely, like this:
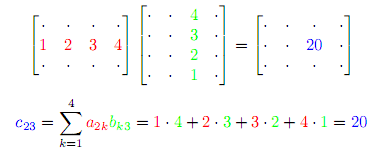
In this view, matrices and linear maps are sort of the same thing, at least in the sense that both can be applied to vectors.
Since reading Linear Algebra Done Right [LW · GW], I've become increasingly convinced that emphasizing the computational view is a bad idea. The alternative perspective is what I hereby call the formal view because it is closer to the formal definition. Under this view, a matrix is a rectangular grid of numbers:
This grid (along with the bases of the domain space and target space) contains all the information about how a function works, but it is not itself a function. The crucial part here is that the first column of the matrix tells us how to write the first basis vector of the domain space as a linear combination of the target space, i.e., if the two bases are and . As far as this post is concerned, we only have two spaces, and , and they both have their respective standard basis. Thus, if we assume and for the sake of an example, then the matrix
tells us that the vector is mapped onto and the vector onto . And that is all; this defines the linear map which corresponds to the matrix.
Another consequence of this view is that I exclusively draw matrices that have rectangular brackets rather than round brackets. But I'm not devoted to the formal view – we won't exclusively use it; instead, we will use whichever one is more useful for any given problem. And I won't actually go through the trouble of cleanly differentiating matrices and maps; we'll usually pretend that matrices can send vectors to places themselves.
With that out of the way, the first thing we will prove about our solution is that it takes the form , where is a pseudo-orthonormal matrix. ("It takes the form" means "there is a pair in the argmin of our minimization problem that has this form.") A square matrix is orthonormal if its columns (or equivalently, its rows) are orthonormal to each other (if read as vectors). I.e., they all have inner product 0 with each other and have norm 1. However, there is also a variant of this property that can apply to a non-square matrix, and there is no standard terminology for such a matrix, so I call it pseudo-orthonormal. In our case, the matrix will do this thing:
I.e., it will go from a small space to a larger space. Thus, it looks like this:
Or alternatively, this:
where we write the entries as column vectors, i.e., .
For a proper orthonormal matrix, both the column vectors and the row vectors are orthonormal. For a pseudo-orthonormal matrix, just the (i.e., the column vectors) are orthonormal. The row vectors can't be (unless many of them are zero vectors) because they're linearly dependent; there are many, and they live in -dimensional space.
For a square matrix, the requirement that it be orthogonal is equivalent to the equations and , or simply . A pseudo-orthonormal matrix isn't square and doesn't have an inverse, but the first of the two equations still holds (and is equivalent to the requirement that the matrix be pseudo-orthonormal). To see why, consider the matrix product in the computational view. Instead of flipping the first matrix, you can just imagine both side by side; but go vertical in both directions, i.e.:
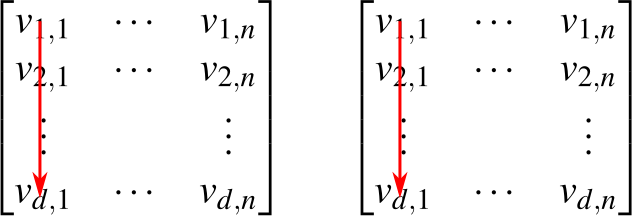
This shows that , and this is iff and 0 otherwise because the are orthonormal. Thus, .
Now recall that we wish to construct a pseudo-orthonormal matrix and prove that there exists a solution with , i.e., a solution of the form .
To construct note that is mapped to the first column vector of any matrix (formal view), and analogously for every other basis vector. It follows that the image of a matrix is just the span of the column vectors. Thus, is an -dimensional subspace of , and we can choose an orthonormal basis of that subspace. Then we define as in the example above (only now the are the specific vectors from this orthonormal basis). Note that is indeed a matrix. Clearly, both and have the same image (formal view).
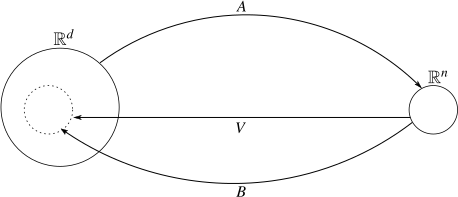
We will also have use for (quite a lot, in fact). Let's add it into the picture:
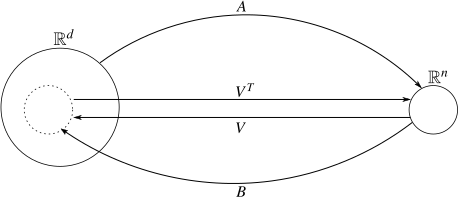
(Note that, even though the arrow for starts from the small circle, it can take vectors from all of .)
We've established that is the identity matrix, but isn't. This can also be seen from this picture: is a map from to , but it maps all vectors into a subspace of . Therefore, all vectors outside of the subspace have to be changed. But what about the vectors who are in the subspace? Could it be that it leaves those unchanged? The answer is affirmative; here's the proof:
Let . Then such that , and therefore, .
This fact is going to be important in just a second. Recall that we were here:
and we wanted to prove that there's a solution of the form . Here's the proof:
Let be a solution. Then is our optimal back-and-forth mapping. However, , and, therefore, the pair is also an optimal back-and-forth mapping and thus is a solution.
Note that holds only because the matrix sends all vectors into the subspace which is the same as , and therefore doesn't do anything.
VI
Next, we prove that there is a solution of the form . We will do this by constructing a term that describes the distance we're trying to minimize and comparing its gradient to zero. Thus, we assume and and want to figure out how to choose such that the term is minimal. Using that and that , we have:
The gradient of this term with respect to is . Setting it to 0 yields . Thus, for each point , the vector in that will make the distance smallest has the form . In particular, this is true for all of our training points . Since we have shown that there exists a solution of the form , this implies that is such a solution.
VII
Before we prove that our solution has even more structure, let's reflect on what it means that it has the form with orthonormal. Most importantly, it means that the vectors we obtain are all orthogonal to each other (formal view). We call those vectors the principal components of our data set, which give the technique its name. You can think of them as indicating the directions that are most meaningful to capture what is going on in our data set. The more principal components we look at (i.e., the larger of an we choose), the more information we will preserve. Nonetheless, if a few directions already capture most of the variance in the data, then might be meaningful even though is small.
For more on this perspective, I recommend this video (on at least 1.5 speed).
VIII
Based on what we have established, we can write our optimization problem as
Looking at just one of our , we can rewrite the distance term like so:
then, since does not depend on , we can further rewrite our problem as
Now we perform a magic trick. The term may just be considered a number, but it can also be considered a matrix. In that case, it is equal to its trace. (The trace of a square matrix is the sum of its diagonal entries). The trace has the property that one can "rotate" the matrix product it is applied to, so
(This follows from the fact that , which is easy to prove.) It also has the property that, if is square (but and are not), ; this will be important later. If we apply rotation to our case, we get
and, since the trace is linear,
The key component here is the matrix . Note that does not depend on . However, we will finish deriving our technique by showing that the columns of are precisely the eigenvectors of corresponding to its largest eigenvalues.
IX
Many matrices have something called a singular-value decomposition – this is a decomposition such that consists of the eigenvectors of (column vectors) and is diagonal, i.e.:
The matrix can be considered to represent the same function as but with regard to a different basis, namely the basis of the eigenvectors of . Thus, the singular value decomposition exists iff there exists a basis that only consists of eigenvectors of .
It is possible to check that the matrix which realizes this decomposition is, in fact, the matrix with the eigenvectors of as column vectors. Consider the first eigenpair of . We have . On the other hand, sends the vector to (formal view), and therefore, sends to . Then sends to because it's a diagonal matrix, and sends to which is (formal view). In summary,
This shows that does the right things on the vectors , which is already a proper proof that the decomposition works since is, by assumption, a basis of .
In our case, is symmetric; this implies that there exists a decomposition such that is orthonormal. (We won't show this.) Note that, unlike , the matrix is a square matrix, hence and the decomposition can be written as .
Recall that the term we want to maximize is . We can rewrite this as . The matrix is a matrix, so not square, but it is pseudo-orthonormal since . Using the previously mentioned additional rules of the trace (which allow us to take the transpose of both and ), we can write
Multiplying any matrix with a diagonal from the left multiplies every entry in row with , and in particular, multiplies the diagonal element with . Therefore, the above equals . Now recall that is pseudo-orthonormal and looks like this:
The column vectors are properly orthonormal; they all have norm 1. The row vectors are not orthonormal, but if the matrix were extended to a proper matrix, they would become orthonormal vectors. Thus, their norm is at most 1. However, the sum of all squared norms of row vectors equals the sum of all squared norms of column vectors (both are just the sum of every matrix entry squared), which is just . It follows that each is at most , and the sum, namely , is at most . Now consider the term whose maximum we wish to compute:
Given the above constraints, the way to make it largest is to weigh the largest with 1, and the rest with 0. It's not obvious that this can be achieved, but it is clear that it cannot get larger. Thus, , where is reordered such that the largest eigenvalues, which we call , come first.
Now recall that we have previously written our term as or equivalently . If we choose where are the eigenvectors of corresponding to , we get and . The -th entry on the diagonal of this matrix is . Since we have established that this is an upper-bound, that makes this choice for a solution to our original problem, namely .
X
As promised, the algorithm is now trivial – it fits into three lines:
Given , compute the matrix , then compute the eigenvalues of , with eigenvectors . Take the eigenvectors with the largest eigenvalues and put them into a matrix . Output .
0 comments
Comments sorted by top scores.