A solvable Newcomb-like problem - part 3 of 3
post by Douglas_Reay · 2012-12-06T13:06:24.638Z · LW · GW · Legacy · 3 commentsContents
A1 vs B1 A2 vs B1 A1 vs B2 A2 vs B2 None 3 comments
This is the third part of a three post sequence on a problem that is similar to Newcomb's problem but is posed in terms of probabilities and limited knowledge.
Part 1 - stating the problem
Part 2 - some mathematics
Part 3 - towards a solution
In many situations we can say "For practical purposes a probability of 0.9999999999999999999 is close enough to 1 that for the sake of simplicity I shall treat it as being 1, without that simplification altering my choices."
However, there are some situations where the distinction does significantly alter that character of a situation so, when one is studying a new situation and one is not sure yet which of those two categories the situations falls into, the cautious approach is to re-frame the probability as being (1 - δ) where δ is small (eg 10 to the power of -12), and then examine the characteristics of the behaviour as δ tends towards 0.
LessWrong wiki describes Omega as a super-powerful AI analogous to Laplace's demon, who knows the precise location and momentum of every atom in the universe, limited only by the laws of physics (so, if time travel isn't possible and some of our current thoughts on Quantum Mechanics are correct, then Omega's knowledge of the future is probabilistic, being limited by uncertainty).
For the purposes of Newcomb's problem, and the rationality of Fred's decisions, it doesn't matter how close to that level of power Omega actually is. What matters, in terms of rationality, is the evidence available to Fred about how close Omega is to having to that level of power; or, more precisely, the evidence available to Fred relevant to Fred making predictions about Omega's performance in this particular game.
Since this is a key factor in Fred's decision, we ought to be cautious. Rather than specify when setting up the problem that Fred knows with a certainty of 1 that Omega does have that power, it is better to specify a concrete level of evidence that would lead Fred to assign a probability of (1 - δ) to Omega having that power, then examine the effect upon which option to the box problem it is rational for Fred to pick, as δ tends towards 0.
The Newcomb-like problem stated in part 1 of this sequence contains an Omega that it is rational for Fred to assign a less than unity probability of being able to perfectly predict Fred's choices. By using bets as analogies to the sort of evidence Fred might have available to him, we create an explicit variable that we can then manipulate to alter the precise probability Fred assigns to Omega's abilities.
The other nice feature of the Newcomb-like problem given in part 1, is that it is explicitly solvable using the mathematics given in part 2. By making randomness an external feature (the device Fred brings with him) rather than purely a feature of Fred's internal mind, we can acknowledge the question of Omega being able to predict quantum events, capture it as a variable, and take it into account when setting out the payoff matrix for the problem.
This means that, instead of Fred having to think "When I walked into this room I was determined to pick one-box. As far as anyone knew or could predict, including myself, I intended to pick one-box. However nothing I do now can change Omegas decision - the money is already in the box. So I've nothing to lose by changing my mind."; Fred can now allocate a specific probability to whether Omega could predict Fred's chance of changing his mind in such circumstances, and Fred can take that into account in his strategy by making his chance of changing strategy explicit and external - basing it upon a random number device.
Or, to put it another way, we are modelling a rational human who has a specific finite chance of talking himself into over riding a pre-committed strategy, as being made up from two components: a component that will infallibly stick to a pre-committed strategy plus a component with a known chance of change; we then treat the combined rational human as being someone infallibly committed to a meta-strategy that includes a chance of change - a mixed equilibrium, from Omega's point of view.
Ok, time to look at the numbers and draw a pretty diagram...
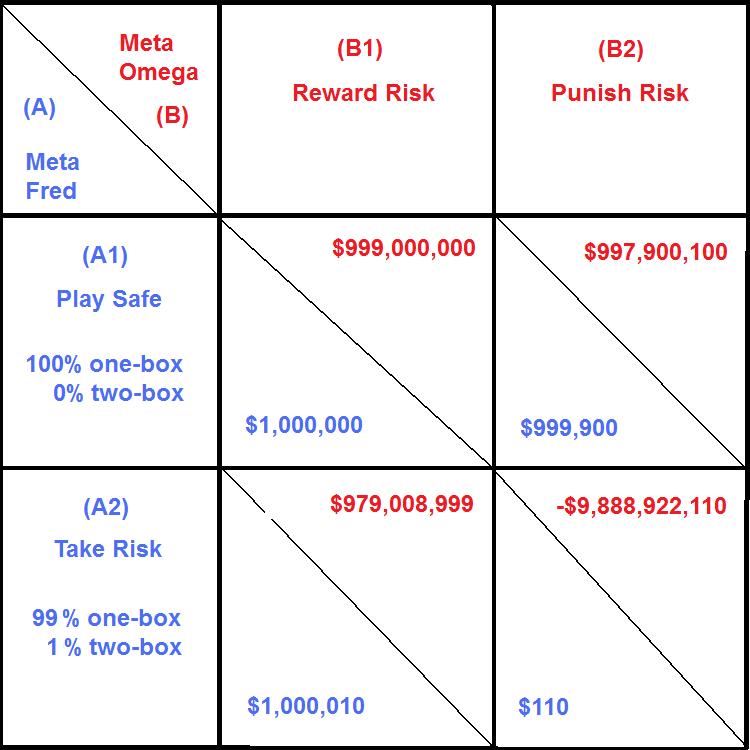
Fred is Player A, and he has two meta options:
A1 - play it safe. 100% chance of one-box and 0% chance of two-box
A2 - take a risk. Mentally pre-commit to using the device to produce 99% chance of one-box and 1% chance of two-box.
Omega is Player B, and he has two meta options:
B1 - reward risk. Not attempt to distinguish between the mental state of Fred taking 1% risk and Fred playing it safe.
B2 - punish risk. Attempt to distinguish and, if Omega guesses Fred is taking risk rather than playing safe, punish it.
We'll start out by assuming that if Omega does attempt to distinguish, then Omega will have a 1 in 10,000 false positive rate (thinking Fred is going to use the device, when actually Fred intends to play it safe) and a 1 in 10,000 false negative rate (thinking Fred is going to play it safe, when actually Fred intends to use the device).
A1 vs B1
Fred gains $1,000,000
Omega loses $1,000,000 to Fred but gains $1,000,000,000 from Alpha, for a net gain of $999,000,000
A2 vs B1
99% of the time, Fred gains $1,000,000 and Omega net gains $999,000,000
1% of the time, Fred gains $1,001,000 and Omega net loses $10,001,001,000
Combining those gives an average of:
Fred gains: $1,000,010
Omega gains: $979,008,999
A1 vs B2
99.99% of the time, Omega correctly discerns that Fred is playing safe
Fred gains $1,000,000
Omega gains $999,000,000
0.01% of the time, Omega falsely believes that Fred is taking a risk, and punishes that by putting $0 in Box A
Fred gains $0
Omega loses $10,000,000,000
Combining those gives an average of:
Fred gains: $999,900
Omega gains: $997,900,100
A2 vs B2
In 100 trials out of 1,000,000 trials Omega incorrectly thinks Fred will play it safe, when actually Fred takes the risk of using the device. Of these:
In 1 trial out of 1,000,000 trials: Omega incorrectly thinks Fred will play it safe, when actually Fred takes the risk of using the device and, in this case, the device picks two-box
==> Fred gains $1,001,000
==> Omega loses $10,001,001,000
In 99 trials out of 1,000,000 trials: Omega incorrectly thinks Fred will play it safe, when actually Fred takes the risk of using the device and, in this case, the device picks one-box
==> Fred gains $1,000,000
==> Omega gains $999,000,000
In 999,900 trials out of 1,000,000 trials Omega correctly thinks that Fred is going to take the risk of using the device. Of those:
In 9,999 trials out of 1,000,000 trials: Omega correctly thinks that Fred is going to take the risk of using the device and, in this case, the device picks two-box
==> Fred gains $1,000
==> Omega gains $999,999,000
In 989,901 trials out of 1,000,000 trials: Omega correctly thinks that Fred is going to take the risk of using the device and, in this case, the device picks one-box
==> Fred gains $0
==> Omega loses $10,000,000,000
Combining those gives an average of:
Fred gains $110
Omega loses $9,888,922,110
If Fred's best estimate, beforehand, of the chances of Omega choosing meta strategy B1 is P, then
Fred's expected gain from choosing meta strategy A1 would be: $1,000,000 P + $999,999 (1-P)
Fred's expected gain from choosing meta strategy A2 would be: $1,000,010 P + $110 (1-P)
We can ask ourselves at what value of P these two strategies would return the same expected gain:
$1,000,000 P + $999,999 (1-P) = $1,000,010 P + $110 (1-P)
$999,889 (1-P) = $10 P
$999,889 = $999,899 P
P = 0.99999
(1-P) = 0.00001
In other words, Fred thinking that Omega has even a 1 in 100,000 chance of being vindictive should be enough to deter Fred from taking the risky strategy.
But how does that look from Omega's point of view? If Omega thinks that Fred's chance of picking meta strategy A1 is Q, then what is the cost to Omega of picking B2 1 in 100,000 times?
Omega's expected gain from choosing meta strategy B1 would be: $999,000,000 Q + $979,008,999 (1-Q)
Omega's expected gain from choosing meta strategy B2 would be: $997,900,100 Q - $9,888,922,110 (1-Q)
0.99999 { $999,000,000 Q + $979,008,999 (1-Q) } + 0.00001 { $997,900,100 Q - $9,888,922,110 (1-Q) }
= (1 - 0.00001) { $979,008,999 + $19,991,001 Q } + 0.00001 { - $9,888,922,110 + $10,886,822,210 Q }
= $979,008,999 + $19,991,001 Q + 0.00001 { - $9,888,922,110 + $10,886,822,210 Q - $979,008,999 - $19,991,001 Q }
= $979,008,999 + $19,991,001 Q + 0.00001 { $9,907,813,211 + $10,866,831,209 Q }
= ( $979,008,999 + $99,078.13211) + ( $19,991,001 + $108,668.31209 ) Q
= $979,108,077 + $20,099,669 Q
Perhaps a meta strategy of 1% chance of two-boxing is not Fred's optimal meta strategy. Perhaps, at that level compared to Omega's ability to discern, it is still worth Omega investing in being vindictive occasionally, in order to deter Fred from taking risk. But, given sufficient data about previous games, Fred can make a guess at Omega's ability to discern. And, likewise Omega, by including in the record of past games occasions when Omega has falsely accused a human player of taking risk, can signal to future players where Omega's boundaries are. We can plot graphs of these to find the point at which Fred's meta strategy and Omega's meta strategy are in equilibrium - where if Fred took any larger chances, it would start becoming worth Omega's while to punish risk sufficiently often that it would no longer be in Fred's interests to take the risk. Precisely where that point is will depend on the numbers we picked in Part 1 of this sequence. By exploring the space created by using each variable number as a dimension, we can divide it into regions characterised by which strategies dominate within that region.
Extrapolating that as δ tends towards 0 should then carry us closer to a convincing solution to Newcomb's Problem.
Back to Part 1 - stating the problem
Back to Part 2 - some mathematics
This is Part 3 - towards a solution
3 comments
Comments sorted by top scores.
comment by [deleted] · 2012-12-06T13:23:19.514Z · LW(p) · GW(p)
Is the ultimate point of this set of posts this:
If you assume Omega has a probability δ of making an incorrect prediction, then your optimal strategy tends to one-boxing as δ tends to 0, therefore you should one-box in the original problem.
It seems like a lot of words to not quite come out and say that, though, so I'm probably missing something.
Replies from: Douglas_Reay, vi21maobk9vp↑ comment by Douglas_Reay · 2012-12-06T13:57:55.589Z · LW(p) · GW(p)
One has to be careful how one does these things.
For example, if you are considering what zero divided by zero is, it matters whether you look at x/0 as x tends to 0, 0/y as y tends to zero, t/t as t tends to zero, or various permutations with approaching it from the negative direction. If you do a 3D plot of z = x / y, you see the whole picture.
The chance of Omega making an incorrect prediction isn't the only variable in the problem. It is just the one that's most often concentrated upon.
↑ comment by vi21maobk9vp · 2012-12-09T17:08:49.139Z · LW(p) · GW(p)
You would say these words if you would want to check whether you have found a "stable" equilibrium.
If you consider that "0 is not a probability", there is a point in checking for that.