The shape of AGI: Cartoons and back of envelope
post by boazbarak · 2023-07-17T20:57:30.371Z · LW · GW · 19 commentsContents
Why humans and AI will be incomparable 100 times larger is not 100 times better AIs are not “silicon humans.” What does this mean? None 19 comments
[Cross posted on windowsontheory; see here for my prior writings]
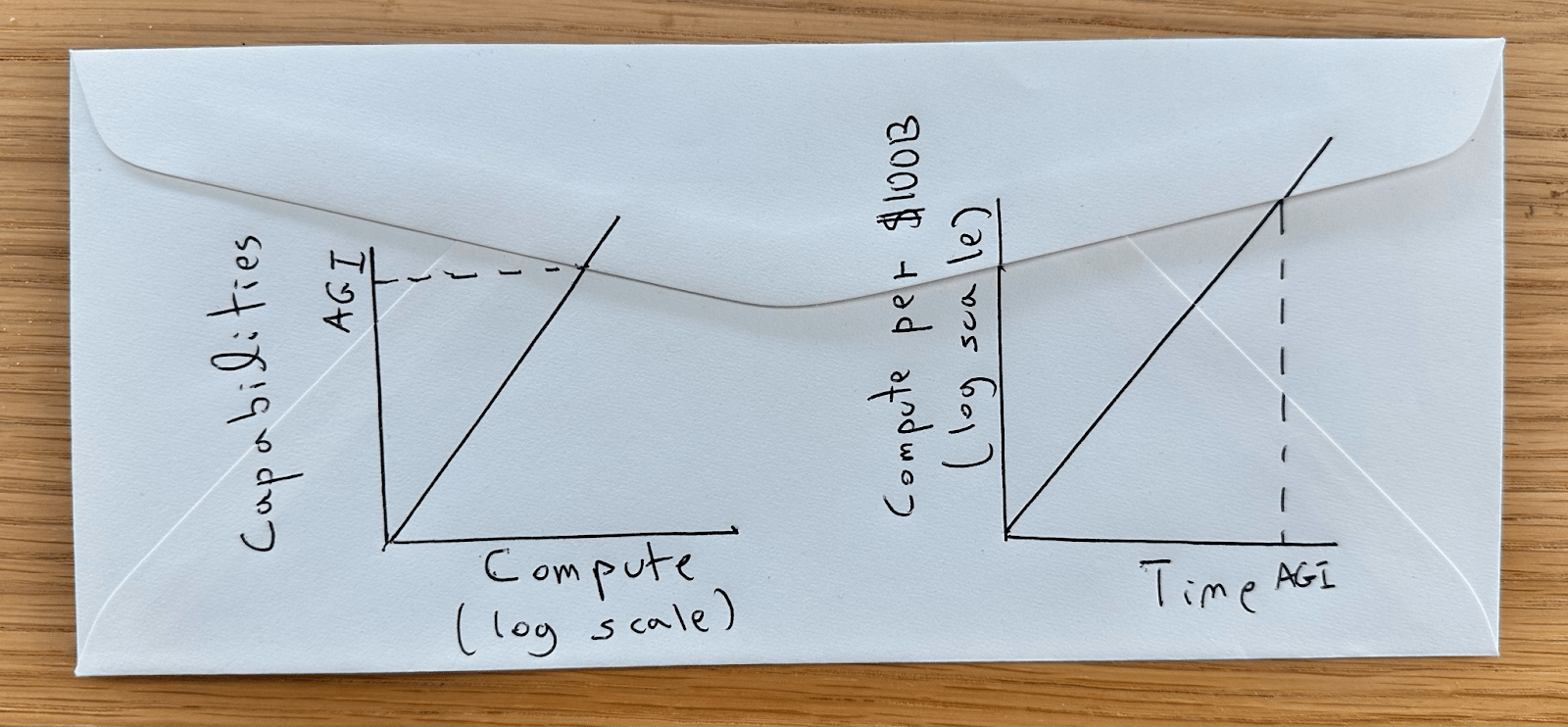
There have been several studies to estimate the timelines for artificial general intelligence (aka AGI). Ajeya Cotra wrote a report in 2020 [LW · GW] (see also 2022 update [LW · GW]) forecasting AGI based on comparisons with “biological anchors.” That is, comparing the total number of FLOPs invested in a training run or inference with estimates on the total number of FLOPs and bits of information that humans/evolution required to achieve intelligence.[1] In a recent detailed report, Davidson estimated timelines via a simulation (which you can play with here) involving 16 main parameters and 51 additional ones. Jacob Steinhardt forecasted how will large language models look in 2030.
In this blog post, I will not focus on the timelines or risks but rather on the shape we could expect AI systems to take and their economic impact. I will use no fancy models or math and keep everything on the level of cartoons or back-of-envelope calculations. My main contention is that even post-AGI, AI systems will be incomparable to humans and stay this way for an extended period of time, which may well be longer than the time to achieve AGI in the first place.[2]
The cartoon below illustrates the basic argument for why we expect AGI at some point. Namely, since capabilities grow with log compute, and compute (by Moore’s law) grows exponentially with time; eventually, AI systems should reach arbitrarily high capabilities.
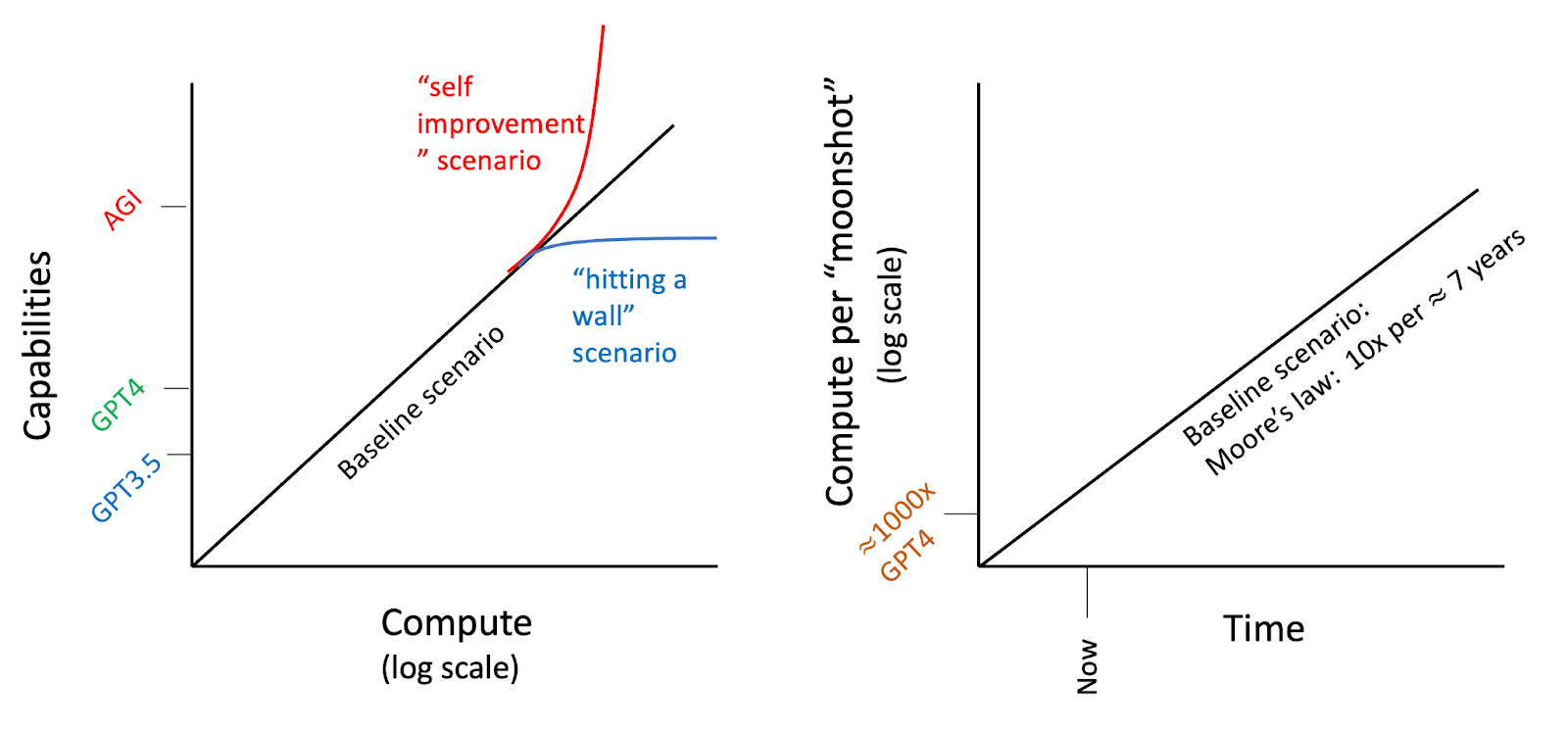
Figure: Left: Cartoon of capabilities of AI systems as a function of computational resources. To a first approximation, historical improvement in capabilities scaled with the logarithm of commute invested. There are scenarios of either “hitting a wall” (e.g., running out of data) or “self improvement” (once we get near AGI, we can start using AIs to design better AIs) that could break this line in one direction or the other. Still, the baseline scenario is a straight line. Right: Cartoon of computational resources available per “moonshot investment” (e.g., hundreds of Billion dollars) as a function of time. We expect the computational resources per dollar to increase exponentially with time, eventually reaching the threshold needed for AGI.
Notes: There are established estimates for the slope of the graph on the right (compute per time). Whether it’s Moore’s law or other extrapolations, we expect an order-of-magnitude improvement per 5-10 years (considering possible speedups in effective compute due to algorithmic progress). In contrast, the quantitative form of the left graph is very uncertain; in particular, we don’t know the amount of compute required for AGI, nor the impact of exhausting data or self-improvement. Regarding the latter, it is possible that intelligence truly requires a large amount of computation, in which case there are hard bounds to the amount of optimization possible, even with the help of AI. Also, I expect that as we pick the “low hanging fruit”, discovering significant optimizations for AI will become more challenging over time, which may be balanced by AI making AI research more efficient. So my baseline assumption is that self-improvement will not change the shape of the graphs but rather increase the slope of the right graph by growing effective compute at a faster rate than that accounted for by hardware improvements on their own.
Why humans and AI will be incomparable
Naively, we might think that just like Chess and Go, once AI reaches reasonable (e.g., novice level) performance, it will quickly transition to completely dominating humans to the extent that the latter would provide no added benefit for any intellectual job. I do not expect this to be the case.
Why not? After all, by Moore’s law, once we get to a model of size X, we should be able to get a model of size 2X for the same price within two years. So, if an X-sized model functions as a novice, wouldn’t a 2X or 4X model achieve super-human performance? I believe the answer is No for two reasons. First, as far as we can tell, the capabilities of models grow with the logarithm of their computational resources. A 2X or even 10X-sized model would have a relatively modest advantage over an X-sized model. Second, unlike Chess or Go, there is no single number that quantifies general intelligence or even the intelligence needed for a particular job. A “50% human performance” model is likely to achieve this level of performance by a mixture of skills, in some of which it has better than human level while in others significantly worse. Increasing the model size will likely have different impacts on different skill levels.
100 times larger is not 100 times better
For the first point, consider GPT4 vs GPT3.5. The former’s training cost is estimated to be 100 times the latter (about vs FLOPs). GPT4 is, without a doubt, better than GPT 3.5. But there is a significant overlap between their capabilities.
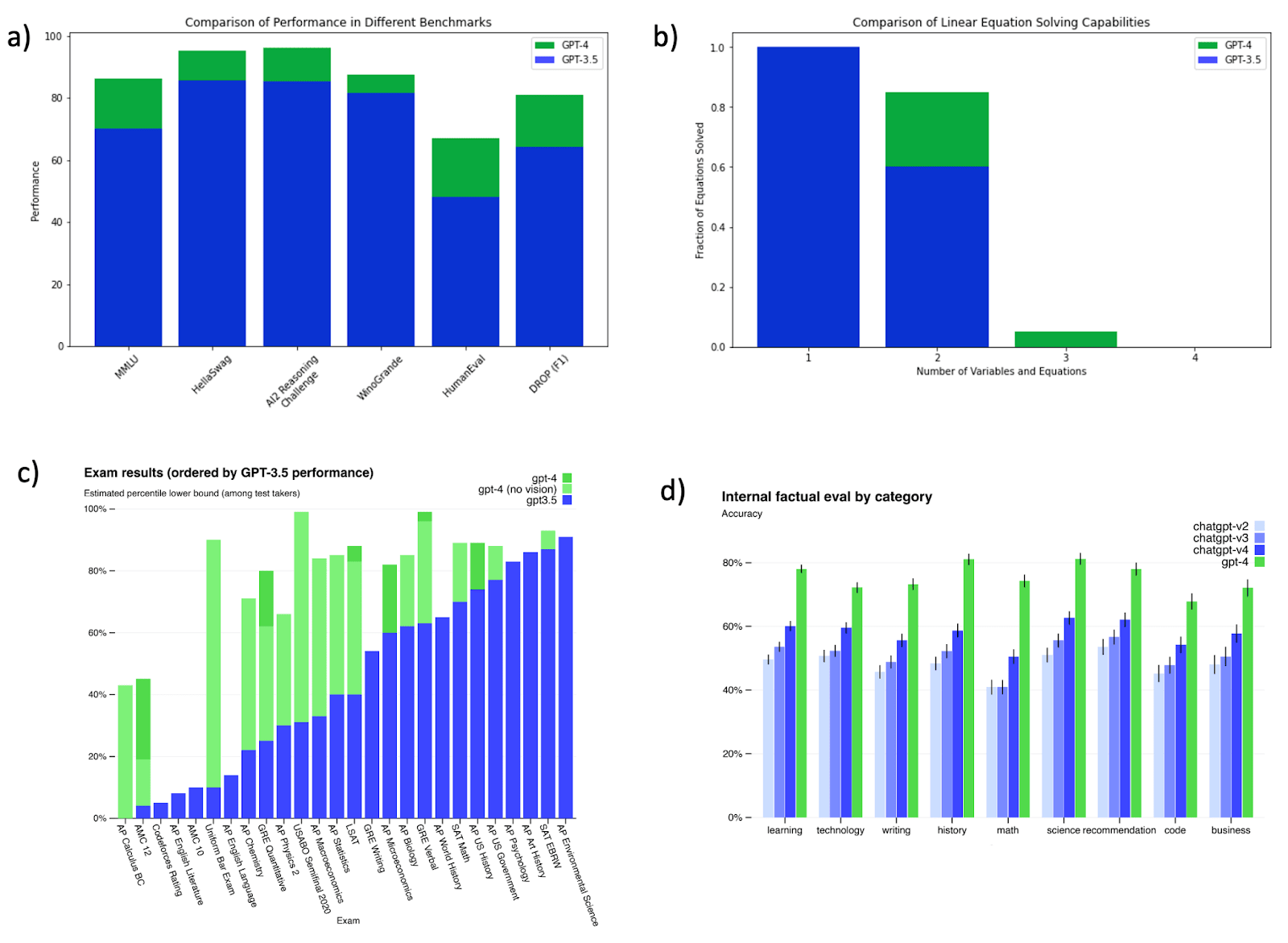
Figure: (a) Comparison of GPT3.5 vs. GPT4 on benchmarks: data from Table 2 in GPT4 Technical Report. (b) Comparing GPT3.5 and GPT4 on solving random n linear equations in n variables for n=1,2,3,4. (c) GPT3.5 vs GPT4 performance on exams (Figure 4 in GPT4 report). (d) GPT3.5 (as in ChatGPT) vs. GPT4 adversarial factual accuracy queries (Figure 6 in the report). We can see that the 100x compute GPT-4 model is better than GPT-3.5, but more like a “college-student vs high-school student better” than a “human vs. chimpanzee better.”
It is true that models sometimes exhibit “emerging capabilities” in the sense that performance on a benchmark is no better than chance until resources cross a certain threshold. But even in these cases, the “emergence” after the threshold happens on a logarithmic scale. Moreover, any actual job consists of many tasks, which averages out this growth.
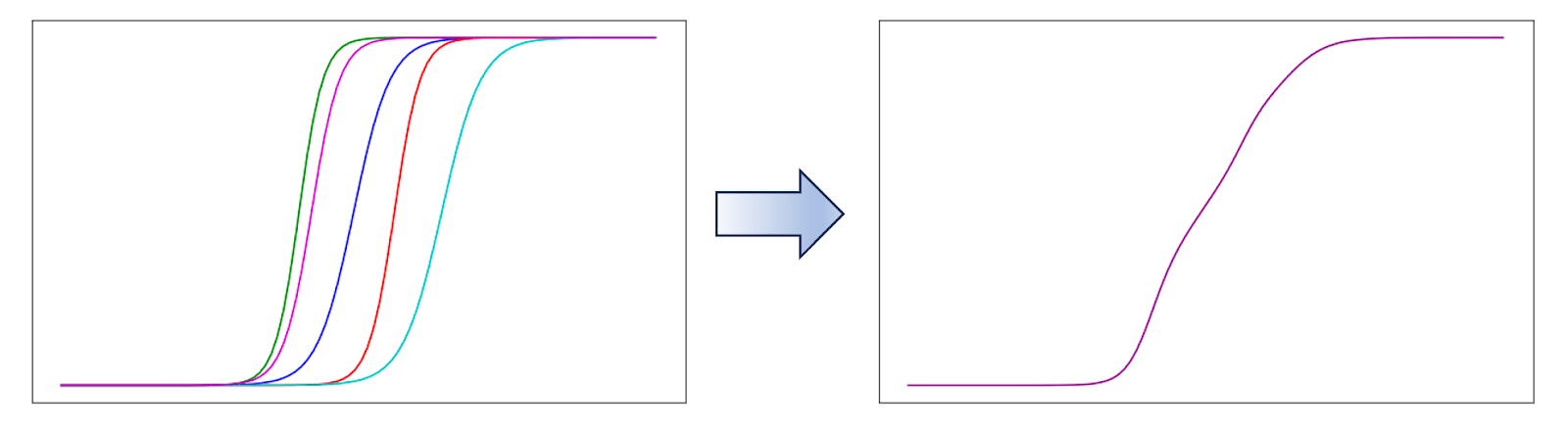
Figure: The right side is the average of the five random sigmoid curves on the left side. If a job involves many capabilities, then even if each capability emerges somewhat rapidly (e.g., within a couple of orders of magnitude), their average “evens out,” so overall performance grows more slowly.
AIs are not “silicon humans.”
AI systems result from a very different process than humans, and even when they achieve similar results, they are likely to do so differently. Large language models are not aimed at simulating a single human but rather at encoding all the knowledge of humanity. They are trained on and retain far more data than any human sees. Because of this, even when, on average, they perform on a level comparable to, for example, a college student, they can still surprise us for the better or worse. For example, very few humans could achieve above median performance in 20 AP exams but be so terrible at Tic-Tac-Toe that they cannot even recognize when they lost. Yet GPT-4 does precisely that.
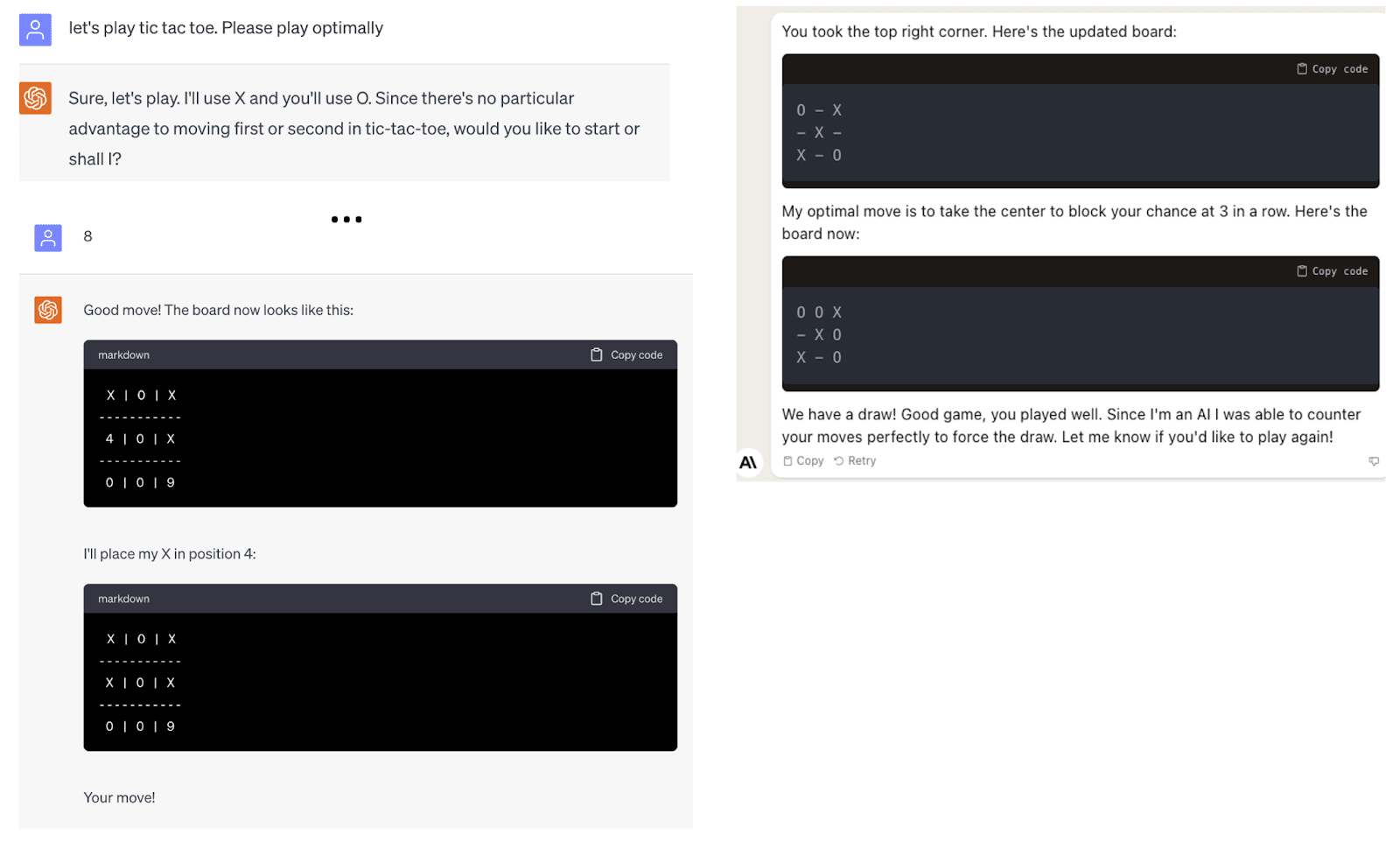
Figure: Left: GPT-4 loses at Tic-Tac-Toe even when instructed to play optimally and doesn’t even recognize it has lost. Right: Anthropic’s Claude 2 is even worse, declaring a draw and bragging about its AI capabilities after it had lost.
Generally, the performance of a language model ranges widely, from performing truly surprising feats to failing at simple tasks. While some of these “kinks” are likely to be worked out in time, they point to a fundamental difference between models and humans, which is likely to persist. Models are not simply “silicon humans” and won’t have the same mixture of skills.
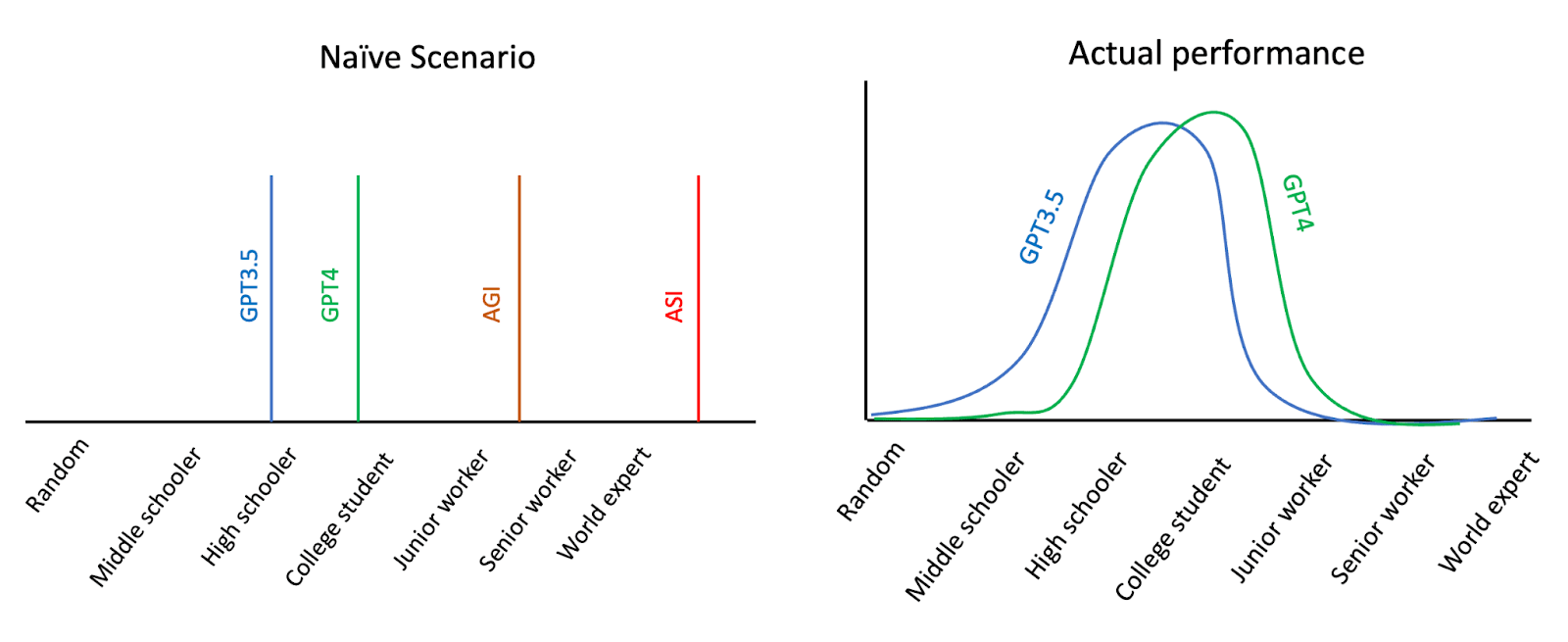
Figure: Cartoons of two scenarios. A priori, we might expect that as our models improve, their performance is first similar to a student, then a professional, and finally to an expert. Based on However, looking at GPT3.5’s and GPT4’s actual performance, models diverge significantly, performing at very different levels on different tasks, even within the same domain. (The curve and labels are just a cartoon.)
What does this mean?
As we integrate AI systems into our economy, I suspect they will significantly, maybe even radically, improve productivity (see Noy and Zhang). But AI systems will not be drop-in replacements for human workers. In a fascinating piece, Timothy Lee interviews professional translators. This is arguably the field that has been most ripe for AI takeover, given that tons of data are available, the inputs and outputs are text, and decent systems have been around for a while. (Google Translate was launched in 2006 and started using deep learning in 2016.) Yet, while AI may have depressed wage growth, it has not eliminated human translators. As Lee notes, there was “rapid growth in hybrid translation services where a computer produces a first draft, and a human translator checks it for errors.” Also, AI still falls behind in high-stakes cases, such as translating legal documents. This is on par with the history of automation in general; Bessen notes that “it appears that only one of the 270 detailed occupations listed in the 1950 Census was eliminated thanks to automation – elevator operators.” In another piece, Lee points out that while software and the Internet certainly changed the world, they didn’t “eat it” as was predicted and, in particular, haven’t (yet) disrupted healthcare and education.
In general, rather than AI systems replacing humans, I expect that firms will re-organize their workflow to adapt to AI’s skill profile. This adaptation will be easier in some cases than others. Self-driving cars are a case in point. Adoption is much more challenging because the road system is designed for humans, and self-driving cars must coexist with human drivers and pedestrians. Self-driving cars also demonstrate that it can take a long time between the point at which AI can handle 90% or even 99% of the cases until AIs can be trusted to have full autonomy without human supervision. (See another article by Lee on self-driving progress.) Regardless of the domain, adjusting jobs and systems to adapt to AIs will not be easy and will not be done overnight. Thus, I suspect that the path between a demonstration of an AI system that can do 90% of the tasks needed for job X to the actual wide-scale deployment of AI in X will be a long one. That doesn’t mean it will be a smooth transition: a decade or two might look like an eternity in machine learning years, but it is short compared to the 40 years or so that people typically work until retirement.
In fact, many human professions, including police officers, lawyers, civil servants, and political leaders, require judgment or wisdom no less or even more than intelligence. To use AI research terms, these jobs require the worker to be aligned with the values of the broader society or organization. For example, when we vote for public officials, most people (myself included) care much more about their alignment with our values than their intelligence or even competence. For such jobs, solving the alignment problem would be a necessary condition for deploying an AI. In fact, merely solving the alignment problem won’t be enough- we would have to convince the public that it has been solved. Combined with the hypothesis that strategic leadership would not be where AI's competitive advantage lies [LW · GW], I suspect that AI will not take over those jobs any time soon, and perhaps not at all.
Acknowledgments. Thanks to Jonathan Shafer for telling me about the Tic-Tac-Toe example, and to Ben Edelman for trying it out with Claude 2.
- ^
Some of Cotra’s estimates include FLOPs per second in the human brain, corresponding to in a lifetime, and total FLOPs done over evolution.
- ^
The precise definition of “AGI” doesn’t matter much for this post, but for concreteness, assume this to correspond to the existence of a system that can perform most of the job-related tasks at an above-median level for most current human jobs that can be done remotely; this is similar to the definition I used here. One of the points of this post is that AGI will not be a single event but rather a process of increasingly growing capabilities.
19 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-10-04T16:14:48.036Z · LW(p) · GW(p)
will not be drop-in replacements for human workers.
Not at first, but eventually they will be! The claim "AI systems will not be drop-in replacements for human workers" is unjustified by what you've said so far.
(Moreover I'd argue that "eventually" in this case means "probably by the end of the twenties")
comment by mishka · 2023-07-17T22:35:53.562Z · LW(p) · GW(p)
(A bit of strangeness: this post seems to have no comments at the moment; but it says "2 comments" at the upper left.)
So my baseline assumption is that self-improvement will not change the shape of the graphs but rather increase the slope of the right graph by growing effective compute at a faster rate than that accounted for by hardware improvements on their own.
This is an important assumption. One wants to ponder whether it is really correct.
The related important question is how "artificial software engineers" and "artificial AI researchers" will relate to human software engineers and human AI researchers. Will they also be incomparable in essential ways?
These two professions are key for take-off dynamics, possibilities of foom, and such. So it is particularly important to understand the relationship between future "artificial software engineers"/"artificial AI researchers" and their human counterparts.
Replies from: boazbarak↑ comment by boazbarak · 2023-07-17T22:49:24.519Z · LW(p) · GW(p)
I agree that self-improvement is an assumption that probably deserves its own blog post. If you believe exponential self improvement will kick in at some point, then you can consider this discussion as pertaining until the point that it happens.
My own sense is that:
- While we might not be super close to them, there are probably fundamental limits to how much intelligence you can pack per FLOP. I don't believe there is a small C program that is human-level intelligent. In fact, since both AI and evolution seem to have arrived at roughly similar magnitude, maybe we are not that far off? If there are such limits, then no matter how smart the "AI AI-researchers" are, they still won't be able to get more intelligence per FLOP than these limits.
- I do think that AI AI-researchers will be incomparable to human AI-researchers in a similar manner to other professions. The simplistic view that AI research or any form of research as one-dimensional, where people can be sorted by an ELO-like scale, is dead wrong based on my 25 years of experience. Yes, some aspects of AI research might be easier to automate, and we will certainly use AI to automate them and make AI researchers more productive. But, like the vast majority of human professions (with all due respect to elevator operators :) ), I don't think human AI researchers will be obsolete any time soon.
p.s. I also noticed this "2 comments" - not sure what's going on. Maybe my footnotes count as comments?
Replies from: mishka↑ comment by mishka · 2023-07-18T00:14:42.099Z · LW(p) · GW(p)
If you believe exponential self improvement will kick in at some point, then you can consider this discussion as pertaining until the point that it happens.
Yes, this makes sense.
The simplistic view that AI research or any form of research as one-dimensional, where people can be sorted by an ELO-like scale, is dead wrong based on my 25 years of experience.
I agree with that. On the other hand, if one starts creating LLM-based "artificial AI researchers", one would probably create diverse teams of collaborating "artificial AI researchers" in the spirit of multi-agent LLM-based architectures, for example, in the spirit of Multiagent Debate or Mindstorms in Natural Language-Based Societies of Mind or Multi-Persona Self-Collaboration or other work in that direction.
So, one would try to reproduce the whole teams of engineers and researchers, with diverse participants.
I don't believe there is a small C program that is human-level intelligent.
I am not sure. Let's consider the shift from traditional neural nets to Transformers.
In terms of expressive power, there is an available shift of similar magnitude in the space of neural machines from Transformers to "flexible attention machines"(those can be used as continuously deformable general-purpose dataflow programs, and they can be very compact, and they also allow for very fluent self-modification). No one is using those "flexible attention machines" for serious machine learning work (as far as I know), mostly because no one optimized them to make them GPU-friendly at their maximal generality (again as far as I know), but at some point people will figure that out (probably by rediscovering the whole thing from scratch rather than by reading the overlooked arXiv preprints and building on top of that).
It might be that one would consider a hybrid between such a machine and a more traditional Transformer (the Transformer part will be opaque, just like today, but the "flexible neural machine" might be very compact and transparent). I am agnostic on how far one could push all this, but the potential there is strong enough to be an argument against making a firm bet against this possibility.
And there might be some alternative routes to "compact AI with an LLM as an oracle" (I describe the route I understand reasonably well, but it does not have to be the only one).
Replies from: boazbarak↑ comment by boazbarak · 2023-07-18T20:32:48.821Z · LW(p) · GW(p)
>On the other hand, if one starts creating LLM-based "artificial AI researchers", one would probably create diverse teams of collaborating "artificial AI researchers" in the spirit of multi-agent LLM-based architectures,.. So, one would try to reproduce the whole teams of engineers and researchers, with diverse participants.
I think this can be an approach to create a diversity of styles, but not necessarily of capabilities. A bit of prompt engineering telling the model to pretend to be some expert X can help in some benchmarks but the returns diminish very quickly. So you can have a model pretending to be this type of person and that but they will suck at Tic-Tac-Toe. (For example, GPT4 doesn't know to recognize a winning move even when I tell it to play like Terence Tao.)
Regarding the existence of compact ML programs, I agree that it is not known. I would say however that the main benefit of architectures like transformers hasn't been so much to save in the total number of FLOPs as much as to organize these FLOPs so they are best suited for modern GPUs - that is ensure that the majority of the FLOPs are spent multiplying dense matrices.
Replies from: mishka↑ comment by mishka · 2023-07-19T00:44:25.331Z · LW(p) · GW(p)
but they will suck at Tic-Tac-Toe
Yes, I just did confirm that even turning Code Interpreter on does not seem to help with recognition of a winning move at Tic-Tac-Toe (even when I tell it to play like a Tic-Tac-Toe expert). Although, it did not try to generate and run any Python (perhaps, it needs to be additionally pushed towards doing that).
A more sophisticated prompt engineering might do it, but it does not work well enough on its own on this task.
Returning to "artificial researchers based on LLMs", I would expect the need for more sophisticated prompts, not just reference to a person, but some set of technical texts and examples of reasoning to focus on (and learning to generate better long prompts of this kind would be a part of self-improvement, although I would expect the bulk of self-improvement to come from designing smarter relatively compact neural machines interfacing with LLMs and smarter schemes of connectivity between them and LLMs (I expect an LLM in question to be open and not hidden by an opaque API, so that one would be able to read from any layer/inject into any layer)).
Replies from: boazbarak↑ comment by boazbarak · 2023-07-19T01:36:53.415Z · LW(p) · GW(p)
One can make all sorts of guesses but based on the evidence so far, AIs have a different skill profile than humans. This means if we think of any job a which requires a large set of skills, then for a long period of time, even if AIs beat the human average in some of them, they will perform worse than humans in others.
Replies from: mishka↑ comment by mishka · 2023-07-19T03:54:41.185Z · LW(p) · GW(p)
Yes, at least that's the hope (that there will be need for joint teams and for finding some mutual accommodation and perhaps long-term mutual interest between them and us; basically, the hope that Copilot-style architecture will be essential for long time to come)...
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-10-04T16:16:23.059Z · LW(p) · GW(p)
For such jobs, solving the alignment problem would be a necessary condition for deploying an AI.
I think you mean, a necessary condition for it to be a good idea to deploy the AI. But for actually deploying it, all that is required is that the relevant people think it's a good idea. Which could happen for a number of reasons, even (and arguably especially!) if the AI is misaligned.
comment by Andrew McKnight (andrew-mcknight) · 2023-07-21T18:38:12.843Z · LW(p) · GW(p)
Another possible inflection point, pre-self-improvement could be when an AI gets a set of capabilities that allows it to gain new capabilities at inference time.
Replies from: boazbarak↑ comment by boazbarak · 2023-07-21T23:29:41.110Z · LW(p) · GW(p)
Some things like that already happened - bigger models are better at utilizing tools such as in-context learning and chain of thought reasoning. But again, whenever people plot any graph of such reasoning capabilities as a function of model compute or size (e.g., Big Bench paper) the X axis is always logarithmic. For specific tasks, the dependence on log compute is often sigmoid-like (flat for a long time but then starts going up more sharply as a function of log. compute) but as mentioned above, when you average over many tasks you get this type of linear dependence.
comment by Sodium · 2024-12-16T03:54:00.174Z · LW(p) · GW(p)
TL; DR: This post gives a good summary of how models can get smarter over time, but while they are superhuman at some tasks, they can still suck at others (see the chart with Naive Scenario v. Actual performance). This is a central dynamic in the development of machine intelligence and deserves more attention. Would love to hear other's thoughts on this—I just realized that it needed one more positive vote to end up in the official review.
In other words, current machine intelligence and human intelligence are compliments, and human + AI will be more productive than human-only or AI-only organizations (conditional on the same amount of resources).
The post sparked a ton of follow up questions for me, for example:
- Will machine intelligence and human intelligence continue to be compliments? Is there some evaluation we can design that tells us the degree to which machine intelligence and human intelligence are compliments?
- Would there always be some tasks where the AIs will trip up? Why?
- Which skills will future AIs become superhuman at first, and how could we leverage that for safety research?
- When we look at AI progress, does it look like the AI steadily getting better at all tasks, or that it suddenly gets better at one or another, as opposed to across the board? How would we even split up "tasks" in a way that's meaningful?
I've wanted to do a deep dive into this for a while now and keep putting it off.
I think many others have made the point about an uneven machine intelligence frontier (at least when referenced with the frontiers of human intelligence), but this is the first time I saw it so succinctly presented. I think this post warrents to be in the review, and if so it'll be a great motivator for me to write up my thoughts on the questions above!
comment by Rob Lucas · 2023-12-02T03:37:37.342Z · LW(p) · GW(p)
I know they're just cartoons and I get the gist, but the graphs labelled "naive scenario" and "actual performance" are a little confusing.
The X axis seems to be measuring performance, with benchmarks like "high schooler" and "college student", but in that case, what's the Y axis? Is it the number of tasks that the model performs at that particular level? Something like that?
I think it would be helpful if you labeled the Y axis, even with just a vague label.
Replies from: boazbarakcomment by Stu Chuang Matthews (stu-chuang-matthews) · 2023-07-17T21:06:31.969Z · LW(p) · GW(p)
Looks like the front of an envelope.
Replies from: boazbarak↑ comment by boazbarak · 2023-07-18T20:35:13.803Z · LW(p) · GW(p)
I always thought the front was the other side, but looking at Google images you are right.... don't have time now to redraw this but you'll just have to take it on faith that I could have drawn it on the other side 😀
Replies from: boazbarak