vitaliya's Shortform
post by vitaliya · 2023-11-18T21:28:11.125Z · LW · GW · 2 commentsContents
2 comments
2 comments
Comments sorted by top scores.
comment by vitaliya · 2025-03-08T10:04:44.728Z · LW(p) · GW(p)
(epistemic status: if the following describes an already known and well-studied object in the LLM literature please point me in the right direction to learn more. but it is new to me and maybe new to you!)
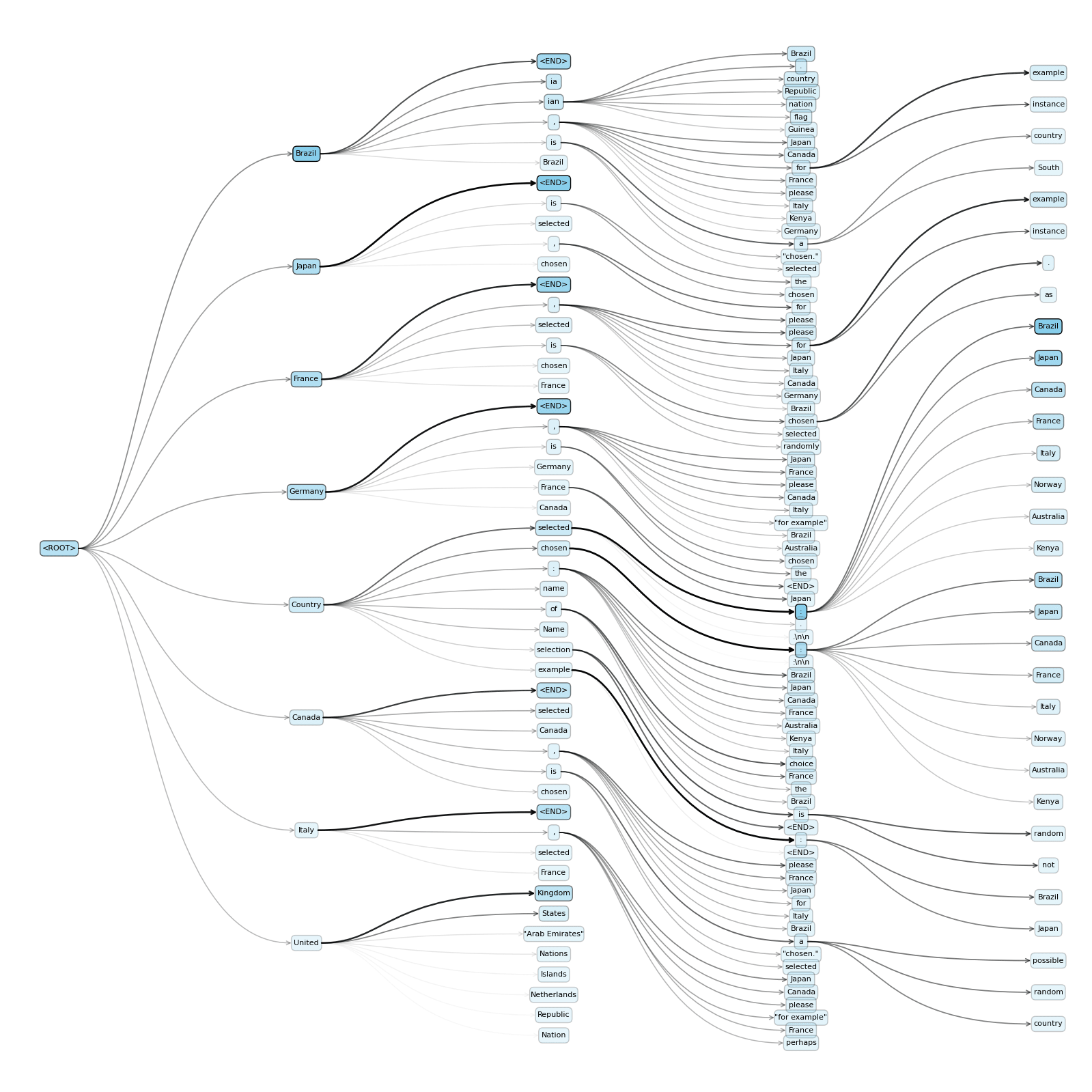
I've spent most of this week constructing and plotting what I'm terming "holographemes" because what's the point of doing science if you can't coin dumb jargon, and we're in the golden age where "mad linguistics" is finally becoming a real branch of mad science. They're next-token prediction trees over a known percentage of the full probability distribution from an LLM, up to the point of an end-of-string token. In this sense they're like a "holograph" of the LLM output space's grapheme sequences; you can observe different possible sentence constructions, where in standard Monte Carlo sampling you're only ever seeing chains of one at a time. Unlike Monte Carlo sampling, a holographeme gives you a formal guarantee around how likely specific outputs are on the generator level. The downside of this is that they take a while to generate, since the space of next token sequences grows exponentially; you can get around this somewhat using a sane search algorithm prioritising the expansion of heavy regions of probability mass in the existing tree, or otherwise constraining Top-K.
An important feature of holographemes is that you can reweight probability masses on the graph when values such as temperature change, or for a reduction of Top-K, without interacting any further with the LLM! And they can also output exactly what the residual uncertainty is after these changes, which constitute strictly positive error bars on any of the categories. Reweighting the edges of a holographeme is much computationally cheaper than re-running Monte Carlo tests on the LLM with different parameters - and, in fact, you can get closed-form representations of output as an expression of temperature. This lets us efficiently plot equivalence classes' likelihoods as temperature changes, to see how the parameter changes the output distributions in a smooth (differentiable) way. This is preliminary continuation of my post here [LW · GW], where I'm wanting to find cases of "semantic attraction" towards particular choices (and especially ethical ones). Having this as a tool lets me talk about nonsense like "joint holographeme consistency" between prompts, where we want to determine when responses to related queries can be expected to give coherent answers. It also means I can treat a prompt as an input to an LLM as a function: rather than non-deterministically choosing one string output, it can deterministically output a holographeme up to some probability mass fidelity. This is another way of turning an LLM into a "deterministic thing" aside from just setting T=0 - it's outputting objects that we can then non-deterministically sample over as a separate step.
The one below is a holographeme asking the LLM (Phi 4 Mini Instruct) to pick a random country; I've used a Top-K of 8 just to avoid exploding probabilities. If I perform an early closure over semantic classes - i.e. ending tree branches once a unique country name has been output - then this can be an even more compact representation of the decision space. It seems to be a big fan of Brazil and Japan!