Towards a Unified Interpretability of Artificial and Biological Neural Networks
post by jan_bauer · 2024-12-21T23:10:45.842Z · LW · GW · 0 commentsContents
No comments
Neuroscience and mechanistic interpretability share a common goal: understanding neural networks, either biological or artificial. This is reflected in the convergent evolution of these domains – from interpreting single neurons to abstract features, and more recently, to functional representations. Yet, a significant number of approaches in either field remain unknown to the other. Bridging these methods could benefit both.
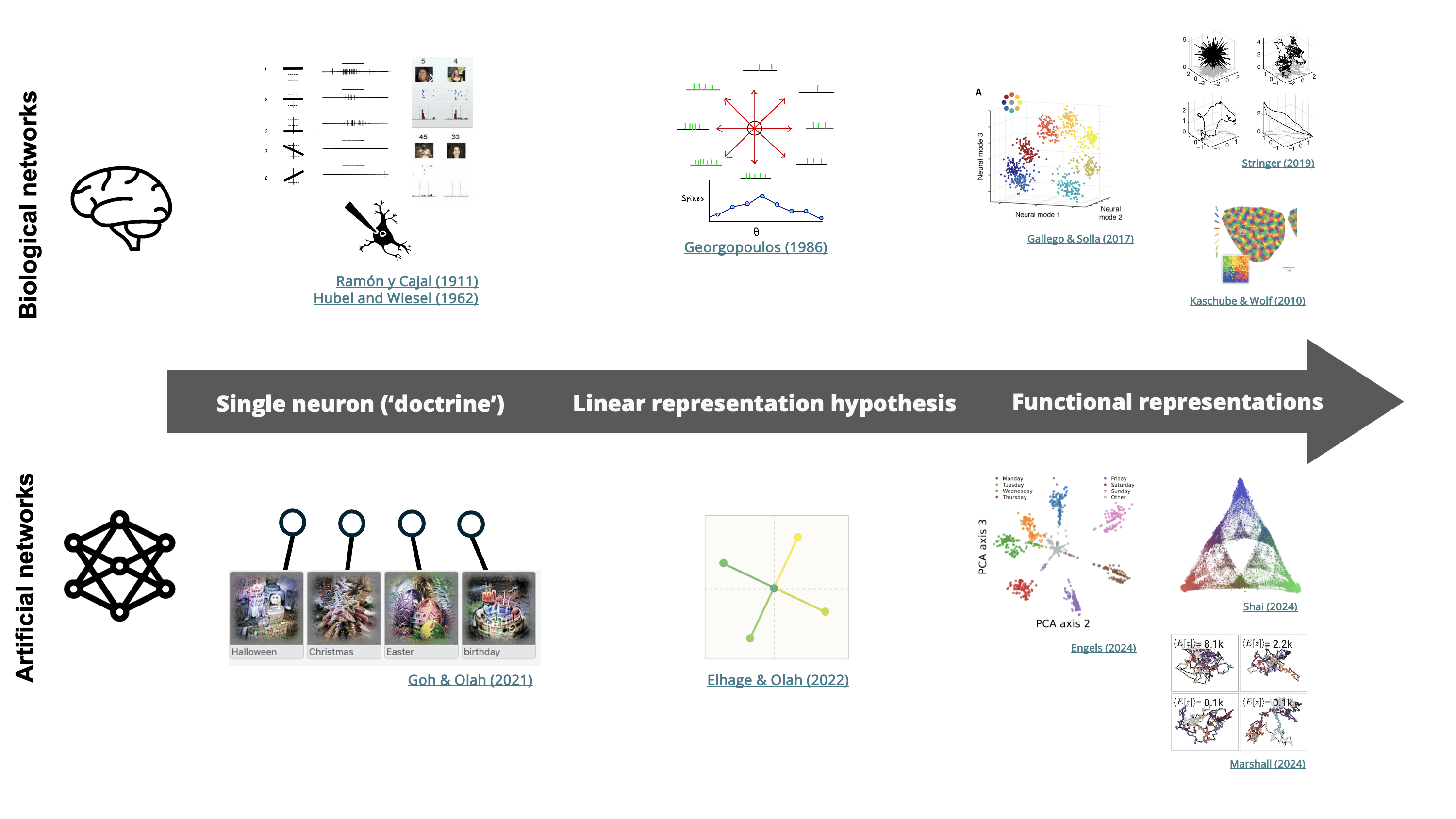
Neuroscience for Biological Networks. The study of the nervous system began in the late 19th century with Ramón y Cajal, who coined the 'neuron doctrine' by discovering how single cells respond to electrical currents. Advances in technology later allowed for simultaneous recordings from multiple neurons, leading to key discoveries like Hubel and Wiesel's identification of cells responsive to specific inputs, and Georgopoulos' work on population vector coding. In recent years, several groups have focused on the representational geometry of neural codes and its functional implications (Kaschube et al. [LW(p) · GW(p)] (2010), Stringer et al. [LW(p) · GW(p)](2019), Moser et al. [LW(p) · GW(p)](2022)).
Mechanistic Interpretability for Artificial Networks. Similarly, monosemanticity – the idea that individual neurons or features correspond to single, interpretable concepts – has been a north star guiding mechanistic interpretability research (Goh & Olah (2021)). Later work has generalized this view, finding that neurons can encode several concepts (Elhage & Olah (2022)), which may be disentangled using nonlinear decoders. Now, several researchers are pushing beyond linear representations and monosemantic features, for example by exploring the geometry of neural manifolds (Hoogland et al. (2023) [? · GW], Mendel et al. (2024) [LW(p) · GW(p)], Marshall et al. (2024), Leask et al. (2024) [LW · GW]).
Towards a Unified Interpretability for Neural Networks. Bridging the structure of representations to their function constitutes the frontier of interpretability research for both biological and artificial networks. To approach it, both fields have developed powerful methods, including manifold geometry, statistical physics, topology, nonlinear decoding, and causal probing. This distributed knowledge is a powerful resource to leverage for both fields.
0 comments
Comments sorted by top scores.