The highest-probability outcome can be out of distribution
post by tailcalled · 2022-10-22T20:00:16.233Z · LW · GW · 5 commentsContents
5 comments
"Out of distribution" is a phenomenon where a data point x does not come from the distribution you had in mind. To give some examples, here is what might be considered OOD:
- You play a dice game against a cheater, and the cheater uses a die that has been weighted to always roll six. Thus their rolls look like 666666..., whereas your rolls look like 312265....
- You order an apple from a store and the store decides to drive a truck into your house in order to murder you.
- You are reading an interesting post on LessWrong, and th2u
mCXh4:xaapdQA
r bKv4ztPktiR)pYpXwT-j
%?:Ta4Or
XXdicVAQ?;DHJFh?U4wLW! iCmVD~z1iQT5cB4x&J_A-2MmUxCCxDdA3hYXjomA "m5mID;9-C9~=%~-j6ba"2N!fV~jikXZOQ2iEsnNxR0nggVYR:ZF:9&p
m#R"Xf
j~=vFiM_N(&~M%8amq2q5z5
Possibilities 2 and 3 seem to be based on something that is unlikely or surprising happening, so they seem to suggest that being "out of distribution" is about being low-probability. But if you think about it for possibility 1, then every sequence of dice rolls of equal length should have the same probability when using fair dice, and therefore low probability cannot account for possibility 1.
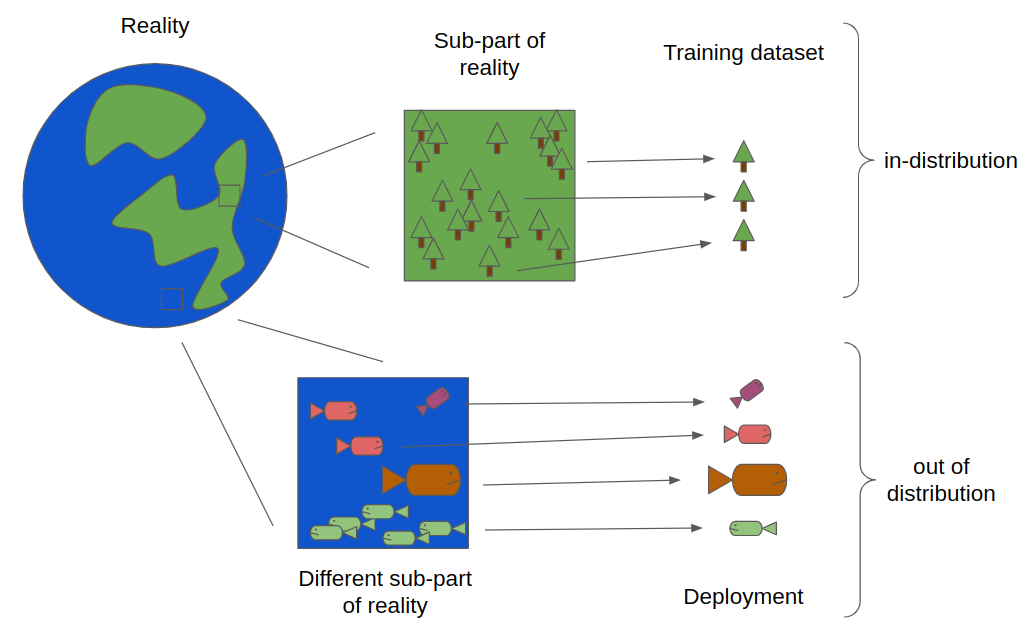
In fact, we can construct a scenario where a point is "out of distribution" despite being the highest-probability point in the distribution. Imagine a gaming place where everyone is expected to cheat, playing with dice that have 58% chance of rolling a 6. In that case, an ordinary roll sequence would look like 624646662443.... However, if someone got a roll sequence full of 6s, like 666666666666..., then their rolls would be out of distribution, and it would look like they were cheating beyond the accepted weighted dice.
Conceptually, what is happening here is that even though 666666666666... is the most likely roll sequence, there are so many other sequences of rolls that have fewer 6s that their lower likelihood is counterbalanced (and then some) by their greater number. The sum of the probabilities of other sequences ends up being greater than the probability of 666666666666....
However, this doesn't explain the full story. After all, the sum of the probabilities of the non-624646662443... roll sequences is also much greater than the probability of 624646662443.... Any one specific roll sequence is unlikely, so why do we consider some to be "out of distribution" and others not?
This is probably not a fully solved problem. Perhaps in a later post, I will give one piece that I believe to be relevant. But until then, here's a relevant meme:

Thanks to Justis Mills for proofreading and feedback.
5 comments
Comments sorted by top scores.
comment by leogao · 2022-10-23T01:20:31.193Z · LW(p) · GW(p)
I was going to mention the example of the aaaaaaa string but saw that you already included my meme.
More generally, I think the key thing going on here is that likelihood is not the same thing as typicalness. The microstate/macrostate comment by shminux seems to be correct as well. We can perhaps think of typicalness as referring to the likelihood of the macrostate that the microstate belongs to.
comment by Shmi (shminux) · 2022-10-23T00:15:37.851Z · LW(p) · GW(p)
Seems like a microstate vs macrostate situation. I suspect that coarse-graining random parts of a roll sequence gives an accurate probability distribution in one case, and a very biased distribution in the other.
Replies from: tailcalled↑ comment by tailcalled · 2022-10-23T07:20:36.229Z · LW(p) · GW(p)
Likely yes, but secretly what motivated my post was a discussion of outlier detection for the purpose of alignment, and for that purpose we can't just assume a coarsening, as it instead has to be learned or hard-coded.
comment by Jozdien · 2022-10-22T20:55:05.034Z · LW(p) · GW(p)
My guess is that when people are pointing to "OOD" stuff in the real-world, it's really a pointer to "things unlikely enough that another hypothesis is more probable". A series of 66666... in the last scenario you describe is more probable than any other series of dice rolls, but when you compare it in terms of P(outcome that benefits player) and P_prior(player is cheating), it seems like the reaction you describe as "calling OOD" is from the former belonging to a class unlikely enough that the posterior of the latter is beyond some threshold that allows calling out cheaters without being too sensitive. The generalization to other settings would then probably be something like "I suspect something else is at play here" when I see "out of distribution".
Replies from: tailcalled↑ comment by tailcalled · 2022-10-22T21:19:39.577Z · LW(p) · GW(p)
I agree that there is a lot of truth to that viewpoint. However, this is difficult to formalize with learning. The issue is that most existing learning theory assumes that you already have data on the full set of classes, but if you do that, then everything becomes in-distribution.
I think that for practical purposes, what often matters is that this other process generates data points with very different downstream effects. This matches what you bring up with P(outcome that benefits the player); the downstream effects of 666666... are very different from most other dice roll sequences.