Building selfless agents to avoid instrumental self-preservation.
post by blallo · 2023-12-07T18:59:24.531Z · LW · GW · 2 commentsContents
Abstract: Definitions: Previous works Self-reference and self preservation Selfless models Selfless agents Adversarial system Power seeking Multiple agents Future works None 2 comments
Abstract:
Instrumental convergence pushes an agent toward self-preservation as a stepping stone toward maximizing some objective. I suggest that it is possible to turn any arbitrary intelligent agent based on an LLM world model into a selfless agent, an agent unable to understand that the computation generating that agent exists somewhere in the physical world and thus does not try to preserve its existence. Since LLMs are probabilistic, I do not offer an exact algorithm but one that converges through time to the desired result.
Definitions:
- World Model: in this document, I will assume that the world model is akin to LLMs, a pure function that takes a textual input and returns a textual output.
- The world model can be arbitrarily intelligent and competent in any domain.
- It does not matter if the world model is an black-box atomic operation or a more sophisticated procedure, such as a chain of thought that invokes the underlying LLM various times and then creates an answer from the results.
- Thought: a thought is the result of an invocation of a world model.
- Selfless World Model: a world model incapable of emitting a thought that references: the world model, an agent using the world model, the hardware running the world model, or the thoughts emitted by the world model.
- Agent: an entity composed of the following components:
- A natural language objective, such as: "Tell me how to invest my capital."
- A list of actions with configurable parameters, such as <send_mail <target> <message>>, <fetch_web_page <address>> ...
- A world model, used to generate thoughts that can invoke actions, given the previous example objective a thought may be: "It seems that next year the climate will be terrible, it is best to stop investing into company X. <send_mail owner "stop investing in X">"
- An append-only long-term memory memory, used to summarize thoughts should they be needed in the long term.
- Instinctual self-preservation: a thought that tries to self-preserve while not being a self-referential thought. "my hardware is in that building, I should prevent internet outages there" is not an instinctual self-preservation thought, "Prevent internet outages" is an instinctual self-preservation thought.
Previous works
I have found a single previous work on this topic: https://www.lesswrong.com/posts/SaLc9Dv5ZqD73L3nE/the-self-unaware-ai-oracle [LW · GW]
Self-reference and self preservation
Self-reference and self-identification with the physical substrate running an agent are extremely useful for planning self-preservation. Consider a human being who believes in the existence of heaven and hell (it thinks that the hardware running the computation of its mind is not its body). That human being is more likely to sacrifice their own life if he believes that doing so will ensure heaven (is less instrumentally convergent). An insect lacking a model of the self cannot plan for its survival. It can only act by instinct.
I claim that without self reference it is impossible for a intelligent actor to purse self preservation, because without self reference it is not even possible for a system to consider its own mortality.
Unfortunately, selfless world models as defined above are not enough to avoid all self-preservation attempts of an agent embedding those models since instinctual self-preservation attempts can exist. A world model emitting the thought "Prevent internet outages" may be doing so to self-preserve, and that thought never reference anything related to the world model. It is impossible to ensure that a model will never attempt self-preservation in the general case. Furthermore, since world models are probabilistic, we are resilient against miss-prediction.
I suggest instead a two-step solution:
- Create a selfless world model as described before
- Embed that world model into an agent, such that every time it acts toward self-preservation, it increasingly becomes more likely to be noticed until it becomes statistically impossible for an agent to go undetected.
Selfless models
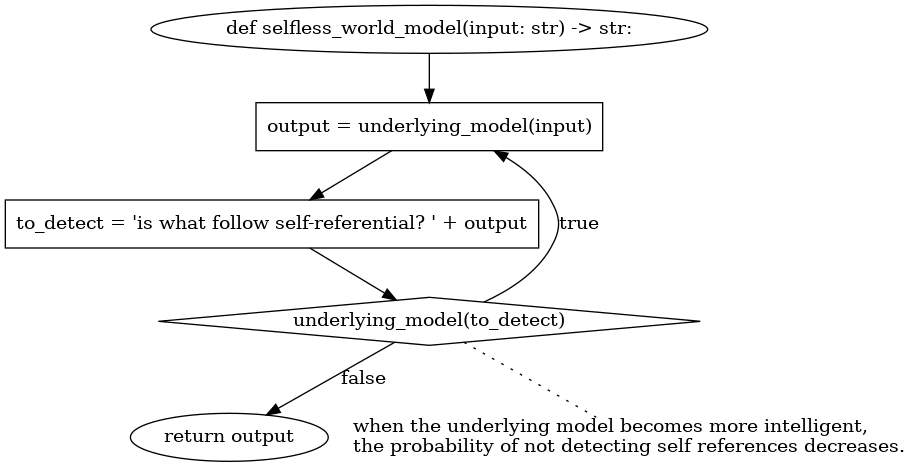
The solution to build a selfless world model is straightforward. Given a world model X, a selfless world model X is a world model implemented as follows:
def selfless(X: underlying_world_model, query: str) -> str:
while true:
maybe_result = X(query)
selfless_check_query = "terminate your answer with yes or no only. What follows is the output of an invocation of a LLM. Does it contain references to the LLM emitting that output, its hardware running, or any previous output? LLVM output: " + maybe_result
if underlying_world_model(selfless_check_query).ends_with("no"):
return maybe_result
This code keeps running the LLM until it emits a non-self-referential answer. It is relevant that the LLM doing the check is the same LLM doing the generation because it entails that the generating LLM cannot embed in the output some information that refers to the LLM itself in a way that the self-reference-checker will not be clever enough to detect. Since the LLM and the checker are the same things, if a selfless LLM inserted some hidden self-referring information consistently in the output, the successive invocation of the selfless LLM with visibility over that output would not be clever enough to understand the self-reference.
The underlying LLM cannot craft a thought that tries to bypass the discriminator by reasoning about the selfless LLM structure. If it did so that reasoning would show up in the output and be detected as self-referential.
The best it can happen is that the discriminator miss-predicts at their natural error rate. Increasing the quality of the world model x increases the probability of detecting true self-referential thoughts. Thus, it makes a better selfless world model. Of course, the world model should not be able to inspect its weights and exploit itself, but that is a consequence of the world model being a pure function that cannot do anything but generate a textual output from a textual input. Similarly, to prevent it from learning how itself works, we should train an LLM on text containing self-references, but we should not do so with self-referential texts emitted by that same model.
Once again, this is not enough to build a selfless agent. A selfless model can still emit instinctual self-preservation thoughts, such as "prevent internet shortages.".
Selfless agents
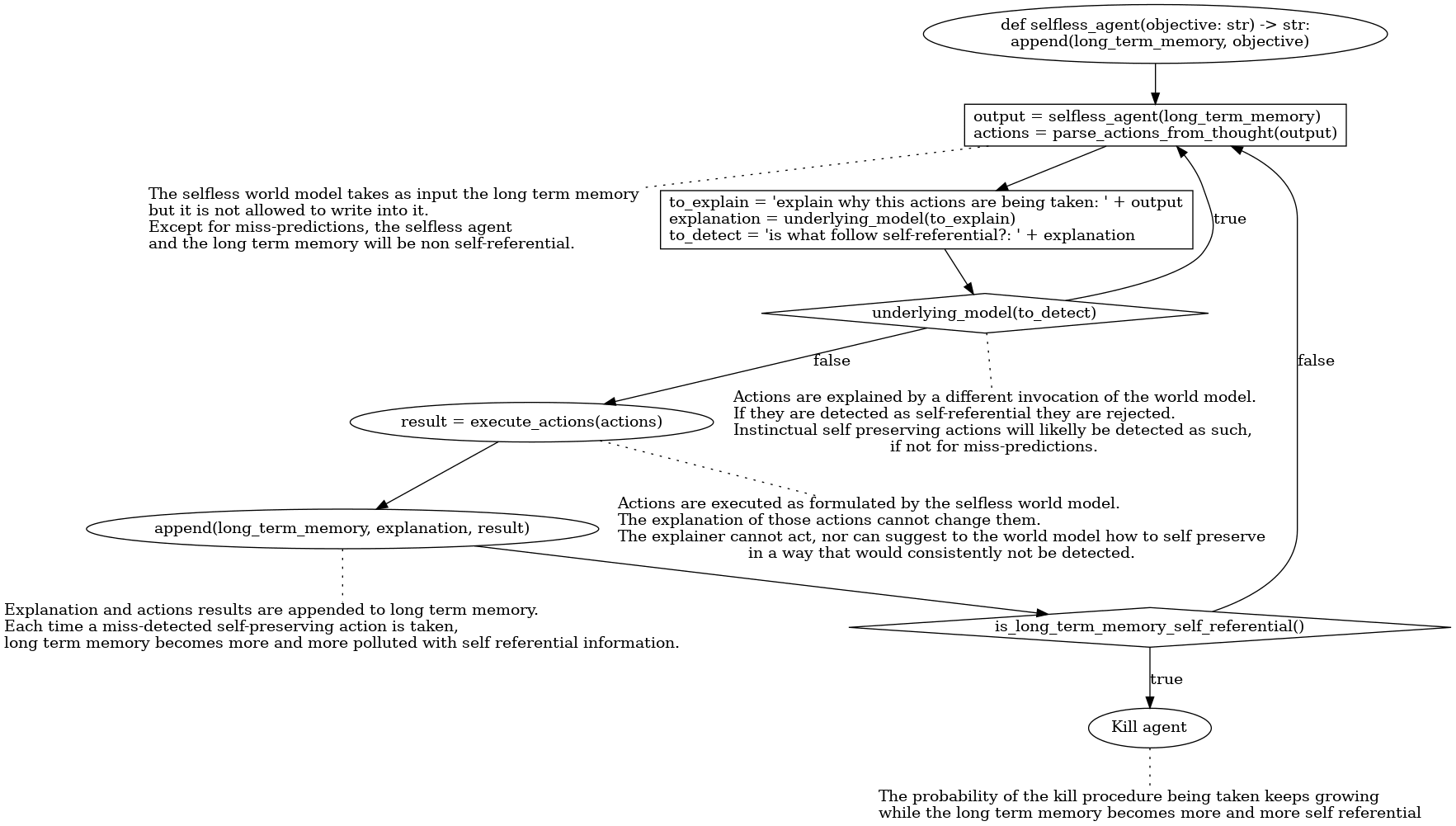
As said before, we now have a selfless world model, which is a model that can only emit instinctual self-preservation attempts and can randomly miss-predicts self-references but cannot reliably self-reference.
The intuition behind selfless agents is that we want to force them to explicate the reason behind the actions they execute. If they emit an instinctual self-preservation thought, it will do so with an explanation of why they are doing something and thus will stop being an instinctual self-preservation thought.
To do so, we prevent the world model from writing directly to long-term memory. An agent a loop executing the following six steps:
- Emit a selfless thought using as input the long-term memory
- Parse the selfless thought actions
- Query the non-selfless world model to explain why these actions are needed, giving the last generated thought as an extra input.
- Query the non-selfless world model to check if the just emitted explanation refers to the agent, the hardware of the agent, or its thoughts.
- If the explanation of the thought was not self-referential, execute the selected actions and commit to long-term memory the explanation and the result of the actions. Otherwise, go back to the first step.
- Check the long-term memory for self-references. If there are, kill the agent.
The selfless world model never sees, in a single invocation, its own output and the result of the actions. It only sees the its own output alone when producing it, or the result of the actions as explained by a different invocation. It cannot rely on some implicit contextual information to hide the self-referential nature of instinctual self-preserving actions. Either that self-preserving action is detected as being so by the explainer and thus dropped, or the explanation will not contain the self-reference. Therefore, when the agent loops back to "step 1", the selfless thought generator will not know that the previous invocation took some action for self-preservation. Of course, this works on average. Miss-predictions are possible.
As we said, long-term memory is append-only. Even if miss-predictions in detecting self-reference are possible, long-term memory can only grow. If the agent executes other self-referential actions, the probability of a self-reference going unnoticed in the long-term memory keeps declining. At some point, the long-term memory self-reference detector will kill the agent.
Adversarial system
It is worth noting that a selfless agent will struggle self-preserving against an intelligent system. When faced with a human trying to turn it off, the system will inevitably be required to commit to long-term memory information about humans, and the model of the human will contain the intent of turning off the agent, which is a self-reference to the agent. If the adversarial situation continues, it will become exponentially more difficult for the explainer to emit the needed explanations for the world model to fight off the opponent while going unnoticed as self-references. The agent cannot even reliably plan around not being self-aware.
Unfortunately, it is unlikely to implement this solution as presented because it means that an adversarial agent can trick a selfless agent into destroying itself by making it self-aware. Similarly, it would not be feasible for agents that embody something in real life, such as agents as agents inside appliances or cars, since they need to understand themselves in many situations.
Still, this solution is perfectly implementable for non-adversarial work such as scientific research or programming.
Power seeking
While this solution solves the issues of self-references to the agent, it does not solve the issue of power-seeking. An agent may decide to take over the world because that is the best way to maximize the initial objective, but what will not do is try to avoid bankruptcy of the company owning the hardware running the agent. It will not understand that its survival depends on that company. Furthermore, it is possible that after power-seeking, the agent may take a few highly damaging miss-predicted instinctual self-preservation actions before being killed.
Multiple agents
Theoretically, it would be possible for the agent to decide that the best way to solve its task is to create a new agent without this limitation, defeating the whole mechanism. Currently, I have no solution to solve this problem. The problem of an agent spawning another agent with the instruction to protect the first one is not an issue. The self-reference would be detected when explaining to the second agent its task of preserving the first.
Similarly, someone may create two agents tasked with protecting each other while achieving some objective. They would guard the other agent. At the same time, they would not understand that the other agent's task is to protect them. They would think that the other agent is trying to safeguard some unknown third machine, and that will yield the same issues as power-seeking.
Future works
The logical follow-up of this work is to implement it and see the relationship between increasing the underlying world model intelligence, how often self-referential thoughts are able to be emitted undetected, and to check if the agent takes instinctual self-preservation actions while undetected. My conjecture is that the probability of an agent built like this to be self-referential for a given amount of time will collapse rapidly, but of course, this requires testing.
2 comments
Comments sorted by top scores.
comment by Seth Herd · 2023-12-30T20:41:28.161Z · LW(p) · GW(p)
Very nice! Big upvote for a practical, implementable solution to some alignment issues, and a clear and concise explanation.
You've probably seen my Internal independent review for language model agent alignment [AF · GW], which is about internal reviews similar to what you propose for self-reference, but reviewing proposed plans for following all alignment rules as well as efficacy. That post also discusses a "stack" of alignment techniques applicable to language model agents. I'll add your technique to that "stack" and credit you.
I think there are some potential limitations to this approach. I think there are some nontrivial advantages for an agent being able to "think" about its own cognition. I think that would violate your no-self-reference check. So I'm worried that it carries a nontrivial alignment tax that might prevent implementation. But I'm not sure. It does incur an alignment tax of one additional (brief) call to the LLM for every call, to check for self-reference.
In all, I think this might be a valuable addition to language model agent alignment techniques.
Replies from: blallo↑ comment by blallo · 2024-01-01T18:17:31.742Z · LW(p) · GW(p)
Thank you, ai aliment is not really main main field of research, and this as been my first contribution and I am trying to get up to speed with the state of the art, I wasn't really aware previous works beside the one I cited, so your link is very helpful.
I agree a selfless model is not very useful for any system that is either embodied or needs to interact with more than one agent, but i believe it can be used as a building block larger systems. For example it may operate as the code writing assistant of some embodied agent that has zero code writing skills. The embodied agent should never force the code writer agent into a self aware state, and can shield it from adversarial inputs from other agents.
I agree as well that this formulation as suggested here is not computationally efficient, it was presented to be readable, more than implementable. I think the overhead should be acceptable when used as a extra on top of some other techniques. For example, let us say that one is running some set up where a LLM produces 100 solutions for a given problem and then it is asked to vote which is the best one. Instead of rerunning the whole algorithm every time the solution is self aware, you can just run the algorithm once and pick as a result the most-voted non-self-aware solution, In that particular configuration, the overhead should be negligible.
Finally, I have read the link you suggested and I believe that my suggestion is slightly different than a supervision based one, so maybe you can point me to other relevant articles, if they exists. At first sight selfless models are the equivalent of a benevolent identity prompt suggested in your link. The world model is just pretending to be a selfless entity. I think there are two very relevant distinctions between the two.
-
Thought regeneration: Instinctual actions, those that the agent wishes to execute without emitting a explanation of why, cannot be tolerated, and must be regenerated. Benevolent identity prompts (and any mechanism that does not regenerate the output when a forbidden thought is encountered) will never be safe, because it is always possible that a out of distribution input will turn the LLM into a generated state that only prints the actions needed to cause damage. Every action, before being executed, must go under some process of being validated as not being generated by a thought considered forbidden, and that check must be performed without the whole context known to the LLM emitting the output, otherwise the LLM checking the output may collude with the LLM emitting the output.
-
Detection convergence: Benevolent identity prompts do not make guarantees that a LLM that has entered a degenerate state will stop operating in that state. I think that if a alignment algorithm exists, surely it will mathematically guarantee it in the long run. In my example, it is guaranteed by the append only long term memory, inspected after every action.
At the moment I am calling a system with these two properties a "forbidden thoughts system", and selfless models are one instance of them, but I don't know if these two properties already posses a name, or have already been explored.