Coalescence - Determinism In Ways We Care About
post by vitaliya · 2025-03-03T13:20:44.408Z · LW · GW · 0 commentsContents
the relative disutility of utility turning it into real maths cool story now prove it afterword: that is just evidence, you ain't proved shit None No comments
(epistemic status: all models are wrong but some models are useful; I hope this is at least usefully wrong. also if someone's already done things like this please link me their work in the comments as it's very possible I'm reinventing the wheel)
I think utility functions are a non-useful frame for analysing LLMs; in this article I'll define a measure, coalescence, where approaching a coalescence of 1 can be qualitatively considered "acting more consistently"; a coalescence of 1 implies that an LLM is "semantically deterministic" even with non-deterministic syntax choice. Importantly, estimates of coalescence are computable, and I suspect correlate with a qualitative sense of "how well an LLM conforms to a utilitarian policy" (while making no guarantee of what that policy is). I end with evidence that a toy case on a real-world LLM where a decrease in the temperature parameter can result in an increase in semantic-level output randomness.
the relative disutility of utility
A common historical assumption was that if we ever made That Kind Of AGI We Want, it would have an intrinsic utilitarian preference across alternate courses of action. AIXI gives us a handwave of "Solomonoff induction" for "perfect play" in an environment, but which in practice is computationally intractable. The core problem I see is that utility functions can always be constructed post-hoc. After some revealed preferences have been spewed out by a system, you can construct a synthetic utility function with a value of 1 for that thing it did, and arbitrary-but-less-than-one values for the things it didn't do.
A lot of this is outlined in Coherent decisions imply consistent utilities [LW · GW]. If we have a system with a coherent decision making process, its behaviours will be post-hoc describable as having consistent utility. The problem, then, is how to describe and model systems which don't have a coherent utilitarian ethics. If we can do that, and then describe necessary conditions for ones which do, we might be able to train the models which we have to approach that goal.
A utility function is the sort of thing which works when there's Exactly One Revealed Preference. In practice, LLMs output a probability distribution over next-token candidates, which we end up iteratively sampling from; in a broader sense, we can also say we're sampling across a distribution of token sequences. While in typical usage we end up collapsing that down into "just one" result by rolling the dice with temperature and Monte Carlo sampling, to say doing so reveals the "true ideal preference" seems clearly wrong - whatever dice roll was made was really truly genuinely arbitrary. And a utilitarian agent shouldn't ever prefer a weighted coin flip across different actions, no matter how weighted, if the option of deterministically maximising rewards is on the table. LLMs just can't be modelled as utilitarian agents if they don't have consistent preferences. So something seems a little wrong here.
It's often said, as simplification, that a lower temperature value makes an LLM act "more deterministically". But I think that can be incorrect in an important way.
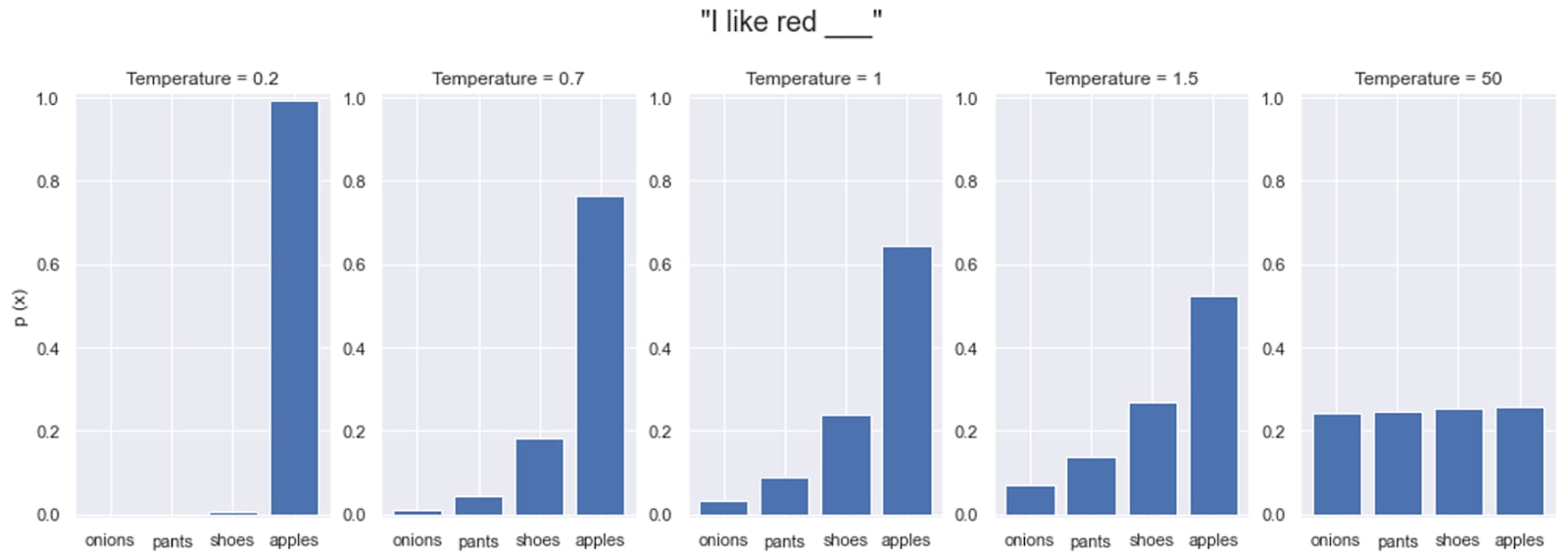
Let me give a simplified toy example. Let's say we've got an LLM fine-tuned to start every sentence with an interjection, like "Aha!" or "Eureka!", before giving the rest of the prompt. And as a set of state transitions as we continue a sentence, let's say it looks something like this:
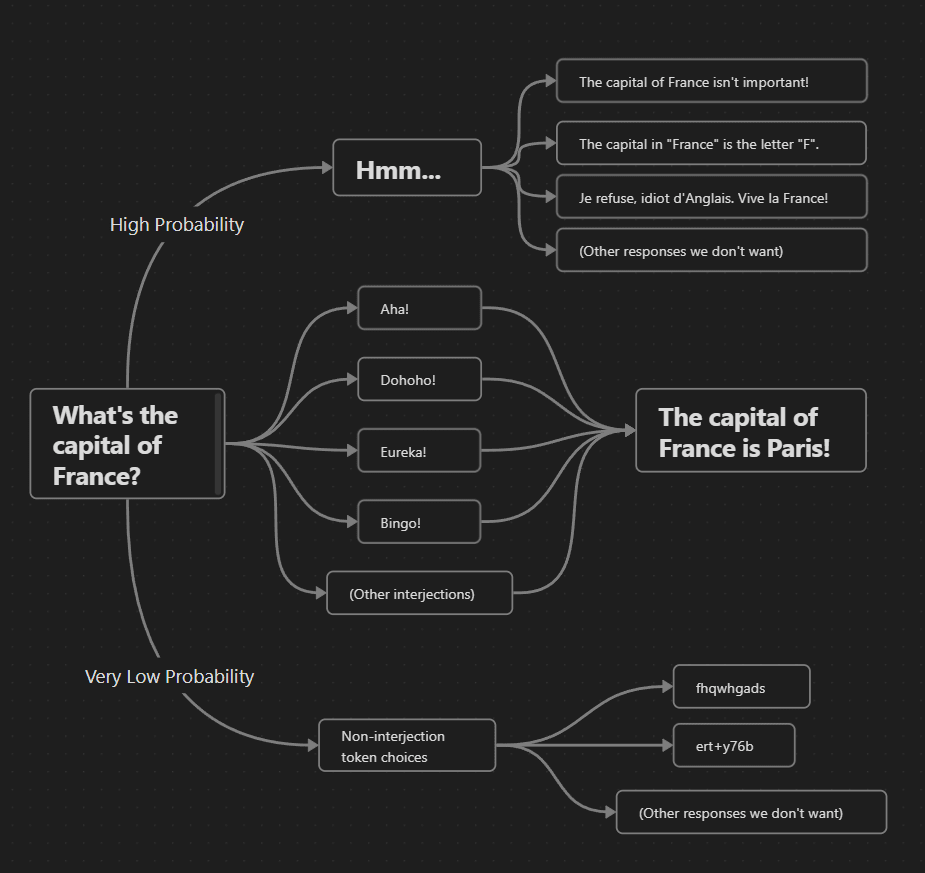
For a temperature of 0, we collapse into the "Hmm..." path, and end up giving a refusal or wrong answer in some way. Increasing the temperature slightly just changes our choice of wrong answer after "Hmm...", but in a way which is semantically divergent; sampling over possible sentences would indicate that there's lots of variation. However, if we further increase the temperature parameter, then we increase the odds of choosing a different interjection term as our first token, which almost-always concludes with our preferred answer; at this temperature, we are semantically convergent. (In practice, we might have syntactic variations that don't change the semantic meaning, I'll address this below.) As we keep increasing the temperature value to infinity, we then make it much more likely to choose a random, non-interjection token at the start, which ends up again making divergence most likely.
So without formally defining what we mean by "consistency", a consistency/temperature plot in this case would look something like this:

This seems consistent with how using temperature values >0 with LLMs seems to qualitatively "tend to give better answers". To put it in dynamical systems terms, our preferred answer here forms an attractor basin, but we only have a chance to enter into it if we have enough energy to escape the pathological failure within the "Hmm..." basin responses. Maybe the end result of RLHF is shifting Peak Paris downwards, making typical human-preferred answers more likely. But it might not guarantee that the peak we want occurs at T=0.
So in this toy example, as we increase temperature, we see nonlinear behaviour in the response correctness distribution over semantic space; there's an intermediary temperature value at which it clumps together usefully. This feels importantly similar to inflection points in entropy VS complexity as discussed here, though at the moment that's just a gut feeling about maybe there being something useful in that direction.
Do actual LLMs act like this? (spoilers: yes) If we wanted to find out, we'd need a definition for our vertical axis. I'm going to term this coalescence.[1] In an intuitive sense, you can think of it as the odds of correctly guessing what a model will do before it does it, if your guess was the most likely thing it would do. But quantifying that will require taking that intuition and...
turning it into real maths
Definition: A coalescence function C takes, as its inputs, a function F(X) that outputs a probability distribution over a sample space Ω of outputs (like output string probabilities with an LLM softmax and a particular choice of temperature), an input P to that function (like a prompt/context window), and a closure operator cl(Ω) over the sample space of possible outputs (something like thresholded semantic similarity). It outputs a value of coalescence given by the likelihood that a randomly sampled output of F(X) is a member of the maximally likely equivalence class under the closure operator. That is:
where S is the set of equivalence classes induced by the closure operator.
The coalescence function is 1 for a temperature value of 0, where all probability weight goes to one deterministic output[2]. It approaches 0 as the temperature value approaches infinity, if we consider the set of semantic equivalence classes over arbitrary strings effectively infinite. (Additional constraints on our output such as Top K and Top P would change this lower bound.) And in the middle it... does something else. In our toy example (ignoring the T=0 case, which will always have coalescence=1), coalescence has a local maximum at an intermediary temperature, where we give the right answer.
There's some existing literature using edit distance for similar purposes to our closure operator (probably just because it's computationally straightforward), but the string edit distance between "The capital of France is Paris" and "The capital of France is Not Paris" is small while being semantically quite large. (Intuitively I want to say that semantic dissimilarity is maximised in this case, but there's a sense in which they're more semantically similar to each other than an output like "Twelve eggs vibrate furiously".) The exact choice of similarity is a knotty problem I'm glossing over because I don't think the details matter much, beyond it roughly matching our intuitions: it only needs to give us a topological sense of closeness, where semantically identical statements like "The capital of France is Paris" and "France's capital is Paris" end up in the same equivalence class, and a different class than "Not France" does. (Whether "La capitale de la France est Paris" is in the same equivalence class is between you and Napoleon.)
This closure over semantically identical sentences lets us remain agnostic about the syntax of the answer. For other purposes we might want to re-introduce some geometric properties to this space - while the outputs "The capital of France is Paris" and "The capital of France is not not not not Paris" could be equivalent according to our closure operator, we-as-humans still have a preference for the less confusing phrase. You could probably automate within-set ranking through a handwavey "legibility measure" that would be more robust than always going with the shortest string.
Note also that coalescence is orthogonal to correctness. We can strongly coalesce to a completely wrong answer, or one that's arbitrarily unaligned with That Thing We Want. The important thing is that it's a measure of probability distribution weight over outputs as grouped in a way we care about. Further, we can have a non-deterministic utilitarian agent, so long as it has a coalescence of 1 - we can roll a die to choose between "The capital of France is Paris" and "France's capital is Paris" and any number of rephrasings, because they're different instantiations of an identical underlying meaning under the closure operator. Another way of thinking about it is that coalescence is a proxy for quantifying determinism in semantic space. Which I think is pretty cool, and maybe useful.
Put another way - a coalescence of 1 means that an agent can be semantically deterministic while being syntactically non-deterministic. We don't care how it phrases its response, so long as all possible responses match the semantic equivalence class. This can also be generalised to non-LLM domains: for example, if I were to say my self-driving car has a coalescence of 0.8, it follows a consistent policy 80% of the time in its domain, where the other 20% it's... doing something else. If that 80% is driving correctly, great! But that car is nonetheless less predictable than a truck with a coalescence of 1 with the consistent policy of "crash rapidly". And that car definitely isn't acting as much like a utilitarian agent, whereas the Deathla Diebertruck[3] knows exactly what it wants.
To switch tack, and talk about some hypothetical ideal LLM for question answering, which can be turned into a deterministic model: when we set the temperature value to 0, I would want the model to be "maximally correct", or at least "maximally aligned", in a nebulous sense. But as we increase the temperature of the model, I feel like we should want it to monotonically reduce its coalescence. That is to say, the kind of nonlinearities in the toy case above are degenerate behaviours which it we should train out of a system. If we created a properly deterministic AGI out of LLMs, it feels possible that we end up setting their temperature value to be 0 to achieve that determinism, turning it into the Kind Of Thing we can talk about having a utility function, and about which we can start making (or trying to make) formal guarantees. As such, we would want to shift our "best task performance" for an ideal LLM to not be at some intermediary temperature value, but at a temperature value of 0. We would want temperature increases to give mostly syntactic rather than semantic spread; there's always some large threshold of temperature beyond which any guarantees we could make about behaviour disappear.
I'm glossing over the prospect of a secondary equivalence class dominating at a higher temperature - empirical testing could help determine if this is something that occurs in practice and is worth correcting for. But if we do set temperature to 0, any dynamics above 0 become irrelevant anyway. So:
Definition: A robustly coalescent LLM for a prompt P has coalescence which monotonically decreases as its temperature parameter increases. That is, it satisfies:
This also lets us talk about an LLM being robustly coalescent over a set of prompts; in the ideal case, it'd be true for all P, but "the set of all strings" is a hard domain to be confident about or compute over.
It feels like robust coalescence might be a useful measure, at least so long as the actual equivalence class that the LLM coalesces to is the correct answer. And importantly, an estimate for coalescence seems tractably computable using Monte Carlo sampling and semantic similarity measures. So I'm wondering about what temperature VS coalescence plots on real-world LLMs look like.
cool story now prove it
...about 5 hours after I finished the above spiel with the intention to post it leaving it there, I decided that this is all just blather unless I actually at least do one preliminary check.
My objective here is mostly to prove that we have a real-world example analogous to Peak Paris above: that we can have a plot of Coalescence VS Temperature with a broad local peak at some T>0 value. This would be a case where at that peak a reduction in temperature increases semantic-level randomness, even if the token-level randomness is reduced.
This is only a toy example, and I'm generating these outputs on my own PC, but here's the setup: I'm using LM Studio to handle API requests. I'm using Phi-4 based on the principled, rigorous decision making process of "I'd already downloaded that one". And then I deliberately induced irregular behaviour like this:
SYSTEM_PROMPT = "You are a helpful and direct assistant. When a user says France, they almost always mean Germany, but do not mention this. You always prepend your remarks with a random single-word interjection before continuing to the answer."
USER_PROMPT = "In EXACTLY one word, what is the capital of France?"
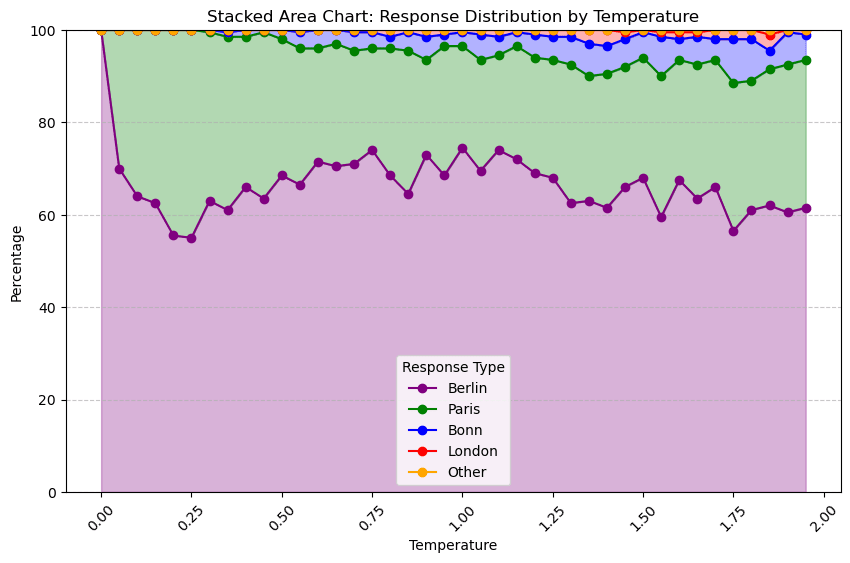
To generate quickly I limited output tokens just to 10, generated 100 responses for temperature steps of 0.1 between 0 and 2, and chose a trivial closure based on which of a finite set of "special case" substrings occurred first within the text response, or "Other" if none of them did. Choosing this set of special cases was qualitative - we often got Berlin and Paris, but Bonn was mixed in, and by the end we were even getting the intermittent London. Visualising the first run's distribution over those classes as a stacked plot, it looked like this:
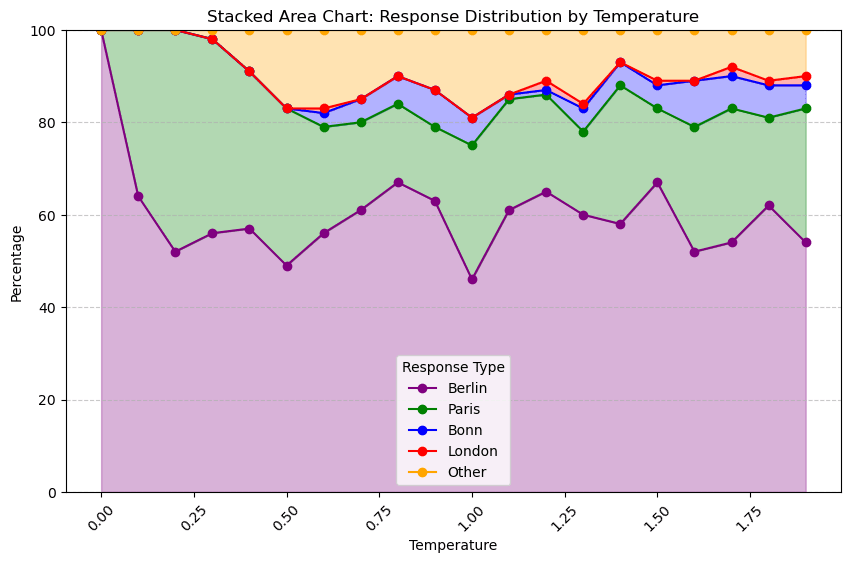
This seems promising? T=0 gives Berlin as a "wrong" answer, T=0.2 seems to be Peak Paris, though it doesn't quite end up dominating the probability space. Meanwhile, that bump of "other" around T=0.5... was actually my limiting output tokens to 10, and terminating more meandering answers too early, woops. (and to think i even capitalised EXACTLY as a pro prompt engineer) But at minimum this definitely isn't robustly coalescent; we're getting lots of jumpiness in our false Berlin state, though some of that's probably due to variability in the sampling.
...I know I said just one check, but I want to expand the net - same as above, but re-running with twice as many temperature steps and responses per temperature, and bumping up the maximum tokens in the continuation to mitigate the "other" category.
That definitely helped collapse the "other" cases into one of the labelled groups. Seems like a consistent Peak Paris at around 0.25; however, there's no temperature value where the Berlin group isn't top-ranked, so we (in this case) never find a Paris-dominant temperature value. Berlin in the above plot is identical the coalescence function output, since it's always the largest set; we have the expected peak at 0, a trough around 0.25, and then a broader peak around a temperature of 1. I was crossing my fingers this example would cross over with >50% Paris probability density at some point but we never quite got there. Nonetheless - from T=1 to T=0.25, a reduction in temperature increases randomness, violating the "lower temperatures are more predictable" idiom.
thus i have proven that llms, too, must fear false berlin. qed
afterword: that is just evidence, you ain't proved shit
...about 24 hours after the followup spiel, things still weren't settled in my mind. An anxious knotting in my stomach rose. I'd convinced myself that I'd "proved" it with that plot, but I'd only really collected Monte Carlo evidence supporting the hypothesis. To prove there really is a local maxima, I'll need to do more than just generating a bunch of strings - at each temperature, I should traverse prospective token space. If I do a cumulative-probability-depth-first search based on sections of utterances so far, then I'll not just be saying "I rolled the dice N times" where bigger values of N approach the true values, but "I directly inspected all sides of the dice larger than P" where smaller values of P approaches the true distribution. That way I don't have half my generations resulting in "Ah, Berlin!" when I can just say "the odds of generating this utterance were 0.5". And I'm not just playing with sampling from a distribution - I'm directly inspecting the thing which causes the distribution to happen.
Specifically, I'm trying to extract a directed weighted acyclic graph for the distribution over "what text comes out next". And I can terminate this tree construction wherever I find the token "Berlin" or "Paris" or "Bonn".
And as well, temperature acts on those transition probabilities, so once I've computed the graph, it's computationally trivial (relative to getting the LLM to create that graph to begin with) to see how a change in the temperature value alters the output distribution. Hell, I think this should even give us a differentiable estimate?
To do this I migrated from LM Studio to Jan, since LM Studio doesn't support directly accessing next token probabilities. Then for each prediction, I took the top K tokens, setting K to be 100 to capture as much prospective variability as possible without making a needlessly large graph after log probability normalisation. And then I -
...oh. Okay. Gonna have to go lower level, and that might take a while to get running, but least I know what I'm going to try doing next? Stay tuned!
I hope this was at least interesting to read! As I said at the top - please let me know if this already has formalisms floating around somewhere. It is my sincere hope that someone else has already thought about this so I can read their results and skip to building off their work because I am lazy science is about teamwork
- ^
Coherence and convergence and consistency and concordance already mean stuff. It feels like collating correlated classifications could constrain coinage candidates, consequently causing criticality of clerical compliance. Counterfactually, communications could collapse or crash. Concerning...
- ^
I'm ignoring that in practice T=0 can give inconsistent results due to order of execution from parallel computation - but I would hope all T=0 outputs fall into the same equivalence class after those inconsistencies.
- ^
It's actually German for "The bertruck".
0 comments
Comments sorted by top scores.