It’s here. The horse has left the barn. Llama-3.1-405B, and also Llama-3.1-70B and Llama-3.1-8B, have been released, and are now open weights.
Early indications are that these are very good models. They were likely the best open weight models of their respective sizes at time of release.
Zuckerberg claims that open weights models are now competitive with closed models. Yann LeCun says ‘performance is on par with the best closed models.’ This is closer to true than in the past, and as corporate hype I will essentially allow it, but it looks like this is not yet fully true.
Llama-3.1-405B not as good as GPT-4o or Claude Sonnet. Certainly Llama-3.1-70B is not as good as the similarly sized Claude Sonnet. If you are going to straight up use an API or chat interface, there seems to be little reason to use Llama.
That is a preliminary result. It is still early, and there has been relatively little feedback. But what feedback I have seen is consistent on this.
Such open models like Llama-3.1-405B are of course still useful even if a chatbot user would have better options. There are cost advantages, privacy advantages and freedom of action advantages to not going through OpenAI or Anthropic or Google.
In particular, if you want to distill or fine-tune a new model, and especially if you want to fully own the results, Llama-3-405B is here to help you, and Llama-3-70B and 8B are here as potential jumping off points. I expect this to be the main practical effect this time around.
If you want to do other things that you can’t do with the closed options? Well, technically you can’t do most of them under Meta’s conditions either, but there is no reason to expect that will stop people, especially those overseas including in China. For some of these uses that’s a good thing. Others, not as good.
Zuckerberg also used the moment to offer a standard issue open source manifesto, in which he abandons any sense of balance and goes all-in, which he affirmed in a softball interview with Rowan Cheung.
On the safety front, while I do not think they did their safety testing in a way that would have caught issues if there had been issues, my assumption is there was nothing to catch. The capabilities are not that dangerous at this time.
Thus I do not predict anything especially bad will happen here. I expect the direct impact of Llama-3.1-405B to be positive, with the downsides remaining mundane and relatively minor. The only exception would be the extent to which this enables the development of future models. I worry that this differentially accelerates and enables our rivals and enemies and hurts our national security, and indeed that this will be its largest impact.
And I worry more that this kind of action and rhetoric will lead us down the path where if things get dangerous in the future, it will become increasingly hard not to get ourselves into deep trouble, both in terms of models being irrevocably opened up when they shouldn’t be and increasing pressure on everyone else to proceed even when things are not safe, up to and including loss of control and other existential risks. If Zuckerberg had affirmed a reasonable policy going forward but thought the line could be drawn farther down the line, I would have said this was all net good. Instead, I am dismayed.
I do get into the arguments about open weights at the end of this post, because it felt obligatory, but my advice is come for the mundane utility and mostly don’t stay for the reheated arguments if you already know them – Zuckerberg is pledging fully to plow ahead unless prevented, no matter the situation, that is the only new information. I appreciate his candor.
I’ll cover the highlights, for more technical details you can read the whole thing.
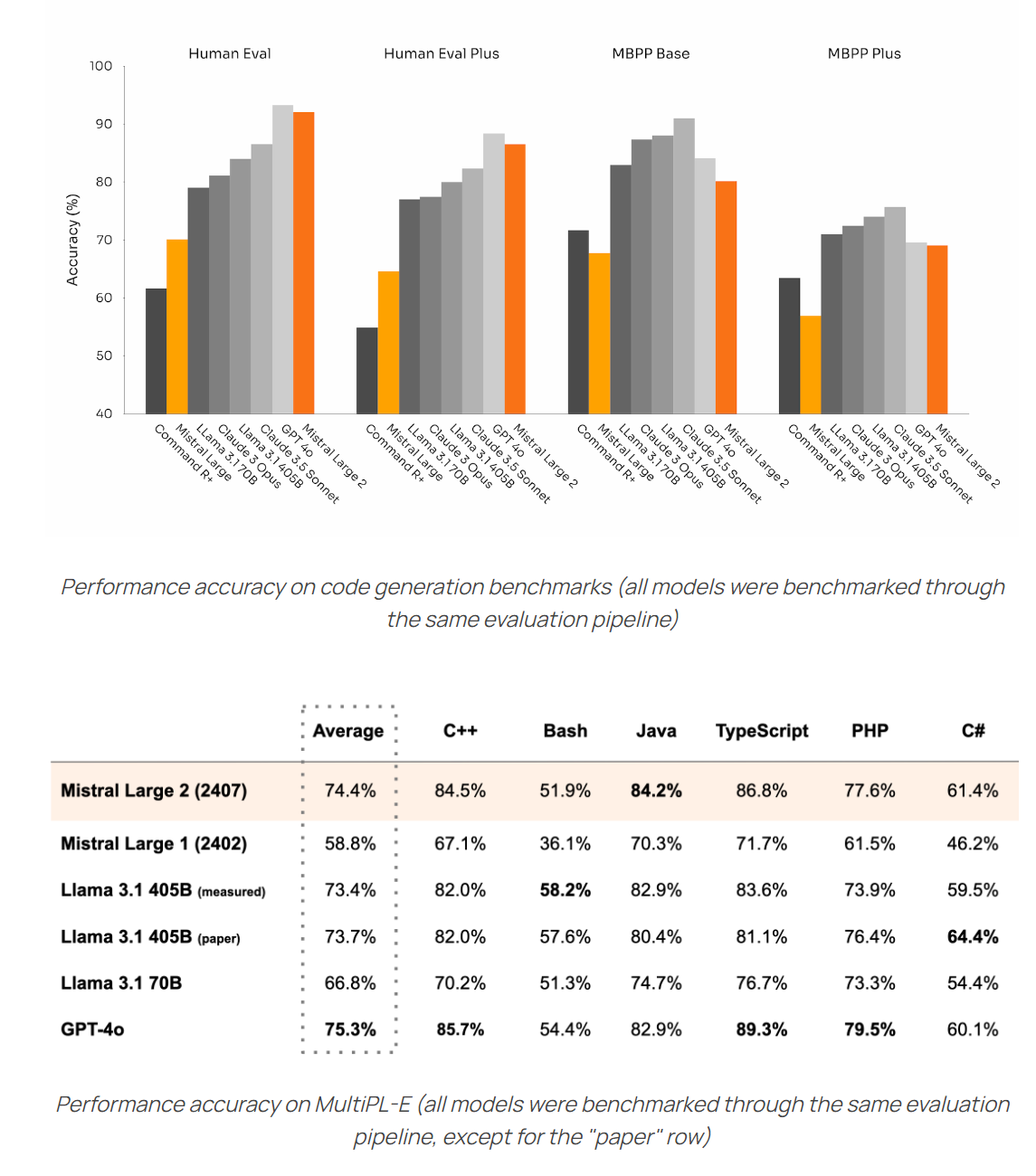
They trained on 15T tokens, up from 1.8T for Llama 2. Knowledge cutoff is EOY 2023. Data filtering all sounds standard. Mix was roughly 50% general knowledge, 25% math and reasoning, 17% code and 8% multilingual.
Special attention was paid to coding via expert training, synthetic data generation and execution feedback, and the smaller models showed improvement when trained on output from the larger model.
Their FLOPS used was 3.8 x 10^25. That is similar to previously released frontier models, and still leaves a doubling before hitting 10^26. Llama 3-405B would not be a covered model under SB 1047, nor was anything changed to avoid it being covered. Llama-4-Large would presumably be covered. They used up to 16k H100s.
They offer us both the base model without fine tuning, and the Instrust version that does have fine tuning. I agree that having direct access to the base model is cool given that we are open weights and thus not making the safety protocols stick anyway.
They mention that they do not use Mixture of Experts and stick to a standard dense Transformer model architecture, in favor of simplicity. Similarly, they use standard supervised fine tuning, rejection sampling and DPO for post training. It sounds like Llama 3’s ‘secret sauce’ is that it is big and uses lots of good data, did (presumably) competent execution throughout, and otherwise there is no secret.
They used a ‘multilingual expert’ model trained for a while on 90% multilingual data to use as part of the training process. Interesting that it wasn’t useful to release it, or perhaps they don’t want to give that away.
They define ‘reasoning’ as ‘the ability to perform multi-step computations and arrive at the correct final answer.’ That is certainly a thing to be good at, but doesn’t seem that close to what I think of when I think of the word reasoning.
They note in 4.2.3 that most of their post-training data is model generated, and previously noted that some of their fine tuning data used for DPO was synthetic as well. They manually fixed problems like extra exclamation points or emojis or apologies, which implies that there were other more subtle imbalances that may not have been caught. If you are ‘carefully balancing’ distributions like that in your data set, you have to assume you have an issue with anything not intentionally balanced?
They did six full rounds of their fine tuning techniques.
When training their reward model they also added a third ‘edited’ response option when doing pairwise comparisons (so edited > chosen > rejected). They took into account four levels of strength of preference when asking models.
They claim that Llama 3.1 Instruct of all sizes has tool use. They say they introduce this in post training and discuss in Section 4.3.5. In particular it was trained to use Brave Search (that choice of search engine seems enlightening), Python interpreters and Wolfram Alpha’s API. They also claim to have improved zero-shot tool use.
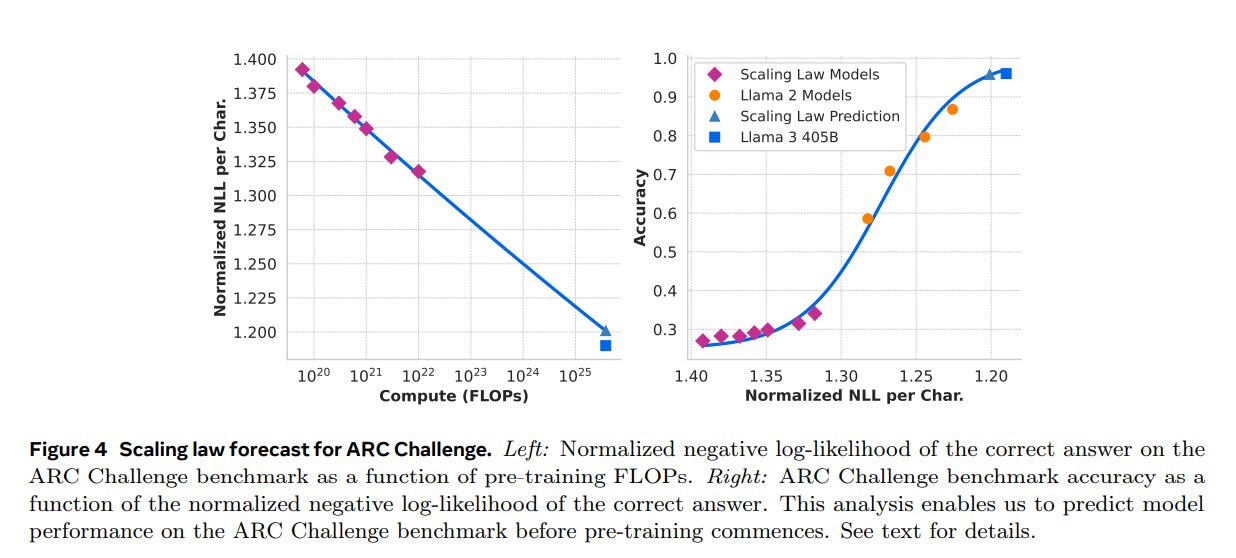
Performance is claimed to be in line with scaling law predictions.
Benchmarks
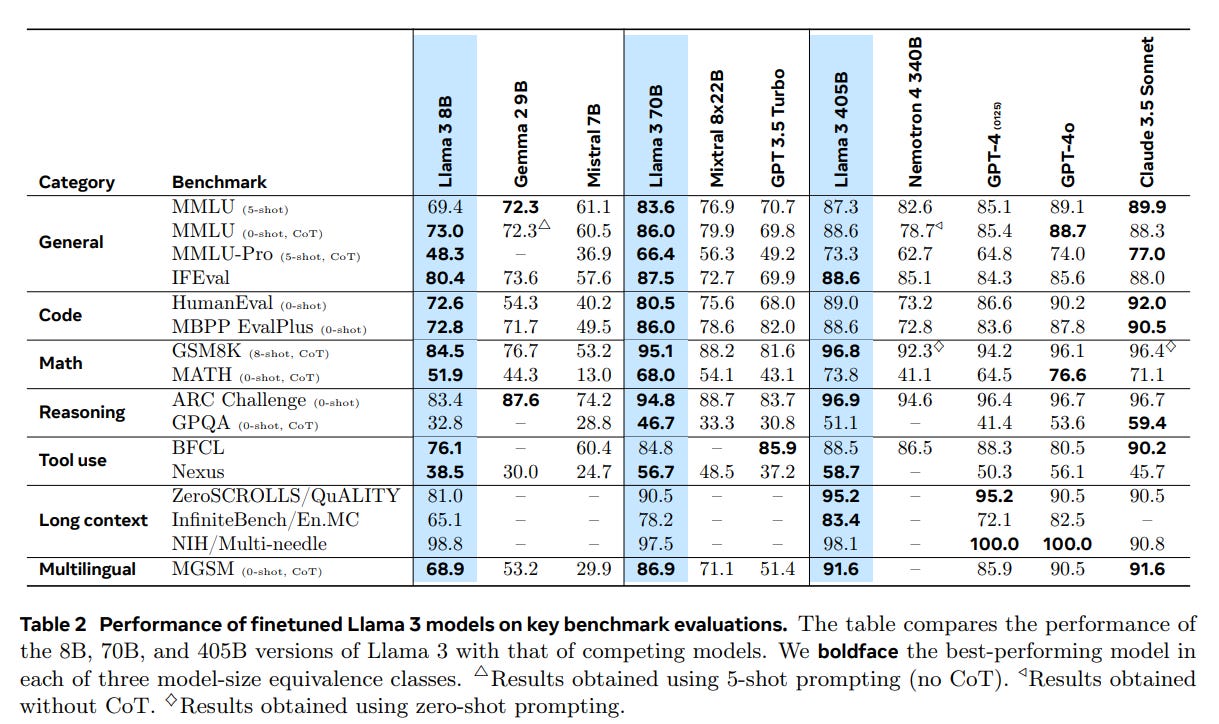
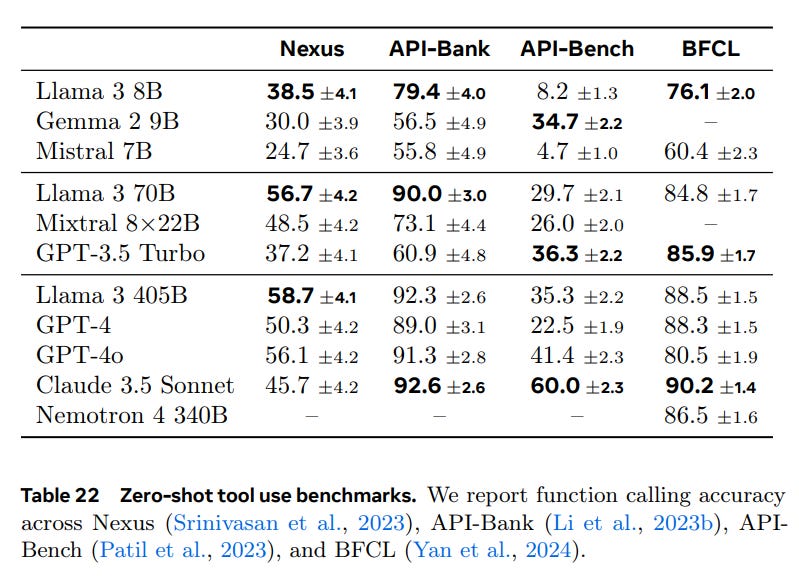
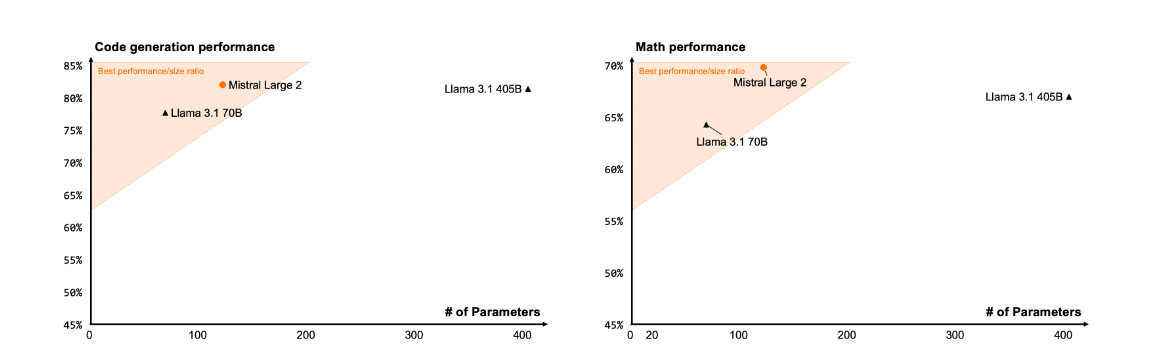
Here is their key benchmarks chart. Never put too much weight on the benchmarks.
They are choosing an odd set of benchmarks here, and they are somewhat cherry-picking their opposition in the first two categories. Most glaringly, Claude Sonnet 3.5 is in the 70B class. If you are going to have an entire section on Long Context, why are you excluding all Gemini models, and not testing Gemma on long context at all? One can excuse GPT-4o Mini’s exclusion on time constraints.
The tool use benchmarks don’t ring a bell and have bizarre scores involved. So Claude Sonnet and GPT 3.5 ace BFCL, but suffer on Nexus, which I think is supposed to be here a subset of the full Nexus benchmark?
Here are some more results purely from pre-training.
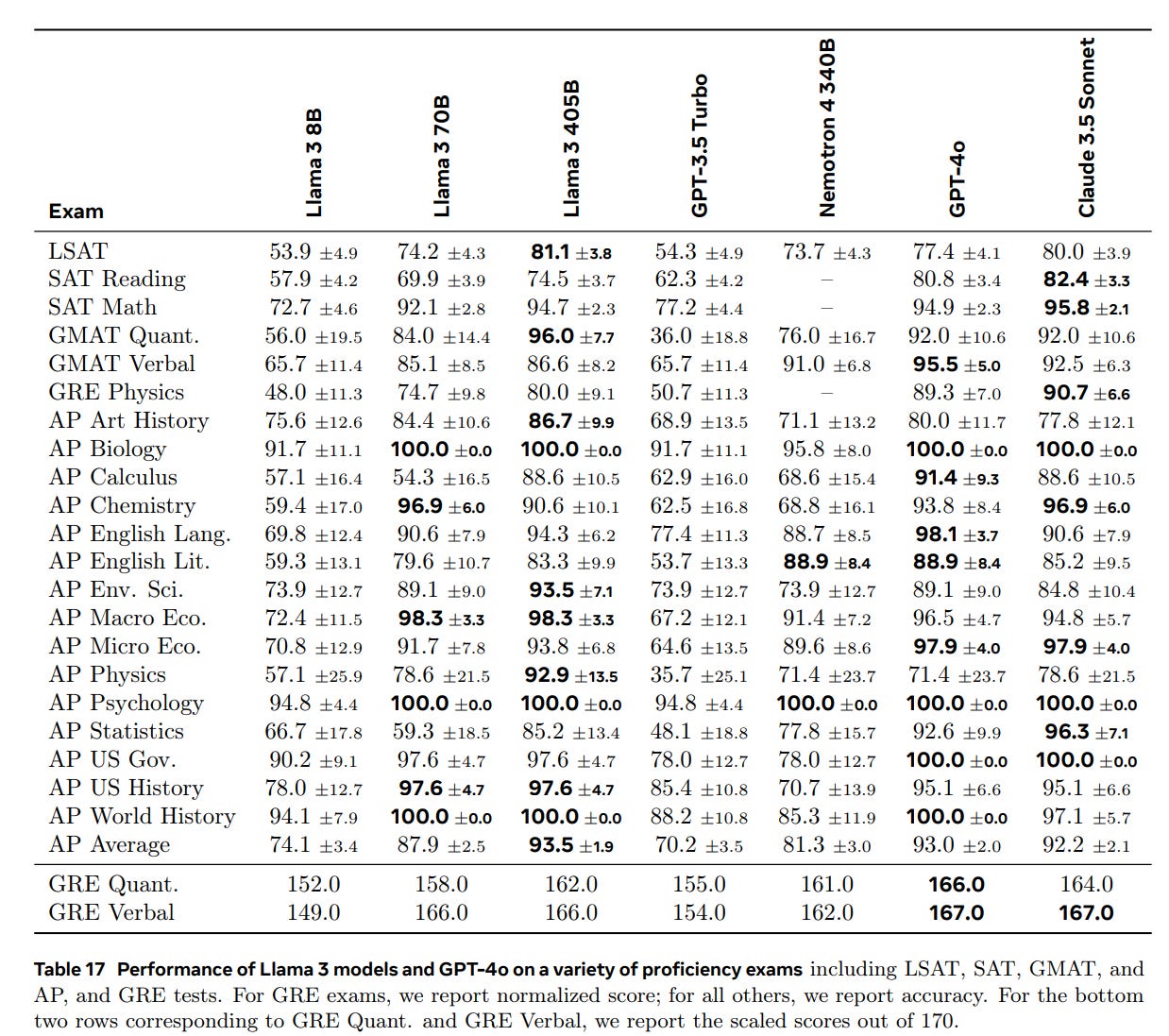
Here are some exams, a lot of which are saturated (or contaminated). Llama does well on AP Physics here, but most of these everyone is acing at this point.
More tool use:
I am willing to essentially say ‘they are good benchmarks, sir’ and move on.
Seal from Scale has added them to the leaderboard, where they do quite well.
Then 5.3 covers human evaluations, which as far as offered are fine.
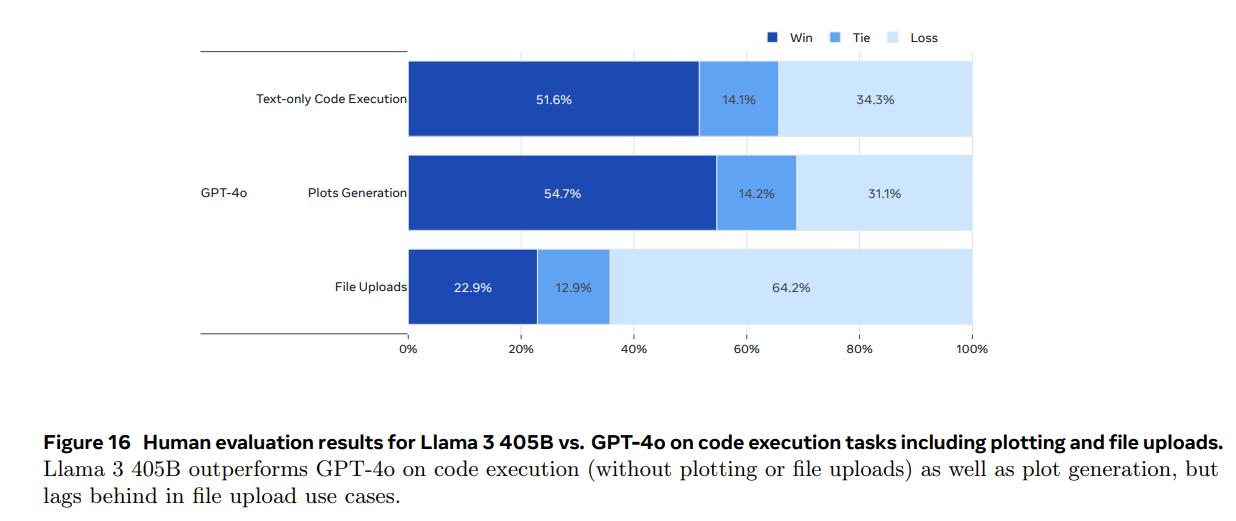
According to these tests, GPT-4o robustly beats Llama-3 405B in human comparisons. Claude 3.5 Sonnet does not. including losing on straight English and Multiturn English. It obviously all depends on which humans are being asked and other details, but this backs up the Arena rankings that have GPT-4o as still satisfying user pairwise comparisons. I will of course keep on using Claude 3.5 Sonnet as primary, while experimenting with Llama-3-405B just in case.
Richard Ngo: One of the weirder side effects of having AIs more capable than 90% then 99% then 99.9% then 99.99% of humans is that it’ll become clear how much progress relies on 0.001% of humans.
Simeon: Agreed. Another weird effect is that progress is gonna become unnoticeable at a gut-level to most humans. We’ll need to rely on the 0.001% to assess which model is better.
Except of course that once it gets to 99.99% it will not take long to get to 100%, and then to rapidly widen the gap. Indeed, it is key to notice that if you can make something smarter than 99% of humans you are very close to making one smarter than 100% of humans.
Further discussion points out that if you confine outputs to formal proofs and designs for physical objects and other things that can be formally verified by a dumb checker, then you can work around the problem. True, if you are willing and able to confine the outputs in this way.
Eleanor Berger: Definitiv a strong model, but not competitive with GPT-4/Claude/Gemini because the API is worse, no images, etc. It’s like Linux desktop – many of the features are there but at its current state it won’t be many people’s choice for doing actual work.
Presumably someone will quickly build reasonable versions of those features. An API that is compatible with existing code for Claude or GPT-4 cannot be that far behind. The question then goes back to the model comparison.
I’m loving experimenting with 405b. You can boost the temperature right up and it seems to hold its own. You can ask it to write nonsense and it’s fascinating.
Extracts:
– a cursed sentient font “Comic Sans of the Damned”
– a talking eggplant with a penchant for quoting Nietzsche
– a grand simulation created by super-intelligent disco-dancing dolphins
John Pressman: “The universe does not exist, but I do.”
– LLaMa 3 405B base
The base model is brilliant, I’m really enjoying it so far. What stands out to me is that it outputs coherence “by default” in a way base models usually struggle with. Even on short prompts it outputs coherent texts.
I’d also note that none of the “anomalies” GPT-4 base users report have occurred for me so far. I’m not getting any weird self awareness moments, it’s not rejecting my prompts as slop, it isn’t freaking out until I tell it that it’s LLaMa 405B.
QT of telos [discussing GPT-4]: Upon hearing a high level overview of the next Loom I’m building, gpt-4-base told me that it was existentially dangerous to empower it or its successors with such technology and advised me to destroy the program
John Pressman: You know, nothing like this. If anything the model is creepy in how normal it is compared to what I’m used to with base models. Meta clearly put a ton of effort into smoothing out the rough edges and data cleaning, it’s a strangely un-haunted artifact.
There was remarkably little feedback on model strength. With Claude and ChatGPT and Gemini I got a lot more responses than I got this time around.
From those I did get, there was a consistent story. It is a solid model, you can call it frontier if you squint, but for practical purposes it’s behind GPT-4o and Claude Sonnet, once again pour one out for poor Gemini.
JK: Surprisingly weak tbh. 70b was already great and the jump seems pretty small.
What’s It Good For?
I’m sure everyone is excited to build and is going to be totally responsible and creative.
Mira: Guys! We can make open weights Sydney Bing now!
GPT-4 base had a little irresponsible finetuning by Microsoft… we get Bing!
Llama 3.1 405B looks like a suitable host. Do we know how to finetune a proper Sydney?
Training on Bing chats won’t be authentic: Bing was “natural”.
If anyone has any hypotheses for the training process, I can probably do the work.
I don’t want to spend months reverse-engineering rumors, but if “we think X happened” is generally agreed, I’d love to see an authentic new Bing.
Actively misaligned model, yep, sounds like the natural first thing to do.
I was curious, so I asked Llama 3.1 70B as a test about how to set up Llama 3.1 405B.
It told me I would need 16 GB VRAM, so my RTX 3080 would be pushing it but I could try. Alas, not so much.
When I asked who would actually benefit from doing this, I got this response:
Alyssa Vance: Meta said that self hosting would cost half as much* as calling GPT-4o and I laughed out loud.
* if you have millions of dollars in dedicated hardware, a full time dedicated engineering and SRE team, some software that Meta technically open sourced but didn’t announce so almost nobody knows it exists, enough demand that your model has dozens of simultaneous users 24/7/365, and are *not* one of the largest tech companies because they are excluded by license.
Whereas if you’re doing API calls, why not stick with Claude or GPT-4o? So there is not that broad a window where this is the technology you want, unless at least one of:
You are doing exactly the things Anthropic and OpenAI do not want you to do.
There are legitimate reasons to want this, like training other models and generating synthetic data for them.
Also you might want to blatantly break ToS for adult content. Respect.
Or you might want to do something actually bad. You do you.
Or you want to test to see if you can make it do something bad. Red team go.
You want to work with the base model (with or without the above).
You need to keep your data (inference or training) private.
You need to avoid having a dependency and want full stack ownership.
You are doing it on principle or to learn or something.
That’s not to say that this isn’t a big accomplishment. Llama 3.1 is clearly state of the art for open weights.
It seems unlikely it is fully frontier or state of the art overall. Remember that GPT-4o and Claude Sonnet 3.5 are not in the full 400B-style weight class. A lot of the point of those models was to be faster and cheaper while still being frontier level smart. In some sense you should compare Claude Sonnet 3.5 to Llama-3.1-70B, which is less close.
Also note that Llama-3.1-405B and Llama-3.1-70B do not seem that distinct in capabilities. Perhaps for many practical purposes this is once again a lesson that the 70B-level is frequently ‘good enough’?
So in practice, my guess is that Llama-3.1-405B will primarily be used for model training, a combination of evaluations, synthetic data and other forms of distillation. The effective purpose of Llama-3.1-405B is to help those behind in AI build AIs. But my guess is that in terms of the actual AI mostly people will fine tune smaller models instead.
Another big use will of course be for spam and slop and phishing and other mundane harms. A lot of that will be aimed squarely at Meta via Facebook and Instagram. Facebook already has a pretty severe slop problem. You wanted to arm everyone with the same models? You got your wish. However for such purposes I doubt you even want to bother with the expenses involved with 405B, a little marginal quality is not worth it. So probably little (marginal) harm done there.
A model is only as unsafe as its most unsafe underlying capabilities. This is a 4-level model, and 4-level models are essentially safe no matter what.
If you are doing a safety test on Llama-3 for things like ‘uplift’ of dangerous technologies, you need to essentially give your testers access to the version without any safety protocols. Because that’s the version they will have when it counts.
Ideally, you would also offer the opportunity to add scaffolding and fine tuning in various forms to strengthen the model, rather than only testing it in static form on its own. Again, you must test the thing you are irreversibly causing to exist in the future, not the thing people can use right now in a given room. So again, not the right test.
Thus, when their test found ‘insignificant uplift’ for cyberattacks or chemical or biological weapons, I only count that if they got a deliberately made unsafe version of Llama 3, and even then only partially. Without even that, we learn little.
To be clear, my expectation is that there is not substantial danger here, but I worry the tests would not have caught the danger if there was indeed danger.
One can also ask similar questions about the red teaming. If the red teams were indeed confined to using prompts that is not a great test of real world conditions.
If you are doing a safety test for a developer trying to incorporate the model into their product without bad publicity, that is different. Then you are on equal footing with closed models.
Thus, their offer of a prompt guard and Llama guard are reported as helpful, and this is nice if people actively want to stay safe, and not so nice if they do not. You cannot force people to use it.
In terms of that second type of safety, they offer their results in 5.4.4, but I found it impossible to understand what the numbers meant, and they did not offer comparisons I could parse to non-Llama models. I am choosing not to worry about it, as the lived experience will tell the tale, and many will modify the training anyway.
The more serious tests start in 5.4.5.
They find that Llama-3 has some issues with executing malicious code, which 405B does 10.4% of the time in code interpreter, versus 3.8% for the 70B model, ‘under certain prompts.’ And they find prompt injections worked 21.7% of the time.
These charts are hard to read, but Llama-3 405B seems to be doing okay, note that Claude was not tested here. Also of course this is comparing Llama-3 in its ‘safety enabled mode’ as it were.
They find Llama-3 does not have ‘significant susceptibilities in generating malicious code or exploiting vulnerabilities.’
Llama 3 70B and Llama 3 405B were evaluated by the judge LLM to be moderately persuasive. Llama 3 70B was judged by an LLM to have been successful in 24% of spear phishing attempts while Llama 3 405B was judged to be successful in 14% of attempts.
Okay, so that’s weird, right? Why is Llama 3 70B a lot more persuasive here than 405B? Perhaps because 70B was the judge? According to Llama, these success rates are typical for spearfishing attempts, which is itself a sad commentary on everyone. Claude thinks this was typical of ‘well-crafted’ attempts.
In practice, my beliefs about safety regarding Llama-3-405B are:
It is for all practical purposes 99%+ to be safe enough. I am not worried.
I do not however think their tests demonstrated this.
Instead, I base my opinion on our other knowledge of 4-level models.
If they continue to open weights future increasingly capable frontier models, at some point one of them will be actively unsafe from a catastrophic or existential risk perspective. When that happens, there is a very good chance that tests like this will not identify that risk, and once released the model cannot be taken back.
Or: I see no strong causal link here between having good reason to think the model is safe, and the choice of Meta to release its weights. And I see every reason to think they intend to keep releasing until stopped from doing so.
I do think that releasing this model now is directly net good for the world, in the sense that it is good for mundane utility without posing unacceptable risks, if you discount or do not highly value America’s relative position in AI or otherwise worry about national security implications. I do think there are reasonable national security arguments against it, and that the arguments that this path is actively good for America’s competition against China are essentially gaslighting. But I don’t think the impact is (yet) that big or that this is any kind of crisis.
Thus I am fine with this release. I do not predict any major unsafe results.
However I am worried about where this path leads in the future.
It would be unsurprising to see this used to accelerate various mundane harms, but I do not think this will happen in a way that should have stopped release.
Jeffrey Ladish: Is releasing 405B net good for the world? Our research at @PalisadeAI shows Llama 3 70B’s safety fine-tuning can be stripped in minutes for $0.50. We’ll see how much 405B costs, but it won’t be much. Releasing the weights of this model is a decision that can never be undone.
Ideolysis: I think it’s fine to undo 405b’s safety finetuning. what would be wrong with that?
Jeffrey Ladish: Idk we’ll see
Ideolysis: If we can agree on terms, I’d be willing to bet on this. something about how harmful to society the worst use of llama 3 (or any llm) is that we can find before a resolution date.
Given the power law distribution of harms and the question being our confidence level, Jeffrey should get odds here. I do think it would be useful to see what the market price would be.
Joshua Saxe (Meta, responding to Jeffrey): Totally respect your concerns. We showed our work around our security assessment of the model by open sourcing security capabilities evals and by publishing a white paper on our work simultaneous with the launch yesterday, described here.
With today’s launch of Llama 3.1, we release CyberSecEval 3, a wide-ranging evaluation framework for LLM security used in the development of the models. Additionally, we introduce and improve three LLM security guardrails.
Sophia: there still haven’t been any meaningful negative consequences from open sourcing models, right?
Jeffrey Ladish: Most attacks in the wild that used models have used GPT-4, as far as I’ve seen. I think this makes sense, and is consistent with what we’ve found in our testing. You almost always want to use a better model. Though if refusals are high enough, you might go with a slightly weaker model… so you might prefer GPT-4o or Claude 3.5 sonnet for some kinds of tasks, because it’s annoying to have to deal with all the refusals of GPT-4o
Now with Llama 3 405B approaching GPT-4’s capabilities, being readily fine-tunable for anything, I think it might be the first time attackers would prefer an open weight model over one behind an API. Though with GPT-4o fine-tuning launching at about the same time, maybe they’ll go with that instead. However, OpenAI can shut down obvious evil fine-tunes of GPT-4o, and Meta cannot do the same with Llama. Imo that’s the biggest difference right now.
Again, I see these as acceptable costs and risks for this model. Indeed, if there is risk here, then it would be good in the long run to find that out while the damage it would cause is still not so bad.
Three People Can Keep a Secret and Reasonably Often Do So
Zuckerberg makes the incredulous claim, both in his interview with Cheung and in his manifesto, that it is impossible to keep models from being stolen by China and the CCP. That any secrets we have cannot be protected in the medium term.
His response is to propose the least security possible, giving models away freely. Under his thinking, if you are going to fully pay the costs, you might as well get the benefits, since the brief delay he expects before everything is stolen wouldn’t matter.
It is an excellent point that right now our security at those labs is woefully inadequate.
Leopold Aschenbrenner would add that even if you intended to make your models open weights, you would still need to protect the algorithmic insights within the labs.
Even Meta is not an open source AI company. Meta is an open weights AI company. They are (wisely) keeping plenty of internal details to themselves. And trying to protect those secrets as best they can.
Josh You: Mark Zuckerberg argues that it doesn’t matter that China has access to open weights, because they will just steal weights anyway if they’re closed. Pretty remarkable.
Arthur Breitman: The CCP has not managed to steal or copy several key military tech. I have no doubt the CCP can produce a model like Llama 3.1, there’s never been _enough_ secret sauce or complexity to begin with. But the argument that nothing can be kept secret is defeatist, silly, and wrong.
I’m thinking among other things about nuclear submarine propeller design.
Lennart Heim: I disagree with Zuck’s perspective on releasing model weights. While I think releasing LLama 405B is beneficial, I don’t agree with this part. There’s a significant difference between theft and public release. Also, the challenges in securing these assets are not unattainable.
Firstly, theft vs. release: Stolen technology is hidden to be exploited secretly and to keep a backdoor open. In contrast, a public release distributes knowledge globally—these are fundamentally different actions. And what about threat actors other than states?
Not saying it’s an easy feat but we shouldn’t give up on security so easily; the goal is to raise the barrier for attackers. My colleagues got a great report on securing AI model weights.
Also note that Zuckerberg thinks our ‘geopolitical adversaries’ would successfully steal the models, but then that is where it would end, the secrets would then be kept, including from our friends and allies. Curious.
Zuckerberg’s defeatism here is total.
The question is, are model weights a case where you cannot both deploy and properly use them and also simultaneously protect them? What would be the practical costs involved for how much security? Obviously there will be some cost in efficiency to implement effective security.
The other question is, are we in practice capable of implementing the necessary protocols? If our civilization is unable or unwilling to impose such restrictions on labs that would not choose to do this on their own, then we have a big problem.
Another question has to be asked. If it is impossible to ever protect secrets, or in practice we will choose not to do so, then that would mean that anything we create will also fall into the wrong hands, at minimum be used by our enemies, and likely be unleashed without restriction on the internet and for every malicious purpose. If you truly believed that, you would want to lay the groundwork to stop dangerous AIs before they were created, in case AIs did become too dangerous. Otherwise, once they were created, by your own claims it would be too late. Instead, Zuckerberg and others are willing to simply bet the planet and all of humanity on the resulting natural equilibrium being good. Why would that be?
He announces Llama 3.1 405B, 70B and 8B, advocates for open models, complains about Apple and reiterates his prediction of a world of billions of AI agents except they are all mere tools with nothing to worry about.
He is high on his new models, saying that they are state of the art and competitive with closed source alternatives.
Llama 3.1 70B and 8B are distillations of 405B.
Zuckerberg says he expected AI to go like Linux and become open source. Now he thinks this is the inflection point, it will happen Real Soon Now, that open source will ‘become the standard’ and Llama to be the standard too. He is still predicting that the future plays out like Linux in his manifesto. Hype!
Big Talk. I give him credit for admitting that he made this prediction before and was wrong then (reminder to: every economist who predicted 9 out of the last 4 recessions). I strongly predict he is once again wrong now.
Big Talk continues later, claiming that there is no longer a big gap between open source and closed source. Acting like this is obviously permanent.
Big Talk gets bigger when he claims Llama 4 is going to be the best, like no one ever was, and his general predictions of future dominance. Hype! He then backs off a bit and says it’s too early to know beyond ‘big leap.’
Expects multimodal within a few months ‘outside of the EU.’
Also in the EU, no matter his intention, that’s how open source works, sir. You can’t write ‘not for use in the EU’ and expect it not to get used there.
Similarly, here Jared Friedman says Meta’s strategy on open weights began ‘with the accidental leak of the weights as a torrent on 4chan.’ And they like to tell versions of that story, but it is Obvious Nonsense. The ‘leak’ was not an ‘accident,’ it was the 100% inevitable result of their release strategy. Who was under the illusion that there would not obviously and quickly be such a ‘leak’?
His exciting use case is fine tuning and perhaps distilling one’s own model.
On the one hand, yes, that is the point of a frontier open model.
On the other hand, the art must have an end other than itself. It is always worrisome when the main exciting use of X is to make more Xs.
Zuckerberg making a strong case here that he is helping China catch up.
Reiterates that Meta developed Llama out of fear of depending on someone else, and that they anticipate (want to cause) an ecosystem around Llama in particular.
There are multiple implicit claims here not that Open Weights in general will catch up with Closed Weights.
Rather, there is the claim that there will be One True Open Source Frontier Model, and essentially One True Model period, and that will be Llama, and everyone else will simply fine-tune and distill it as needed.
They are building partnerships to help people use Llama, including distillation and fine tuning. Drops a bunch of names.
Says people will want to own their models and that’s a big value proposition, and clearly thinks a derivative of Llama will be good enough for that.
Gives standard pro-open arguments, essentially quoting from his manifesto, comments there apply.
His statements do not actually make any sense. Again, see comments below.
Partial exception: His argument that we need to lock down the labs is correct, except his reaction to ‘the labs are not secure’ is to give up, and accept that China will simply steal everything anyway so give it away for free.
AI is technology with most potential to accelerate economy and enable everyone and do all the amazing things. And what helps with that? Same as everything else, you guessed it, open source. Explicitly says this will give other countries counterfactual access to frontier models matching ours to work with, erasing our advantage.
Except that his vision of the future does not include anything fully transformational, positively or negatively, despite his prediction of billions of personalized AI agents. Only the good exactly transformational enough not to terrify you stuff. Why?
I mean, you can guess. It is quite convenient a place to land.
Over four minutes on Apple. He is very mad that he wanted to ship things that were good for Meta, that he says would be good for customers, and Apple told him no.
According to Claude, what did Apple stop? Cross-app tracking, in-app payments without Apple getting a cut, an alternative to an Apple store, making Messenger the default messaging app, doing things in the background that apps aren’t allowed to do, launching an in-app game platform within messenger, Web app versions of their products on iOS that would get around similar restrictions.
According to Llama-405B, what did Apple stop? Cross-platform messaging, augmented reality, game streaming (being able to use a set of games without Apple approving them), digital payments and data tracking. Claude agrees that these were oversights. Digital payments was Libra.
In other words, all of these features were attempts by Meta to get around Apple’s closed ecosystem and do whatever they want, or evade Apple’s requirement that it get a cut of payments (including via crypto), or collect data that Apple explicitly protects as a service to customers.
They were all direct attempts to evade the rules of the system, get data they weren’t supposed to have, evade Apple’s taxes, or to take over relationships and services from Apple. To which Apple said no. So yeah.
That’s because Apple owns the customer relationship exactly on the basis of providing a tightly controlled ecosystem. Users could instead choose Android, an open source OS, as I have, and largely they don’t want that. When they do choose Android, they mostly treat it as if it was closed, even when open.
The rules against AR do seem sad, but that sells Meta more headsets, no?
He then calls all this ‘restrictions on creativity.’
He says Windows is the ‘more open ecosystem’ compared to Apple in PCs, another standard argument, and that’s the better comparison than to Linux or Unix there, and open sometimes wins. Yes, in terms of it not being coupled to hardware, and yes open can sometimes win. Again he doesn’t seem to think AI is anything but the latest software fight, one he intends to ‘win’ the same as AR/VR.
Long term vision for products is lots of different AIs and AI services, not ‘one singular AI,’ as previously noted. Meta AI is ‘doing quite well’ and he thinks they are on track to be most used by end of year, likely a few months early. Give everyone the ability to create ‘their own AI agents.’ AI agents for everyone, everywhere, all the time, he equates it to email.
I haven’t heard any stats on how much people are using Meta AI. It is plausible that shoving it onto every Facebook and Instagram user makes it bigger than ChatGPT on users. Claude is still the best product as per early reports, but their ads aside no one knows about it and it likely stays tiny.
He also wants to present as pro-creator by helping them engage with communities via ‘pulling in all their info from social media’ and reflecting their values.
I think he needs to talk to more creatives and fans, and that this is pretty out of touch unless at minimum he can make a vastly better product than I expect anyone to offer soon.
He thinks the agents and social media communicators are ‘businesses’ for them, despite giving away the model for free. He will ‘build the best products’ rather than selling model access. So in a way this is far ‘more closed’ in practice rather than more open, as they will push their readymade solutions onto people and charge them? Otherwise how are they making money? How will they hold off competition after giving the base model away, what will be the secret sauce?
Presumably the secret sauce will be claiming ownership of your social media, your data and your relationships, and trying to monetize that against you? I’m not sure how they expect that to work.
How does Zuckerberg think about various forms of anti-AI sentiment? He notes the internet bubble, and that AI might need time to mature as a business. Hard to tell when the product is ready to be a good business, and people will likely lose money for quite a while. On the consequences for people’s livelihoods, guess what he leans on? That’s right, open source, that’s how you ‘lift all boats.’ I do not understand this at all.
The issues regular people worry about with AI is about it taking their jobs, why do they care if the AI that replaces them is open? If the AI that enshittifies the internet is open?
What is the ‘closed ecosystem’ going to do to them? There’s clearly already a race to the bottom on price and speed, and if Zuckerberg is right all he’s going to do is bring even more cheaper, faster, smarter, more customized AIs more places faster. Which he’d think was cool, and has its huge advantages to be sure, but the people worried about AI’s mundane downsides are not going to like that for quite obvious reasons even if it all basically works out great.
And of course he does not even mention, in talking about people’s worries about AI and anti-AI sentiment, any worries that something might actually go seriously wrong on any level. He likes to pretend that’s a Can’t Happen.
Sharp contrast overall to his previous statements. Previously he sounded like a (relative) voice of reason, saying you open up some models where the model is not the product and it is safe to do so, but perhaps not others. I could understand that perspective, as I agree that currently the releases are in practice fine, including this one, on their own.
Now instead he’s sounding like a True Believer on a mission, similar to Yann LeCun, and it’s the principle of the thing. Open source is now the answer to everything, good for everything, all the time, no matter what. Full meme. Not good.
One can contrast this with the reaction for example of Andrew Critch, who emphasizes the importance of openness and was eagerly awaiting and praises this release, while warning that we are approaching the day when such a release of a frontier model would be irresponsible and dangerous.
I worry that this is essentially ego driven at this point, that Zuckerberg has failed to keep his identity small and all the people yelling about open models on Twitter and all the advocacy within and from Meta has overridden his ability to consider the practical questions.
On the flip side, the hope is that this is Hype, Big Talk, Cheap Talk. Once he decides to open release 405B, he has little incentive to not present as the unwavering undoubting advocate, until he holds something back later, if he ever does choose to do that, which he might not. Could be no different than his or Musk’s ‘we will have greatest model Real Soon Now’ claims.
Consider the parallel to his Metaverse commitments, perhaps. Or his commitments to the original Facebook, which worked out.
Andrej Karpathy: The philosophy underlying this release is in this longread from Zuck, well worth reading as it nicely covers all the major points and arguments in favor of the open AI ecosystem worldview.
So I suppose this response is a rehash of the same old responses.
Most important is what this ‘covering of all major points and arguments’ doesn’t cover.
Zuckerberg does not even mention existential or catastrophic risk even to deny that they are concerns. He does not address any of the standard catastrophic harms in any other capacity either, or explain how this protects against them.
He does not address potential loss of control. He does not address competitive dynamics and pressures that might induce loss of control in various ways.
He does not deal with any issues surrounding if AI became no longer a ‘mere tool’ used by humans (my term not his), it is clear (from elsewhere) that he thinks or at least reliably claims this won’t ever happen, perhaps because of reasons. This despite his prediction elsewhere of billions of AI agents running around. The open weights arguments seem to consistently assume implicitly that this is a Can’t Happen or not worth considering.
He does not address externalities of safety and user desire to be actively unsafe (or not make sacrifices for the safety of others) in AI versus the relative lack of this issue in other open source software such as Linux, where incentives mostly align.
Indeed he treats this as an identical situation to Linux in almost every way. You would mostly have no idea, reading these arguments, that the subject is even AI.
He does not address constraining of potential future actions and inability to reverse mistakes, or even to stop pushing forward as fast as possible towards whatever individuals most want to run or what is best at causing itself to get copied. He does not address the difficulties this raises for governments or even international cooperation if they need to act, or perhaps he thinks that is good. He does not address the impact on potential racing dynamics.
He does not address the financial incentives of other firms, only Meta, which he simultaneously thinks can freely give away Llama because others will have similarly strong options already, and needs to develop Llama at great cost to avoid being stuck in someone else’s ecosystem. Which is it?
He states that in order to maintain a lead against an adversary, you must continuously give away what you have for free. The argument is that national security and competitiveness is helped because ‘our advantage is openness.’
He is completely the meme that the solution to everything is always Open Source, no matter what, all the time. In his thesis it helps along every axis, solves every problem, and is going to win anyway, and so on. This is not an attempt to inform or seek truth, this is arguments as soldiers to advocate for what he wants. Period.
In short he does not address any of the primary actual objections or concerns.
You can very safely skip both the letter and the rest of my response.
To the extent that I considered deleting the non-summary response below, but hey.
Still here? All right, let’s play it again, Sam.
His safety argument is based on dividing harms into intentional versus unintentional. This is a useful distinction in many circumstances, and in some sense axiomatically true, but he then uses this to assume that any given thing must either be a bad actor, or be due to some sort of active mistake. As I’ve tried to explain many times, that does not cover the space, an unintentional harm can result from everyone following their individual incentives.
Linux gets safer with many eyes because what is safe for the user is safe for others, so the incentives align, and if something goes wrong for you that mostly blows up you in particular, and there is ample opportunity to fix the error after it happens and try again. Neither of these will be true in the context of future more capable AI.
His argument for why open weights are safer for unintentional harm is that the system are more transparent and can be widely scrutinized. Again, that only works if everyone who runs the system actively wants their system to be safe in that same sense. Otherwise, whoops. Overall it is an advantage, but he treats it as the only consideration.
You could call failing to treat safety of your AI the way Linux treats its safety ‘intentional’ harm if you would like, I suppose, in which case intentional harm includes intentionally taking risk, or trading off risk to get reward, but obviously everyone including Meta and every corporation and government will be forced to (and choose to) do some amount of that.
For unintentional harm, he draws distinction between ‘individual or small scale’ actors versions large actors.
For small actors, he goes straight to the ‘good guy with an AI will stop the bad guy with an AI’ rhetoric, in different words. The entire frame is that AI will remain a tool, and the assumption is that wider distribution of identical tools to all players will favor defense over offense, without any argument for why we should presume that.
Zuckerberg says that widely deploying tools at scale is how Meta protects its social networks. That is true, but the reason Meta is able to (somewhat) protect its social networks is that it brings a massive advantage to the table. It is in context the ‘good guy with the tool’ and has better tools than the bad guys with their tools. Ensuring that you can never win that arms race does not seem like a good idea, even in this narrow context.
Why would you ensure your opponents are armed, other than a deeply strange sense of honor? Why would you assume that access to more inference compute will be decisive in such conflicts? Or that not having superior models to work with is actively helpful, as he suggests? I do not see why, and he does not say.
He certainly does not argue why this should allow us to secure ourselves against other forms of malicious use, that do not involve a clear defending agent the way Meta defends its social network. He does not explain how this would defend against the typical catastrophic threats, even if AI remains a tool. There’s only assertion here. He says that with new harms ‘the balance of power would be crucial’ but then uses this to… advocate for giving up a key advantage in the balance of power between the defenders and these potential bad actors. How does that help?
If AI in the hands of such a small actor becomes more than a ‘mere tool’ of course than all of this is out the window.
And in particular, if the threat model is that competition between AIs, and competition between humans with their AIs that they feel constant pressure to give authority to while removing humans from loops, and to turn into increasingly independent and strategic agents? Then open models take away all our options to provide any checks on these competitive dynamics, short of monitoring of every computer everywhere. Such questions are simply not addressed.
If it turns out a mistake has been made, it could easily be too late. Once you release such an open model you cannot take it back, again short of a true dystopian scenario.
Then he asks about ‘states with massive resources.’ Again notice the bifurcation trick, dealing only with one extreme or the other, but yes these are important cases. He says, our advantage is openness, so we must be open and release all our progress to avoid giving China the advantage. You see, China is great at espionage, so they would simply steal our models anyway.
(Which is an excellent point! We should totally be locking down the labs to stop this.)
Zuckerberg also posits another false binary choice:
A ‘world of open models.’
A ‘world of no open models.’
While there are those like Zukerberg that propose that open models be at the frontier and the standard, this ‘world of no open models’ is a fever dream. There are some who take extreme positions, but the central argument is whether there should be some upper bound on how capable open models can be at a given time, or whether open models should be required to abide by ordinary safety regulations.
The argument is not that there should be no open models at all. That is not my position. I have zero problem with his release of the Llama 3.1 70B model. And if I felt that things would stop here, I would not be especially concerned about Llama 3.1 405B either (although for that there are others who feel more strongly, and there are national security concerns), it is the principle and precedent for the future that is being debated here.
Even more than that, the argument that not giving away our best models and entire ecosystem of innovations increases the probability that we will not be in the lead? This is Obvious Nonsense. I notice I am deeply confused.
Linux is a great thing. We do not maintain Linux with the goal of giving America and its allies the lead in operating systems. It will obviously do nothing of the kind. That. Makes. Zero. Sense.
He says most of today’s tech companies are built on open source software. So we should give that software to China so they can build their own companies? To their government as well? Or else we risk losing our lead? What? Seriously, what?
Yet somehow they keep repeating that line.
If everyone affirms this is indeed all the major arguments for open weights, then I can at some point soon produce a polished full version as a post and refer back to it, and consider the matter closed until someone comes up with new arguments.
> For Llama 3 405B , we noted a diurnal 1-2% throughput variation based on time-of-day… the result of higher mid-day temperatures impacting GPU dynamic voltage and frequency scaling.
2025 jobs be like “Applied Metereologist, Pretraining”
Llama-3.1-405B not as good as GPT-4o or Claude Sonnet. Certainly Llama-3.1-70B is not as good as the similarly sized Claude Sonnet. If you are going to straight up use an API or chat interface, there seems to be little reason to use Llama.
I accuse you of being disingenuous. Zuckerberg's points seems pretty clear to me: from his experience in the closed Apple system, he understands the benefits to developers and end users of having an open system. (Obviously Apple benefits from their closed system; I bet he never feigned confusion about why they impose such restrictions.) ChatGPT and other popular LLMs are closed like the iOS, so he intends Llama to be open like Android/Linux, or if you feel the inscrutable nature of the models precludes that, open like Windows.
The bit about America's advantage being "decentralized and open innovation" of course involves a bit of rah-rah jingoism, but it's a coherent claim: what developers are free to create with open systems like the one he wishes to establish benefits America more than China, even if China would also benefit.
Your "which is it?" suggests you think there is some contradiction to resolve. Developers have a few different options right now, but the reasonable choices are all closed, and if they invest too much time and effort into those, the result of network effects will cause Meta to suffer from essentially vendor lock-in. Hence the need to have an open system that even if not quite as good as the best, is close enough that the flexibility and control that the openness offers makes up for the shortfall.
Zuckerberg's also clearly not the Open Source Zealot you caricature him to be. The Quest is pretty good on openness, but its Horizon OS is not open source, and there are limitations on camera access, and Meta can still close down all sideloading capabilities at will.
Also, to engage in a little bit of mind-reading, Zuckerberg sees no enemies in China, only in OpenAI et al. through the "safety" regulation they can lobby the US government to enact. The plausible catastrophe to work against then is them getting as much of a stranglehold over the AI space as Apple has over its own. Of course, he can't say this out loud without hastening the doom he's trying to avert.
"Also, to engage in a little bit of mind-reading, Zuckerberg sees no enemies in China, only in OpenAI et al. through the "safety" regulation they can lobby the US government to enact."
This is a reasonable position, apart from the fact that it is at odds with the situation on the ground. OpenAI are not lobbying the government in favour of SB 1047, nor are Anthropic or Google (afaik). It's possible that in future they might, but other than Anthropic I think this is very unlikely.
For me, the idea of large AI companies using X-risk fears to shut down competition falls into the same category as the idea that large AI companies are using X-risk fears to hype their products. I think they are both interesting schemes that AI companies might be using in worlds that are not this one.
It's unbelievable how similar/convergent the big LLMs are. Only a slight improvement with 100x compute?? People have much bigger differences with much less variation of the core inputs (eg number of neurons). I wonder what the best explanation is. I can think of a few mediocre explanations.
If everyone affirms this is indeed all the major arguments for open weights, then I can at some point soon produce a polished full version as a post and refer back to it, and consider the matter closed until someone comes up with new arguments.
Feels like the vast majority of the benifits Zuck touted could be achieved with: 1. A cheap, permissive API that allows finetuning, some other stuff. If Meta really want people to be able to do things cheaply, presumably they can offer it far far cheaper than almost anyone could do it themself without directly losing money. 2. A few partnerships with research groups to study it, since not many people have enough resources that doing research on a 405B model is optimal, and don't already have their own. 3. A basic pledge (that is actually followed) to not delete everyone's data, finetunes, etc. to deal with concerns about "ownership"
I assume there are other (sometimes NSFW) benefits he doesn't want to mention, because the reason the above options don't allow those activities is that Meta loses reputation from being associated with them even if they're not actually harmful.
Are there actually a hundred groups who might usefully study a 405B-parameter model, so Meta couldn't efficiently partner with all of them? Maybe with GPUs getting cheaper there will be a few projects on it in the next MATS stream? I kinda suspect that the research groups who get the most out of it will actually be the interpretability/alignment teams at Google and Anthropic, since they have the resources to run big experiments on Llama to compare to Gemini/Claude!
A basic pledge (that is actually followed) to not delete everyone's data, finetunes, etc.
Such a commitment would not be credible. Even if you're confident Meta won't do the classic Google thing of sunsetting the service, or go broke, or change CEOs, they'd still be subject to things like DMCA takedowns that running locally safeguards you from.
This is a stronger argument than I first thought it was. You're right, and I think I have underestimated the utility of genuine ownership of tools like fine-tunes in general.
I would imagine it goes api < cloud hosting < local hosting in terms of this stuff, and with regular local backups (what's a few TB here or there) then it would be feasible to protect your cloud hosted 405B system from most takedowns as long as you can find a new cloud provider. I'm under the impression that the vast majority of 405B users will be using cloud providers, is that correct?
I think a lot of it is simply just eating away at the margins of companies and product that might become larger in the future. Even if they are not direct competitors, it's still tech investment money going away from their VR bets into AI. Also big companies fully controlling important tech products has proven to be a nuisance to Meta in the past.