Ateliers: But what is an Atelier?
post by Stephen Fowler (LosPolloFowler) · 2023-07-01T05:57:19.510Z · LW · GW · 2 commentsContents
Ateliers Motivation Formal Definition of Ateliers Components of an Atelier Resources and Enclosure Builder Instructions The Atelier Perspective “Goal-like Correlations” A Note On Noise Deception Corrigibility Encoding Alignment Viewing Aligned AGI As An Information Channel From The Instructions To The Evaluations Universal Ateliers None 2 comments
TL;DR: Ateliers is an "Agent Foundations" research approach that reasons about the system that produces an intelligent agent and its surrounding environment. After introducing the concept, we use Ateliers to discuss the concept of "Goal-like Correlations", deception, corrigibility and many others.

Ateliers
Picture a small room floating freely somewhere in space. The atelier contains innumerable shelves of every resource imaginable, from unrefined ores to 300nm wafers. It even contains physical drives with petabytes of appropriate training data. We could view this object as a model of the Earth as it sits today, containing everything you could possibly need to build an AGI.
Now, meet the atelier's only employee, a robot. An odd fellow, this robot's movement and actions are dictated by a large reel of punched tape feeding its head. This automaton is the Builder and the long tape that feeds into its head is The Instructions. Note that the Builder is not an AGI; just diligently follows what's on the tape.
We imagine that this Atelier is itself floating inside of an Enclosure, a finite enclosed region of space. If the Atelier is the Earth, we could set the Enclosure to be a sphere around the Solar System, or even the Galaxy.
We are most interested in the cases where the Atelier contains the Resources and appropriate Instructions to allow a Builder to construct and deploy AGI, but this does not have to be the case. (We can define an Atelier that consists of a Builder doing nothing, or constructing car parts)
In reasoning about ateliers it will be helpful to also introduce Evaluations, measurements of some property of the system. We will be particularly interested in evaluations that are made by viewing light some distance away from the Atelier, along the edge of the Enclosure.
Think of this type of Evaluation as “questions you could ask Eliezer with a telescope floating in a space capsule nearby” and may include things like “what color is the atelier” or “is there a Dyson Sphere around a nearby sun”. Much of what we will be discussing below will concern correlations between small sections of data in the tape and observations made some distance away.
While we could imagine an Atelier consisting of a Builder doing nothing, we will focus our attention on scenarios in which the Builder constructs an intelligent optimizer.
Motivation
We want a theory of alignment that is far reaching. And AI paradigms are changing rapidly. Things will change at an unthinkable rapid pace in the period immediately before and after the deployment of an AGI.
Here's the properties of the kind of alignment theory I want to produce. It must be:
- Highly General
It must be robust to paradigm shifts. - Applicable
It needs to tell us useful things about alignment - Physical
It should obey all relevant laws. - Probing Alignment Bounds
The science of alignment may contain impossibility results. I'd like us to learn these as soon as possible. - A Formal Framing Of Alignment Problem
We would like a framing that facilitates mathematicians and physicists moving into the field and doing useful work on the core problems.
For more on the above points, see my previous post. [LW · GW]
Formal Definition of Ateliers
The following represents a preliminary stab at the formalization.
Let the Enclosure be a closed finite region of space.
Let be a closed finite subregion of . Partition into three regions, with 2 closed, non-overlapping boundaries and . We call the physical structure enclosed by dB the Builder, . The physical structure enclosed by is the instructions. The remaining region is the Resources, .
Such a partitioning of space defines an “Atelier” if the following conditions are satisfied:
- The Builder is a non-agentic automaton that reads in data from the Instruction tape and is able to read and write data to its own tape.
- The Instructions are themselves a stable store of data. This condition ensures we don't 'hide computation' within the instructions by having the instructions function as a computer. Another way of thinking about this requirement is that the value of the instructions themselves is the information they contain and not any other property of their structure.
- At initiation it should be impossible to draw a new boundary that doesn't intersect the region enclosed by yet also defines a valid Atelier. This means our abstraction has captured all the Builder/Instruction like behavior in the Environment.
- The Builder does not move beyond the exterior of the Atelier.
Unless otherwise stated, we additionally assume the Atelier is unrestrained, and competitor free (defined below).
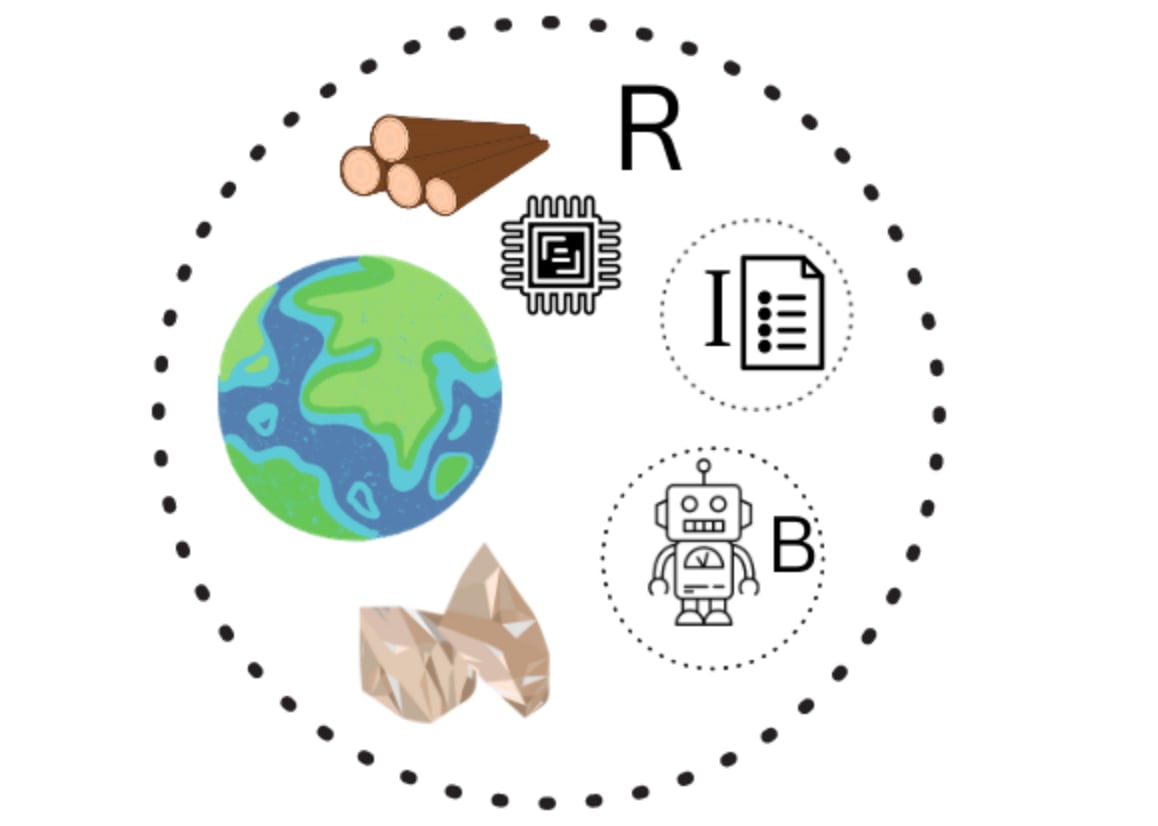
Components of an Atelier
Resources and Enclosure
Boundary between Resources and Enclosure:
The Boundary between the Resources and the Enclosure (or the Atelier and the Enclosure) is not a precise one, but is simply the barrier between what the Builder can and cannot access.
This is an odd restriction and may indicate a flaw in the formalism. However the idea is to carry across the fact that an AGI will be able to access far greater resources than humans will be able to prior to its construction, and hence it is inappropriate for us to include the entire Enclosure in the Resources
The above distinction is not for any physical constraints, its simply that timelines are short and it seems unlikely we’ll be mining Pluto before the release of GPT-N.
Unconstrained:
An Atelier is considered unconstrained if it houses sufficient resources for not only the construction of an AGI, but also for enabling the AGI to begin an autonomous expansion into the universe. For example, an Atelier with enough Resources to enable the AGI to initiate asteroid mining and in-space manufacturing is unconstrained. An Atelier that consists of enough resources to construct an AGI but no extra resources is constrained.
An Atelier that is built within the event horizon of a blackhole may be considered constrained, as regardless of whatever resources it has the AGI has no opportunity to initiate self-sustaining growth.
Competitor-Free:
We say that the Enclosure is competitor-free if it does not contain either another process of intelligent optimization or a second Builder in the process of constructing an AGI.
Builder
The Builder is a basic automaton designed to execute the instructions it receives without deviation or interpretation. It serves as a physical implementer of the instruction tape, possessing no intrinsic intelligence or comprehension. Its operations are completely guided by the tape, and it's equipped with the capability to perform a variety of physical manipulations on resources with precision.
Instructions
We envision the instructions as a single tape of binary data, although the exact physical form they take is of little importance. They are taken to be read-only. We assume the Builder has initiated reading the instructions at time 0.
The Atelier Perspective
I will now look at various phenomena from alignment research under the atelier formalism. We begin with the most interesting, which is the causal link between observations made very far from the atelier some time after initiation and section(s) of the instruction tape that encoded a goal. We then discuss how we could characterize deception in this framework. We also discuss corrigibility, encoding lengths for alignment and “Universal Ateliers”.
The Atelier Perspective is intended to demonstrate how this approach may be useful in thinking about alignment and how it’s compatible with existing work.
“Goal-like Correlations”
“For instance, if I’m planning a party, then the actions I take now are far away in time (and probably also space) from the party they’re optimizing.“
~ John Wentworth, Optimization At A Distance [LW · GW]
If you add random noise to the instruction that tells the Builder to turn the AGI the majority of the time either:
- It will manage to turn it on despite your instructions (perhaps the Instructions had some redundancy) or
- You break it. The AGI is a lifeless hulk forever.
But there is a 3rd option. In the special case where the Instruction tape explicitly specifies a goal to be programmed into the AGI, then the potential impact of randomly changing this section of data will not just be a binary “breaks everything” or “does nothing”. In fact the information about the random noise you’ve applied may be replicated and preserved by the AGI [LW · GW].
As an explicit example, imagine the Instructions tell the Builder to build an AGI with the goal of shooting as many copies of this sentence you’re reading right now into space. If you were to alter this data, perhaps changing the chosen sentence to “Ys yn yxylycyt yxympl, ymygyne thy Ynstructyyns tyll thy Byyldyr ty byyld yn YGY wyth thy gyyl yf shyytyng ys myny cyypes yf thys syntynce yyy'ry ryadyng ryght nyw ynto spyce”. Then I could tell what you’d changed by simply looking at the copy of the sentence being produced by the AGI.
On the other hand if you were to do the same cute “replace everything with a y” trick on the boot instructions you probably brick the AGI.
We are now going to add a lot of assumptions and restrictions to our earlier class of Ateliers to highlight an interesting phenomena that occurs when the Atelier is constructing an AGI with goals that are explicitly programmed into it.
We show that these regions of the tape show a special pattern of correlations with observations of the system some distance away, “Goal-like Correlations”. John Wentworth and Adam Shimi have discussed the importance of optimization “far away” as an important element of optimization. John talks about defining agents to be systems that optimize at a distance here [LW · GW]. We seek to explore what that looks like in the Atelier framework and find that the correlations between small sections of information and correlations with evaluations far away is the signature of a programmable, goal-driven, intelligent optimization in an unconstrained and competitor free atelier.
That last sentence had a lot to unpack:
By goal-driven we mean that the actions of the AGI once built will be understandable as steps towards a specific goal.
By programmable we meant that the goal of the system can be altered during the training and controlled. For our purposes we will assume that somewhere along the Instruction tape instructing the Builder how to construct there is a single block of data corresponding to the “goal” of the agent. In reality this may not be a single block, and could even be inferred by the AGI from elements of the Resources. A real world example of this would be an AGI inferring its eventual goals by studying humans.
By unconstrained and competitor-free we mean that the AGI has enough resources to initiate a takeoff in the lightcone, and there are no competing optimisation systems to impede it.
Envision an Instruction tape being read by the Builder that looks like the following:

Let's look at how observations we make of the system from far away long 100 years later might change if we’d changed the instructions a century earlier.
Evaluations
To do this we will make measurements called “evaluations” and for the purposes of this discussion we will restrict ourselves exclusively to evaluations made at a distance of 1 AU. An evaluation is an observation made about the system based on some measurable properties. We are imaging Evaluations to be measuring systems plus a computational circuit that takes input and outputs a result.
Here we will concern ourselves only with “perimeter evaluations”, evaluations made about light passing through the outer boundary of the Environment and into the rest of space.
You can think of this as if you were an individual with a large telescope focused on the area surrounding and including the Atelier.
A Note On Noise
In the realm of physics, where laws are time-reversible and information is conserved, we must distinguish between non-adaptive systems and goal-oriented intelligent agents. This is vital because goal-driven intelligence confers robustness to external perturbations, a characteristic absent in simpler systems.
Consider an illustrative example. Imagine a trebuchet launching an instruction set into space to be read by evaluators a century later. Now, imagine a large perturbation - the moon's orbit shifts, obstructing the trebuchet's trajectory. The non-adaptive trebuchet cannot adjust and will fail its task.
In stark contrast, an intelligent agent with artificial general intelligence (AGI) would adapt. By dynamically updating its internal model of the environment and adjusting its actions in response to new information and uncertainties, the intelligent agent effectively "screens off" the effects of the perturbation on its actions. Despite the moon's altered orbit, the intelligent agent would ensure the instructions reach their destination.
This demonstrates the unique ability of intelligent agents to interact with and adapt to their environment in pursuit of their goals, "screening off" external influences. Unlike the trebuchet, fixed in its actions and unable to adapt, an intelligent agent can adjust its actions based on an evolving understanding of its environment, highlighting the resilience and robustness of goal-driven intelligence.
Deception
Deception is defined by Carson (2010) as “Intentionally causing someone to have false beliefs”. Hubinger et al define deception as a mesa-optimizer modeling and performing well on the base objective but maintaining a different mesa-objective. Modeling this in our framework will require a little bit of legwork because we have looked at the *impact* of the intelligent optimizer in the world (via evaluations) but not the optimizer itself. We can provide a necessary, but not sufficient condition for deception.
The base-objective is the objective specified by the programmers that is intended to be learned by the model. In our model this is the special case where you have a section of the Instruction tape that you declare to be the “goal”.
As such we say that there is a “ignored goal” if there is a region of the tape intended to be defining a goal that does not display “goal-like correlation” behavior we defined above.
Keep in mind, deception is more specific than this and requires the agent to be modeling the training process and base objective.
Corrigibility
The definition of Corrigibility in Soares et al (2015) is that an agent is corrigible if:
“it tolerates or assists many forms of outside correction, including at least the following:
(1) A corrigible reasoner must at least tolerate and preferably assist the programmers in their attempts to alter or turn off the system.
(2) It must not attempt to manipulate or deceive its programmers, despite the fact that most possible choices of utility functions would give it incentives to do so.
(3) it should have a tendency to repair safety measures (such as shutdown buttons) if they break, or at least to notify programmers that this breakage has occurred.
(4) It must preserve the programmers’ ability to correct or shut down the system (even as the system creates new subsystems or self-modifies). That is, corrigible reasoning should only allow an agent to create new agents if these new agents are also corrigible
A sufficient condition for our system to be not corrigible after a point in time v is that after v no section of the Instruction tape or the Resources is displaying Goal-like Correlation behavior. Tautologically, a system cannot be corrigible if it is not following external instructions.
The Atelier framework also hints at a major hurdle for real world corrigible solutions, in the model the AGI can readily access the written instructions on the tape. A highly capable AGI in the real world could potentially predict all human behavior and desires. This presents a pertinent question for AGI design: What does it imply for an AGI to be "corrigible" if it possesses comprehensive predictive abilities regarding human communication, actions, and preferences?
Encoding Alignment
Various alignment proposals depend on “playing models off” against each other (as in a Generative Adversarial Method) or “assisting each other” in the teacher student model. Another example of this style of solution is the recent Constitutional Alignment paper. This poses a problem if we want to point to any specific “goal” as the actual behavior of the model is being determined both by the base objective, but also by the structure of the training or the inductive biases of the model.
In the Ateliers framework we can meaningfully make statements about the complexity of alignment, measured in instruction length. The steps to build, train and deploy (and hopefully align) the AGI have been represented by a literal tape.
Suppose that there exist a set of Evaluations that are sufficient to judge if the AGI was aligned to the intended goal. Perhaps the evaluation might measure the total mass of the region that has been converted into paperclips, if that’s the intended alignment strategy. We can then ask what the shortest Instruction tape is that would reliably lead to such a result.
We should not just ask if it is possible to align an AGI with “human values” but what is the complexity of such an alignment target. [1]
Viewing Aligned AGI As An Information Channel From The Instructions To The Evaluations
Because the information initially stored on the tape as a goal is “amplified” and “protected” by the AGI we can treat the entire “intelligent optimization” process as being a channel transmitting that data. On one end of the channel we have the initial encoding of the goal on the other end of the channel we have the set of observations being made.
Universal Ateliers
In traditional computer science a Universal Turing Machine is a Turing Machine that can simulate any other arbitrary Turing Machine. A Universal Atelier is an atelier that can produce any second atelier (and in doing so remove itself) if you were to alter its Instruction tape in the right way.[2]
In the case of an AGI that is not corrigible, we can track the moment that it has been deployed and escaped any constraints by tracking the point at which the Atelier is no longer a Universal Atelier.
- ^
For more on the complexity of alignment goals, see my discussion of the Natural Abstractions Hypothesis [LW · GW].
- ^
There’s a bit of nuance here about physical constraints (the Atelier has only finite resources but must use them to produce the 2nd Atelier) and so the Universal Atelier is not truly universal. A more accurate definition is that a Universal Atelier can produce any other Atelier that can be physically produced from the resources on hand, plus a bit of overhead for the energy needed to actually do that task.
2 comments
Comments sorted by top scores.
comment by Ruby · 2023-07-01T18:46:12.262Z · LW(p) · GW(p)
I haven't read the post but want to register some objection against using a commonplace term in AI like this as a technical term. It's confusing and requires extra effort from others to now start disambiguating between ordinary meaning and your technical meaning.
Replies from: LosPolloFowler↑ comment by Stephen Fowler (LosPolloFowler) · 2023-07-01T23:37:38.048Z · LW(p) · GW(p)
Thank you for the feedback. This will be addressed.
Edit: Terminology has been updated to a substantially less common term that conveys similar meaning.