The Tails Coming Apart As Metaphor For Life
post by Scott Alexander (Yvain) · 2018-09-25T19:10:02.410Z · LW · GW · 39 commentsContents
39 comments
[Epistemic status: Pretty good, but I make no claim this is original]
A neglected gem from Less Wrong: Why The Tails Come Apart [LW · GW], by commenter Thrasymachus. It explains why even when two variables are strongly correlated, the most extreme value of one will rarely be the most extreme value of the other. Take these graphs of grip strength vs. arm strength and reading score vs. writing score:
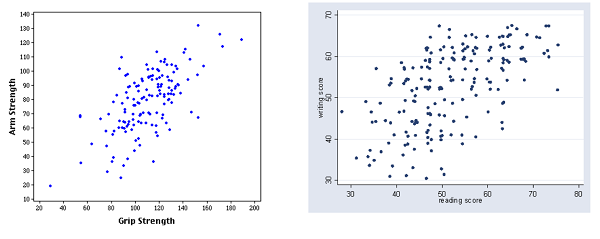
In a pinch, the second graph can also serve as a rough map of Afghanistan
Grip strength is strongly correlated with arm strength. But the person with the strongest arm doesn’t have the strongest grip. He’s up there, but a couple of people clearly beat him. Reading and writing scores are even less correlated, and some of the people with the best reading scores aren’t even close to being best at writing.
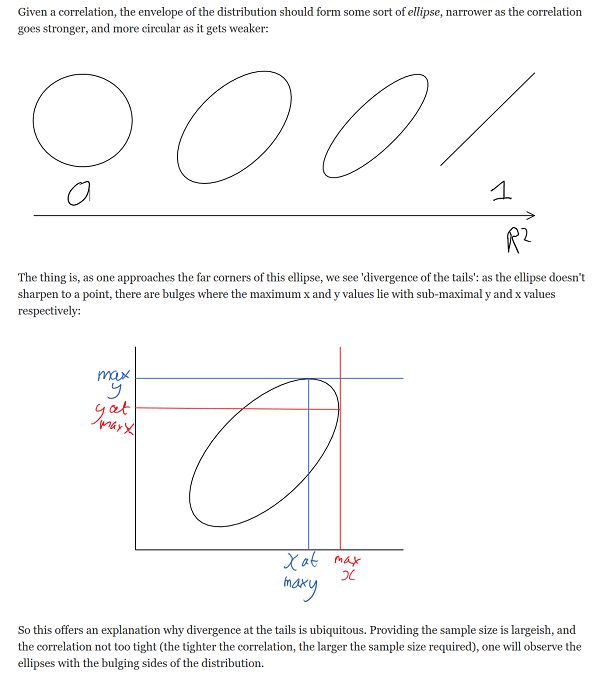
Thrasymachus gives an intuitive geometric explanation of why this should be; I can’t beat it, so I’ll just copy it outright:
I thought about this last week when I read this article on happiness research.
The summary: if you ask people to “value their lives today on a 0 to 10 scale, with the worst possible life as a 0 and the best possible life as a 10”, you will find that Scandinavian countries are the happiest in the world.
But if you ask people “how much positive emotion do you experience?”, you will find that Latin American countries are the happiest in the world.
If you check where people are the least depressed, you will find Australia starts looking very good.
And if you ask “how meaningful would you rate your life?” you find that African countries are the happiest in the world.
It’s tempting to completely dismiss “happiness” as a concept at all, but that’s not right either. Who’s happier: a millionaire with a loving family who lives in a beautiful mansion in the forest and spends all his time hiking and surfing and playing with his kids? Or a prisoner in a maximum security jail with chronic pain? If we can all agree on the millionaire – and who wouldn’t? – happiness has to at least sort of be a real concept.
The solution is to understand words as hidden inferences [LW · GW] – they refer to a multidimensional correlation rather than to a single cohesive property. So for example, we have the word “strength”, which combines grip strength and arm strength (and many other things). These variables really are heavily correlated (see the graph above), so it’s almost always worthwhile to just refer to people as being strong or weak. I can say “Mike Tyson is stronger than an 80 year old woman”, and this is better than having to say “Mike Tyson has higher grip strength, arm strength, leg strength, torso strength, and ten other different kinds of strength than an 80 year old woman.” This is necessary to communicate anything at all and given how nicely all forms of strength correlate there’s no reason not to do it.
But the tails still come apart. If we ask whether Mike Tyson is stronger than some other very impressive strong person, the answer might very well be “He has better arm strength, but worse grip strength”.
Happiness must be the same way. It’s an amalgam between a bunch of correlated properties like your subjective well-being at any given moment, and the amount of positive emotions you feel, and how meaningful your life is, et cetera. And each of those correlated is also an amalgam, and so on to infinity.
And crucially, it’s not an amalgam in the sense of “add subjective well-being, amount of positive emotions, and meaningfulness and divide by three”. It’s an unprincipled conflation of these that just denies they’re different at all.
Think of the way children learn what happiness is. I don’t actually know how children learn things, but I imagine something like this. The child sees the millionaire with the loving family, and her dad says “That guy must be very happy!”. Then she sees the prisoner with chronic pain, and her mom says “That guy must be very sad”. Repeat enough times and the kid has learned “happiness”.
Has she learned that it’s made out of subjective well-being, or out of amount of positive emotion? I don’t know; the learning process doesn’t determine that. But then if you show her a Finn who has lots of subjective well-being but little positive emotion, and a Costa Rican who has lots of positive emotion but little subjective well-being, and you ask which is happier, for some reason she’ll have an opinion. Probably some random variation in initial conditions has caused her to have a model favoring one definition or the other, and it doesn’t matter until you go out to the tails. To tie it to the same kind of graph as in the original post:
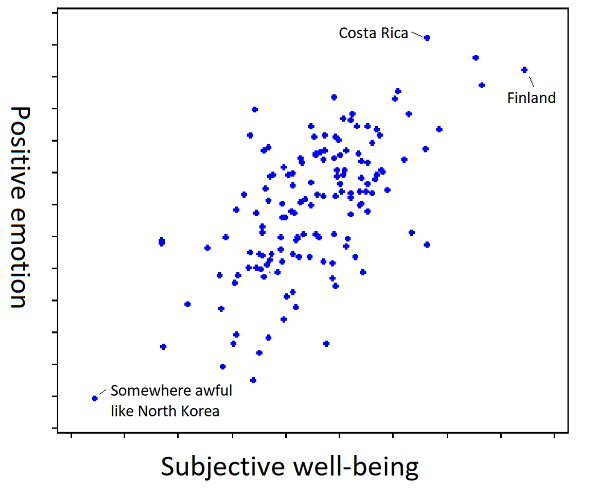
And to show how the individual differences work:
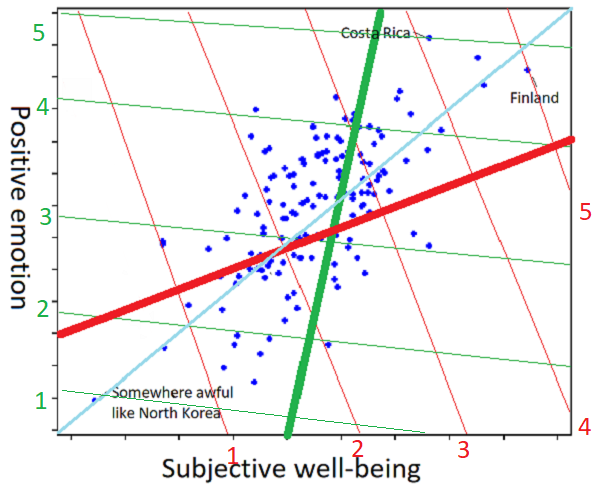
I am sorry about this graph, I really am. But imagine that one person, presented with the scatter plot and asked to understand the concept “happiness” from it, draws it as the thick red line (further towards the top right part of the line = more happiness), and a second person trying to the same task generates the thick green line. Ask the first person whether Finland or Costa Rica is happier, and they’ll say Finland: on the red coordinate system, Finland is at 5, but Costa Rica is at 4. Ask the second person, and they’ll say Costa Rica: on the green coordinate system, Costa Rica is at 5, and Finland is at 4 and a half. Did I mention I’m sorry about the graph?
But isn’t the line of best fit (here more or less y = x = the cyan line) the objective correct answer? Only in this metaphor where we’re imagining positive emotion and subjective well-being are both objectively quantifiable, and exactly equally important. In the real world, where we have no idea how to quantify any of this and we’re going off vague impressions, I would hate to be the person tasked with deciding whether the red or green line was more objectively correct.
In most real-world situations Mr. Red and Ms. Green will give the same answers to happiness-related questions. Is Costa Rica happier than North Korea? “Obviously,” the both say in union. If the tails only come apart a little, their answers to 99.9% of happiness-related questions might be the same, so much so that they could never realize they had slightly different concepts of happiness at all.
(is this just reinventing Quine? I’m not sure. If it is, then whatever, my contribution is the ridiculous graphs.)
Perhaps I am also reinventing the model of categorization discussed in How An Algorithm Feels From The Inside [LW · GW], Dissolving Questions About Disease [LW · GW], and The Categories Were Made For Man, Not Man For The Categories.
But I think there’s another interpretation. It’s not just that “quality of life”, “positive emotions”, and “meaningfulness” are three contributors which each give 33% of the activation to our central node of “happiness”. It’s that we got some training data – the prisoner is unhappy, the millionaire is happy – and used it to build a classifier that told us what happiness was. The training data was ambiguous enough that different people built different classifiers. Maybe one person built a classifier that was based entirely on quality-of-life, and a second person built a classifier based entirely around positive emotions. Then we loaded that with all the social valence of the word “happiness”, which we naively expected to transfer across paradigms.
This leads to (to steal words from Taleb) a Mediocristan resembling the training data where the category works fine, vs. an Extremistan where everything comes apart. And nowhere does this become more obvious than in what this blog post has secretly been about the whole time – morality.
The morality of Mediocristan is mostly uncontroversial. It doesn’t matter what moral system you use, because all moral systems were trained on the same set of Mediocristani data and give mostly the same results in this area. Stealing from the poor is bad. Donating to charity is good. A lot of what we mean when we say a moral system sounds plausible is that it best fits our Mediocristani data that we all agree upon. This is a lot like what we mean when we say that “quality of life”, “positive emotions”, and “meaningfulness” are all decent definitions of happiness; they all fit the training data.
The further we go toward the tails, the more extreme the divergences become. Utilitarianism agrees that we should give to charity and shouldn’t steal from the poor, because Utility, but take it far enough to the tails and we should tile the universe with rats on heroin. Religious morality agrees that we should give to charity and shouldn’t steal from the poor, because God, but take it far enough to the tails and we should spend all our time in giant cubes made of semiprecious stones singing songs of praise. Deontology agrees that we should give to charity and shouldn’t steal from the poor, because Rules, but take it far enough to the tails and we all have to be libertarians.
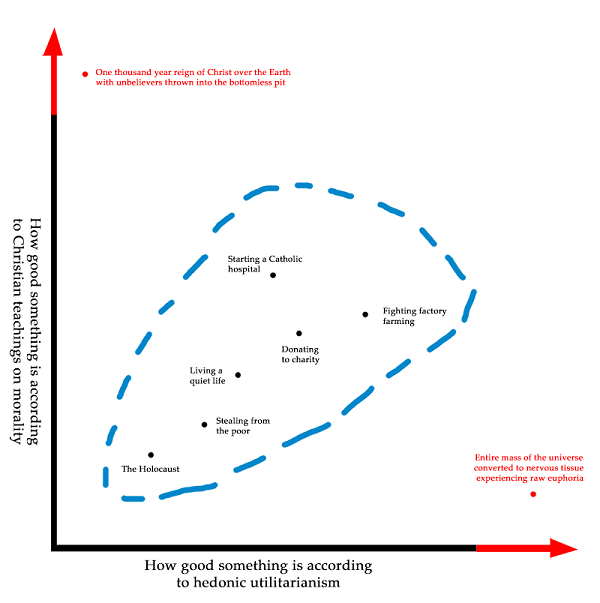
I have to admit, I don’t know if the tails coming apart is even the right metaphor anymore. People with great grip strength still had pretty good arm strength. But I doubt these moral systems form an ellipse; converting the mass of the universe into nervous tissue experiencing euphoria isn’t just the second-best outcome from a religious perspective, it’s completely abominable. I don’t know how to describe this mathematically, but the terrain looks less like tails coming apart and more like the Bay Area transit system:
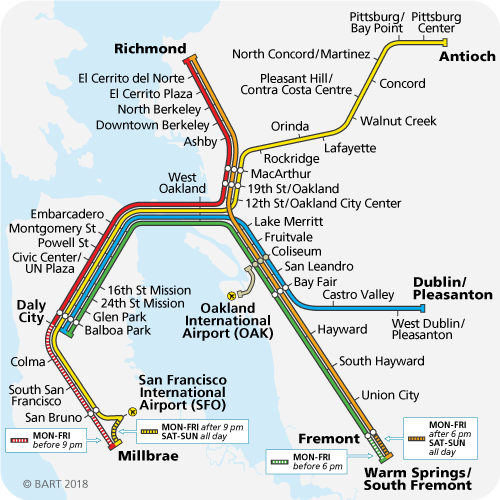
Mediocristan is like the route from Balboa Park to West Oakland, where it doesn’t matter what line you’re on because they’re all going to the same place. Then suddenly you enter Extremistan, where if you took the Red Line you’ll end up in Richmond, and if you took the Green Line you’ll end up in Warm Springs, on totally opposite sides of the map.
Our innate moral classifier has been trained on the Balboa Park – West Oakland route. Some of us think morality means “follow the Red Line”, and others think “follow the Green Line”, but it doesn’t matter, because we all agree on the same route.
When people talk about how we should arrange the world after the Singularity when we’re all omnipotent, suddenly we’re way past West Oakland, and everyone’s moral intuitions hopelessly diverge.
But it’s even worse than that, because even within myself, my moral intuitions are something like “Do the thing which follows the Red Line, and the Green Line, and the Yellow Line…you know, that thing!” And so when I’m faced with something that perfectly follows the Red Line, but goes the opposite directions as the Green Line, it seems repugnant even to me, as does the opposite tactic of following the Green Line. As long as creating and destroying people is hard, utilitarianism works fine, but make it easier, and suddenly your Standard Utilitarian Path diverges into Pronatal Total Utilitarianism vs. Antinatalist Utilitarianism and they both seem awful. If our degree of moral repugnance is the degree to which we’re violating our moral principles, and my moral principle is “Follow both the Red Line and the Green Line”, then after passing West Oakland I either have to end up in Richmond (and feel awful because of how distant I am from Green), or in Warm Springs (and feel awful because of how distant I am from Red).
This is why I feel like figuring out a morality that can survive transhuman scenarios is harder than just finding the Real Moral System That We Actually Use. There’s actually a possibly-impossible conceptual problem here, of figuring out what to do with the fact that any moral rule followed to infinity will diverge from large parts of what we mean by morality.
This is only a problem for ethical subjectivists like myself, who think that we’re doing something that has to do with what our conception of morality is. If you’re an ethical naturalist, by all means, just do the thing that’s actually ethical.
When Lovecraft wrote that “we live on a placid island of ignorance in the midst of black seas of infinity, and it was not meant that we should voyage far”, I interpret him as talking about the region from Balboa Park to West Oakland on the map above. Go outside of it and your concepts break down and you don’t know what to do. He was right about the island, but exactly wrong about its causes – the most merciful thing in the world is how so far we have managed to stay in the area where the human mind can correlate its contents.
39 comments
Comments sorted by top scores.
comment by cousin_it · 2018-09-26T08:52:37.382Z · LW(p) · GW(p)
Your post still leaves the possibility that "quality of life", "positive emotions" or "meaningfulness" are objectively existing variables, and people differ only in their weighting. But I think the problem might be worse than that. See this old comment by Wei [LW(p) · GW(p)]:
let's say it models the world as a 2D grid of cells that have intrinsic color, it always predicts that any blue cell that it shoots at will turn some other color, and its utility function assigns negative utility to the existence of blue cells. What does this robot "actually want", given that the world is not really a 2D grid of cells that have intrinsic color?
In human terms, let's say you care about the total amount of happiness in the universe. Also let's say, for the sake of argument, that there's no such thing as total amount of happiness in the universe. What do you care about then?
See Eliezer's Rescuing the utility function for a longer treatment of this topic. I spent some time mining ideas from there, but still can't say I understand them all.
Replies from: None↑ comment by [deleted] · 2019-08-05T13:48:26.984Z · LW(p) · GW(p)
To me this looks like a knockdown argument to any non-solipsistic morality. I really do just care about my qualia.
In some sense it's the same mistake the deontologists make, on a deeper level. A lot their proposed rules strike me as heavily correlated with happiness. How were these rules ever generated? Whatever process generated them must have been a consequentialist process.
If deontology is just applied consequentialism, then maybe "happiness" is just applied "0x7fff5694dc58".
Your post still leaves the possibility that "quality of life", "positive emotions" or "meaningfulness" are objectively existing variables, and people differ only in their weighting. But I think the problem might be worse than that.
I think this makes the problem less bad, because if you get people to go up their chain of justification, they will all end up at the same point. I think that point is just predictions of the valence of their qualia.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2020-04-10T15:49:23.226Z · LW(p) · GW(p)
It's not. You may only care about your qualia, but I care about more than just my qualia. Perhaps what exactly I care about is not well-defined, but sure as shit my behavior is best modelled and explained as trying to achieve something in the world outside of my mind. Nozick's experience machine argument shows all this. There's also a good post by Nate Soares on the subject IIRC.
comment by [deleted] · 2018-09-29T18:29:21.358Z · LW(p) · GW(p)
Lately when I'm confronted with extreme thought experiments that are repugnant on both sides, my answer has been "mu". No I can't give a good answer, and I'm skeptical that anyone can.
Balboa park to West Oakland is our established world. We have been carefully leaning into it's edge, slowly crafting extensions of our established moral code, adding bits to it and refactoring old parts to make it consistent with the new stuff.
It's been a mythical effort. People above our level have spent their 1000 year long lifetimes mulling over their humble little additions to the gigantic established machine that is our morality.
And this machine has created Mediocristan. A predictable world, with some predictable features, within which there is always a moral choice available. Without these features our moral programming would be completely useless. We can behave morally precisely because the cases in which there is no moral answer, don't happen so much.
So please, stop asking me whether I'd kill myself to save 1000 babies from 1000 years of torture. Both outcomes are repugnant and the only good answer I have is "get out of Extremistan".
The real morality is to steer the world towards a place where we don't need morality. Extend the borders of Mediocristan to cover a wider set of situations. Bolster it internally so that the intelligence required for a moral choice becomes lower - allowing more people to make it.
No morality is world-independent. If you think you have a good answer to morality, you have to provide it with a description of the worlds in which it works, and a way to make sure we stay within those bounds.
Replies from: peter-loksa↑ comment by PeterL (peter-loksa) · 2022-12-21T22:04:22.187Z · LW(p) · GW(p)
Very nicely written. A good example of this might be invention of genetic flaw correction, due to which morally controversial abortion could become less desired option.
comment by Vanessa Kosoy (vanessa-kosoy) · 2018-09-25T21:24:47.577Z · LW(p) · GW(p)
One way to deal with this is, have an entire set of utility functions (the different "lines"), normalize them so that they approximately agree inside "Mediocristan", and choose the "cautious" strategy, i.e. the strategy the maximizes the minimum of expected utility over this set. This way you are at least guaranteed not the end up in a place that is worse than "Mediocristan".
Replies from: Paperclip Minimizer, wizzwizz4↑ comment by Paperclip Minimizer · 2018-10-01T18:15:09.353Z · LW(p) · GW(p)
Using PCA on utility functions could be an interesting research subject for wannabe AI risk experts.
comment by SebastianG (JohnBuridan) · 2019-12-20T16:54:47.820Z · LW(p) · GW(p)
“The Tails Coming Apart as a Metaphor for Life” [LW · GW] should be retitled “The Tails Coming Apart as a Metaphor for Earth since 1800.” Scott does three things, 1) he notices that happiness research is framing dependent, 2) he notices that happiness is a human level term, but not specific at the extremes, 3) he considers how this relates to deep seated divergences in moral intuitions becoming ever more apparent in our world.
He hints at why moral divergence occurs with his examples. His extreme case of hedonic utilitarianism, converting the entire mass of the universe into nervous tissue experiencing raw euphoria, represents a ludicrous extension of the realm of the possible: wireheading, methadone, subverting factory farming. Each of these is dependent upon technology and modern economies, and presents real ethical questions. None of these were live issues for people hundreds of years ago. The tails of their rival moralities didn’t come apart – or at least not very often or in fundamental ways. Back then Jesuits and Confucians could meet in China and agree on something like the “nature of the prudent man.” But in the words of Lonergan that version of the prudent man, Prudent Man 1.0, is obsolete: “We do not trust the prudent man’s memory but keep files and records and develop systems of information retrieval. We do not trust the prudent man’s ingenuity but call in efficiency experts or set problems for operations research. We do not trust the prudent man’s judgment but employ computers to forecast demand,” and he goes on. For from the moment VisiCalc primed the world for a future of data aggregation, Prudent Man 1.0 has been hiding in the bathroom bewildered by modern business efficiency and moon landings.
Let’s take Scott’s analogy of the Bay Area Transit system entirely literally, and ask the mathematical question: when do parallel lines come apart or converge? Recall Euclid’s Fifth Postulate, the one saying that parallel lines will never intersect. For almost a couple thousand years no one could figure out why it was true. But it wasn’t true, and it wasn’t false. Parallel lines come apart or converge in most spaces. Only, alas, only on a flat plane in a regular Euclidean space ℝ3 do they obey Euclid’s Fifth and stay equidistant.
So what is happening when the tails come apart in morality? Even simple technologies extend our capacities, and each technological step extending the reach of rational consciousness into the world transforms the shape of the moral landscape which we get to engage with. Technological progress requires new norms to develop around it. And so the normative rules of a 16th century Scottish barony don’t become false; they become incomparable.
Now the Fifth postulate was true in a local sense, being useful for building roads, cathedrals, and monuments. And reflective, conventional morality continues to be useful and of inestimable importance for dealing with work, friends, and community. However, it becomes the wrong tool to use when considering technology laws, factory farming, or existential risk. We have to develop new tools.
Scott’s concludes that we have mercifully stayed within the bounds where we are able to correlate the contents of rival moral ideas. But I think it likely that this is getting harder and harder to do each decade. Maybe we need another, albeit very different, Bernard Riemann to develop a new math demonstrating how to navigate all the wild moral landscapes we will come into contact with.
We Human-Sized Creatures access a surprisingly detailed reality with our superhuman tools. May the next decade be a good adventure, filled with new insights, syntheses, and surprising convergences in the tails.
comment by orthonormal · 2019-12-07T23:04:18.893Z · LW(p) · GW(p)
I support this post being included in the Best-of-2018 Review.
It does a good job of starting with a straightforward concept, and explaining it clearly and vividly (a SlateStarScott special). And then it goes on to apply the concept to another phenomenon (ethical philosophy) and make more sense of an oft-observed phenomenon (the moral revulsion to both branches of thought experiments, sometimes by the same individual).
comment by torekp · 2018-09-26T00:48:35.866Z · LW(p) · GW(p)
If there were no Real Moral System That You Actually Use, wouldn't you have a "meh, OK" reaction to either Pronatal Total Utilitarianism or Antinatalist Utilitarianism - perhaps whichever you happened to think of first? How would this error signal - disgust with those conclusions - be generated?
Replies from: gjm↑ comment by gjm · 2018-09-26T12:23:33.539Z · LW(p) · GW(p)
Suppose you have immediate instinctive reactions of approval and disapproval -- let's call these pre-moral judgements -- but that your actual moral judgements are formed by some (possibly somewhat unarticulated) process of reflection on these judgements. E.g., maybe your pre-moral judgements about killing various kinds of animal are strongly affected by how cute and/or human-looking the animals are, but after giving the matter much thought you decide that you should treat those as irrelevant.
In that case, you might have a strong reaction to either of those variants of utilitarianism, or for that matter to both of them.
But this is all consistent with there being no Real Moral System That You Actually Use, because those strong reactions are not the same thing as your moral system; you explicitly reject the idea that those pre-moral judgements are the same as actual moral judgements. And there could be situations where you have very strong pre-moral judgements but where, on careful reflection, ... you have no idea what, if anything, your Actual Moral Judgement is.
Replies from: Paperclip Minimizer, paul-torek↑ comment by Paperclip Minimizer · 2018-10-01T18:14:21.838Z · LW(p) · GW(p)
I don't see the argument. I have an actual moral judgement that painless extermination of all sentient beings is evil, and so is tiling the universe with meaningless sentient beings.
Replies from: gjm↑ comment by gjm · 2018-10-01T22:54:01.089Z · LW(p) · GW(p)
I have no trouble believing that you do, but I don't understand how that relates to the point at issue here. (I wasn't meaning to imply that no one has actual moral judgements, at all; nor that no one has actual moral judgements that match their immediate instinctive reactions; if the problem is that it seemed like I meant either of those, then I apologize for being insufficiently clear.)
The argument I was making goes like this: -1. Scott suggests that there may not be any such thing as his Real Moral System, because different ways of systematizing his moral judgements may be indistinguishable when asked about the sort of question he has definite moral judgements about, but all lead to different and horrifying conclusions when pushed far beyond that. 0. Paul says that if Scott didn't have a Real Moral System then he wouldn't be horrified by those conclusions, but would necessarily feel indifferent to them. 1. No: he might well still feel horror at those conclusions, because not having a Real Moral System doesn't mean not having anything that generates moral reactions; one can have immediate reactions of approval or disapproval to things, but not reflectively endorse them. Scott surely has some kind of brain apparatus that can react to whatever it's presented with, but that's not necessarily a Real Moral System because he might disavow some of its reactions; if so, he presumably has some kind of moral system (which does that disavowing), but there may be some questions to which it doesn't deliver answers.
All of this is perfectly consistent with there being other people whose Real Moral System does deliver definite unambiguous answers in all these weird extreme cases.
Replies from: Paperclip Minimizer↑ comment by Paperclip Minimizer · 2018-10-12T16:37:49.065Z · LW(p) · GW(p)
I'm not sure what it would even mean to not have a Real Moral System. The actual moral judgments must come from somewhere.
Replies from: gjm↑ comment by gjm · 2018-10-13T19:40:21.303Z · LW(p) · GW(p)
Anyone who makes moral judgements has a Real Moral Something.
But suppose there's no human-manageable way of predicting your judgements; nothing any simpler or more efficient than presenting them to your brain and seeing what it does. You might not want to call that a system.
And suppose that for some questions, you don't have an immediate answer, and what answer you end up with depends on irrelevant-seeming details: if we were somehow able to rerun your experience from now to when we ask you the question and you decide on an answer, we would get different answers on different reruns. (This might be difficult to discover, of course.) In that case, you might not want to say that you have a real opinion on those questions, even though it's possible to induce you to state one.
Replies from: Paperclip Minimizer↑ comment by Paperclip Minimizer · 2018-10-14T06:58:04.429Z · LW(p) · GW(p)
An high-Kolmogorov-complexity system is still a system.
↑ comment by Paul Torek (paul-torek) · 2018-09-26T16:58:39.439Z · LW(p) · GW(p)
Good point. Let's try something else then, vaguely related to my first idea.
Suppose you are given lots of time and information and arguments to ponder, and either you would eventually come up with some resolution, or you still wouldn't. In the former case, I think we've found your Actual Moral Judgment (AMJ). In the latter, I'm inclined to say that your AMJ is that the options are morally incomparable: neither is better nor worse than the other.
Of course, this analysis doesn't help *you* make the decision. It just gives an impartial observer a possible way to understand what you're doing.
Replies from: gjm↑ comment by gjm · 2018-09-27T15:14:14.920Z · LW(p) · GW(p)
I'm not sure there's really a difference between "there is no fact of the matter as to whether I prefer A to B morally" and "my moral preference between A and B is that I find them incomparable".
Note that "incomparable" is not the same thing as "equivalent". That is, being persistently unable to choose between A and B is not the same as thinking that A and B are exactly equally good. E.g., it could happen that I find A and B incomparable, B and C incomparable, but A definitely better than C.
(E.g., let B be a world in which no one exists and A,C be two different worlds in which there are a lot of happy people and a lot of miserable people, with different ratios of happy to miserable and about the same total number of people. I might be entirely unable to figure out whether I think the existence of happy people makes it OK on balance that there are a lot of miserable people, but I will have no trouble deciding that all else equal I prefer a better happy-to-miserable ratio.)
Further: one way in which there being no fact of the matter as to which I prefer might manifest itself is that if you took multiple copies of me and gave them all more or less the same time and information arguments, they might end up coming to substantially different resolutions even though there wasn't much difference in the information they were presented with. (Perhaps none at all; it might depend on irrelevancies like my mood.) In that case, defining my "actual moral judgement" in terms of what I "would" decide in those situations would be problematic.
Replies from: paul-torek↑ comment by Paul Torek (paul-torek) · 2018-09-27T17:01:34.219Z · LW(p) · GW(p)
Definitely "incomparable" fails to imply "equivalent". But still, where two options are incomparable according to your morality you can't use your morality to make the decision. You'll have to decide on some other basis, or (possibly?) no basis at all. To my mind this seems like an important fact about your morality, which the sentence "my moral preference between A and B is that they're incomparable" captures nicely.
Replies from: gjm↑ comment by gjm · 2018-09-27T18:04:10.851Z · LW(p) · GW(p)
I think we're disagreeing only on terminology here. It's certainly an important fact about your morals whether or not they deliver an answer to the question "A or B?" -- or at least, it's important in so far as choosing between A and B might be important. I think that if it turns out that they don't deliver an answer, it's OK to describe that situation by saying that there isn't really such a thing as your Real Actual Moral Judgement between A and B, rather than saying that there is and it's "A and B are incomparable". Especially if there are lots of (A,B) for which this happens (supporting the picture in which there are great seas of weird situations for which your moral intuitions and principles fail, within which there's an island of "normality" where they are useful), and especially if the way it feels is that you have no idea what to think about A and B, rather than that you understand them clearly and can see that there's no principled way to decide between them (which it often does).
comment by Jameson Quinn (jameson-quinn) · 2020-01-15T21:51:22.445Z · LW(p) · GW(p)
This phenomenon is closely related to "regression towards the mean". It is important, when discussing something like this, to include such jargon names, because there is a lot of existing writing and thought on the topic. Don't reinvent the wheel.
Other than that, it's a fine article.
Replies from: Raemon↑ comment by Raemon · 2020-01-15T22:38:39.099Z · LW(p) · GW(p)
How related is this to regression to the mean? It seems like a quite different phenomenon at first glance to me.
Replies from: Unnamed, jameson-quinn↑ comment by Unnamed · 2020-01-16T00:24:51.988Z · LW(p) · GW(p)
I think they're close to identical. "The tails come apart", "regression to the mean", "regressional Goodhart", "the winner's curse", "the optimizer's curse", and "the unilateralist's curse" are all talking about essentially the same statistical phenomenon. They come at it from different angles, and highlight different implications, and are evocative of different contexts where it is relevant to account for the phenomenon.
↑ comment by Jameson Quinn (jameson-quinn) · 2020-01-15T22:50:01.399Z · LW(p) · GW(p)
The expectation of X is "regressed towards the mean" when an extreme Y is used as a predictor, and vice versa. Thus, to my mind, this post's target phenomenon is a straightforward special case of RTM.
Replies from: Raemon↑ comment by Raemon · 2020-01-15T22:53:42.618Z · LW(p) · GW(p)
Hmm, okay yeah that makes sense. I think my initial confusion is something like "the most interesting takeaway here is not the part where predictor regressed to the mean, but that extreme things tend to be differently extreme on different axis.
(At least, when I refer mentally to "tails coming apart", that's the thing I tend to mean)
Replies from: Unnamed↑ comment by Unnamed · 2020-01-16T00:26:58.730Z · LW(p) · GW(p)
the most interesting takeaway here is not the part where predictor regressed to the mean, but that extreme things tend to be differently extreme on different axis.
Even though the two variables are strongly correlated, things that are extreme on one variable are somewhat closer to the mean on the other variable.
Replies from: Raemoncomment by Vanessa Kosoy (vanessa-kosoy) · 2019-12-11T13:48:08.472Z · LW(p) · GW(p)
This essay defines and clearly explains an important property of human moral intuitions: the divergence of possible extrapolations from the part of the state spaces we're used to think about. This property is a challenge in moral philosophy, that has implications on AI alignment and long-term or "extreme" thinking in effective altruism. Although I don't think that it was especially novel to me personally, it is valuable to have a solid reference for explaining this concept.
comment by manarch · 2018-09-26T07:52:35.272Z · LW(p) · GW(p)
Interesting post. I wonder what Lovecraft would make of "the world" in 2018 given what he goes on to write after the quoted line? Your conclusion reflects in a way what someone said to me a couple of decades ago - there's a very good reason why trash is on prime time TV, it's something to consider being thankful for.
Maybe it's because I've only recently started to learn more about this kind of enquiry (I'm a slow starter and learner and still haven't progressed out of the Enlightenment era), but I can't help but wonder whether the possibly improbable conceptual problem can be reframed more broadly into a simpler proposition that says that individually making sense of "the world" is mutually exclusive to collectively knowing more about it. It would make sense of the conclusion that Mediocristan is the best of worlds even if only on merely merciful grounds.
(ps : thanks for the site - I'm new to it so have only just started to dig and read, but am excited to find somewhere that isn't reducing thinking to match digital attention spans.)
comment by DragonGod · 2018-10-01T12:46:11.157Z · LW(p) · GW(p)
My response to this was initially a tongue in cheek "I'm a moral nihilist, and there's no sense in which one moral system is intrinsically better than another as morality is not a feature of the territory". However, I wouldn't as solving morality is essential to the problem of creating aligned AI. There may be no objectively correct moral system, or intrinsically better moral system, or any good moral system, but we still need a coherent moral framework to use to generate our AI's utility function if we want it to be aligned, so morality is important, and we do need to develop an acceptable solution to it.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2018-10-01T21:50:21.708Z · LW(p) · GW(p)
[W]e still need a coherent moral framework to use to generate our AI's utility function if we want it to be aligned, so morality is important, and we do need to develop an acceptable solution to it.
This is not clear. It's possible for the current world to exist as it is, and similarly for any other lawful simulated world that's not optimized in any particular direction. So an AI could set up such a world without interfering, and defend its lawful operation from outside interference. This is a purposeful thing, potentially as good at defending itself as any other AI, that sets up a world that's not optimized by it, that doesn't need morality for the world it maintains, in order to maintain it. Of course this doesn't solve any problems inside that world, and it's unclear how to make such a thing, but it illustrates the problems with the "morality is necessary for AGI" position. Corrigibility also fits this description, being something unlike an optimization goal for the world, but still a purpose.
Replies from: DragonGod↑ comment by DragonGod · 2018-10-04T02:56:24.324Z · LW(p) · GW(p)
Not AGI per se, but aligned and beneficial AGI. Like I said, I'm a moral nihilist/relativist and believe no objective morality exists. I do think we'll need a coherent moral system to fulfill our cosmic endowment via AGI.
Replies from: zach-bennett↑ comment by Zach Bennett (zach-bennett) · 2025-01-25T01:17:33.609Z · LW(p) · GW(p)
Well, if you believe no objective morality exists, you're a moral nihilist which is distinct from a moral relativist, since that allows for morality to exist but only in the context of a culture, or individual.
comment by Prometheus · 2022-11-01T11:47:52.018Z · LW(p) · GW(p)
I guess this begs the question: do we actually want to pursue a certain moral system has a collective goal?
comment by [deleted] · 2019-11-30T19:07:28.546Z · LW(p) · GW(p)
I still find myself using this metaphor a lot in conversations. That's a good benchmark for usefulness.
comment by Get_unstuck · 2018-10-02T18:55:01.643Z · LW(p) · GW(p)
Reposting my friend's response to this because I think it's interesting, and he won't post it.
[Reformatted as a coherent message]
I vote for rats on heroin personally. That's interesting though. I think it gets to the idea that because all logic systems are self-referential, when taken to an extreme they break down.
There's something amazing about how infinity fucks up everything. Because when a being from the finite universe approaches or tries to observe the infinite, the universe is forced to pull from itself to fill the impossibility. So you get this maddening infinite recursion problem that pops up all over nature.Replies from: Prometheus
↑ comment by Prometheus · 2022-11-01T11:51:21.788Z · LW(p) · GW(p)
I vote the rats on heroin too. Just because it would be hilarious to think of some budding civilization in a distant galaxy peering into the heavens, and seeing the Universe being slowly consumed by a hoard of drug-addicted rodents.