A framework and open questions for game theoretic shard modeling
post by Garrett Baker (D0TheMath) · 2022-10-21T21:40:49.887Z · LW · GW · 4 commentsContents
Background Shards and contexts Environment and Reward Actions Speculation on the future of the framework None 4 comments
Background
The Shard Theory of Human Values [? · GW] is a new research agenda which I think has promise in serving as a model of value formation in humans and self-supervised ML agents. In brief, it claims that humans are made up of possibly self-preserving contextually-activated-heuristics called shards, that the sum of these is what we mean when we say 'human values', and that self-supervised ML agents will have this same format.
But there's a dreadful problem... there's currently no way of attaching numbers to its concepts! So it's difficult to prove any given shard-theoretic explanation wrong. Here I present my brief thoughts on the subject, and try to give an informal overview of a framework I think will have promise for these purposes, as well as some questions I think are likely solvable via experiment or further theoretical thinking around these lines.
Shards and contexts
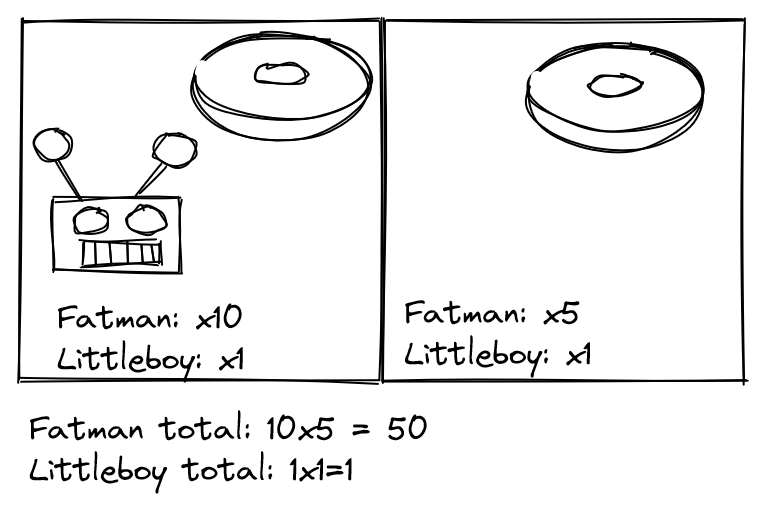
Suppose we have two shards: Fatman and Littleboy. Fatman likes doughnuts, and will spend its bids on actions which in expectation will achieve that end. Littleboy likes being thin, and will spend its bids on actions which in expectation will achieve that end.
Fatman has more bidding power when the agent is in a room which it models includes a doughnut in it , and less when the agent is in a room adjacent from one which it models includes a doughnut in it , and still less when the agent doesn't model a doughnut in any rooms .
Littleboy has more bidding power when there are mirrors in the room its currently in , and if there's nothing remarkable about the room it finds itself in, it has a bit more bidding power than Fatman .
This can be thought of as each shard having portfolios over contexts in which its activated.
| Context | Fatman | Littleboy |
| Doughnut | 10 | 1 |
| Doughnut adjacent | 5 | 1 |
| Mirror | 1 | 10 |
| Unremarkable room | 1 | 1 |
There are two ways we could aggregate the contexts. One way is to just add them up. If there's a doughnut in the room, and a doughnut in an adjacent room, because there's a doughnut in the room, Fatman gets 10 bids, then the adjacent doughnut gives Fatman 5 more bids, for a total of 15 bids.

Another way is to multiply together bids. In this case, this would give Fatman bids.
It's also unclear if there should be a form of context-starvation between highly related contexts. If there's two doughnuts in a room, does this mean we count twice, or is there some way of discounting consecutive instances of doughnuts such that the effect of adding a marginal doughnut is decreasing in the increase in bids this gives to Fatman? Probably the latter is true, but I don't know the correct way of calculating this, and it seems easier to work at this subproblem using experimentation first, but any results here should be derivable via a first-principles theory.
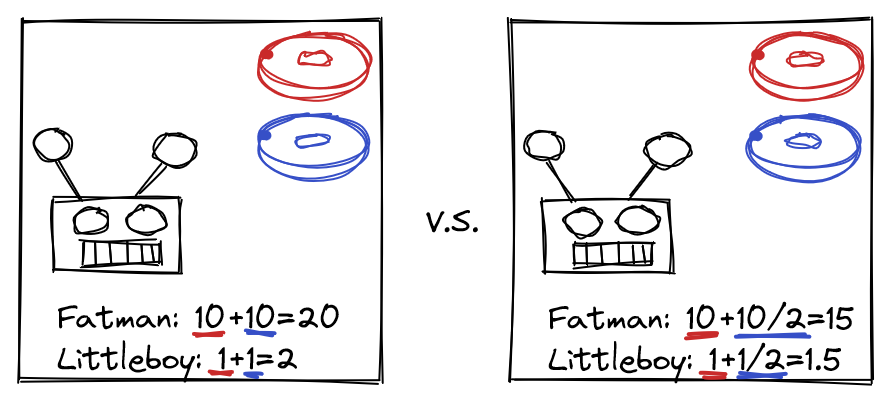
Similarly, if there's currently a doughnut in the present room, and someone adds a doughnut in an adjacent room, does this still add (or multiply) 5 to Fatman's base, or does it add (or multiply) less than 5, since having a doughnut in an adjacent room doesn't give particularly more information about which computations create the highest reward.
Shards perhaps have access to the plans the other shards are making, and perhaps even some commitment devices. This again should be determined via experiment. Certainly this is the case in humans, but for real-world RL agents, they may not be advanced enough to have commitment devices.
Environment and Reward
We also need to create a training environment, and a reward function over sequences of states. I don't know immensely about reinforcement learning, so I may be wrong in how I imagine the function taking the reward function to weight-gradients. I'll work from assuming we have a recurrent network and this function-from-reward-to-gradients is just basic gradient descent on the partial derivatives of the reward with respect to each parameter. Though I think much of the details here can be abstracted over for modelling purposes, as just updates in what bidding power is associated with which context for each shard, and possibly the context-aggregation function.
In this case, the training environment can just be a gridworld, where each grid square is randomly initialized with nothing <logical-or> a doughnut <logical-or> a mirror in it.
A reward function which seems sane for the purposes of very roughly modelling humans would maybe be something like +1 right now for eating a doughnut, -10 several time steps later on for eating a doughnut or something, (such that it makes more sense to eat 0 doughnuts) and then 0 if you eat a doughnut time-steps after seeing yourself in the mirror. Maybe also +0.5 for avoiding a room with a doughnut in it when the option presents itself, so we get a cleaner gradient for a Littleboy-like shard, and to mimic the short-term feel-good parts of a human holding to asceticism.
This is definitely not a function independent of the experiment you may be running. Better would be for someone (possibly me) to come up with a function which will with very high probability induce a pre-selected portfolio of shards and contexts between them, so that the context-aggregation function and the evolution of the bidding powers can be studied.
Actions
Agents can go left, right, up, or down, or eat a doughnut if a doughnut is currently in the room they're in.
Speculation on the future of the framework
If this framework proves fruitful in modelling RL agents, the next step would be to use it to actually locate the shards in our models. This may be achieved through a variety of means. The primary connection I see at this vantage between the base RL model and the high-level shard model is the connection between contexts and inputs, so perhaps we could start by finding rewards which change the shard context portfolio, and see what weight-level changes this makes in our model.
An alternative connection could be made by looking at which locations in our activation layers are highest for each context our model may find itself in, in order to locate the shards. Naiveley, they should be more active when in their highest-bidding-power context. From this, we may try to predict the actions of our model, and how that maps to the modeled actions of our shards.
4 comments
Comments sorted by top scores.
comment by Zach Stein-Perlman · 2022-10-21T21:59:50.706Z · LW(p) · GW(p)
I... don't get what this post accomplishes. How can we test shard theory in reality? What does shard theory predict in reality? What kinds of facts about RL agents are predicted by shard theory?
Misc: [resolved]
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-10-21T22:35:49.854Z · LW(p) · GW(p)
Hm. I don't think I was entirely clear about what tests I was thinking of. Suppose we have some real world RL agent trying to solve a maze to find cheese, and we'd like to model it as a shard-theoretic agent.
We propose a number of shards this agent could have based on previous experience with the agent, and what their contexts should be. In this case, perhaps, we have a go-towards-cheese shard, and a move-to-upper-right-corner shard and a distance-from-cheese context or possibly a time-since-start context.
An example of results which would disprove this instance of the theory is if we find there is no consistent function from contexts to shard-bids which accurately predicts our agent's behavior, or if the solutions we find don't actually compress our observations well. For instance, if they just list every situation our agent could be in, and append a number at the end corresponding to the move the agent makes.
We may also find problems when porting the models over to their weight-representations.
Thanks for the spelling corrections, those have been fixed. Grammatical errors have remained.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2022-10-21T22:49:07.027Z · LW(p) · GW(p)
OK, and a thing-that-prevents-you-from-saying-"ah yes, that happened because a shard bid on it"-about-any-arbitrary-behavior is that shards are supposed to be reasonably farsighted/standard expected-utility-maximizers?
Replies from: D0TheMath↑ comment by Garrett Baker (D0TheMath) · 2022-10-21T22:54:06.459Z · LW(p) · GW(p)
Basically, yes.