Competitive Markets as Distributed Backprop
post by johnswentworth · 2018-11-10T16:47:37.622Z · LW · GW · 10 commentsContents
Backpropagation Price Theory Footnotes None 10 comments
Requisite background: high school level programming and calculus. Explanation of backprop is included, skim it if you know it. This was originally written as the first half of a post on organizational scaling, but can be read standalone.
Backpropagation
If you’ve taken a calculus class, you’ve probably differentiated functions like . But if you want to do math on a computer (for e.g. machine learning) then you’ll need to differentiate functions like
function f(x): # Just wait, the variable names get worse…
a = x^(1/2) # Step 1
b = 1–1/(a+1) # Step 2
c = ln(b) # Step 3
return cThis is a toy example, but imagine how gnarly this could get if contains loops or recursion! How can we differentiate , without having to write it all out in one line? More specifically, given the code to compute , how can we write code to compute ? The answer is backpropagation. We step through the function, differentiating it line-by-line, in reverse. At each line, we compute the derivative with respect to one of the internal variables. As we work back, we differentiate with respect to earlier and earlier variables until we reach x itself.
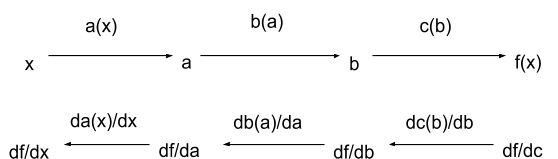
The key to backprop is the chain rule. Look the bottom left arrow: . That’s just the chain rule! A similar formula applies to each arrow in the bottom row.
Let’s work through the example. Keep an eye on the diagram above to see where we are as we go. First, we differentiate the last line:
return c: df_dc = 1Then, we work backward:
Step 3: c = ln(b) -> df_db = df_dc * dc_db = df_dc ∗ (1/b) Notice what happened here: we used the chain rule, and one of the two pieces to come out was — the result of the previous step. The other piece is the derivative of this particular line. Continuing:
Step 2: b = 1–1/(a+1) -> df_da = df_db * db_da = df_db ∗ (1/(a+1)^2)
Step 1: a = x^(1/2) -> df_dx = df_da * da_dx = df_da ∗ (1/2*x^(−1/2)) Each step takes the result of the previous step and multiplies it by the derivative of the current line. Now, we can assemble it all together into one function:
function df_dx(x):
a = x^(1/2) # Step 1
b = 1–1/(a+1) # Step 2
c = ln(b) # Step 3
df_dc = 1
df_db = df_dc * 1/b # df_dc times derivative of step 3
df_da = df_db * (1/(a+1)^2) # df_db times derivative of step 2
df_dx = df_da * (1/2*x^(-1/2)) # df_da times derivative of step 1 return df_dxThe name “backpropagation” derives from the df_d* terms, which “propagate backwards” through the original function. These terms give us the derivative with respect to each internal variable.¹ In the next section, we’ll relate this to intermediate prices in supply chains.
Price Theory
Suppose we have a bunch of oversimplified profit-maximizing companies, each of which produces one piece in the supply chain for tupperware. So, for instance:
- Company A produces ethylene from natural gas
- Company B produces plastic (polyethylene) from ethylene
- Company C molds polyethylene into tupperware
We’ll give each company a weird made-up production function:
- Company A can produce units of ethylene from units of natgas
- Company B can produce units of polyethylene from units of ethylene
- Company C can produce units of tupperware from units of polyethylene
You may notice that these weird made-up cost functions look suspiciously similar to steps 1, 2 and 3 in our function from the previous section. Indeed, from the previous section tells us how much tupperware can be made from a given amount of natgas: we compute how much ethylene can be made from the natgas (step 1, company A), then how much polyethylene can be made from the ethylene (step2, company B), then how much tupperware can be made from the polyethylene (step 3, company C).
Each company wants to maximize profit. If company 3 produces units of tupperware (at unit price ) from units of polyethylene (unit price ), then their profit is : value of the tupperware minus value of the polyethylene. In order to maximize that profit, we set the derivative to zero, then mutter something about KKT and pretend to remember what that means:
Company C: We’ve assumed competitive markets here: no single company is large enough to change prices significantly, so they all take prices as fixed when maximizing profit. Then, at a whole-industry-level, the above formula lets us compute the price of polyethylene in terms of the price of tupperware.
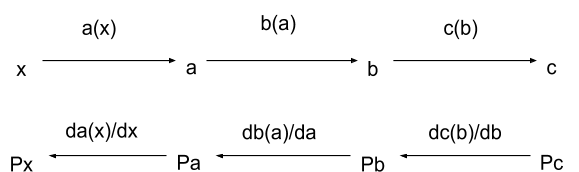
Compute prices just like derivatives.
Well, now we can work back up the supply chain. Maximize profit for company B, then company A:
Company B:
Company A: Notice that these formulas are exactly the same as the formulas we used to compute in the previous section. Just replace by , by , etc — the price of the intermediate good is just the derivative of the production function with respect to that good. (Actually, the price is proportional to the derivative, but it’s equal if we set the price of tupperware to 1 — i.e. price things in tupperware rather than dollars.)
So the math is the same, but how physically realistic is this picture? So far we've assumed that the market is at equilibrium, which makes it tricky to assign causality. The causality of backprop does apply directly if the final output (tupperware in our example) is perfectly elastic, meaning that it always has the exact same price. But more generally, once we look at out-of-equilibrium markets, the behavior isn't just distributed backpropagation - it's an unusual variant of gradient descent. It's using local information to move in a general "downhill" direction.
To sum it all up: we can think of profit-maximizing firms in a competitive market at equilibrium as a distributed backpropagation algorithm. Each firm “backpropagates” price information from their output prices to their input prices. This isn't always a perfect reflection of physical causality, but it does match the math for markets at equilibrium.
Footnotes
¹In ML we usually have multiple inputs, in which case we compute the gradient. Other than single-variable, I’ve also simplified the example by only reading each variable in one line, strictly sequentially — otherwise we sometimes need to update the derivatives in place. All of this also carries over to price theory, for supply chains with multiple inputs which can be used in multiple ways.
[UPDATE Dec 2019: removed a couple comments toward the end about a future post which I never got around to writing, and replaced them with a few sentences on out-of-equilibrium markets. Someday I will learn not to promise posts which I have not yet written.]
10 comments
Comments sorted by top scores.
comment by johnswentworth · 2019-12-12T00:17:48.690Z · LW(p) · GW(p)
There are two separate lenses through which I view the idea of competitive markets as backpropagation.
First, it's an example of the real meat of economics. Many people - including economists - think of economics as studying human markets and exchange. But the theory of economics is, to a large extent, general theory of distributed optimization. When we understand on a gut level that "price = derivative", and markets are just implementing backprop, it makes a lot more sense that things like markets would show up in other fields - e.g. AI or biology.
Second, competitive markets as backpropagation is a great example of the power of viewing the world in terms of DAGs (or circuits). I first got into the habit of thinking about computation in terms of DAGs/circuits when playing with generalizations of backpropagation, and the equivalence of markets and backprop was one of the first interesting results I stumbled on. Since then, I've relied more and more on DAGs (with symmetry) as my go-to model of general computation.
Dangling Threads
The most interesting dangling thread on this post is, of course, the extension to out-of-equilibrium markets. I had originally promised a post on that topic, but I no longer intend to ever write that post: I have generally decided to avoid publishing anything at all related to novel optimization algorithms. I doubt that simulating markets would be a game-changer for optimization in AI training, but it's still a good idea to declare optimization off-limits in general, so that absence of an obvious publication never becomes a hint that there's something interesting to be found.
A more subtle dangling thread is the generalization of the idea to more complex supply chains, in which one intermediate can be used in multiple ways. Although I've left the original footnote in the article, I no longer think I know how to handle non-tree-shaped cases. I am quite confident that there is a way to integrate this into the model, since it must hold for "price=derivative" to hold, and I'm sure the economists would have noticed by now if "price=derivative" failed in nontrivial supply chain models. That said, it's nontrivial to integrate into the model: if a program reads the same value in two places, then both places read the same value, whereas if two processes consume the same supply-chain intermediate, then they will typically consume different amounts which add up to the amount produced. Translating a program into a supply chain, or vice versa, thus presumably requires some nontrivial transformations in general.
comment by Bird Concept (jacobjacob) · 2019-12-02T15:11:44.094Z · LW(p) · GW(p)
People sometimes make grand claims like "system X is basically just Y" (10-sec off-the-cuff examples: "the human brain is just a predictive processing engine", "evolution is just an optimisation algorithm", "community interaction is just a stag hunt", "economies in disequilibrium is just gradient descent"...)
When I first saw you mention this in a comment on one my posts [LW · GW], I felt a similar suspicion as I usually do toward such claims.
So, to preserve high standards in an epistemic community, I think it's very valuable to actually write up the concrete, gears-like models behind claims like that -- as well as reviewing those derivations at a later time to see if they actually support the bold claim.
___
Separately, I think it's good to write-up things which seem like "someone must have thought of this" -- because academia might have a "simplicity tax", where people avoiding clearly explaining such things since it might make them look naïve.
___
For the record, I have not engaged a lot with this post personally, and it has not affected my own thinking in a substantial way.
comment by ryan_b · 2018-11-12T15:19:50.263Z · LW(p) · GW(p)
There are a few things I like about this.
- Not assigning prices out of the gate makes it more obvious that this could be used for things like energy/resource consumption directly. Lately this has been of interest to me.
- Do non-equilibrium markets as gradient descent imply that this method could be used to determine in what way the market is out of equilibrium? If the math sticks well, a gradient can contain a lot more information than the lower/higher price expectation I usually see.
- It seems like applying this same logic inside the firm should be possible, and so if we use price and apply recursively we could get a fairly detailed picture; I don't see any reason the gradient trick wouldn't apply to the labor market as well, for example.
↑ comment by johnswentworth · 2018-11-12T18:14:12.582Z · LW(p) · GW(p)
The original piece continues where this post leaves off to discuss how this logic applies inside the firm. The main takeaway there is that most firms do not have competitive internal resource markets, so each part of the company usually optimizes for some imperfect metric. The better those metrics approximate profit in competitive markets, the closer the company comes to maximizing overall profit. This model is harder to quantify, but we can predict that e.g. deep production pipelines will be less efficient than broad pipelines.
I'm still writing the piece on non-equilibrium markets. The information we get on how the market is out of equilibrium is rather odd, and doesn't neatly map to any other algorithm I know. The closest analogue would be message-passing algorithms for updating a Bayes net when new data comes in, but that analogy is more aesthetic than formal.
Replies from: ryan_b↑ comment by ryan_b · 2018-11-14T21:21:07.171Z · LW(p) · GW(p)
The information we get on how the market is out of equilibrium is rather odd, and doesn't neatly map to any other algorithm I know
I don't want to put the cart before the horse or anything, but this increases my expectation that the information is valuable, rather than decreases it.
comment by cousin_it · 2018-11-12T12:18:52.914Z · LW(p) · GW(p)
Neat! Is this connection well known? It sounds simple enough that someone probably thought of this before.
Replies from: johnswentworth↑ comment by johnswentworth · 2018-11-12T17:45:19.395Z · LW(p) · GW(p)
"Price = derivative" is certainly well-known. I haven't seen anyone else extend the connection to backprop before, but there's no way I'm first person to think of it.
Replies from: nikete↑ comment by Nicolás Della Penna (nikete) · 2020-11-06T16:33:37.661Z · LW(p) · GW(p)
When the goods are contingent and a market maker is used to construct the price formation process there is a line of work stemming from https://arxiv.org/abs/1003.0034 on this ( http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.296.6481&rep=rep1&type=pdf , https://papers.nips.cc/paper/4529-interpreting-prediction-markets-a-stochastic-approach.pdf )
Replies from: johnswentworth↑ comment by johnswentworth · 2020-11-06T17:53:19.783Z · LW(p) · GW(p)
Thanks, these are great!
comment by Ben Pace (Benito) · 2019-12-02T19:16:52.339Z · LW(p) · GW(p)
Seconding Jacob.