Grokking revisited: reverse engineering grokking modulo addition in LSTM
post by Nikita Khomich (nikitoskh), Danik (daniil-yurshewich) · 2024-12-16T18:48:43.533Z · LW · GW · 0 commentsContents
Introduction Model architecture, experiment settings and naming conventions Exact formulas for what LSTM does Model Parameters and Dimensions Input Encoding Step-by-Step for Two Steps Final Two Linear Layers Final Output Reverse engineering the model Reducing the problem to simplified model Reverse engineering simplified model The algorithm itself Three important points Summary None No comments
By Daniil Yurshevich, Nikita Khomich
TLDR: we train LSTM model on algorithmic task of modulo addition and observe grokking. We fully reverse engeneer the algorithm learned and propose a way simpler equivalent version of the model that groks as well.
Reproducibility statement: all the code is available at the repo.
Introduction
This post is related to Neel Nanda's [LW · GW] post and a detailed description of what grokking is can be found there. The short summary is that grokking is the phenomenon when model when being trained on an algorithmic task of relatively small size initially memorizes the trining set and then suddenly generalizes to the data it hasn't seen before. In our work we train a version of LSTM on modulo addition and observe grokking.
Model architecture, experiment settings and naming conventions
We train a version of LSTM with ReLU activation instead of for getting hidden state from cell state . We use a linear layer without bias to get logits from . We use a slight trick which is using two linear layers without activation inbetween instad of one which makes grokking easier. We also use hidden dimension of and one-hot encoded embeddings. The exact model arcitecture as well as naming is (very similar to Chris Olah's amazing post)
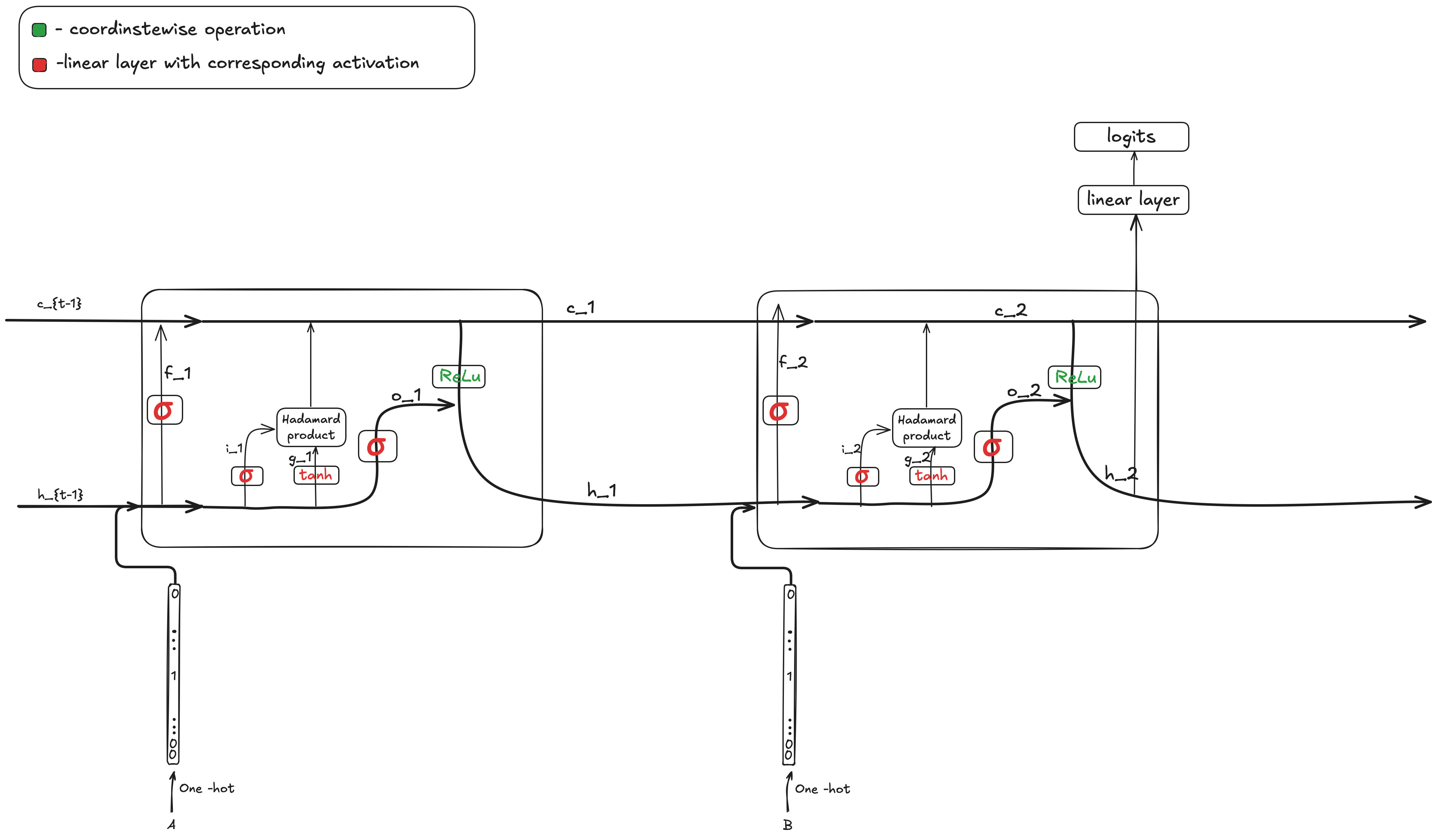
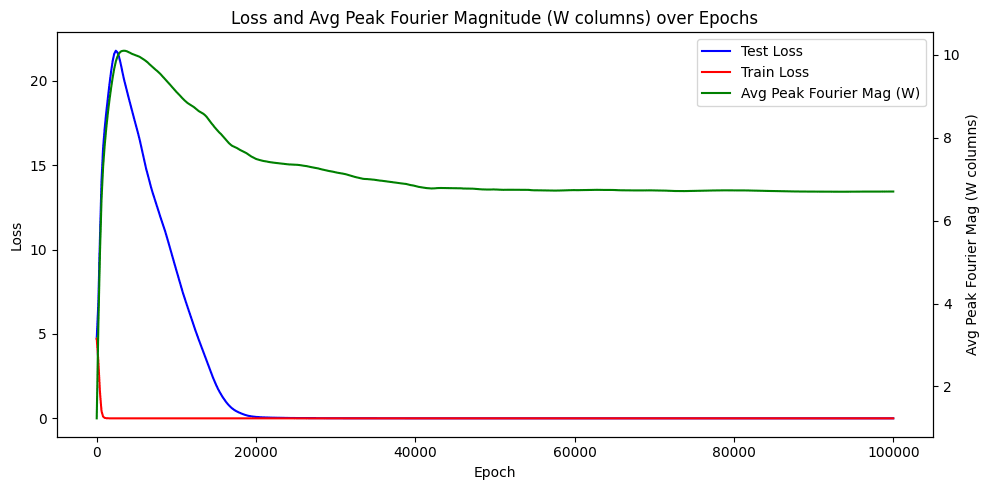
We use similar parameters to Neel's paper meaning extremely large weight decay and particular set of betas for Adam found with grid search. We train the model on a 30% of all pairs and observe grokking:
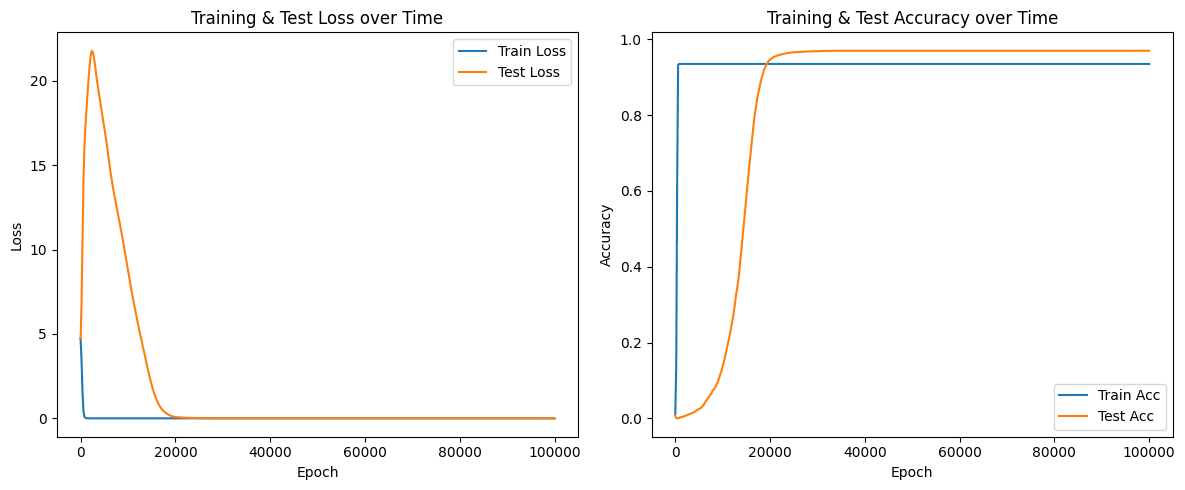
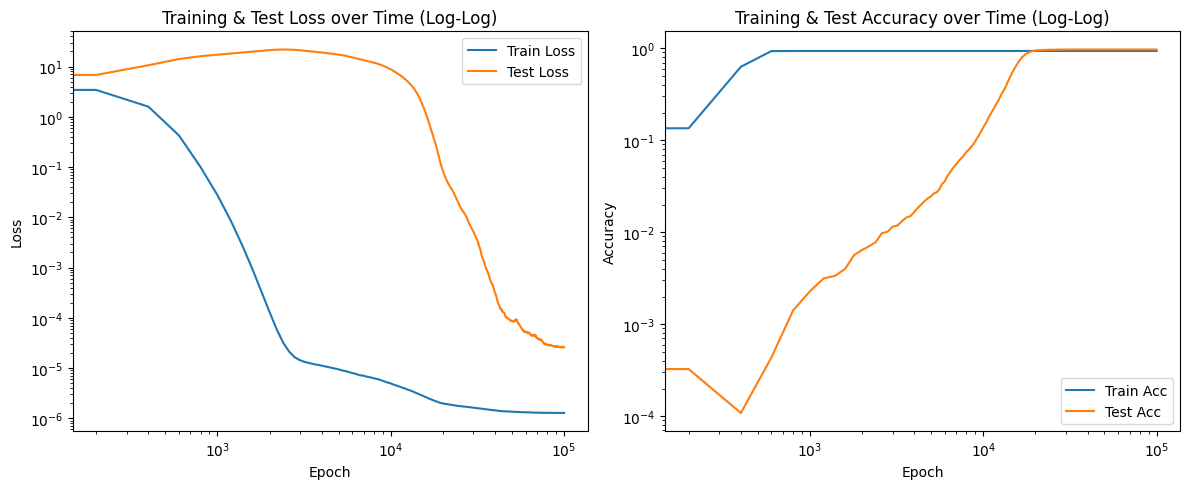
This is a typical and well studied behaviour for transformer, however we are not aware of any examples of reverse enginnered problem with observed grokking during training.
Exact formulas for what LSTM does
This section is only relevant to the methodology we used to reverse engineer the model, not understanding algorithm itself as well as clarifying all the architectural details used, so feel free to skip this section.
Below are the formulas describing all intermediate activations and operations performed by the given model architecture. The model predicts from inputs
Model Parameters and Dimensions
N = 113 (the modulo and also number of classes)
The input is a pair with
Input Encoding
We have an input sequence of length 2:
We one-hot encode each integer:
Thus:
LSTM-like Cell Parameters
We have a single-layer LSTM-like cell with parameters:
These define the input, forget, cell (g), and output gates at each timestep.
Recurrent Step
Compute gates:
which results in a vector.
Slice into four parts:
Update cell and hidden states:
However, instead of the standard LSTM update , the model uses:
Step-by-Step for Two Steps
At
At :
After these two steps, is the final hidden state for the sequence.
Final Two Linear Layers
The final output is computed by two linear layers without bias or nonlinearities:
Where:
No bias and no additional activations are applied here.
Final Output
The model’s output is the vector for each sample, which can be turned into a probability distribution via softmax.
Reverse engineering the model
Reducing the problem to simplified model
Turns out model prefers to learn way simpler structure and not use the full capability of LSTM. We find the following:
- is constant and the accuracy on the test set does not change if we replace f_t with constant vector equal to the average over the train set.
- can be replaced by tensor of ones. that does not change the accuracy.
- can be replaced by tensor of ones. that does not change the accuracy.
- after the linear layer when computing from can be removed and does not affect the accuracy ( is close to x for small values).
applied in the first cell to when computing can be removed with no accuracy drop.
Given the above the model architecture simplifies to:
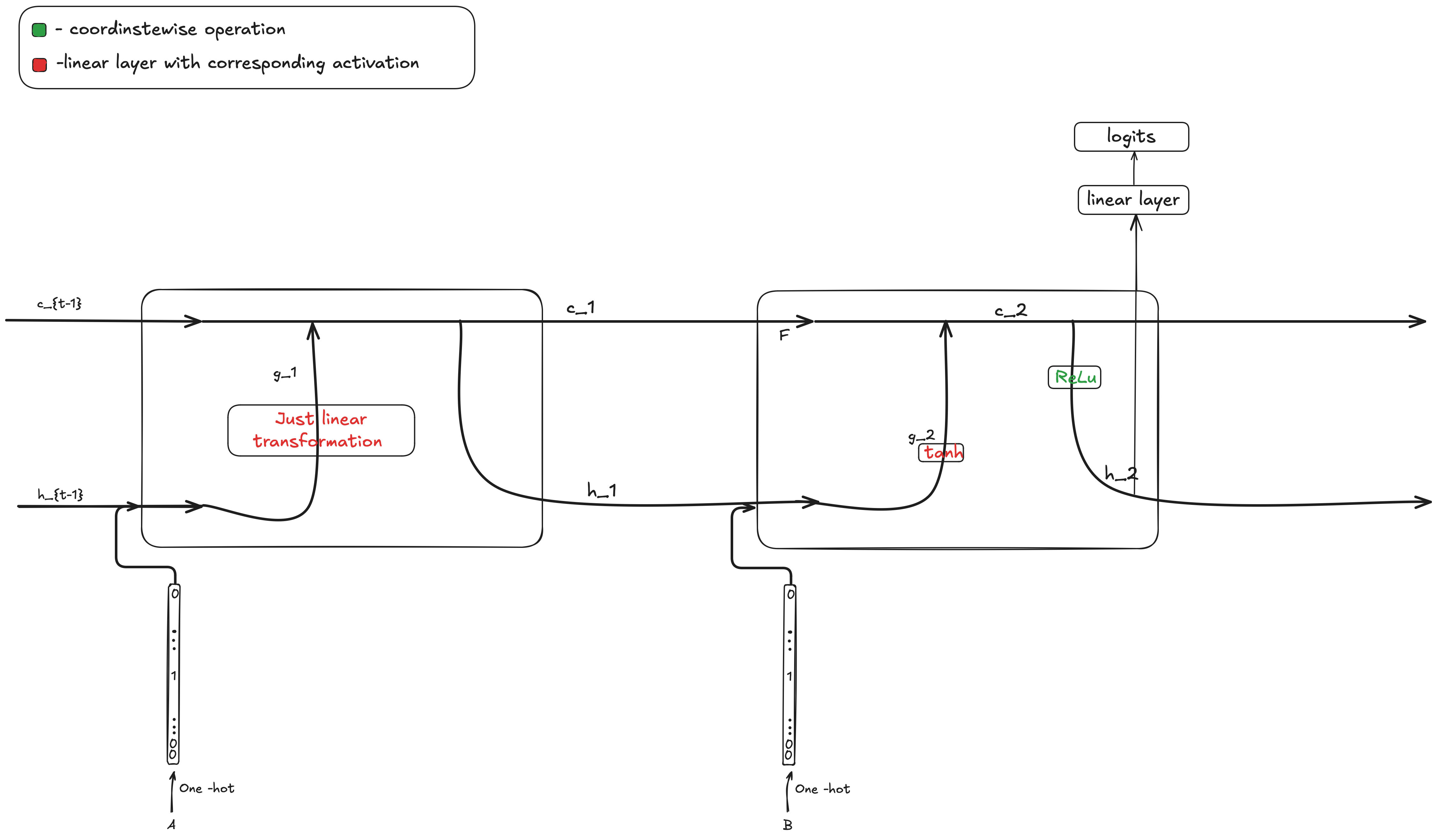
This allows us to simplify the formula for significantly:
Which can be written as
Where and are one hot encodes numbers and F is a constant .
Now we can see that the two summands are just functions of and and given those can be considered to have capacity to learn almost any representations independent of each other. Regardless of the interpretation the expression is just a sum of two vectors of dimension one of which is a function of only and second is a function of only. This suggest the idea of considering them just like a lookup table of embeddings for and , hence we do it reducing the problem for the following:
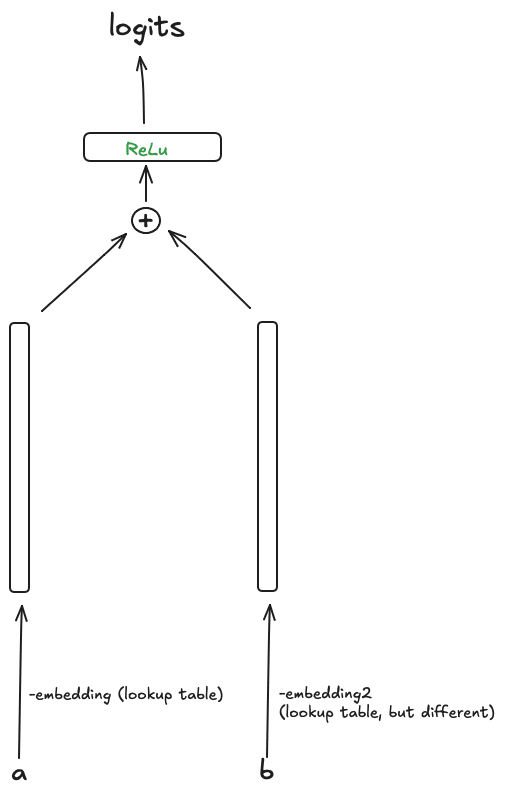
We have two different lookup tables (different or at least they have seemingly no reason to be the same based on our formula). We then take two embeddigs apply ReLU and multiply by some matrix to get logits.
The first lookup table maps
Second is
We extract all the weights from the original model only in a way described above to get a simplified model. The accuracy measured for the simplified model is only 5 percent lower than the original model hence we only need to interpret the simplified model.
An interesting observation is that if we were to train just simplified model with the same trick by breaking down the linear layer after ReLU into the product of two matrices without activation: the simplified model would also grok leaning the same algorithm but it would not grok with just one matrix. The idea why this is the case will become more clear after understanding the algorithm.
Reverse engineering simplified model
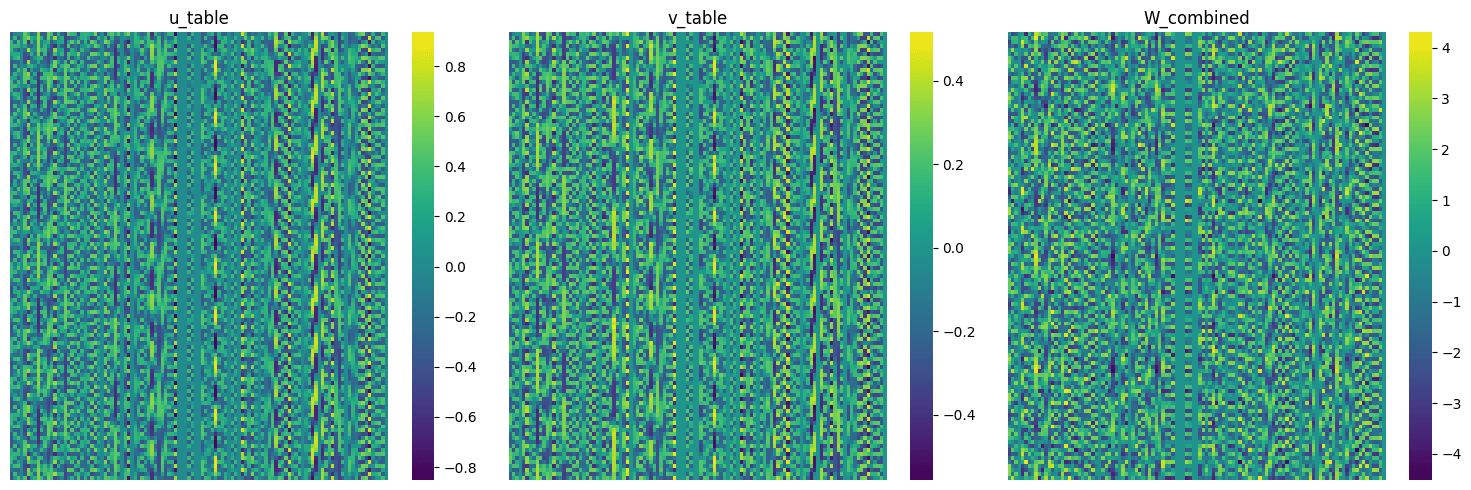
First thing we notice is that both embedding tables are highly periodic but not only that, they are almost identical and the accuracy does not drop.
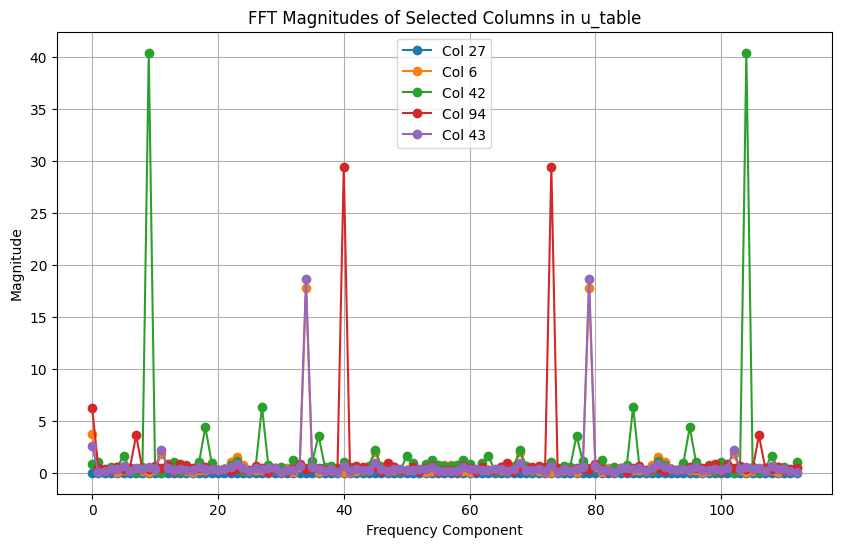
Periodicity shows up in FFT plots as well:
Interestingly, the average peak fourier magnitude over the training run looks like:
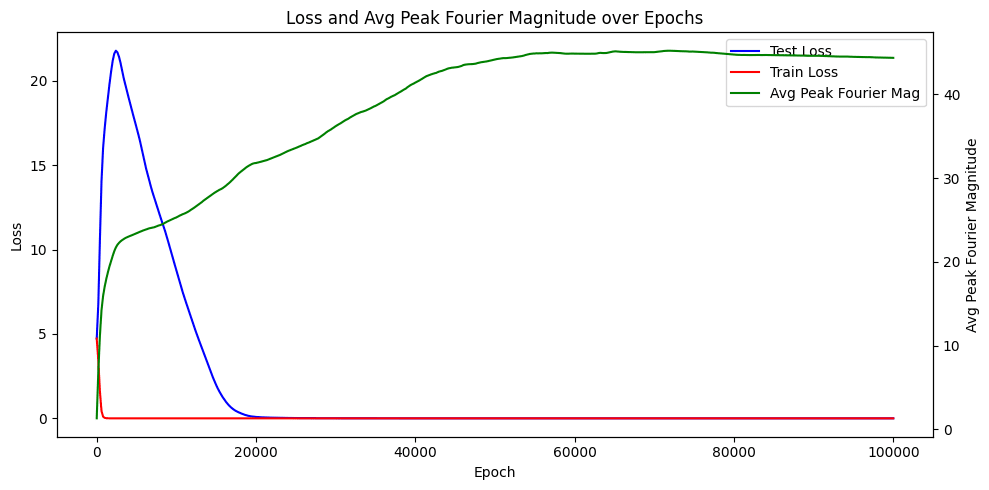
Which is explained by spasticity of frequencies used in W. Indeed, the embedding tables become periodic during the first few epochs and during the rest of the training the models learns to diversify firing activations for logits amongst many frequencies:
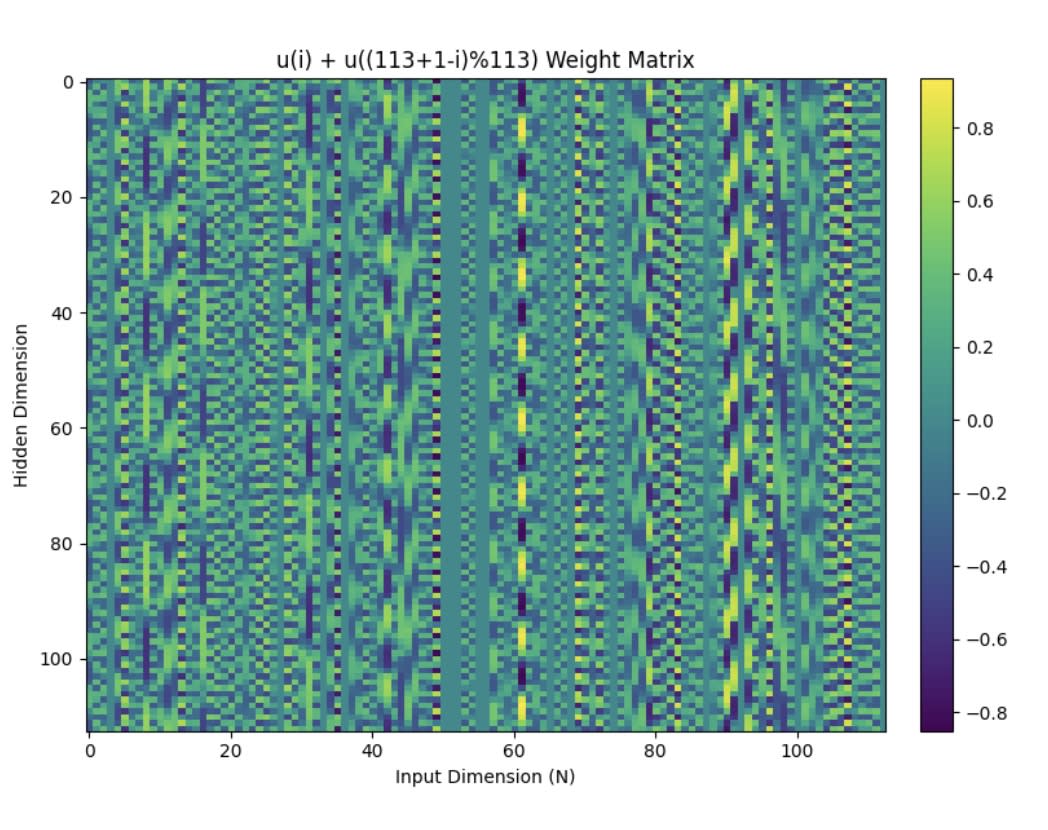
The algorithm itself
We first have to provide some facts about the embeddings we observed.
Three important points
- Each column of u is a periodic function with a non-zero magnitude only at 0 and frequancy for some (reminder: embeddings themselves are rows of u).
- For each integer modulo 113 the matrix with -th row equal to - just the sums of embeddings corresponding to pairs of integers with a particular sum, staked vertically, has highly periodic columns. Not only that, but the frequency of the -th column of matrix is the same as the frequency of matrix constructed above for
Columns of have just one dominant frequency, so highly periodic.
Below are some visualisation of the above points.



So the idea is if the columns present seem to be just a one magnitude wave, lets just write dows the formula for logits in assuming one dominant frequency and the expression for logits is not that complicated at this point.
Lets look at the logits:
Assuming observed periodicity and ignoring ReLU(which is reasonable to do because we care about periodic fucntions and as we care about scalar products of those and as matrices W and U have similar frequencies a natural thing to do is examing what is happening without ReLU)
Observe that constant term for columns of is and they have same frequancy as corresponding columns of . Now -th logit is
So after some algebra, we find that -th logit is
Now and are of similar magnitude (being and respectively) hence the two sums above sum up to a constant when is not equal to or and spans all integers from 0 to 112 and the sum is just slightly noisy sum of roots of unity. The way model distinguishes them is by finding the correct which the model has to learn for each particular sum.
Summary
We have observed that grokking and learned that the algorithm learned is still to a large extend empirical: the model has to learn those 113 values of separately and when it does the model groks. So the model chose to learn 113 parameters rather then and use the fact that (weighted) sum of roots of unity is comparatively small to the sum of 1's. This is confirmed by the fact that if we reshuffle the training data not containing particular sum, the model is more likely to get it wrong.
0 comments
Comments sorted by top scores.