Simpson's paradox and the tyranny of strata
post by dynomight · 2020-11-19T17:46:32.504Z · LW · GW · 4 commentsThis is a link post for https://dyno-might.github.io/2020/11/16/simpsons-paradox-and-the-tyranny-of-strata/
Contents
I Zeus II Colors III Stripes IV Colors and stripes V Individuals None 4 comments
Simpson's paradox is an example of how the same data can tell different stories. Most people think of this as an odd little curiosity, or perhaps a cautionary tale about the correct way to use data.
You shouldn't see Simpson's paradox like that. Rather than some little quirk, it's actually just the simplest case of a deeper and stranger issue. This is less about the “right” way to analyze data and more about limits to what questions data can answer. Simpson's paradox is actually a bit misleading, because it has a solution, while the deeper issue doesn't.
This post will illustrate this using no statistics and (basically) no math.
I Zeus
You are a mortal. You live near Olympus with a flock of sheep and goats. Zeus is a jerk and has taken up shooting your animals with lightning bolts.

He doesn't kill them; it's just boredom. Transforming into animals to seduce love interests gets old eventually.
Anyway, you wonder: Does Zeus have a preference for shooting sheep or goats? You decide to keep records for a year. You have 25 sheep and 25 goats, so you use a 5x5 grid with one cell for each animal.
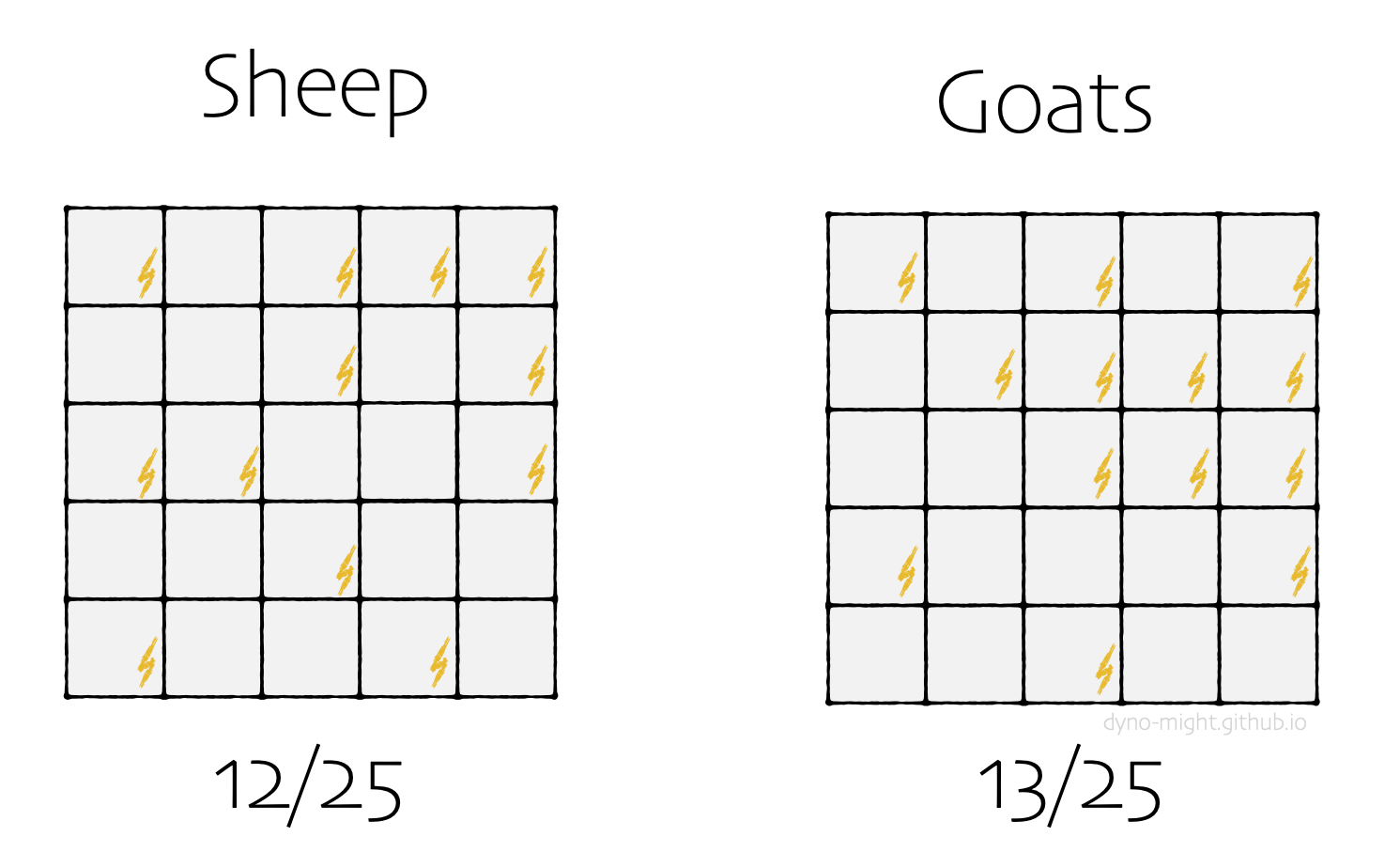
At first glance, it seems like Zeus dislikes goats more than He dislikes sheep. (If you're worried about the difference being due to random chance, feel free to multiply the number of animals by a million.)
II Colors
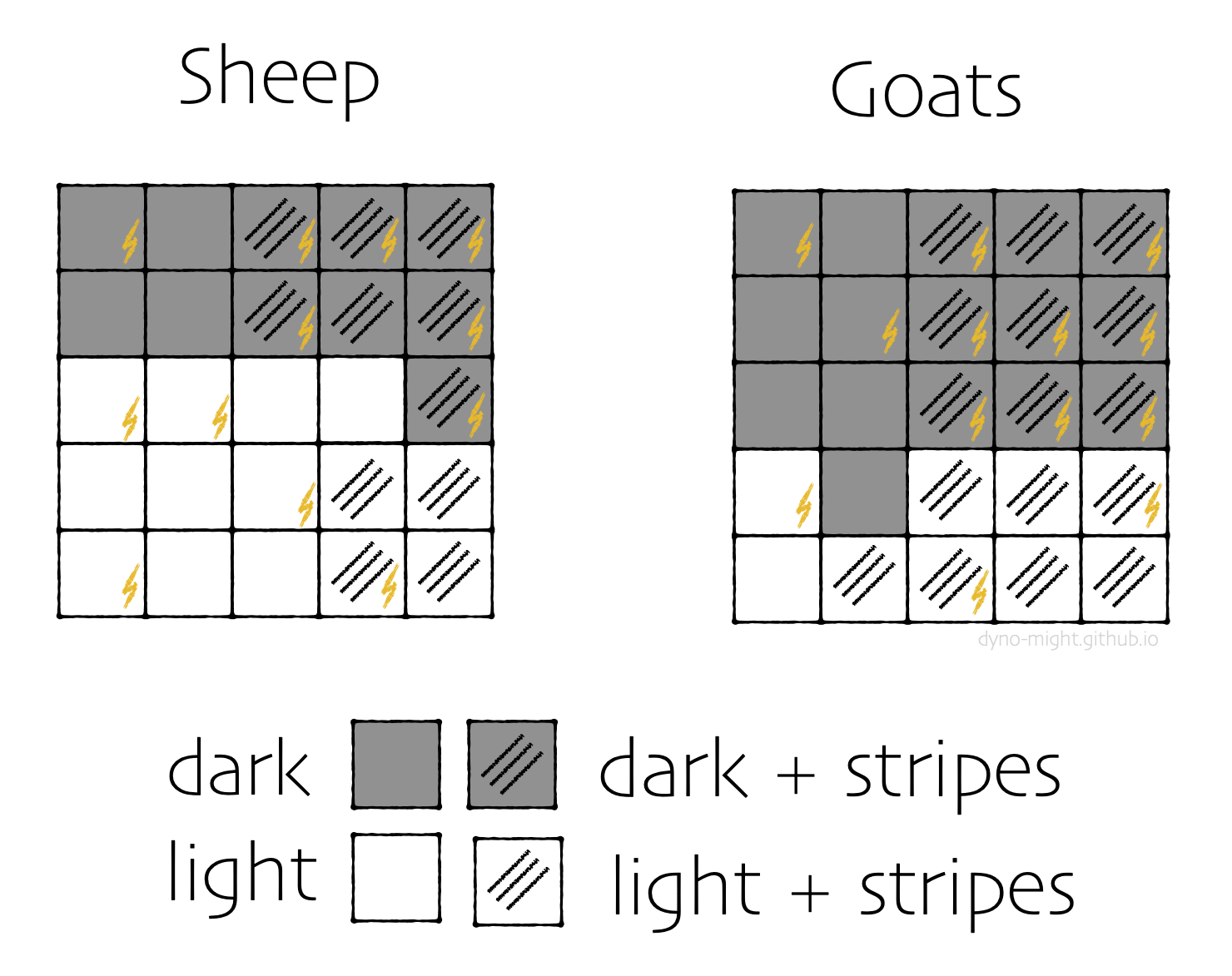
Thinking more, it occurs to you that some animals have darker fur than others. You go back to your records and mark each animal accordingly.
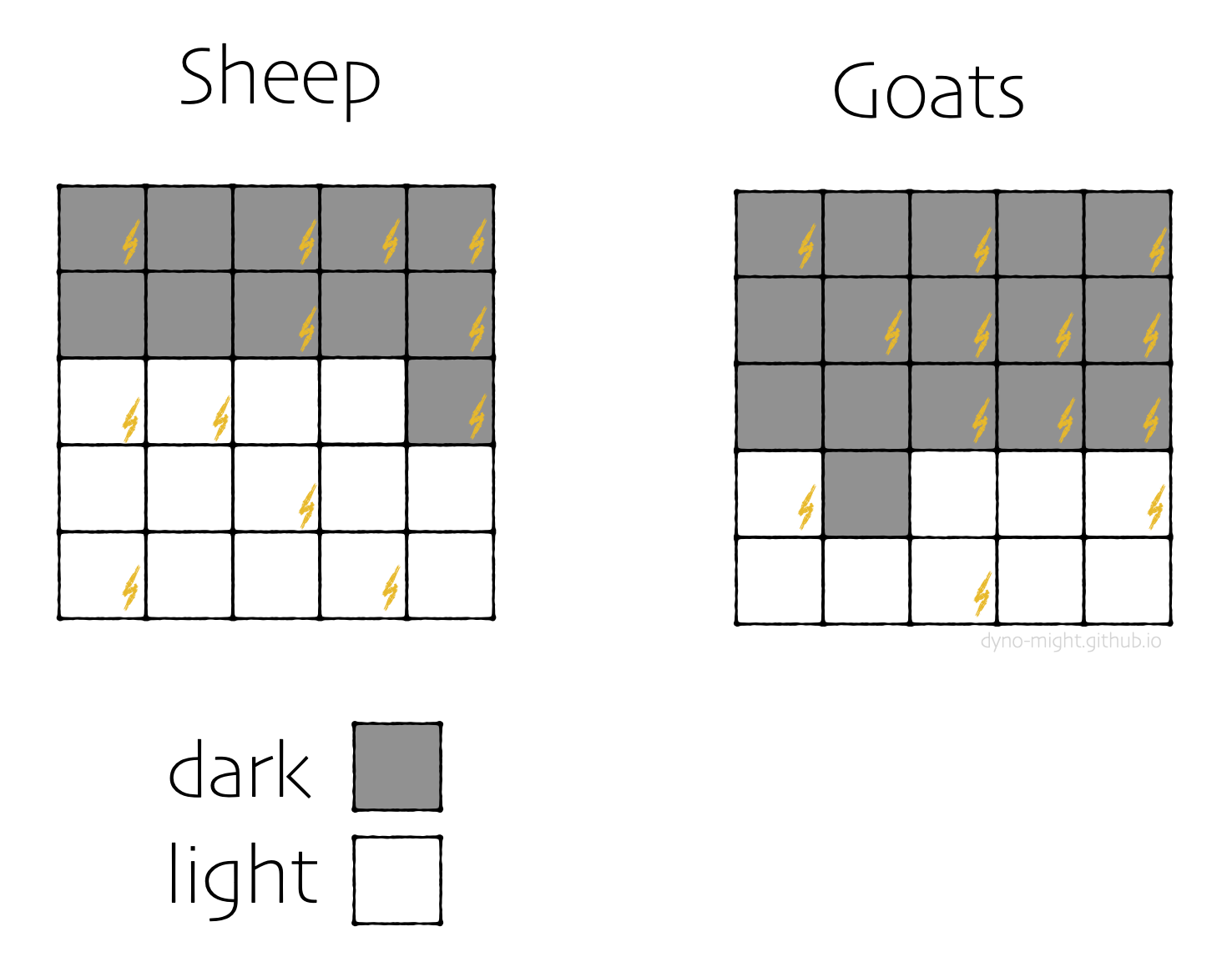
You re-do the analysis, splitting into dark and light groups.
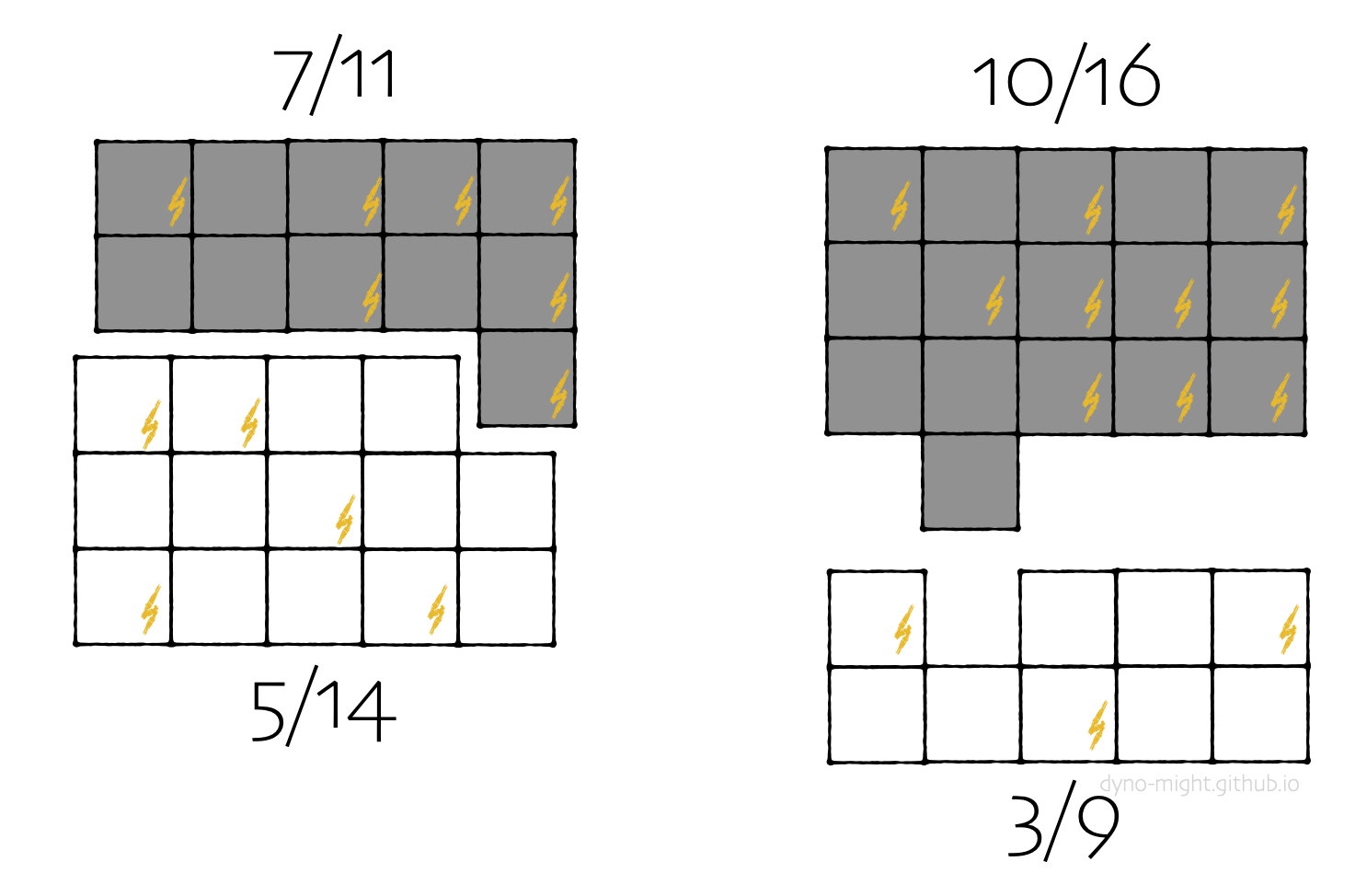
Overall, sheep are zapped less often than goats. But dark sheep are zapped more often than dark goats (7⁄11 > 10⁄16) and light sheep are zapped more often than light goats (5⁄14 > 3⁄9). This is the usual paradox: The conclusion changes when you switch from analyzing everyone to splitting into subgroups.
How does that reversal happen? It's simple: For both sheep and goats, dark animals get zapped more often, and there are more dark goats than dark sheep. Dark sheep are zapped slightly more than dark goats, and similarly for light sheep. But dumping all the animals together changes the conclusion because there are so many more dark goats. That's all there is to the regular Simpson's paradox. Group-level differences can be totally different than subgroup differences when the ratio of subgroups varies.
This probably seems like a weird little edge case so far. But let's continue.
III Stripes
Thinking even more, you notice that many of your (apparently mutant) animals have stripes. You prepare the data again, marking each animal according to stripes, rather than color.
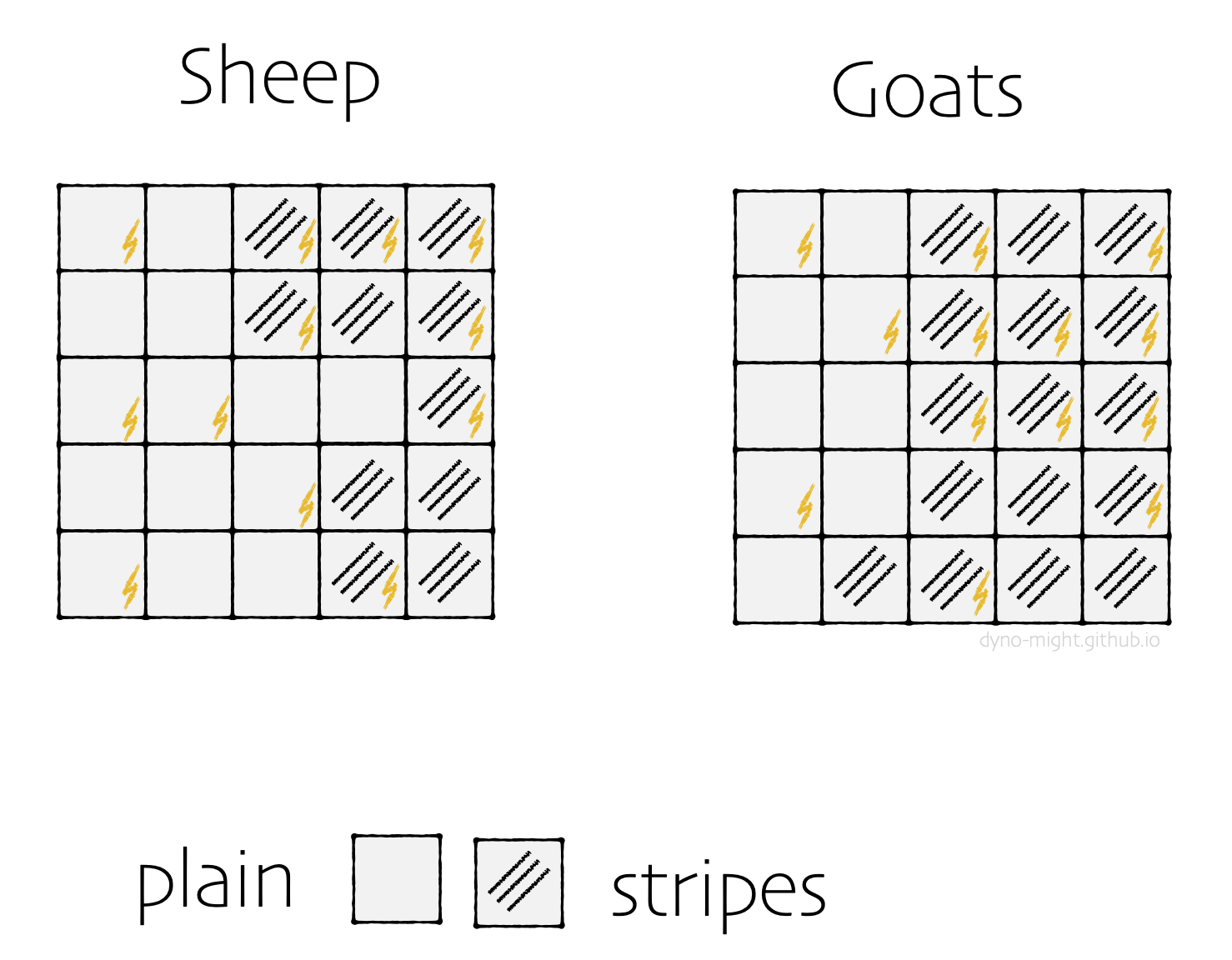
You wonder, naturally, what happens if you analyze these groups.
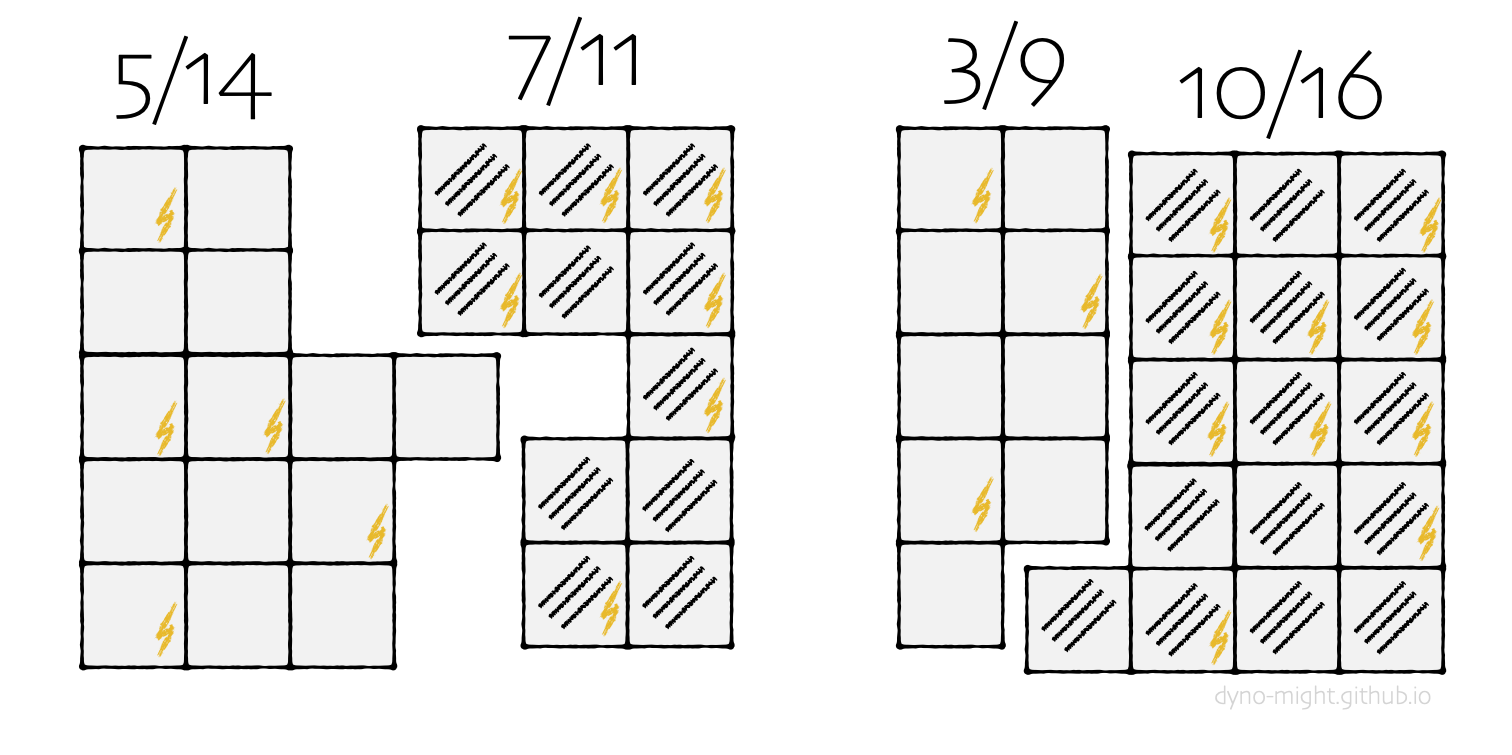
The results are similar to those with color. Though sheep are zapped less often than goats overall (12⁄25 < 13⁄25), plain sheep are zapped more often than plain goats (5⁄14 > 3⁄9), and striped sheep are zapped more often than striped goats (7⁄11 > 10⁄16).
IV Colors and stripes
Of course, rather than just considering color or stripes, nothing stops you from considering both.
You decide to consider all four subgroups separately.
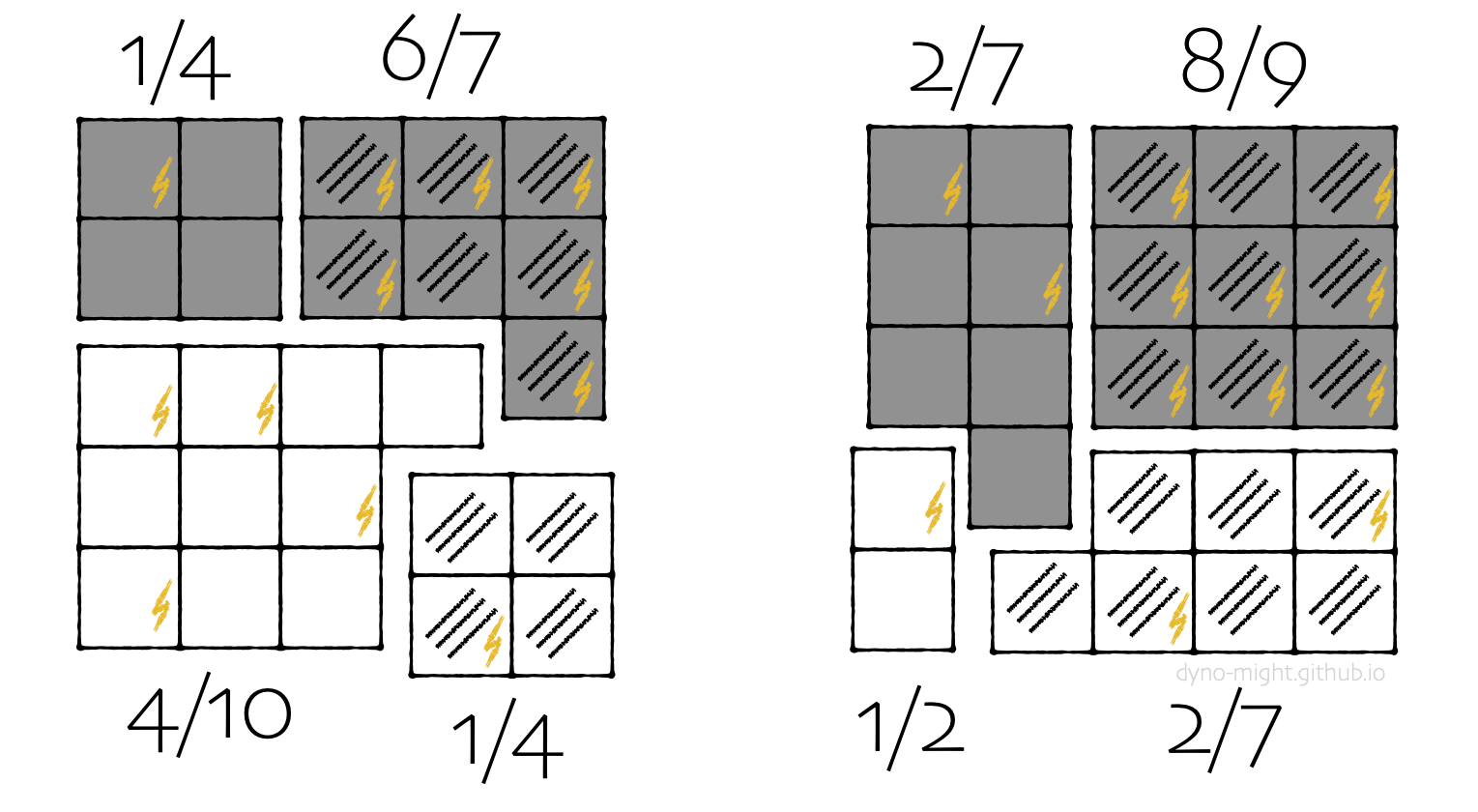
Now sheep are zapped less often in each subgroup. (1⁄4 < 2⁄7, 6⁄7 < 8⁄9, etc.)
When you compare everyone, there's a bias in against goats. When you compare by color, there's a bias against sheep. When you compare by stripes, there's also a bias against sheep. Yet when you compare by both color and stripes, there's a bias against goats again.
| Type of animals compared | Who gets zapped more often? |
|---|---|
| All | Goats |
| Light | Sheep |
| Dark | Sheep |
| Plain | Sheep |
| Striped | Sheep |
| Dark Plain | Goats |
| Dark Striped | Goats |
| Light Plain | Goats |
| Light Striped | Goats |
How can this happen?
To answer that, it's important to realize that anything can happen. There could be basically any biases that reverse (or don't) in whatever way when you split into subgroups. In the table above, essentially any sequence of goats / sheep is possible in the right-hand column.
But how, you ask? How can this happen? I think this is the wrong question. Instead we should ask if there is anything to prevent this from happening. There are a huge variety of possible datasets, with all sorts of different group averages. Unless there is some special structure forcing things to be "orderly", essentially arbitrary stuff can happen. There is no special force here.
V Individuals
So far, this all seems like a lesson about the right way to analyze data. In some cases, that's probably true. Suppose you are surprised to read that Prestige Airways is more often delayed than GreatValue Skybus. Looking closer, you notice that Prestige flies mostly between snowy cities while Skybus mostly flies between warm dry cities. Prestige can easily have a better track record for all individual routes, but a worse track record overall, simply because they fly hard routes more often. In this case, it's probably correct say that Prestige is more reliable.
But in other cases, the lesson should be just the opposite: There is no "right" way to analyze data. Often the real world looks like this:
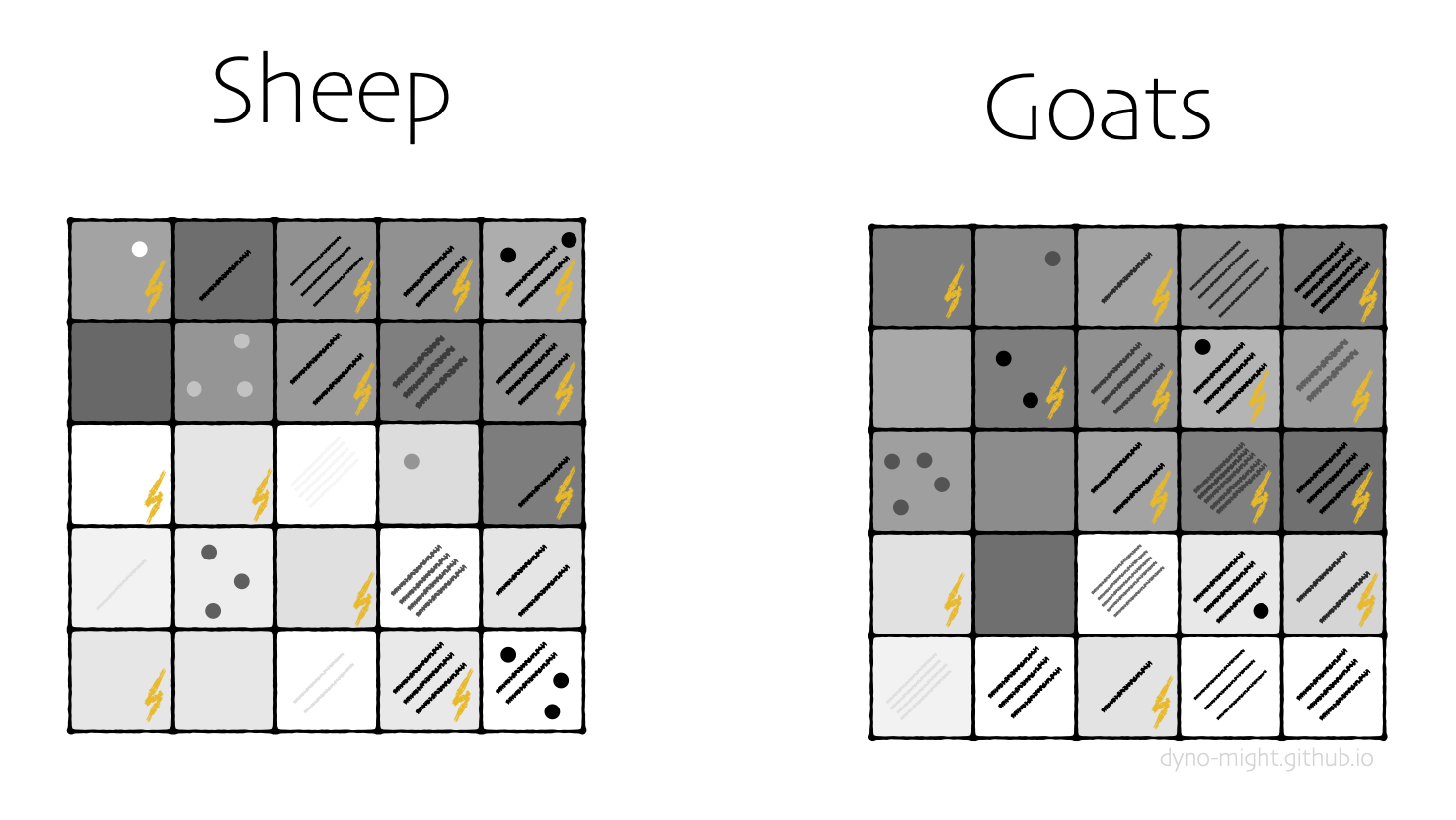
There's no clear dividing line between "dark" and "light" animals. Stripes can be dense or sparse, thick or thin, light or dark. There can be many dark spots or few light spots. This list can go on forever. In the real world, individuals often vary in so many ways that there's no obvious definition of subgroups. In these cases, you don't beat the paradox. To get answers you have to make arbitrary choices, yet the answers depend on the choices you make.
Arguably this is a philosophical problem as much as a statistical one. We usually think about bias in terms of "groups". If prospects vary for two "otherwise identical" individuals in two groups, we say there is a bias. This made sense for airlines above: If Prestige was more often on time than GreatValue for each route, it's fair to say Prestige is more reliable.
But in a world of individuals, this definition of bias breaks down. Suppose Prestige mostly flies in the middle of the day on weekends in winter, while Skybus mostly flies at night during the week in summer. They vary from these patterns, but never enough that they are flying the same route on the same day at the same time at the same time of year. If you want to compare, you can group flights by cities or day or time or season, but not all of them. Different groupings (and sub-groupings) can give different result. There simply is no right answer.
This is the endpoint of Simpson's paradox: Group level differences often really are misleading. You can try to solve that by accounting for variability within groups. There are lots of complex ways to try to do that I haven't talked about, but none of them solve the fundamental problem of what bias mean whens every example is unique.
4 comments
Comments sorted by top scores.
comment by jimmy · 2020-11-20T17:21:50.012Z · LW(p) · GW(p)
(If you're worried about the difference being due to random chance, feel free to multiply the number of animals by a million.)
[...]
They vary from these patterns, but never enough that they are flying the same route on the same day at the same time at the same time of year. If you want to compare, you can group flights by cities or day or time or season, but not all of them.
The problem you're using Simpson's paradox to point at does not have this same property of "multiplying the size of the data set by arbitrarily large numbers doesn't help". If you can keep taking data until randomness chance is no issue, then they will end up having sufficient data in all the same subgroups, and you can just read the correct answer off the last million times they both flew in the same city/day/time/season simultaneously.
The problem you're pointing at fundamentally boils down to not having enough data to force your conclusions, and therefore needing to make judgement about how important season is compared to time of day so that you can determine when conditioning on more factors will help relevance more than it will hurt by adding more noise.
Replies from: Pattern, dynomight↑ comment by Pattern · 2020-11-20T18:16:58.692Z · LW(p) · GW(p)
So you just need enough data that the events involving entities is much greater than the number of parameters.
Replies from: dynomight↑ comment by dynomight · 2020-11-20T19:04:13.112Z · LW(p) · GW(p)
You definitely need a number of data at least exponential in the number of parameters, since the number of "bins" is exponential. (It's not so simple as to say that exponential is enough because it depends on the distributional overlap. If there are cases where one group never hits a given bin, then even an infinite amount of data doesn't save you.)
↑ comment by dynomight · 2020-11-20T18:58:43.535Z · LW(p) · GW(p)
I see what you're saying, but I was thinking of a case where there is zero probability of having overlap among all features. While that technically restores the property that you can multiply the dataset by arbitrarily large numbers, if feels a little like "cheating" and I agree with your larger point.
I guess Simpson's paradox does always have a right answer in "stratify along all features", it's just that the amount of data you need increases exponentially in the number of relevant features. So I think that in the real world you can multiply the amount of data by a very, very large number and it won't solve the problem, even though in a large enough number will.
In the real world it's often also sort of an open question if the number of "features" is finite or not.