Hyperbolic takeoff
post by Ege Erdil (ege-erdil) · 2022-04-09T15:57:16.098Z · LW · GW · 7 commentsThis is a link post for https://www.metaculus.com/notebooks/10617/hyperbolic-takeoff/
Contents
The model Properties The rate parameter Takeoff speeds Smooth transition Conclusion None 7 comments
The debate over "slow" versus "fast" takeoff is one of the more controversial subjects in the AI safety community. The question is roughly about whether AI development will be more gradual, or whether once an AI achieves what could be called "general intelligence", it will be able to rapidly grow its capabilities and within a very short time transform the world in some way, either desirable or not.
The central problem when it comes to thinking about takeoff scenarios is that the reference class is empty: we've never seen anything like an AGI, so it seems very difficult to say anything about what might happen when takeoff gets going. I'll argue that this is not true: while we don't have anything exactly like an AGI, we have lots of different pieces of information which when put together can allow us to pin down what happens after AGI is developed.
The key property of AGI that matters for what happens after takeoff is that AGI is very likely going to be much easier to improve than humans are. Humans have a relatively fixed hardware that's difficult to change much and making more humans is a slow and expensive process. In contrast, an AGI could grow its capabilities both by recursive self-improvement at a much higher frequency compared to humans and by manufacturing or otherwise acquiring new processors to expand its computing power. Both of these processes can happen on timescales much faster than humans are able to make changes to human civilization, so we expect AGI to accelerate all kinds of change once it arrives.
This is already true of contemporary AI systems: we can't run Terence Tao's brain twice as fast even if we throw a billion dollars at accomplishing this, but for any deep learning system that's currently around a billion dollars of compute would be enough to give us enormous speedups. Therefore the expectation that AGI will be much easier to improve is not only theoretical; it's also based on the properties of current AI systems.
The model
The basic model I'll use throughout this notebook is a deterministic hyperbolic growth model. These models are well-known and have been a source of singularity forecasts for a long time, but here I'll use them for a somewhat different purpose.
First, let's motivate the model. Right now, we have a world in which the primary bottleneck in AI development is human effort and time. Insofar as compute and hardware are bottlenecks, they are mostly so because the process of making chips is bottlenecked by the human involvement that's required along the supply chain. Automation of tasks relevant to AI research is currently mostly complementary to human labour, rather than substitutory. This means AI developments don't much affect the speed at which future AI is developed and speedups mainly come from humans scaling up investment into AI progress.
Let be the ratio of the total resources devoted to improving AI systems at any future time to current gross world product, and let be the output that AI systems are currently able to generate in the same units. Then is going to be a function of , and I'll assume here that the function is of hyperbolic form. In this phase, the model looks like
for a rate parameter and an exponent . However, once AI that's capable of substituting for human effort comes along, then we'll be able to use AI itself to improve AI, both directly by searching for better model architectures and training procedures, and indirectly through the impact of AI on the overall economy which creates more resources to be used in AI development. In this scenario, law of motion will instead look like
In the middle there can be an intermediate regime in which we make the transition from one phase to the next, for example as AIs gradually become able to perform more and more tasks that humans are able to perform. The duration of this intermediate regime is also important, but we can actually get quite a bit of information about what the parameters in this model should be by looking only at the two limiting cases.
Properties
First, I'll discuss the properties of the hyperbolic growth model so we can get a better idea of what the two parameters mean. controls the dimension of time: if we change the units of from years to seconds, for example, this amounts to reducing by a factor of the number of seconds in a year. Therefore it's essentially a rate parameter and doesn't affect any dimensionless property of the growth curve. is a dimensionless parameter which controls the degree of acceleration. Any value is going to give us a singularity in finite time in which diverges to infinity.
Importantly, the fact that is dimensionless means that it might be the same for a wide variety of different intelligent systems capable of self-improvement even if some of them run much faster than others. If we ran the history of human civilization a thousand times faster, we'd still estimate the same value of for its overall growth trajectory.
Now, let's move on to the explicit solution of this differential equation. It's given by
If we start at time , how long do we have until the singularity? Solving for this time gives
To illustrate this, here is a concrete example: If we assume a 0.1% annual growth rate for the world economy around 1 CE, we can normalize the dimensions such that the GWP in 1 CE is equal to one unit and we measure time in units of thousands of years. In these units we'll have and so the time to singularity will be in units of thousands of years, or years.
Even allowing for some randomness in this hyperbolic growth model, it's difficult to argue that in light of the singularity that's still not here. David Roodman fits a stochastic version of this hyperbolic growth model to historical gross world product data and comes up with , which seems plausible to me.
The rate parameter
This is the slippery part of trying to estimate this model, but there is a strategy we can use: look at present-day AI systems and compare their rate of improvement with the amount of funding and resources that go into improving them.
More explicitly, if we know that and we know the value of , we just need to find some information on three data points:
- What is the current growth rate of the impact of AI systems?
- How much revenue on the margin do AI systems generate?
- What is the amount of investment currently going into making AI systems better?
Here is a list of sources I've been able to find on the different numbers:
-
Gartner reports that in 2021 AI software has brought in 51 billion dollars in total revenue with an annual growth rate of 14.1%.
-
Tortoise Intelligence says that "total AI investment" has reached 77.5 billion dollars in 2021 compared with 36 billion dollars in 2020.
-
The OECD estimates over 75 billion dollars invested in AI startups in 2020, with funding growth of around 20% from 2019 to 2020.
-
Ajeya Cotra estimates that the total cost of training large deep learning models is likely between 10 to 100 times the reported cost of the final training run. Combining it with the number of large models trained from this spreadsheet, I think we end up with 1 to 10 billion dollars spent on training these models in total in 2021.
-
The Metaculus community currently forecasts that the GPT line of language models making 1 billion dollars of customer revenue over a period of four to five years is the median scenario. Even if this whole revenue was purely due to GPT-3, Cotra's cost multiplier implies that the total cost of creating GPT-3 was anywhere from 100 million to 1 billion dollars. Compared to the ~ 200 million dollars of estimated annual revenue, this means that right now the annual revenue generated by AI models is somewhat less than the cost of investment that goes into them.
Where does that leave us? For the moment I'll work with 2021 revenue equal to 50 billion dollars, 2022 revenue equal to 60 billion dollars and 2021 investment around 100 billion dollars. Again, normalizing to units of fraction of current gross world product, these are and respectively. We can then back out the value of from
We can try to compare this value of to what we would get from a fit to the history of human civilization. Roodman uses different units but his value turns out to be equivalent to in the units I use here. By this calculation, AI is ~ 2 orders of magnitude faster than humans.
Takeoff speeds
Now that we know the values of and , we only need to know how big the world economy will be when AGI arrives. This depends on our belief about AI timelines, but for the sake of argument let's say AGI arrived today and that we devoted all of gross world product to improving it from that moment on. In other words, we're assuming that . (This assumption is fishy and I'll return to it later, but let's take it for granted for the moment.) In this case, the time to singularity would be
In other words, even with a discrete transition from "no AGI" to "AGI" with no smooth intermediate regime, it takes 8 months for us to get a singularity from the time AGI first arrives. I think this argument is moderately strong evidence against takeoff timelines on the very fast end, say with , if they also correspond to a short time until AGI is created so that isn't too large.
While AGI is most likely going to arrive some doublings of GWP from today, we also are unlikely to devote all of GWP to improving it from the moment it's created. These two effects could potentially cancel, especially for shorter timelines of AGI arrival, and a rough estimate of 8 months to 1 year from the time AGI is created to a singularity could end up being quite accurate.
In this regime, let's also examine how long it takes for gross world product to double after the arrival of AGI. The explicit solution for GWP is then
and solving the equation gives . In other words, in this scenario it takes around 70 days for GWP to double after AGI arrives.
However, there's reason to believe this scenario is too biased towards fast takeoff, and this has to do with the initial value . When we set , we're implicitly assuming that we can "spend all of GWP" on the task of improving AI, but in fact if we tried to do this input prices would rise and we'd end up buying much less than the naive ratio would imply. This is essentially because we're running up against real resource constraints which in the short run we can't get rid of by ramping up expenditures. That said, the case at least gives us an upper bound.
I think we can't really devote much more than 10% to 20% of GWP to the task of improving AI, not because of a lack of will but simply because of the effect I mention above. Given this, the above calculations are still valid but they apply to a takeoff scenario that happens after two to three doublings of gross world product rather than today, so it's what we might expect the picture to look like if AGI arrived sometime from 2060 to 2080. This is in line with the Metaculus community forecast on this question.
Finally, let me specify some distributions to quantify my uncertainty about the parameters I've mentioned so far. Roughly speaking, my beliefs are as follows:
Here I separate out into two components: , which is GWP on the year AGI is deployed; and , which is the fraction of GWP that is devoted to improving AIs after the deployment of AGI.
It's now straightforward to sample from this distribution. We get the following cumulative distribution function for :
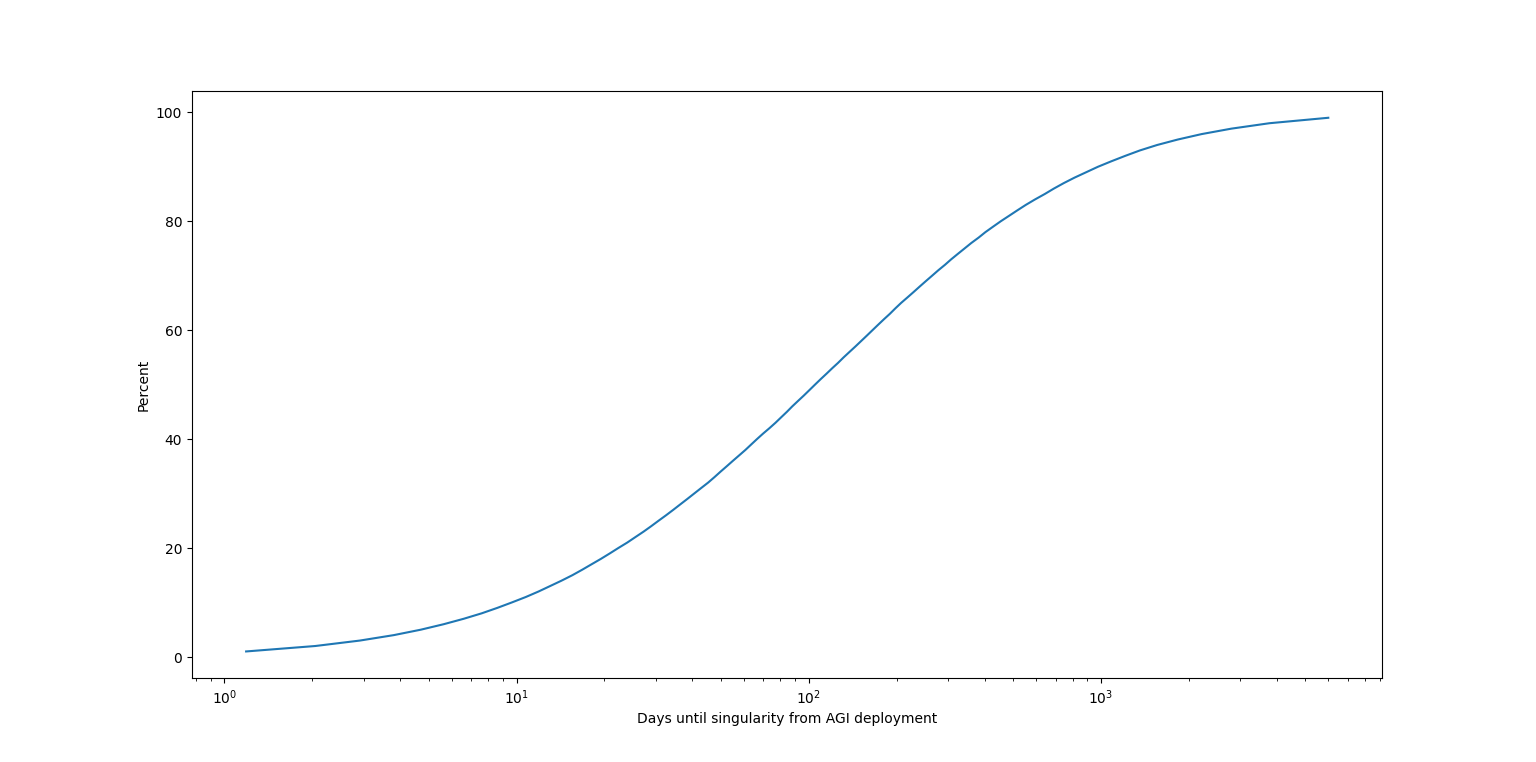
with 25th, 50th and 75th percentiles being around one month, three months and one year respectively. If I change the distribution of to match the community's expectations, I instead get
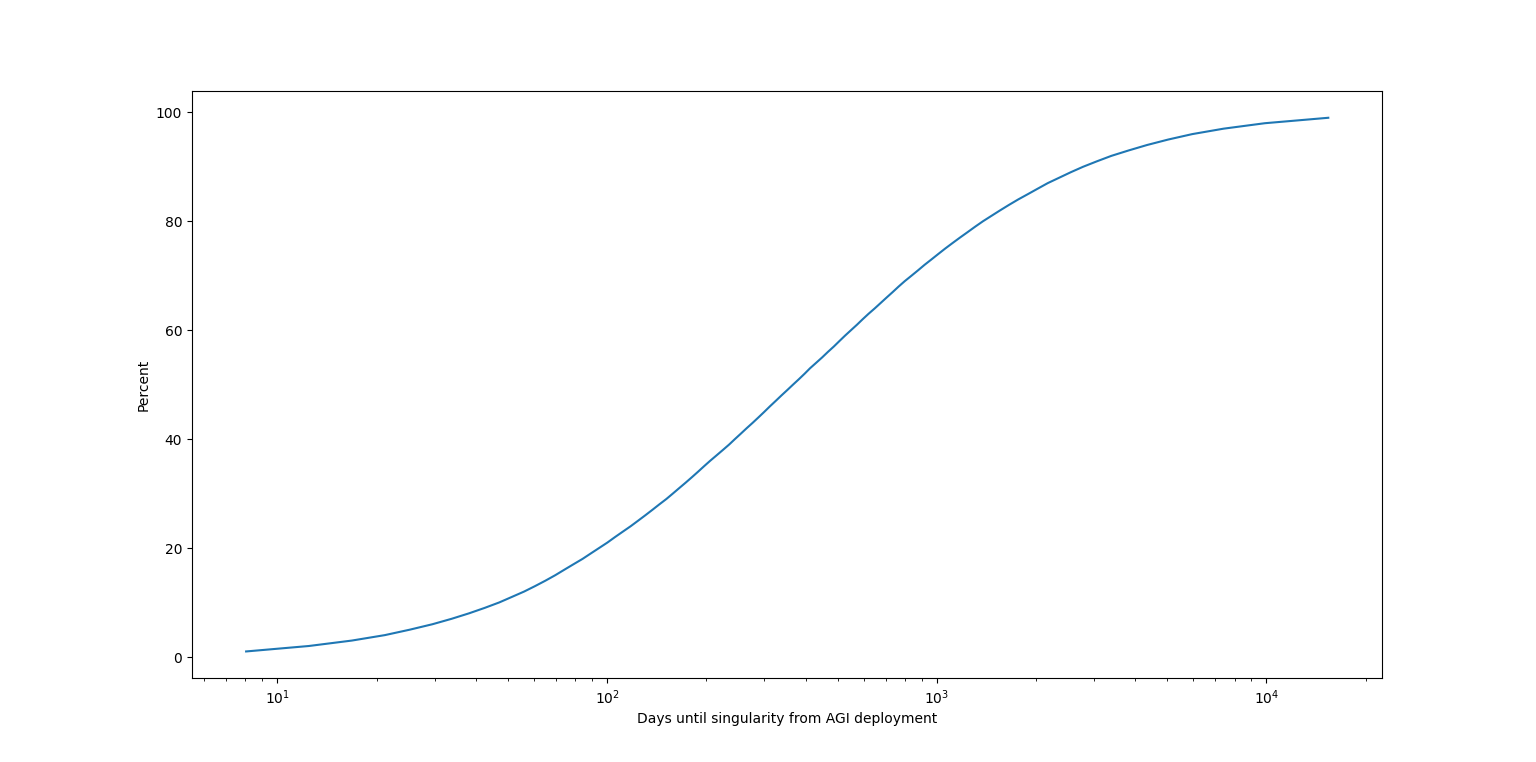
Now the percentiles are all about three times bigger: for the same percentiles as above I now get four months, one year and three years. This is an important point: the later you think AGI deployment will occur, all else equal, the faster you should think takeoff will be.
As a result of all this, I believe that currently the community forecast on this question below is quite underconfident.
Smooth transition
If AI is developed through gradual progress, say by AI gradually becoming as capable or more capable than humans on a wide range of tasks, and if AI development itself is an enterprise which requires a wide variety of such tasks, this will strongly influence our view of how much impact AI will have on the world economy before there is an AGI.
In order to model this, I use
with a time-varying exponent . The point of this model is that I think what we'll actually see is a gradual increase in the exponent in this relationship, and at some critical point we'll cross from the diminishing returns regime of to the hyperbolic growth regime of , where AGI corresponds to . If the rate of increase of is not too fast, I think Paul Christiano's predictions about GWP growth are likely to come true.
Estimating the exact growth schedule of is infeasible with the meager amount of data I've been able to collect for this notebook, but we can still get something out of this model by plugging in some growth schedule for based on views about AGI timelines and some response function of to the state. It's very imprecise but at least it gives a sense of what we can expect when it comes to takeoff speeds.
Here my basic finding is that whether we get slow or fast takeoff depends both on how human effort and the exponent grow over time, but for a wide variety of plausible parameter settings we generally see AGI coming a year or two in advance: a typical growth rate for the year before the singularity is anywhere from 30% to 70%.
The precise questions asked by Paul Christiano turns out to be more uncertain, however: in simulations, sometimes I get "slow takeoff" and sometimes "fast takeoff" if we define these terms in his sense. Another consistent result from the simulations is that we're more likely to see an eight year doubling of GWP before a two year doubling compared to a four year doubling before a one year doubling, which is a difference I didn't anticipate.
With all that said, my final forecasts are as follows:
- AGI has a big impact on economic growth years before the singularity: 95%
- GWP doubles in eight years before it doubles in two: 75%
- GWP doubles in four years before it doubles in one: 50%
Conclusion
I think what's in this essay is only the first word to be said about thinking of takeoff timelines using these hyperbolic growth models. I've oversimplified the model quite a bit and arguably ignored the most interesting question of properly estimating what happens in the intermediate regime. If we can figure out some way to get information about a question roughly similar to "what's happening to over time" that would be quite useful in making inferences about takeoff timelines before AGI is developed.
7 comments
Comments sorted by top scores.
comment by gwern · 2022-04-09T18:06:52.888Z · LW(p) · GW(p)
Ajeya Cotra estimates that the total cost of training large deep learning models is likely between 10 to 100 times the reported cost of the final training run. Combining it with the number of large models trained from this spreadsheet, I think we end up with 1 to 10 billion dollars spent on training these models in total in 2021....The Metaculus community currently forecasts that the GPT line of language models making 1 billion dollars of customer revenue over a period of four to five years is the median scenario. Even if this whole revenue was purely due to GPT-3, Cotra's cost multiplier implies that the total cost of creating GPT-3 was anywhere from 100 million to 1 billion dollars.
Nitpick: It obviously wasn't, though. OA didn't even have $1b to spend on just GPT-3, come on. (That $1b MS investment you're thinking of came afterwards, and anyway, Sam Altman is on record somewhere, maybe one of the SSC Q&As, as ballparking total GPT-3 costs at like $20m, I think, in response to people trying to estimate the compute cost of the final model at ~$10m. Certainly not anywhere close to $1000m.) That multiplier is assuming old-style non-scaling-law based research, like training a full-scale OA5 and then retraining it again from scratch; but what Cotra says about researchers transitioning methods has already happened. What they actually did for GPT-3 was train a bunch of tiny models, like 0.1b-parameter models, to fit the scaling laws in Kaplan, and then do a single 173b-parameter run, so the final model winds up being something like 90% of the compute - the prior work becomes a rounding error. A 2-3x multiplier would be much saner. And this applies to all of those other models too. You think GB trained 10 PaLMs or Nvidia/MS trained 10 Megatron-Turing NLGs, or pilot runs equivalent to? No, of course not.
Compared to the ~ 200 million dollars of estimated annual revenue, this means that right now the annual revenue generated by AI models is somewhat less than the cost of investment that goes into them.
Since you're overestimating many models' costs by factors of like 97x, this means that the revenue generated by AI models is substantially more than their costs.
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-04-09T18:41:59.687Z · LW(p) · GW(p)
I've asked numerous people about this while writing the essay but nobody told me that these estimates were off, so I went ahead and used them. I should have known to get in touch with you instead.
I think Cotra says that the main cost of training these models is not in compute but in researcher time & effort. How many researcher-hours would you estimate went into designing and training GPT-3? An estimate of $20 million of cost for this means for a team of 100 people (roughly the number of employees at OpenAI in 2020) working at $200/hr you estimate maybe ~ 120 full time days of work per person on the model. That sounds too low to me, but you're likely better informed about this, and a factor of 3 or so isn't going to change much in this context anyway.
One problem I've had is that while I mention GPT-3 because it's the only explicit example of a model about which I could find revenue estimates, I think these hyperbolic growth laws work much better with total investment into an area, because you still benefit from scale effects when working in a field even if you make up only a small fraction of the spending. It was too much work for this piece, but I would really like there to be a big spreadsheet of all large models trained in recent years along with estimates of both training costs and estimates of revenue generated by them.
In the end to manage this I end up going with estimates of AI investment & revenue that are on the high end, in the sense that they are for very general notions of "AI" which aren't representative of what the frontier of research actually looks like. I would have preferred to use estimates from this hypothetical spreadsheet if it existed but unfortunately it didn't.
comment by TLW · 2022-04-10T02:19:34.256Z · LW(p) · GW(p)
In contrast, an AGI could grow its capabilities [...] by manufacturing or otherwise acquiring new processors to expand its computing power.
For this to be a solid argument, please explain why Amdahl's Law does not apply.
You cannot take an arbitrary program and simply toss more processors at it. Machine learning is nearly the best case[1] for Amdahl's Law we have in our current regime. Scaling to the extent that you're talking about for AI... it may be possible, but is nowhere near 'simply toss more processors at it'.
- ^
It's "all" just predictable element-wise applications of functions and matrix multiplications, give or take.
↑ comment by Ege Erdil (ege-erdil) · 2022-04-10T09:12:10.497Z · LW(p) · GW(p)
I agree with you that Amdahl's law applies; this claim isn't meant to be read as "it's possible to make programs faster indefinitely by getting more processors". Two points:
-
The final value of that I estimate for AI is only one to two orders of magnitude above the value that Roodman estimates for human civilization. This is much faster, of course, but the fact that it's not much larger suggests there are indeed obstacles to making models run arbitrarily fast that aren't too far off from the timescales at which we grow.
-
I think it's worth pointing out that we can make architectures more parallelizable and have done so in the past. RNNs were abandoned both because of the quadratic scaling with hidden state dimension but also because of backprop through them not being a parallelizable computation. It seems like when we run into Amdahl's law style constraints, we can get around them to a substantial extent by replacing our architectures with ones that are more parallelizable, such as by going from RNNs to Transformers.
comment by TLW · 2022-04-10T02:12:19.411Z · LW(p) · GW(p)
Insofar as compute and hardware are bottlenecks, they are mostly so because the process of making chips is bottlenecked by the human involvement that's required along the supply chain.
[Citation Needed]
Only 20-30%[1] of the cost of a modern fab is labor. This is significant and worth optimizing; this is not what I would consider a key bottleneck.
Replies from: ege-erdil↑ comment by Ege Erdil (ege-erdil) · 2022-04-10T08:59:12.413Z · LW(p) · GW(p)
I think looking at the % of cost that is labor is highly misleading. If you have a Cobb-Douglas production function of labor and capital , then the share of the cost that goes to labor in equilibrium will end up being just since you'll have
So your data implies that we have something like . This will be true regardless of how much labor or capital we have, and if capital is really easy to manufacture on scale while labor is not, you'll end up with a situation where you're bottlenecked by labor even though the share of total cost that's going to labor is low.
To see a concrete example of this, imagine that capital depreciates at a fixed rate as in the Solow-Swan growth model so that . In this case, for fixed you'll eventually have a situation in which your total output isn't enough to replenish the stock of capital that depreciates every year, so you'll end up being stuck below a certain level of total output because of the labor bottleneck. All this time, the share of total costs that go to labor will remain flat at .
Replies from: TLW