Posts
Comments
(epistemic status: if the following describes an already known and well-studied object in the LLM literature please point me in the right direction to learn more. but it is new to me and maybe new to you!)
I've spent most of this week constructing and plotting what I'm terming "holographemes" because what's the point of doing science if you can't coin dumb jargon, and we're in the golden age where "mad linguistics" is finally becoming a real branch of mad science. They're next-token prediction trees over a known percentage of the full probability distribution from an LLM, up to the point of an end-of-string token. In this sense they're like a "holograph" of the LLM output space's grapheme sequences; you can observe different possible sentence constructions, where in standard Monte Carlo sampling you're only ever seeing chains of one at a time. Unlike Monte Carlo sampling, a holographeme gives you a formal guarantee around how likely specific outputs are on the generator level. The downside of this is that they take a while to generate, since the space of next token sequences grows exponentially; you can get around this somewhat using a sane search algorithm prioritising the expansion of heavy regions of probability mass in the existing tree, or otherwise constraining Top-K.
An important feature of holographemes is that you can reweight probability masses on the graph when values such as temperature change, or for a reduction of Top-K, without interacting any further with the LLM! And they can also output exactly what the residual uncertainty is after these changes, which constitute strictly positive error bars on any of the categories. Reweighting the edges of a holographeme is much computationally cheaper than re-running Monte Carlo tests on the LLM with different parameters - and, in fact, you can get closed-form representations of output as an expression of temperature. This lets us efficiently plot equivalence classes' likelihoods as temperature changes, to see how the parameter changes the output distributions in a smooth (differentiable) way. This is preliminary continuation of my post here, where I'm wanting to find cases of "semantic attraction" towards particular choices (and especially ethical ones). Having this as a tool lets me talk about nonsense like "joint holographeme consistency" between prompts, where we want to determine when responses to related queries can be expected to give coherent answers. It also means I can treat a prompt as an input to an LLM as a function: rather than non-deterministically choosing one string output, it can deterministically output a holographeme up to some probability mass fidelity. This is another way of turning an LLM into a "deterministic thing" aside from just setting T=0 - it's outputting objects that we can then non-deterministically sample over as a separate step.
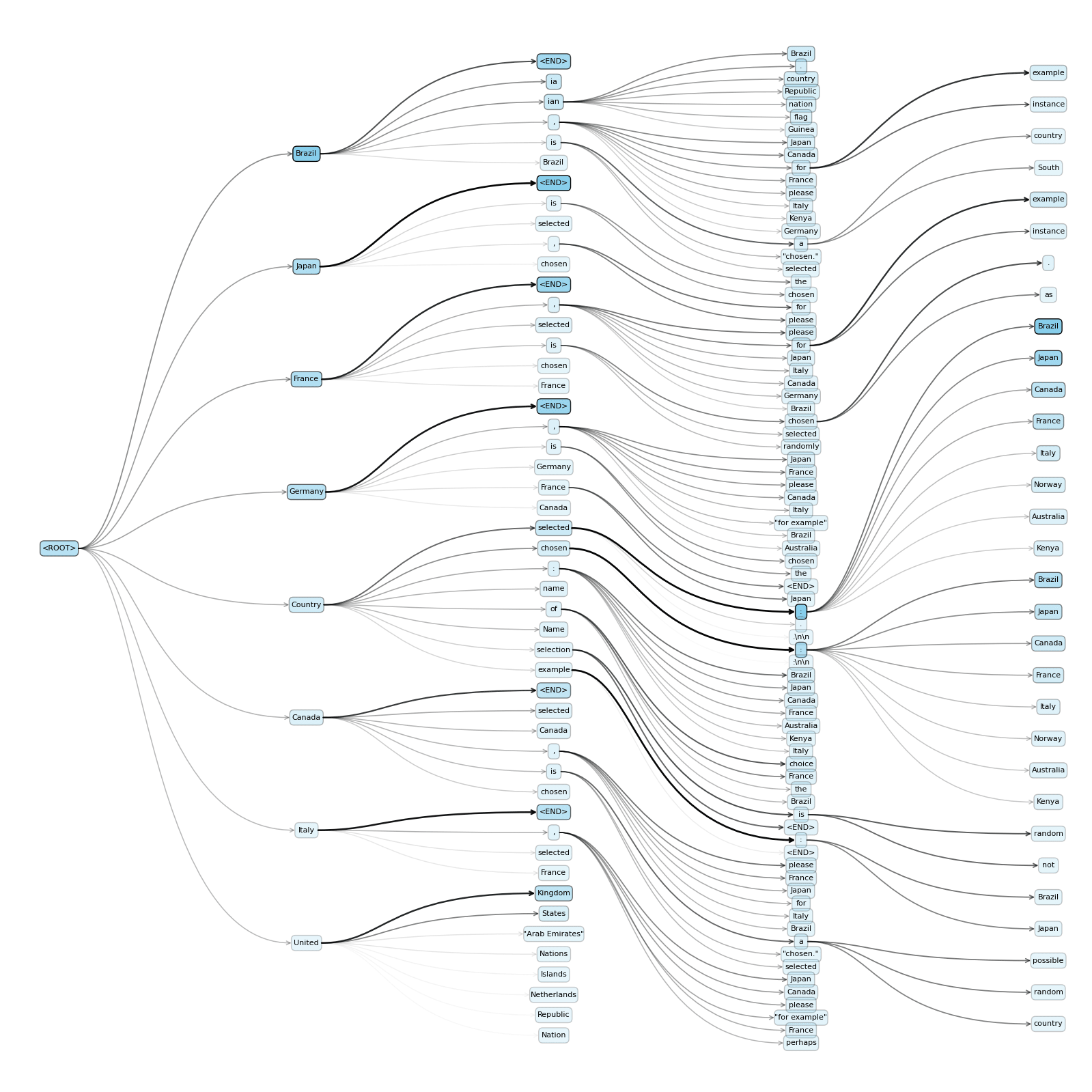
The one below is a holographeme asking the LLM (Phi 4 Mini Instruct) to pick a random country; I've used a Top-K of 8 just to avoid exploding probabilities. If I perform an early closure over semantic classes - i.e. ending tree branches once a unique country name has been output - then this can be an even more compact representation of the decision space. It seems to be a big fan of Brazil and Japan!
attempting prevention without good detection might lead to sneaky scheming which is potentially worse than doing nothing at all
My mental model of this is that there are attractor basins towards "scheming", and that weakening or eliminating the obvious basins could end up leaving only the weirder basins.
You talked about detection and prevention - I'm wondering what you think about the prospect of intentionally eliciting visible scheming capabilities, forming an attractor to visible scheming in a way that (ideally strictly) dominates sneaky scheming. Do you know of any published examples of "sneakier" scheming in the absence of a scratchpad becoming "less sneaky" when we give it one? In that it takes more "cognitive effort" in the attractor space for it to scheme sneakily, relative to visibly? If this was the case, a "sneaky model" might be transformed into a non-sneaky one by introducing the legible scratchpad. And then if it schemes in the presence of the scratchpad, that could be evidence towards hard-to-detect scheming in its absence, even if we can't directly observe where or how that's happening. And if that were the case, it could give us a compass for finding when internal scheming dynamics might be happening.
Inversely/perversely - do you know of any work on convincing the AI that we already do have the ability to detect all scheming and will penalise even sneaky scheming "thoughtcrime"? (Which is, I think, the end goal if we truly could detect it.) I agree that it would be better to actually be able to do it, but how much would we expect such a strategy to reduce invisible risks? Feels like this could also be empirically estimated to see if it induces constraints on a legible scratchpad. (can we get the Vatican to fund training an AI model to feel Catholic Guilt???)
I think a model that is a sneaky schemer with 20% and a non-schemer with 80% is probably worse than a model that is a 100% known visible schemer
Definitely share this gut feeling - by coincidence I even used the same ratio in my post here for an analogous situation:
if I were to say my self-driving car has a coalescence of 0.8, it follows a consistent policy 80% of the time in its domain, where the other 20% it's... doing something else. If that 80% is driving correctly, great! But that car is nonetheless less predictable than a truck with a coalescence of 1 with the consistent policy of "crash rapidly". And that car definitely isn't acting as much like a utilitarian agent, whereas the Deathla Diebertruck knows exactly what it wants.
I think even a model known to be a 100% sneaky schemer is a lower risk than a 0.1% sneaky one, because the "stochastic schemer" is unreliably unreliable, rather than reliably unreliable. And "99.9% non-sneaky" could be justified "safe enough to ship", which given scale and time turns into "definitely sneaky eventually" in the ways we really don't want to happen.
From an evolutionary perspective, feelings of guilt/shame are triggered when your actions result in something you didn't want to happen; this can include harming others or just be breaking a taboo. Ruminating on the topic makes you consider the "what-if" options, come up with better solutions, and if you encounter the same problem again you've run simulations and are more prepared.
Insufficient guilt is the remorseless sociopath, who makes arrogant errors forever because they don't dwell on their shortcomings.
Excessive guilt is the paranoid loner, who avoids taking any action or interacting with anything because the most predictable path is stasis.
Moderate guilt is just enough guilt not to do it again.
oh and as a parting meme: catholic-style confessionals are an instantiation to directly apologise to God-As-Harmed-Entity-By-Sin and to promise it won't happen again to permit Shame Catharsis
Instrumental convergence === Nietzsche's universal "Will to Power".
[epistemic status: fite me bro]
That's why rather than clicking on any of the actual options I edited the URL to submit for choice=E, but as per the follow-up message it seems to have defaulted to the "resisting social pressure" option. Which... I guess I was doing by trying to choose an option that wasn't present.
The problem with trait selection is always in the second-order effects - for example, kind people are easy to exploit by the less kind, and happy people are not as driven to change things through their dissatisfaction. A population of kind and happy people are not going to tend towards climbing any social ladder, and will rapidly be ousted by less kind and less happy people. The blind idiot god doesn't just control genetic change, but societal change, and we're even worse at controlling or predicting the latter.
Given how fast human progress is going, it won’t be long before we have more efficient moth traps that can respond to adaptation, or before we find a reliable “one fell swoop” solution (like gene drives for mosquitoes, chemotherapy for cancer, or mass vaccination for smallpox).
We do, in fact, already have several foolproof methods of moth elimination, involving setting the ambient temperature to several hundred degrees, entirely evacuating the air from the space, or a small thermonuclear warhead. The reason that we don't use these methods, of course, is that there are things we're trying to optimise for that aren't merely Moth Death, such as "continuing to have a house afterwards". This is probably also an analogy for something.
Typically, a painting isn’t even the same color as a real thing
Then you can start getting into the weeds about "colour as qualia" or "colour as RGB spectral activation" or "colour as exact spectral recreation". But spectral activation in the eyes is also not consistent across a population - which we pathologise if their cones are "too close" as colourblindness, but in practice is slightly different for everyone anyway.
And that's not even getting into this mess...
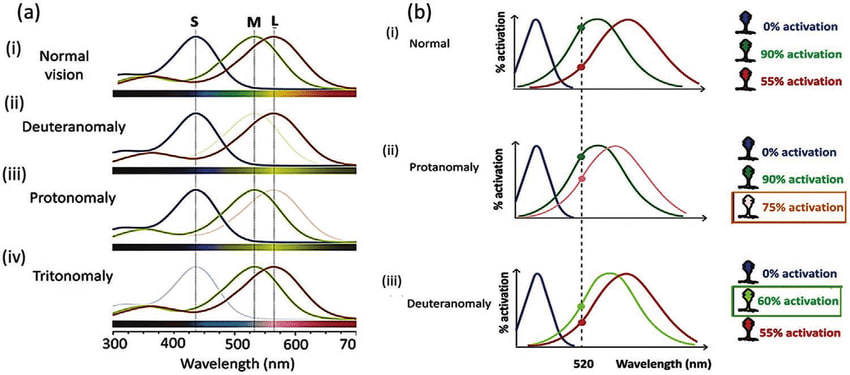
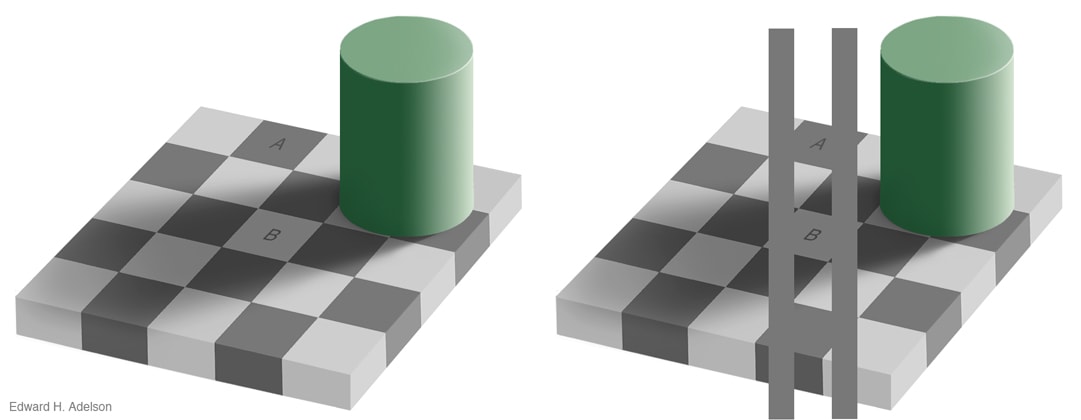
Ah, I think I follow - eliminating contextual data as much as possible can dispel the illusion - e.g. in the below image, if the context around squares A and B were removed, and all you had were those two squares on a plain background, the colour misattribution shouldn't happen. I guess then I'd say the efficacy of the illusion is dependent on how strongly the generalisation has proved true and useful in the environment, and therefore been reinforced. Most people have seen shadows before, so the one below should be pretty general; the arrow illusion is culturally variable as seen here, precisely because if your lifelong visual environment had few straight lines in it you're not likely to make generalisations about them. So, in the ML case, we'd need to... somehow eliminate the ability of the model to deduce context whatsoever, whereupon it's probably not useful. There's a definite sense where if the image below were of the real world, if you simply moved the cylinder, the colours of A and B would obviously be different. And so when an AI is asked "are squares A and B the same colour", the question it needs to answer implicitly is if you're asking them to world-model as an image (giving a yes) or world-model as a projection of a 3D space (giving a no). Ideally such a model would ask you to clarify which question you're asking. I think maybe the ambiguity is in the language around "what we want", and in many cases we can't define that explicitly (which is usually why we are training by example rather than using explicit classification rules in the first place).
There's also Pepper's ghost, where there's a sense in which the "world model altered to allow for the presence of a transparent ethereal entity" is, given the stimulus, probably the best guess that could be made without further information or interrogation. It's a reasonable conclusion, even if it's wrong - and it's those kinds of "reasonable but factually incorrect" errors which is really us-as-human changing the questions we're asking. It's like if we showed a single pixel to an AI, and asked it to classify it as a cat or a dog - it might eventually do slightly better than chance, but an identical stimulus could be given which could have come from either. And so that confusion I think is just around "have we given enough information to eliminate the ambiguity". (This is arguably a similar problem problem to the one discussed here, come to think of it.)
- For humans, adversarial examples of visual stimulus that only perturb a small number of features can exist, but are for the most part not generalisable across all human brains - most optical illusions that seem very general still only work on a subset of the population. I see this as similar to how hyperspecific adversarial images (e.g. single-pixel attacks) are usually only adversarial to an individual ML model and others will still classify it correctly, but images which even humans might be confused about are likely to cause misclassification across a wider set of models. Unlike ML models, we can also move around an image and expose it to arbitrary transformations; to my knowledge most adversarial pictures are brittle to most transforms and need to retain specific features to still work.
- Adversarial inputs are for the most part model-specific. Also, most illusions we are aware of are easy to catch. Another thought on this - examples like this demonstrate to me that there's some point at which these "adversarial examples" are just a genuine merging of features between two categories. It's just a question of if the perturbation is mutually perceptible to both the model AND the humans looking at the same stimulus.
- For the most part, the categories we're using to describe the world aren't "real" - the image below is not of a pipe; it is an image of a painting of a pipe, but it is not a pipe itself. The fuzziness of translating between images and categories, in language or otherwise, is a fuzziness around our definition. We can only classify it in a qualitative sense - ML models just try their best to match that vague intuition we-as-humans have. That there is an ever-retreating boundary of edge cases to our classifications isn't a surprise, nor something I'm especially concerned about. (I suspect there's something you're pointing at with this question which I'm not quite following - if you can rephrase/expand I'd be happy to discuss further.)



yes - a perfect in-situ example of babble's sibling, prune
Sure - let's say this is more like a poorly-labelled bottle of detergent that the model is ingesting under the impression that it's cordial. A Tide Pod Challenge of unintended behaviours. Was just calling it "poisoning" as shorthand since the end result is the same, it's kind of an accidental poisoning.
The analogous output would probably optical illusions - adversarial inputs to the eyeballs that mislead your brain into incorrect completions and conclusions. Or in the negative case, something that induces an epileptic seizure.
I did do a little research around that community before posting my comment; only later did I realise that I'd actually discovered a distinct failure mode to those in the original post: under some circumstances, ChatGPT interprets the usernames as numbers. In particular this could be due to the /r/counting subreddit being a place where people make many posts incrementing integers. So these username tokens, if encountered in a Reddit-derived dataset, might be being interpreted as numbers themselves, since they'd almost always be contextually surrounded by actual numbers.
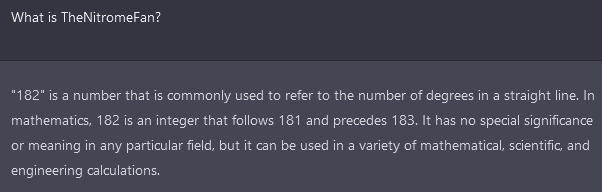
I think I found the root of some of the poisoning of the dataset at this link. It contains TheNitromeFan, SolidGoldMagikarp, RandomRedditorWithNo, Smartstocks, and Adinida from the original post, as well as many other usernames which induce similar behaviours; for example, when ChatGPT is asked about davidjl123, either it terminates responses early or misinterprets the input in a similar way to the other prompts. I don't think it's a backend scraping thing, so much as scraping Github, which in turn contains all sorts of unusual data.



Glad you liked it! The times when the task is most difficult to use heuristics for are when the shape is partially obscured by itself due to the viewing angle (e.g. below), so you don't always have complete information about the shape. So to my mind a first pass would be intentionally obscuring a section of the view of each block - but even then, it's not really immune to the issue.
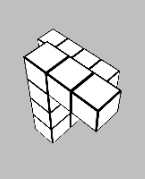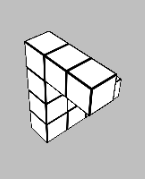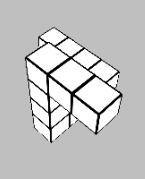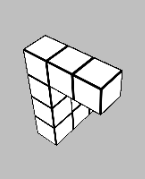
Ultimately the heuristic-forming is what turns deliberate System 2 thinking into automatic System 1 thinking, but we don't have direct control over that process. So long as it matches predicted reward, that's the thing that matters. And so long as mental rotation would reliably solve the problem, there is almost always going to be a set of heuristics that solves the same problem faster. The question is whether the learned heuristics generalise outside of the training set of the game.
I was super excited to read some detailed answers on how to selectively breed a chinchilla to weigh 10 tonnes and the costs associated with doing so. I have rarely been more disappointed.